基于卷积神经网络的深度图修复
2022-03-25卫鑫王立国陈春雨
卫鑫,王立国,陈春雨
哈尔滨工程大学 信息与通信工程学院, 黑龙江 哈尔滨 150001
畜牧业作为中国的传统行业,近年来在互联网的推动下,借助大数据的潮流实现了较大的发展[1]。尤其是在非洲猪瘟的影响下,伴随着人工智能的发展,我国的养猪业正处在由劳动密集的传统养殖方式向现代化转型的路上,成为了人工智能应用的新兴领域,因此养殖无人化是大势所趋[2]。目前人工智能在养猪领域的研究主要集中在视觉识别和声音识别领域,其中视觉识别表现在对猪只身份的识别,猪只数量的统计以及猪只行为的检测等任务;声音识别领域则包括对猪只声音的检测来判断猪只的情绪、饥饿、发情等状态。无论是视觉识别还是声音识别,都离不开传感器的使用。在对猪只测重和活体测膘中,猪只在活动的过程中体重秤的测量数值会上下波动导致测量偏差以及饲养员携带猪瘟等其他病毒,需要通过结合深度摄像头,非接触式、非应激式地间接测量。然而在实际应用过程中,常常由于场地环境、设备问题以及技术成本等其他原因,用来采集信息的设备会受到影响,深度摄像头采集到的深度图会出现大小不一的空洞,以及猪只在活动过程中被栏杆遮挡的情况。残缺的深度图会导致后续的视觉任务精度下降甚至失败。
关于深度图修复的算法研究发展大致分为2个阶段,一是基于滤波的传统算法,二是基于数据驱动的深度学习算法。传统滤波算法主要有均值滤波、中值滤波、双边滤波和联合双边滤波,之后的算法大部分是基于此进行改进。双边滤波在高斯滤波的基础上同时考虑了空间上的距离以及像素值之间的距离,使修复后的图像保留了结构和纹理信息。联合双边滤波在双边滤波的基础上引入了与深度图对应的彩色图像,将彩色图像的像素值转换到灰度图进行计算,在空洞处的结构恢复效果上优于双边滤波,然而当彩色图像高频信息较多时修复会产生较为严重的伪影。将深度图与RGB图像结合的修复方式除了联合双边滤波,还有使用平滑度优先[3]、快速行进方法[4]、基于纳维叶−斯托克斯方程[5]、各向异性扩散[6]、背景表面外插法[7]、低秩矩阵补全[8]以及基于图像块合成[9]等方法。随着计算机算力的提升,基于数据驱动的深度学习算法被越来越多的人提出。Zhang等[10]预先训练了一个能通过RGB图像预测出表面法线和遮挡边界的网络,然后将该网络的预测结果与原始深度图结合,经过全局优化后得到完整的深度图。Huang等[11]同样借助由RGB图像预测出表面法向量,并引入门限卷积克服了网络简单学习深度插值的困难,使修复后的深度图结构更加清晰。Senushkin等[12]将图像分为有效测量区域和无效测量区域,提出了一种改进的编解码器结构,使网络能够学习仿射变换的能力,并引入了新的损失函数。
以上提及的方法在完成深度图修复任务时,大都会额外借助深度图对应的RGB彩色图像来获得额外的信息辅助修复任务,而基于滤波的传统算法在当深度图缺失面积较大的时候难以获得较好的效果,会出现边缘模糊等问题。在实际任务中,由于设备存储空间以及工程成本等原因,通过猪舍实时采集到的数据只有深度图,加上由限位栏导致的深度图缺失及深度信息异常的面积相对较大,传统滤波方法已不能适用,故本文将彩色图像的修复方法引入到深度图修复的任务中,提出改进后的循环特征推理网络(recurrent feature reasoning network, RFR-Net)。
1 方法介绍
本算法主要是针对圈养猪只被栏杆遮挡导致深度摄像头不能完整获得深度信息的情况。本文将预处理后的深度图作为神经网络的数据集,由猪场采集到的原始数据经过栏杆分割、图像去噪等预处理后得到。受Edge Connet方法[13]的启发,整个算法由分为2个步骤:第1步是利用U-Net网络得到深度信息缺失或者不正常位置;第2步是将识别出的缺损位置和缺损深度图一起送到RFR-G网络进行深度信息预测或者校正,最后得到完整的深度图。本文采取的算法框图如图1所示。

图1 本文的算法框图
1.1 修复位置识别网络
找到缺损处和深度信息不正常的位置实质上等价于图像分割任务,考虑到待修复的深度图相较于其他深度图结构形状单一,语义信息较少,故引入U-Net[14]网络来完成识别修复位置的任务。U-Net网络最早应用于医疗图像分割,它简单高效,整体是一个编码器—解码器结构。图像经过编码器的4次下采样,得到4个不同尺寸的特征,然后与解码器卷积上采样得到的4个不同尺寸特征进行拼接,最后得到与输入图像大小相同的预测结果。
1.2 深度图补全网络
深度补全网络采用了改进后的RFR-Net网络,其网络结构如图2所示。
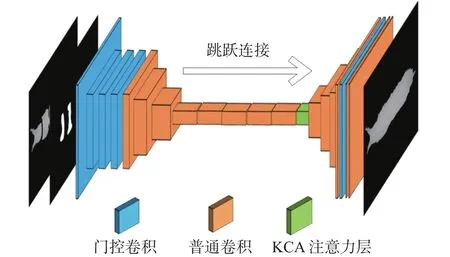
图2 改进后的 RFR−Net网络
模型采用了编码器−解码器的结构。在编码器部分,为了改进网络识别缺损区域的能力,本文将原模型中的部分卷积替换为了门限卷积,见图2中蓝色模块。网络识别缺损区域后通过普通卷积提取特征得到特征图,然后根据随网络更新的二进制掩膜来计算无效特征像素点 (x,y)和有效特征像素点的特征相似度,计算公式见式(1):
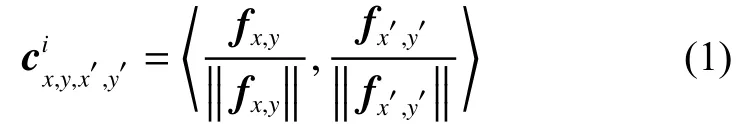
式中 〈, 〉表示余弦相似度。我们记c和f分别为特征相 似 度 和 特 征 图 ,fx,y,fx′,y′分 别 表 示 特 征 图 上(x,y)和处的特征向量。
接着计算 (x,y)周围与的特征相似度,并与该点处平均后经过softmax函数得到最后的注意力分数。最后,网络根据注意力分数重建特征图,见式(2):

式中W、H为特征图的宽和高。
在解码器部分,每层输入都由上一层的输出和重建的特征图在通道上叠加组成。通过多层卷积,最后恢复出完整的深度图。
在图像特征提取的过程中,普通卷积通过滑动卷积核给图像每个像素施加不同的权重,即表明图像的每个像素都是有效的。然而对于修复任务来说,图像中被遮挡区域的像素在卷积核提取特征的过程中应该被视为无效像素,未遮挡区域的像素应该被视为有效像素。PConv[15]表明,对缺损图像直接采用普通卷积的方式,随着网络层加深,这些无效像素会变成有效像素,进而导致测试结果产生颜色缺损和边缘模糊等现象。针对此类情况,RFR-Net[16]引用了部分卷积,掩膜更新规则见图3(a)。部分卷积利用二进制掩膜将输入的像素划分为有效像素和无效像素,当输入区域至少包含1个有效值时,该区域的掩膜更新为1,否则更新为0,更新规则由式(3)表示。

图3 部分卷积和门限卷积掩膜更新策略
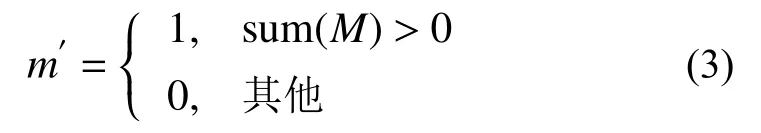
式中:M为二进制掩膜,m′为下一层掩膜在该区域的值。掩膜随着卷积层数的增加不断更新,最后到达一定层数后M就会变成全1矩阵。
然而部分卷积也存在缺陷,不管上一层二进制掩膜有多少个有效像素,下一层都将置1。同时,网络的每层特征图都使用了一样的掩膜,抑制了网络学习的能力。因此,本文引入了门限卷积。门限卷积相比部分卷积,它抛弃了部分卷积更新掩膜的固定规则,对掩膜同样使用了卷积操作。它将上一层的特征图和二进制掩膜分别与2个不同的卷积核Wf和Wg进 行卷积操作,得到在(y,x)处的值F和G,见式(4)和式(5):

接着分别经过激活函数 ϕ以及Sigmoid函数,最后通过点乘得到下一层的输入,见式(6):
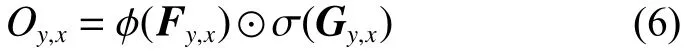
整个更新过程如图3(b)所示。卷积操作能让掩膜更新从数据中学习,使得网络可以对每个通道每个空间位置学习动态特征选择机制。
2 实验
2.1 实验数据准备
2.1.1 实验数据
原始数据通过深度摄像头 Intel RealSense D435在2个猪场采集得到。待修复的深度图来自其中1个有限位栏的猪场,限位栏的作用是防止猪翻过栏杆。而另外1个猪场没有限位栏,能采集到无遮挡的深度图,本文将无遮挡的深度图作为训练集和测试集。采集到的深度图图片数量一共有上百万张,本文从2个猪场采集到的图片随机抽取了50 000张无遮挡图片作为训练集,10 000张图片作为测试集,训练集与测试集比例为5:1。
2.1.2 数据预处理
数据预处理分为2个部分。
第1部分是对原始深度图处理。原始数据包含了栏杆、地面和猪这3类语义信息,渲染后的深度图如图4所示。为了排除地面和栏杆对训练的影响以及方便后续测重测膘等任务,我们通过深度图分割出猪只的掩膜,见图5,进而得到只包含猪只信息的深度图。然后经过平移旋转等变换,让猪只处于图片中心位置,非猪只部分的深度信息全部置0。由于两猪场深度摄像头离猪只距离的尺度范围不一样,为了防止网络在训练过程中过拟合,本文将变换后的深度图在5 000像素范围内整体上下随机偏移,偏移前后地面非猪只部分的信息始终置0。原始数据经过分割、变换,像素偏移最后得到500 像素×500 像素大小的16位深度图,如图6(a)中所示。

图4 渲染后的原始深度图

图5 分割出的猪只掩膜

图6 预处理效果图
第2个部分是缺损部分的掩膜生成。本文使用Opencv随机生成面积、位置不同的掩膜来模拟被遮挡的位置形状,如图6(b)所示。图中遮挡位置像素为255,否则为0。生成掩膜后,将其与完整深度图叠加,得到模拟的缺损深度图,如图6(c)所示。
2.1.3 标签制作
用于训练U-Net网络的数据集由经预处理后带栏杆的深度图制作。在Labelme上标注出缺损的位置以及深度信息不正常的位置。标注完成后利用生成的Json文件生成对应的掩膜。本文共标注了400张,其中320张为训练集, 80张作为测试集。
2.2 实验环境和设置
进行实验的电脑参数如下:系统为Ubuntu 18.04,显卡为 GTX2060super,显存 6 GB,CPU为i7-8700K, 内 存 16 GB。 模 型 的 实 现 基 于Pytorch框架。修复模型输入的图片分辨率大小为 500 像素×500 像素的单通道 16 bit深度图,在模型前处理阶段,对输入图片进行归一化操作,使向量在0~1。训练阶段,在梯度优化器采用Adam,学习率设置为0.000 4,当损失函数趋于收敛时,对模型进行细调,冻结所有BatchNorm层,学 习 率 变 为 0.000 05。 损 失 函 数 由Lvalid、Lhole、Lperceptual3部分组成,对应系数分别为 1、6、0.05,损失函数具体公式分别为式(7)~(9):
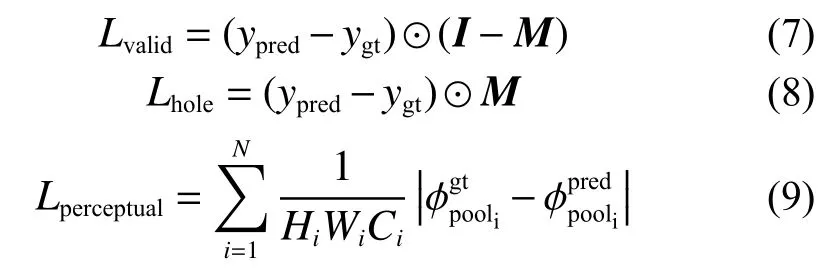
式中:ypred、ygt分别为网络修复后的深度图和真实的深度图;M为U-Net预测出的掩膜,用来表示的矩阵在需要修复的位置上值为1,否则为0。式(7)中的I表示值全部为1且和M矩阵同大小的矩阵。在训练时,使用了VGG16网络分别对真实的深度图和修复后的深度图提取特征图,得到和,Hi、Wi和Ci分别为N个特征图中第i个的高、宽和通道数。
2.3 实验结果对比
2.3.1 消融实验
为证明改进后的RFR-Net[16]在修复深度图的任务上相比改进前修复效果有所提升,本文进行了消融实验。将原模型记做RFR-P,改进后的模型记做RFR-G。两模型分别在同一训练集上迭代 300×103步,其平均绝对误差(mean absolute error,MAE)曲线如图7所示。

图7 两模型 MAE 损失曲线对比
训练过程中,黑色曲线表示的RFR-G在迭代相同步数时其MAE值低于RFR-P。训练完成后,两模型分别在包含10 000张深度图的测试集上进测试。本文对每张修复后的图像进行质量评估,然后对所有图像的评价指标取均值,对比结果见表1。结果的量化指标选择了衡量图片质量常用的峰值信噪比(peak signal to noise ratio,PSNR),结构相似性(structural similarity,SSIM),另外本文还选择了MAE来衡量在缺损位置处网络预测的深度值与真实深度值误差的百分比。从表中可以看出,在引入门限卷积后,模型保持结构特点的同时,在峰值信噪比和平均深度误差上都有了一定的提升,效果优于改进前的模型。
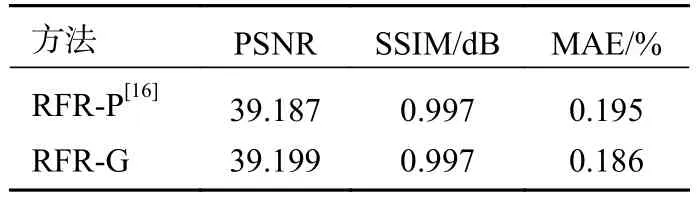
表1 改进前后量化对比
图8给出了模型改进前后在一部分测试集上的修复效果。为使视觉效果明显,图中的深度图都经过渲染,颜色越深的地方表示离摄像头的距离越近,其中蓝色表示地面。由于深度摄像头测量对象是摄像头到猪的背部距离,深度图在修复后理想情况下相邻深度值应该是连续的,渲染后颜色为渐变。

图8 消融实验结果对比
2.3.2 不同方法对比
另外,本文还将该算法与基于块的PatchMatch[9]和PConv[15]进行了比较。图9给出了3种方法的对比效果。从图9(b)中可以看出,PatchMatch在修复时改变了原深度图中猪只的形状。表2给出了量化结果分析,可以明显看出本文使用的方法相较于其他2种方法,在3项指标上都有了很大的提升。

图9 不同方法对比

表2 不同方法的量化对比
2.3.3 实际效果图
图10给出了3种不同方法在真实缺损的深度图上的修复效果。因为缺损部分的真实值未知,因此只能从主观上来评价。图10(b)、图10(c)2种方法与本文提出的方法相比,用图10(b)方法修复后形状发生了变化,而用图10(c)方法保持了形状但在原缺损处有明显像素不连续的现象。只有用图10(d)方式同时保持了形状和像素连续的特点。

图10 不同方法真实场景下修复效果
3 结论
本文通过与其他方法的对比实验,证明了在不加入额外辅助信息的条件下,改进后的RFRNet在修复大面积缺损的深度图时能表现出较好的效果。由于模型自身的注意力机制,理论上该算法也有能力去修复结构复杂、语义信息丰富的深度图。后续的研究可以引入生成对抗网络或者使用其他更合适的注意力机制,使网络在语义理解能力和修复精度上有近一步提升。
