基于孪生网络特征融合与阈值更新的跟踪算法
2022-04-02杨小军
刘 洋,杨小军
(长安大学 信息工程学院,陕西 西安 710064)
0 引 言
计算机视觉已经发展了很多年,视频目标跟踪作为其中十分火热的课题之一,在现实生活中应用广泛[1]。其主要任务是通过第一帧中给出的目标的初始信息(一般以矩形框表示),在后续帧中自动输出目标的参数信息[2]。在实际跟踪过程中,仍存在着诸多难点,例如背景相似、光照变化、严重遮挡以及目标姿态变化等,这些都会导致跟踪精度下降[3]。早期目标跟踪领域采用的算法可归结为传统目标跟踪算法,它通常使用生成式模型,以卡尔曼滤波[4]、粒子滤波[5]、Meanshift算法[6]、Camshift[7]算法和光流法[8]等为代表。随着相关滤波研究的发展,出现了基于相关滤波器的跟踪算法,使传统的时域计算变为频域计算,大大减少了计算量,有效提升了跟踪速度。2010年,MOSSE利用目标的特征来训练滤波器,对下一视频帧滤波[9]。CSK在此基础上加入了循环矩阵和核函数,大大提高了跟踪速度[10]。随后,KCF引入HOG特征(梯度颜色直方图)来表征运动目标的纹理特征和形状特征[11],成为相关滤波最为经典的算法。2013年后,深度学习领域逐渐火热,基于该领域的算法得到空前发展。DLT率先采用“预训练+微调”的方式,解决了训练样本过少的问题[12]。2016年,L.Bertinett等提出了十分具有代表性的SiamFC算法,该算法采用权值共享的两条孪生结构,通过度量相似性来进行目标跟踪[13],使得跟踪速度得到空前提高。Li等人提出的SiameseRPN首次将RPN的思想融入目标跟踪,避免了SiamFC中多尺度测试的问题,实现了非常高的跟踪速度和精度[14]。之后,针对深层网络会使得跟踪精度下降的问题,SiamRPN++通过实验表明其原因在于破坏了网络的空间不变性,并通过引入均匀分布采样这一策略,训练出了基于残差网络Resnet的追踪器[15]。Wang等提出的SiamMask通过增加分割分支,使得普通的目标跟踪框架可实现实时分割[16]。虽然SiamFC显著提高了深度学习方法跟踪器的跟踪速度,但在复杂场景下仍然无法较好地适应目标和背景信息的变化,当目标发生严重形变或者目标附近出现干扰时,跟踪的精度会大大降低。
针对以上问题,该文提出一种基于注意力机制的融合特征跟踪算法,并引入加权平均模块和阈值模板更新模块。该算法延续了SiamFC的基本框架,将浅层的AlexNet[17]替换为深层网络MobileNetV2,在获取更深层特征信息的同时,尽可能减少参数量。同时由深至浅进行多层特征融合,使得语义特征与表观特征进行互补,解决复杂背景中目标与背景相似以及目标快速移动所导致定位不足的问题。模板分支的特征通过注意力机制模块,突出目标特征的重要信息。再将融合并通过注意力机制后的特征向量的互相关结果与原始提取的特征向量的互相关结果进行加权平均获得响应图,进一步提升模型的鲁棒性。最后,比较相似度分数与设定的阈值大小来判断是否需要模板更新,并通过实验找到了更新的最佳阈值。在OTB100数据集上的实验表明,该算法在面对各种具有挑战因素的视频序列时仍能取得较好的跟踪效果,具有良好的鲁棒性。
1 算法网络架构
1.1 算法框架概述
算法的整体框架如图1所示。模板分支与搜索分支由两条权值共享的卷积神经网络组成。使用改进后的MobileNetV2作为特征提取网络,并对第三、五、七个BottleNeck提取到的特征进行自适应融合,使得特征同时具备深层与浅层的信息。模板分支的特征通过注意力机制模块,突出目标的关键特征。引入加权平均模块,将经过融合与增强后的特征的卷积结果与原始的特征卷积结果进行权值为u的加权平均,得到最终的响应分数图。最后,比较相似度与阈值的大小,根据比较结果进行模板更新,并利用重复实验的办法,找到最优的阈值。

图1 算法整体结构
1.2 特征提取网络与特征融合
1.2.1 特征提取网络
MobileNet是由谷歌提出的一系列轻量级的神经网络,采用深度可分离卷积操作(deep-wise)替代原来的传统3D卷积,大大地减少了运算量。该文使用MobileNetV2替换原先较浅的AlexNet,以获得更深层的语义信息,并对网络结构做出改进,平衡参数规模与特征丰富度,适应该跟踪任务。
MobileNetV2由三个卷积层、一个池化层和七个卷积区(BottleNeck)组成。针对目标跟踪的任务特点,去掉了最后一个卷积区后面的两个卷积层和池化层,保留提取初级图像特征的常规卷积层。
高维tensor可以获取更丰富的特性信息,而低维tensor能带来更小的计算量。MobileNetV2采用一种反向残差结构,以较小的计算量取得了较好的性能,很好地平衡了速度与精度的问题,其结构如图2所示。首先,通过Expansion Layer层扩张维度,之后进行深度可分离卷积运算,再由Projection Layer降维,使得网络重新变小。使用Relu6作为激活函数是为了在低精度的计算下也能获得高数值分辨率,而最后一层降维使用线性激活函数是为了防止小于0的元素经特征提取后丢失信息。
1.2.2 特征融合
深层特征和浅层特征包含的信息是不同的。在对一些属性相同但表现差异较大的目标进行跟踪时,若仅采用深层特征,则会缺乏位置信息,导致对快速移动的目标定位能力不足,从而导致跟踪精度下降。因此,为了提高算法的准确性,该文抽取第三、五、七个BottleNeck的特征,由深至浅,采用双线性插值公式,将深层提取的小分辨率特征图进行扩大,逐步地完成特征融合。双线性插值公式为:
(1)
1.3 注意力机制(CASA)
注意力机制的引入在计算机视觉领域大获成功。该文参考由胡杰等人在2017年Image分类比赛中提出的SENet(Squeeze and Excitation Net)模型,以及X.Wang等人提出的Non-Local模型,分别设计出通道注意力模块与空间注意力模块,对模板分支上的融合特征进行空间和通道上的加权,进一步提升模型的判别能力。由于搜索域含有大量无关信息,加入注意力模块易导致模型对某些无关特征过度关注从而降低模型的普适性,故只在模板分支加入。
1.3.1 通道注意力
不同的通道是从不同的角度对目标的信息构建特征,因此各通道的重要程度并不相同。SENet算法提出一种压缩激励模型,使得各个通道之间产生依赖关系,网络通过自适应学习,对基于通道的特征响应进行重新校准,提高了网络的表达能力。参照这一模型,该文引入了一种通道注意力机制模块,加强与目标物体相关的特征通道权重,降低无关的特征通道权重,同时也改变了通道之间的依赖性。其结构主要由全局池化层、激活层以及两个全连接层构成,如图3所示。
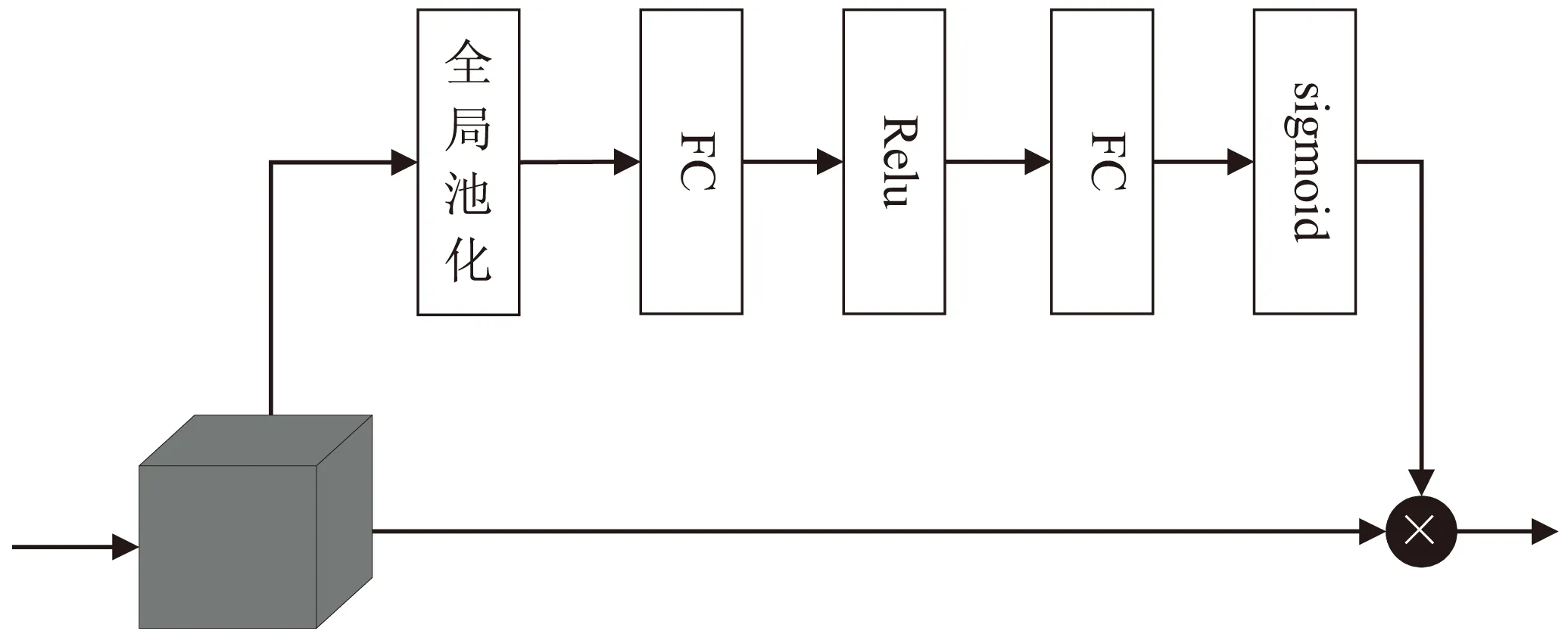
图3 通道注意力模块
将融合后的特征图的通道定义为:
A=[a1,a2,…,an]
(2)
式中,ak∈RH×W,k=1,2,…,n。
输入特征经过池化和FC得到压缩,再由Relu激活获得非线性的性质,然后再通过第二个FC层恢复,最后由sigmoid激活。权值向量可以表示为:
α=[α1,α2,…,αn]
(3)
式中,αk∈RH×W,k=1,2,…,n。
将权重向量α与原来的特征向量A相乘,原始的特征向量通道便被赋予了不同的权重,表示为:
(4)
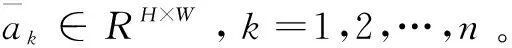
1.3.2 空间注意力
Non-Local的提出最先被应用在图像识别任务上,是一种空间注意力机制模型,它建立起特征图上任意两个位置之间的联系,并且引入残差连接,使得模型能够十分方便地在任意一个预训练过的网络中嵌入进去而无需改变原来的网络结构。在目标跟踪的过程中,只关心与跟踪任务相关的区域,而不关心无关的区域。因此,不同空间区域应该被赋予不同的权重。参考上述一模型,该文引入一种空间注意力模块,首先通过加权求和,使得特征图上的每一个位置都包含周围所有位置的特征信息,然后将原始特征与含有空间位置信息的特征相加,原始特征便被赋予了不同空间位置的权重,其结构如图4所示。
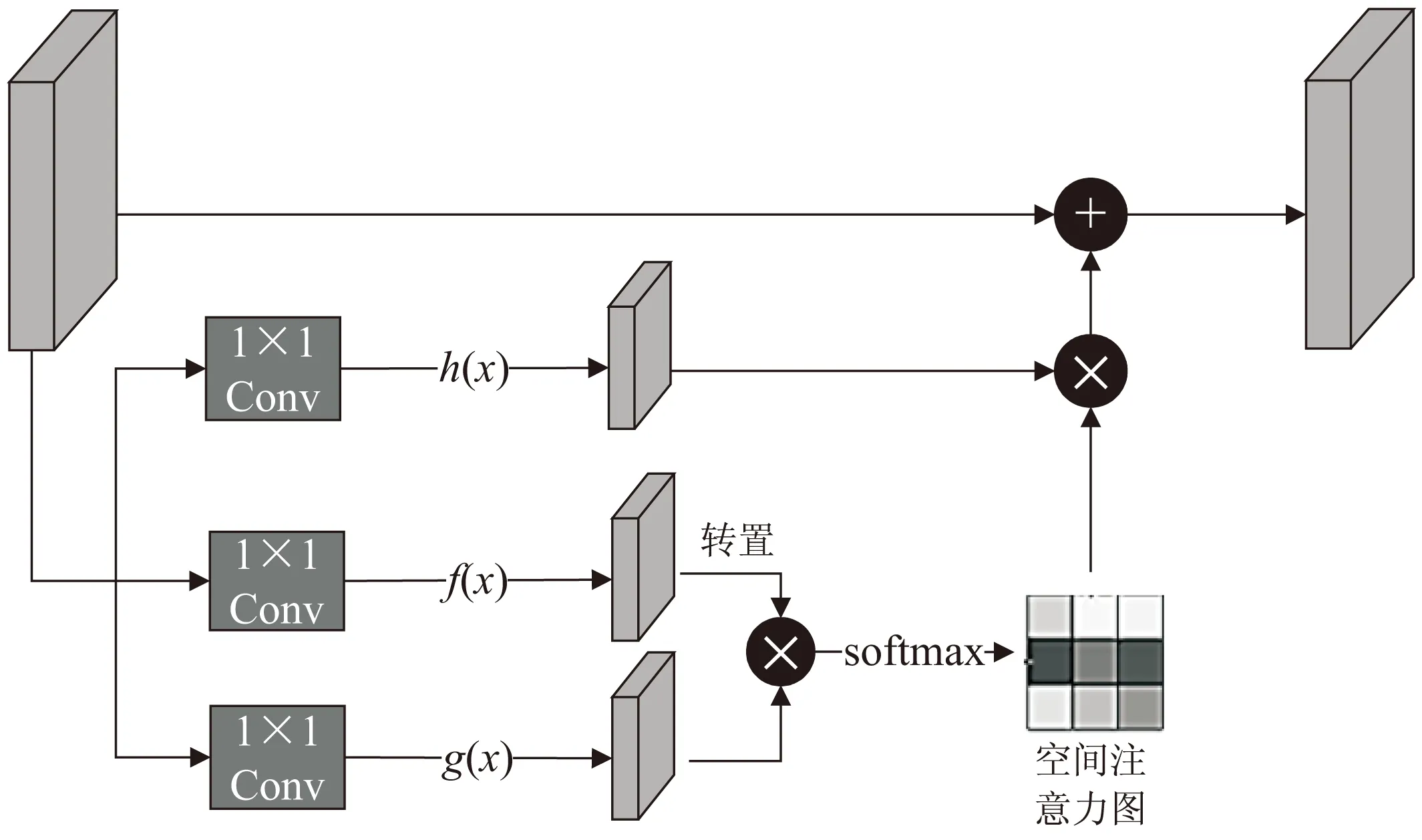
图4 空间注意力模块
首先,对输入的特征图分别使用三个1×1的卷积核进行卷积。接着通过三个变换函数f(x)、g(x)、h(x)进行转换,其表达式为:
(5)
式中,W1、W2、W3分别表示f(x)、g(x)、h(x)的权重。将通过f(x)后的输出转置后与g(x)的输出相乘,并用softmax函数进行激活,得到空间注意力图。它表示任意两个位置的相关程度:
(6)
式中,a和b分别表示图像上的第a个像素位置和第b个像素位置。再将此空间注意力图与h(x)相乘,输出结果乘以权重系数β再加上原先输入的特征,即可得到经过了空间注意力模块调整过后的特征图。计算公式为:
(7)
1.4 加权平均模块
为进一步提高鲁棒性,避免模型过于关注某个局部的训练特征,该文采用加权平均的思想,将两个分支的互相关结果进行一次加权平均。其中分支一为经过特征融合与注意力机制后的特征图的互相关运算结果,分支二为由MobileNetV2网络提取的原始特征图。计算公式如下:
f(p,q)=μfm(p,q)+(1-μ)fa(p,q)
(8)
式中,fm为经过特征融合与注意力机制的互相关结果,fa为原始提取的特征互相关结果。μ为权重,文中μ=0.6。
1.5 阈值模板更新
与大多数的目标跟踪算法类似,SiamFC在目标的跟踪过程中,始终采用第一帧作为模板而不进行模板的更新。这是因为第一帧包含目标最准确的信息,同时也能大大提升跟踪的速度。然而,随着跟踪时间的增长,当目标因遮挡、光照、运动等因素出现较大的形变时,继续使用第一帧作为模板则会导致跟踪的精度下降,甚至跟踪失败。但如果每次都进行更新,既增加了运算量,降低了目标的跟踪速度,又容易引入噪声等干扰因素。因此,该文采用一种阈值更新的方式,将得到最终响应图上的最大相似度值后,与设定阈值进行对比判断,以决定是否需要对模板进行更新。具体而言,相似度高于阈值,则不进行更新,仍采用当前模板,继续读取下一帧的数据进行跟踪任务。相似度低于阈值,则进行更新,更新方式为用当前帧替换模板帧。为了确定合适的阈值,该文将阈值分别设定为95%、93%、91%、90%、89%、87%、85%并进行重复实验,记录相应的精确度和成功率,如表1所示。
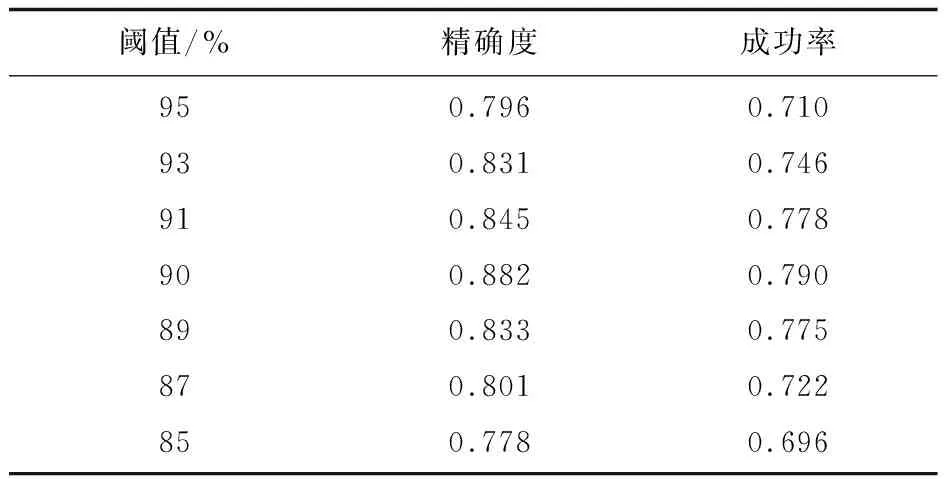
表1 不同阈值下的跟踪精确度和成功率
可以看出,将阈值设定为90%时,获得了最高的精确度与成功率。通过这一机制,即使目标出现了遮挡或者较大的形变,算法依然能较好地跟踪到目标。
2 实验结果与分析
2.1 实验环境及参数
该算法的软件环境采用Ubuntu18.04搭载pycharm,采用pytorch编程框架验证算法的性能。实验平台配置为Intel Core i7-9750 2.60 GHz CPU和GeForce GTX 2080Ti GPU。算法执行的平均速率为32帧每秒,利用在ImageNet数据集上预先训练好的权重初始化网络参数。
2.2 数据和评估方法
为验证算法的有效性,选取包含各种挑战性因素的公开标准测试数据集OTB100进行实验。在测试序列中从第一帧的基础真值位置初始化它们,采用距离精度(distance precision,DP)、成功率(success rate,SR)作为实验的主要评价指标,计算公式如下所示。
DP=lDP(CLE≤T0)/l
(9)
式中,lDP表示中心位置误差小于等于阈值的帧数,CLE表示预测目标中心和实际目标中心间的欧氏距离,T0表示阈值像素,一般设置为T0=20 px,l表示当前视频序列的总帧数。
另外,成功率图曲线下方的面积(AUC)也可用于评估跟踪的成功与否,该面积也可用于对目标跟踪算法进行排序,公式如下。
(10)
2.3 定量比较
将该文提出的算法和一些现有算法在OTB100上进行对比,对比的算法有MOSSE,SRDCF,MDNet,SiamFC,SiamRPN,DaSiamRPN,CFNet,Staple。可以看出,由于加入了基于注意力机制的特征融合算法以及加权平均模块和阈值模板更新模块,该文提出的算法取得了较好的结果。跟踪结果精度和成功率如图5所示。
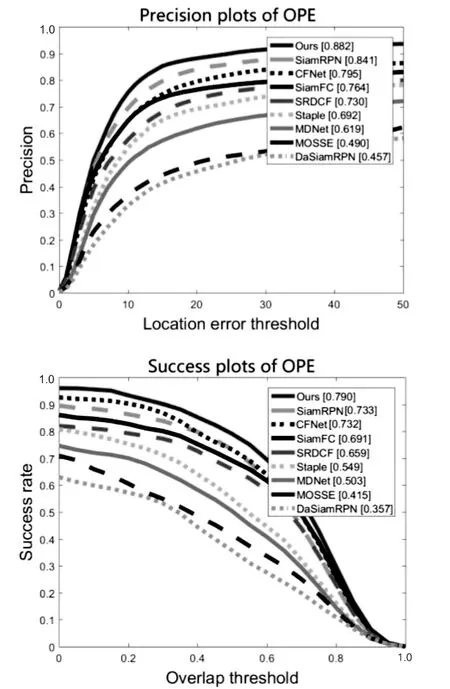
图5 精度和成功率对比
图5显示了所有比较算法在OTB100上的一遍验证(OPE)的测试结果。可以看出,该文提出的算法均取得了较好的跟踪精度和成功率,和SiamRPN算法相比较,精度上提升了4.1%,成功率上提升了5.7%。总体来说,提出的算法在精度和成功率上都比其他几种算法优越。
2.4 定性比较
为了更好地体现该跟踪算法的优异性能,再次在数据集OTB100中选取了一些代表性的视频序列进行测试,且与不同的算法进行对比,结果如图6所示。
综合上述实验的对比结果,可知该算法对目标在快速运动、尺度变化、平面内旋转以及低分辨率等方面,均展现出优越的跟踪性能。从图6可以看出,在Human2视频序列中,目标存在运动模糊和旋转的变化,该算法较其他算法能够更加准确地跟踪目标。在Panda视频序列中可以看出,当低分辨率的目标尺度发生变化时,从973帧开始,其余算法已经跟丢,而由于该文加入了基于注意力机制的特征融合策略以及阈值模板更新模块,使得该算法始终能有效地完成跟踪任务。

图6 算法在不同视频序列的跟踪结果
3 结束语
该文提出的基于孪生网络特征融合与阈值更新的跟踪算法,通过对深层网络提取到的特征进行多层融合,并通过模板分支的空间与通道的联合注意力机制,使得特征能够具备多重有效信息,且能更好地关注于目标的关键特征。通过加权平均模块对分数图进行融合,进一步提升模型的性能。阈值模板更新机制既减少了频繁更新带来的计算量,又有效避免了跟踪漂移问题,通过选取不同的阈值进行重复实验,确定了最优阈值。实验结果表明,相对于一些已有算法,该算法在精确度、成功率上均有所提升,展现出了更强的鲁棒性。
