改进的U-Net在视网膜血管分割上的应用
2022-03-13谷鹏辉肖志勇
谷鹏辉,肖志勇
江南大学 人工智能与计算机学院,江苏 无锡214122
眼底视网膜血管分割在糖尿病、高血压、早产儿等眼部相关疾病的诊断中具有重要作用。然而,传统的需要专业医生进行手工标注血管的方法不仅任务量大,而且耗时且容易出错。
在过去的几十年里,为了解决这个问题,许多算法被提了出来,所提算法可以分为两大类。一类是非监督学习算法。例如Azzopardi 等人设计出了BCOSFIRE 滤波器,该滤波器可以对不同方向上的血管主干和末端进行精确检测,尤其对细小的血管有很好的检测效果。另一类是监督学习的算法,利用事先标记好的血管点和背景点,再通过构造好的模型来学习输入到输出间的映射关系,不断调整模型。例如Lupascu 等人首先为视网膜图像中的每个像素点构造一个对应的特征向量,然后用训练样本训练了一个AdaBoost 分类器,最后用训练好的分类器将像素点进行分类。
近年来,随着深度神经网络的发展,在医学图像处理领域深度神经网络也取得了良好的效果。Ronneberger 等人提出了一种具有跳跃连接结构的U-Net,让解码层更好地利用编码层获得的特征信息;然而U-Net 的跳跃结构并不能有效利用这些结构信息,会影响血管分割的性能。代洋洋等人提出了UU-Net,借鉴了级联U-Net 的构想,以U-Net 为核心模块构建的U 形网络,在U-Net 内部引入残差结构代替普通卷积,使得网络深度增加,能获取更多的信息,同时延缓模型训练中的梯度消失;在U-Net 模块之间对特征图进行Addition 或者Concatenation 操作,构建出多条传递信息的路径,每一条传递信息的路径实质是一个FCN(fully convolution network)变体。Zhang 等人提出AG-Net,将注意力机制加入了传统的指导滤波器形成注意指导滤波器,可以从不同分辨率的特征图中恢复空间信息和合并结构信息,去除引入的复杂背景中的噪声成分。Liu 等人提出了一种无监督集成策略,通过无监督集成网络将多个基础网络所得到的血管分割结果融合起来得到更好的分割效果。Li 等人提出IterNet,用标准U-Net 作为一个基础架构,然后通过迭代的精简U-Net 去发现更多的血管细节,可以将断着的血管连接起来。
上述方法能够有效地分割血管的主要部分,但是不能够解决由于血管边界非血管像素部分包含血管像素的一部分而使网络误将其分类为血管的问题。本文提出了一种基于编/解码模式的眼底血管分割算法。通过在编码阶段使用GCN(global convolutional network)模块和BR(boundary refinement)模块替换传统的卷积操作来解决血管边界非血管像素误分为血管的问题;为了改善低对比度下血管分割的效果,本文将文献[10]中的注意力模块进行了改进,在跳跃连接部分添加了改进后的位置注意模块(position attention,PA)和通道注意模块(channel attention,CA);还在编码部分使用DenseNet,受刘辰等人将ConvLSTM 应用在医学图像分割,并且取得良好性能的启发,在解码阶段使用ConvLSTM来更好地获取特征信息,得到更好的分割效果。
1 相关工作
1.1 卷积长短记忆网络
由于普通的循环神经网络(recurrent neural network,RNN)无法解决长时依赖问题,还可能带来梯度消失或梯度爆炸问题,为此Hochreiter 等人提出了长短记忆网络(long short-term memory,LSTM)。已经证明,LSTM 能够有效解决长序列依赖问题。
传统的LSTM 在数据的处理上能力非常强,但是如果时序数据是图像,传统的LSTM 由于在输入到端和端到端的转换中使用的是全连接操作,不能够有效获取图像的空间信息。为了解决这个问题,Shi 等人提出了ConvLSTM 模型,用卷积操作来替换全连接操作去实现从输入到端和端到端的转换。ConvLSTM的定义如下,其中,*表示卷积函数,∘表示哈达玛函数,是Sigmoid 函数,x是输入张量、C是记忆张量、h是隐藏张量,b、b、b、b是输入、遗忘、激活和输出状态的偏置项,W是对应于输入状态的权重矩阵,W是对应于隐藏状态的权重矩阵,tanh 是双曲正切函数。
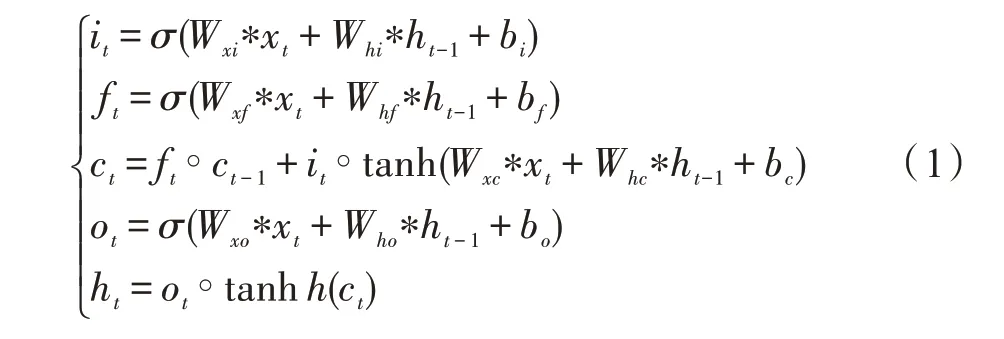
1.2 密集卷积网络
在传统的U-Net 中包含一系列的卷积操作来学习不同类型的特征,然而在这样连续的卷积操作中会学习到一些冗余的特征,为了缓和这个问题,Huang等人提出了DenseNet结构。
DenseNet是受到残差网络(residual network,ResNet)的启发而设计出来的。与残差网络的相同之处在于每一层的输入与前边层有关。主要不同之处是,ResNet 对于每一层,其输入的特征是之前有限层的输出。而DenseNet 对于每一层,其输入的特征是之前所有层的输出。并且每一层的输出特征则作为之后所有层的输入。DenseNet的结构如图1所示。
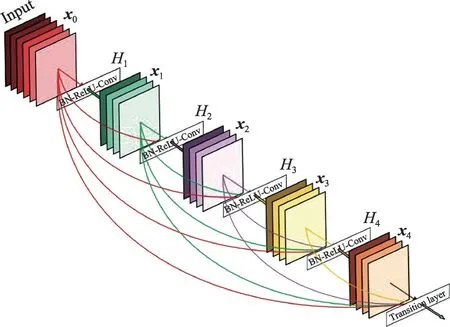
图1 五层的DenseNet模块Fig.1 Five layers of DenseNet modules
图1 显示了一个包含五层,层宽度为=4 的稠密模块,层与层之间的激励函数(即H(·))为BNReLU-Conv(3×3)的结构。第层将它之前-1 层所输出的特征图[,,…,x]作为输入:

其中,~x代表前面层的输出。
1.3 全局卷积网络和边界细化
为了同时提升网络在视网膜血管分割的定位和分类能力,本文引入了GCN 模块,其结构如图2 所示:它使用由1×与×1 和×1 与1×的卷积操作的结合来代替用×的卷积核进行卷积。其中、为图片宽度和高度,为输入图片的通道数,为输出图片的通道数。与普通的×卷积相比,GCN 的计算复杂度和参数量只为(2/),得到了缩减。在本实验中,的值为3,激活函数为ReLU。
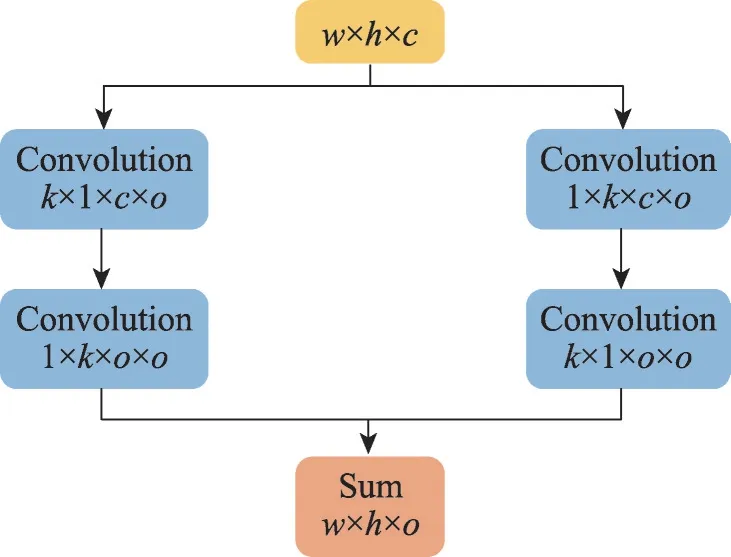
图2 全局卷积网络Fig.2 Global convolutional network
因为血管边界非血管像素含有部分血管像素,所以网络将其误分为血管像素等现象会使得血管边界难以识别。为了提升网络在血管边界的分割能力,引入了BR 模块,其结构如图3 所示:其中、为输入图片的宽度和高度,为输入图片的通道数,为所用卷积操作对应的卷积核的大小,本文定义*为得到的特征图*=+(),其中为输入的特征图,(·)是一个卷积核为×激活函数为ReLU 的卷积操作和一个卷积核为×没有激活函数的卷积操作。经过(·) 得到的特征图与输入的特征图进行Add 操作得到最终的特征图。
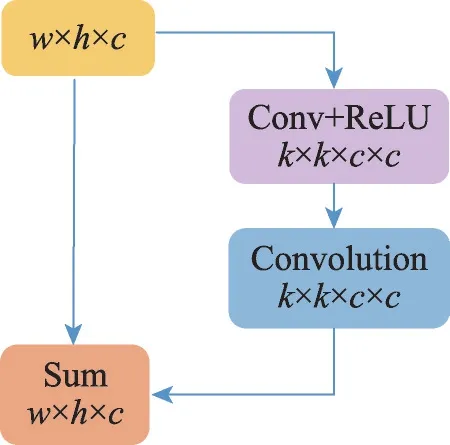
图3 边界细化Fig.3 Boundary refinement
2 网络结构与算法原理
2.1 网络结构
本文提出的AtGBU-Net(Attention_GCN_BR_UNet)框架,如图4 所示。本文算法采用编/解码模式的网络架构,因为传统U-Net 的卷积操作不能精确地对血管边界进行分割,并且不能兼顾在眼底血管分割任务中同时需要的定位和分类能力,所以在编码部分用GCN+BR 来替换传统的卷积运算。为了解决在低对比度情况下将血管与背景分隔开,本文采用了两种方式:一种是对图像进行了预处理,提高了图像的对比度并且缓解了中心血管线反射的现象;另外一种是在跳跃连接部分加入了改进的自适应注意力机制,将包含更丰富空间信息和语义信息的特征图结合起来,从而去除背景中的噪声部分。为了防止过拟合,在编码的最后一层采用DenseNet的思想。为了更好地提取特征,在解码部分加入了ConvLSTM。
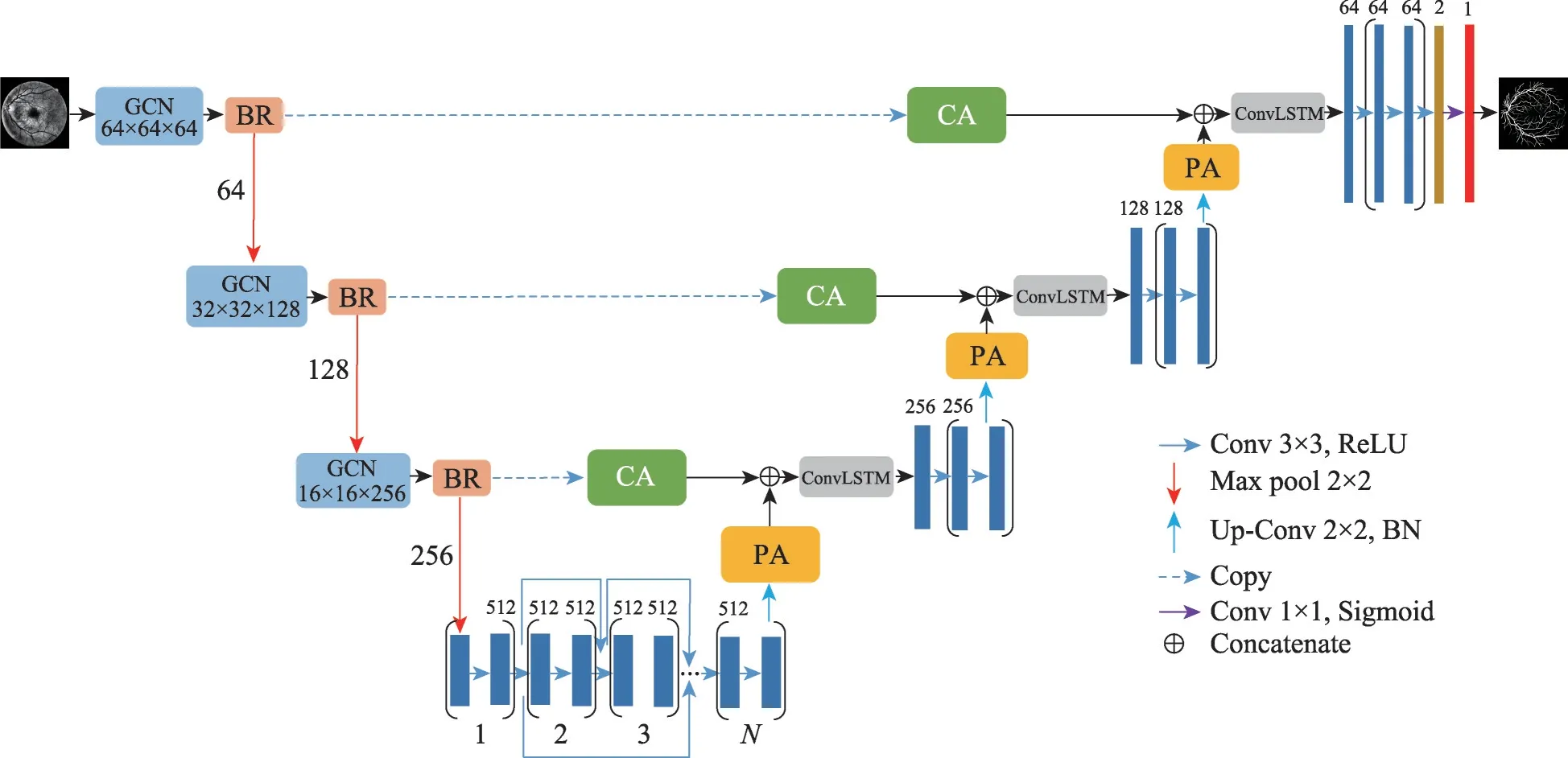
图4 网络结构Fig.4 Network mechanism
编码部分主要负责对特征图进行特征提取。主要包括四层:前三层的每一层由一个GCN 模块和BR模块构成;再加上批归一化层(batch normalization,BN),BN 有助于加快网络的训练速度,并且提高模型的训练精度,归一化的结果再通过最大池化将特征映射输出到下一层;最后一层使用DenseNet 模块,它能够通过信息的流动性和重复利用性来提高网络的表示能力,而且可以从之前产生的所有特征中受益,使网络避免梯度爆炸或者消失的风险。在本文中,将两个连续的卷积作为一个Dense 块,Dense 块的个数为3,也就是图4 中的值为3,对上一层的特征映射经过3 个Dense 块,其中每个Dense 块中的卷积核尺寸为3×3,使用ReLU 作为激活函数,在每经过一个Dense 块后都进行一次Dropout 操作。解码部分主要负责对提取后的特征进行上采样。在本文中,将上采样和对应编码层的特征图分别执行改进的PA 和CA 操作,然后进行级联操作;在级联操作后,进行一次ConvLSTM 操作和2 个卷积操作;其中ConvLSTM和卷积操作的激活函数为ReLU,卷积核的尺寸为3×3;经过上采样之后,得到和输入图像分辨率相同的特征图,再经过1 个卷积核数目为2,卷积核尺寸为3×3,激活函数为ReLU 的卷积操作,和1 个卷积核数目为1,激活函数为Sigmoid,卷积核尺寸为1×1 的卷积操作获得最终的分割结果,实现端到端的分割。
2.2 算法原理
Fu 等人提出了一种具有自注意机制的双注意网络(dual attention network,DANet),通过位置注意模块来学习特征的空间相关性,通过通道注意模块来学习通道相关性。为了更好地提升眼底血管的分割效果,本文对以上两个模块进行了改进,取消模块的自适应机制,还可以得到包含更多语义信息和空间信息的特征图,与原始的模块相比,网络的复杂度也得到了降低。
为了使上采样获取的特征图包含更多的语义信息,本文在进行反卷积操作后加入了PA 模块。与文献[10]中的PA 不同,本文取消了PA 中的自适应操作,PA 模块结构如图5 所示,特征图∈R直接通过Reshape 操作得到∈R和∈R,取消卷积操作;和进行矩阵相乘得到包含丰富语义信息的特征图∈R;将与进行矩阵相乘并进行Reshape 操作得到∈R;将得到的与直接进行Add 操作和BN 操作得到最终的特征图∈R。

图5 位置注意模块Fig.5 Position attention module
为了使对应编码器的特征图包含更多的空间信息,本文在进行跳跃连接前加入了CA 模块。与文献[10]中的CA 不同,本文主要采用与提出的CA 类似的操作,其结构如图6 所示,将特征图∈R直接通过Reshape操作得到∈R和∈R;和进行矩阵相乘得到包含丰富空间信息的特征图∈R;将与进行矩阵相乘得到∈R;将得到的与直接进行Add 操作和BN操作得到最终的特征图∈R。
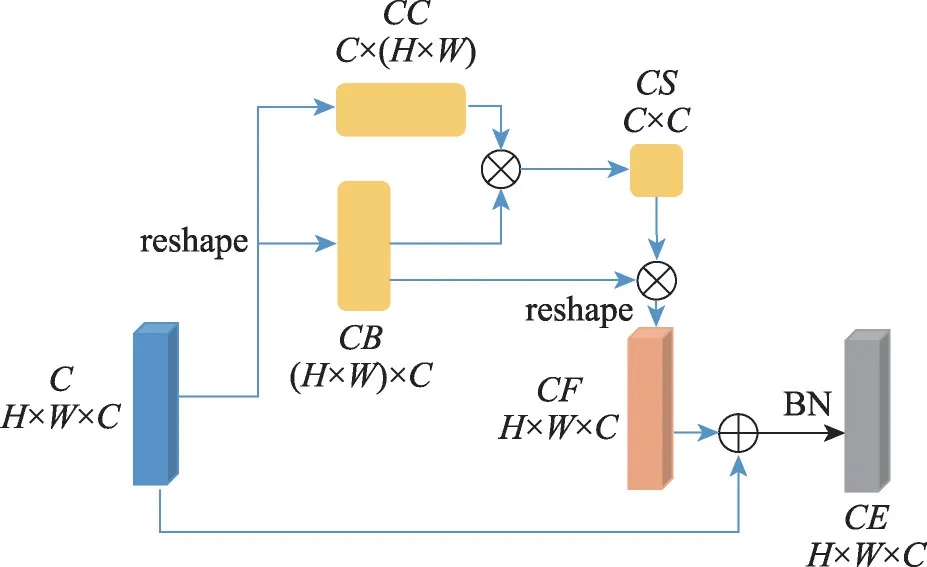
图6 通道注意模块Fig.6 Channel attention module
3 实验结果与分析
3.1 实验数据集
在DRIVE、CHASE_DB1两个视网膜眼底血管的公共数据集上对本文方法进行训练和测试。
DRIVE 数据集包括视网膜的40 幅彩色眼底图像,这些图像来自荷兰的一个糖尿病视网膜病变筛查项目,每幅图像的像素为584×565。本文将40 幅图像的前20 幅图像用于训练,其余20 幅图像用于测试。对数据集中的每幅图像都提供了二值视场mask和GT 图像。
CHASE_DB1 数据集有28 张视网膜彩色图像,每幅图像的像素大小为999×960。本文中,前14张图像用于训练,其余14 张图像用于测试。对CHASE_DB1中的28 幅图像都提供了分割的GT 图像。
由于眼底视网膜数据集的数据量较少,而深度学习需要大量的数据集才能有更好的效果,本文对训练集进行了数据增强,包括旋转和镜像操作。对于DRIVE 数据集的20 张训练集图像和CHASE_DB1 的14 张训练集图像,扩充后,整个训练集分别有1 200张584×565 图像和1 680 张999×960 图像,并且对训练集的图片进行了分割,每张图片都切割为64×64 尺寸的patch块;最后将DRIVE训练集扩充成了120 000张64×64 尺寸的patch 块,将CHASE_DB1 训练集扩充成了168 000 张64×64 尺寸的patch 块。对于扩充后的训练数据集,其中80%用于训练,20%用于验证。测试集图片只进行了图像预处理和切片操作,没有进行数据增强,算法得到的64×64 尺寸的patch 块再合并成对应的图片。
3.2 实验环境
本文实验是在Keras2.3.1 下进行的。使用he_normal 方法对权重进行初始化,采用二分类交叉熵损失函数,学习率使用Keras 中的回调函数ReduceLROnPlateau 来进行调整,通过检测值的变化幅度来调整分辨率,本文的检测值是验证集损失;采用Adam 优化器更新参数;并用Keras 中的回调函数ModelCheckpoint 来保存最优模型,它的原理是通过判断一个指标来决定是否更新模型参数;本文中取验证集损失最小的模型;训练与测试的Batchsize 分别取8 和16。
3.3 评价指标
为了评估本文算法的性能,选用敏感性()、准确性()和1-来评价本文算法的性能,评价指标的定义如下:

其中,真阳性(true positive,TP)表示将血管正确分类的像素点数;真阴性(true negative,TN)表示将背景正确分类的像素点数;假阳性(false positive,FP)表示将背景错误分类的像素点数;假阴性(false negative,FN)表示将血管错误分类的像素点数。
还通过受试者工作特征(receiver operating characteristic,ROC)曲线来评价。ROC 曲线以真阳性率为纵坐标,假阳性率为横坐标。(area under ROC curve)面积是ROC 曲线与横轴之间的面积,的值越接近1 表示模型的分割能力越好。
3.4 实验结果
韩铖惠等人通过对图像进行预处理增加前背景对比度,来提高分割性能。由于在采集视网膜图像的时候会受到光照不均匀等因素的影响,从而造成血管与图像背景的对比度较低,而且有血管中心线反射等问题,因此本文对眼底视网膜图像进行图像预处理来提高血管与背景的对比度。具体步骤如下:
(1)将RGB 形式的眼底视网膜血管图像转换为对应的灰度图像。
(2)将灰度图像进行自适应直方图均衡化,去提升血管与背景的对比度并且抑制噪声。本文中,颜色对比度的阈值设置为10.0,进行像素均衡化的网格大小设置为(8,8)。
(3)利用局部自适应伽马矫正,将视网膜图像进行矫正,使得光照不均匀因素与中心线反射现象加以抑制。本文中,伽马因子设置为1.0。
经过预处理,图像变为了灰度图像,血管与背景的对比度增加,血管中心线反射的问题得到了抑制。预处理结果如图7 所示。图7 左为原始图片,图7 右为预处理后的图片。
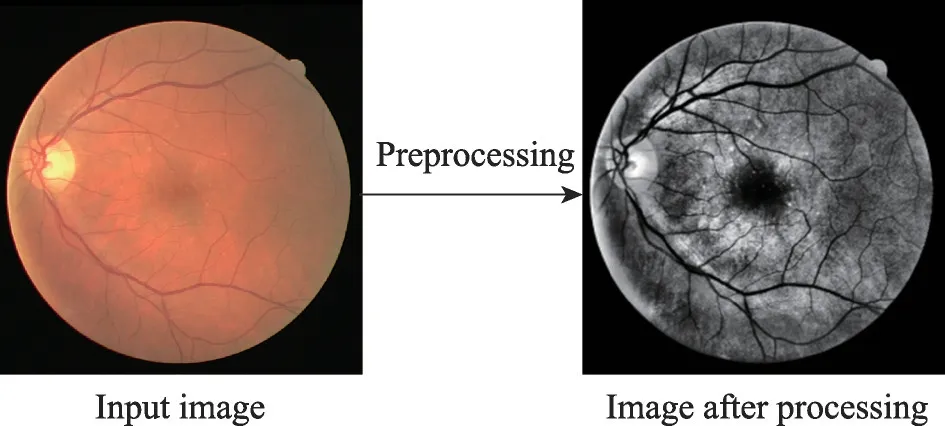
图7 预处理结果Fig.7 Preprocessing results
在数据集上是否预处理结果如表1 所示。通过预处理提高了血管和背景的对比度,网络可以更容易地学习血管和背景的区别,从而将背景误分为血管的像素点数减少,因此预处理后的精度明显高于未预处理的精度,尤其是敏感性指标上。
由于网络得到的是一张二维的灰度图,是血管分布的概率图,本文通过最大类间方差算法自动地寻找最佳阈值,来进行阈值分割实现二值化。通过后处理,背景被误认为血管的像素减少,缺点是会把部分血管误认为背景,但是后处理之后的图像,血管部分与GT 相比差距不大,与后处理前的图像相比噪声问题也得到了有效的解决,后处理前后对比如图8所示,其中图(a)、图(b)和图(c)分别是GT 和后处理前后的结果,可以看出图(c)相比于图(b)少了很多的噪声点,可是也会把一部分血管像素给去除掉。后处理结果如表1 所示,通过后处理,算法的性能得到了提升,进一步验证了后处理的效果。
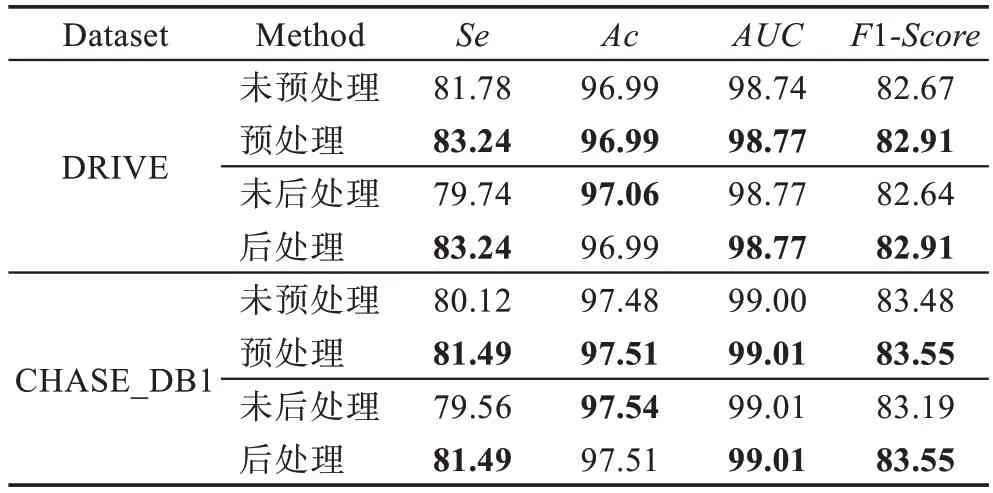
表1 预/后处理结果比较Table 1 Comparison of pre/post processing results %
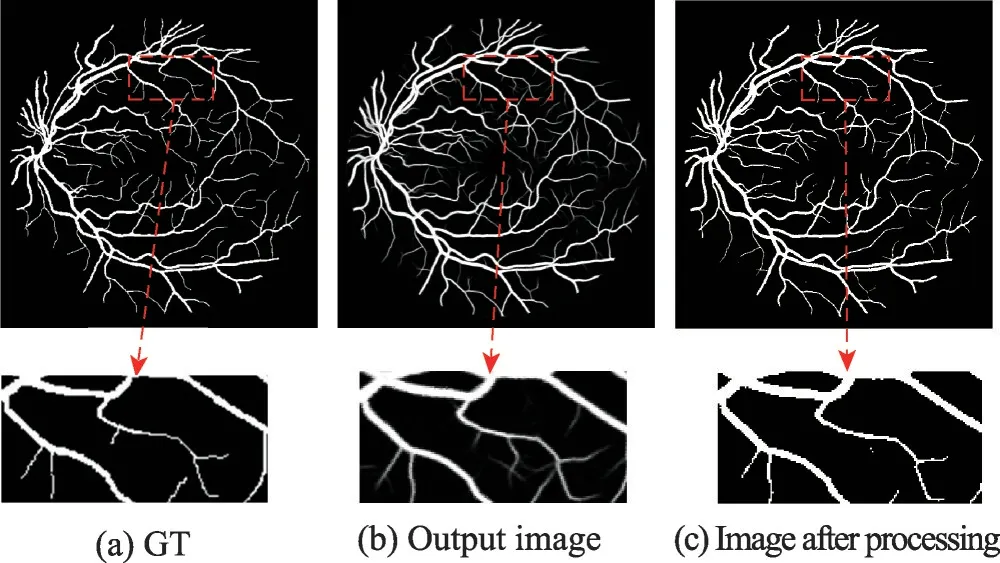
图8 后处理结果Fig.8 Post-processing results
为了验证本文提出的改进策略可以有效提高算法在视网膜血管上的分割性能,本文做了三组对比实验来说明GCN+BR、ConvLSTM、CA+PA 可以在一定程度上提高算法的分割性能。
多种改进策略结果如表2 所示。本文利用对称的可分离的滤波器GCN 和BR 模块作为一个边界对齐的残差模块来代替传统的卷积操作提升算法在血管边界的分割能力,性能得到了较大的提升,尤其是和指标。本文在解码部分通过利用ConvLSTM 的长时记忆能力来解决算法的梯度消失问题,使算法更好地提取特征信息,从而提升分割性能。为进一步提升算法的分割性能,通过加入CA 使解码器以不同程度的权重利用到编码的所有信息,并且在上采样部分加入PA 来提升所获特征图的语义信息。为了防止过拟合问题,在编码层的最后一层使用密集卷积网络的思想。表2 的结果验证了本文算法的有效性。

表2 多种改进策略的分割算法的比较Table 2 Comparison of segmentation algorithms of several improved strategies %
为了更好地验证本文算法的性能,本文将在DRIVE 数据集和CHASE_DB1 数据集上把提出的分割算法与一些最先进的算法进行比较,算法性能都是算法对应论文中的性能,不同分割算法在DRIVE数据集和CHASE_DB1 数据集上的比较结果分别如表3、表4 所示。
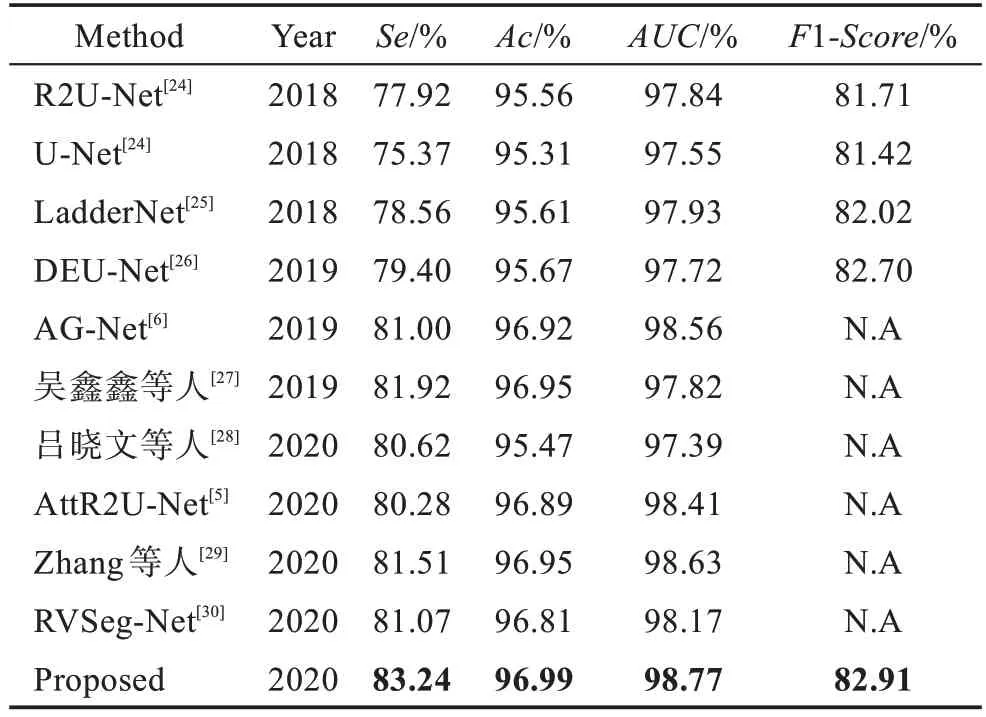
表3 DRIVE 数据集不同算法的结果Table 3 Results of different algorithms on DRIVE dataset
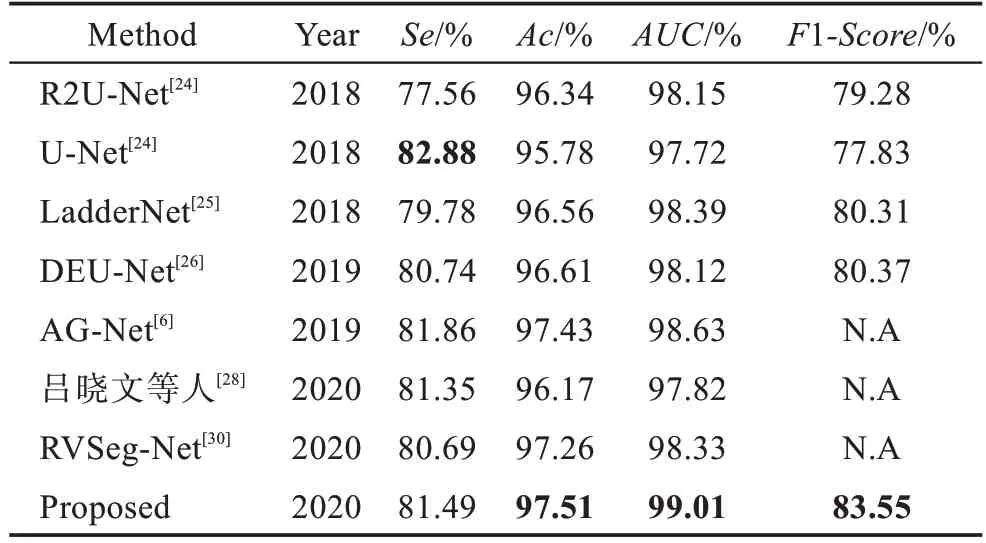
表4 CHASE_DB1 数据集不同算法的结果Table 4 Results of different algorithms on CHASE_DB1 dataset
由表3 可以看出,本文在DRIVE 数据集上的、、和1的评价结果分别达到83.24%、96.99%、98.77%、82.91%,均优于其他算法。和基准的U-Net 相比,所有指标都取得了更好的性能,而且有较大的差距。由表4 可以看出,本文在CHASE_DB1 数据集上的、和1的评价结果分别达到97.51%、99.01%、83.55%,均优于其他算法。与基准的U-Net 相比,4 个指标中的三方面都取得了更好的性能,除了有些低于U-Net。为了更好地说明本文算法的有效性,图9 显示了本文方法在两个数据集上的可视化分割结果。其中,第一列为原始RGB 眼底视网膜测试图像,第二列为GT 图片,第三列为U-Net 的分割结果,第四列为本文算法结果,前两行为在DRIVE 数据集上的预测结果,后两行为在CHASE_DB1 数据集上的预测结果。可以发现,本文算法能够识别血管的主要部分,相较于U-Net,可以发现更多的血管末梢部分。以上结果说明了本文算法在血管分割方面的强大能力。
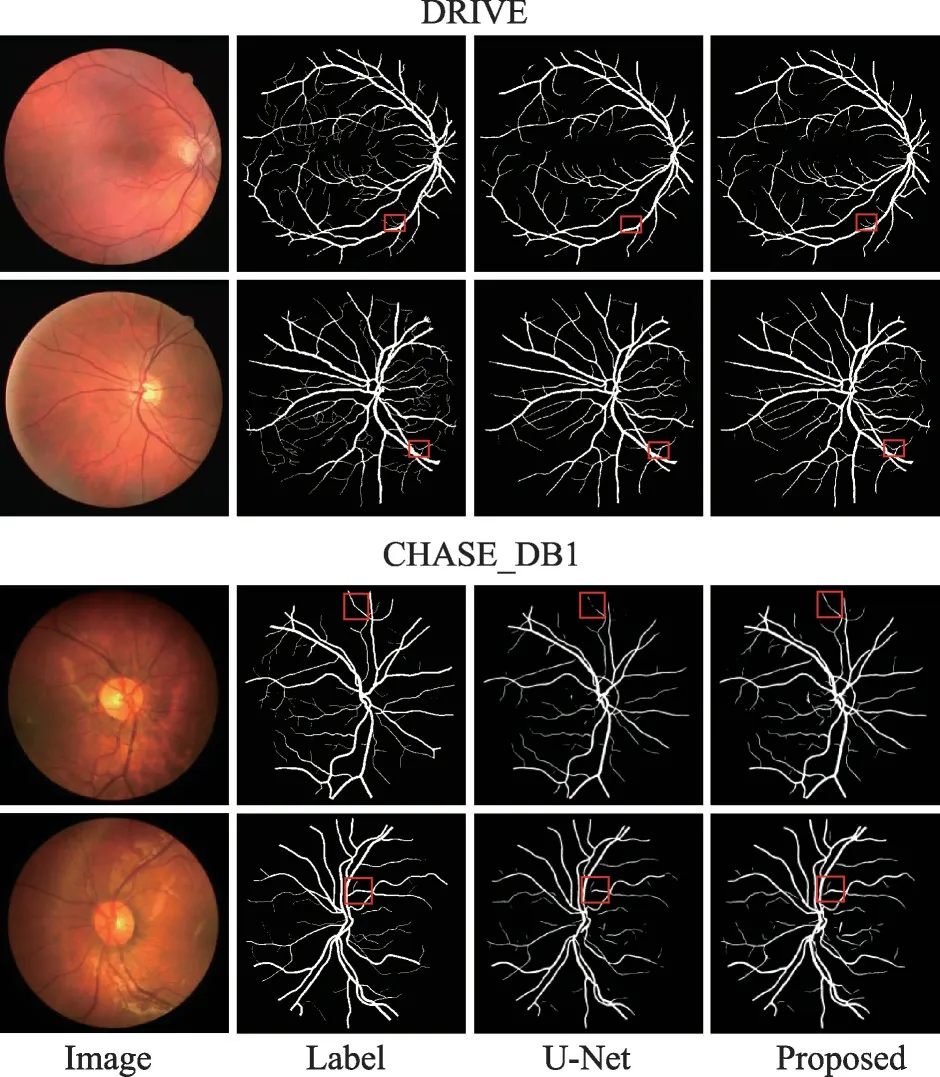
图9 不同模型的分割结果Fig.9 Segmentation results of different models
4 结束语
针对视网膜血管分割中分割血管边界和低对比度区域的问题,本文提出了一种引进注意力机制的边界细化网络。在下采样过程中将原始的卷积层替换为全局卷积和边界细化,使网络更好地分割血管边界,同时也提升网络的定位和分类能力;在跳跃连接部分引入注意力,将血管与背景的差别变大,提高血管的分割效果;在编码的最后一层使用DenseNet思想缓解过拟合问题,在上采样过程使用ConvLSTM提升网络的特征提取能力。实验结果表明,本文在DRIVE 和CHASE_DB1 这两个数据集上相较于传统U-Net能够取得更好的分割效果。
