考虑任务拆分特性与簇准备时间的并行机调度
2022-03-24朱松平王小明鄢敏杰陈庆新
朱松平,王小明,鄢敏杰,陈庆新,毛 宁
(广东工业大学 广东省计算机集成制造重点实验室, 广东 广州 510006)



尽管国内外学者对并行机调度问题 (parallel machines scheduling problem, PMSP)开展了广泛研究,但是大部分文献未考虑任务拆分特性,经典PMSP研究详见综述文献[4-5]。针对任务可以任意拆分的PMSP,Serafini[6]以纺织行业为工程背景,提出了以最大加权拖期最小为决策目标的网络流模型与多项式算法。Xing等[7]证明了最小总拖期目标下的任务可拆分PMSP为NP-难问题。针对目标为总拖期最小的具有任务拆分特性与簇准备时间的PMSP,Kim等[1]提出一个两阶段启发式算法,第1阶段在不考虑任务拆分的情形下,基于现有的并行机调度启发式方法获得每台机器的加工序列,第2阶段将任务拆分成多个子任务并重新在机器上排序。Shim等[8]针对该问题提出3种优势定理和多种下界计算方法,并据此构建分支定界 (branch and bound, B&B)算法,然而该算法求解10个任务需耗时1 h左右,求解25个任务则需耗时10 h。Saricicek等[3]基于序列位置 (sequence position, SP)变量构建一个面向该问题的数学模型,对比禁忌搜索和模拟退火算法 (simulated annealing, SA)求解该问题的表现,结果表明SA算法更优。
簇准备时间属于序列相关准备时间的一种特例,而考虑序列相关准备时间的PMSP是调度领域的研究热点之一。在最小化最大完工时间目标下,Yalaoui等[9]、Tahar等[10]、郑秋亚等[11]、Wang等[12]分别提出相应的启发式算法。此外,Wang等[13]和Liu等[14]提出考虑学习效应的优势定理,据此建立基于SP变量的数学模型和分支定界算法。在最小化总拖期目标下,Kim等[15]建立数学模型并基于遗传算法 (genetic algorithm,GA)和SA算法提出多种编码和种解码方法,其实验结果表明商业求解器CPLEX在1 h内仅能精确求解少数包含10个任务和2台机器的算例,SA算法的总体表现优于GA算法。


1 问题描述

本文作如下假设。1) 所有任务在0时刻到达,任务以及子任务之间相互独立;2) 每台机器同一时间只能加工同一个任务的子任务。
对于上述问题,Shim等[8]、 Wang等[13]和Kim等[15]提出两个优势定理。本文后续将基于这两个优势定理来构建相应的数学模型和算法。从理论角度来说,由于优势定理能够直接排除部分非最优解空间,因而必然能够提升优化方法的求解效率。
优势定理1 在最优调度方案中,同一台机器上最多存在一个属于同一任务的子任务。
该定理的证明见Shim等[8]提出的 Proposition 1,Wang等[13]提出的Theorem 2,以及Kim等[15]提出的Property 1。
优势定理2 在最优调度方案中,所有任务在各台机器上的加工顺序相同。
该定理的证明见Wang等[13]提出的 Theorem 3。虽然Wang等[13]研究的是最小化总完工时间的考虑任务拆分特性与学习效应的PMSP,但是该优势定理同样适用本文所研究的问题。
2 数学模型
2.1 符号说明
除了在问题描述中已定义的符号之外,本文还引入如下符号。

2.2 SP模型


其中,式(1)是目标函数表达式,优化目标为总拖期时间最小;式(2)确保每个任务只能安排到一个位置上 (嵌入优势定理1);式(3)确保每个位置上只能安排一个任务;式(4)确保每个任务的所有单位任务都安排到机器上,且在每台机器安排的位置相同且唯一 (嵌入优势定理2);式(5)和式(6)表示变量yjkl和变量zjkl之间的关系;式(7)是计算每台机器的每个位置上的子任务拖期时间;式(8)和式(9)表示计算任务的拖期时间。
2.3 LO模型
基于线性序列 (linear ordering, LO)变量的机器调度模型最早出现在Dyer等[16]的研究中。Unlu等[17]将基于LO变量的并行机调度模型与其他模型进行对比,结果表明该模型具有较好的表现。本节将基于LO变量构建嵌入优势定理1和2的数学模型,并在后续实验部分将其与现有SP模型进行对比。

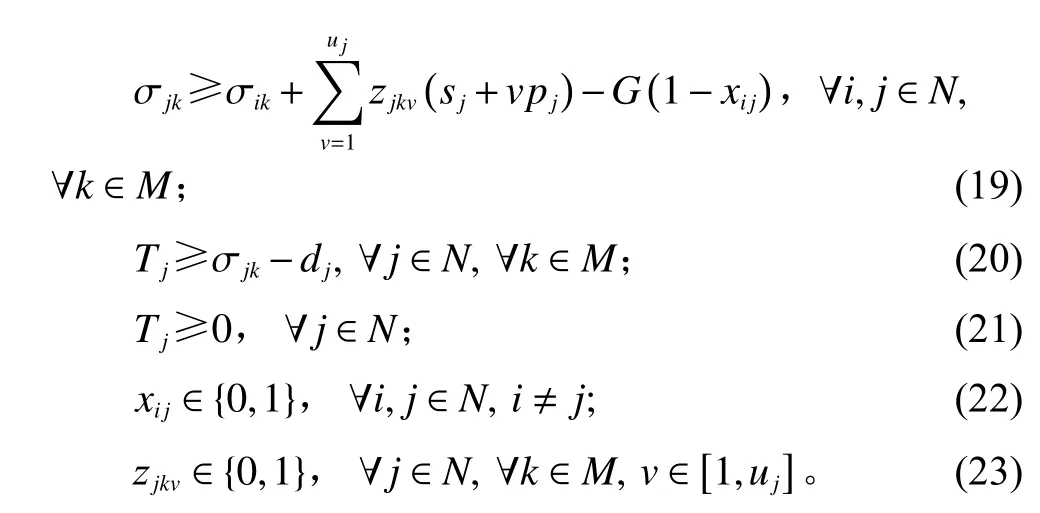
其中,式(13)是目标函数表达式,优化目标为总拖期时间最小;式(14)确保任意两个任务存在先后加工关系;式(15)表示任意3个任务之间存在线性关系;式(16)将优势定理1嵌入模型中,表示每个任务在每台机器中最多安排一个子任务;式(17) 确保每个任务的所有单位任务都安排到机器上加工;式(18)和式(19)是计算在每台机器上加工的子任务的完工时间;式(14)、式(15)和式(19)将优势定理2嵌入模型中,表示所有任务在每台机器上的加工顺序相同;式(20)和式(21)是计算任务的拖期时间。
3 模拟退火算法
由于问题的NP难属性,导致数学规划方法难以精确求解大规模问题。现有研究表明,SA算法在求解该问题时表现较好[3,15]。为此,本文将描述一种嵌入优势定理的SA算法,以高效求解实际规模的问题。SA的伪代码如图1所示。其中,X0为初始解;X为当前解;Y为邻域解;E0为初始温度;E为当前温度;Ef为截止温度, α为温度衰减系数;C(X)表示解X对应的总拖期。

图1 模拟退火算法伪代码Figure 1 Pseudocode of SA algorithm
3.1 编码规则
Saricicek等[3]的SA算法编码方法是定义每台机器的子任务序列以及子任务的单位任务数量。该方法解码过程简单,很容易计算目标值,但解空间很大。Kim等[15]的SA算法编码方法是采用一条总任务序列替代m条每台机器的子任务序列,解码时按照总序列中的任务依次将任务分解,并分配到机器上。这样处理可以减小解空间,但是解码过程太复杂。综合以上编码方法的优缺点,本文提出一种嵌入优势定理1和优势定理2的编码方式,即定义一条总任务序列,以及每个任务在每台机器上的单位任务数量。这样既能保证每台机器子任务序列与总任务序列一致,也能直接确定各台机器加工子任务的单位任务数量,从而避免上述解空间过大以及复杂解码的问题。
本文将Saricicek等[3]的编码方法称为基于子任务的编码规则,基于优势定理1和优势定理2的改进编码规则称为基于任务的编码规则,两者详细描述如下。
基于子任务的编码规则如图2所示。Jkl表示在机器k的第l个位置上加工的子任务; SJkl表示子任务Jkl的单位任务数量;nk表示在机器k上的子任务数量。

图2 基于子任务的编码规则Figure 2 Coding rules based on sub-task
基于任务的编码规则如图3所示。其中,Jl表示总任务序列的第l个位置上加工的任务; Sjki表示任务i在机器k上加工的单位任务数量。根据优势定理1和优势定理2可知,每个任务在每台机器上最多有一个子任务,且每台机器的子任务序列通过总任务序列确定。因此,只需要对总任务序列以及每个任务在每台机器上加工的单位任务数量编码,就可以确定每台机器的子任务序列以及子任务的单位任务数量。
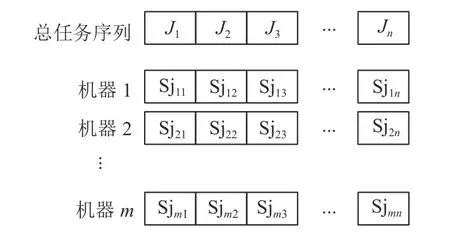
图3 基于任务的编码规则Figure 3 Coding rules based on task
3.2 邻域结构
由于上述两种编码方式不同,对应的调度方案邻域构造方法也将有区别。本文描述如下3种邻域结构,并构造出对应的3种SA算法。
第1种是建立在基于子任务的编码规则基础上的常规邻域结构。两者在未嵌入任何优势定理的情形下组合形成的SA算法称为SA1。该邻域结构包括同台机器子任务插入/交换、两台机器单位任务插入/交换4种典型的操作。
第2种是建立在基于子任务的编码规则基础上的改进邻域结构。该邻域结构中嵌入优势定理 1,组合而成的SA算法称为SA2。该邻域结构具有与常规邻域结构相同的4种操作,不同之处在于两台机器单位任务插入和交换时会进一步令其满足优势定理 1。例如,若将机器k中的任务j的一个单位任务插入或交换到机器k′上,则先判断机器k′上是否存在属于任务j的子任务,若存在就直接将该单位任务并入该子任务中,否则随机插入或交换到机器k′,这避免了一个任务在一台机器上存在多个子任务。
第3种是建立在基于任务的编码规则基础上的改进邻域结构,该编码规则已经嵌入优势定理1和2,组合而成的SA算法称为SA3。该邻域结构包括总任务序列中的任务插入/交换、两台机器的单位任务插入/交换4种操作。前两种邻域结构中的同台机器子任务插入/交换操作只可能改变该机器的任务顺序,而这里对总任务序列中的任务进行交换/插入,相当于对所有机器的任务顺序进行同步更新操作。
3.3 参数确定
SA算法参数的设置对优化效果和计算效率有显著影响。为合理设置SA算法参数,本文利用SA2和SA3算法,分别在不同参数组合下求解一种中等规模算例,并据此选定一组合理的参数用于后续计算实验。
本文设置3种水平的初始温度E0为300、400、500;5种水平的温度衰减系数α为0.95、0.99、0.999、0.999 5、0.999 9;截止温度Ef固定为0.001。所使用的调参算例包含40个任务和12台机器,每个任务有6个单位任务,考虑3种交货期、3种准备时间,每种参数下随机生成3个算例,共27个算例。详细的算例参数设置见本文4.1节。
SA2和SA3算法的调参计算结果分别如图4和图5所示。可以看出,SA2和SA3算法的表现基本一致,其中优化效果和计算耗时与E0相关性不明显,但与 α显著相关。总体来说, α越大计算耗时越长、优化效果越好,但是当 α增大到0.999 5之后,计算耗时会显著增加而优化效果相差不大。因此,综合考虑优化效果和计算耗时,本文设定3种 SA算法采用相同的参数:E0=300, α=0.999 5。

图4 SA2算法调参Figure 4 Parameter tuning for the SA2 algorithm

图5 SA3算法调参Figure 5 Parameter tuning for the SA3 algorithm
4 实验计算
本文基于随机生成的算例进行多组计算实验,以验证所建数学模型和算法的有效性。采用C语言编程实现各个模型和SA算法,并调用商业优化求解器Gurobi 8.1.0 (内置分支切割算法)求解所有数学模型。实验结果由计算程序运行在配置为Inter(R) Xeon CPUE5-4603 v2 2.20 GHz处理器,32.0 GB内存的服务器上所得。
4.1 实验设计

由于基于数学规划的精确方法只能求解部分小规模算例,本文设定Gurobi求解每个算例限时1 h时,其他参数采用默认设置。为了对比各数学模型的求解效率,设置如下评价指标。
1) 1 h内求出最优解的算例数量OptN;
2) 求出最优解的平均耗时AT;
3) 1 h内未求出最优解,但有可行解的算例数量FeaN;
4) 可行解的平均间隙AGap,单个算例间隙Gap的计算依据式(24),其中,ObjVal表示最好的可行解值;ObjBound表示问题的线性松弛所得下界值。

本文采用交货期优先规则生成所有SA算法的初始解,其过程如下。先根据交货期从小到大对任务排序,接着逐一将任务的所有单位任务安排到负荷最小的机器上,直到所有单位任务被安排完毕。为对比各SA算法的求解效率,设置如下评价指标。
1) 平均总拖期相对偏差ARDI;单个算例的总拖期相对偏差RDI,如式(25)所示,其中, TTe为方法e的总拖期,TTmax和TTmin分别为相同算例下所有方法对应的最大总拖期和最小总拖期。


4.2 结果分析
首先,采用Gurobi求解小规模算例对应的各个数学模型,得到如表1和表2所示结果及如下两个主要结论。

表1 各数学模型在不同交货期环境下的表现Table 1 The performance of each mathematical model under different due date environments
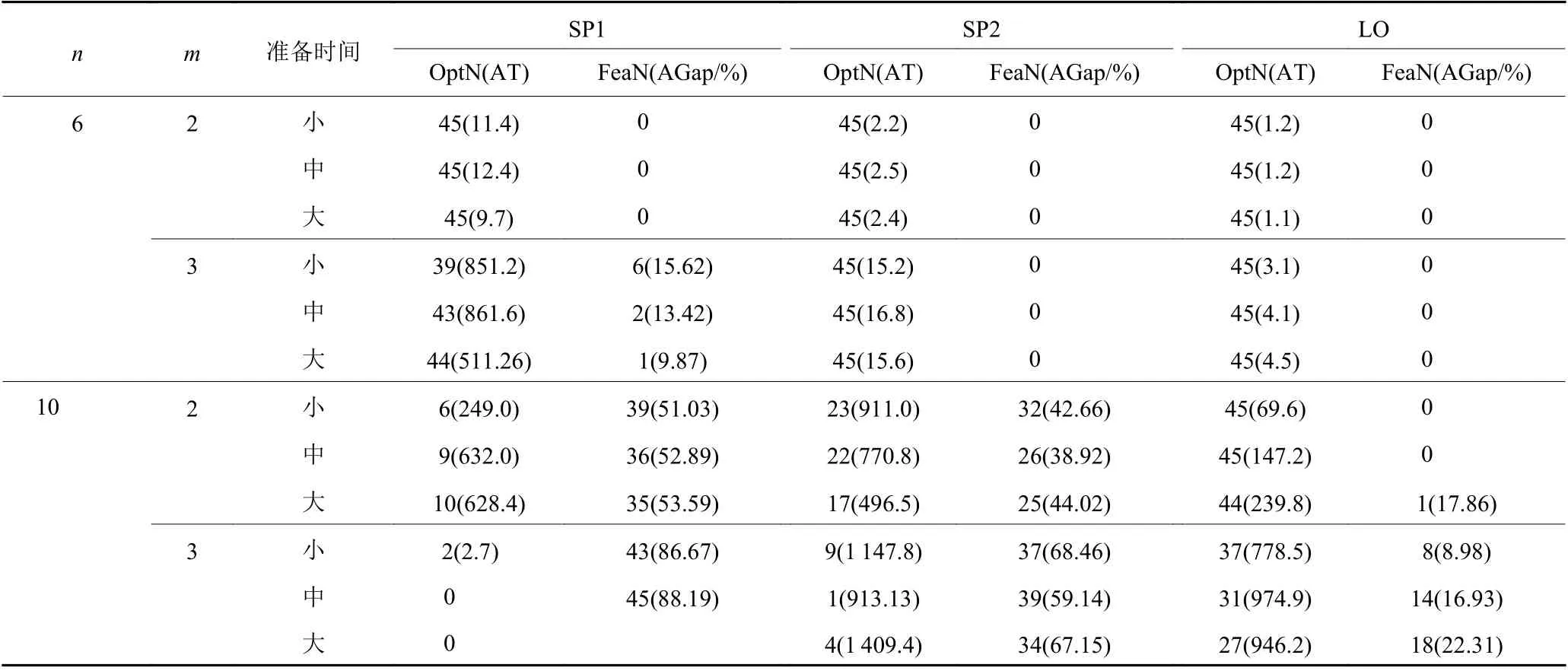
表2 各数学模型在不同准备时间下的表现Table 2 The performance of each mathematical model under different setups
1) LO模型总体表现最优,SP1模型表现最差,改进的SP2模型优于SP1模型。在6个任务下,LO模型和SP2模型都能够获得所有算例的最优解,但LO模型耗时更短。而SP1模型有部分算例无法求解最优解,且平均耗时最长。在10个任务下,LO模型精确求解的算例数量最多,其次是SP2模型,SP1模型最少。此外,在未能精确求解出的算例中,LO模型的平均间隙最小,其次是SP2模型,SP1模型最大。与Shim等[8]的B&B算法相比,LO模型在6个任务下、10个任务两台机器β=0.8和 β=1.2下、10个任务3台机器β=1.2下的计算耗时更短。
2) 模型的求解效率与β相关,与准备时间无显著关系。虽然Shim等[8]的研究表明其B&B算法效率与β无关,但是表1结果表明3个模型的求解效率都与β相关。具体地,在相同的任务数和机器数下,β越大模型表现越好。此外,由表2可知,本文的3个模型的求解效率与准备时间并无显著相关。
采用3种SA算法求解小规模任务算例,所得结果与表现最好的LO模型对比,如表3所示。在优化效果方面,由于LO模型能够获得大多数算例的最优解,因此其在ARDI指标方面表现最好,SA3表现与之最接近,而SA1则表现最差。在计算耗时方面,3种SA算法的耗时都远小于LO模型耗时,且随着任务规模增长,SA算法耗时增长并不明显,而LO模型的求解耗时则呈指数增长。

表3 小规模算例下SA算法与精确方法对比Table 3 Comparison of SA algorithm and exact method for small-scale instances
最后,采用3种SA算法求解大规模任务算例,得到如表4、表5和图6所示结果及如下结论。
在优化效果方面,由表4和表5可知,SA2和SA3相差不大,且都显著优于SA1。SA2和SA3的优化效果与β、准备时间之间不存在显著相关性。由此可见,在本研究中,优势定理1是提升SA算法优化效果的主要因素,优势定理2的提升作用相对不显著。
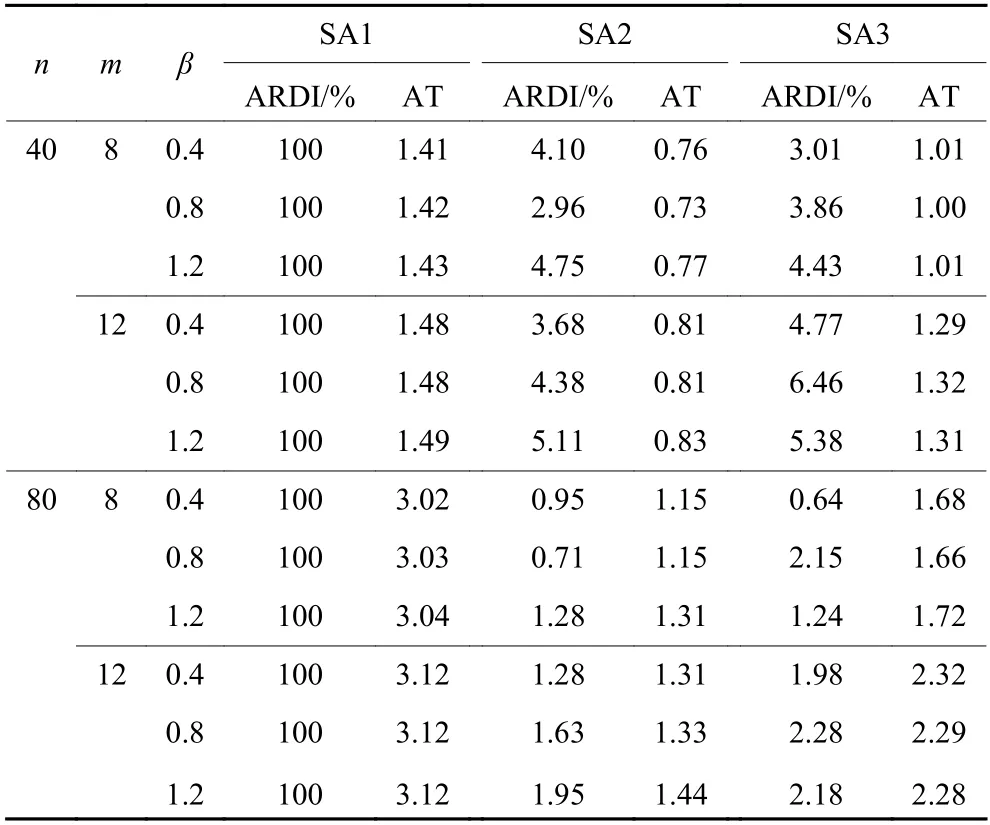
表4 各SA算法在不同交货期下的表现Table 4 The performance of each SA algorithm under different due date environments

表5 各SA算法在不同准备时间下的表现Table 5 The performance of each SA algorithm under different setups
在计算耗时方面,3种SA算法的耗时均很短,满足工程实际要求。而SA1的耗时最长,SA2耗时最短,SA3耗时介于SA1和SA2之间。
在收敛速度方面,由于SA1算法收敛速度相对于SA2和SA3差很多,因此,图6仅展示SA2和SA3算法的收敛曲线。可以看出,在迭代前期SA3的收敛速度略快于SA2,但是随着迭代次数增大,SA2和SA3收敛曲线基本重合,即这两种算法的最终优化效果区别不大。这表明尽管优势定理2对于提升SA算法优化效果不如优势定理1显著,但其在算法开始阶段可以进一步提升算法的收敛速度。

图6 SA2和SA3算法的收敛速度对比Figure 6 Comparison of SA2 and SA3 algorithm on convergence rate
5 结束语
针对具有任务拆分特性与簇准备时间的并行机调度,本文改进了现有SP模型,建立嵌入两种现有优势定理的LO模型,并提出嵌入优势定理的SA2和SA3算法。实验结果表明,本文构建的LO模型表现优于现有SP模型,不仅能够精确求解更多小规模算例、耗时更短,而且不能求解算例的平均间隙也最小。在智能算法方面,相比于无优势定理的现有SA1算法,本文基于优势定理提出的SA2和SA3算法能够在更短的时间内获得更好的优化效果。具体来说,SA3算法在小规模任务下优化效果最好,SA2和SA3在大规模任务下的优化效果相同,但是SA2计算耗时稍短,而SA3收敛速度稍快。
在下一阶段工作中,将考虑非同等并行机、任务工期不确定等更贴近工程实际的因素,探索面向这类问题的优势定理以及高效模型和算法。
