基于工况聚类分析和信息融合的相似性剩余使用寿命预测方法
2022-03-21韩冰洁
韩冰洁,牛 伟,周 骁
(中国航空工业集团公司西安航空计算技术研究所,陕西 西安 710068)
0 引言
在预测和健康管理(PHM)中,剩余使用寿命(RUL)评估已成为保障系统安全性和可靠性的主要关注点[1-2]。基于性能退化数据的RUL估计是当前研究的热点,主要包括基于状态预测/外推的方法,基于统计回归的方法和基于相似度的方法[3-5]。当复杂系统不能使用数据学习建立全局模型时,基于相似性的方法适合于RUL估计[6]。基于相似性的方法适用于复杂系统无法利用数据学习建立全局模型时的RUL预测,研究成果多集中在相似性度量方法等方面[5],对系统运行数据基于工况的处理和信息筛选研究较少。
本文针对采用单个性能参量以状态量间的欧几里德距离为残差测度函数的相似性RUL预测方法[9]不能简单适用多工况发动机寿命预测,提出基于工况聚类分析和信息融合的相似性剩余使用寿命预测方法。
1 基于工况聚类分析相似性RUL估计
系统退化与系统运行历史相关,过去的行为改变了系统的属性。从系统处于正常运行状态时收集数据,直到系统接近故障或维护为止。这些相似系统的数据可以用来预测类似系统的寿命。因此基于相似度法的RUL估计的核心思想是,如果测试样本与参考样本具有相似的退化特性,那么它们就可能具有相似的RUL。测试样本取自从未发生过故障的系统,参考样本来自于已失效的系统(训练单元)的历史样本[7-8]。
之前的基于相似性方法的预测剩余寿命的研究成果集中在相似性度量方法、预测不确定性等方面,对系统运行数据基于工况的处理和信息筛选研究较少[9]。系统工况具体指系统运行所处的环境或操作条件。实际上一个系统从开始投入使用到性能失效的过程中会经历多种不同的运行状态。不同的系统工况对系统降级的影响是不同的。例如,飞机发动机在起飞、巡航、爬升、降落等不同工况下的性能退化明显不同[10]。本文以相似退化轨迹方法为基础,利用聚类分析区分工况,建立多信息融合残差相似性模型,最终拟合出预测寿命的概率分布,给出RUL的估计。
2 多信息融合残差相似性模型估计原理
2.1 数据预处理
不同工况下监测数据的基准有差异,趋势性会淹没在不同运行状态引起的干扰中。针对这一问题,本文利用K均值聚类方法区分工况。K均值聚类算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大[11]。提取工况信息后,在同一工况下对每一个传感器值求均值和方差。对于每个传感器的测量值做Z-score标准化,即减去“该聚类下该传感器”的平均值,再除以“该聚类下该传感器”的标准差。如式(1)所示:
(1)
传感器数据根据工况聚类分析区分,对每一个聚类分别进行Z-score标准化过程。这个数据处理的过程剔除掉了由于运行工况差异所造成的传感器数据差异。数据处理后可在同一时间轴上对比,再从处理后的数据集中选择对系统性能退化敏感的传感器作为相似模型的训练数据。
2.2 建立相似模型
相似模型的建立过程是将系统原始的特征数据映射成健康指数关于时间的函数。如果有多个传感器数据,则首先需要利用信息融合技术融合不同的信息。为实现不同生命周期的归一化表示,将寿命时间表示成健康指数,初始状态时的健康指数设为1,完全失效时的健康指数为0。本文用时间的二次多项式拟合融合后的传感器数据建立系统的健康状况相似模型。
2.3 RUL预测
基于相似模型的RUL预测过程是将测试样本的退化曲线与训练集模型中健康状况相似样本相匹配的过程。本文利用测试样本的退化曲线和相似模型的退化轨迹距离远近作为打分依据,按照打分高低选取最接近的几条退化曲线。测试数据与模型数据之间的距离通过残差的 1 范数计算,如式(2)所示:
(2)
相似度分数通过式(3)计算:
score(i,j)=exp(-|d(i,j)|)
(3)
最后以选取的这些曲线的剩余寿命为依据,利用核函数为高斯分布的核密度估计拟合出对应的这一类发动机RUL应该满足的概率密度函数。使用分布中的中值作为RUL的估计。
3 实验案例分析及结果分析
为了验证所提方法有效性,本文所采用实验数据来自PHM国际会议举办的故障预测竞赛IEEE PHM08数据集。该数据集包括喷气发动机运行至失效数据,训练集和测试集总计超十万个运行周期的样本。每台喷气发动机记录了24维时间序列数据,包括3维控制变量和21维传感器测量值。
3.1 数据预处理
发动机传感器数据采集来自不同的发动机操作数(条件数据),代表发动机的不同工况。从图1中看不出数据的退化趋势,下面将对退化特征进行提取。
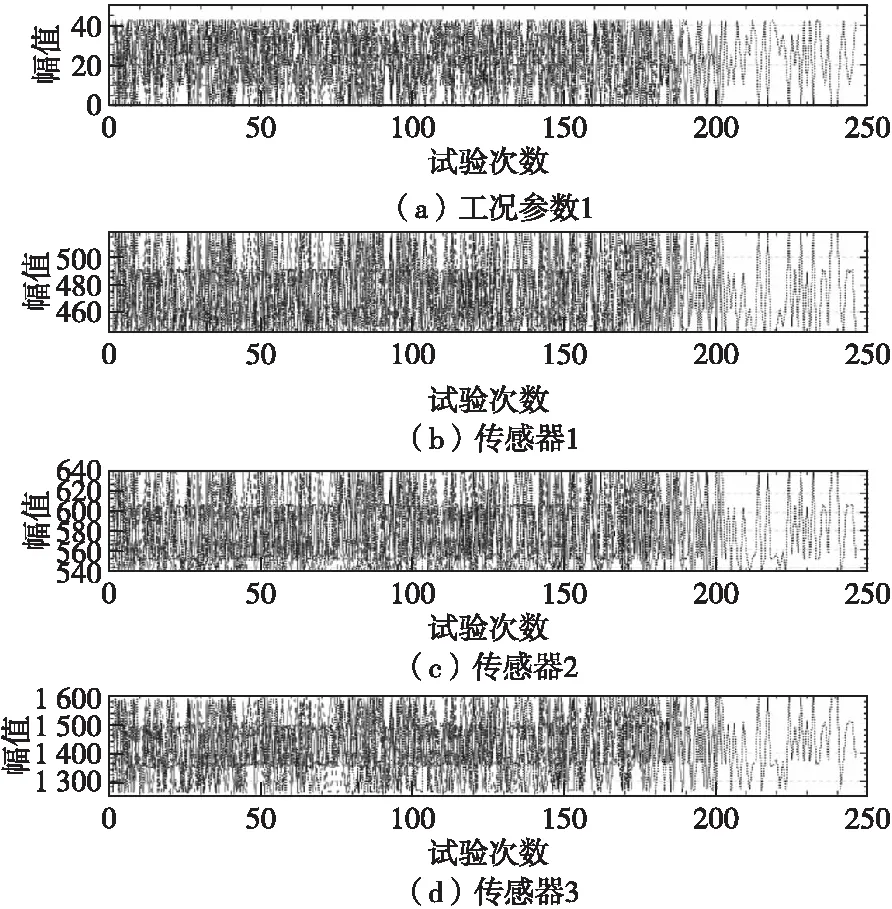
图1 未预处理数据Fig.1 Raw data
在图2中描出所有操作数的三维点,显然有六个聚集。通过迭代的方法计算到该聚集范围所有点的欧式空间距离和每个聚集的中心点。将多种工况通过K-means聚类分析,得到六个发动机典型工况中心。
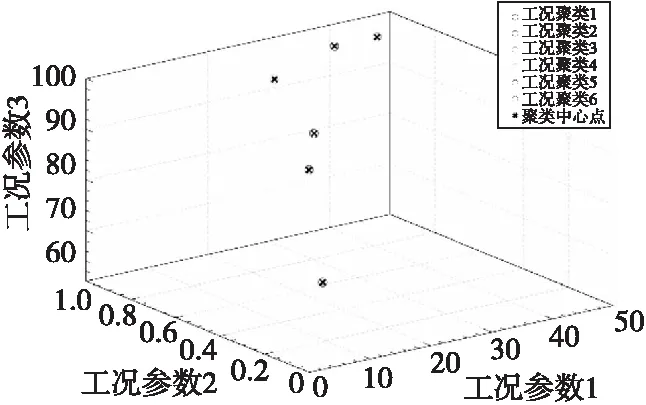
图2 工况聚类分析Fig.2 Cluster analysis of working conditions
同一传感器在不同工况下的标准化数据处理后,确实有传感器值在发动机整个生命周期中存在明显的退化。但从图3发现并不是所有的传感器退化趋势都明显,所以需要定性得出最能反应退化的传感器。通过构建传感器测量值线性退化模型,并对模型的斜率的绝对值进行排序。本文选择最具趋势性的8个传感器测量值准备构建健康指数进行预测,如图4所示。
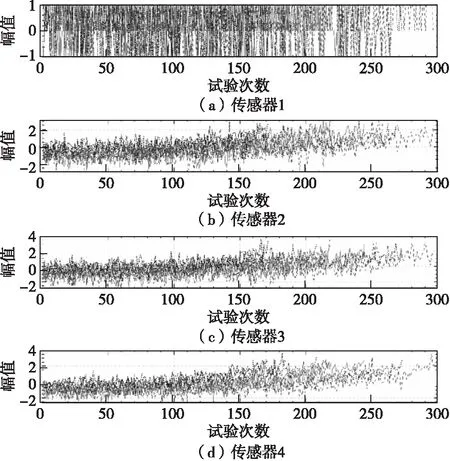
图3 聚类标准化处理后的传感器数据Fig.3 Sensor data after clustering normalization processing

图4 退化特征最明显的传感器数据Fig.4 Sensor data with the most obvious degradation characteristics
3.2 传感器信息融合并建立相似模型
选定了8个退化规律最明显的传感器,需要将选出的这些传感器数据融合到一个健康指标中。假设所有训练集中的发动机健康指数从1到0线性衰减。线性融合8个传感器数据按时间线性衰减的曲线,利用8个传感器数据融合后的健康参数HI训练模型创建残差相似性模型,拟合为关于时间的二次多项式函数。图5为信息融合后用健康参数表示的训练集数据。
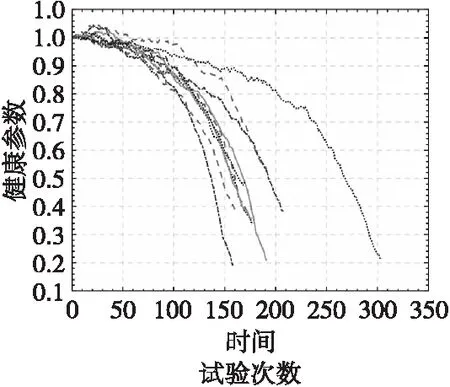
图5 用健康参数表示训练集数据Fig.5 Use health parameters to represent training set data
3.3 预测RUL
在得到的残差相似性模型中找出与测试发动机衰减曲线最相似的50个模型。以这50个模型的寿命值为数据,打分为权值,拟合出对应的RUL应该满足的概率密度函数,并取分布的中值作为RUL的估计值。
3.4 评估
为了评估方案,分别使用50%、70%和90%的样本验证数据来预测RUL。对验证数据集重复相同的评估程序,并计算每个断点的估计RUL和真实RUL之间的误差,并绘制误差直方图,如图6所示。图6的横坐标是试验周期的预测误差,纵坐标是直方图的频次占比。随着观测的数据越来越多(从50%到90%),误差越来越集中于0附近。
误差棒是数据可变性的图形表示,以指示所报告的测量中的误差或不确定性。如图7中每个竖线代表了预测的平均误差以及一个标准差的范围。可以看出,随着观测的数据越来越多,预测误差均值越来越小,误差范围也越来越小。
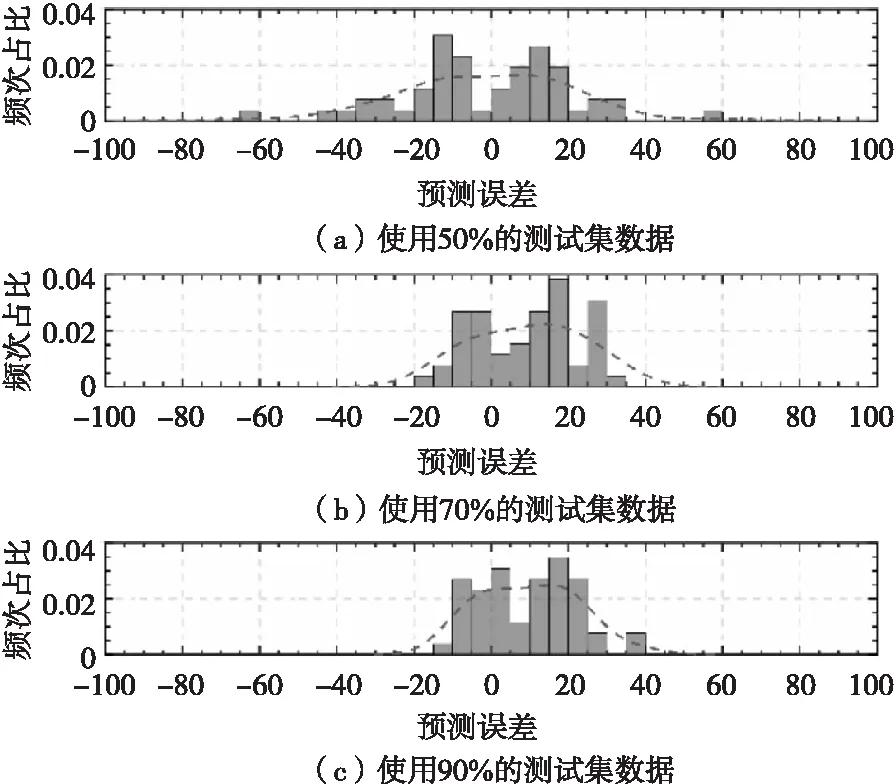
图6 不同截断点验证数据RUL预测误差直方图Fig.6 RUL prediction error histogram of verification data with different breakpoints

图7 不同截断点验证数据RUL预测误差棒图Fig.7 RUL prediction error bar graph of verification data with different breakpoints
评价一个模型预测性能,需给定一个度量性能的指标,采用均方误差(RMSE)[12],其反映了预测值和真实值的平均偏离程度,如式(4)所示:
(4)
利用本文方法计算的RMSE值为25.4,与其他相关方法如RF、SVM、CNN等进行比较取得了较好的预测结果[8,13-15]。
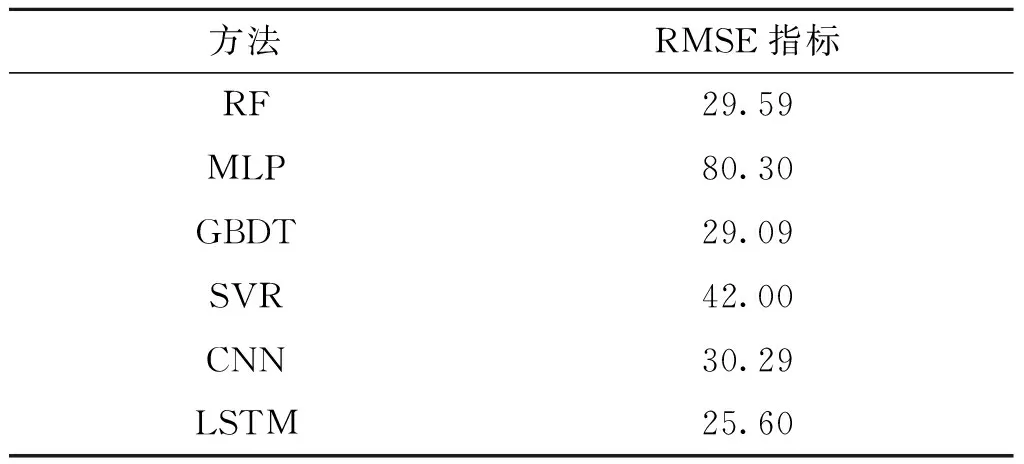
表1 RMSE指标下各项预测算法对比Tab.1 Comparison of various forecasting algorithms under RMSE metrics
4 结论
本文考虑了系统运行状态和传感器灵敏度对航空发动机寿命预测的影响,提出基于工况聚类分析和信息融合的相似性剩余使用寿命预测方法。该方法主要改进如下:1) 利用聚类分析标准化处理系统各工况下的监测数据;2) 分析选择对系统退化最敏感的传感器数据作为建立相似模型的基础;3) 将多个传感器数据融合为表征发动机健康状况的单个性能参量。最终拟合出预测寿命的概率分布,给出RUL的估计。
通过比较不同断点的估计寿命,发现随着观测的数据越来越多(从50%到90%),剩余有效寿命估计的准确性越来越高。最后将RMSE值与其他相关方法进行比较,试验结果表明,该方法在预测精度方面取得了较好的效果,具有较大的工程应用价值。
