基于截断历史注意力的商品评论属性词抽取框架
2022-03-21张顺香朱广丽张镇江孙争艳
张顺香,赵 彤,朱广丽,张镇江,孙争艳
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
商品评论不仅为用户的购买决策提供了参考,商家同样通过对商品评论进行细粒度的情感分析得到用户对商品不同属性(例如:材质、价格、颜色等)的情感倾向[1-2],从而调整商品的制作工艺、销售策略等,以此获取更大的商业利润。从商品评论中抽取属性词是后续针对属性词所属方面进行细粒度情感分析的必要步骤。但由于商品评论具有基数大、表达口语化等特点,故为商品属性词的完整抽取带来了一定的挑战,使其成为当前的研究热点之一。
属性词分为显式属性词和隐式属性词,例如:“颜色好看!”中“颜色”是显式属性词,“有点小贵!”中隐藏了“价格”这个隐式属性词,现有的主流属性词抽取方法是2016年提出的BiLSTM-CRF模型[3],该模型通过BiLSTM(bidirectional short and long term memory network,BiLSTM)自动学习上下文语义信息,一定程度上克服了对人工选取特征的依赖,并通过CRF(conditional random field)计算输出标签序列的全局概率,提高了显式属性词抽取的准确率,但是该模型无法抽取隐式属性词,导致了属性词抽取的不完整。为了解决该问题,属性词的抽取方法有待深入研究。一种完整的属性词抽取方法应该考虑以下两个方面:1)如何有效地挖掘单词间的隐式关系,抽取评论中的隐式属性词;2)如何同时抽取显式、隐式属性词,使属性词抽取过程更加高效。
基于上述两个问题,本文提出了一种基于截断历史注意力机制(truncated history-attention,THA)[4]的商品评论属性词抽取框架,如图1所示。该框架在对商品评论语料进行预处理后,通过BiLSTM-CRF模型抽取评论文本中的显式属性词,引入截断历史注意力机制,建立包含属性词和词间映射关系的词库,获取单词间的隐式关系,抽取评论中的隐式属性词。框架主要包括以下3部分:

图1 THA-BiLSTM-CRF框架图Fig.1 THA-BiLSTM-CRF frame diagram
1)商品评论语料预处理。首先对商品评论语料进行清洗,去除重复、空值和与商品评论无关的语句,然后使用哈工大信息检索实验室开发的LTP工具对商品评论进行分词、词性标注和实体标注,最后通过word2vec中的CBOW模型,将单词转化成包含语义信息的词向量。
2)基于BiLSTM-CRF模型抽取显式属性词。将预处理后的词向量传入BiLSTM层获取文本特征的前向向量和后向向量,拼接后作为当前单词的隐藏状态向量,通过CRF进行解码,计算出序列文本每个单词的标签得分,得分最高的标签序列为显式属性词。
3)基于THA模型抽取隐式属性词。将预处理后的词向量传入截断历史注意力机制(THA)模型,将每个时间步得到的摘要输入到注意力机制中,建立包含属性词和词间映射关系的词库,获取单词间的隐式关系,通过注意力机制抽取隐式属性词。
本文研究工作的主要贡献可概括为以下两点:
1)在BiLSTM-CRF模型基础上引入截断历史注意力机制(THA),有效挖掘了商品评论中的隐式属性词。
2)使用BiLSTM-CRF模型抽取显式属性词,为后续挖掘评论文本词间隐式关系提供显式属性词词库,此种设计可以共享数据,同时抽取显式和隐式属性词,使属性词的抽取工作更加高效。
1 相关工作
属性词抽取是命名实体识别的三大子任务之一,现主要使用的抽取方法是基于统计概率和基于神经网络的方法。基于统计概率的方法是通过分类统计模型将属性词抽取问题转化为一个分类问题进行求解。基于神经网络的方法在统计概率模型的基础上通过自学习样本特征,在不需要提供大量的特征工程的情况下训练抽取模型。
1.1 基于统计概率的方法
在基于统计概率方法的属性词抽取任务中,隐马尔可夫模型(hidden markov model,HMM)[5]和条件随机场[6]是最常用的两种模型。1991年BIKEL et al[7]首次提出将隐马尔可夫模型用于命名实体识别任务中,通过马尔可夫链生成状态序列和与其对应的观测序列,使用联合概率模型训练参数,得出联合似然最大值。LIU et al[8]通过最大熵模型构造了属性词与标签之间的映射关系,利用HMM进行属性词的命名实体识别。CRF在HMM的基础上进行了改进,不再要求独立性假设,支持了丰富的语言特征。MCCALLUM et al[9]在CONLL-2003测评中将CRF用于命名实体识别,获得了良好的效果。JAKOB et al[10]首次将CRF用于商品评论中商品属性词的抽取任务,证明了基于CRF的抽取方法在商品评论领域的可行性。在属性词抽取任务中,虽然基于统计概率的传统机器学习方法取得了较好的性能,但由于机器学习的方法需要对数据集进行人工特征的选择与处理,所以耗费了大量的人力和时间成本。
1.2 基于深度学习的方法
随着近年来以神经网络为核心的深度学习理论快速发展,使用深度学习去解决属性词抽取问题成为目前的一种趋势。在属性词抽取任务中,常用的神经网络有循环神经网络(recurrent neural network,RNN)[11]和长短期记忆网络(short and long term memory network,LSTM)[12]。2003年,BENGIO et al[13]在论文中首次将深度学习的思想融入到语言模型中。但由于文本数据中各个字词之间相互关联,单向结构的神经网络模型并不适用于属性词抽取,而RNN存在梯度消失问题,因此又引入了LSTM模型。LSTM则通过引入“门”来控制信息的累计速度,有选择地增加和遗忘信息,更加适合处理命名实体识别问题[14]。LAMPLE et al[15]使用的LSTM-CRF模型在英文命名实体识别中获得良好的效果。2017年,TAN et al[16]首次将自注意力机制应用在序列标注问题中。在不同的领域中,PENG et al[17]利用词向量提升社交领域中命名实体识别的性能,ZENG et al[18]将LSTM-CRF 模型应用在医药实体名的识别任务中,CAO et al[19]利用对抗迁移学习和自注意力机制对微博文本进行命名实体识别,CHEN et al[20]提出一种半监督的深度学习框架系统对政府文件中的实体信息进行识别。而在商品评论领域,LIU et al[21]利用循环图和开关递归神经网络模型对属性词进行识别。
综上,在属性词抽取任务中,基于统计概率的方法需要满足一定规模的特征工程,会耗费大量的人工和时间成本,而基于深度学习的抽取方法通过自学习样本特征,无需过多的人工特征,更具有研究价值。因此,本文在BiLSTM-CRF模型的基础上加入截断历史注意力机制(THA)用于隐式属性词抽取的研究,进一步提高属性词抽取的完整度。
2 基于BiLSTM-CRF的显式属性词抽取
2.1 文本预处理
原始的商品评论文本中含有许多空值、与商品评论无关和重复的语句等噪声,首先对语料库中的文本进行数据清洗;然后使用哈工大信息检索实验室开发的LTP工具对处理后文本进行分词、词性标注等预处理,例如,“衬衫颜色很好看,喜欢!”标注结果为“衬衫/n 颜色/n 很/d 好看/a,/wp喜欢/v !/wp”;最后利用BIO标签进行命名实体的词库标注。在属性词抽取任务中BIO标签输入一个单词序列X={x1,x2,…,xT},输出预测方面标签序列Y={y1,y2,…,yT},其中每个yi来自一个有限的标签集Y={B,I,O},它描述了可能的方面标签,B、I和O分别表示相位跨度的开始、内部和外部。


图2 文本向量化过程Fig.2 Text vectorization process
2.2 BiLSTM-CRF模型介绍
BiLSTM-CRF模型结合了长短时记忆网络(LSTM)和条件随机场算法(CRF),主要用于解决命名实体识别的有效性问题,是现有的主流显式属性词抽取模型,其模型框架如图3所示。

图3 BiLSTM-CRF模型Fig.3 BiLSTM-CRF model
2.2.1BiLSTM层
相比循环神经网络(RNN),长短时记忆网络(LSTM)利用数据中的长期依赖关系,解决了序列训练过程中的梯度消失和梯度爆炸问题。LSTM是一个记忆单元通过输出门、输入门和遗忘门来控制其内部状态的读、写和重置操作,其内部结构如图3中的LSTM模块。
在某一时刻,使用当前输入和前一状态的输出,遗忘门将决定保留哪些信息和丢弃哪些信息,随后更新记忆单元。当输入的文本词向量矩阵为X=[x1,x2,…,xK]时,LSTM的传递过程如式(1)-式(6)所示。
it=σ(Wi·[Ht-1,xt]+bi).
(1)
ft=σ(Wxf·xt+Whf·ht-1+bf).
(2)
ot=σ(Wxo·xt+Who·ht-1+bo).
(3)
zt=tanh(Wxz·xt+Whz·ht-1+bz).
(4)
ct=zt·it+ct-1·ft).
(5)
Ht=tanh(ct)·ot.
(6)
式中:W为权重矩阵;b为偏置向量;σ为sigmoid函数,sigmoid层输出0或1,当输出为0时代表不能通过,1代表能够通过。zt是待增加内容,ct是t时刻的更新状态,it、ft、ot分别是输入门、遗忘门和输出门的输出结果,Ht则是整个LSTM单元t时刻的输出H={h1,…,hi,…,ht}.

(7)
(8)
(9)
式中:wt是t时刻向量层的输出向量,即BiLSTM层t时刻的输入向量;ct-1是t-1时刻记忆细胞的状态;ht-1是t-1时刻LSTM层输出向量;ct是t时刻的记忆细胞状态;ht是t时刻BiLSTM层的输出向量,该层的输出向量序列构成的矩阵记为[h1,…,ht].
2.2.2CRF层
CRF是一种统计建模方法,结合了最大熵模型和隐马尔可夫模型的优点形成了无向图模型,并且可以考虑上下文信息。随机场的主体思想是若干个位置组成的整体,当给每一个位置中按照某种分布随机赋予一个值之后,该全体就叫做随机场。CRF是隐马尔可夫模型的特例,CRF假设隐马尔可夫模型中只有x和y两种变量,其中x一般是给定的,而y是在给定x的条件下模型的输出。当CRF中x和y具有相同的结构,就构成了线性链条件随机场,如图3中的CRF模块。
通过将CRF从训练数据中自动学习得到的标签序列之间的约束条件添加到最终的命名实体标签,保证了预测标签的有效性。CRF层通过引入状态转移矩阵获得实体标签之间的依赖关系,以提高属性词的抽取效果。首先,计算其所有的实体标签序列(y1,…,yi,…,yn)的概率;然后,计算规范化因子Z(X);最后,使用Viterbi算法判断最有可能出现的标签序列,并将其作为属性词抽取结果,其计算过程如公式(10)-(11)所示。
(10)
(11)

2.3 显式属性词抽取过程
BiLSTM-CRF模型中,对于输入的商品评论,经过预处理后将包含语义的词向量传入BiLSTM层,获得句子的前向向量和后向向量;接着将前向向量和后向向量进行拼接作为当前词汇或字符的隐藏状态向量;最后将包含上下文信息的语义向量输入到CRF中进行解码,通过CRF计算出序列文本每个词语或字符的标签,将具有最高得分的标签序列作为模型预测的最好结果,即商品显式属性词输出,具体过程如算法1所示。
算法1 基于BiLSTM-CRF的显式属性词抽取算法。
输入:商品评论词向量S={s1,s2,…,sn},注意力机制层矩阵元素M;
输出:商品显式属性词输出y.
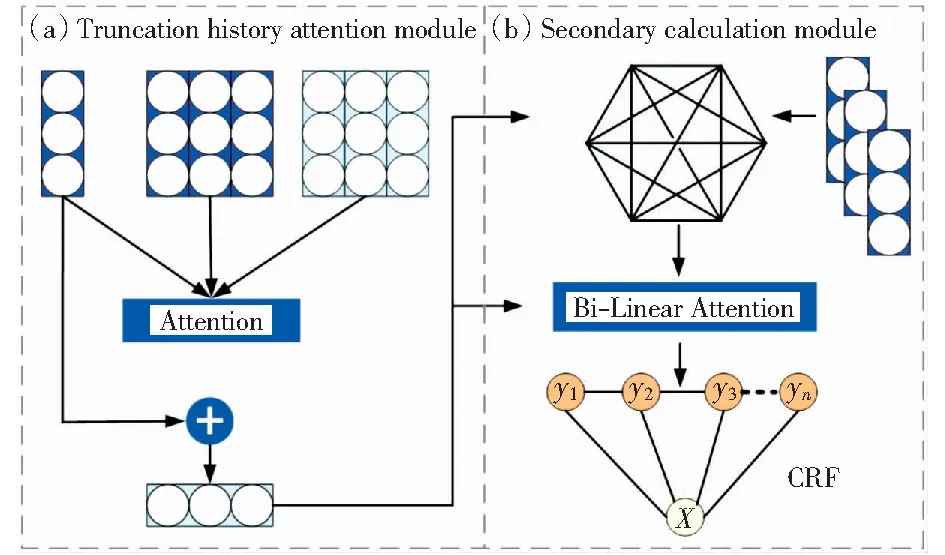
for each epoch until Δ for each batch do BiLSTMCRF.Insert(sentence); CRF.Forward(); CRF.Backward(); UpdateModel(); end for end for T←Gettransferscore(y);/*计算属性转移分数*/ Z←Exceptionsum(T,M);/*计算规范化因子Z(X)*/ PY←Calprobabilityof(y);/*计算标签序列概率*/ y←Viterbi(s);/*计算属性词抽取结果*/ 由于商品评论具有表达口语化的特点,例如“有点小贵!”中“价格”这样的隐式属性词无法通过BiLSTM-CRF等现有模型被有效抽取。针对该问题,本文提出一种基于截断历史注意力机制(truncated history-attention,THA)的隐式属性词抽取方法。THA算法通过挖掘整个商品评论语料库中观点词与属性词的词间隐藏关系,在语料库中抽取单条评论中被隐藏的属性词,即完成隐式属性词的抽取。 THA模型分为两个模块,如图4所示,分别是截断历史注意模块和二次计算模块,分别用于捕获方面检测历史和观点摘要。 图4 THA模型Fig.4 THA Model 截断历史注意模块通过遍历所有评论首先抽取每条评论内所包含的观点词、显式属性词,接着将显式属性词与其对应观点词的关系进行记录(例如,“昂贵—价格”、“好吃—味道”),最后将显式属性词和对应关系一同输入注意力机制模型中,如果发现注意力机制的词库中有匹配当前评论观点词的属性词,则抽取隐式属性词。 在算法上,截断历史注意模块主要由BiLSTM模块处理后的词向量和注意力机制模块组成,如图4(a)所示。由于递归神经网络可以记录上下文的序列信息,故使用LSTM模型来构建和组织向量化的评论语句。具体构建如式(12)所示。t表示当前处理语句的位置指示,st来表示当前处理的语句,使用BiLSTM来产生初始化的状态信息ht. (12) 截断历史注意模块的另一个组成部分是注意力机制模块。注意机制的基本思想是从每一个较低的层次提取一个注意权值,然后将这些权值集合起来,得到较高层次的表示。使用BiLSTM可以记忆预测的整个历史,但是没有办法记忆先前已有的经验和当前经验之间的关系,所以引入注意力模块建模当前时间步和历史时间步的关系,即在注意力模块中存储属性关系。对于每一个预测步骤t,注意力模块会记住每一对单词间的关系,并予以计算相关性,再将得到的相关性使用softmax函数进行处理,其计算过程如式(13)-(14)所示。 (13) (14) 算法2 基于THA的初步隐式属性词抽取算法。 输入:向量化的评论信息S={s1,s2,…,sn}; 输出:每条商品评论的属性词。 S←data_cleaning(S);/*进行数据的预处理,包括去除过短、重复、主题不同的评论*/ VS←word2vec(S);/*向量化评论信息*/ for each sentence inVS [sentence,feature]←BiLSTM(sentence);/*利用BiLSTM对评论进行处理,得到初步的属性词*/ Attention.Insert(feature);/*将属性词写入注意力机制*/ [sentence,feature]← Attention.Deal(sentence); /*利用注意力机制提取特征词,得到评论语句与对应的属性词*/ ST.Insert(sentence,feature); end for 由于词库的建立是动态的,即一边遍历商品评论一边进行词库的建立,所以前后不同时间顺序处理的评论属性词的抽取质量不同。虽然使用BiLSTM模型一定程度上可以弱化此种问题,但还是有大量评论语句的属性词抽取没有达到抽取要求。为解决这个问题,文本通过加入二次计算来进一步完善隐式属性词的抽取。 在截断历史注意模块中,评论语句的属性词和对应关系的抽取是动态的,随着处理过程的进行,抽取的准确性会越来越好,所以最初抽取的隐式属性词和靠后时间抽取的隐式属性词的质量参差不齐。为了提高隐式属性词抽取的整体效果,本文引入了二次计算。 二次计算部分的组成主要包括了全连接层和双线性注意力机制两部分,如图4(b)所示。首先,将原始评论预处理后的词向量与截断历史注意模块抽取出的隐式属性词共同输入到全连接层。在全连接层上,由于在截断历史注意模块中已经将所有显式属性词、词间关系抽取,所以将所有显式属性词作为节点,建立全连接关系。当某个观点词输入全连接层后,在全连接层上进行词间关系挖掘,找到观点词对应的隐式属性词。然后,将全连接层的输出与截断历史注意模块抽取出的隐式属性词再次共同输入到双线性注意力机制中。全连接层通过直接映射的方式,得到更加准确的隐式属性词,但当{观点词,属性词}中存在一对多的情况时(例如,“好看”可能对应的属性词是“颜色”或“样式”)部分词会出现偏差,所以此时需要更高维度的关系挖掘,即双线性注意力机制,它可以构建注意力模型,以挖掘更深层的关系,完成隐式属性词进一步的抽取。基于THA的二次隐式属性词抽取过程如算法3所示。 算法3 基于THA的二次隐式属性词抽取算法。 输入:向量化的评论信息S={s1,s2,…,sn},THA计算后每条评论语句的属性词集合ST; 输出:每条商品评论的属性词. for eachifrom 1 toS.Count Sentence←S[i]; Feature←ST[i].Feature; FCLayer.Insert(feature); Abstract←FCLayer.Deal(sentence,feature); BiLinearAttention.Insert(abstract); end for For eachiform 1 toS.Count Sentence←S[i]; feature←ST[i].Feature; Abstract←BiLinearAttention.Deal(feature);/*将属性词输入双线性注意力机制进行计算*/ Feature←FCLayer.Deal(feature,abstract); SA.Insert(sentence,feature); end for end 综上所述,通过上述两部分基于THA的抽取算法,最终可以实现完整的隐式属性词的抽取。 本文采用京东平台2011年1月1日到2014年3月31日的消费者的部分购买评论作为实验的数据集,该数据集由ChallengeHub提供。数据集主要包含5个表关系,分别是商品编号与商品名的映射、商品类别与类别编号的映射、商品编号与类别编号的映射、商品编号与评论信息的映射,商品评论与属性词的映射。其中,商品编号与商品类别存在着多对多的映射关系,例如商品“鼠标”可同时被分类为“电脑配件”类和“电子产品”类,而“电脑配件”类也可以包含多种商品。 数据集包含了525 620种商品,1 175种类别,71 865条商品评论(数据集中很多商品没有评论),每件商品都拥有关键字标注。本文从原始数据集中选取5 000条高质量评论作为实验数据集。将数据集以随机分配的方式,以70%的数据作为训练集,30%的数据作为测试集。 对于商品评论属性词抽取,本实验将商品的评论信息作为原始输入,将商品的属性词作为标签,通过本文提出的商品评论命名实体识别方法对原始输入进行计算,将得到的预测标签,与真实标签相比较。 采用召回率R、精确率P和F1值来评测模型的性能,各评价指标的计算方法如式(15)-式(17)所示。 (15) (16) (17) 式中:a为识别正确的实体数,A是总实体数,B为识别出来的实体数。 本实验的软硬件环境如表1所示。 表1 训练环境参数配置Table 1 Training environment parameter configuration 本文提出了一种商品评论属性词的抽取框架THA-BiLSTM-CRF.首先,在商品评论信息的基础上进行人工标注,计算本模型对人工标注信息的召回率、准确率以及F1值作为实验的评价指标;然后,对本模型中的重要参数进行提取,使用训练集对模型的参数进行训练;最后,将本文的模型与传统属性词抽取模型进行比较,评测本文提出的属性词抽取模型相对于其他模型的进步性。具体实验步骤如下: 1)实验数据获取。本文实验所需数据集来自电商平台对外提供的商品评论数据。 2)实验数据预处理。结合商品评论的特点,将过短、重复、空值和与商品评论无关的语句进行过滤,并使用哈工大信息检索实验室开发的LTP分词工具进行分词,然后利用CBOW模型将数据集转换成词向量的形式进行存储。 3)抽取显式属性词和其对应的观点词。将预处理后的词向量传入BiLSTM-CRF模型进行处理,得到评论的显式属性词和其对应的观点词,显式属性词和观点词之间的词间关系通过共享内存的方式将数据传给THA模块,在此过程中不断训练BiLSTM-CRF模型中的参数。 4)抽取隐式属性词。THA接收BiLSTM-CRF模型共享的显式属性词和观点词之间的词间关系并处理,得到所有属性词与对应观点词之间的联系,即全联接层,然后遍历所有评论,根据全联接层的信息得到隐式属性词,在此过程中不断训练THA模型中的参数。 5)设计本模型与其他模型的对比实验。比较属性词抽取结果对人工标注的召回率、准确率以及F1值,证明本文所提出的属性词抽取框架的进步性。 4.5.1隐式属性词抽取结果举例 本文提出的模型可以将原本商品评论中不直接出现的属性词同样抽取出,改善了已有的BiLSTM-CRF模型只能抽取显式属性词的局限性,增加属性词抽取的完整度,表2为隐式属性词抽取的示例。 表2 隐式属性词抽取示例Table 2 Implicit attribute word extraction example 4.5.2模型性能对比 为了验证本文所提出模型的有效性,现将模型与BiLSTM-CRF、Attention-BiLSTM-CRF两种主流的属性词抽取模型进行比较实验。由于本文模型考虑了隐式属性词的抽取,因此模型的准确率、召回率和F1值较对比模型都有了明显提高,具体实验结果如表3所示。 表3 模型性能对比Table 3 Model performance comparison % 实验验证了3种模型在同一数据集下对商品属性词的抽取能力,通过数据测试的P、R和F1值作为评测标准。本文所提出的THA-BiLSTM-CRF属性词抽取模型在属性词抽取任务中的F1值达到80.88%,领先于其他模型6.44%~9.56%,验证了通过引入THA提取隐式属性词,很大程度地提高了商品属性词抽取的完整性。 商品属性词的完整抽取,是提高商品评论细粒度情感分析准确性的重要工作之一。传统的属性词抽取模型难以有效抽取隐式属性词,故本文提出了一种基于截断历史注意力机制的商品评论属性词抽取框架THA-BiLSTM-CRF.该模型在BiLSTM-CRF模型的基础上引入截断历史注意力机制(THA),充分利用历史时间步信息,建立包含属性词和单词间映射关系的词库,挖掘商品评论中的隐式属性词。研究工作的主要贡献包括: 1)通过在BiLSTM-CRF模型中引入THA模型有效挖掘了隐式属性词。传统的属性词抽取多是针对显式属性词,但由于商品评论表达的口语化,很多评论中并没有显式属性词,故本文提出的隐式属性词抽取方法提高了属性词抽取的完整度。 2)通过BiLSTM-CRF模型与THA模型的数据共享,将BiLSTM-CRF模型抽取的观点词、显式属性词作为THA模型挖掘词间关系的词库,实现了同时抽取显式、隐式属性词,使抽取步骤更加简洁高效。 实验结果表明,本文提出的框架不仅可以抽取显式属性词也可以抽取隐式属性词,提高了属性词抽取的完整度。本文提出的抽取方法需要遍历每一条评论,具有一定的计算复杂度,未来我们会继续改进属性词抽取算法并进一步研究细粒度情感分析的相关工作,例如更准确地抽取商品属性词和与之对应的观点词等。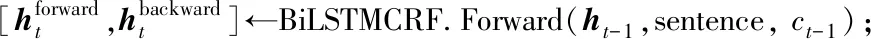

3 基于THA的隐式属性词抽取
3.1 截断历史注意模块

3.2 二次计算模块
4 实验及结果分析
4.1 实验数据集
4.2 评价指标
4.3 实验环境

4.4 实验方法
4.5 实验结果


5 总结
