融合有向图的文本敏感词过滤模型
2022-03-18杨超宇
刘 莹 杨超宇
(安徽理工大学经济与管理学院 安徽淮南 233000)
由于互联网信息爆炸式增长,带有暴力倾向、不健康色彩的词或不文明语,涉及军事、政治、经济等各方面[1-3]的非法信息也会在网络中传播。因此对互联网网页内容的监控、过滤必不可少。
目前,许多学者针对敏感词的过滤和敏感词变体的识别进行研究。文献[4]提出了基于改进的Trie树和DFA的敏感词过滤算法,通过排列组合的数学原理扩充中文词库,构建敏感词树存储DFA的所有状态,解决了在敏感词过滤技术中的人工干扰、分词障碍等关键问题。文献[5]提出了基于决策树的敏感词变形体识别算法,该算法针对词的拼音、词的简称和词的拆分三种敏感词变形体的分析,对敏感词库进行扩充,构建敏感词树,该算法提高了敏感词变形体的识别效率。文献[6]中,作者提出了一种基于Aho-Corasick,并结合Trie树的多模式匹配算法,该算法在匹配速度、匹配查全率和空间利用率方面都有很好的效果,但是无法处理敏感次变形体。文献[7]提出基于改进音形码的中文敏感词检测算法,算法综合考虑汉字读音及字形特点,并对汉字相似度算法改进。文献[8]在Trie树的基础上进行改进,以实现对普通敏感词的识别的同时,也将敏感词变形体识别出来。
目前算法大都基于敏感词库构建Trie树,并结合相关匹配算法实现对敏感词的过滤。缺点是当敏感词的前缀不同时,无法使用敏感词共同前缀的敏感词相同关键字会出现在不同的敏感词分支中,造成存储的冗余。在敏感词库中的敏感词数量较大时,会花费更多的时间、空间存储重复出现的敏感词关键字,造成不同前缀敏感词的节点重复构建。如:混蛋、滚蛋、王八蛋。这三个敏感词没有相同的前缀,但有相同的后缀。因此,三棵敏感词树存储了相同的“蛋”字节点。这些节点会使敏感词树的子树数、树的层数、树的深度增加。存储敏感词树时会占用和大量的空间,算法需要花费较长的时间去构建敏感词树。
针对敏感词Trie树各个分支上可能存在大量的重复节点的问题,提出了基于有向图和DFA的敏感词过滤算法(DG-DGA)。算法通过有向图存储敏感词,减少了重复敏感词关键字的存储,提高敏感词的检索速度。
一、相关技术
基于汉明距离的相似度。汉明距离是指在数据传输差错控制编码中两个相同长度的二进制字符串对应位不同的数量。以h(x,y)表示两个字符串x,y之间的汉明距离。h(x,y)是对两个字符串x,y进行异或运算后,结果为1的个数。文献[7]提出了敏感词中汉字的汉基于音形码的相似度算法,并考虑了汉字拼音和字形在相似度中的贡献比,相似度S为:
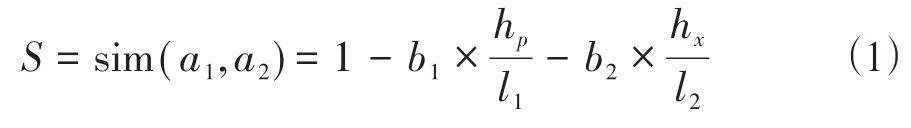
其中,hp表示拼音部分汉明距离,hx表示字形部分汉明距离,l1为音码的二进制长度,l2为形码的二进制长度,b1和b2为音码部分和形码部分在最终相似度计算中所占的贡献比,且满足b1+b2=1,计算公式为:

本篇文章着重考虑读音相似的敏感词,因此汉字拼音上的相似度,充分考虑拼音声母、韵母、声调对相似度的影响,着重考虑拼音和声调对相似度的贡献比,对相似度公式进行改进。相似度S为:
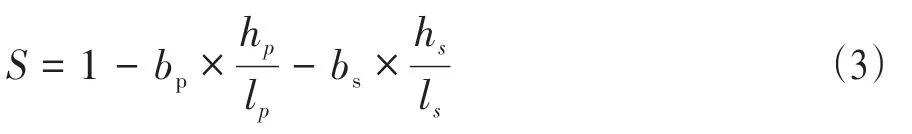
其中,hp表示拼音字母部分汉明距离,hs表示拼音声调部分汉明距离,lp为拼音字母部分的二进制长度,
ls为拼音声调部分的二进制长度,bp和bs为拼音字母部分和拼音声调部分在最终相似度计算的贡献比,且满足bp+bs=1,计算公式为:
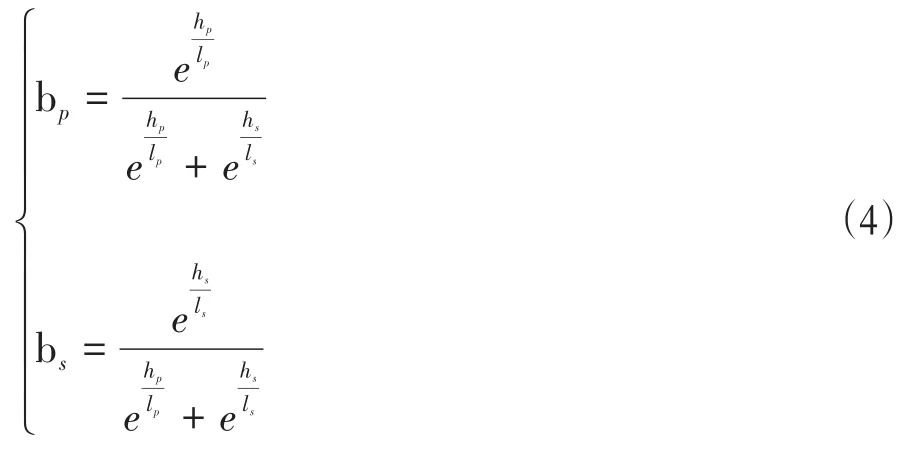
当两个字差别越大,相似度S越接近0,当两个字读音越相似,相似度S越接近1,当两个字相同时,相似度S等于1。
确定有限状态自动机。确定有限状态自动机(DFA),能够实现状态转移的自动机,给定一个自动机状态和一个输入符,经映射后,将转移到下一个自动机状态[9-12]。
D=(K,Σ,M,S,F),其中D为五元组;K为有穷、非空的状态集合;Σ为有穷、非空的输入符号集合;M为转换函数,是在K×Σ→K上的映射,如,M(ki,a)=kj,(ki∈K,kj∈K)表示:当前状态为ki,输入符为a时,经过映射,转换为下一个状态kj,并把kj称作ki的一个后继状态;S(S∈K)是唯一的初始状态;F(F⊆K)是非空的终止状态的集合。
如果输入为a,b,则假设DFA状态转移图如图1所示:
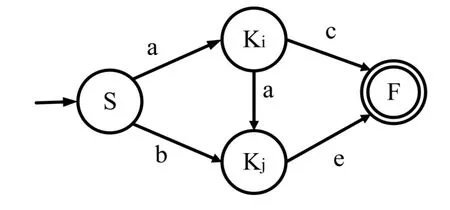
图1 状态转移图
本文通过有向图将敏感词库中的敏感词联系起来,每个敏感词关键字都是节点,通过节点的指向关系表现敏感词中每个字的前后顺序。在敏感词有向图中检测敏感词时,以DFA的机理实现状态转移。以敏感词的起始关键字作为初始状态S的元素,以待判断的字作为输入,确定状态转移的指向,从而转换为下一个状态,直到到达终止状态F,即敏感词最后一个字,此时一个敏感词被成功检测出来。
二、改进的敏感词过滤模型
(一)基于有向图和DFA的敏感词算法设计。一个有向图D是指一个有序三元组(V(D),A(D),ψD),其中V(D)表示有向图D的节点点集合;A(D)表示有向图D的边的集合;ψD为关联函数,它使A(D)中的每一条边对应于V(D)中的一个有序节点对[13-16]。对于敏感词有向图,一个节点表示一个敏感词关键字,其特点如下:
a)所有节点关键字都是独一无二的,不存在两个相同的节点字符。
b)具有相同关键字的敏感词共享该关键字节点。
c)每个节点记录了起始和结束标志,以及以该节点字符结尾的所有敏感词起始字符。
d)节点的度越大,说明这个敏感词关键字在敏感词库里出现的频率越高。
e)若节点只有入度,没有出度,说明该节点的关键字是敏感词的最后一个字。
f)若节点只有出度,没有入度,说明该节点的关键字是敏感词的第一个字。
g)在原有敏感词有向图的任意位置添加敏感词节点。
有向图中每个敏感词关键字节点表示DFA的一个状态,每条边的指向关系表示出敏感词关键字之间的关系。假设敏感词为:“王八蛋、混蛋、混球、滚蛋、滚边去”,每个节点都有起始标志isStart、结尾标志isEnd、起始节点集合starts。当节点作为起点时,起始标志设为1;当节点为尾节点,结尾标志为1。由于“王”“混”“滚”均为敏感词的起始关键字,因此这三个关键字的节点的起始标志isStart=1。由于“蛋”“球”“去”均为敏感词的最末关键字,因此这三个关键字的节点的结尾标志isEnd=1。并且,以“蛋”为结尾关键字的敏感词有“王八蛋、混蛋、滚蛋”,因此该节点的起始节点集合starts存储了这三个敏感词的的起始关键字。则构建的敏感词有向图如图2所示:

图2 敏感词有向图
(二)敏感词有向图构建算法。敏感词有向图构建算法将敏感词库中的敏感词以有向图的形式存储,敏感词库中的每个字在有向图中以节点表示,且重复出现的字以同一个节点表示。构建敏感词有向图的具体描述如下:
S1:以一个敏感词为单位把敏感词库中的所有敏感词添加到名为keyWordList的列表中,新建字典变量entrance存储所有敏感词关键字的字符节点,构建字典变量root存放所有敏感词起始关键字节点,并执行S2;
S2:循环执行以下操作,当keyWordList到达末尾时循环结束,构建敏感词树也结束,若循环未结束,则执行S2.1;
S2.1:依次从keyWordList中取出一个敏感词,放在名为keyWord的变量中,keyword的长度为len_chars,执行S2.2;
S2.2:循环执行以下操作,若循环未结束,则执行S2.2.1,若结束,跳转执行S2.1;
S2.2.1:定义变量i表示当前敏感词的第i个位置,当前敏感词关键字为chars[i],执行S2.2.2;
S2.2.2:判断当前字符chars[i]是否在有向图entrance中,如果不在,则新建节点node,并以该字符为键,以该节点node为值,添加到字典entrance中,并继续执行S2.2.3;
S2.2.3:若i>0,即为不为敏感词起始关键字,则将该节点指向上一节点;继续执行S2.2.4;
S2.2.4:若为敏感词最后一个关键字,则执行S2.3,否则跳转执行S2.2.1;
S2.3:将敏感词起始关键字节点的isStart标志设置为1,敏感词末尾关键字节点的isEnd标志设置为1,将起始关键字节点添加到末尾关键字节点的starts列表中,以起始关键字字符为键,以起始关键字节点为值,添加到字典root中,跳转执行S2.1。
根据以上算法描述,敏感词库中的所有敏感词都被存储到敏感词有向图中,且可以在原有敏感词有向图的任意位置添加敏感词节点。若新的敏感词中的关键字在有向图中已经存在,那么,只需要修改对应关键字的isStart标志、isEnd标志,将起点顶点添加到末点顶点的starts中即可。
(三)敏感词检测算法设计。构建敏感词有向图后,根据设定的敏感程度阈值,将原文本中的词与敏感词有向图比对,进行基于音码的拼音敏感程度的计算,若敏感程度大于设定的阈值,那么则认为该词为敏感词,并进行敏感词的过滤。
音码编码。本文采用四位音码的方式展现每个字的拼音特征,分别是声母、韵母补位、韵母、声调,并将其采用格雷码对
其进行编译成二进制数序列,音码结构如图3所示:

图3 音码结构
本文将所有每位声母、韵母补位、韵母、声调都分配一个十进制数字表示,再将该数字转化为六位格雷码,由于格雷码任意相邻的两位编码只有一位二进制数不同。因此,发音相近的拼音声母及韵母设置的数字间隔更小,使其计算相似度更高,如“z”和“zh”,“an”和“ang”。由于声母、韵母和声调的十进制表示和对应的格雷码编码如表1~4所示。

表1 声母编码

表2 韵母补位编码

表3 韵母补位编码

表4 声调编码
通过以上编码规则,可以将汉字转化为相应的格雷码,例如,“淮”字的拼音为“huai”,声调为“阳平”。由于声母“h”的格雷码为“011111”,韵母补位“u”的格雷码为“001101”,韵母“ai”的格雷码为“001011”,声调“阳平”的格雷码为“000011”,则“淮”字格雷码为“011111001101001011000011”。
基于相似度的敏感词检测算法。构建敏感词有向图后,将原文本中的待检测汉字与敏感词有向图中特定节点汉字比对,分别根据两汉字的拼音得到对应的格雷码,再根据改进的拼音相似度计算公式计算两个汉字的相似度,判断该相似度是否大于设定的相似度阈值,若大于,则认为该待检测汉字与节点汉字相符,继续判断下一个待检测汉字和下一节点汉字的相似度。基于相似度的敏感词检测算法描述为:
S1:从原文本的第一个字符开始,循环执行以下操作,直到原文本最后一个字符被执完结束,定义变量ret存储过滤后的文本字符,定义变量i表示原文本的当前位置,初始值i=0指向原文本的第一个字符位置,定义level为敏感词有向图的当前位置;
S1.1:判断第i个字符是否为标点符号,如果是,继续执行S1.2,如果不是,则跳转执行S1.3;
S1.2:将第i个字符直接存入ret,并跳转执行S1.1;
S1.3:将第i个字符与root中所有起始节点字符分别计算相似度,将得到的最大相似度存储在变量max_sim_root中,对应的最大相似度的节点字符存储在变量char_max_sim_root中,该字符认为是当前检测敏感词的起始字符,并设定拼音相似度临界值sim_standard为0.92,继续执行S1.4;
S1.4:判断字符最大相似度max_sim_root是否大于sim_standard,如果不是,则将原文本第i个字符存入ret,并跳转执行S1.1,如果是,则继续执行S1.5;
S1.5:将敏感词有向图当前位置level定位到字符为char_max_sim_root的节点上,以变量start_index存储当前检测敏感词的首字符在原文本中的位置,即start_index=i,执行S1.6;
S1.6:循环执行以下操作,若循环未结束,则执行S1.6.1,若结束,跳转执行S1.1;
S1.6.1:定义变量j表示当前判断的是原文本的第j字符位置,初始值j=i+1,继续执行S1.6.2;
S1.6.2:将第j个字符与当前敏感词有向图level位置下所有节点字符分别计算相似度,将得到的最大相似度存储在变量max_sim中,对应的最大相似度的节点字符存储在变量char_sim中,继续执行S1.6.3;
S1.6.3:判断最大相似度max_sim是否大于sim_standard,如果不是,则将原文本第i个字符存入ret,并跳转执行S1.1,如果是,则继续执行S1.6.4;
S1.6.4:判断起始字符char_max_sim_root节点是否为当前末点char_sim节点的起点,如果不是,则有向图指针level指向原下一字符,并跳转执行S1.6.1,如果是,则将原文的敏感词字符位置存储“*”,将原文指针i移到当前敏感词末字符位置,即i=j,若当前原文字符不是原文最后一个字符,并跳转执行S1.1,若是,则继续执行S2;
S2:将列表ret中的字符串连接成一个完整字符串,并返回该字符串,即过滤完成。
根据上述算法描述,将待检测原文的逐字与敏感词有向图对比,直到有向图的末点节点。若待检测汉字的相似度都大于阈值,则可以认为这些待检测汉字是一个敏感词,并对其以“*”替代,进而将该敏感词过滤。以此对读音相似的敏感词干扰问题进行处理。图4是文本敏感词检测过程。
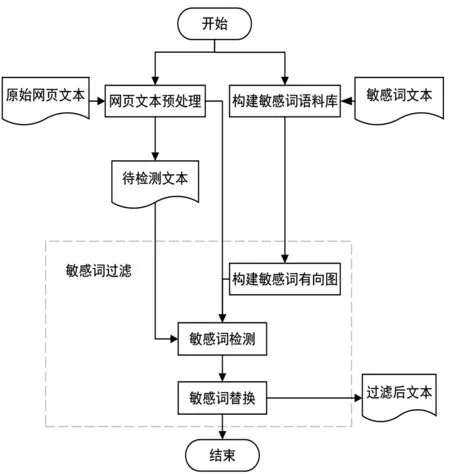
图4 文本敏感词检测过程
三、实验及结果分析
实验是在WIN10系统下,使用编程语言是Python3.7,算法运行环境是PyCharm。
(一)数据集。敏感词库来自从网络上下载的开源敏感词库,敏感词词库共有1757个敏感词,其中暴恐类敏感词有116个,反动类敏感词有456个,民生类敏感词有417个,色情类敏感词有499个,贪腐类敏感词有218个,其他51个。根据以上敏感词库构建敏感词有向图。
(二)全模式匹配实验分析。全模式匹配实验关闭相似度比较入口,只有和敏感词库中收录的敏感词相同的词才会被过滤。
1.敏感词检测算法过滤效率对比。该实验将基于敏感词Trie树的DFA敏感词检测算法和本文DG-DFA算法进行对比,敏感词对比采用完全匹配模式。该实验的待检测文本来自键盘随机敲击产生的汉字和字母组合,并从中插入751个敏感词。插入的敏感词及其个数如表5所示:

表5 敏感词数目
由于敏感词的查找时间会因计算机运行状况而有细微差别,因此在计算不同算法的过滤时间时,使用控制变量的方法,且在每种算法下连续重复实验10次,记录每次敏感词过滤耗时,取其平均值。敏感词查找耗时如表6所示:

表6 敏感词查找耗时
在敏感词总数均为751时,基于敏感词trie树的DFA敏感词检测算法的检测耗时约为DG-DGA算法的6倍,说明DG-DGA算法的检测效率要远高于基于敏感词Trie树的DFA敏感词检测算法。
2.不同文本字数过滤效果对比。该实验在相同的条件下比较基于敏感词Trie树的DFA敏感词检测算法和DGDGA算法的检测时间,根据待检测文本的文本字数的不同共进行8组测试,待检测文本的字数分别为5万、10万、15万、20万、25万、30万、35万、40万。每组测试重复进行10次,记录每次敏感词检测时间,并将这10次检测时间的平均值作为该组文本字数的检测时间。实验检测结果如表7所示:

表7 不同文本字数的检测时间
为了更好地将算法检测时间在柱状图上显示,对敏感词检测时间进行处理。

将敏感词检测时间T取对数,并加上常数4,得出相对检测时长t,以检测的相对时长进行比较,如图5所示:
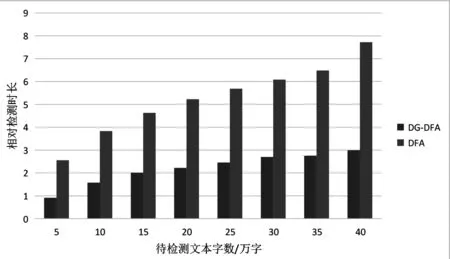
图5 不同文本字数的检测时间
如表7和图5所示,检测相同字数的文本时,DG-DGA所需时间远远短于DFA,因此DG-DGA的匹配速度远远高于DFA,当待检测文本的字数越多,DG-DGA的速度优势越明显,敏感词检测效率越高。
综上所述,在敏感词检测过程中,构建敏感词有向图比构建敏感词Trie更节省时间。
(三)模糊匹配模式实验分析。不同敏感度阈值文本过滤实验。实验通过设定不同的相似度阈值,比较DG-DFA算法的过滤效果。待检测文本的数据集来从敏感词库中抽取131各敏感词,并人为构建读音相近的敏感词,共扩展敏感词833个。在不同敏感词阈值下进行实验,并统计敏感词个数。敏感词阈值分别取0.5、0.6、0.7、0.8、0.9,表8是不同敏感词阈值下的敏感词检测数量。

表8 不同敏感词阈值的敏感词检测数量
从表8中结果可以看出,敏感词算法在阈值为0.5时,就可以将92.6%的相似敏感词识别出来,且敏感词阈值为0.9时检测出来的相似敏感词占敏感词阈值为0.5时的94.56%,说明算法能较好地识别敏感词的相似读音。
因此,融合有向图的文本敏感词过滤模型在构建敏感词有向图时,比构建敏感词树更节约时间;且通过汉字拼音和声调相似度的计算,能够有效识别读音相似的敏感词,能够增强敏感词识别效率和覆盖程度。
四、结语
该文本敏感词过滤模型中的DG-DFA算法融合了有向图的思想,将敏感词库中的敏感词以有向图的方式连接。该算法将敏感词库中的敏感词关键字存放于有向图中,通过有向图的边维系每个敏感词。与原有的DFA算法相比,DG-DFA将敏感词树替换成敏感词有向图,敏感词中的相同关键字在有向图中只存储一次,避免了原始DFA算法敏感词决策树中不同前缀的敏感词中相同关键字的重复存储,节省了存储空间。为了验证算法的性能,进行了DFA算法和DG-DGA算法在全模式匹配下的敏感词检测算法过滤效率对比实验、不同文本长度下的时间效率对比实验,以及DG-DGA算法在不同敏感度阈值文本过滤实验。通过实验表明:DG-DGA算法的过滤算法的检测速度约是DFA算法的6倍,有更高的敏感词匹配效率;文本敏感词过滤模型在不同文本数量下检测敏感词时,待检测文本数量越大,模型的检测优势越明显,且DG-DGA算法能较好地识别敏感词的相似读音。
