一种基于权重预处理的中文文本分类算法
2022-04-02管有庆
何 铠,管有庆,龚 锐
(南京邮电大学 物联网学院,江苏 南京 210003)
0 引 言
信息检索[1]、文本挖掘[2]作为自然语言处理[3]领域的关键技术,给人们的生活带来了许多便利,而文本分类[4-6]正是这些关键技术开展的重要基础。文本分类作为自然语言处理研究的一个热点,其主要原理是将文本数据按照一定的分类规则实现自动化分类。目前常见的文本分类方式主要分为基于机器学习和基于深度学习两种,它们的本质是通过计算机自主学习从而提取文本信息中的规则来进行分类。针对数据量较小、硬件运算能力较低的应用场景,往往使用基于机器学习算法而衍生的文本分类模型。这类模型运行速度快、硬件资源占用量小,并且可以取得不错的分类准确性。机器学习算法是当前文本分类领域研究的一个重点。
目前,几种重要的机器学习算法在文本分类领域都有所应用,如KNN(K-nearest neighbor,K临近算法)、SVM(support vector machine, 支持向量机)和LR[7](logistic regressive,逻辑回归)等。将基于词频的TF-IDF(term frequency-inverse document frequency,词频逆文本频率)算法和NBC[8](naive Bayes classifier,朴素贝叶斯分类器)进行结合,是基于机器学习原理衍生出的一种被广泛应用的文本分类模型[9]。NBC分类器原理简明易懂,并且由于其所需要估算的参数较少,对于缺失的数据不敏感,所以在进行小规模文本分类时,有着不错的表现。但该算法也存着一些问题,传统TF-IDF[10-12]算法仅通过词语在文本中出现的频率来判断词语的重要性,无法根据词语所在的位置信息来进行评估,从而导致文本分类的准确性受到限制[13]。
该文提出一种基于权重预处理的文本分类算法,即PRE-TF-IDF(pre-processing term frequency inverse document frequency,文本预处理的文本词频和逆文本词频)算法。该算法在传统TF-IDF模型的基础上,增加了关键信息权重处理和词密度权重处理两个新的处理环节,增加分类模型对词语位置信息的评估,最终提升了文本分类的准确性。
1 TF-IDF算法
TF-IDF算法是一种统计方法,该算法在文本分类中的作用是评估某一个词语对其所在文本的重要性,结合NBC最终实现对文本的分类。TF-IDF主要包含两个部分,TF(term frequency,词频)和IDF(inverse document frequency,逆文本频率)。具体定义如式(1)所示:
TF-IDF=TF×IDF
(1)
TF-IDF算法从定义上看是将TF和IDF两个数值相乘,其中TF的定义式为:

(2)
式中,N(wi,d)表示词语wi在文本d中出现的次数,S表示文本d中所有词语的总数。用词语wi在文本d中出现的次数除以文本d中所有词语的总数,当词语wi出现的次数越多,TF值越大,词语wi对文本d越重要;当词语wi出现的次数越少,TF值越小,词语wi对文本d越不重要。但仅凭TF值来衡量一个词语区分文本类别的能力会出现一些问题,诸如“的”和“是”,这类词语在每个文本中几乎都具有非常高的出现次数。因此,在评价某个词语对于整个文本集的区分能力时,需要依据IDF值来判断。IDF的定义式为:
(3)
式中,N表示文本集中所有文本的总量,N(wi)表示文本集中出现过词语wi的文本总数。当N(wi)的数值越小,IDF值就会越大,表示某个词语在整个文本集中出现的次数越少,则该词将具有很强的区分类别的能力。
TF-IDF算法的含义是:如果某一个词语在一篇文本中出现的概率很高(即TF的数值高),但在其他文本中出现的概率很低(即IDF的数值高),则可以认为该词语具有很好的区分类别的能力,可以作为特征词语进行分类。
TF-IDF算法单纯地认为文本频率越小的单词越具有区别文本类别的能力,而文本频率越大的单词就越无用,这样的思想运用于文本集中的文本是同一类型的文本时就显得不正确了;并且TF-IDF算法没有根据词语出现的位置赋予不同的权值。这两方面的不足导致TF-IDF算法的精度并不是很高。PRE-TF-IDF算法在传统TF-IDF算法的基础上,增加了关键信息权重处理和词密度权重处理两个新的处理环节,以解决上述两点不足,最终提升文本分类的准确性。
2 基于权重预处理的优化算法(PRE-TF-IDF)
传统TF-IDF算法在进行文本分类时,主要存在两个问题。首先,算法仅凭某一个词语在文本和整个文本集中的出现频率来判定这个词语的重要性,IDF值计算式结构简单,不能有效地反映词语的重要程度,导致算法精度不高。其次,不考虑词语在文本中出现的位置,在词频相同的情况下,关键词语和非关键词语的权重相同,从而导致分类的准确性降低。为解决这两个问题,提出了基于权重预处理的改进TF-IDF算法,在文本预处理阶段增加了关键信息权重处理环节,对文本中不同位置出现的词语赋予不同的权重,以解决传统算法无法反映词语位置信息的问题。在特征词语的选取阶段,增加了词密度权重处理环节并改进了IDF值的计算方法,以便选取出更具有类别区分能力的特征词语。结合上述两方面的改进,最终提出一种基于权重预处理的优化算法,PRE-TF-IDF算法。
2.1 关键信息权重处理
(1)算法原理。
针对传统TF-IDF算法无法根据特征词在文本中的分布情况而赋予不同权重的问题,基于权重预处理的PRE-TF-IDF优化算法在预处理阶段,对于不同位置出现的词语赋予不同的权重,以突出关键位置词语的重要性,提升区分文本类别的能力。PRE-TF-IDF算法模型主要针对的应用场景是论文、期刊等文本的分类。这类文本往往包含着标题、发表单位、摘要、关键词等特殊信息,这些段落文字量较少,但对全文起到了概括和提炼的作用。针对这些段落中的词语,赋予更高的权重,有利于更好地选取出具有类别区分能力的特征词语。
文章标题字数一般在20字左右,字数较少并且能够简明扼要地概述全文的内容,对标题内的词语赋予高于正文词语的权重。
摘要可以使读者在最短的时间内准确地了解文章的内容,摘要对区分文本类别也起到了十分重要的作用,因此对于摘要段落内出现的词语赋予高于正文词语的权重。
关键词段落常常位于摘要后一段,使用几个词语来概括文章涉及的专业领域,字数较少但概括能力极强,因此需要对关键词赋予高于正文词语的权重。针对不包含摘要和关键词的期刊文本,则不作额外赋值,统一按正文中出现词语赋值。
发表单位常常会出现学校的名称、企业名称或期刊名称等。根据文本所属的出版单位信息,可以大致对文本可能涉及的领域进行一定的评估。例如,一篇发表自理工类学校的文章,该文章属于计算机、电子或能源等领域的可能性要比艺术、教育或法律等领域的可能性高。通过中国大学信息查询系统,获取国内所有高校的名称及其所对应的专业类别,类别包含“综合类”、“理工类”、“师范类”、“财经类”和“农林类”。表1中这五种高校类别与表2中八类文本专业领域分别具有不同的权重配比。
(2)权重处理具体过程。
如图1所示,虚线框内的步骤为权重处理的流程。经过预处理后,文本去除了停用词,并以词语的形式保存,词与词之间用空格分隔,段落之间使用换行符分隔。使用预处理后的文本数据作为输入,对文本进行位置权重赋值,赋值规则如下:
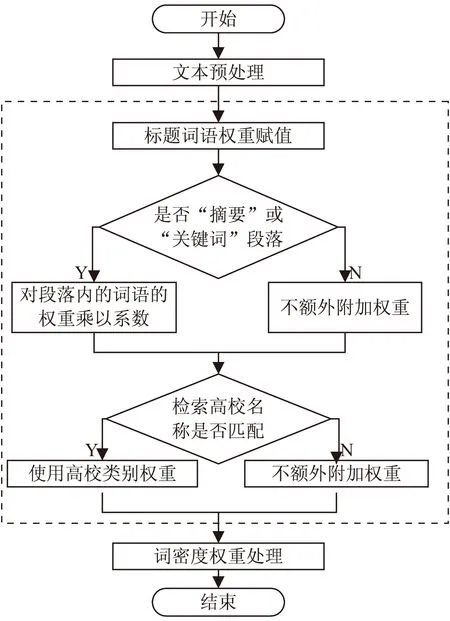
图1 权重处理流程
对于标题段落内的词语,权重值乘以2。通过中国大学信息查询系统,获取国内所有高校的名称及其所对应的专业类别。检索“摘要”和“关键词”段落,对“摘要”段落内的词语,权重值乘以1.5;“关键词”段落内的词语,权重值乘以2。检索文本中前300个词语,与高校名称库进行匹配,若匹配成功,按高校所属类别乘以类别权重,具体类别权重见表1。若匹配失败则不做额外赋值处理。

表1 高校类别对应专业领域权重
通过中国大学信息查询系统,收集“综合类”、“理工类”、“师范类”、“财经类”和“农林类”这五类大学,每类10所院校。通过统计不同专业研究生数量进行加权平均的方式,求得每个专业领域的权重,绘制成表1。
在求得待分类文本中所有特征词语出现在不同类别的联合概率分布后,可以得到该文本分别属于各个类别的概率值,再将各个类别的概率值与表1的专业领域权重进行相乘,最终取概率值较大的类别,即为待分类文本的类别。
关键信息权重处理中标题段、摘要段和关键词处的权重系数为通过多次实验后,经过分类效果对比,最终确定的具体数值。
2.2 词密度权重处理
传统TF-IDF算法单纯地认为文本频率越小的词语越具有区别文本类别的能力,而文本频率越大的词语就越无用,这样的思想并不是完全正确的。造成这一问题的主要原因是IDF值的计算方式较为简单,只考虑了某个词语与其出现的文本数量之间的关系。为解决这一问题,在PRE-TF-IDF算法中增加了词密度权重处理环节,该环节的主要原理是通过类别内词密度和类别外词密度两个指标对特征词语的类别区分能力进行衡量。
通过ICD(intra class density,类别内词密度)来表示特征词语在类别内文本中的出现密度权重;用OCD(outer class density,类别外词密度)来表示特征词语在其他类别文本中出现的密度权重。同时引入WF(word frequency,词语出现频数),即WF(wi)、WF(wi,Cj)和WF(wi,Cjk)这三个参数进行计算。
类别内词密度权重ICD表示为:
(4)
类别外词密度权重OCD表示为:

(5)
式(4)和式(5)中,WF(wi)表示特征词语wi在所有类别文本中出现的频数总数,WF(wi,Cj)表示特征词语wi在第j类中的频数,WF(wi,Cjk)表示特征词语wi在第j类中第k篇文本中出现的频数,n表示第j类中文本的总数,m表示文本的类别总数。
类别内词密度权重ICD的取值范围为[0,1]。当ICD值趋向于0时,表明在类别内特征词语wi的出现密度较为平均,能够很好地体现该类文本的共性;当取值趋向于1时,表明特征词语wi在该类文本中出现密度不平均,存在某些文本频数过高的情况,不具有代表性。
类别外词密度权重OCD的取值范围也为[0,1]。当取值趋向于0时,表明特征词语wi在不同类别的文本中都有较为平均的出现密度,不能很好地代表某一类文本;当取值趋向于1时,表明特征词语在不同类别中的出现密度分布不均,类别区分能力较强。
综上所述,当某个特征词语的ICD值趋向于0,OCD值趋向于1时,代表该词语针对某一类文本具有较强的代表能力。基于传统TF-IDF算法,结合ICD和OCD两种词密度权重,最终形成PRE-TF-IDF权重计算函数:
PRE-TF-IDF=TF×IDF×OCD×(1-ICD)
(6)
式(6)中,TF表示词频,由式(2)定义;IDF表示逆文本频率,由式(3)定义;OCD表示类别外词密度权重,由式(5)定义;ICD表示类别内词密度权重,由式(4)定义。
3 实验结果与分析
采用三个性能评估指标来对基于权重预处理的PRE-TF-IDF分类算法进行实验分析,分别是精确率(Precision)、召回率(Recall)和F1值(F1 Score)。通过对相同数据集使用传统选取方式和该文优化后的选取方式,进行对照实验并评估。实验运行设备是在安装了Windows10专业版操作系统,内存为16 GB,CPU(central processing unit,中央处理器)主频为2.8 GHz的PC机上进行的。主要使用的软件环境是基于Python3.6.7内核和Pycharm 2018.12.5版本,采用的数据集源于复旦大学中文文本分类语料库。在实验过程中,将获取的数据集分为训练集和测试集并且按照1∶1的比例进行实验评估。分类类别为8种,训练集共8 800篇文章,测试集共8 800篇文本。文本以“.txt”的格式进行保存,实验共分为10组,将这8类文本进行等比例缩放,形成10组数据集,具体数据集明细如表2所示。

表2 数据集分类明细
将上述数据按照所占比例的大小,分成10组实验数据集,其中训练集和测试集的比例为1∶1,表3描述了每组数据的大小。
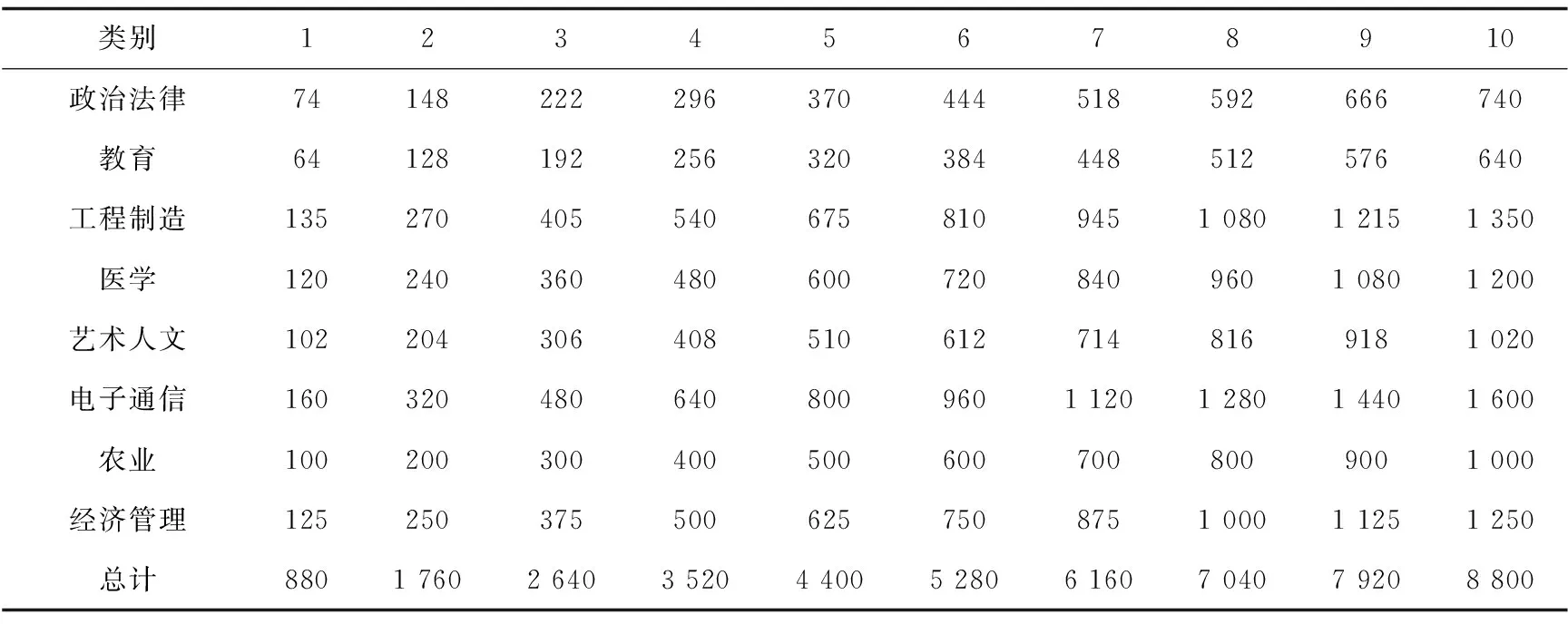
表3 数据集分组大小
在完成分词后,针对文本中出现的语气助词、人称、标点符号这类对文本特征没有贡献的字词,将其收集、合并,形成了一个停用词列表。通过与停用词列表匹配并将停用词从文本中去除掉,以达到提升程序运行效率、减少干扰因素和提高算法准确性的目的。
3.1 特征词语选取
在实验过程中,特征词语选取的数量对PRE-TF-IDF算法的精确率和运行效率都有一定的影响。通过实验计算出兼顾精确率与运行效率的特征词语占比。实验时,将训练集和测试集的数量都定为8 800,在保持这一条件不变的情况下,通过调整特征词语所占的比重,观察运行效率和精确率的变化,最终选取最佳的特征词语占比。

图2 特征向量占文本比重
根据图2可知,在一定范围内,PRE-TF-IDF算法的分类准确性随着特征词语在文本中的比重增加而增加。但当特征词语占文本比重超过一定数值后,反而使得算法分类的效果下降,对分类的精确率产生负面影响。所以,特征词语在文本中的比重存在一个峰值。随着特征词语在文本中的比重不断增加,算法进行文本分类时所需要的时间也随之变长。最终得出精确率峰值时的平均值为特征词语所占文本的比重17.57%。此时,能使得PRE-TF-IDF算法兼顾分类精确率和运行效率。
3.2 精确率
精确率定义为测试集文本经过算法所分类出的类别与其正确类别之间的百分比,也就是正确分类的文本占所有文本的百分比,其对应的公式如下:
(7)
其中,TP表示被正确分类的文本,FP表示被错误分类的文本数量,(TP+FP)即文本的总数量[14]。
这里将上述8类文本按照文本数量的大小进行从小到大的排序,随着训练集数量的增加,观察不同算法对于文本分类精确率的表现。实验中将KNN[15]、LR[7]、TF-IDF[12]算法和所提出的PRE-TF-IDF算法进行对比,结果如图3所示。

图3 四种分类算法在不同数据集下的
由图3可知,PRE-TF-IDF权重预处理优化算法进行分类的准确率比KNN、LR和传统TF-IDF算法都要高。随着训练集文本量的增加,各个分类模型的精确率也在不断增加。当数据集数量达到最大时,KNN算法、LR、TF-IDF和PRE-TF-IDF算法对应的精确率分别为74.8%、80.0%、84.9%和86.9%。LR算法当遭遇特征空间较大时,进行LR分类时的性能不是很好,容易出现欠拟合,精确性不高的情况。传统TF-IDF算法结合朴素贝叶斯分类器在进行分类时,虽然精确性相比于KNN和LR算法有所提升,但是由于传统TF-IDF算法存在无法根据词语位置信息分别赋予权重和仅凭文本词频进行IDF值计算的问题,所以精确性存在一定的限制。PRE-TF-IDF算法由于增加了权重预处理和词密度处理两个环节,相比于传统的算法,精确率提升了2%~5.5%。
3.3 召回率
召回率作为一项评估文本分类系统从数据集中分类成功度的指标,用来体现分类算法的完备性,数值越高代表算法的成功度越高。具体公式如下:
(8)
其中,TP表示被正确分类的文本数量,FN表示应当被分到错误类别中的文本的数量。为了评估PRE-TF-IDF算法的召回率指标,同样进行十组不同数据量的对照实验。分别采用KNN、LR、TF-IDF算法和PRE-TF-IDF算法进行实验。实验结果如图4所示。
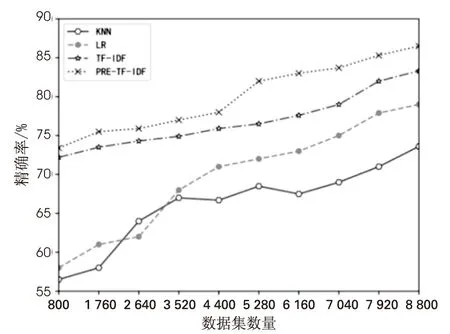
图4 不同分类算法的召回率对比
由图4可以看出,PRE-TF-IDF的召回率比其他三种文本分类算法的召回率都要高。文本分类的召回率和精确率往往随着数据集的增加而有所提升,召回率与数据集的数量总体上成线性增长。当数据集数量达到最大时,KNN算法、LR、TF-IDF和PRE-TF-IDF算法对应的召回率分别为73.6%、79.0%,83.3%和86.5%。
3.4 F1值
F1值是一个综合考虑精确率和召回率的指标,同时兼顾了分类模型中的精确率和召回率,也可以将这个指标看作是算法精确率和召回率的调和平均。计算公式如下:
(9)
其中,P表示精确率(Precision),R表示召回率(Recall),这两个指标反映了分类准确性和成功性两个不同的方面。将精确率和召回率数据进行计算,并绘制成如图5所示的折线图。
F1值通过精确率和召回率计算而得,可以用来评价整个分类器分类效果的优劣。KNN、LR、TF-IDF和PRE-TF-IDF的F1值最终分别为0.742、0.795、0.841和0.867。
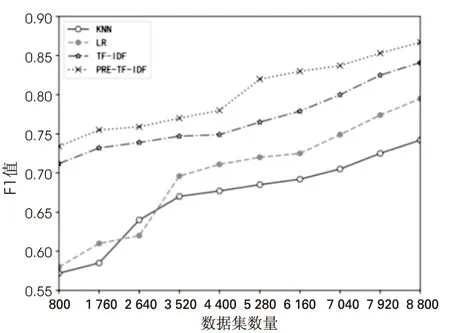
图5 不同分类算法的F1值对比
4 结束语
该文首先介绍了传统TF-IDF算法的实现原理,并指出了传统TF-IDF算法存在的两个问题,即无法根据词语的位置信息进行权重赋值和仅凭文本词频计算IDF值。对此,该文提出了一种基于权重预处理的PRE-TF-IDF算法。通过PRE-TF-IDF算法中的关键信息权重处理和词密度权重处理两个环节来相应地解决传统TF-IDF算法存在的两个问题,并且描述了原理和处理流程。通过实验,将PRE-TF-IDF算法与现有的KNN、LR和传统TF-IDF算法进行对照,在精确率、召回率和F1值这三个方面进行对比,对PRE-TF-IDF算法进行了评估。
