无线网络中基于网络编码与Hash查找的广播重传研究
2019-03-19,
,
(浙江工业大学 信息工程学院,浙江 杭州 310023)
随着移动通信技术的飞速发展,网络技术已经由传统的互联网过渡到移动互联网时代。相对于有线网络传输,无线链路本身有着独特的传输特性,比如广播传输、易受天气的影响、不稳定、丢包率大等。由于无线网络传输的带宽有限,为了提高整个网络系统资源的利用率,学者们从各个方面提出了诸多办法以提高无线网络的传输效率。在负载均衡方面,孟利民等[1]借鉴已有的负载均衡算法,并在其基础之上,引入了任务分类、任务加权等策略,使网络中各个节点之上的负载分配更为合理,从而提高了资源利用率,提高了系统性能。在用户体验方面,孟利民等[2]针对宏基站和家庭基站组成的无线异构网络,从用户体验的角度入手,将业务分为视频、语音和数据等3 个部分,采用模拟退火智能算法,对有限的频谱资源和功率资源进行分配,在保证无线视频用户体验的前提下,达成了不同业务的用户体验之和最大化,实现了无线资源的最优分配。在网络传输方面,孟利民等[3]在LT码基础上,提出了一种改进的度分布Raptor编译码策略,改善了无线视频信息的传输质量,降低了由丢包引起的视频实时性问题。但是,以上改善网络传输性能的方法都是在网络传输链路质量得到保证的前提下进行的,由于无线网络引起的数据丢包不可避免,而传统的OSI模型的链路层是采用自动重传请求(ARQ)技术来进行差错恢复的,ARQ需要对数据包进行一一重传,因此,在无线网络中采用传统的ARQ重传技术难免造成资源的浪费,且效率低下,近些年发展起来的网络编码理论为解决提高无线网络的重传效率问题提供了新的启发。
2000年,Ahlswede等[4]首次提出了网络编码(NC)的概念,允许网络节点在传统数据转发的基础上参与数据处理,可以有效地提高网络吞吐量,降低传输时延。网络编码的提出为无线数据的重传提供了另一种思路,在某些特定情形下,利用无线信道的广播性质和NC技术,在N个接受端丢失的N个数据包,通过简单的编码,仅需要1 次重传就能有效恢复。由此可见:基于NC的ARQ(NC-ARQ)方案提高了重传的系统性能。近年来,NC-ARQ方案在单发多收(Single-sender-multiple-receiver,SSMR)及多发多收(Multiple-sender-multiple-receiver,MSMR)无线网络中,都得到了广泛运用。随后,研究者们[5-8]提出了一些NC-ARQ方案,用以提升重传效率及重传可靠性。随后,Li等[9]提出了一种在MSMR场景下的机会式NC重传机制。此外,Tutgun等一批学者[10-12]结合空间分集与NC技术,提出了单源中继多播场景下的重传方案。Song等[13]结合空间分集与NC技术,设计了多源中继多播中的重传方案,可以有效减少重传次数,增加吞吐量。Ren等[14]和Niu等[15]讨论了缓存器辅助的NC-ARQ机制,该机制将当前无法解码的组合编码重传包存储在缓存器中,在一些新的特定编码重传包到来后,就可以成功解码恢复出原始数据包,可以有效降低所需重传包的数量,提升重传效率。为了保证每一次重传的收益最大化,笔者在现有NC-ARQ方案之上作了改进,设计了一种新的基于Hash查找无块化重传方法(Hash searching based non-block retransmission,HSNBR)。其基本思想是根据反馈信息对发送缓存器内的数据包生成反馈矩阵,并由反馈矩阵生成丢包权值表,再通过Hash邻域搜索找到使重传收益最大编码组合。若经过Hash邻域搜索未能找到使重传收益最大的编码组合,则对发送缓存器中的数据包进行更新,将已被成功接收的数据包移除,发送相等数量的新数据包填满发送缓存器,更新反馈矩阵与丢包权值表,再进行1 次Hash邻域搜索。最后得到的编码组合就是最优的重传编码组合。该方法可以确保每一次重传收益最大化,有效提高了NC-ARQ的平均重传效率。
1 网络模型
如图1所示的无线单跳广播网络,发送节点,即基站(Base station,BS)负责向N个接收节点发送数据包,N个接收节点记为Rs={Ri,i=1, 2,…,N}。广播基于数据包传输,数据包会受到物理层信道噪声、衰落和干扰的影响,因此,从高层看,由BS到Rs的广播传输可以视为包删除信道。假设BS到Ri之间数据包被删除的概率相互独立,设BS的发送缓存器大小为M,可以发送M个原始数据包,记为Pi(i=1, 2,…,M)。Rs根据M个数据包的接收情况反馈ACK或NACK至BS,为了模型的简便,这里假定ACK,NACK总能被BS正确地接收。BS根据反馈信息构建反馈矩阵A,A是N×M的矩阵。行号和列号分别代表接收节点序号和数据包序号。此外,A是一个二进制矩阵,A(i,j)=1表示Ri没有成功接收Pj数据包。反之则表示Ri成功接收了Pj数据包。表1为N=3,M=10的一个反馈矩阵示例。假设,只有当所有接收者全都正确接收数据包Pi,Pi才被视为成功发送,否则算作丢失。每当数据包丢失,BS需要重传这些数据包。根据反馈矩阵A,BS生成并发送由原始数据包线性组合的编码包。原始数据包的编码采用简单的异或机制。设一次重传中参与编码的丢失数据包为X1,X2,…,Xk,每个数据包长度均为L,Y为编码包。Xi可以表示为[xi1,xi2,…,xiL],Y可以表示为[y1,y2,…,yL],Xi与Y之间的关系式为
(1)
式中amodb为a对b求模。接收端通过将已成功接收的数据包和收到的编码包进行异或操作解码出自己丢失的数据包。即不同的接受者可以从一个编码重传包中恢复出不同的丢包。由此可见NC-ARQ机制可以有效地减少重传次数,提高无线网络资源的利用率。设计重传算法的主要目的在于设计出一种选包策略,可以让尽可能多的接收节点从一次重传中获得收益,以此减少重传次数。
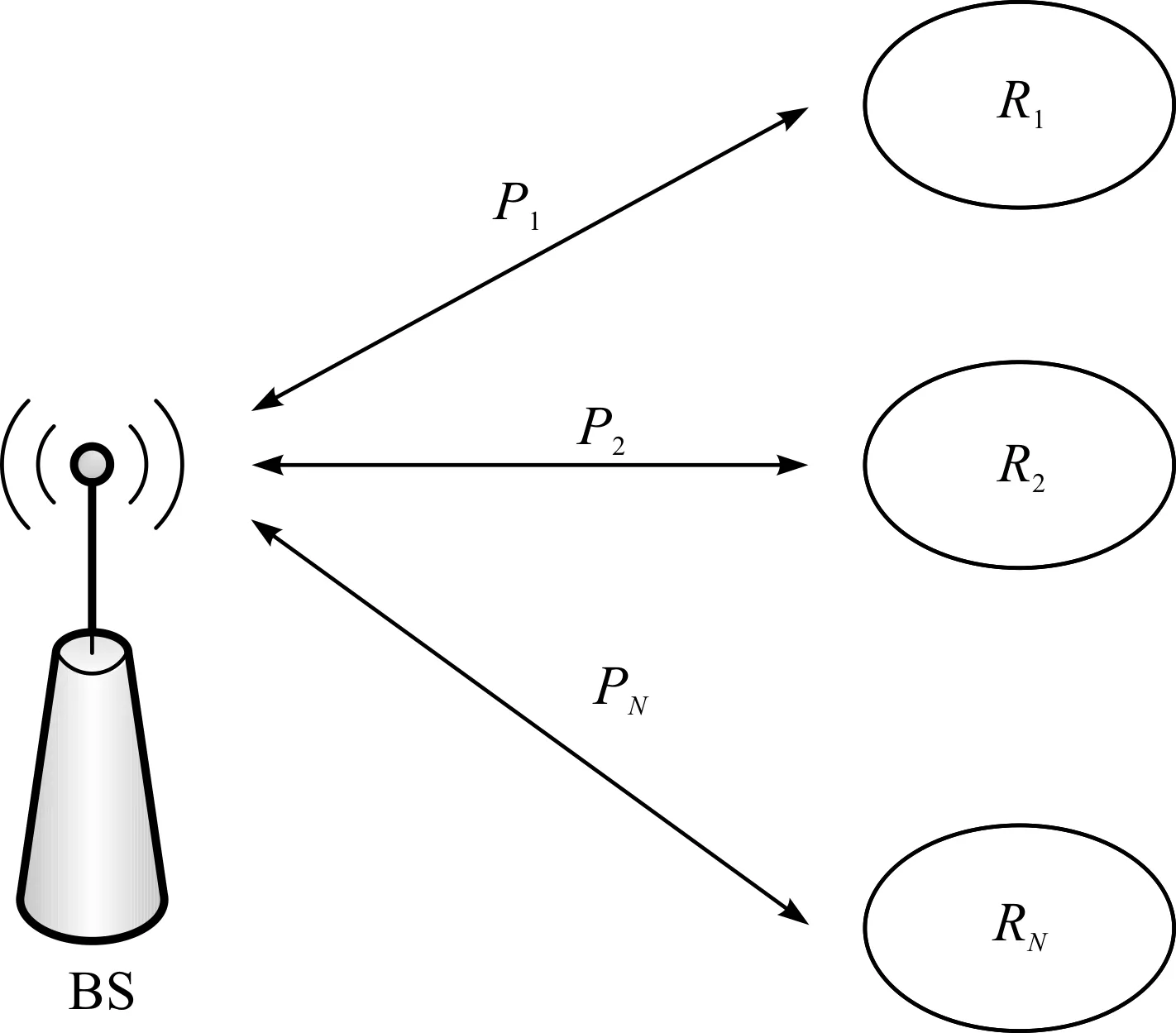
图1 无线广播网络模型Fig.1 Wireless broadcast network model with packet-erasure channels
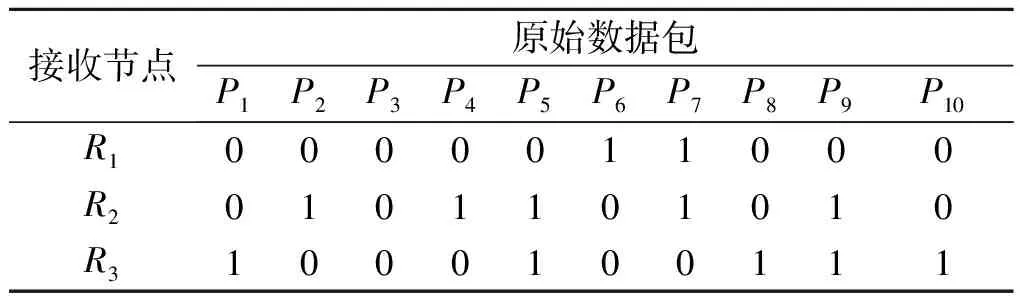
接收节点原始数据包P1P2P3P4P5P6P7P8P9P10R10000011000R20101101010R31000100111
2 HSNBR 重传算法
2.1 基于Hash邻域搜索的选包策略
定义1受益节点(Benefit node, BN):若1 个接收节点可以从该编码包中成功恢复1 个丢包,则称该节点为此编码重传包的BN。
定义2完美编码包(Perfect encoding package,PEP):若所有的接收节点都是该编码包的BN,则该编码包称为PEP。
定义3最优编码包(Optimum encoding package,OEP):若1 个编码包,从发送缓存器内尚未参与编码的原始丢包中,选取任意组合的原始丢包加入编码,都无法增加BN的数量,则称该编码包为OEP。
从定义3可以看出:OEP未必是PEP,而PEP必定是OEP。
在第1 节提到,BS会根据反馈信息构建反馈N×M的矩阵A。A的第j列表示数据包Pj相对于Rs的接收状态。根据数据包Pj的接收状态,生成特定的Hash值hj,Hash值的计算函数式为

(2)
BS根据式(2)计算每个丢包的Hash值hj,然后根据每个丢包对应的Hash值hj创建权值表,如表2所示。表2是根据表1反馈矩阵生成的权值表,表2中cj表示丢失数据包Pj数据包的接收节点的数量。

表2 丢包权值表Table 2 The lost weight table
为了尽可能提高重传的效率,HSNBR算法应当确保每一次发送的重传编码包为PEP或OEP。若1 个编码包Y由原始丢包X1,X2, … ,Xk编码而成,它们对应的Hash值为h1,h2, … ,hk,若接收节点Ri可以从Y中成功恢复出{X1,X2, … ,Xk}中之一的原始数据包,则必须满足
Fi(h1,h2,…,hk)=1
(3)
式中:Fi表示h1,h2, … ,hk全部转换为二进制后它们的第i位之和。
定理1如果1 个编码数据包Y1,对于所有的i=1, 2, …,N,均能满足式(3)则编码包Y1是PEP,即PEP满足
Fi(h1,h2,…,hk)=1i=1, 2, …,N
(4)
定理2若数据包Y2满足
Fi(h1,h2,…,hk)≤1i=1, 2, …,N
(5)
并且当发送缓存器中任意的其他原始丢包加入到组合中时,式(5)都不再满足,则Y2是OEP。
证明由定义1~3可知:Fi指示了Ri和X1,X2, …,Xk之间的接收状态,若Fi(h1,h2,…,hk)=0,则表示Ri已经成功接收了这k个参与编码的原始数据包,即这次重传对于Ri来说没有收益。此外,若Fi(h1,h2,…,hk) ≥2,则表明Ri在{X1,X2,…,Xk}中丢失了两个以上的数据包,即使成功接收了重传,也无法通过亦或解码从中回复出原始数据包。因此,只有满足式(3),即Ri在{X1,X2,…,Xk}中仅丢失1 个数据包。假设Ri丢失的数据包为Xj(1≤j≤k),编码包Y=X1⊕…⊕Xj⊕…⊕Xk,则Ri可以通过Xj=Y⊕X1⊕…⊕Xj-1⊕Xj+1⊕…⊕Xk恢复出Xj。
特别地,如果编码包Y1满足式(4),表示所有N个接收节点可以从中恢复1 个原始数据包,由PEP的定义2可知Y1是PEP。而如果Y2满足式(5),表示一部分节点已经成功接收了Y2编码组合中所有的数据包,另一些只丢失了Y2编码组合中1 个数据包,而将发送缓存器中其他任意原始丢包加入编码组合,都无法使式(5)继续满足,即组合中加入新的原始丢包时,会导致对于一些接收节点丢失的数据包在编码组合中不止1 个,因此无法恢复出原始丢包,根据OEP的定义,Y2是OEP。证毕。
由定义2可知:PEP可以使重传的效率最大化,因此所提出的HSNBR需要尽可能从发送缓存器中搜寻PEP。为了高效地从发送缓存器中找到PEP或OEP,需要引入Hash邻域的概念。
定理3若Hash值的集合U满足

(6)
那么U为Hash值h1,h2,…,hk的Hash邻域。
对于1 个原始丢包Pj,Rs中未能成功接收Pj的接收节点越多,则Pj对重传效率的贡献越大,因此应该被优先选择加入编码组合,而Hash值hj无法直观地体现丢失Pj的接收节点的数量cj。因为hj与cj即不成正相关,也不成负相关。举两个例子,如果优先选择Hash值大的包,当接收节点{R1,R2,R3}丢失了P1,接收节点{R3,R4}丢失了P2,h1=7,h2=12,优先选择的是P2,但显然P1更应当被优先选择。而若优先选择Hash值较小的包,当接收节点{R1,R2}丢失了P3,接收节点{R2,R3,R4}丢失了P4,h3=3,h4=14,优先选择的是P3,但显然P4更应当被优先选择。因此,如果只选用Hash值作为选包的依据是不妥的。
为了提高重传效率,又考虑到选包算法的复杂度不宜过大,提出一种Hash邻域搜索算法,过程如下:
步骤1首先从权值表中选择1 个cj最大的丢包,并取得其Hash值。
步骤2计算已选择的Hash值的邻域U。
步骤3从权值表2中挑选1 个属于U的最大的Hash值。重复步骤2,3直到所选择的Hash值满足式(4),或遍历了权值表。
执行完上述过程,如果挑选的包不满足式(4),则由定义可知所选的编码包为OEP,否则为PEP。
2.2 HSNBR算法流程
HSNBR算法的具体流程如图2所示。
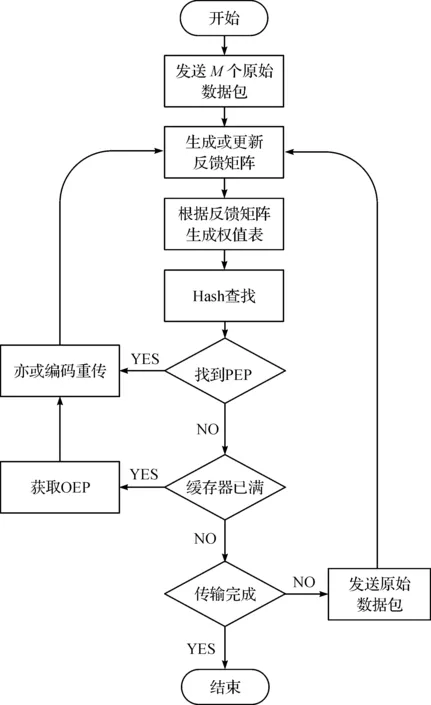
图2 HSNBR流程Fig.2 Flowchart of HSNBR
HSNBR算法的具体步骤如下:
步骤1BS逐个广播M个原始数据包。
步骤2根据Rs返回的ACK或NACK创建反馈矩阵A。
步骤3根据A计算每一个丢包的Hash值并生成权值表并将成功发送的数据包从发送缓存器中清除。
步骤4对生成的权值表进行Hash查找,如果找到PEP组合,则对选中原始数据包亦或编码后重传,随后跳转至步骤2。
步骤5如果未找到PEP组合,则检查发送缓存器是否已满。
步骤6如果发送缓存器已满,则根据Hash查找的结果发送OEP,随后跳转至步骤2。
步骤7如果发送缓存器未满且传输尚未完成,则广播新的原始数据包填满,随后跳转至步骤2。
HSNBR算法与普通NC-ARQ重传的主要区别在于步骤5,因为普通的NC-ARQ方案都根据发送缓存器的容量M将原始数据依次按大小为M的块进行发送,只有在一个块的所有数据包都被成功接收后才会发送下一个块的数据,因此,每次Hash邻域搜索的只能在一个单一的块内进行,这会限制每一次重传的平均效率,这些方案可以被视为块内NC-ARQ(Block NC-ARQ,BNC-ARQ)。而HSNBR只有在找到PEP组合或者在发送缓存器已满而不得不发送OEP的时候才会发送重传编码包。换言之,HSNBR会尽可能发送PEP,以此提高重传效率。
以表1反馈矩阵对应重传为例。
BNC-ARQ首先选择Hash值最大的P5,再对其进行Hash邻域搜索,则第1 个重传包Y1=P5⊕P6,BN1=3。依次地,Y2=P9,BN2=2;Y3=P1⊕P7;BN3=3;Y4=P8⊕P2;BN4=2;Y5=P10⊕P4,BN5=2。5 次重传的平均受益节点数BNavg=12/5。
HSNBR首先生成如表2所示的权值表,选择权值最大的P5,再对其进行Hash邻域搜索,则第1 个重传包Y1=P5⊕P6,BN1=3。随后选择权值最大的P9,进行Hash邻域搜索后Y2tmp=P9,并非PEP,根据HSNBR算法,会将发送缓存器中成功接收的数据包清除,并发送新的数据包,更新后的反馈矩阵如表3所示。
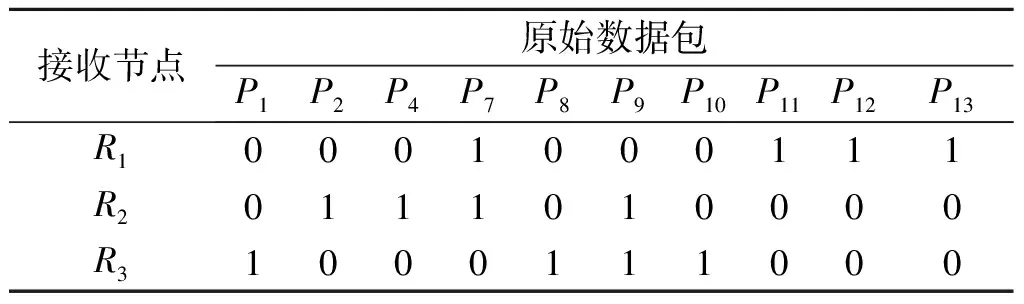
表3 更新后的反馈矩阵Table 3 The updated feedback matrix
更新后的权值表如表4所示。

表4 更新后的丢包权值表Table 4 The updated lost weight table
更新权值表后再对Y2tmp进行Hash邻域搜索,Y2=P9+P11,BN2=3。依次地,Y3=P7⊕P1;BN3=3;Y4=P8⊕P2⊕P12;BN4=3,Y5=P10⊕P4⊕P13,BN5=3。5 次重传的平均受益节点数BNavg=3。
可见HSNBR每一次重传的平均受益节点数要大于BNC-ARQ。换言之,HSNBR相较于BNC-ARQ可以有效减少重传次数,具有更高的重传效率。
3 实验仿真结果
为了验证所提出的HSNBR算法在有限缓存的情况下能有效地提高重传效率。采用Matlab仿真软件对ARQ,BNC-ARQ,HSNBR等3 种重传算法进行仿真以分析算法之间的性能差异。分析可知:在发送缓存器大小(M)、接收节点数(N)、信道平均丢包率(Average packet loss rate,APLR)以及发送数据包总量相同的情况下,不同算法所需的平均重传次数是重传算法重传效率高低最直观的体现,但其值随着发送数据包数量呈线性增长而浮动过大。因此,采用平均重传率(Average retransmission rate,ARR)作为衡量算法重传效率的指标。ARR定义为
(7)
式中:NR为重传总次数;NP为原始数据包的总数。ARR越低重传效率越高。为了便于分析,这里假设每一个重传包都能被各个接收节点百分之百正确接收,并且忽略接收端的定时误差。
图3反应了3 种重传算法的ARR随着发送缓存器大小变化的规律,其中接收节点数N为5,平均丢包率APLR为0.2,发送原始数据包总数为1×105。由图3可见:ARQ重传方案的ARR并不会随发送缓存器大小M变化而有显著改变,而仅仅是在一个固定值上有微弱的浮动,可以视为其ARR与M无关,但其ARR一直保持在一个很高的值,重传性能低下。在缓存器容量较小的区间,HSNBR的ARR会明显低于BNC-ARQ,因为理论上HSNBR相较于BNC-ARQ对于发送缓存器空间利用得更充分。随着发送缓存器大小M逐渐增大,HSNBR与BNC-ARQ的ARR均逐步下降,而HSNBR的ARR始终低于BNC-ARQ。当M进一步增大,HSNBR的ARR将非常接近理论下限的APLR。由此可见:在整个区间HSNBR的表现优于ARQ和NC-ARQ,在发送缓存器较小的情况下对重传性能的提升尤为明显,并且不需要非常大的缓存容量,HSNBR就可以非常接近理论的重传效率上限。
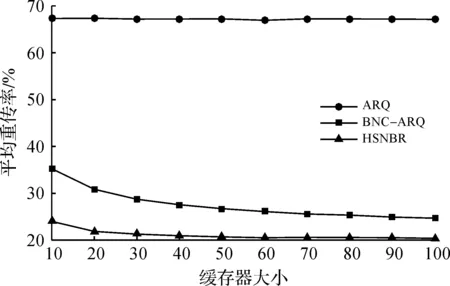
图3 重传效率随发送缓存器大小变化的规律Fig.3 Retransmission efficiency against the size of transfer buffer
图4为3 种重传算法的ARR随接收节点数N变化的规律。其中M固定为50,APLR为0.2,发送原始数据包总数为1×105。由图4可见:3 种算法的ARR均会随着接收节点数N的增大而增加。ARQ方案的ARR随N增大最快,且很快接近100%。HSNBR和BNC-ARQ随节点数量增加的增长速度较之于ARQ都更为缓慢,而HSNBR的ARR在N变化的情况下相较于BNC-ARQ更为稳定并且ARR始终低于BNC-ARQ,并不会随着N的增加有很大的涨幅,仅仅是随着N增加而有细微增长并且始终接近于ARR的理论值下限APLR。
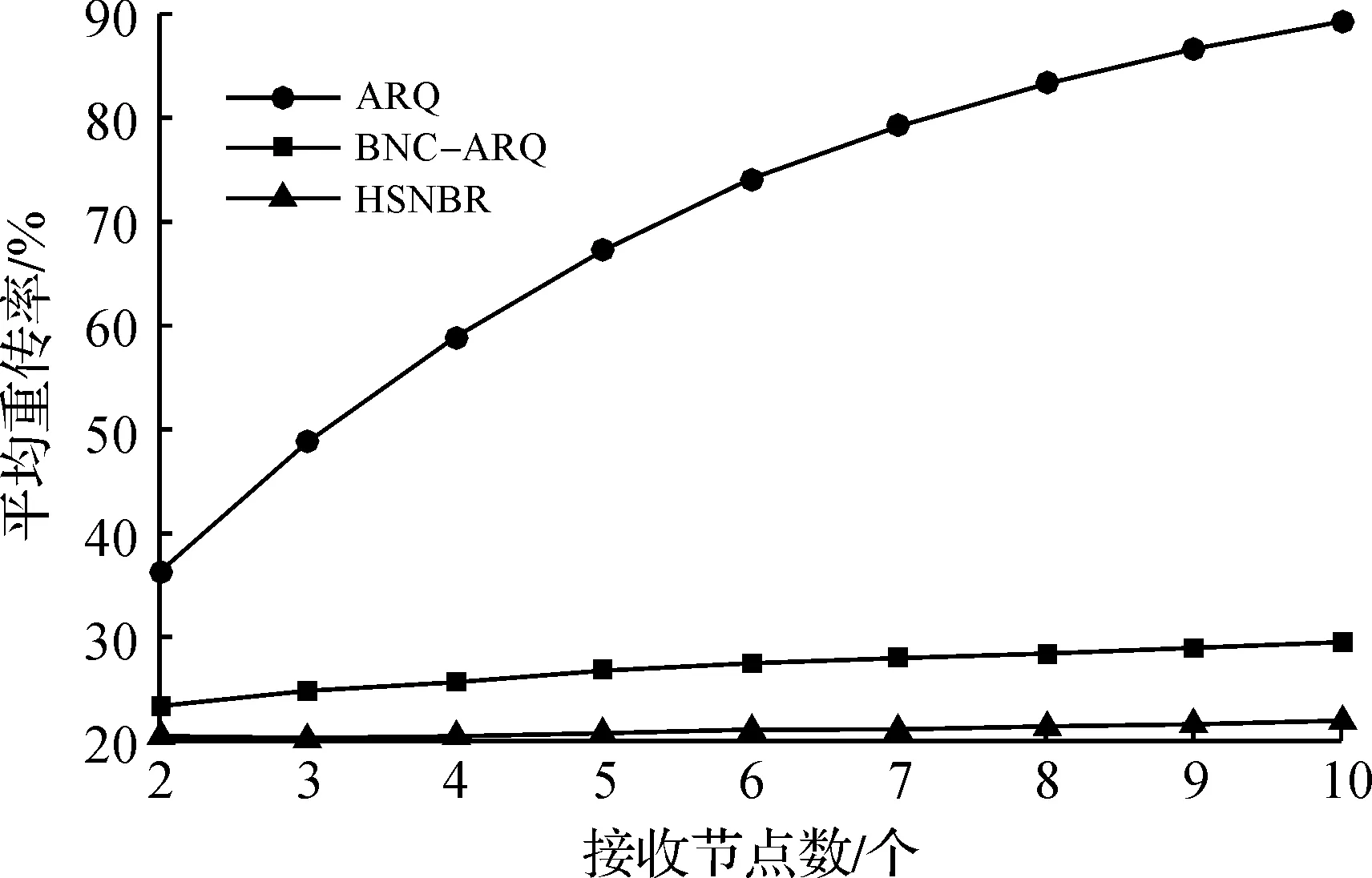
图4 重传效率随接收节点数变化的规律Fig.4 Retransmission efficiency against number of receivers
图5为3 种重传算法ARR随着平均丢包率APLR变化的规律。其中发送缓存器大小M为50,接收节点数N为5,发送元数据包总数为1×105。APLR的区间在0.05~0.5。由图5可知:ARQ算法的ARR随着APLR的增长最快,并且会很快地接近100%。HSNBR与BNC-ARQ的ARR在该APLR区间内近似地呈线性增长,并且HSNBR的ARR始终非常接近理论值的下限APLR,可见HSNBR在重传效率方面依然始终优于BNC-ARQ。
以上仿真结果表明:所提出的HSNBR重传算法的重传效率在各种环境下均优于ARQ和BNC-ARQ,且ARR通常都非常接近于理论值的APLR,这证明了方案的合理性与有效性。若传输时信道的丢包率高且面向的接收节点较多,只要适当增加缓存器容量就可以使重传效率保持在较为理想的水平,即通过增加硬件资源以弥补信道资源,这在信道资源受限的场景下是具有实际意义的。

图5 重传效率随平均丢包率变化的规律Fig.5 Retransmission efficiency against the APLR
4 结 论
针对BNC-ARQ存在的不足,提出了一种无线网络中基于网络编码与Hash查找的优化广播重传算法。在发送缓存器容量有限的情况下,通过动态地更新发送缓存器中的数据包,充分地利用了发送缓存器的空间,提高了丢包之间组合编码的概率,提升了重传包的重传效率,降低了重传丢包的次数,从而有效提高了SSMR网络中的传输效率。仿真结果表明:所提出的HSNBR重传算法的重传效率在各种环境下均优于ARQ和BNC-ARQ,证实了该方案的合理性和有效性。
