基于机器学习的新发急性缺血性卒中患者1年功能预后预测研究
2022-04-06陈思玎俞蔚然黄馨莹刘欢姜勇王拥军
陈思玎,俞蔚然,黄馨莹,刘欢,姜勇,2,王拥军,3,4
卒中是全球第二大死亡原因,也是我国死亡和残疾的主要原因[1-2]。急性缺血性卒中(acute ischemic stroke,AIS)占全部卒中的80%,具有高致残率、高致死率及高复发率等特点[3]。利用预测模型准确预测AIS患者预后,提升患者的精准风险分层与诊疗策略管理、优化医疗资源配置,从而改善患者预后是卒中二级预防中不可忽视的环节。随着大数据时代的到来,计算机算力的提高和算法的更新,机器学习在疾病预测方面取得了较大的进展。其中,多种集成模型(如各种树模型)在疾病预测方面逐渐呈现出一定优势。本研究利用中国国家卒中登记(China national stroke registry,CNSR)数据库研究新发AIS患者1年功能预后的相关因素,比较机器学习模型和logistic模型的预测性能,为相关研究和临床工作提供参考。
1 对象与方法
1.1 研究对象 本研究的研究对象来源于CNSR数据库。CNSR为全国范围内的前瞻性、观察性急性卒中登记研究,其数据库资料连续记录了2007年9月-2008年8月全国27个省和4个直辖市(包括香港),共132家医院收治的急性卒中患者信息。入组标准:①发病年龄≥18岁;②临床确诊为缺血性卒中或TIA;③发病7 d内就诊并住院治疗的患者。排除标准:①既往有卒中病史;②1年功能预后结局缺失。CNSR共纳入了13 616例AIS和TIA患者,其中AIS患者为12 415例。本研究纳入CNSR数据库中新发AIS患者的资料。
1.2 预测变量及结局
1.2.1 预测变量 结合临床经验及AIS早期管理指南、文献报道的相关预后预测模型和CNSR数据特点确定备选预测因子[4-5],使用病例报告表收集患者的人口学特征、卒中前mRS、饮酒史、既往史、用药史、入院查体、发病-到院时间、入院实验室检查、TOAST分型、入院NIHSS、出院NIHSS、出院带药、90 d用药依从情况、1年用药依从情况等共37个变量。其中人口学特征包括年龄、性别、教育水平;既往史包括冠心病、心房颤动、糖尿病、高血压、周围血管病;用药史包括抗血小板药、抗凝药、调节血脂药、降糖药、降压药;入院情况包括入院时BMI、心率、收缩压、舒张压、意识障碍、肢体运动功能障碍、视野缺损;入院实验室检查包括血糖、白细胞、肌酐、血小板;出院带药包括抗血小板药、抗凝药、调节血脂药;用药依从性包括抗血小板药物和抗凝药物的依从性。
1.2.2 结局变量 本研究结局变量是新发AIS患者发病1年预后不良。研究采用中心化电话随访的方法,使用mRS评估发病1年时的功能预后,随访由经过统一培训的中心化随访员进行。根据mRS将患者分为预后良好(mRS 0~2分)和预后不良(mRS≥3分)两组。
1.3 数据预处理 删除不合逻辑的异常值,连续变量缺失值利用线性插值法填补,分类变量缺失值利用众数填补。
1.4 模型构建方法
1.4.1 特征选择 特征选择是在建立模型之前减少输入预测因子数量的过程。可以简化输入预测因子的数量同时提高运算效率,提高模型的可解释性。本研究的特征选择步骤在训练集中利用logistic算法进行,利用OR和95%CI等指标增加模型的可解释性。将单因素logistic回归中P<0.1的预测因子纳入多因素分析,使用逐步回归最后确定进入模型的预测因子。
1.4.2 机器学习模型 本研究涉及的机器学习模型有CatBoost模型、XGBoost模型、梯度提升决策树(gradient boosted decision trees,GBDT)模型、随机森林模型4种树模型。
(1)CatBoost模型:CatBoost模型是一种创新的有序梯度提升算法,它使用基于有序目标的统计量进行分类特征处理和排列策略来避免预测偏移,提高了算法的可泛化能力。CatBoost是一种新的集成学习算法,具有独特的对称数结构,通过计算叶子节点的值来构造决策树,非常适合分类和异构数据的学习任务,同时降低了对超参数调优的要求[6]。
(2)XGBoost模型:XGBoost模型是一种可扩展的、高效率的机器学习分类器,在2016年由陈天奇等学者开发,是集成学习Boosting系列中支持自定义代价函数的模型,早期是由GBDT模型发展而来,它不仅以提升的方式组合多个决策树,还可以进行二次泰勒展开[7]。XGBoost模型支持并行运算且在目标函数基础上加入了正则项,以得到最优解,同时避免过拟合。
(3)GBDT模型:GBDT中使用的决策树是一个回归树。每次训练的目标是减小最后一次训练的误差,最终使误差最小,模型采用梯度下降法减小误差[8-9]。
(4)随机森林模型:随机森林是将决策树作为元分类器的一种集成学习方法,对变量共线性不作要求。是一种集成的监督学习方法,它由多个决策树对应不同的子数据集组成。计算每棵树的结果,并得到预测结果的平均值。这种方法可以减少决策树中的方差[10]。
比较不同模型对预后不良的预测性能时,主要从区分度和校准度两个方面进行评价。本研究采用C统计量即ROC中的AUC值来评估区分度;采用Brier得分(0~1分)评估校准度,Brier得分越趋近0,模型的校准度越好;本研究其他评估的指标有准确率、阳性预测值、阴性预测值和F1分数。
应用Python 3.6.8软件进行预测模型建模和可视化,应用SAS 9.4统计软件进行logistic回归分析。本研究利用Python 3.6.8软件中train_test_split函数以进行5次随机分组,将纳入的研究对象按7∶3比例随机分为训练集和测试集。利用GridSearch CV在训练集中进行10折交叉验证调参,使模型在训练集中AUC表现最优,结合特征选择后的预测因子进行反复训练和参数优化。测试集仅参与训练好的模型评价。进入每个模型训练和测试的预测因子都是经过特征选择的最优预测因子集合。logistic模型采用逐步回归法,其预测因子的效应通过回归系数或OR值及其95%CI体现。以P<0.05为差异有统计学意义。
2 结果
2.1 基线信息和随访情况 本研究共纳入12 415例AIS患者,排除有卒中病史的患者4172例,1年mRS资料缺失13例,共纳入8230例新发AIS患者进入研究,其中1年预后良好组5870例,预后不良组2360例。入组患者的平均年龄64.4±12.8岁,女性3113例(38.7%),高中及以上教育水平2329例(29.0%)。单因素分析结果显示,1年预后良好和预后不良组间的人口学特征、饮酒史、冠心病史、心房颤动史、糖尿病史、周围血管病史、卒中前mRS、降糖药物用药史、入院查体情况和实验室检查、发病-到院时间、TOAST分型、入院和出院NIHSS、出院带抗血小板和调节血脂药物比例、90 d和1年抗血小板药服用依从比例等指标的差异均有统计学意义(表1)。

表1 新发AIS患者1年预后良好和预后不良患者基线和随访资料比较
2.2 特征选择结果及调参 多因素分析结果显示增龄、女性、卒中前mRS≥3分、入院NIHSS、出院NIHSS、肢体运动功能障碍、周围血管病史、入院血糖、调节血脂药物(出院带药)、抗血小板药(1年服药依从)可作为预测模型的预测因子(表2)。
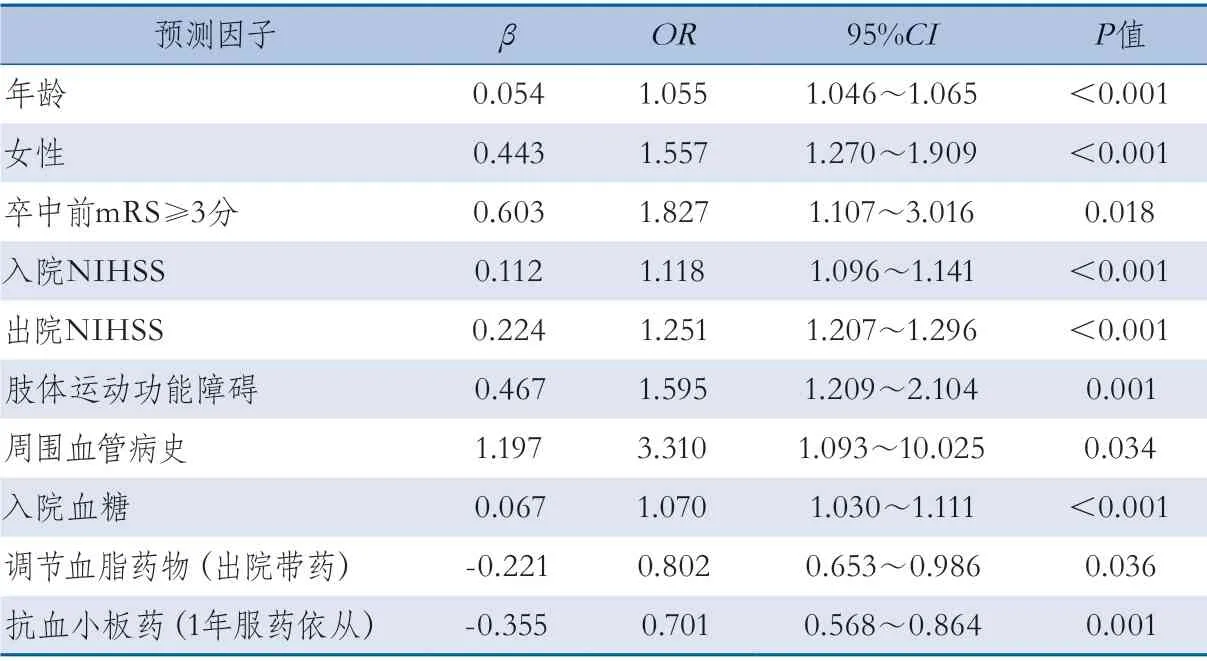
表2 训练集多因素logistic回归分析结果
2.3 机器学习模型和传统logistic回归模型预测性能比较 在测试集中,Catboost模型预测1年预后不良的AUC最高,其次为XGBoost模型、GBDT模型、随机森林模型和logistic回归模型(图1、表3)。Catboost模型(P=0.0130)、XGBoost模型(P=0.0133)、GBDT模型(P=0.0229)、随机森林模型(P=0.0429)对1年预后不良的预测性能均优于logistic回归模型。每个模型的校准度均良好(表3)。

表3 机器学习模型和传统logistic模型预测性能比较(测试集)
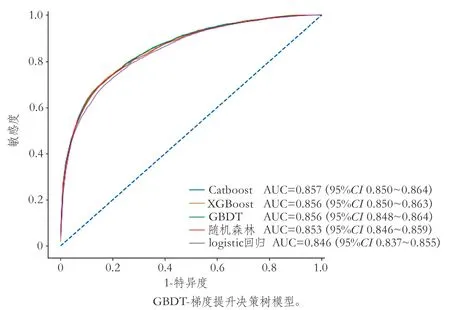
图1 机器学习模型和传统logistic模型ROC曲线(测试集)
3 讨论
本研究基于机器学习的方法建立了新发AIS患者1年功能预后的预测模型,为了增加预测因子的可解释性,采用了多因素logistic来进行特征选择。然后利用机器学习的算法进行建模,并与传统的logistic回归模型进行比较。研究结果显示,在区分度方面本研究所训练的Catboost模型、XGBoost模型、GBDT模型和随机森林模型均优于传统logistic回归模型,同时本研究建立的每个模型的校准度均良好。
既往常用的AIS功能预后预测模型主要为评分量表,多是基于logistic回归算法建立的,常见的有洛桑急性卒中登记分析(acute stroke registry and analysis of Lausanne,ASTRAL)评分[11-12]、缺血性卒中风险预测评分(ischemic stroke predictive risk score,IScore)[13-14]以及血管事件总体健康风险(totaled health risks in vascularevents,THRIVE)评分[15-17]等。其中ASTRAL评分是利用多因素logistic回归筛选出年龄、入院NIHSS、发病至入院时间、视野、血糖和意识水平6个预测变量,并对各变量进行分级赋值,应用最广泛[11-12]。2016年,Cooray等[18]利用ASTRAL量表对36 131例AIS患者进行了90 d预后不良的预测,其外部验证的AUC为0.790。
随着大数据时代的到来和算法的更新,海量数据和机器学习算法的发展为脑血管病预测提供了新的技术。不过,在已发表的文献研究中,无论是评分量表还是机器学习模型,更多的是对AIS患者出院和短期预后的预测,1年以及长期预后研究较少。相较于短期预后预测,AIS患者的长期预后更可能受到各种因素的影响,如长期的服药依从性、生活习惯、经济情况、文化程度等。所以本研究在纳入变量时,除了基于疾病诊疗指南、相关预测模型以及公共卫生知识纳入的基线信息,还纳入了出院带药情况、90 d及1年服药依从情况等。
本研究采用了logistic回归的方法在训练集进行特征选择,最终确定的预测因素包括增龄、女性、卒中前mRS≥3分、入院NIHSS、出院NIHSS、肢体运动功能障碍、周围血管病史、血糖、调节血脂药物(出院带药)和抗血小板药(1年服药依从)。机器学习算法利用logistic回归方法选择的预测因子进行建模,在测试集上预测性能表现仍优于传统logistic回归模型,说明机器学习算法优于传统logistic回归模型。这可能由于机器学习算法不仅有处理海量数据的优势,更有诸多参数可以进行配置优化,所以相较于传统logistic模型更有灵活性。
在本研究中,测试集中Catboost模型预测性能最好,其次为XGBoost模型、GBDT模型、随机森林模型以及logistic回归模型,整体机器学习模型预测性能优于传统logistic回归模型,,同时本研究建立的每个模型的校准度均良好,且机器学习模型校准度Brier分数均低于logistic回归模型。Catboost模型作为一种新的集成学习算法,具有独特的对称数结构,通过计算叶子节点的值来构造决策树,它嵌入了自动将类别特征处理为数值特征的创新算法。Catboost模型还可以利用特征之间的联系,采用排序提升的方法对抗训练集中的噪声点,从而可以有效避免估计偏差,解决预测偏倚问题。此外,Catboost模型鲁棒性更强,减少了对很多超参数的调优要求,并降低了过拟合的机会。
本研究纳入样本量大,涵盖我国大多数地区,对我国新发AIS人群的代表性较好。本研究除了基线临床信息外,还纳入了实验室检测指标、出院带药情况、90 d及1年用药依从性情况,在对新发AIS患者1年功能预后预测时纳入的变量维度更广泛。本研究的局限性:一方面是缺乏影像学指标,可能限制了预测模型的预测效能。另一方面尽管CNSR是全国性的多中心前瞻性队列,在中国卒中人群中有较好的代表性,但仍需要进一步在独立的外部人群队列中进行外部验证,来检验预测模型的鲁棒性和可外推性。未来将会进一步探究不同模型对于缺血性卒中的适应条件,在特征选择、模型建立以及模型验证方面进行全面研究,以期为后续建立更加完善的AIS患者功能预后预测提供更全面的借鉴。
【点睛】机器学习算法模型因其可以处理海量数据,优化参数的配置,已经成为卒中风险和预后预测研究的新兴技术,本研究构建了CatBoost、XGBoost、GBDT和随机森林模型4种预测AIS患者1年预后的机器模型,并证实其预测效能优于传统的logistic回归构建的模型。
