汽车行驶工况识别模型搭建的方法研究
2020-05-07余卓平YuZhuopingGuTianLengBoXiongLu
余卓平,顾 天,冷 搏,熊 璐 Yu Zhuoping,Gu Tian,Leng Bo,Xiong Lu
汽车行驶工况识别模型搭建的方法研究
余卓平,顾 天,冷 搏,熊 璐 Yu Zhuoping,Gu Tian,Leng Bo,Xiong Lu
(同济大学 汽车学院,上海 201804)
汽车行驶工况的识别,可以用于优化车辆能量策略,在获得分类好的工况数据样本后进行输入输出的模式识别。对于现有的工况识别模型进行分析总结,根据工况数据前处理过程划分为基于实车采集数据和基于已知循环工况两种工况识别模型。同时给出构建工况识别模型流程,包括了工况块的划分,特征参数的选择,确定参考循环工况构建样本,主流的工况识别方法,以及样本模型的搭建与实车数据的验证。最后总结工况识别模型的特点,提出构建工况识别模型的思路。
行驶工况;模式识别;模型搭建
0 引 言
汽车驾驶工况识别的核心思想是给定若干代表不同路况条件的典型循环工况,通过离线优化方法得到各个典型驾驶循环的全局优化结果,并提炼出相应的离线优化控制参数,建立离线控制参数数据库。在车辆的实际运行过程中,通过提取实际行驶工况的特征参数,运用某种识别方法识别车辆正在经历的实际行驶工况特征接近于哪个典型循环工况,选择最适合的离线优化控制参数进行能量管理,其能量管理策略如图1所示。

图1 基于工况识别的能量管理策略
行驶工况识别本质属于模式识别在实际工程中的一种应用,当前优化整车能量管理控制策略的工况识别方法中,主流的分类方式基本上按照工况识别使用的方法进行区分;神经网络、模糊控制、聚类分析等方法均为工况识别模型的构建提供了理论基础。一个典型的神经网络工况识别模型如图2所示,一个基于聚类分析方法工况识别模型如图3所示。
上述所有模式识别模型都需要建立在分类好的样本的基础上,所以数据的前处理过程非常关键。虽然这些识别方法迥异,但都是在获得分类好的工况数据样本后进行输入输出的模式识别。现有的工况识别的方法按照工况数据前处理过程可总结为2大类型:基于实车采集数据构建工况识别模型、基于已知循环工况构建工况识别模型。

图2 典型的神经网络模式识别[1]

图3 典型的聚类分析[2]
1 实车数据构建工况识别模型
实车采集数据通常是用来进行当地实车工况构建,但其在工况构建的过程中也将实际情况下车辆行驶数据进行了处理和分类,而这种处理和分类的样本通常可以直接用来构造工况识别模型。其整体流程为:
(1)将车辆行驶数据进行短行程分割,如图4所示,若时间间隔为150 s,则被分为如图4所示的4个工况块;

图4 实车数据分割示意图[3]
(2)提取分割好后的工况块的特征参数并对特征参数进行降维,如图5所示;
(3)根据城市工况的循环特点(手动)将样本数据分成类,并进行-means聚类;
(4)在类行驶工况中各自选取一种典型工况组成代表工况,完成工况构建,如图6所示,用速度-时间曲线表示;

图5 工况块特征参数提取[4]

图6 实车聚类出来的典型工况[5]
(5)将之前完成好分类的样本用以构建工况识别模型;
(6)工况识别验证。
表1为使用该方式构建工况识别模型的具体分析。

表1 实车采集数据构建工况识别模型
注:①行程分析法:选取相邻两个停车点间的运动片段;②stopngo工况:闹市区拥堵走走停停;urban工况:次干道生活区低速;suburban工况:主干道中速;rural 工况:近郊区中高速;③LVQ:(Learning Vector Quantization,学习向量量化神经网络训练),BP神经网络:(Back Propagation,误差逆传播算法训练的多层前馈神经网络)。
这种工况识别模型构建虽然流程较为复杂,但以实车采集数据为基础,识别样本更能反映实际道路的情形。
2 基于已知循环工况构建工况识别模型
该方法没有实车的已知数据,通过对各国已有的循环工况提取各种特征进行分析聚类,得到分类样本后构建工况识别模型。根据已知循环工况处理方式的不同,该方法又可以细分为以下几种。
2.1 基于少数典型循环工况
首先设定好需要模型识别的工况类型,然后针对不同工况类型选择能够代表该种类型的典型工况。工况类型划分通常为市区拥堵、市郊工况、高速工况,如图7所示。

图7 典型工况示意[7]
该方法的整体流程为:
(1)根据汽车城市行驶特点将工况分类;
(2)找到不同类别下的典型工况,如图7所示;
(3)为增加样本数对典型工况进行划分,如图8所示;
(4)选取合适的特征参数;
(5)根据样本搭建工况识别模型;
(6)工况识别模型验证。
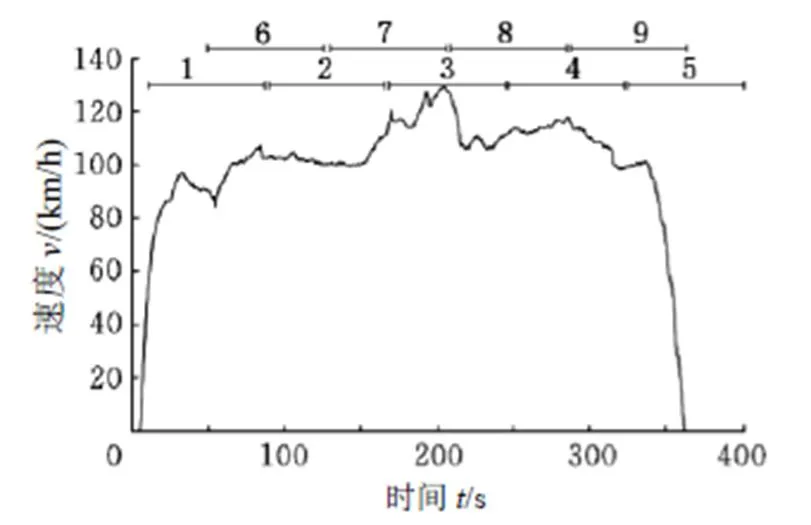
图8 划分典型工况增加样本数[8]
相比基于实车数据进行的工况识别模型搭建,该种方法操作起来较为简单,不需要额外对数据进行聚类分析,只需将不同典型工况进行切割和划分,从而获得足够多的样本供模型训练。表2为使用该方式构建工况识别模型的具体分析。

表2 基于少数典型循环工况构建工况识别模型
2.2 基于多种循环工况
这种方法选取多国不同的多种循环工况,将这些循环工况按照一定方法进行聚类,在不分段的情况下将这些样本作为构建工况识别模型的基础。
该方法的整体流程为:
(1)搜索各国大量循环工况;
(2)设置特征参数,直接对该工况进行聚类分析;
(3)根据样本搭建工况识别模型;
(4)工况识别模型验证。
表3为使用该方式构建工况识别模型的具体分析。
这种方法与基于少数典型循环工况的识别方法相比,省去了工况块的划分,将整个工况作为一个样本构建模型,这使得样本个数受限于工况的个数,适用于对数据量依赖较小的模型。

表3 基于多种循环工况构建工况识别模型
3 构建工况识别模型的比较分析
将上述所有方法的特点进行整理可以得出,基于实车数据构建工况识别模型的优点为以实车采集数据为基础,识别样本更能反映实际道路的情形,并且样本数量大,利于训练工况识别模型;缺点为数据前处理过程复杂,需要划分工况并进行聚类分析。
基于少数典型工况构建工况识别模型的特点在于数据前期处理过程较为简单,不用进行聚类,但需要划分工况段增加样本数量,虽然样本种类较为单薄,但样本数量较大,利于模型训练。
基于多种典型工况构建工况识别模型的特点在于数据前期处理过程简单,需进行聚类,但不划分工况段,虽然使用样本种类较多,但不划分工况段导致样本数量明显偏少,适用于构建简单的识别模型。
4 结 论
综上所述,在没有实车采集数据的情况下,可以采用少数典型循环工况构建工况识别模型,或者对多种循环工况构建工况识别模型所描述的方法进行改进。
改进的思路为将多种循环工况数据当作实车数据,按照实车数据的方式进行划分和处理,充分利用多种工况的数据增加样本数据量以求达到模型泛化能力的增强。
汽车行驶工况识别模型的发展方向可分为两种:一种是根据汽车城市行驶特点将工况进行分类,找到不同类型下的典型工况,为增加样本数对典型工况进行划分,选择合适的特征参数,得到分类好的样本;另一种是搜索全国多种循环工况,将所有工况数据进行行程划分,选取特征参数并对特征参数进行降维,根据城市工况特点将样本数据进行分类,并对样本进行聚类分析得到分类好的样本。神经网络作为最常用的工况识别方法,具有运算高效简便、复杂工况识别能力强的特点,所以两种发展方向都会依靠所得样本训练神经网络,构建基于神经网络的工况识别模型,并对模型进行准确性的验证和统计。
[1]罗少华. 基于工况识别的混联式混合动力汽车能量管理策略研究[D]. 重庆:重庆大学,2016.
[2]吕建美,牛礼民,秦子晨,等. 并联混合动力汽车工况识别与参数优化[J]. 安徽工业大学学报(自然科学版),2018,35(3):232-239.
[3]詹森. 基于工况与驾驶风格识别的混合动力汽车能量管理策略研究[D]. 重庆:重庆大学,2016.
[4]吕仁志. 基于工况与驾驶意图识别的HEV控制策略[D]. 大连:大连理工大学,2013.
[5]姜涛. 基于工况识别的插电式混合动力汽车控制策略研究[D]. 合肥:合肥工业大学,2018.
[6]陈玉成. 基于工况识别的混合动力汽车控制策略研究[D]. 济南:山东大学,2017.
[7]章楠. 基于工况在线识别的汽车电能管理系统的研究与实现[D]. 合肥:合肥工业大学,2018.
[8]邓涛,卢任之,李亚南,等. 基于LVQ工况识别的混合动力汽车自适应能量管理控制策略[J]. 中国机械工程,2016,27(3):420-425.
[9]邓涛,罗俊林,韩海硕,等. 混合动力汽车工况识别自适应能量管理策略[J]. 西安交通大学学报,2018,52(1):77-83.
[10]刘永刚,解庆波,秦大同,等. 基于工况识别的混合动力汽车能量管理策略优化[J]. 机械传动,2016(5):64-69.
U461.6
A
10.14175/j.issn.1002-4581.2020.01.011
1002-4581(2020)01-0039-04
