基于窗口内投影的闭合高效用模式挖掘
2022-03-21李慕航陈志强武红鑫张喜龙
李慕航,韩 萌,陈志强,武红鑫,张喜龙
(北方民族大学 计算机科学与工程学院,银川 750021)
高效用模式挖掘(HUIM)已成为数据挖掘领域中一个重要的研究主题。给定一个事务数据库,HUIM的目标是在事务数据库中找出具有高效用(高利润)的项集(HUIs)[1].HUIM通过综合考虑内部效用(购买数量)以及外部效用(利润),解决了传统频繁模式挖掘(FIM)只考虑了模式出现的频率而无法找出利润较高的模式的限制。传统HUIM的一个主要缺陷是会产生大量冗余的高效用项集。对用户来说,分析这些算法的输出会消耗大量时间。同时,算法产生这些冗余项集会消耗大量的运行时间以及内存空间[2]。为了解决该问题,提出了闭合高效用项集(CHUIs)[3],CHUIs能够比HUIs的数量小几个数量级,并且能够从CHUIs中恢复HUIs的全集,所以CHUIs是HUIs的精简且无损的表示方法[2]。已有很多算法[2-5]被提出在事务数据库中高效地挖掘CHUIs.
近年来,在数据流环境中挖掘高效用项集引发了越来越多的关注。数据流具有持续且无边界的特性,其产生来自于多种场景,例如:网络点击流、传感器网络、电信网络等。由于内存和时间限制,无法存储和处理整个数据流,因此数据流中的模式挖掘是一种具有挑战的任务[6]。一些算法[7-9]已被提出在数据流环境中挖掘高效用项集,但这些算法通常会产生大量的冗余项集。为了减小这些无用项集的数量且不丢失重要的信息,程浩东等[10]提出了第一种数据流环境下的闭合高效用模式挖掘算法CHUI_DS.但是由于该算法是一种基于列表的算法,列表的交叉操作会消耗大量的时间,并且新批次到来时算法需要对列表进行更新操作,也会消耗大量时间,导致算法效率不高。
因此,本文通过提出一种更有效的数据流高效用闭合模式挖掘算法EFIM_Closed_DS来解决上述问题。算法将每个滑动窗口都视为一个新的数据库,在每个窗口中使用数据库投影技术以及事务合并技术来减少数据库扫描的代价,在窗口中调用深度优先的搜索算法挖掘闭合高效用项集。算法使用子树效用以及本地效用剪枝低效用项集,采用有效的前向扩展、后向扩展策略在窗口中剪枝非闭合项集,并使用闭包跳跃策略有效地在数据流环境中挖掘闭合高效用项集。本文的贡献如下:
1)提出一种新的基于窗口内投影的候选集生成策略,在每个滑动窗口内部利用数据库投影技术以及事务合并技术减少数据库扫描的代价。
2)提出一种基于窗口内投影技术的数据流闭合高效用模式挖掘算法EFIM_Closed_DS,能够快速且高效地挖掘CHUI的全集。
3)在6种数据集上的大量评估实验显示,提出的算法比之前的CHUI_DS算法在运行时间和内存消耗方面都更加有效。
1 相关工作
1.1 静态数据库高效用闭合模式挖掘算法
HUIM的缺陷在于会产生大量的模式,导致用户需要消耗大量时间分析这些模式。此外,大量的结果集导致HUIM算法会消耗大量时间且占用较多内存空间[3]。而CHUI是HUIM精简且无损的表示方式,CHUIs要比HUIs要小数个数量级且能够在不扫描数据库的情况下恢复HUI的全集[5],所以CHUI算法能够给用户提供精简且无损的信息。
WU et al[2]提出不产生候选项集的闭合高效用项集挖掘算法CHUI-Miner,算法设计了一个EU-List效用列表结构采用分而治之的方法挖掘高效用闭合项集,算法在密集数据集上有着更好的性能。FOURNIER-VIGER et al[4]提出了EFIM_Closed算法,使用高效用数据库投影和高效用事务合并方法减少数据库扫描的代价。采用3个高效的剪枝策略闭合跳跃(closure-jumping)、前向闭合检查(forward closure checking)还有后向闭合检查(backward closure checking),来剪枝非闭合高效用项集。DAM et al[5]提出了CLS-Miner算法,该算法使用效用列表结构来直接计算项集的效用而无需产生候选项集。该算法提出了3种策略:Chain-EUCP策略、LBP策略以及coverage概念,分别用来估计成对的项的效用、剪枝低效用的项集及其扩展和快速发现项集的闭包。该算法还引入了快速预检查策略来快速执行闭包计算及包含性检查,从而高效地发现高效用闭合项集。
1.2 动态数据库高效用模式挖掘
动态数据库例如数据流环境中的数据具有持续且无限的特性。由于受到时间以及内存空间的限制,数据流环境下的HUIM算法无法像静态环境中那样将全部数据保存在内存空间中进行存储及处理[6]。数据流CHUI算法能够适用于现实生活中例如网络点击流、传感器网络以及典型网络等具有实时且数据量较大的环境。
AHMED et al[7]提出了一种两阶段的HUPMS算法在数据流环境中挖掘高效用项集。该算法设计了一种HUS-tree结构保存数据流中的信息。算法利用HUS-tree结构以模式增长的方式挖掘数据流中的高效用项集。DAWAR et al[6]提出的Vert_top-k_DS算法是一种不产生候选项集的一阶段数据流top-k高效用项集挖掘算法。算法设计一种iList列表结构能够对批次进行有效的插入与删除,还提出了一个有效的效用阈值提升策略,通过计算两个窗口之间的共有批次中的top-k项集效用来快速提升阈值。JAYSAWAL et al[8]提出了一种一阶段的算法SOHUPDS在数据流中挖掘高效用项集,设计了一种IUDataListSW结构存储当前滑动窗口中项的效用、上边界以及项在事务中的位置。通过该结构,该算法能够利用之前窗口挖掘的高效用项集更新当前窗口中的高效用项集。
1.3 动态数据库高效用闭合模式挖掘
动态环境下的闭合模式挖掘算法克服了增量以及数据流环境中HUIs结果冗余且较多的缺点,能够适用于现实生活中数据动态变化的环境。
DAM et al[9]提出了IncCHUI算法,是首个在动态数据库中增量挖掘闭合高效用项集的算法。算法引入了一个增量效用列表结构来存储原始数据库和添加的事务中单一项的关键信息。算法使用有效的剪枝策略来剪枝没有更新的项集,从而快速地构建增量效用列表。该算法只需要扫描一次数据库来构建以及更新增量效用列表,使用一个基于哈希表的结构CHT来保存闭合高效用项集。程浩东等[10]提出的CHUI_DS算法是第一种在数据流环境中挖掘高效用闭合模式的算法。该算法基于滑动窗口模型处理数据流,提出一种新的效用列表结构CH-List,该结构能够记录当前窗口中项集的效用信息,并使用一种被称为BRU_table的双重散列表,初始时保存当前窗口中所有批次的事务效用信息,BRU_table以批次Bid为键,值为一个以事务效用Tid为键、剩余效用为值的散列表,该散列表中的项会随着窗口的滑动而更新。BRU_table结构能够方便地更新窗口滑动后CH-List中项的剩余效用。算法提出一种有效的事务重组算法,能够快速计算窗口中效用列表的剩余效用。
2 定义
本节介绍在数据流中挖掘高效用闭合模式的相关定义。设I={I1,I2,…,In}是项的有限集合,其中每个项Ii都与一个正数相关联,被称为外部效用(利润)。一个项集X⊆I是一个项的有限集合。事务Tc⊆I,其中c是事务Tc的唯一标识符,称为Tc的Tid.在事务中每个项Ii∈Tc都与一个正数q(Ii,Tc)相关联,称为Tc中项Ii的内部效用(数量)。数据流DS={T1,T2,…,Tm}是由事务组成的有限序列,s(1≤s≤m)代表第s个到达的事务。
在基于滑动窗口的数据流挖掘算法中,每个窗口Wk={Bi,Bi+1,…,Bv}由固定数量的批次组成,Wk的窗口大小(win_size)为v.每个批次Bl={T1,T2,…,Tz}由固定数量的事务组成,Bl的批次大小(batch_size)为z.
图1是一个数据流的示例,表1为图1的数据流示例中所有项的外部效用(利润)。图1中每一行代表一个事务,并在右侧列出了每个事务的事务效用Tu.示例中包含3个批次{B1,B2,B3},每个批次包含3个事务,数据流中有两个窗口{W1,W2},每个窗口包含两个批次。

图1 数据流示例Fig.1 Example of data stream

表1 外部效用表(利润)Table 1 External utility(Profit)
定义1 项的效用。事务Tc中项Ii的效用被表示为u(Ii,Tc),被定义为p(Ii)×q(Ii,Tc).在一个批次Bj中,u(Ii,Bj)=∑Tc∈Bju(Ii,Tc).在窗口Wk中,u(Ii,Wk)=∑Bj∈Wku(Ii,Bj).例如,u(a,T1)=1×5=5;u(a,B1)=u(a,T1)+u(a,T2)+u(a,T3)=5+15+0=20;u(a,W1)=u(a,B1)+u(a,B2)=20+10=30.
定义2 项集的效用。事务Tc中k项集X={I1,I2,…,Ik}的效用被表示为u(X,Tc),被定义为∑Ii∈Xu(Ii,Tc).在一个批次中,u(X,Bj)=∑X∈Tcu(X,Tc).在窗口Wk中,u(X,Wk)=∑Bj∈Wku(X,Bj).例如,u(ac,T1)=u(a,T1)+u(c,T1)=5+4=9;u(ac,B1)=u(ac,T1)+u(ac,T2)=9+19=28;u(ac,W1)=u(ac,B1)+u(ac,B2)=28+22=50.
定义3 事务效用。事务Tc的效用被表示为Tu(Tc),被定义为∑Ii∈Tcu(Ii,Tc).例如,Tu(T1)=u(a,T1)+u(c,T1)+u(d,T1)=11.
定义4 闭合项集。如果窗口Wk中不存在一个项集Y⊃X,且sup(X)=sup(Y),则项集X在窗口Wk中是一个闭合项集。
定义5 高效用项集。在窗口中,如果一个项集X的效用大于用于定义的最小效用阈值minutil,则X是一个高效用项集,即:u(X,Wk)≥minutil.
定义6 闭合高效用项集。如果项集X在窗口Wk中是一个闭合项集,且满足u(X,Wk)≥minutil,则该项集是一个闭合高效用项集(CHUI).
定义7 事务加权效用(UTW)。项集X的UTW是为当前窗口Wk中所有包含项集X的事务的效用之和,被表示为UTW,Wk(X),定义为∑X∈Tc∧Tc∈WkUT(Tc).例如,UTW,W1(cd)=UT(T1)+UT(T2)+UT(T5)=67.
属性1 事务加权向下闭包属性。对于窗口Wk中的一个项集X,如果UTW,Wk(X)≤minutil,则项集X以及它的所有超集都是低效用项集。
定义8 子树效用(sub-tree utility,us)[4]。设有一个项集α以及一个项z∈E(α).z关于项集α的子树效用us(α,z)=∑T∈g(α∪{z})[u(α,T)+u(z,T)+∑i∈T∧i∈E(α∪{z} )u(i,T)].
属性2 利用子树效用剪枝[4]。设有一个项集以及一个项z∈E(α).若us(α,z) 定义9 本地效用(local utility,ul)[4]。设有一个项集α以及一个项z∈E(α).z关于项集α的本地效用UL(α,z)=∑T∈g(α∪{z})[u(α,T)+re(α,T)]. 属性3 利用本地效用剪枝[4]。设有一个项集以及一个项z∈E(α).若ul(α,z) 定义10 投影窗口。一个事务关于一个项集α的投影被表示为α-T,被定义为α-T={Ii|Ii∈T∧Ii∈E(α)}[4].窗口Wk关于项集α的投影被表示为α-Wk,被定义为α-Wk={α-T|T∈Wk∧α-T≠Ø}. 定义11 前向扩展与后向扩展(Forward/backward extensions)[4].设项集β=α∪{i}.如果存在一个项z>i且满足z∈E(β),sup(β∪{z})=sup(β),则称项集β有前向扩展。如果存在一个项z 属性4 识别非闭合项集[4]。如果一个项集β=α∪{i}不存在前向扩展以及后向扩展,且最小效用阈值大于minutil,则β是一个闭合高效用项集(CHUI). 属性5 闭包跳跃(closure jumping)[4]。设有项集β以及一个投影窗口β-W.如果对于所有的z∈E(β),满足sup(β)=sup(β∪{z}),则项集β∪E(β)是β的子树中唯一的闭合项集。 本节提出一种新的基于窗口内投影的数据流闭合高效用模式挖掘算法EFIM_Closed_DS.算法在滑动窗口内采用窗口内投影技术以及事务合并技术来减小数据库扫描的代价。 根据定义10,随着算法的执行,在窗口中探索的项集越大,在窗口中对该项集进行投影产生的投影数据库就越小,所以窗口内的投影技术能够大量减少窗口中对数据进行扫描的消耗。 例如,在图1的数据流示例中,以窗口W1为例。设有项集α,对项集α在窗口W1中进行投影,得到投影窗口α-W1,如图2所示,当在搜索与α相关的项集时,仅需要搜索α-W1,并不断进行投影,所以窗口内投影技术可以极大地减小搜索项集时扫描数据库的代价。 P-TidProjected transactionP-UTα-T1(c,1)(d,1)6α-T2(b,2)(c,1)(d,7)(d,1)(f,3)28α-T6(c,3)(e,1)(f,3)18 本节描述整个算法的运行过程。首先,如果批次中的事务数没有达到用户设定的批次大小,则读入一个事务,并将其添加到当前批次中,否则将当前批次添加到窗口中。如果当前批次数没有满足用户设定的窗口大小,则将当前批次添加到当前窗口中,否则开始挖掘当前窗口中的CHUI.具体如算法1所示。 算法1:EFIM_Closed_DS算法 输入:数据流 DS,最小效用阈值 minutil,窗口大小win_size,批次大小batch_size. 输出:数据流中所有满足阈值的闭合高效用项集。 while transaction in stream do transaction_number++; if(transaction_number≤batch_size) batch.add(tranction); if(tranction_number=batch_size) batch_number++; window.add(batch); if(batch_number==win_size) prepare_mining(window,minutil); window.remove(0);/删除旧批次 end if end if end while 在挖掘过程中,将项集α设置为空集。算法扫描整个窗口来计算窗口中所有项的UTW.然后通过比较每个项的本地效用(local utility)(当前与UTW相同)与minutil,找出Secondary(α).然后将这些项按照UTW升序排序。然后扫描窗口一次,删除所有不属于Secondary(α)的项。如果事务为空,则从窗口中删除。然后扫描窗口一次将窗口中的事务按照≻T顺序排序,以便进行事务合并。随后,扫描窗口一次来计算Secondary(α)中项的子树效用(sub-tree utility)。最后算法调用mining_process来递归地挖掘CHUI.如算法2所示。 算法2:prepare_mining 输入:窗口Window,最小效用阈值minutil. 输出:当前窗口中的闭合高效用项集。 α=Ø; Calculate lu(α,i)for all itemi∈Iby scanning Window,using a utility-bin array; Secondary(α)={i|i∈I∧ul(α,i)≥minutil}; let ≻ be the total order ofUTWascending values on Secondary(α); Scan Window to remove each item ∉ Secondary(α)from the transaction,and delete empty transactions; Sort transactions in Window according to ≻T; Calculate the sub-tree utility su(α,i)of each itemi∈ Secondary(α)by scanning Window,using a utility-bin array; Primary(α)={i|i∈Secondary(α)∧ul(α,i)≥minutil}; Search(α,Window,Primary(α),Secondary(α),minutil); Mining_process算法将项集α,α的投影数据库,α的primary(α)以及secondary(α)项与最小效用阈值minutil作为输入参数。算法首先遍历所有能够用于扩展α的项i∈Primary(α),来构建α的扩展β=α∪{i}.对于每个项集β,通过扫描α的投影数据库来计算β的效用,同时构建β的投影数据库。如果β有后向扩展,则不必探索β的扩展。否则,扫描β的投影数据库来计算β的支持度、子树和本地效用。如果β的支持度等于β的扩展的支持度,并且该扩展是高效用项集,则使用闭包跳跃策略直接输出该闭合项集。否则递归调用Mining_process算法来深度优先搜索β的扩展。根据定理3,如果不存在β的扩展具有与β相同的支持度,并且β的效用不小于minutil,则β是一个CHUI,并输出。如算法3所示。 算法3:Search 输入:α一个项集,α-Windowα在窗口中的投影数据库,Primary(α)α的primary项,Secondary(α)α的Secondary项,minutil最小效用阈值。 输出:α的扩展的高效用项集 foreach itemi∈ Primary(α)do β=α∪{i}; Scanα-Window to calculateu(β)and creatβ-Window;∥with transaction merging ifβhas no backward extension then calculate sup(β,z),us(β,z),UL(β,z)for all itemz∈Secondary(α)by scanningβ-Window once using three utility-bin arrays; if sup(β)=sup(β∪{z})∀z≻i∧z∈E(α)then outputβ∪U(z≻i∧z∈E(α)){z}/闭包跳跃 else Primary(β)={z│z∈Secondary(α)∧us(β,z)≥minutil}; Secondary(β)={z│z∈Secondary(α)∧ul(β,z)≥minutil}; Search(β,β-Window,Primary(β),Secondary(β),minutil); ifβhas no forward extension andu(β)≥minutil then outputβ; end if end if end for 本小节对所提出的算法给出一个详细的实例来描述算法的具体运行过程。将图1中的数据流作为一个实例,设置最小效用阈值minutil为50.如图1中所示,批次大小batch_size为3(3个事务),窗口大小win_size为2(2个批次)。 以数据流示例中第一个窗口为例,窗口中事务数量为win_size×batch_size=2×3=6.算法首先扫描整个窗口计算窗口中的本地效用以及子树效用,按照定义8以及定义9,本地效用以及子树效用如表2-3所示。设置算法按照字典顺序对项进行排序,当前α=Ø,Secondary(α)={a,b,c,d,e,f},Primary(α)={a,b,c}.算法扫描数据库删除所有不满足子树效用的项,然后对相同的事务进行合并。随后算法开始搜索,根据算法3,对于Primary(α)中的每一项,扫描窗口计算项集β=α∪{i}的效用并执行对窗口的投影。由于当前α=Ø所以分别计算Primary(α)中a,b,c三项的效用,并执行对窗口的投影,以a为例。根据定义10,对窗口W1投影的结果窗口α—W1如图2所示。通过扫描窗口,项a的效用为30,且根据定义11,项a不存在后向扩展(按照字母顺序项a是第一项),所以继续执行进一步的深度搜索。此时,在投影窗口α—W1中,项a的Secondary(α)={c},Primary(α)={c}.所以β=α∪c=αc,通过扫描投影窗口α—W1,计算得项集αc的效用为28,创建αc的投影窗口αc—W1,项集αc没有前向扩展以及后向扩展,即:αc为闭合项集,但由于效用小于minutil,所以项集αc不是闭合高效用模式。算法结束项a的深度搜索,转而以同样的方式分别执行项b,c的深度搜索过程,最终完成对窗口W1中所有闭合高效用项集的搜索,然后加入新的批次,窗口滑动,执行新窗口内的搜索过程。 表2 本地效用表Table 2 Local utility table 表3 子树效用表Table 3 Subtree utility table 本节进行了大量的对比实验以评估提出的算法的效率。实验将提出的算法与之前较为先进的闭合高效用模式挖掘算法EFIM_Closed、CHUI_Miner、CLS_Miner以及CHUI_DS算法进行对比。主要从以下几方面评估算法的性能:1)变化最小效用阈值;2)变化窗口大小;3)变化批次大小。所有对比试验均在SPMF中使用JAVA语言实现。实验中使用了6种HUIM中通常使用的基准数据集来进行对比实验,包括3种密集数据集以及3种稀疏数据集,数据集的特性在表4中给出。 表4 实验数据集Table 4 Datasets 本小节通过逐渐减小最小效用阈值来比较提出的算法EFIM_Closed_DS与之前的EFIM_Closed、CHUI_Miner、CLS_Miner以及CHUI_DS算法在运行时间方面的性能。实验分别在数据流环境以及静态环境下进行对比试验。其中,在静态数据集上与其他4种闭合高效用模式挖掘算法EFIM_Closed、CHUI_Miner、CLS_Miner、CHUI_DS算法对比时,提出的算法与CHUI_DS算法采用单窗口处理方式运行(即:将数据集中所有事务输入一个窗口),以评估静态环境下二者与其他静态闭合模式挖掘算法的性能。在数据流环境下,控制窗口大小以及批次大小,比较算法的运行时间。 在静态环境下,随着最小效用阈值的增大,算法产生的结果集逐渐减少,5种对比算法的运行时间逐渐减小。在图3中,除Chainstore以及Retail数据集上,提出的算法与EFIM_Closed算法均具有最好的性能,消耗了最少的运行时间。提出的算法与EFIM_Closed使用了有效的子树效用与本地效用能够剪枝大量的搜索空间,提出的高效用事务合并技术通过合并相同的事务大量减少了数据库扫描的消耗。此外使用的前向、后向扩展技术相较CHUI_Miner、CLS_Miner、CHUI_DS使用的闭包计算策略以及包含性检查操作能够更快地计算闭合项集。在Chainstore和Retail数据集两个稀疏数据集中,提出的算法与对比算法在最小效用阈值较大时,运行时间较为接近,但算法在最小效用阈值较小时,CLS_Miner算法消耗了最少的运行时间,该算法所使用的基于EUCS结构的Chain_EUCP策略、LBP策略以及coverage概念有效地提升了CHUI_Miner算法的效率,且在稀疏数据集上也相当有效[5]。由于提出的算法与EFIM_Closed算法在递归过程中执行了过多的数据库投影,因此消耗了大量的时间。实验结果显示,提出的算法基于EFIM_Closed算法增加基于数据流环境做出的改进并未影响算法的性能,在静态数据环境下同样具有较好的性能。同时,由于密集数据集更容易在投影过程中产生相同的投影事务,而提出的算法所使用的事务合并以及闭包跳跃技术能够更为有效地减少投影事务,从而在密集数据集上具有比稀疏数据集更好的性能。 图3 静态数据库中比较不同最小效用阈值情况下算法运行时间Fig.3 Runtime comparison among various utility thresholds 在数据流环境下,实验对提出的算法以及CHUI_DS算法在Retail以及Foodmart两个数据集上进行对比。在Retail数据集上设置窗口大小为10,批次大小为1 000,Foodmart数据集上窗口大小设置为10,批次大小为100.最小效用阈值变化范围均从10 000到500.如图4所示,运行时间方面,随着最小效用阈值的减小,算法产生的闭合高效用模式数量不断增加,所耗费的时间也随之增加。通过对比实验可以看出,所提出的算法在Retail数据集上的运行时间比CHUI_DS最高要快7倍左右,在Foodmart数据集上的运行时间最高要快10倍左右。实验结果显示,提出的EFIM_Closed_DS算法与CHUI_DS算法虽均基于滑动窗口技术,但提出的算法所使用的窗口内投影技术比基于效用列表的CHUI_DS算法的公共批次重组技术和改进的闭包挖掘技术更为高效。 图4 数据流环境下比较不同最小效用阈值情况下算法运行时间Fig.4 Runtime comparison among various utility thresholds 由于CHUI_DS算法和EFIM_Closed_DS算法均基于滑动窗口模型,均有两个参数:1)窗口的大小;2)批次大小。本节分别控制算法所使用的窗口大小与批次大小进行对比实验。采用密集数据集Accidents和稀疏数据集Chainstore进行实验。设定Accidents数据集的最小效用阈值为1.5×107,设定Chainstore数据集的最小效用阈值为9.5×107. 首先,固定实验中每个事务的批次大小,调节窗口大小对比两个算法的运行时间。固定数据集Accidents批次大小为3×104,固定数据集Chainstore批次大小为1×105.在Accidents数据集上控制窗口大小从1到4,Chainstore数据集上窗口大小从4到10进行对比,实验结果如图5所示。在固定批次大小的情况下,提出的EFIM_Closed_DS算法在两个数据集上的运行时间均快于CHUI_DS算法。在两个数据集上两个算法随着窗口大小的增大,差距越来越大。在Accidents数据集上,提出的算法的运行时间最高比对比算法要快300倍左右。在Chainstore数据集上,最高要快130倍左右。 图5 不同窗口大小下运行时间对比Fig.5 Runtime comparison among various window sizes 其次,算法固定窗口大小为2,比较批次大小不同时的总运行时间。控制算法在Accidents数据集上批次大小从4×104到8×104,在Chainstore数据集上控制批次大小从10×104到20×104.实验结果如图6所示,随着批次大小的增加,每个窗口中算法需要处理的数据量不断增大,运行时间不断增加。提出的EFIM_Closed_DS算法在两个数据集上运行时间均优于CHUI_DS算法,且随着批次大小的增加,二者的差距也逐渐增大。 图6 不同批次大小下运行时间对比Fig.6 Runtime comparison among various batch sizes 通过控制窗口大小与批次大小,实验结果可以看出,提出的算法随着处理的数据量的增大,与对比算法之间的差距不断增大,提出的算法比对比算法在数据流环境中运行更为有效,是更高效的一种基于滑动窗口的算法。算法在密集数据集(Accidents)上更加有效,与对比算法之间的差距更大,且随着处理的数据量增大,差距成线性增加。在两种数据集上,随着数据量的增大,提出的算法运行时间曲线相对较为平缓,运行时间变化不大。 在数据流环境下,控制窗口大小以及批次大小,对比提出的算法与CHUI_DS算法在不同最小效用阈值情况下的内存占用大小。实验中,控制窗口大小为10,控制批次大小为100,变化最小效用阈值从10 000到500.如图7所示,内存占用方面,随着最小效用阈值的减小,算法需要占用更大的内存空间来处理候选项集。在大部分情况下,提出的算法EFIM_Closed_DS的内存消耗更小,最好的情况下内存占用比CHUI_DS小11倍。CHUI_DS算法改进自CHUI_Miner算法,是一种一阶段基于效用列表的算法,该算法的缺点在于需要构建搜索空间中所有项集的效用列表,会占用大量内存空间,且构建效用列表的交叉操作也会消耗大量时间[5]。这导致了实验结果中CHUI_DS算法内存占用较高,且随着最小效用阈值的减小,会产生更多的候选项集,使得CHUI_DS算法所占用的内存空间逐渐增多。 图7 不同最小效用阈值情况下内存占用对比Fig.7 Memory used comparison among various utility thresholds CHUI_DS算法是一种基于效用列表结构的算法,算法需要执行大量的列表交叉操作,会耗费大量时间,并且算法需要将项的列表结构保存在内存当中,会占用大量内存空间。同时,CHUI_DS算法在新批次到来时,需要进行公共批次事务重组来对之前窗口构建的效用列表进行更新,同样消耗了大量时间。CHUI_DS算法基于批次更新,无法通过UTW剪枝技术删除窗口中无希望的项,导致搜索过程中浪费更多的时间。EFIM_Closed_DS算法基于窗口内投影技术能够减少数据库扫描的代价,在每个窗口中使用UTW剪枝技术删除无希望的项也能够大量减小搜索范围,通过子树效用以及本地效用的剪枝技术能剪枝大量的无希望项集。在静态数据环境下的对比实验结果显示,提出的算法性能并未因改进到数据流环境而受到影响,与EFIM_Closed性能相比差异不大,比多数静态环境下的闭合模式挖掘算法性能优异,尤其在密集数据集上比之前较先进的CLS_Miner算法的最佳性能提升了1倍到50倍。在数据流环境下,提出的算法运行时间比对比算法最好能够提升300倍且在实验设置条件下差异呈线性增加,提出的算法内存占用比对比算法最好要小11倍。因此,提出的算法在运行时间和内存占用方面比CHUI_DS都更加有效。 本文提出了一种新的基于窗口内投影的数据流闭合高效用模式挖掘算法EFIM_Closed_DS.算法使用数据库投影以及事务合并两种技术有效地减少了数据库扫描的代价。通过前向闭包检查、后向闭包检查以及闭包跳跃3种策略探索闭合的高效用项集。通过在窗口中利用本地效用以及子树效用剪枝技术,有效地减少了搜索空间。在6种不同数据集上的大量实验结果证明算法比之前的CHUI_DS算法在时间以及内存方面效果有显著的提高。3 EFIM_Closed_DS算法
3.1 窗口内投影技术

3.2 EFIM_Closed_DS
3.3 算法实例


4 实验

4.1 最小效用阈值对实验的影响


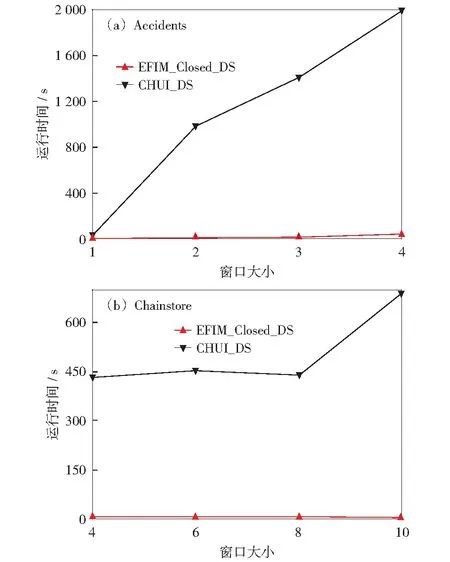
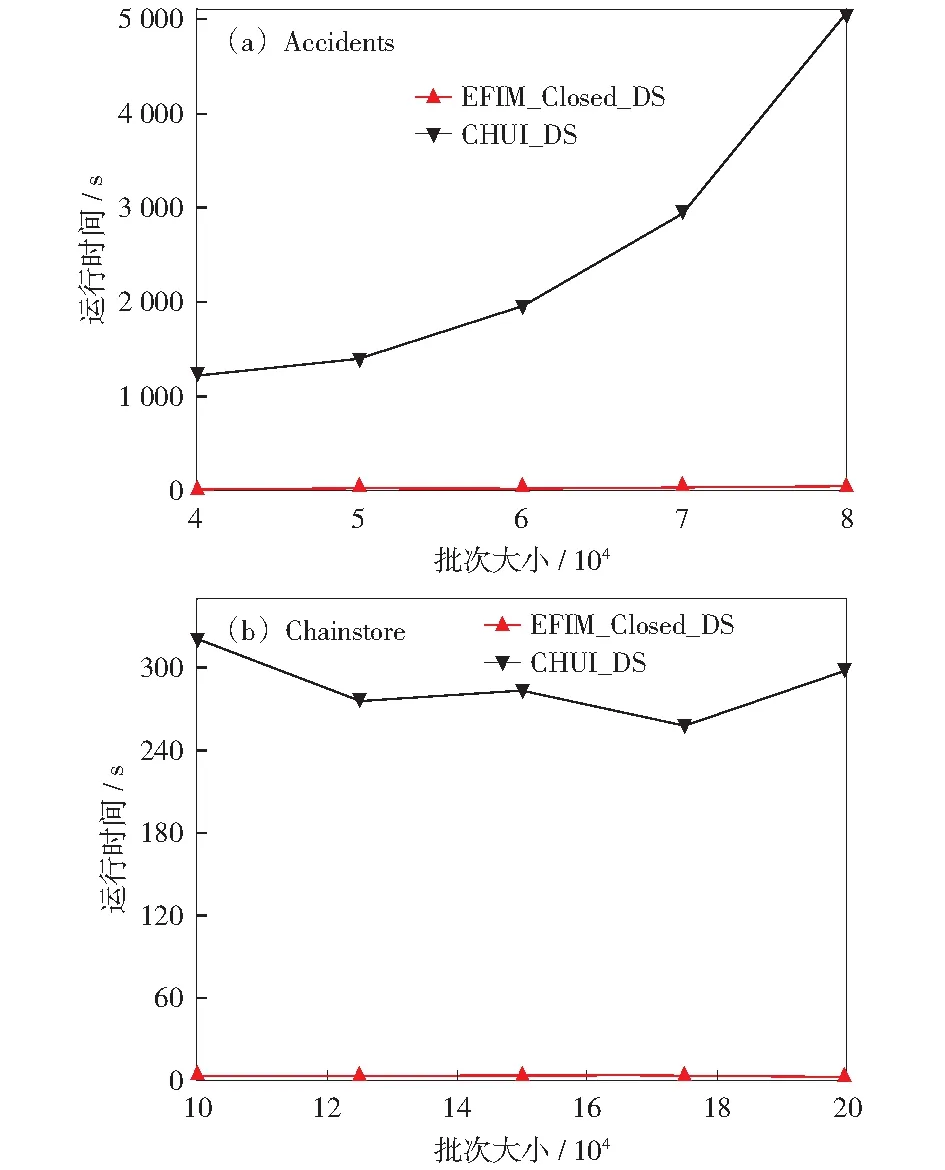
4.2 不同窗口大小与批次大小下的对比
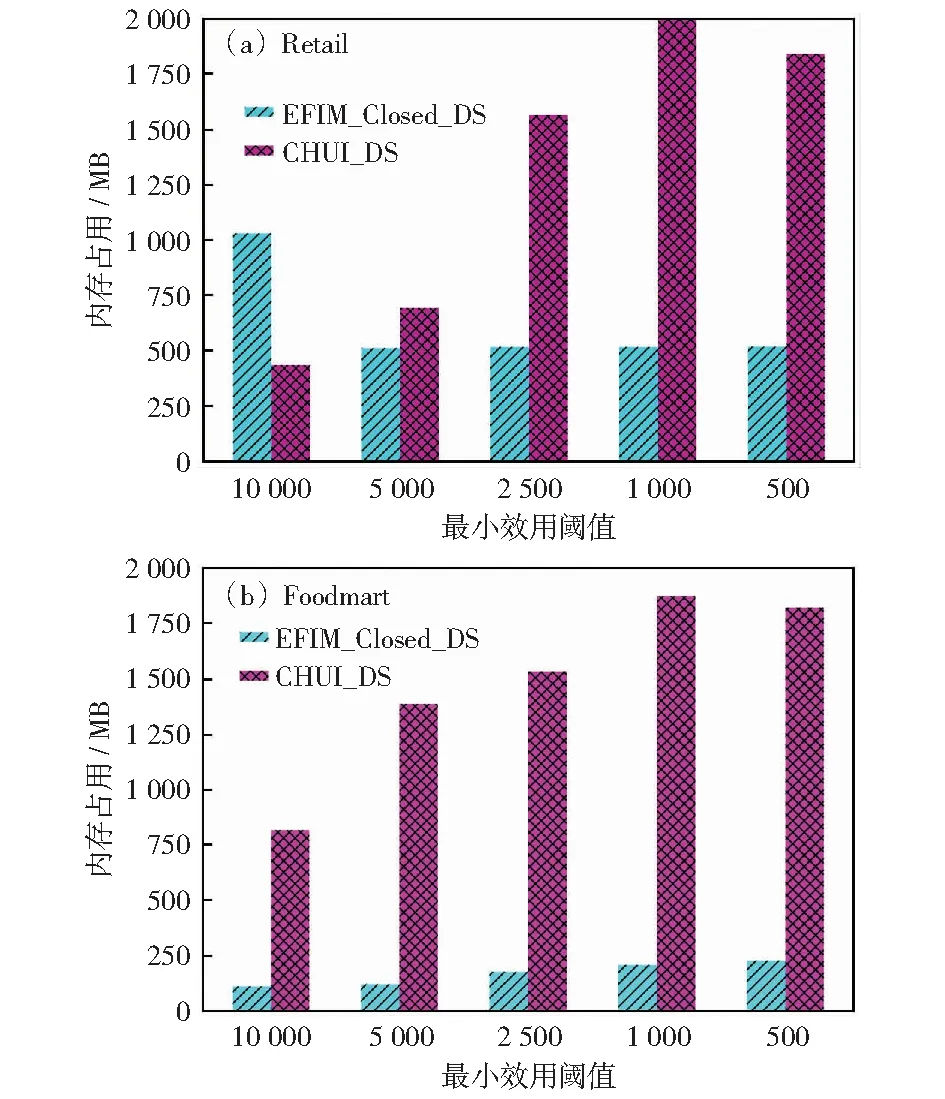
4.3 不同最小效用阈值下算法使用内存大小对比
4.4 实验结论
5 结束语
