耦合用户公共特征的单类协同过滤推荐算法
2022-03-13张全贵胡嘉燕
张全贵,胡嘉燕,王 丽
辽宁工程技术大学 电子与信息工程学院,辽宁 葫芦岛125105
协同过滤是推荐系统的一种重要方法,它通过分析用户和项目(如商品、电影、音乐等)之间的历史交互信息预测新的用户-项目交互。在协同过滤领域,由于一些公开竞赛(如Netflix 竞赛)和公共数据集的出现,大部分研究都是基于显式反馈信息(如五级评分)。这类研究一般利用历史评分信息进行评分预测,常作为回归问题或多分类问题处理。然而,在实际场景中,显式反馈信息相对难以获得。相反,在线系统中提供了更多的隐式反馈信息(如页面链接点击、视频观看、产品购买以及其他用户-项目交互历史记录)。近年来,隐式反馈推荐领域的研究受到越来越多的关注。隐式反馈协同过滤由于缺少负反馈信息,一直作为单类协同过滤(one-class collaborative filtering,OCCF)问题研究。
由于隐式反馈数据的不确定性、极度稀疏性和不平衡性,仅使用隐式反馈信息很难获得较高的推荐精度。针对这一问题,研究人员对OCCF 进行了一定的扩展。Yao等人将上下文信息融入到OCCF中,并提出了基于上下文感知的个性化随机游走(contextaware personalized random walk,CPRW)和基于语义路径的随机游走(semantic path-based random walk,SPRW)方法。文献[8]在OCCF 中融入了丰富的用户信息,如用户的搜索查询历史、购买和浏览行为等。文献[9]提出了一种基于地理位置信息和功能描述的情境偏好评分的推荐方法。Pan 等人提出了一种新的假设,在贝叶斯个性化排序(group preference based Bayesian personalized ranking,GBRP)中引入群体偏好而不是单独引入个体偏好,从而放宽了对个体的独立性假设。
以上研究的出发点均是将一些辅助信息融入到OCCF 模型中,以提高推荐准确性。这些工作大多是直接使用原始显式特征或其交叉特征,但这种方式很难获得显著的性能改进,因为难以判断哪些显式特性真正重要。基于此,本文提出了一种耦合用户公共特征的单类协同过滤推荐算法(one class collaborative filtering recommendation algorithm coupled with user common characteristics,UCC-OCCF),该算法不是直接使用显式特征或交叉特征,而是通过建立一个深度神经网络学习当前用户的邻居对项目类别的共同偏好。本文“邻居”的概念不同于文献[2,12],他们将“邻居”定义为具有相似兴趣的用户(例如,用户-项目评分矩阵中有相似项目的用户)。在本文中,邻居是指具有与当前用户相似的显式特征(如人口统计学信息)的用户,本文称之为自然邻居。本文假设具有相似显式特性的用户存在共同偏好。此外,利用自然邻居代替直接使用显式特征,并且利用深度神经网络学习抽象知识的能力,可以获得用户显式特征与项目类别之间的高层次交互关系。
本文工作具有以下三点贡献:
(1)提出了一种基于显式特征和隐式反馈信息相结合的深层神经网络结构,以提高OCCF 的性能。
(2)通过学习当前用户的自然邻居与某一类项目之间的交互,从而间接学习用户的显式特征与项目类别之间的高层次交互关系,以充分发挥显式特征的作用。
(3)通过在三个实际数据集上的实验评估,验证了该模型的推荐性能优于基线模型。
1 相关工作
深度神经网络在表示学习领域具有突出的能力,如在计算机视觉和自然语言处理及语音识别中,深度学习均显示出了有效学习抽象表示的潜力。近年来,深度学习开始应用于推荐系统领域。如文献[13]提出了一个基于神经网络的协同过滤模型,它将一个浅层的矩阵分解(matrix factorization,MF)神经网络和一个NCF(neural collaborative filtering)多层感知器结合起来,学习用户-项目的隐式交互。本文将个人深度潜在因素表示网络(deep latent factors representation,DLFR)与基于邻居的共同偏好表示网络(neighborhood based common preference representation,NB-CPR)相结合,实现了个人用户-项目交互与邻居共同偏好表示的协同训练网络。
本文工作的动机与文献[10-11]类似,都是将用户显式特征集成到OCCF 中。文献[10]提出了一个深度神经网络联合训练浅层模型和深度模型(jointly trained wide linear models and deep neural networks,Wide&Deep)。文献[11]建立了一个结合了用于推荐的因子分解机器和用于特征学习的深度学习神经网络结构(deep neural network and factorization machine,DeepFM)模型,与谷歌的Wide&Deep 模型不同,它使用共享的原始特征作为Wide 模型和Deep 模型的输入,而不需要特征工程。本文通过学习当前用户的邻居和项目类别之间的隐式交互使用显式特征,而不是直接将显式特征作为模型的输入。
本文工作出发点与文献[2,17]有共同之处,均是将用户的共同偏好融合到协同过滤模型中,通过学习群体的共同偏好来提高协同过滤的准确性。但是,他们的工作中“群体”仅是根据用户历史行为构建的。文献[17]将聚类算法应用于用户和项目的潜在向量,然后利用聚类级评分矩阵上的MF 来提高评分预测精度。另外,文献[18-20]均是利用显式特征来提高OCCF 的性能,说明使用显式特征提高推荐性能是一项具有意义的工作。基于以上工作,本文采用间接利用显式特征的方式,利用深度神经网络模型学习用户深层抽象共同偏好,以提高OCCF的性能。
2 本文提出的方法
2.1 问题描述
在单类协同过滤问题中,用户集={,,…,u}包含个用户,项目集={,,…,v} 包含个项目,用户与项目之间的交互构成交互矩阵(记为)。中的每个元素(记为y)表示一个用户与一个项目之间是否交互。如图1 所示,若用户与项目之间存在交互,则y表示为1(例如,用户购买了项目或用户观看了电影);空元素表示用户与项目之间没有交互。与评分预测问题不同,OCCF的目的是预测中未观测项目是否为1。

图1 基于隐式(单类)反馈信息的用户-项目交互矩阵Fig.1 User-item interaction matrix with implicit(one-class)feedback
本文使用的数学符号如表1 所示。

表1 数学符号Table 1 Mathematical notations
2.2 UCC-OCCF 框架
为了有效利用辅助信息,本文从较高层次间接利用显式特征,提出了一种双分支神经网络框架,称之为耦合用户公共特征的单类协同过滤推荐算法(UCC-OCCF)。如图2 所示,该框架包括两部分:个人深度潜在因素表示网络(DLFR)和基于邻居的共同偏好表示网络(NB-CPR)。

图2 UCC-OCCF 框架Fig.2 UCC-OCCF framework
DLFR 网络结构主要思想与NCF 模型相似,该模型将用户和项目ID 的独热向量(one-hot)分别输入模型中,然后分别经过嵌入层将高维稀疏向量转换为低维稠密用户和项目向量,再输入到多层全连接层中,学习当前用户与项目之间的交互概率。
NB-CPR 网络结构中,通过某种相似度度量方法计算得到的当前用户与其前个自然邻居。将得到的当前用户与其前个自然邻居和待预测项目的类别分别转换为多热向量(multi-hot)。然后将每个用户自然邻居多热向量输入到嵌入层得到每个用户自然邻居嵌入向量。随后,每个用户自然邻居嵌入向量通过神经网络的学习得到所有用户的混合嵌入向量,将其与预测项目类别的嵌入向量通过全连接层学习邻居对待预测项类别的共同偏好。
本文将DLFR 模型学习到的当前用户与项目之间的交互概率向量与NB-CPR 模型学习到的邻居对待预测项目类别的共同偏好向量融合,并送到全连接网络中联合学习得到最终的交互向量。最后,输出层中Sigmoid 函数激活,从而将其输出压缩到[0,1],表示用户与项目的交互概率。总之,UCC-OCCF的目标是通过两种网络的协同训练,预测受显式特征影响的用户-项目交互概率。
2.3 个人深度潜在因素表示网络
UCC-OCCF 框架的右侧分支是个人深度潜在因素表示网络(DLFR),其可以独立成图3 所示的模型。其作用是预测用户-项目交互的概率。潜在因素模型(如矩阵分解)是协同过滤领域的重要方法,其试图从评分模式中学习出用户和项目的潜在因素,然后利用这两个潜在因素预测评分表中的缺失评分。它试图解释用户的评分和从评分模式中推断出的用户和项目潜在因素。项目潜在因素可以用来描述项目的显式属性(如电影类型)或不可解释的属性。用户潜在因素用来描述用户对项目潜在因素中对应隐式属性的偏好。DLFR 模型在某种程度上类似于NCF 模型,将用户和项目的隐式特征连接到一个多层全连接神经网络中,学习用户和项目之间的交互。

图3 个人深度潜在因素表示网络(DLFR)Fig.3 Deep latent factor representation(DLFR)
在DLFR 模型中,分别输入用户标识和项目标识的独热向量。受文献[21-22]的启发,将用户和项目分别通过神经网络嵌入层(embedding)转换为和的两个低维稠密嵌入向量。

其中,权值矩阵W∈R和W∈R在输入层与连接层之中是一样的。
通过这一过程,模型将用户和项目映射成相同空间维度的潜在因素向量。在嵌入层之上,将潜在因素向量和输入到一个连接层中,该连接层将和对应元素相乘,输出向量代表线性用户-项目交互,表示为:

与基本的矩阵因子分解模型不同,本文模型利用内积对用户-项目交互进行建模,将向量送入多层全连接神经网络中,学习深度抽象的用户-项目交互。
经过DLFR 模型的训练,W和W两个矩阵分别表示所有用户和项目的潜在因素。由于用户和项目的编码表示为独热编码,W和W的每一列分别表示某个用户和项目潜在因素和。对于一个给定的项目,每个维度度量的是该项目具有这些因素的程度。对于给定的用户,每个维度度量的是用户对项目相应因素的兴趣程度。因此,连接层的输出向量捕获了用户和项目之间的线性交互。经过多层全连接层的处理,可以将其转换为表示用户与项目之间的非线性交互,表示为:

其中,,,…,W和,,…,b分别表示各层的权矩阵和偏置,,,…,a表示的是由ReLU 激活函数激活的每一层的输出。由于DLFR 的目标是预测用户-项目交互的概率,本文使用逻辑(logistic)回归的sigmoid 函数将该模型的输出压缩到区间[0,1],并将目标问题解释为概率:

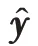

其中,是最后一层的权重矩阵;a是上一层的输出;是最后一层的偏重向量。
由于OCCF 问题没有负样本,需要用负样本采样策略抽取负样本。在本文实验中,采用类似于文献[13]的均匀负采样策略,从矩阵中未观察到的交互中抽取了负样本。


学习损失函数的参数:

2.4 基于邻居的公共偏好表示网络
下面介绍如何将NB-CPR 模型与DLFR 模型结合起来,利用显式特征来提高DLFR 模型的性能。图2①展示NB-CPR 模型的架构,该模型通过学习当前用户的邻居和项目类别之间的交互,学习具有相似显式特征用户的共同偏好。NB-CPR 的输入是当前用户自然邻居的ID,可以通过相应的相似性度量方法,如汉明距离(Hamming distance)、Pearson 相关性系数(Pearson correlation coefficient)和COS(coupled attribute similarity),从所有用户中确定邻居。通过全连接层的第一个隐藏层将用户自然邻居和项目类别转化为稠密向量。
在输入层输入当前用户的个自然邻居向量,,…,NB。NB(∈{1,2,…,})是当前用户及自然邻居用户ID 转换的独热编码,因此每个用户的用户自然邻居维数最大值为||。然后,将其送入神经网络嵌入层得到用户的自然邻居低维稠密的嵌入向量。



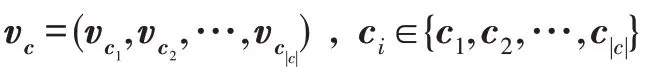
将项目类别的多热向量输入到网络中后,使用一个嵌入层将稀疏向量转换为项目类别的稠密向量。然后将用户邻居和项目类别的嵌入向量送入连接层并输出向量E,并将其输入多层全连接神经网络中,学习邻居对某类项目高层抽象的共同偏好表示,表示为:
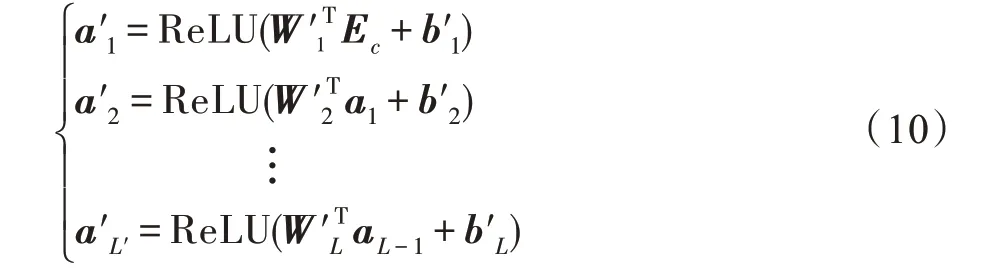
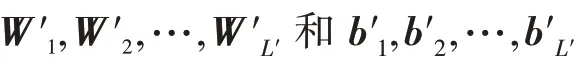





本文使用与DLFR 相同的代价函数来训练UCCOCCF 模型。
2.5 选择用户邻居方法
本节介绍如何获取当前用户的邻居。首先,使用用户的显式特征(如性别、年龄、职业和邮编等),采用某种相似度度量算法计算得到某个数据集的用户相似度矩阵(如图4 所示)。然后,为每一个用户取出前个相似用户作为该用户的邻居。本文实验中使用三个相似度度量算法:汉明距离、Pearson 相关性系数和COS。

图4 用户相似矩阵和邻居Fig.4 User similarity matrix and neighbors
汉明距离是利用类别型属性计算对象相似性的一种简单而常用的方法,其计算两个等长向量汉明距离,若两个向量对应位置的字符相同则汉明距离增加1,从而得到两个向量的汉明距离。汉明距离的值越小,两个向量相似度就越高。
Pearson 相关性系数算法考虑向量之间的变化趋势,公式如式(13)所示。

其中,(,)为数据对象,为向量总数。
COS是由Wang 和Cao 等人提出的一种基于耦合关系分析的相似度度量方法,其考虑了类别型属性之间的耦合关系,由于篇幅所限,本文不做阐述,在文献[23]中有详细介绍。本文采用三种相似度度量算法的目的是验证不同相似度度量算法对UCCOCCF 性能的影响。
3 实验与评估
3.1 数据集


表2 数据集统计Table 2 Statistics of datasets

表3 用户和项目的显式特征Table 3 Explicit features of users and items
3.2 实验环境
UCC-OCCF 是在Python 和Keras 框架中实现的。所有的实验执行于IntelCorei7-4770K@3.50 GHz处理器,32 GB 运行内存,NVIDIA GeForce GTX 1080Ti 11 GB 显卡硬件设备。
3.3 基线方法
使用以下基线方法评估本文提出的UCC-OCCF方法。
itemKNN(item K-nearest neighbor),基于项目的协同过滤方法。本文按照文献[10]的设置对OCCF进行评估,比较本文方法与传统的不使用深度学习方法的性能。
NeuMF(neural matrix factorization),这是一种利用神经网络进行隐式反馈的协同过滤方法。用它来比较本文提出的具有显式特征的方法与没有显式特征的基本神经网络协同过滤方法的性能。
Wide&Deep,这是由谷歌提出的一种包含Wide模型和Deep 神经网络的神经网络结构。在该模型中,需要对Wide 模型的输入进行特征工程(如交叉产品特征)。为了公平起见,本文将每个用户的显式特征(人口统计学信息:性别、年龄、职业、邮政编码)转换为交叉特征。将交叉特征和原始的显式特征一起输入到Wide&Deep 模型,来比较间接使用用户邻居显式特征的模型与直接使用显式特征和交叉特征的模型的性能。
NGCF(neural graph collaborative filtering),该模型通过GNN(graph neural network)的高阶连通性传播学习用户与项目的显式交互信息的作用,来比较间接使用用户邻居显式特征和用户-项目交互信息的模型与仅使用显式用户-项目交互信息模型的性能。
DeepICF(deep variant of item-based collaborative filtering),该模型不仅仅对两个项目之间的相似性建模,而且使用非线性神经网络考虑项目之间的高阶关系模型,捕获用户的决策从而提高基于项目的协同过滤的性能。用它来比较本文使用用户共同项目类别偏好联合个人深度潜在因素的模型和其项目之间高阶关系模型的性能。
3.4 评估指标
本文使用OCCF中广泛使用的留一法作为性能评估方法。与文献[13,19,31]相同,本文将每个用户最新的交互项作为测试项,其余交互项作为训练数据,随机抽取数据集中用户-项目交互项之外的99 个项目作为负样本,与测试项目一起构成用户测试数据。评估目的是对每个用户的100 个条目进行排序,利用命中率(hit ratio,HR)、归一化累积折扣信息增益值(normalized discounted cummulative gain,NDCG)和平均倒 数排名(mean reciprocal rank,MRR)来评估其性能。
上述方法公式分别为:

其中,为测试集,rel为位置处项目的分级关联值,Z为归一化系数。实验设置rel∈{0,1},若在测试数据集正例中则为1,若不在则为0。


3.5 实验设置
将数据集转换为隐式版本后,对每个正例随机抽样4 个负例。本文模型的超参数主要如表4 所示。
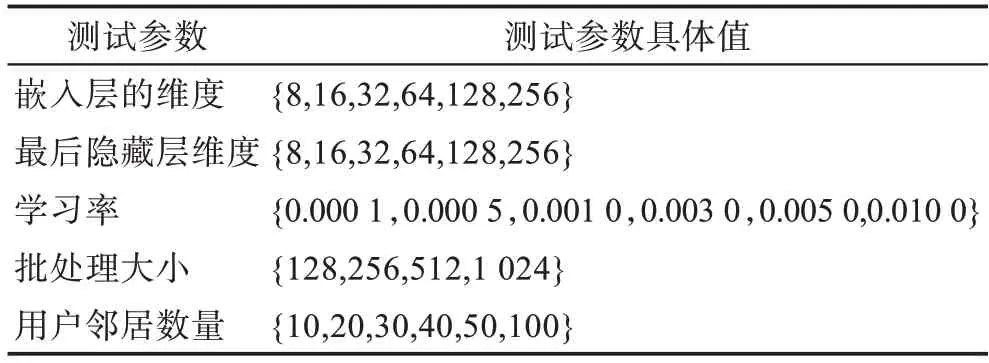
表4 测试超参数Table 4 Test hyper-parameters
本文使用ReLU 作为所有全连接层的激活函数。本实验使用Adam 优化器。对于参数初始化,使用随机正态分布(均值和标准差分别为0 和0.01)初始化嵌入矩阵,使用glorot-uniform 作为全连接层的初始化。该模型中的所有偏置项都初始化为0。
为了验证用户邻居数量对UCC-OCCF 性能的影响,本实验针对COS、汉明距离和Pearson 相关性系数度量分别采用表4 中的邻居数量进行测试。
3.6 结果分析
图5、图6 和图7 分别对比了UCC-OCCF 和基线方法在HR@、NDCG@和MRR 评估指标下的性能,测试了取1 到10 时的情况。本文从以下几个方面来讨论实验结果。

图5 HR@K 评估Fig.5 Evaluation of HR@K

图6 NDCG@K 评估Fig.6 Evaluation of NDCG@K

图7 MRR 评估Fig.7 Evaluation of MRR
(1)与基线方法的比较:对于3 个数据集上的每一个值,所有方法的性能都优于itemKNN(基本的协同过滤方法)。这说明深度学习方法的性能优于传统的OCCF 方法。
(2)Wide&Deep 和NeuMF 在3 个数据集的每个值时结果都很接近。这说明对于Wide&Deep 来说,直接使用显式特征的深度模型不一定能获得更好的性能。
(3)本文提出的使用三种度量方法的UCC-OCCF均比所有基线方法表现得更好。使用COS、汉明距离和Pearson 相关性系数度量的UCC-OCCF 在3 个数据集中性能均优于所有对比实验,如图5、图6 和图7所示。在MovieLens 1M 与NGCF 比较,HR@10 的性能分别提高了0.057、0.092 和0.120,NDCG@10 的性能分别提高了0.034、0.076 和0.213,MRR 的性能分别提高 了0.121、0.178 和0.270;在MovieLens 100K 与NGCF 比较,HR@10 的性能分别提高了0.076、0.035和0.054,NDCG@10 的性能分别提高了0.109、0.033和0.089,MRR的性能分别提高了0.130、0.099 和0.119;在MyAnimeList与DeepICF 比较,HR@10 的性能分别提高了0.066、0.074 和0.085,NDCG@10 的性能分别提高了0.061、0.075 和0.092,MRR 的性能分别提高了0.037、0.060 和0.085。这些结果表明,与直接使用用户显式特征或使用隐式反馈信息(用户和项目历史交互信息)相比,通过邻居间接集成用户显式特征可以获得更多的性能改进。
(4)邻居数量的影响:图8、图9 和图10 为UCCOCCF 在不同用户邻居情况下的结果。可以看出,邻居数量对UCC-OCCF 的性能有不同的影响。对于MovieLens 1M,当每个用户设置20个邻居时,HR@10的性能最高;当每个用户设置50 个邻居时,NDCG@10 和MRR 的性能对于COS 和汉明距离度量都是最高的,而Pearson 相关性系数是最低的,每个用户设置20 个邻居时性能最高;对于MovieLens 100K,每个用户设置40 个邻居时,HR@10、NDCG@10 和MRR 的性能最高;对于MyAnimeList,每个用户设置20 个邻居时,HR@10、NDCG@10 和MRR 的性能最高。由上述结果可知,邻居的数量会影响OCCF 的性能,但是OCCF 的性能与邻居的数量没有对应关系。本文目的是学习具有相似显式特征邻居的共同偏好,最合适的邻居数量由数据集的数据分布决定。

图8 评价邻居数量对HR@10 的影响Fig.8 Evaluation of HR@10 using different number of neighbors

图9 评价邻居数量对NDCG@10 的影响Fig.9 Evaluation of NDCG@10 using different number of neighbors

图10 评价邻居数量对MRR 的影响Fig.10 Evaluation of MRR using different number of neighbors
(5)不同邻居距离度量方法的比较:从图5、图6和图7 可以看出,邻居距离度量方法会影响UCCOCCF 的性能。对MovieLens 1M 和MyAnimeList 而言,Pearson 相关性系数度量的效果是最好的,对于MovieLens 1M 和MyAnimeList,使用汉明距离度量比COS 度量表现得更好,但对于MovieLens 100K,结果却相反。究其原因,Pearson 相关系数在数据受级别膨胀影响大时更加有效,COS 中存在较多的特征工程,在大数据集下的深度学习模型不一定能带来积极的影响。相反,当数据集较小时,它是有意义的。
(6)网络结构评估:本文对是否集成NB-CPR 模块情况下的OCCF 性能进行了评估,如图11 所示,集成NB-CPR 模块可以获得更高的性能。UCC-OCCF模型的性能在3 个数据集上都比基本的DLFR 模型提高了0.1以上,表明本文提出的网络结构的有效性。
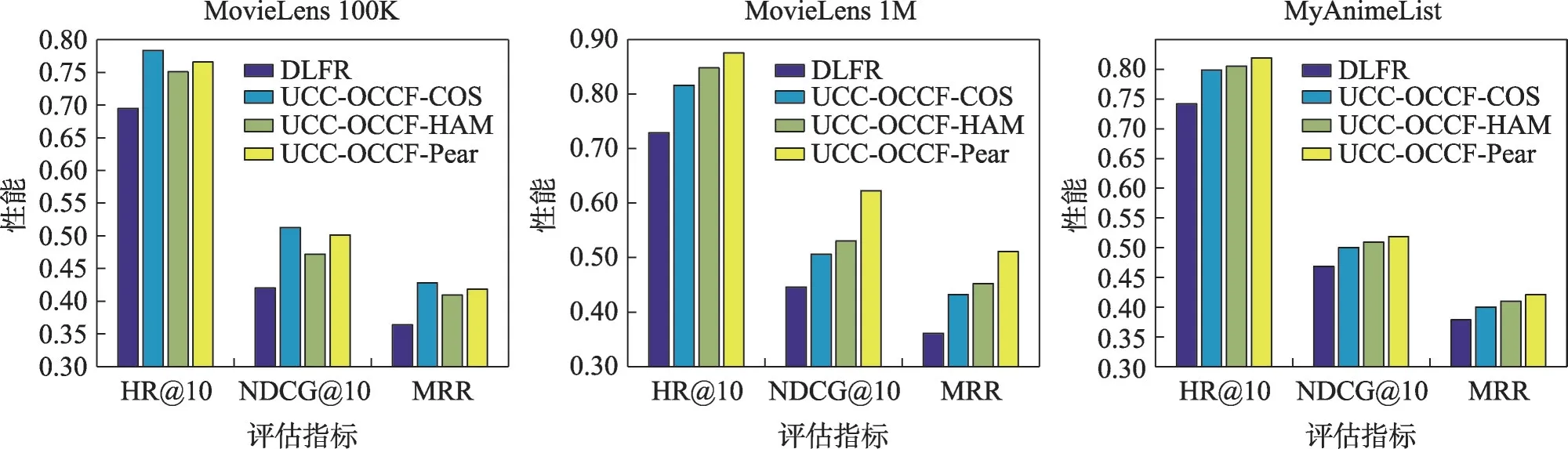
图11 模型结构评估Fig.11 Evaluation of model structure
(7)基线模型和UCC-OCCF 在3 个数据集中训练和预测的时间对比,如表5 所示。当数据集的数量级变大时,对于所有模型来说,训练和预测所需的时间都会显著增加。在所有模型中,itemKNN 在所有数据集上的训练和预测过程花费的时间始终是最少的。在训练过程中,本文的模型UCC-OCCF 每一个epoch 的平均训练时间高于大部分对比模型,然而UCC-OCCF 的训练总时间小于绝大多数的模型。证明UCC-OCCF 花费更少的训练时间来获得更佳性能。对于预测过程,UCC-OCCF 花费的时间与其他模型相差不大,且均小于NGCF。

表5 训练和预测时间Table 5 Time for training and prediction
(8)参数评估:本文模型使用的最终超参数如表6 所示。

表6 超参数Table 6 Hyper-parameters
4 结束语
本文提出了一种深度单类协同过滤模型UCCOCCF,通过将用户邻居的共同偏好与当前用户的个人偏好相结合,间接融合潜在特征和显式特征。通过对MovieLens 100K、MovieLens 1M 和MyAnimeList数据集的实证评估,证明了该方法相对于现有方法的优越性。在这项工作中,只使用人口统计学信息来计算用户邻居,在实际应用中,UCC-OCCF 模型可使用更多其他类型的显式特征,例如社交网络信息。未来考虑基于GNN学习用户的人口统计学信息和社交网络信息来得到用户的邻居,从而提高推荐性能。
