边缘指导图像修复算法研究
2022-03-13胥加洁朱俊武
姜 艺,胥加洁,柳 絮+,朱俊武
1.扬州大学 信息工程学院,江苏 扬州225127
2.上海交通大学 海洋工程国家重点实验室,上海200030
图像修复指计算机根据破损图像缺失区域外的信息推理修复出图像破损区域的过程,图像修复目的是使修复后的图像破损区域足够真实。然而,人类的视觉系统能够敏锐地捕捉到图像修复的痕迹。如何使得修复结果真实到骗过人眼的观察是图像修复研究的重点之一。现有的许多图像修复算法已经能够生成较好的修复结果,但是遇到缺失结构较为复杂的情形时,修复的结果往往会出现过度平滑或者模糊的现象。现有方法往往注重图像缺失区域内容的生成,而对缺失部分细节的处理能力较差。本文的工作是研究图像复杂结构缺失下的修复问题。
传统的图像修复方法主要通过搜索图像中完好区域的像素信息后填充至图像中的缺失区域。这些方法大多基于图像的低级特征进行修复,使得修复模型只能处理图像中一些简单纹理信息缺失的修复工作,而难以修复图像缺失的复杂结构信息。修复图像的复杂结构需要对图像有更深的理解,基于图像的低级特征来修复远远不能满足实际需求。
基于学习的图像修复方法解决了传统图像修复方法对图像理解能力不够的问题。深度学习通过对海量图像数据的学习,能够很好地理解图像的语义信息。基于学习的图像修复方法能够学习缺失图像到完整图像端到端的映射函数。为了获得更逼真的修复效果,大部分图像修复方法使用了生成对抗网络技术(generative adversarial networks,GAN)。虽然基于深度学习的图像修复较传统的图像修复方法在修复质量上得到了很大的提升,但是在面对图像复杂结构缺失时,现有方法不能很好地修复出结构纹理信息。
针对上文分析的问题,本文将图像修复工作分为两部分:边缘修复和内容填充。边缘修复主要修复图像缺失部分的边缘信息,而内容填充则修复图像缺失部分的颜色信息。具体来说,本文模型先训练边缘修复模型以生成较为真实的缺失区域的边缘信息,而后基于边缘修复网络生成的边缘图进行缺失部分内容的生成。本文在CelebA 数据集和ParisStreet-View 数据集上训练、评估模型和对比实验。总的来说,本文的主要贡献有如下几点:
(1)提出了一种边缘生成模型,并使用边缘生成模型指导图像修复工作。
(2)将图像修复任务拆分为两部分,分别是边缘修复和内容填充。
(3)提供端到端训练的网络模型能够修复图像中缺失的复杂结构信息。
1 相关工作
基于扩散的图像修复方法将图像缺失区域周边的信息扩散至缺失区域。Bertalmío 等人从手工修复图像技术中汲取经验,首次提出了基于扩散的图像修复方法。在此之后,Chan 和Shen 在Bertalmío 等人提出模型的基础上提出了全变分模型(total variation,TV),该模型在修复速度上有了明显的提升,但在图像修复结果的连贯性修复上较为乏力。为了解决该问题,Chan 和Shen 基于TV 模型加入等照度线几何信息,提出了一种新的曲率驱动扩散(curvature-driven diffusion,CDD)模型,弥补了TV模型的不足。Mumford-Shah 模型是另外一个具有代表性的基于扩散的图像修复模型,该模型降低了运算的复杂度,但修复结果连通性不足。Shen 等人引入Euler's elastic 模型,提出Mumford-Shah-Euler 模型,很好地解决了Mumford-Shah 模型的不足。除此之外,文献[11-13]均采用基于扩散的思想进行图像修复。总的来说,基于扩散的图像修复方法局限于缺失区域周边的局部信息,难以修复缺失部分的语义信息,更难以修复复杂的结构信息,该类方法只适用于图像较小区域修复或者背景修复工作。
基于补丁块的图像修复方法从图像中搜索与缺失区域相似度高的图像块填充至缺失区域,由于要进行大量的相似度计算,这类方法的计算成本很高。Barnes 等人提出的PatchMatch 算法是典型的基于补丁块的图像修复方法之一,该算法利用快速近似最近邻方法降低了运算的复杂性,提高了计算速度,但是随机化的方法也降低了修复的精度。Criminisi 算法利用置信度和修复边界信息来确定填充顺序的优先级,进而在图像完好区域搜索与待填充块相似度最高的块来填充,最后再更新需要填充的块的边界和置信度,大大增加了计算量。除此之外,文献[9,14-15]所提出来的算法均基于补丁块的思想进行图像修复。总的来说,基于补丁块的图像修复方法总是假设缺失区域的内容会在图像其他完好的区域中找到,但是这种假设往往不成立,比如,当一张人脸的鼻子被遮挡了,这类方法就搜索不到与鼻子相似的块,难以修复缺失的鼻子。该类方法擅长于恢复高度图形化的区域,如背景补全,但在重建局部独特的图形时却很困难。
基于深度学习的图像修复方法成了近几年图像修复领域的热门研究,相比基于扩散和基于补丁块的图像修复方法,该类方法最大的优势在于从海量数据中学习到图像的语义信息,这是其他方法难以做到的。这些方法基于卷积神经网络训练出从破损图像到完好图像的映射函数,能够学习、理解图像修复过程中图像的动态特征,进行如人脸、建筑等复杂物体的修复工作。Context-Encoder 模型是深度学习进行图像修复工作的最早尝试,模型通过对L2 损失和对抗性损失的训练,得到较为清晰的修复结果。Iizuka等人使用两个判别器来保证修复结果全局的一致性和局部的正确性,修复效果较好但模型依赖后处理。Song 等人使用一个预先训练好的图像分割网络得到图像损坏区域的前景掩膜,然后填充掩膜以指导图像修复,取得了较好的修复效果。但是,当前景和背景都被遮挡时,该类方法的效果较差。除此之外,文献[11,19-22]方法均基于深度学习方法修复图像。总的来说,基于深度学习的图像修复方法能够很好地学习到缺失区域的语义信息,修复结果较为逼真,但是如何修复图像复杂结构的缺失并且使得修复结果足够逼真仍然是具有挑战性的科学问题。
2 边缘生成模型设计及算法实现
2.1 模型框架
本文提出一种基于生成对抗网络(GAN)的图像修复模型,架构如图1 所示。该模型由两大部分组成,分别是边缘修复模型和内容填充模型。边缘修复模型的作用是修复生成缺失部分的边缘结构信息,内容填充模型的作用是在边缘修复模型输出结果的基础上填充内容信息。

图1 整体模型框架Fig.1 Whole framework of model
边缘修复模型结构基于深度卷积生成对抗网络模型,包括生成网络和判别网络两部分。其中生成网络使用自编码器的结构,在自编码器的编码器和解码器之间是8 个连续残差块组成的网络。为了降低网络的计算量,使用空洞卷积而非普通的卷积层。整个边缘修复模型的网络参数结构图如图2 所示,输入是256 imes256 imes3 的待修复图像的边缘图,经过一个自编码器网络生成修复后的边缘图。在生成网络的后面加上一层优化网络,对边缘修复网络修复的边缘图进行优化提纯,将提纯后的边缘图输入至判别网络进行判别。

图2 边缘修复模型网络结构参数图Fig.2 Network structure parameter diagram of edge-guided repair model
边缘修复模型中优化网络的网络参数结构图如图3 所示,优化网络是一个简单的自编码器结构,编码器和解码器之间是连续4 块空洞卷积层。优化网络可以优化提纯生成网络中前面自编码器修复的边缘图里冗余的信息,产生更好的边缘修复图供内容填充模型使用。

图3 优化网络的网络结构参数图Fig.3 Network structure parameter diagram of optimization network
与边缘修复模型结构类似,内容填充模型结构也是基于生成对抗网络。生成网络使用自编码器的结构,判别网络使用普通的卷积神经网络结构。与边缘修复模型的网络架构类似,但内容填充模型没有优化网络。内容填充模型由生成网络和判别网络两部分组成,其中生成网络的输入是边缘生成模型的输出,输入经由编码器、8 个连续的残差块和解码器生成修复后的最终的彩色图像,再将生成网络的输出输入至判别网络中,输出的结果就判定该图像是由网络修复的还是来自于真实的样本空间。具体的内容填充模型图如图4 所示。

图4 内容填充模型网络结构参数图Fig.4 Network structure parameter diagram of content filling model
2.2 损失函数
总损失函数由边缘修复模型损失函数和内容填充模型损失函数两部分组成,如式(1)所示:


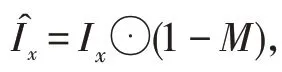

其中,G为边缘修复模型中生成器所代表的函数。将生成的和E共同输入进判别器训练,训练后的判别器需要判别输入的边缘图是由边缘生成器生成的还是原图的边缘图。边缘修复模型损失由对抗损失和特征匹配损失组成:
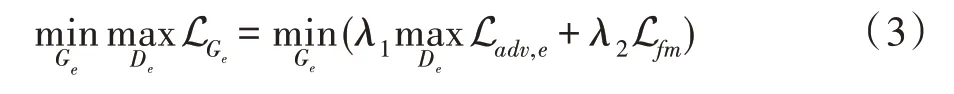
其中,D代表边缘修复模型中判别器所代表的函数;和是平衡对抗损失和特征匹配损失的超参数;L代表边缘修复模型中的对抗损失;L代表特征匹配损失。L的具体定义如式(4)所示:

特征匹配损失通过比较判别器中间层之间的激活图来稳定训练进程,类似于感知损失。L的具体定义如式(5)所示:


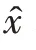

其中,G代表内容填充模型生成器所代表的函数。内容填充模型的损失函数由重建损失、对抗损失和风格损失三部分组成:



本文使用μ代表在ImageNet 数据集上预训练的VGG-19 网络的relu1_1、relu2_1、relu3_1、relu4_1和relu5_1 的每一层的激活图,并使用风格损失用来测量激活图之间协方差的差异。给定大小为C×H×W的激活图,那么风格损失L即可由式(9)得到:


2.3 训练算法

边缘生成模型训练算法


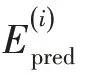
内容填充模型训练算法

3 实验
3.1 实验数据与预处理
实验所使用数据集为CelebA 数据集和Paris Street-View数据集,其中CelebA数据集包括202 599张三原色(red green blue,RGB)三通道彩色人脸图像,本实验使用10 万张图像用作模型训练,并在剩下的图像中选择1 000 张用来模型测试。ParisStreet-View 数据集训练集包含14 902 张图片,本实验选择14 000 张用作模型训练。
在数据集的预处理阶段,将选取的图像的分辨率固定为256×256。除此之外,本实验使用文献[11]的不规则掩膜生成方法生成不规则随机掩膜数据集,总共生成2 万张分辨率为256×256 的不规则掩膜图像用作模型的训练和测试。如图5 所示生成的不规则掩膜数据集中的示例图像。

图5 不规则掩膜数据集样本Fig.5 Samples of irregular mask datasets
除此之外,由于实验将破损部分缺失的图片直接输入至模型进行修复,生成接近真实图像或与原图类似的结果。为了确保待修复图像未缺失部分的像素信息不被改变,在后处理阶段将修复生成的图片原缺失部分的像素填充至待修复图像的缺失部分,但直接填充可能会造成填充部分与原图边界的不连贯,因此实验在填充后对边界使用泊松融合处理。泊松融合基于泊松方程,能够很好地将源图像和目标图像进行无缝融合。本实验将待修复图像作为背景图像,将生成的缺失部分作为填充图像,通过泊松融合将填充图像融入背景图像中,减少拼接的痕迹提升最终的图像修复结果质量。
3.2 实验细节及超参数设置
实验是在一块显存为8 GB 的NVIDIARTX2070显卡上训练的。模型采用卷积神经网络的架构,激活函数使用=0.2 的LeakyReLU,模型参数更新使用Adadelta 优化算法,本实验中对于边缘修复网络的损失函数中的权重和取值分别为1 和10,对内容填充网络的损失函数中的权重、和取值分别为1、0.1 和250。实验代码使用Python 语言编写,使用TensorFlow 和Pytorch 框架。
4 实验结果
本文方法在CelebA 数据集和ParisStreet-View 数据集上与Shift-Net 模型、DIP(deep image prior)模型以及FFM(field factorization machine)模型进行对比。其中Shift-Net 模型是一个基于生成对抗网络的图像修复模型,它结合了传统的基于范例的图像修复方法和基于神经网络的图像修复方法的优点,能够修复出较为精细的纹理细节。DIP 模型是基于卷积神经网络提出的一个新的非学习的图像修复模型,它通过在单张损坏图像上的反复迭代学习图像的先验信息,进而实现图像修复。FFM 模型则是一种传统的图像修复模型,它利用待修复像素与其周围邻近像素的相关性来修复边界上的像素信息,并将待修复区域的边界不断往里推进,以达到图像修复的目的。
4.1 定性分析
分别在CelebA 数据集和ParisStreet-View 数据集的测试图片中选取部分样本,以规则掩膜和不规则掩膜遮挡分别进行修复。如图6 所示为CelebA 数据集上不规则掩膜遮挡的修复结果,自左向右,(a)~(f)每一列分别代表原图、待修复图像、Shift-Net 模型修复结果、DIP 模型修复结果、FFM 模型修复结果和本文模型修复结果。由图6 可以看出,本文模型修复结果所造成的模糊现象最少,且能较好地修复出缺失部分的语义信息。从第1、3 和4 行的修复结果可以看出,本文模型能够生成很逼真的修复结果,尤其是第四行当一半墨镜被遮挡,本文模型仍然可以修复出缺失的墨镜结构和语义信息,很好地解决了难以修复复杂结构信息的问题。根据本文提出模型的修复结果,修复生成的一只眼睛并不能很好地同另外一只眼睛形成对称,因此使得修复结果在视觉上不太合理,比较容易辨认出修复过的痕迹。同样的,Shift-Net 模型也能较好地修复出缺失部分的语义信息,但是修复结果会有一些模糊现象。DIP 模型作为一个不需要训练的深度学习模型,修复结果在像素级别上能较好地与原图相融合,但是不能很好地修复出缺失部分的语义信息,而FFM 模型作为一个传统的非深度学习的图像修复算法,只能简单地将周围的信息复制到缺失部分,在语义修复上表现较差。总的来说,本文提出的模型在CelebA数据集上不规则掩膜的修复结果在视觉上要优于其他几个对比模型,且能较好地修复出缺失区域的复杂结构信息。

图6 CelebA 数据集上不规则掩膜修复结果Fig.6 Irregular mask repair results on CelebA datasets
图7 展示各个模型在CelebA 数据集上规则掩膜遮挡的修复结果,每一列结果所代表的模型与图6 相同。可以看出,本文模型在规则掩膜遮挡图片上的修复结果较其他几个模型的修复结果要好。在图7的第一行和第二行中,实验用矩形规则掩膜遮挡了一只眼睛,与图6 的结果类似,本文模型能够很好地修复出缺失的眼睛并且修复的结果与周围完好区域融合性较好,但是修复生成的眼睛与另外一只眼睛的相似度较低。Shift-Net 模型也能够修复出缺失的眼睛,但是修复结果存在些许的模糊现象,很容易看出修复的痕迹。而DIP 模型和FFM 模型则很难修复出缺失部分的语义信息,只是简单地从缺失区域的周边获取像素信息填充至缺失区域。在图7 的第三行中,本实验遮挡住人脸眼镜和眼睛部分进行修复,从后四张修复结果可以看出,只有本文模型和Shift-Net 模型修复出视觉上较好的结果。虽然(c)列的Shift-Net 模型可以较好地修复出缺失的眼睛,但是修复出的眼睛与眉毛之间的间距较小,不能在视觉上产生真实感。本文模型已经能够较好地修复出缺失的复杂结构信息,修复出的眼睛在视觉真实程度略优于Shift-Net模型,但是在眼睛的细节生成上还有所欠缺。第四行实验遮住了鼻子以下的部分进行修复,虽然本文模型的修复结果较好,略优于其他几个模型修复的结果,但是在脸颊的左边还是有一些伪影。总的来说,本文提出模型在CelebA 数据集上规则掩膜的修复结果在视觉上也优于其他几个对比模型。能够修复出较好的结构信息,但是在修复结果细节上还有所欠缺。

图7 CelebA 数据集上规则掩膜修复结果Fig.7 Regular mask repair results on CelebA datasets
图8 所示为各个模型对ParisStreet-View 数据集上规则掩膜遮挡的修复结果,实验共取7 张图像并对图像中心进行固定大小的规则掩膜遮挡,具体每列所代表的模型同图6 一致。由图8 的修复结果可以看出,作为传统图像修复方法的FFM 模型的修复结果不太乐观,很难很好地修复出建筑图像缺失部分的纹理结构以及语义信息。而DIP 模型虽然在修复人脸信息上效果不是很好,但在修复建筑图像上效果较好,尤其是第6、7 行,DIP 模型较好地修复出了窗户的结构信息,但是也产生了些模糊。而经过训练的Shift-Net 模型和本文模型则较好地修复出了图像缺失的复杂结构信息,并生成逼真的结果。从图8 的7 张建筑图像修复结果的模糊程度上看,本文模型相较于Shift-Net模型产生了较少的模糊。但是,在第一行的修复结果上,相对而言,Shift-Net 的修复结果更加具有真实性,Shift-Net 模型很好地修复出了上下两扇窗户的分界,而本文模型则产生上下窗户相连的结果,缺少了些许的真实性。总的来说,本文提出模型在ParisStreet-View 数据集上规则掩膜的修复结果已经能够很好地还原了原图像缺失的复杂结构信息,并且在视觉上略优于Shift-Net 的修复结果,与其他两个对比模型相比有较大的优势。

图8 ParisStreet-View 数据集上规则掩膜修复结果Fig.8 Regular mask repair results on ParisStreet-View datasets
图9 则是各个模型对ParisStreet-View 数据集上不规则掩膜遮挡的修复结果对比,实验选取4 张建筑图片并对它们使用不规则掩膜遮挡处理,每一列所代表的模型与图6 相同。由图9 可以看出,在图像修复结果的语义性上,本文模型和Shift-Net模型修复的结果较好,都能修复出较好的复杂结构信息和缺失部分的语义信息,但是Shift-Net 的修复结果较模糊。在第一行的修复结果中,随机掩膜遮挡了最左边一辆车,本文模型的修复结果已经接近物体移除的效果,而其他几个模型则很难做到这一点。在第三行的修复结果中,Shift-Net 模型、DIP 模型和FFM 模型对商店门牌的修复都较为模糊,而本文的模型很好地修复了被遮挡的文字部分。相较于本文模型和Shift-Net 模型,DIP 模型和FFM 模型在建筑图像不规则掩膜遮挡修复的表现不是很出色,DIP 模型会产生一些模糊现象,而FFM 模型则会产生扭曲的结果。但是,DIP模型在第四行对商店门牌的修复上较成功,虽然没有修复出文字部分,但是门牌修复结果在像素上足够真实。总的来说,本文提出模型在ParisStreet-View 数据集上不规则掩膜修复结果在视觉上是明显优于其他几个模型的,而且对于缺失部分的结构修复以及细节修复表现较好。

图9 ParisStreet-View 数据集上不规则掩膜修复结果Fig.9 Irregular mask repair results on ParisStreet-View datasets
除了最终修复的定性分析之外,实验还对中间过程中的纹理修复结果进行了提取,具体结果如图10所示,(a)~(d)列分别为原图、待修复图像、边缘修复图和最终修复结果图。实验分别取CelebA 数据集和ParisStreet-View 数据集上规则掩膜和不规则掩膜结果各一张进行展示。由图10 的(c)列可以发现,边缘生成模型能够较好地修复出模型缺失部分的边缘信息,尤其是该列的第一张和最后一张,边缘修复模型很好地修复除了缺失眼睛的结构信息,但是细节上生成得不够充分,造成了模型对第一行的样本图像修复时眼球的细节修复不够完善,使用更大分辨率的图像训练模型应该可以解决该问题。

图10 边缘指导图像修复方法结果展示Fig.10 Results of edge-guided image repair method
4.2 定量分析
除了视觉上的定性分析之外,实验还对模型修复结果进行定量指标分析。所选的评估指标为峰值信噪比PSNR 和结构相似度SSIM。
表1 所示为本文模型、Shift-Net 模型、DIP 模型及FFM 模型在CelebA 数据集和ParisStreet-View 数据集上规则掩膜修复结果的PSNR 和SSIM 指标对比。实验随机从CelebA 测试集和ParisStreet-View 测试集各取100 张图片,使用规则的掩膜遮挡处理各得到100张待修复图像,使用本文模型、Shift-Net 模型、DIP 模型以及FFM 模型4 个模型进行修复,将修复结果与原图进行比较并计算平均PSNR值和平均SSIM值。
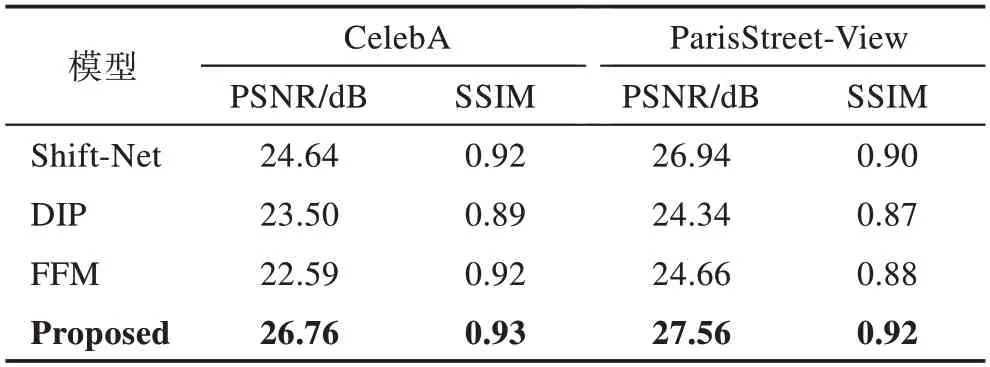
表1 不同数据集上规则掩膜修复结果对比Table 1 Regular mask repair results comparison on different datasets
由表1 的结果可以看出,在CelebA 数据集和ParisStree-View 数据集上进行规则掩膜遮挡修复实验,本文模型的修复结果在PSNR 和SSIM 指标上略优于Shift-Net 模型,对比DIP 模型和FFM 模型则具有较大的优势,这也对应了定性分析中各个模型修复结果的视觉对比结果。
表2 所示为本文模型、Shift-Net 模型、DIP 模型以及FFM 模型在CelebA 数据集和ParisStreet-View 数据集上不规则掩膜修复结果的PSNR 和SSIM 指标对比。实验与规则掩膜修复结果比较相同,在两个数据集上随机各取100 张图片,使用随机掩膜测试集中的掩膜遮挡处理各得到100 张待修复图像,使用4 个模型修复并比较结果与原图之间的平均PSNR 值和平均SSIM 值。

表2 不同数据集上不规则掩膜修复结果对比Table 2 Irregular mask repair results comparison on different datasets
由表2 可以看出,本文模型在不规则掩膜下的修复结果在PSNR 和SSIM 指标上依然领先其他3 个模型。但是,相较于规则掩膜修复结果的PSNR 和SSIM,不规则掩膜下修复结果的PSNR 和SSIM 指标略有下降,因为不规则掩膜可能遮挡了图像中的较多关键信息,而且不规则掩膜容易遮挡距离较远、相关性不高的图像区域,修复的结果与原图比较差距较大,规则掩膜大多遮挡较少的关键信息,而且规则掩膜遮挡的区域大多连贯,相似性较高。
除此之外,本实验还分析了掩膜大小的不同对修复结果的影响。在CelebA 数据集和ParisStreet-View 数据集各取50 张测试图片,使用大小为20~90,每次大小增加10 的掩膜进行测试,每个大小每个数据集有50 个样本数,计算平均PSNR 值和平均SSIM值,结果折线图如图11 所示。由图11 可以直观地看出,随着掩膜规模的增大,修复结果在PSNR 指标和SSIM 指标上随之下降,因此可以得出结论:图像被遮挡部分越大,修复的结果与原图相似度就越低。

图11 不同掩膜下修复结果与原图的对比曲线Fig.11 Comparison curves of repair results and original image under different mask sizes
实验对比分析了本文模型和Shift-Net 模型下不同大小掩膜修复结果的PSNR 和SSIM 指标。首先对于CelebA 数据集,本实验取100 张测试图片。不同于上文实验的固定大小掩膜,实验使用百分比取掩膜进行测试,分别取图片10%、20%、30%、40%、50%、60%大小的掩膜进行测试。在CelebA 数据集上的对比结果如图12 所示。由图可见在CelebA 数据集上本文模型的修复效果在PSNR 指标和SSIM 指标上均略优于Shift-Net 模型。而且,从图中可以看出,随着掩膜越来越大,本文模型和Shift-Net模型修复结果的PSNR 指标和SSIM 指标的差距越来越大。
对于ParisStreet-View 数据集,实验还是取100 张测试图片,掩膜大小与CelebA 数据集上的实验相同。在ParisStreet-View数据集上的对比结果如图13所示。由图可见在ParisStreet-View 数据集上本文模型表现依然略优于Shift-Net模型。对比图12 所示的CelebA数据集上的对比结果,本实验修复结果的PSNR 值和SSIM 值均略低于图12 的实验,因为CelebA 数据集是人脸数据集,不同人脸的构造基本相同,所以修复结果的容错率较高,很容易生成缺失的器官且与原图类似。反观ParisStreet-View 数据集,这是一个街景数据集,数据集中的图片构造差距都比较大,因此模型学习生成的内容很难与原图相同。

图12 CelebA 数据集不同掩膜大小下修复结果对比Fig.12 Repair results comparison on CelebA datasets under different mask sizes

图13 ParisStreet-View 数据集不同掩膜大小下修复结果对比图Fig.13 Repair results comparison on ParisStreet-View datasets under different mask sizes
5 结束语
本文提出了一种基于生成对抗网络的图像修复模型,模型分为边缘修复模型和内容填充模型两部分,实验证明了模型在处理图像复杂结构缺失的情形时修复效果是优于现有的一些模型的,这也反映了边缘信息在图像修复过程中具有很重要的作用。但是,本文模型在处理极具细节纹理特征区域的修复时还是会产生一些模糊,这是未来研究需要改善的地方。
