基于消息反馈与强化学习的节能路由算法
2022-03-25王桐龚续常远薛书钰陈奕霏
王桐,龚续,常远,薛书钰,陈奕霏
1.哈尔滨工程大学 信息与通信工程学院, 黑龙江 哈尔滨 150001
2.哈尔滨工程大学 先进船舶通信与信息技术工业和信息化部重点实验室, 黑龙江 哈尔滨 150001
3.国家计算机网络应急技术处理协调中心 黑龙江分中心, 黑龙江 哈尔滨 150028
随着人类对海洋资源越发重视,水下无线传感器网络 (underwater wireless sensor network, UWSN)正在成为水声环境领域方向的热点研究问题,在水环境监测、海洋数据收集、海底勘探、灾害预警等方面具有重要的应用[1−2]。针对无人看守但需要长期采集水下信息的使用场景,传感器网络的能量消耗成为亟待解决的问题。
UWSN由若干传感器节点组成,用以监测水下环境。实验数据表明,电磁波在水中传播的衰减极大,故水下环境中多采用声波进行通信[3]。受水下环境影响,传感器节点可能在水流作用下发生位置偏移,导致整个网络拓扑结构发生变化。此外,水下节点一经部署,就难以对节点能量进行补充。随着传感器网络不断工作,部分节点可能因能量耗尽成为空节点[4]。因为以上原因,关于UWSN的研究重点正逐步偏向具有更长网络生命、更高能量效率 的路由协议。Wahid等[5]在基于深度信息的水下路由算法 (depth-based routing, DBR)[6]的基础上进行改进,提出了EEDBR(energy-efficient depth-based routing)协 议 ,以深度信息为切入点,考虑节点之间的深度差值、节点剩余能量等信息筛选参与转发的节点。该协议虽然在路由效率上效果显著,但仍存在能量的多余开销、网络生命周期短的问题。Hu等[7]基于强化学习的思想,在Q-Learning的基础上设计基于强化学习的能量有效生命周期感知路由协议 (energy-efficient and lifetime-aware routing protocol based on reinforcement learning, QELAR),将路由问题建模为满足马尔可夫性质的强化学习任务,整个网络通过学习环境和评估动作值函数筛选转发节点。该方法可有效均衡网络节点能耗,但单纯考虑节点能量因素导致路由效率降低,且对数据包发送失败的情况没有很好的处理,算法的消息投递率偏低。
本文基于强化学习对水下路由协议进行研究,提出一种新的基于反馈消息的能量有效水下路由协议 (energy-efficient routing based on message feedback and reinforcement learnin, EERFQ)。 该 协议在QELAR的研究上新增了节点转发适宜度作为衡量节点存在空路由风险的指标,在考虑剩余能量信息的基础上增加对深度信息的权重并重新设计奖励函数,在保证整个网络能量均衡的前提下,优化了传输时延并延长了水下网络声明周期。此外,针对消息转发中转发失败的情况,设计基于反馈信息的消息重传机制,改善了投递成功率。
1 模型描述
1.1 网络模型
水下传感器网络仿真应尽可能贴近实际用途,研究表明,三维水下环境中节点的移动特征表现为在水平方向随机移动,但垂直方向位置基本无变化[8]。本文采用的水下三维环境仿真模型如图1所示。整个水下无线传感器网络中存在一个产生有效数据的源节点(source)与有效消息最终送达的目的节点(sink),其余节点均为中继节点,中继节点拥有有限的初始能量,且具备转发和接收消息包的能力。在水下环境中,节点受洋流作用移动,难以获取准确的三维位置信息,但节点深度信息可以轻易得到[9]。网络中每个节点都有唯一的标识(node ID),源节点产生的每个数据包也有唯一标识(packet ID)。每当目的节点接收到由源节点产生的携带有效数据的消息包,视为消息投递成功。
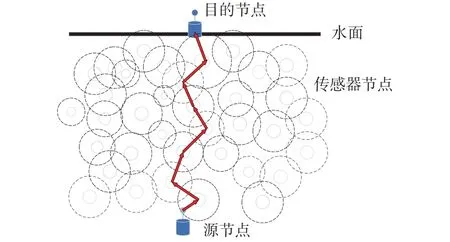
图1 水下传感器网络模型
1.2 能量模型
水下无线传感器网路中节点行为可分为监听、发送、接收等动作,不同动作对应的能量消耗也是不同的。本文中所有节点具备统一的初始能量且在整个网络生命周期内中不会得到补充,节点之间的通信采用Thorp传播模型[10]。节点发送一个传输时延为Tp的数据包消耗的能量为
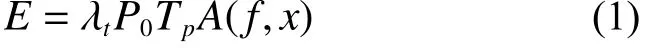
式 中: λt为节 点的发 射功率 系数, 通常 取0.001;P0为节点接收数据包的最低功率;x为数据包需要传输的距离;A(f,x)是与消息发送方式、传输距离及频率有关的物理量衰减模型,可表示为

式中:k是能量扩展系数(圆柱形扩展k为1,球形扩展k为2,实际仿真采用k为1.5),k与频率f有关。吸收系数 α (f)根据Thorp表达式得到:
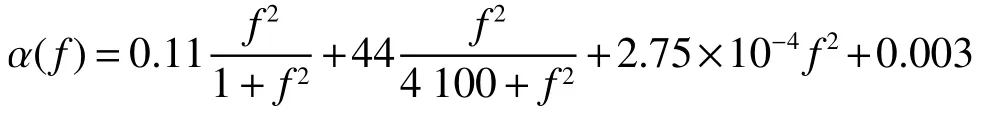
节点融合1个数据包的能耗表示为

式中 λr为接收能耗系数,通常也取0.001。
由式(1)和式(2)可知,节点收发数据包消耗的能量与数据包的传输时间和通信距离呈正相关,即水下通信网络中节点通信距离越远,节点能耗就越大。基于经典水下传感器能量模型,中继节点在路由过程中的主要能量开销在消息的发送、接收以及监听3个动作上,节点在处理数据时的能量损耗通常忽略不计。
2 协议描述
在经典的水下路由协议中多采用基于跳数或能量消耗的最短路径算法来实现算法低延迟、高能量效率的需求。利用强化学习实现的水下路由算法可以通过综合考虑转发节点的邻居节点的剩余能量、深度信息及历史转发成功率等信息计算奖励函数,从而选择合适的下一跳转发节点,在兼顾转发跳数与分组投递率的同时达到整个网络能量均衡,从而延长网络生命周期。
2.1 基于强化学习的水下路由状态空间
强化学习主要关注智能体如何在环境中采取不同的行为,目的是最大限度地提高累计回报[11]。水下传感器网络中,携带数据包的节点向邻居节点转发的过程满足马尔可夫性,因此可以将这样的路由问题建模成满足马尔可夫性质的强化学习任务 (markov decision process, MDP)。
强化学习框架如图2所示,智能体通过与环境交互不断改进策略从而对不同的状态进行动作决策。在RL问题中,处于状态si下的智能体Agent经过动作aj到达状态sj的概率为,而奖励函数表示环境对Agent从状态si采取动作aj到达状态sj的期望回报。在水下路由过程中,节点对下一跳转发节点的选择至关重要。将强化学习过程映射到水下路由模型中,通过不断地交互与试错,转发节点最终可以选出最优的转发路径。
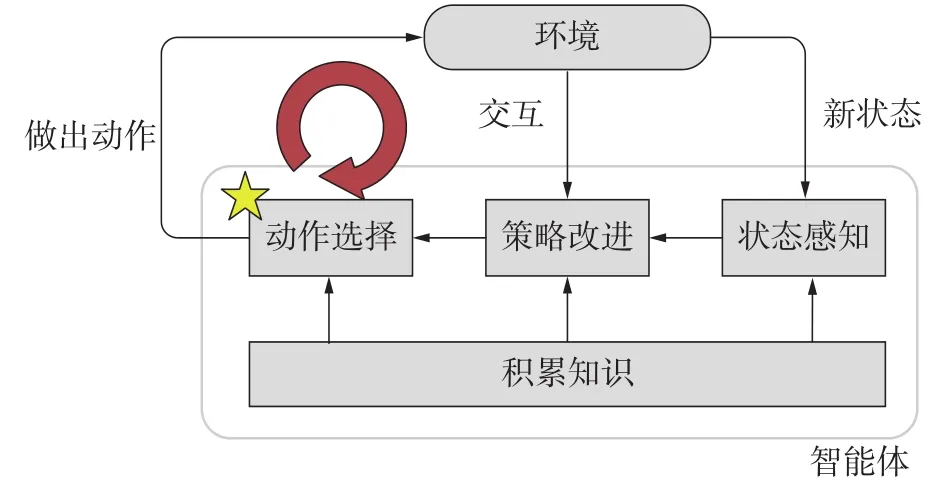
图2 强化学习框架
本文定义整个水下传感器网络为一个系统,系统状态定义与单个数据包有关:假设网络中存在n个 节点,其中n1持有数据包,与数据包相关的系统状态定义为s1。节点n1将数据包转发到节点n2的动作定义为a2。所有与传感器网络中每个节点相关的状态和动作组成状态集S与动作集A。
在t时刻从状态st采取动作时收到的行为终端反馈表示为

强化学习的目的是获取尽可能多的累计奖励的策略,对于水下路由这种需要不断与环境交互的持续性任务,累计奖励也被称为回报,它的定义如下:

式中 γ为折扣因子,它的作用是保证回报不会发散至无无穷大,折扣因子处于[ 0 ,1)的范围内。Q-Learning中定义在 π策略下在状态s采取动作a时得到的预期回报为
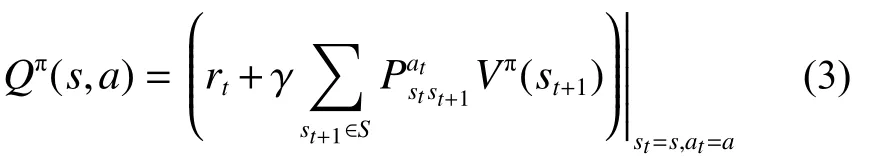
状态s在 π策略下的值Value的最优解表示为

由式(3)和式(4)得到在最低限度采取行动并遵循最优策略所能得到的预期报酬为
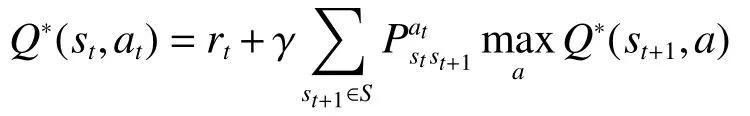
以迭代来近似表示
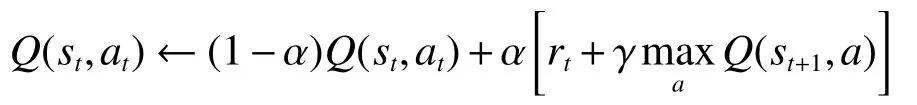
式中 α 为学习率,取值范围在 [0 ,1),若取值为0则表示将不会学习到任何新的东西。我们借助 α来模拟学习过程中更新Q值的速率。
在水下传感器网络中,节点的转发并不总是成功的,定义从状态sn成功转移到状态sm的概率为,则相应的转移失败概率为 1 −。对于状态s1得到如下状态转移矩阵:

2.2 奖励函数及分析
强化学习问题中,智能体与环境的交互均作用于奖励函数,本文算法在设计奖励函数时从节点转发的跳数、能量消耗、数据包传输方向3个方面入手,在保障数据转发次数尽可能少、端到端时延尽可能低的情况下,均衡网络节点能量损耗,延长网络整体生命周期。
考虑节点sn将消息包转发给节点sm的情况。在消息包转发成功的情况下,将对状态动作对(sn,am)的瞬时奖励函数定义为
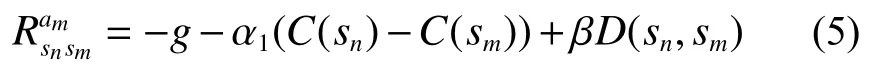
每当节点转发消息时,它将消耗一定的能量,占用信道带宽。在多跳传输的路由网络中,额外的转发次数还将增加消息到达目的地的时延。设置固定的惩罚因数g用以约束节点的行为。即参与转发的节点将持续受到固定的惩罚,在这种情况下,节点为了保证尽可能大,将被迫选择相对短的路径到达目的地从而减小路由延迟。
由于基于贪婪策略的Q-Learning总是选取q值最大的动作,导致节点倾向于在转发次数最少的情况下将消息发送到目的节点。实际上在节点的感知范围内,如果仅考虑单一因素,将导致节点学习过程中能耗过多、V值收敛速度缓慢等问题。式(5)中的系数 β可以决定深度决策因子D(·)在对奖励函数的影响。系数 β越大,节点在转发时会倾向选择地理位置更高的节点。这与水下无线传感器网络的实际需求是相符的。水下无线传感器网络中,节点深度信息是容易获取的。因此定义深度决策因子为
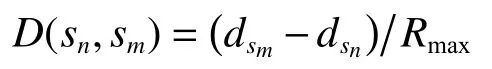
式中:dsn与dsm分 别为节点sn、sm的深度,Rmax为节点的最大传输半径。 此外,出于传感器网络能量均衡的目的,还希望节点在选择下一跳转发节点时优先选择剩余能量较高的节点,通过这样的方式延长网络整体生命周期。 能量决策因子C(·)定义为

通过定义可知,奖励函数中D(·)的范围为[−1,1],C(·)的范围为 [0 ,1]。可以通过调整瞬时奖励函数中的固定奖励与各项系数来平衡3种因素在决策时的重要性。在3项因素中,固定成本比较重要,它可以大大减少节点到达目标节点的跳数。但实际上基于多跳的绕行方案更有利于节省能量。本文设置固定惩罚因数g=1,能量决策系数 α1=0.5,深度决策系数 β =0.1。
若消息转发失败,瞬时奖励定义为
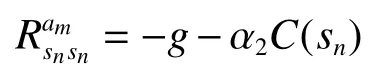
此处将系数 α1、 α2的值统一为0.5。
长期回报公式定义为

根据长期回报公式定义,不论转发行为成功与否,智能体收到的即时奖励总是小于0,意味着节点进行转发行为时总是收到负值奖励。
2.3 节点转发适宜度
在节点进行转发行为时,需要对下一跳转发节点进行决策。考虑一种消息转发失败的情况。当前携带消息的节点为sn,它的邻居节点为集合S,当前节点sn经过决策选择下一跳消息转发节点为sm。 若出于某种原因,此次转发失败,消息未能成功转发到节点sm,在下次进行决策时,需要将这样的失败传输记录纳入决策因素。因此设计节点转发适宜度因素F,节点转发适宜度可以近似反映节点参与下一跳转发的适宜程度。以节点sm为例进行说明,定义节点sm节点转发适宜度为Fm,表达式为

式中:Dm为节点sm邻居节点中处于更高位置的节点比例,Nm用来反映节点sm的邻居节点稠密程度。随着数据包的交换,每个节点维护自己邻居节点的节点转发适宜度。 ηm表示节点sm历史消息转发成功率。
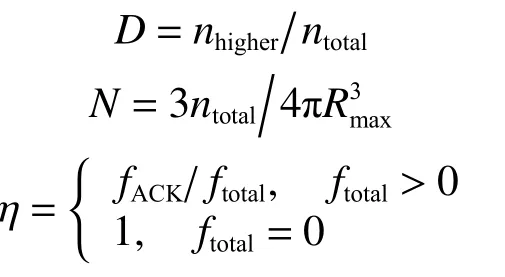
式中:nhigher、ntotal分别为节点的邻居节点中深度信息小于当前节点的节点个数与邻居节点总数,fACK与ftotal分别为该节点所有转发过程中收到的对应 A CK 消息数量与尝试转发的总次数,Rmax为节点最大通信范围。显然,一个节点拥有越多的邻居节点,它的候选下一跳节点数量就越多,我们希望消息的转发过程具备自下而上的方向性,因此邻居节点中处于更高位置的节点数量越多,参与转发的优势越大。此外,如果一个节点在转发过程中总是失败,将会削弱它的优势,所以将节点的历史消息转发成功率也纳入参考。引入节点转发适宜度后长期回报定义为
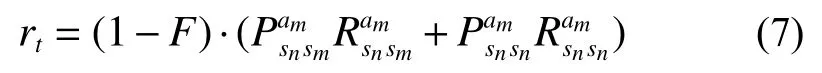
根据式(6)和式(7),节点的转发适宜度F的范围在 [0 ,1),因此下一跳节点转发适宜度越大,此次转发行为受到的惩罚越小。所有sink以外参与转发的节点总是收到负值奖励,因而Vvalue总是负值,而sink节点的Vvalue总是整个无线传感器网络中最大的,设其值为0。
2.4 数据包设计
EERFQ算法的路由过程中信息交互主要由有效消息的转发和控制信息的交换两部分组成。有效信息的转发是水下无线传感器网络的主要任务。源节点产生的有效信息经由传感器网络中节点之间多次转发,最终抵达目的节点的过程。控制信息的交换是指发生在转发过程中的节点间信息交换。控制信息的交换与实际有效信息无关,是各节点通过数据包的报头信息维护自身邻居节点的行为。
在EERFQ中,消息包格式如图3所示。消息包主要由消息包相关信息、上一跳节点信息与实际有效载荷3部分组成。

图3 数据包格式
数据包相关项说明:
1)Packet_Type表示当前消息包的功能。用来区分当前消息包是否承担有效载荷。
2)Packet_Sequence_ID,消息包序列号,对具体数据包起辨识作用。
3)Destination_Address,消息包最终被送达的目的节点。目的节点由产生消息的源节点指定,通常,在整个水下无线传感器网络的生存周期中都不会改变。
在节点对消息进行转发时,会将本身的一部分信息添加在消息包中起到信息交换的作用,其中包括:
1)Sender_Node_ID,转发当前消息包的节点ID,在整个传感器网络中唯一。
2)Vvalue,节点当前Vvalue。
3)Residual_Energy,转发当前消息包的节点剩余能量。
4)Node_Depth,此节点的深度信息。假设水下无线传感器网络中节点容易获取自身的深度信息。
5)Forwarding_Factor,节点的转发适宜度因子。下文将给出具体定义。
6)Next_hop_Node,转发此消息包的下一跳节点。
当节点监听并收到数据包时,将根据数据包中携带的报头信息更新其邻居节点相关信息。基于本文中提出的消息重传机制,Next_hop_Node字段在重传过程中可能存在不止一个节点信息,更多细节在下文中给出。
2.5 基于消息反馈的重传机制
在Lu等[12]提出的EDORQ算法中,给出了一种对陷入空节点的数据包的挽救措施,即以广播数据包的方式使数据包脱离空节点。这种方法可以起到挽救数据包的作用,但广播的方式将大量消耗节点能量占用网络资源。本文在此基础上提出基于消息反馈的数据包重传机制。节点成功接收到包含有效载荷的数据包时,广播一个针对此数据的控制包。因为控制包不包含有效数据,所以体量非常小,传输时间短,并不占用过多的网络资源,却可以通知上一跳节点消息已被成功送达,保证消息的有效传递。
如图4所示,节点n1经过决策尝试将数据包发送给节点n2,但某些原因导致此次发送失败,经过一定等待时间后n1仍未能收到由n2成功接收当前数据包的反馈,此时触发数据包重传机制。图5(a)和图5(b)分别描述了节点转发成功与转发失败2种不同情况时的处理逻辑。第1次尝试重传时,除节点n2以外,节点n1从它的所有候选节点中选择下一跳适宜度仅次于节点n2的节点n3。
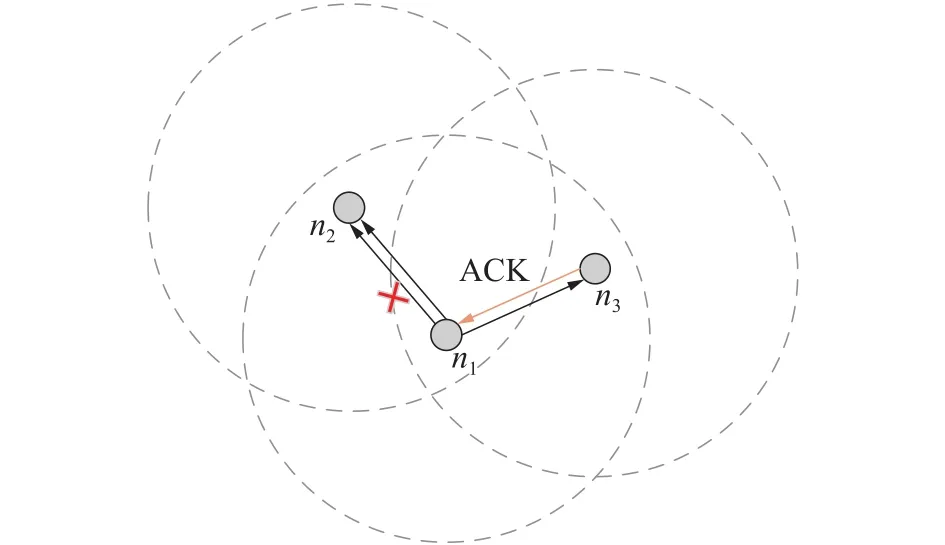
图4 消息转发示意
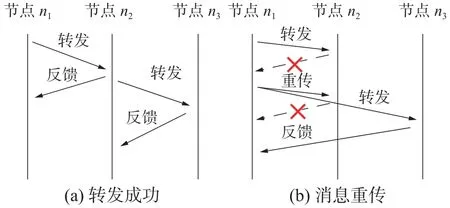
图5 消息重传逻辑
随着重传的尝试次数增多,每次节点都多指定一个节点作为下一跳,直到某次传输成功,收到某个节点接收成功的反馈信息,或者到达最大重传尝试次数Ttrans_max。若重传尝试成功,当前发送节点立即更新下一跳节点转发适宜度F,并根据重传尝试次数不同,削减接收失败节点的转发适宜度。若此次转发以失败告终,则当前携带数据包的节点大概率陷入了路由空洞。成为空节点的原因多种多样,可能是能量不足,可能是由于移动性到达了周围邻居节点的感知盲区,也可能仅仅是通信质量不好造成的误判。改进的消息重传机制一定程度上占用了更多带宽,但可以大大提高消息转发效率,减少消息端到端时延。
2.6 EERFQ 算法流程
算法1是路由算法节点转发过程伪代码。当节点监听到一个数据包p时,首先根据数据包的发送方信息更新发送节点信息。然后判断该数据包是否携带有效消息,如果是控制包,那么仅更新邻居节点信息,然后直接丢弃该数据包。如果数据包携带有效信息,该节点首先针对此数据包广播反馈消息,然后进行虚拟计算,并更新自身维护的邻居节点的Vvalue。当前节点选出最适合转发的下一跳节点后,将更新数据包的报头信息并进行转发,同时等待此数据包的反馈信息。此过程中如果接收到针对此数据包的反馈信息证明下一跳节点已成功接收,节点更新邻居节点的转发适宜度等信息。若传输失败,则启动失败重传,直到消息包成功转发或重传次数超出最大限制。
算法1节点转发
输入:节点监听消息包p
输出:下一跳转发节点m;附带了当前节点信息的消息包p
1)if Packet_Type = 0 // 如果数据包p不携带有效消息
2)根据p中报头消息更新邻居节点信息
3)更新上一跳节点转发适宜度
4)丢弃p
5)else
6)广播针对数据包p的反馈消息
7)更新节点Vvalue
8)T_trans ← 1//初始化重传次数
9)计算邻居节点转发适宜度,选择下一跳转发节点m
10)更新数据包p//将自身节点信息附加到数据包中
11)向节点m转发数据包p
12)if 未收到当前p的反馈消息do
13)消息重传函数()
14)end if
15)if 收到p反馈消息 then
16)更新对节点m转发适宜度
17)end if
18)ifT_trans =T_trans_max do
19)广播数据包p,邻居节点更新信息
20)丢弃数据包p
21)end if
22)end if
数据包重传过程伪代码如算法2所示。若重传次数到达最大限制,则认为转发失败,节点向邻居节点广播当前数据包p并告知邻居节点更新对当前节点的转发适宜度。这种做法可以帮助路由过程中绕过存在空洞风险的节点,从而增加路由效率。节点在数据转发时的算法复杂度为与文献[13]提出的算法复杂度类似,与节点的邻居节点个数和网络规模有关。
算法2消息重传
输入:当前数据包p;下一跳转发节点m;重传次数T_trans
输出:尝试转发次数T_trans
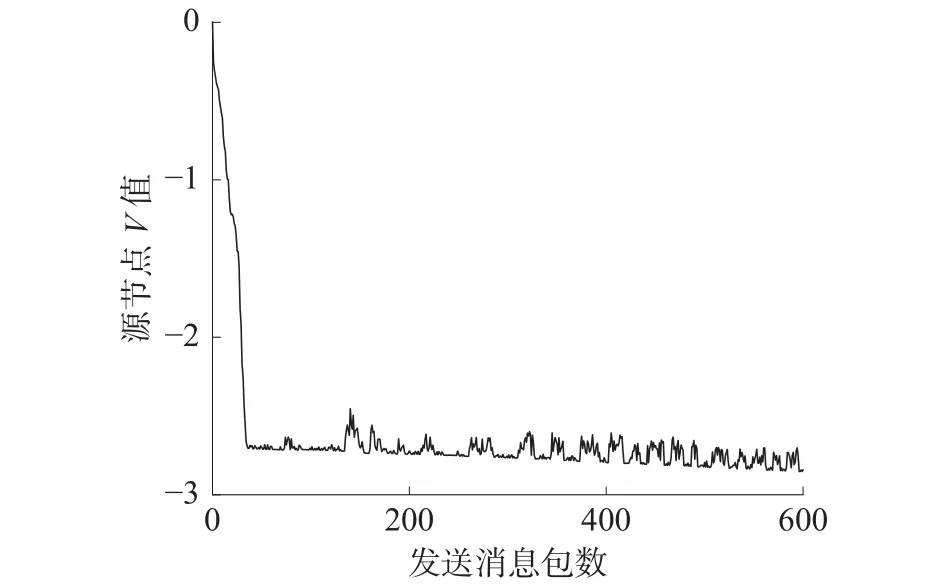
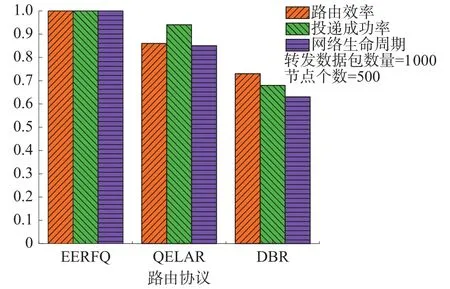
1) whileT_trans 2)等待单位转发时间T_wait 3)更新对节点m1转发适宜度 4)根据邻居节点列表另寻适合转发的节点m2 5)更新数据包p 6)向节点m1,m2转发数据包p//每次重传,都多指定一个下一跳目的节点 7)T_trans += 1 8)end while 本文基于NS-3网络仿真模拟器,在其提供的uan模块基础上实现本文算法仿真分析验证。仿真中设置中继节点移动速度为1 m/s,移动模型为RandomWalk2dMobilityModel;网络中源节点与目的节点各一个,分别固定在网络边界底层与顶层中央位置,源节点以1 个/s速率产生数据包,通过中继节点转发到目的节点,当目的节点接收到数据包视为成功传输。网络规模随固定网络边界中节点数量变化而变化,定义100~300为稀疏规模,300~500为中等规模,500个节点以上为密集型网络。各项参数设置见表1。 表1 仿真参数 由于算法收敛速度可以反映路由算法的性能,本文首先对算法的收敛性进行分析;接下来对协议的性能进行评估,分析不同策略的算法在不同网络规模的投递成功率;分析节点平均能量利用率受网络规模变化的影响;最后对中等网络规模下不同算法从投递成功率、路由效率和网络生命周期3个方面对比分析。节点平均转发次数指路由过程中数据包被转发的平均次数。 定义节点平均能量利用率为 3.2.1 算法收敛性分析 根据EERFQ算法模型,目的节点的V值始终保持整个水下无线网络节点中的最大值0。路由过程中,各节点转发行为都将收到负值奖励,由于源节点距离目的节点最远,因此其V值收敛所需时间最长。如图6中曲线显示,在发送数据包的起始阶段,源节点V值快速下降,在发送约30~40个数据包后趋于稳定,这意味着源节点路由在发送数据包过程中找到从源节点到达目的节点的转发路径。在后续过程中V值始终保持减少的趋势,这是因为转发行为始终收到固定的负值奖励,导致V值存在下降趋势。在转发过程中V值存在小幅度波动变化,这是在转发过程中,需要考虑剩余能量、节点深度等因素为了使能量均匀分布,节点在转发时放弃最短路径,选择转发次数更多的路径,此外还存在消息的传输故障重新转发等情况。以上情况导致的转发绕路行为将导致V值暂时增大,但随着发送数据包的增多,V值存在始终减少的趋势。 图6 源节点 V 值收敛过程 3.2.2 算法性能对比分析 本文将EERFQ算法与DBR、QELAR共3种算法在性能上仿真分析对比。首先是分析不同网络规模下,发送相同数量数据包与相同网络规模下发送不同数量的数据包这2种情况下3种算法的差异。 结果如图7所示。图7 (a)显示了在相同网络规模下3种不同的路由协议分组投递率随网络中节点个数变化受到的影响。发现3种算法在节点数较少的场景下分组投递率并不高,但随着节点数量的增加逐渐上升到稳定水平。这是因为在网络中节点数量较少时,节点转发路径较为单一,遇到数据包转发失败的情况时将难以应对。图7(b)描述了在中等网络节点的情况下,3种路由协议的分组投递率指标随转发数据包的增加变化的趋势:随着转发数据包个数的增加,3种算法的分组投递率一开始可以维持在一定水平,后来逐渐减少。其中DBR算法的衰减迅速,这是由于随着网络中转发次数的增多,一些节点频繁参与转发,没有足够剩余能量参与后续转发行为,导致了投递成功率的降低。 图7 不同条件下分组投递率变化 图8描述了3种算法的节点平均能量利用率变化趋势。由于EERFQ与QELAR算法在节点的能量均衡方面切入,因此节点平均能量利用率保持在较高水平,而DBR算法虽然未做能量均衡处理,但参与转发的节点很多,因此也保持一定的节点平均能量利用率。由图9可知,同等条件下的3种路由算法中,EERFQ与QELAR算法投递成功率相近,较DBR提升约32%;DBR算法仅以深度信息为依据,转发过程中存在较多冗余数据,消耗大量节点能量,因而网络生命周期较短。相比之下,EERFQ与QELAR算法转发过程中引入剩余能量信息作为转发依据,使得路由过程中节点能量保持相对均衡,获得了更长的网络生命周期,EERFQ较QELAR算法网络生命周期延长约 15%,较 DBR延长约 35%;而 EERFQ算法在转发过程中引入了深度信息作为转发参考依据,因此获得了更高的路由效率,较QELAR路由效率提高约15%,较DBR提高约27%。 图8 不同算法节点平均能量利用率 图9 算法综合性能对比 本文针对水下无线传感器网络中存在的节点能量消耗不均衡和网络生命周期较短的问题,将强化学习与水下无线传感器路由问题结合,提出了一种基于强化学习与消息反馈机制的能量均衡路由算法。通过综合考虑邻居节点的深度、剩余能量及历史转发成功率等信息,重新设计了直接奖励函数;通过节点转发适宜度因子,节点可以筛选出疑似空洞节点,保障了消息的投递率;对于数据包转发失败的情况,改进了节点重传机制,在占用更少网络带宽的情况下对陷入空节点的数据包进行挽救。仿真表明EERFQ算法可以有效适应中等网络规模下的传感器网络,并在保持较高分组投递率和路由效率的前提下,有效均衡网络整体能耗,延长网络整体生命周期,更适用于水下无线传感器网络需要长期工作的使用场景。下一步考虑对算法奖励函数更进一步扩展,考虑应用于规模更为稀疏的水下传感器网络,从节点行为出发,设计节能性能更好的方案以应用于动态性更强的水下环境。3 算法仿真与结果分析
3.1 仿真环境

3.2 结果分析
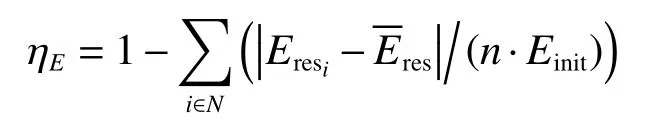


4 结论
