基于特征优选策略的居民用电行为聚类方法
2022-03-23张洁,夏飞,袁博,刘伟
张 洁,夏 飞,袁 博,刘 伟
(1. 上海电力大学自动化工程学院,上海市 200090;2. 南瑞集团有限公司(国网电力科学研究院有限公司),江苏省 南京市 211106;3. 海宁亚大塑料管道系统有限公司,浙江省 海宁市 314415)
0 引言
近年来,居民用电负荷成为高峰负荷,对居民用电行为进行分析显得尤为重要[1-3]。通过用电负荷曲线聚类分析得到居民用户用电规律,对用电负荷预测[1]、需求侧响应[4]、电价调整[5]、电网规划[6]和发输电计划改变[7]等都有重要意义。
文献[8]针对48 维功率向量,采用改进模糊C均值(fuzzyC-means,FCM)算法对日负荷曲线进行聚类;文献[9]基于云模型确定聚类中心和聚类数,以24 维日负荷数据进行了负荷模式提取和用户分类实验;文献[10]基于改进密度峰值聚类算法分别对48 维和96 维有功功率数据进行聚类分析。上述文献都是直接对高维用电负荷曲线进行聚类,随着可获取的用电负荷数据量及维数大幅增加,其计算时间和计算复杂度均相应增加。因此,需要在保证聚类效果的同时降低计算复杂度。
文献[11]通过负荷率、日峰谷差率等6 个特性指标对日负荷曲线进行聚类,具有运行时间短、鲁棒性好的特点;文献[12]提取日负荷率、日峰谷差率等7 类指标进行聚类,在聚类质量、运行效率和鲁棒性上都体现了优越性;文献[13]利用符号集合近似(symbolic aggregate approximation,SAX)算法对负荷曲线进行降维提取特征,引入日负荷率、谷电系数、日平均负荷等5 个典型用电特征指标。在以上研究中,虽然实现了降维负荷曲线聚类分析,但没有给出聚类特征选择依据。文献[14]针对用电特征选择,提出一种基于特征互信息量与相关系数的特征优选准则获取优选特征集。根据优选特征集中的特征进行聚类大大减少了迭代次数和聚类时间,但选取的聚类特征并不能反映负荷曲线形态,影响了聚类效果。因此,本文提出一种兼顾各特征有效性和各特征间相关性的聚类特征优选策略。通过贝叶斯信息准则(Bayesian information criterion,BIC)和相关系数来评价特征,一方面,在降低特征维度的同时保证了模型的准确率,即实用性;另一方面,通过将特征维度作为惩罚因子实现了冗余性要求[15]。
一般在用电负荷聚类时,特征集中仅选用日负荷率、峰时耗电率等常用的用电特征[11-14,16-18]。居民用电负荷曲线可以通过负荷率、日峰谷差率等典型用电特征反映,同时也会受到政策、季节、温度等因素的影响[9]。因此,本文在常用用电特征的基础上加入气象因素特征构成原始特征集,再利用本文提出的优选特征策略分析原始特征集,挑选出满足聚类要求的最优特征子集。
得到优选特征后,采用传统聚类算法,如K均值(K-means)算法对居民用电行为进行分析,但只能发现球状类簇,且易受噪声点影响[19]。密度峰值快速搜索聚类(clustering by fast search and find of density peaks,CFSFDP)算法[20]可以在不确定聚类数的情况下发现任意形状的类簇,且收敛速度快,对海量高维、类簇形状差异大[21]的用电负荷数据可以快速实现聚类分析[22-23]。但该算法也存在以下不足:1)截断距离选择会对聚类结果产生影响;2)人为选择聚类中心具有主观性。因此,本文利用布谷鸟优化算法对截断距离进行寻优,并利用异常值思想实现聚类中心的自动选择,提出了一种加权的皮尔逊距离量度方法,可以反映负荷曲线之间变化趋势的相似性。
综上所述,本文不仅设计了一种特征优选策略,而且通过改进密度峰值法,提高了小区居民用电行为聚类分析的准确性,为负荷预测、需求侧管理等提供了参考。
1 原始特征集构建
通常表示用户用电行为特点的典型用电特征包括[16-18]:表述峰谷特性变化的特征指标如峰期负载率、平期负载率、谷期负载率等;表述负荷变化的特征指标如负荷率、峰谷差、峰谷差率等;以日为单位表述用电特征的指标如日用电负荷、日平均负荷、日最大负荷、日最小负荷等,具体如表1 所示。表中,P代表用电负荷,下标peak、fl、val 分别表示峰期、平期、谷期,下标sum、av、max、min 分别代表负荷总值、均值、最大值、最小值。

表1 典型用电特征Table 1 Typical electricity consumption features
同时,气象因素也是影响用户用电行为的重要特征之一,通常有气温、降水、湿度、风力等影响。典型的气象因素特征包括:平均温度、最高温度、最低温度、雨水、风向、风速、压强、湿度,具体如表2所示。
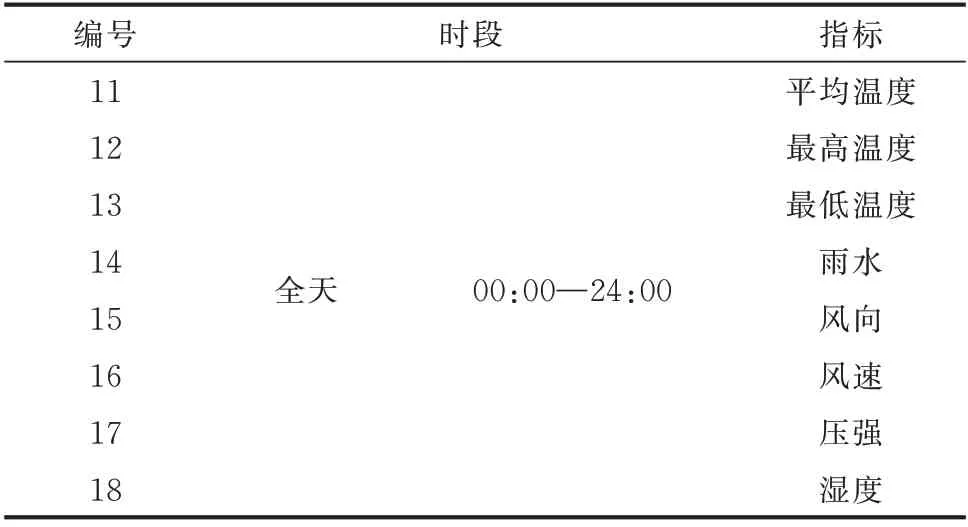
表2 典型气象特征Table 2 Typical meteorological features
本文在研究用户用电行为时,同时考虑典型负荷特征和典型气象特征因素的综合影响,构建原始特征集X,使得聚类研究用电行为的变化更加准确。
2 聚类特征优选
第1 章中提到的原始特征集中的典型用电特征和典型气象特征共有18 个。如果利用以上全部特征进行聚类分析,不仅计算量大、计算时间长,而且某些特征对分析产生的效果是相似的。因此,要对原始特征集中的特征进行优选,可以通过构建评价函数的方法进行最优特征选择。在构建评价函数时,需要在考虑特征有效性的同时兼顾各特征间的互补性。本文利用基于信息量的BIC,结合聚类评价指标轮廓系数,衡量聚类特征的有效性。同时,在评价函数中加入了相关系数,从而充分考虑了各特征间的互补性。
2.1 特征集评价函数
2.1.1 轮廓系数指标
聚类评价指标轮廓系数(silhouette coefficient,SC)用于评估聚类效果。假设数据集X被分为J个类簇:C={C1,C2,…,CJ},则数据集X中的第i个样本点的SC 指标定义为:

式中:a(xi)为xi到同一簇内其他对象之间的平均距离;b(xi)为xi到其余类簇的最小平均距离。
2.1.2 BIC
本文选用基于信息量的BIC 来评价特征的有效性,即

式中:cov(x,y)表示特征x与y的协方差;σx和σy分别表示x和y的标准差。相关系数ρxy的取值范围为[-1,1],其绝对值越接近于1 则说明二者的相关性越强。
2.2 特征优选策略
原始特征集中的每个特征对聚类分析的影响效果不同。与此同时,有些特征所提供的信息可能存在重复和冗余。如果可以选择有效的特征指标去反映用电数据的多维指标,则既能够除去多余的特征指标,又能够改善分析结果。因此,对原始特征集进行优选,得到最优特征集再进行聚类分析很有必要。
为得到最优特征子集,既需要考虑特征的有效性,又需要考虑各特征之间的互补性。因此,本文综合考虑特征的有效性及各特征间的相关性构建特征优选的评价函数[14],定义为:

式中:Z(x)为特征x的评价值;B′(x)为特征x进行归一化后的BIC 值;Z(Y)为最优特征子集Y的评价值,为该子集中所有特征的评价值之和。
原始特征库中的各特征利用此评价函数进行计算时,评价值越小则说明该特征对用电行为分析影响越大,效果越好。
特征优选就是从原始特征集中选出评价值较小的特征构成最优特征子集。特征优选过程如下:首先,计算出原始特征库中各特征的评价值;然后,利用启发式序列前向搜索法对特征进行逐个选取,从空集开始,每次选出评价值最小的特征放入最优特征子集Y中,直到最优特征子集满足停止条件。所选出的特征y可以表示为:
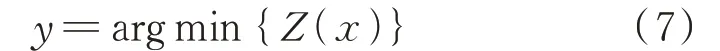
特征挑选终止的判别条件为原始特征库中所剩余特征的有效性远小于其所带来的冗余性时则停止选择,即

式中:R为原始特征库中最优特征的评价值与最优特征子集的评价值的比值;T为所设阈值,当R≤T时则停止选择,本文设定阈值T为0.1。
3 密度峰值聚类算法
利用第2 章的特征优选策略选出最优特征子集Y后,还需要结合相应的聚类算法对居民用电负荷进行聚类分析。本文针对密度峰值法的主观性,采用布谷鸟搜索(cuckoo search,CS)算法对截断距离进行优化。同时,根据异常值检测的思想,实现聚类中心的自动选取。
3.1 密度峰值法
本文基于最优特征子集Y中的特征,利用密度峰值法对用电负荷完成聚类分析。该算法主要有2个需要计算的量:局部密度ρi和与高密度点之间的距离δi。
1)局部密度ρi
为减小截断距离dc对聚类结果的影响,采用高斯核函数对局部密度进行改进[24]:

式中:dij为2 个点间的距离,这里采用加权皮尔逊距离。原算法中的局部密度ρi表示数据集X中与点xi的距离小于截断距离dc的样本点的个数,是离散的。改进算法中采用的高斯核是一个连续的值,可以减小不同数据点具有相同局部密度值的可能性。
2)与高密度点间的距离δi
定义每个样本点xi到更高密度点间的最小距离δi:

对于数据集中局部密度最大的样本点xi,令其距离δi为:
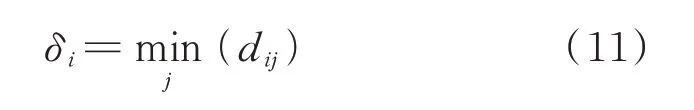
传统的密度峰值算法存在以下不足之处:一方面,截断距离dc的选择对聚类结果产生影响;另一方面,根据决策图中ρ和δ都较大的点选择聚类中心,对于聚类中心明显的数据集可以很轻易地选择出来,但对于ρ和δ不太明显的数据集选择起来就会比较困难。同时,每次运行都要重新选择聚类中心,从而增加了算法的冗余性,而人为选择也包含了主观性,故每个人选择聚类中心的不同也会导致聚类结果的不同。因此,需要对以上2 个问题分别进行改进。
3.2 改进的密度峰值法
本文提出的改进的密度峰值法主要表现在以下2 个方面:一方面,根据聚类评价指标SC,利用CS算法对截断距离dc进行优化;另一方面,利用异常值检测的思想,采用高斯分布(Gaussian distribution)实现聚类中心的自动选择。
3.2.1 优化截断距离dc
本文采用CS 算法优化截断距离dc,选取SC 指标作为目标函数。
CS 算法是2009 年提出的一种新兴启发式算法[25]。该算法相比于粒子群优化(particle swarm optimization,PSO)算法[26]设置参数更少,采用Levy飞行进行全局搜索,并且通过随机游走的方式进行局部寻优,寻优能力更强、精度更高。本文将聚类评价指标SC 作为目标函数,经过多次迭代选出最优的截断距离dc。
结果表明,CS 算法具有较好的局部寻优能力,减少了迭代时间。具体寻优过程详见附录A,利用CS 算法进行寻优,同时与PSO 算法作为对比,最终的寻优结果见附录A 图A1。
3.2.2 自动确定聚类中心
由3.2.1 节所述,选择局部密度ρ和距离δ都较大的点作为聚类中心。本文自适应选择聚类中心时,利用标准化的局部密度ρ和距离δ的乘积来反映聚类点之间的差异度,对这些乘积通过高斯分布寻找出异常点,并将异常点作为聚类中心,实现聚类中心的自动选取。
高 斯 分 布 又 称 为 正 态 分 布(normal distribution),具有两头小、中间大的特点。本文选用高斯分布作为异常检测的模型,将分布在两头的小概率事件作为异常值,从而选择出聚类中心。
首先,定义局部密度ρ和距离δ标准化处理后的乘积作为簇中心的权值γ,即

在正态分布的假设下,利用3σ原则选择异常点,即区域μ±3σ中包含99.7%的数据,若均值μ超过了3σ,则可以认为该点为异常值。
本文利用正态分布作为异常值检测的模型,实现自动确定聚类中心,其具体步骤如下:
1)计算出每个数据点的局部密度ρ和距离δ,并将其标准化;
2)计算出每个数据点的簇中心权值γ;
3)根据式(13)、式(14)计算每个数据点的均值μ和方差σ2;
4)根据3σ原则确定异常点,即自动选择出聚类中心。
4 实验分析
为验证本文提出的方法,选用某居民小区5 类典型日负荷曲线共500 条进行聚类分析实验。其中类别1~5 的用户平均用电负荷分别为1 146.03、1 220.58、570.86、689.26、103.30 kW,平均温度分别为30.14、30.56、28.77、22.84、16.63 ℃。这5 类用户的用电行为特征描述如表3 所示,利用准确率(即分类的正确率)来衡量聚类效果的质量。本文算例在2.6 GHz CPU、16 GB 内存、64 位操作系统的单台PC机上进行了测试。

表3 各类用户用电行为特征描述Table 3 Feature description of electricityconsumption behavior for each type of users
4.1 特征优选策略的性能分析
根据提出的特征优选策略,对原始特征集进行挑选。最优特征子集Y从空集开始,依次挑选评价值最小的特征。首先,进行第1 次特征挑选,各特征指标的评价值Z包括归一化后的BIC 值B′及相关系数ρ值,其具体计算结果见附录B 表B1。
特征挑选时,应选择评价值Z最小的特征放入最优特征子集Y中。由附录B 表B1 可知,第1 次应选择本次评价值最小的日用电负荷作为最优特征(特征编号7)。
后续的特征挑选与上述过程类似,这里不再进行赘述。最终,通过本文提出的特征优选策略进行特征挑选时,各特征指标挑选的顺序见附录B 表B2。利用本文提出的特征优选策略,当特征挑选了7 次后满足终止条件,不再进行选择,最终选出的最优特征子集为编号7、9、4、11、5、10、17 的特征。
接下来,利用聚类分析的准确率来验证该特征优选结果的可行性。按照附录B 表B2 中2 种方法给出的顺序,依次挑选特征至最优特征子集中,利用密度峰值法聚类,详见附录B,其聚类分析的准确率变化趋势见附录B 图B1。
4.2 基于优选特征的聚类分析
在4.1 节中,利用本文所提的优选策略对原始特征库中的特征进行挑选,最终选择出7 个特征至最优特征子集Y中,分别为日用电负荷、日最大负荷、日负荷率、平均温、日峰谷差、日最小负荷和压强。本文将根据以上7 个特征进行聚类分析。这里为了对比聚类效果,还利用了原始特征集X和仅根据BIC 挑选的特征子集Y*进行实验。Y*中包括的特征分别为日用电负荷、风速、雨水、风向、湿度、谷期负载率和日最小负荷。
4.2.1 不同特征集的聚类效果分析
首先,为验证优选特征策略的效果,分别利用原始特征集X中的全部特征、BIC 挑选出的特征子集Y*和本文所提优选策略选择出的特征子集Y中的特征进行聚类分析。为比较聚类效果,都采用密度峰值法进行聚类,截断距离dc设定为2.0,其聚类结果的对比如表4 所示。
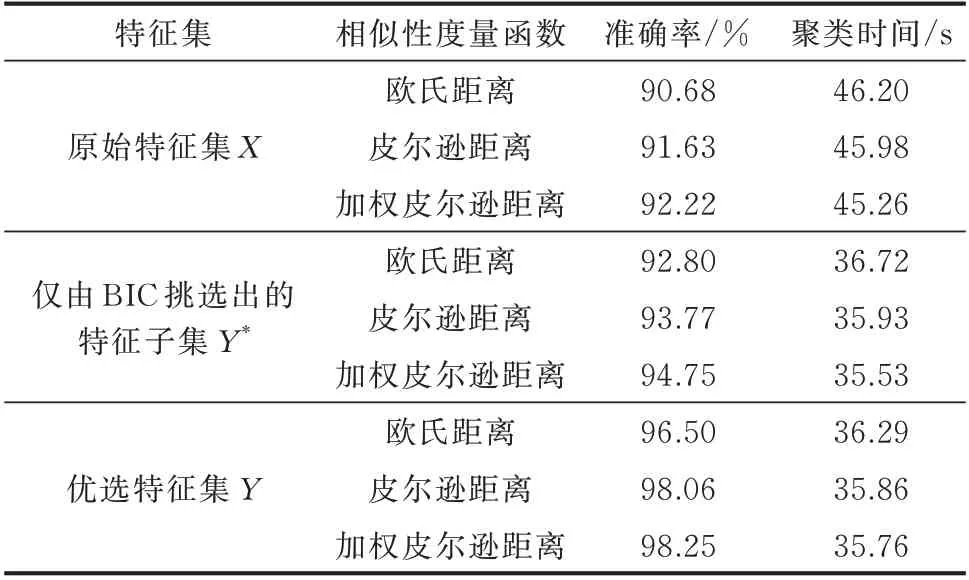
表4 不同特征集的聚类效果分析Table 4 Clustering effect analysis of different feature sets
由表4 可知,无论采用哪一个特征集,当相似性度量函数采用加权皮尔逊距离时,与欧氏距离及皮尔逊距离相比,不仅聚类准确率最高,而且聚类时间也最短。由此可见,相似性度量函数应该选择加权皮尔逊距离。
当相似性度量函数同样选择为加权皮尔逊距离时,采用原始特征集X的聚类准确率为92.22%,采用BIC 挑选出的特征子集Y*的聚类准确率为94.75%,采用本文方法挑选出来的特征子集Y的准确率为98.25%。由此可知,通过特征优选后聚类准确率可以显著提高。
4.2.2 不同聚类方法的聚类效果分析
4.2.1 节对比了不同特征集在采用相同聚类方法时的聚类效果。本节主要分析采用本文方法得到的优选特征集Y在使用不同聚类方法时的聚类效果。聚类方法包括K均值算法、CFSFDP 算法和本文提出的改进CFSFDP 算法,聚类效果如图1所示。
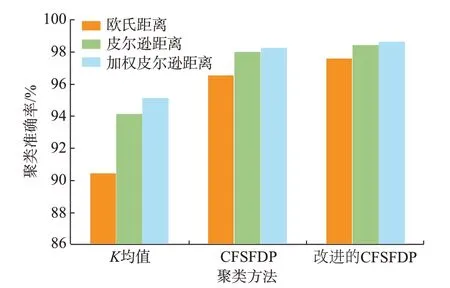
图1 不同聚类方法结果对比Fig.1 Result comparison of different clustering methods
由图1 可知,利用本文提出的优选策略得到的优选特征集Y,并采用基于加权皮尔逊距离的改进CFSFDP 算法进行聚类,聚类准确率达到了98.64%,要高于以皮尔逊距离和欧氏距离作为相似性度量函数的聚类准确率98.45%和97.67%,也要高于以K均值和CFSFDP 为聚类方法的聚类准确率95.14%和98.25%。
综上所述,在聚类相似性度量函数上,聚类方法采用K均值算法、CFSFDP 算法或是改进的CFSFDP 算法,均是采用加权皮尔逊距离作为相似性度量函数时的聚类准确率最高;在聚类方法上,无论相似性度量函数为欧氏距离、皮尔逊距离还是加权皮尔逊距离,均是采用本文提出的改进CFSFDP算法时的聚类准确率最高。
5 结语
本文针对居民用电分析特征优选的有效性和互补性问题,提出了基于信息量的BIC 和相关系数特征优选策略的聚类方法。该方法采用基于信息量的BIC 和相关系数进行聚类特征优选,并使用改进的密度峰值算法实现了居民用电行为聚类分析。通过实际数据分析表明,采用本文优选特征子集进行聚类分析可以有效提高聚类准确率,减少计算量和聚类时间。同时在特征优选的基础上,采用本文提出的改进密度峰值法聚类对居民用电行为进行模式识别具有更高的准确性。
在本文的研究中,聚类分析结果对下一阶段居民用电预测的效果并未得到验证。在后续的工作中,可以根据居民用电行为的具体分类结果开展居民用电负荷预测的研究,为用电管理提供参考依据。
附录见本刊网络版(http://www.aeps-info.com/aeps/ch/index.aspx),扫英文摘要后二维码可以阅读网络全文。
