基于改进K均值聚类算法的汽车行驶工况构建
2022-04-02李春生
李春生,余 虎
(东北石油大学 计算机与信息技术学院,黑龙江 大庆 163318)
0 引 言
汽车行驶工况的构建对汽车的研发具有重要的作用,不仅是汽车测试汽车能耗排放的方法,也是汽车行业的重要技术。其构建过程呈现出行驶的运动学特征,并且是汽车各种性能指标优化的重要基准[1-2]。当今许多汽车行业发展迅速的国家,设计出符合国情的汽车行驶工况,并已完善使用,如Nyberg等[3]将驱动循环等效公式算法应用在汽车行驶工况的构建中,把行驶循环转化为等价循环;Nguyen等[4]提出了基于马尔可夫链理论的行驶循环构建过程;Fotouhi等[5]、John Brady等[6]均采用K均值聚类算法进行汽车行驶工况的研究。
目前,国内相关学者在汽车行驶工况构建的研究中,依据ECE工况[7-9],完善符合国内汽车行驶工况的构建方式。为了更好地反映国内汽车和路况的运行特点,王国林等[10]提出基于短行程法的行驶工况构建;秦大同等[11]和彭育辉等[12]使用K均值聚类算法进行城市循环工况构建;董恩波等[13]将自组织特征映射神经网络算法与K均值聚类算法相结合构建车辆行驶工况,但聚类中最优K值如何选择尚未确定;高建平等[14]在汽车行驶工况的构建中使用全局K均值聚类算法进行改进,但处理样本数据的时间较长。
针对以上分析,该文提出改进的K均值聚类算法,降低算法迭代次数,减少聚类运行消耗的时间。再以CH指标数作为最优聚类数的选择标准,并依据聚类后的结果构建汽车行驶工况,通过比较实际数据,检验该方法的有效性和准确性。
1 行驶数据预处理
1.1 数据误差分析
以某城市汽车行驶的实际数据为例,采集真实数据(采样频率1 Hz),采集的样本数据集通常存在一些因外界引起的异常数据,异常数据会对实验结果的准确性造成影响,因此需要对异常数据进行合理的分析处理。根据样本数据的采集方式、采集环境等可能引起数据异常的原因,总结出以下5种异常数据类型:
(1)时间异常。
当汽车行驶通过隧道或者较高建筑物时,可能导致GPS信号异常,传输的时间数据存在不连续。通过编写程序将时间不连续的数据点进行缺失值标注,将其筛选出来,采用平均值法对其进行数据修补。
(2)加、减速度异常。
加、减速度异常指的是速度瞬间过大产生的数据,因为在正常行驶过程中,汽车出现突然加速度变大的概率较小,所以对于这样的异常数据可以采用线性插值法来平滑处理。
(3)长期停车异常(长时间怠速异常)。
停车异常的现象是在停车熄火和不熄火时,设备采集器仍然运行的现象,数据出现长时间的怠速段,这种状况下造成采集数据异常。对于这样长时间的怠速段数据,为了避免误差,采用删除的方法来减少此数据对实验的影响。
(4)堵车及低速过长异常。
汽车长时间保持在10 km/h以下,以及汽车在长时间堵车的状态下,设备继续采集数据,这样的异常通常可按怠速情况处理。
(5)怠速时间超过180秒异常。
通常来说怠速时间超过180秒为异常情况,并且怠速的最长时间段可按照180秒处理。
1.2 数据预处理
针对以上数据误差分析,根据异常数据的种类不同采用不同的处理方式,处理完成后使用T4253H滤波算法[15]进行数据处理。T4253H滤波器不仅在处理非线性数据时,能够更好地发挥其性能,而且在解决非高斯干扰产生的问题中,能够更好地抵制干扰。他是一种非线性的滤波器,其特点是吉布斯反弹与低通转移,具体公式如下所示:
依据公式(1)~公式(4)将数据序列分别进行2、4、5、3的中心移动处理,其中median(X)表示中位数函数,其中X在公式中不仅是原始数据序列,也是一个向量。当median(X)选取X值为中间值,此时向量的维数是奇数;当median(X)选取X中间两个数的均值,此时向量的维数是偶数,Z表示在数据处理的过程中,获得的中间变量序列。
(1)
式中,j=2,3,…,n-2
(2)
式中,j=2,3,…,n-1
(3)
式中,j=3,4,…,n-2
(4)
式中,j=2,3,…,n-1
再以Hanning为权重,经过移动平均处理计算,其中计算公式如下:
(5)
式中,j=2,3,…,n-1
(6)
式中,j=1,2,…,n。
(7)
式中,j=1,2,…,n。
通过T4253H滤波算法处理后,对原始数据中变化幅度较大的数据、加减速异常等行驶数据进行了处理和删除,最后将原始数据中加速度的范围设定在-4 m/s2和4 m/s2之间,正常行驶中多数汽车达到这种加速度的几率很小,这里视为无效值。因此,需要结合道路状况与汽车的行驶状况,把超出这种加速度的数据进行删除,减少汽车行驶工况的构建对其产生影响。
2 行驶工况数据分析
2.1 特征参数提取
对于汽车行驶工况的构建,需要根据汽车实际行驶状况选择合适的运动学片段,通过选取合理的特征参数对运动学片段进行评价和归纳。通过研究分析运动学片段,该文对特征参数的选取包括两个方面,一方面是对运动学片段进行分类,另一方面是判断运动学片段的有效性。准确地选取特征参数,不仅能够保障构建过程中的准确性,而且能够降低数据运算带来的误差,提高分析数据的能力。
不同的特征参数对汽车行驶状况的描述不同,并且由于实际情况,导致在汽车行驶状况的构建过程中,特征参数的选择数量也不同。因此,该文通过研究国内外现状,总结特征参数选取情况,针对实际情况选择特征参数,总共选取11个特征参数,具体包含:运行时间T、平均速度Vm、最大速度Vmax、最大加速度amax、最小减速度amin、加速段平均加速度aam、减速段平均减速度adm、怠速比例Pi、加速比例Pa、减速比例Pd、匀速比例Pc。通过这11个特征参数来描述运动学片段的基本信息。
依据上述选取的特征参数进行计算,将特征参数公式依次在Matlab软件中编写运算,计算运动学片段的特征参数,具体计算结果如表1所示。
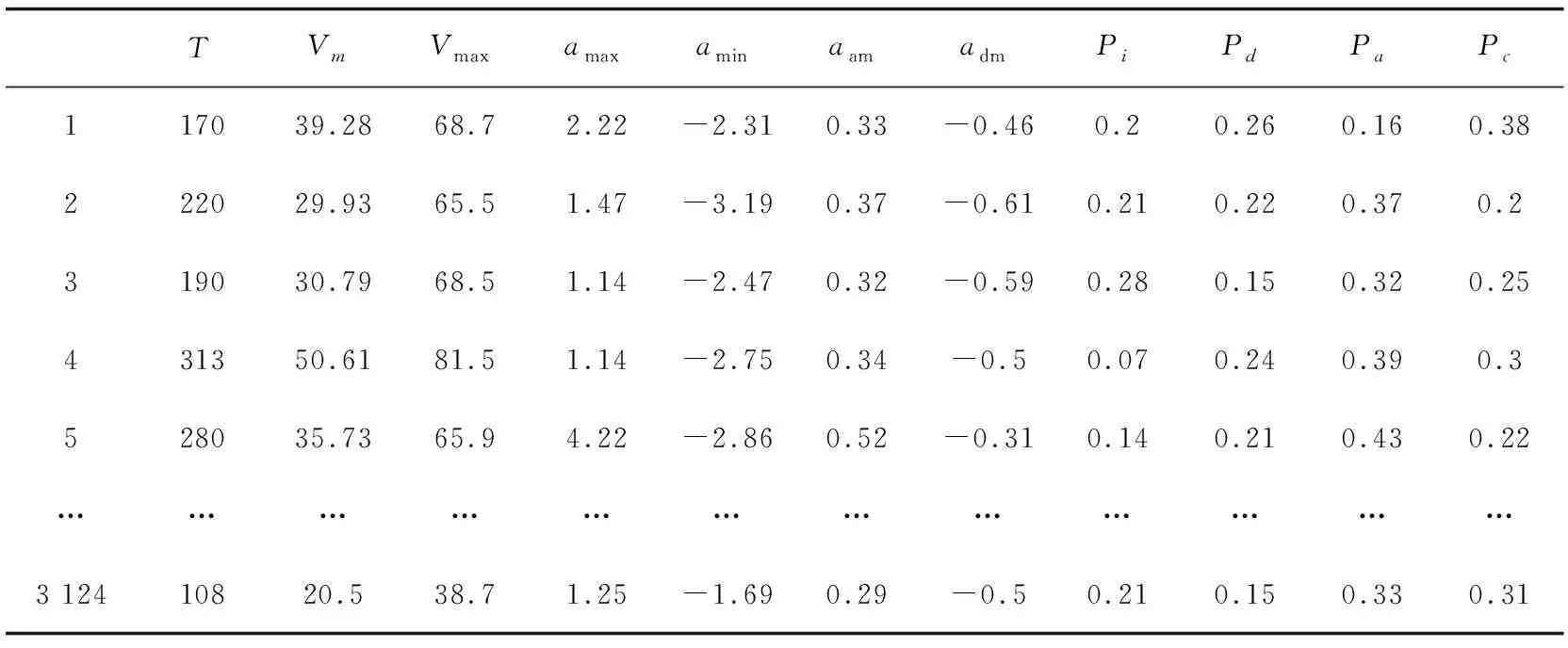
表1 运动学片段特征参数
较多的特征参数会影响分析问题的复杂程度,为了更多地反映原始数据的信息,对选取的特征参数进行进一步的分析。
2.2 主成分分析
通过文献学习,在原始数据降维这一方面选择主成分分析法,该方法在降低问题的复杂程度的同时提高准确性,通过分析删除重复的变量,重新建立新的变量,保证这些变量之间的关系不相关[16]。在数学领域中,主成分分析法的原理是对数据进行降维处理,通过降维减少原始变量的数量,用新的变量对信息进行描述[17]。汽车行驶状况涉及的数据具有相互的联系,通过选取过多的特征参数进行计算过于繁琐,并且各个变量携带的信息是冗余的。
因此,原始数据首先利用主成分分析法进行降维处理[18],然后再利用pcacov函数分析数据的主成分,最终得出11个主成分,通过主成分与特征值、贡献率和累计贡献率之间的关系进行比较,选择最佳的主成分,具体内容如表2所示。
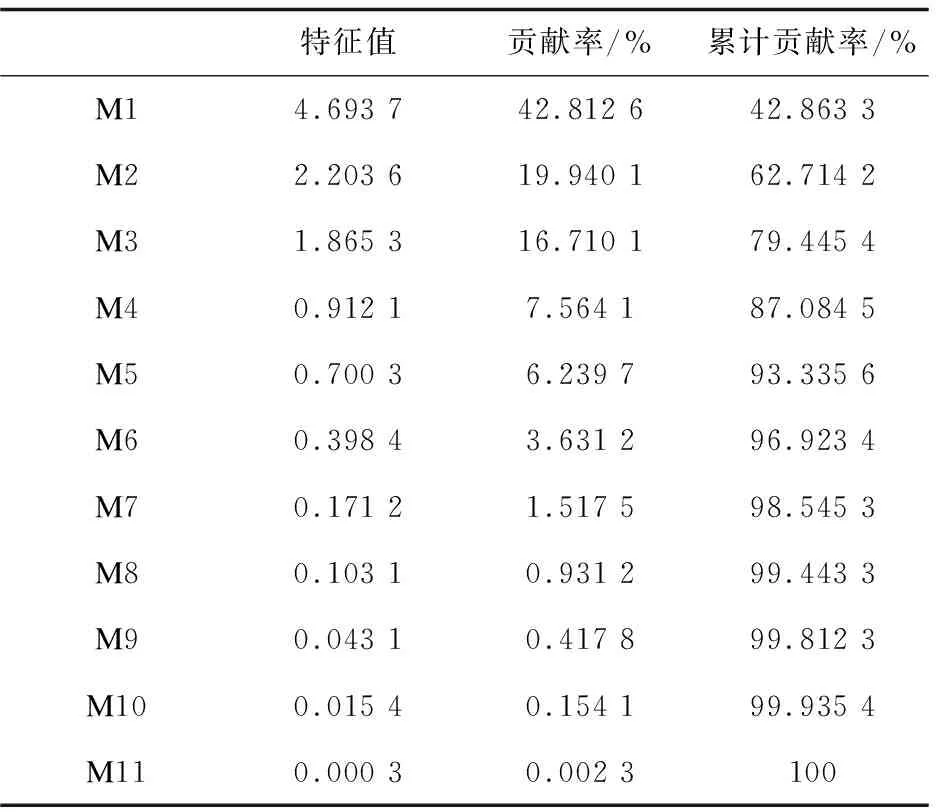
表2 主成分贡献率和积累贡献
依据文献[19],为了降低丢失信息对汽车行驶工况构建的影响,以累计贡献率在85%以上,并且贡献率在1以上为选择标准,依据此标准选择主成分结果,能够更好地反映原始数据的信息。从表2得出,表中满足选择标准的主成分结果共有四个主成分。因此,可以获得四个主成分与原始特征参数的主成分载荷矩阵。最终,通过将特征参数矩阵和主成分载荷矩阵相乘,得出关于短行程的主成分得分矩阵,通过对短行程片段进行分析,获得汽车行驶状况的描述信息。因传统K均值聚类算法在聚类过程中收敛速度较慢,并且过于复杂,该文采用改进K均值聚类算法,并且对短行程主成分得分矩阵进行聚类分析。
2.3 改进K均值聚类
改进的K均值聚类算法是在传统K均值聚类算法迭代的基础上,应用层次结构的思想,通过数据分层次聚类分析。在迭代过程中通过判断当前聚类结果是否合适,再决定是否继续进行聚类分析。依据该方法能够自适应地获得最佳的聚类数,减少因经验选择k值产生的影响,改进算法流程如下所示:
步骤1:选定初始聚类个数k,数据集χ,其中χi={χ1,χ2,…,χn}(i=1,2,…,n),随机选择k个初始化聚类中心进行一次迭代。
步骤2:采用平方欧氏距离,通过计算原始数据与各个类之间的距离,在聚类后,根据该距离计算聚类测度值J。
步骤3:在每次迭代之后,聚类中心在全部簇中找出最大半径的簇,并且在此簇中选取距离较远的点当作新的聚类中心。
步骤4:将步骤3获得的新的聚类中心,与其他的聚类中心重新进行迭代计算,并且计算聚类测度值之比,具体公式如下所示:
(8)
其中,t为迭代次数。
步骤 5:判断ε是否大于Δ值,如果大于,则返回步骤3继续执行;否则输出聚类结果。
对3 124个短行程分别采用传统K均值聚类算法、全局K均值聚类算法和改进K均值聚类算法进行实验分析,算法的性能分析如图1和图2所示。
从图1和图2可以得出,改进K均值聚类算法在运行时间和迭代次数方面都优于传统K均值聚类算法和全局均值聚类算法,通过改进K均值聚类算法,降低计算复杂度,减少运算时间,提高聚类性能。因此采用改进K均值聚类算法进行聚类分析,但需要选取聚类数有效指标,判定聚类前的K值最优。对聚类数的有效性进行验证,该文从指标DI、CH、Wint等进行选择,通过分析评价结果的稳定性,选择CH为评价指标。CH值越大,类本身就越紧密,与其他类关系就越分散。选择最大的CH值,其对应类数为最优,通过Matlab编程进行指标计算,具体分析结果如图3所示。
从图3得出,当聚类数为3时,CH评价指标最大,此时聚类数也是最佳聚类数。并且当聚类数为3时,改进K均值聚类算法的迭代次数和运行时间最少,所以将短行程分为3类最为合理。3类短行程反映了不同的道路交通状况,因此经过聚类,3 124个短行程被分为3类。
通过聚类分析后短行程速度界限较为明显,其中三类短行程被分为以下三种,第一种为低速行驶工况,其速度范围在[0,35]内;第二种为中速行驶工况,其速度范围在[35,70]内;第三种为高速行驶工况,其速度范围在[70,120]内。通过计算部分特征参数,分析其与短行程的关系,具体内容如表3所示。
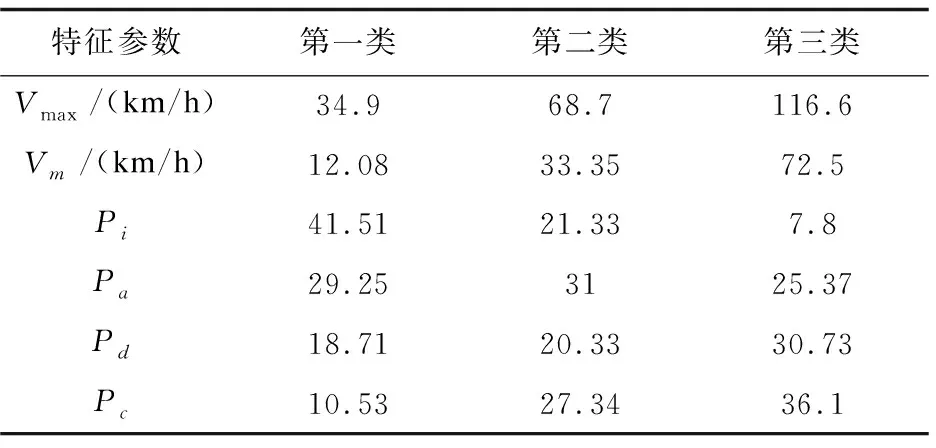
表3 三类短行程部分特征参数
通过计算特征参数与三类短行程的结果进行分析,总结出以下内容:
(1)第一类短行程中怠速状态占全部数据的比例较高,平均速度最低,而且匀速状态比例最少。因此,第一类短行程反映出汽车在行驶过程中道路状况较为拥堵的情形。
(2)第二类短行程中怠速状态比较低,平均速度处于33.45 km/h,而且加速与减速状态的比例相差较小。因此,第二类短行程反映出汽车在行驶过程中道路状况比较畅通,反映了道路的综合交通情况。
(3)第三类短行程中怠速状态最低,加速、减速和匀速状态的比例都比较高,反映出汽车在道路行驶过程中为高速行驶。
3 汽车行驶工况构建
3.1 三类工况持续时间
通过改进的K均值聚类算法计算,对结果进行分析,把三类运动学片段库分成低速区、中速区和高速区,在此基础上,从每一类运动学片段库中选择运动学片段,构建车辆行驶工况。
通过计算各个运动学片段与聚心之间的欧氏距离,根据其值大小进行分类。并且在整体运动学片段库中计算每一类运动学片段库所占的比例值。最后依据汽车行驶工况的时间,按照公式(9)进行计算,获得每类运动学片段的工况时间。
(9)
式中,ti为第i类工况在构建的车辆行驶工况中的持续时间,Ti为第i类工况中运动学片段总的持续时间,TS为全部运动学片段持续时间,tc为构建汽车的行驶工况持续时间。
在最终构建工况时,通过计算得到最终的三类运动学片段的时间占比和各自所占的时长。其中第一类时长为405 s,时间占比为34.8%;第二类时长为590 s,时间占比为50.4%;第三类时长为205 s,时间占比为14.8%。
3.2 汽车行驶工况合成
根据三类工况的计算结果,首先选择聚类中心,选择方法是通过挑选每类运动学片段库中最具有代表性的运动学片段。其次,以运动学片段和聚类中心距离最短为原则,挑选运动学片段。最后,将挑选出来的运动学片段以低速工况、中速工况和高速工况进行合成,汽车行驶工况合成之后,能够有效地描述道路的拥堵状况。
总的汽车持续时间为1 200 s,因此将合成的低速工况、高速工况和中速工况进行连接,也就是汽车在道路行驶的总工况信息,图4为最后构建的汽车行驶工况。可以看出低速工况反映出道路较为拥堵;中速工况表示道路的综合情况,速度有高有低;高速工况表示道路十分畅通。
3.3 汽车行驶工况仿真检验
针对该文研究的方法进行检验,验证所构建的汽车行驶工况的可行性,判断其构建方法的合理性。将汽车合成工况数据与原始数据的特征参数统计结果进行对比[20],通过相对误差验证其有效性,结果如表4所示。

表4 结果对比
通过对比结果可以得出,该文提出的改进K均值聚类算法提高了算法的准确性,减少了因聚类中心选择错误带来的误差。特征参数中平均速度的相对误差基本都控制在0.36%以内,平均误差为4.071%。最大误差为7.4%。所以,从统计结果看,利用该方法进行汽车行驶工况的构建能够满足需求,准确地反映样本总体的特征。
4 结束语
使用某市轻型汽车实际行驶数据,采用T4253H滤波器对原始数据进行处理,并结合主成分分析法和改进K均值聚类算法进行汽车行驶工况的构建。研究结果显示,经过改进K均值聚类算法,使得数据在聚类过程中的运行时间和迭代次数得到提高,同时,聚类分析的实效性也比较强。
仿真实验结果对比表明,所构建的汽车行驶工况中特征参数的相对误差均小于7.4%,所提方法能够构建与真实工况更加接近的典型行驶工况,表明所构建的工况是可行的。
