基于LSTM分类器的航空发动机预测性维护模型
2022-03-11蔺瑞管王华伟车畅畅倪晓梅熊明兰
蔺瑞管, 王华伟, 车畅畅, 倪晓梅, 熊明兰
(南京航空航天大学民航学院, 江苏 南京 210016)
0 引 言
作为飞机的关键部件之一,航空发动机的工作条件通常非常复杂,任何意外故障都可能导致灾难性后果。随着传感器技术的最新发展,以及通信系统和机器学习技术的显着进步,预测性维护(predictive maintenance,PdM)已经成为航空发动机故障预测与健康管理(prognostic and health management,PHM)领域的研究热点。通过建立航空发动机的PdM模型,管理者可以更有效地计划维护活动,以减少发动机停车时间并降低平均维护成本,保证发动机运行的可靠性和安全性。
随着工业中实际需求的日益增长,PdM在近十年中受到了学者的极大关注。通常,航空发动机预测维护框架包括两个相互联系的关键部分:系统剩余使用寿命(remaining useful life, RUL)的预测和维修决策。在航空发动机的性能退化过程中,传感器数据之间存在紧密的时间相关性。RUL预测就是根据该航空发动机的历史传感器时间序列数据,辨识隐含其中的运行规律,进而应用该规律对航空发动机剩余使用寿命进行预测。
提高RUL预测的准确性不仅可以提高安全性和可靠性,降低平均维护成本,并为航空发动机维修决策提供参考。基于预测方法的研究主要分为两大类:基于物理模型的PdM 框架和基于数据驱动的PdM 框架。但是由于设备结构日益复杂,再加上各种环境的影响,很难用物理模型去准确地预测RUL。随着大数据时代的到来,以及计算机技术的不断发展,基于人工智能的数据驱动方法已经成为发动机RUL预测领域的研究热点。
在最近的研究中,已经开发了许多机器学习技术(尤其是深度学习),并成功应用于预测各种复杂系统的RUL。深度学习算法可通过对历史性能退化状态序列的学习,逼近传感器数据的时间相关性规律,从而预测RUL。在深度学习中,循环神经网络(recurrent neural network, RNN)包含递归隐藏层,非常适用于利用时间序列信息预测RUL。但是,在RNN处理长时间序列数据时,会出现梯度消失现象,导致其在实际应用中性能受限。为了解决RNN的这一问题,文献[14]提出了长短期记忆(long short-term memory network, LSTM)网络,其作为一种RNN的变体,将长期内存保存在单元状态,可有效处理发动机性能退化数据的长期依赖关系,适用于解决RUL预测问题,因此备受关注。
Che等提出了一种结合多种深度学习算法的PHM模型,通过深度置信网络(deep belief network,DBN)和LSTM的集成来估计RUL。主要思想是使用构造的健康因子(health indicator, HI)和目标标记来训练神经网络模型,根据预测的HI,通过设置阈值以获得发动机RUL的估计值。Tamilselvan等提出了一种使用DBN分类器的新型多传感器健康诊断方法。Guo等提出了一种基于递归神经网络的健康指标,利用单调性和相关度量从原始特征集中选择最敏感的特征,用于进行RUL预测。Hinchi等提一种基于卷积和长短期记忆的深度RUL估计框架。首先,使用卷积层直接提取传感器数据的局部特征,然后利用LSTM层获得退化过程并估计RUL。Aldulaimi等提出了一种用于RUL估计的混合深度神经网络模型,该方法使用LSTM路径提取时间特征,而同时使用卷积神经网络(con-volutional neural networks, CNN)提取空间特征,对复杂系统具有较好的预后效果。Yuan等利用LSTM在复杂操作,混合故障和强噪声情况下预测发动机的RUL。张妍等提出由多层感知器(multi-layer perceptron,MLP)和进化算法组成的框架,并利用跨步时间窗口和分段线性模型来估计机械组件的RUL。针对航空发动机性能退化和多状态参数时间序列预测的问题, 车畅畅等构建了基于多尺度排列熵算法和LSTM的RUL预测模型。针对RUL 预测精度低的问题。张永峰等提出基于一维CNN和双向长短期记忆(bi-directional long-short term memory,BD-LSTM)的集成神经网络模型,并于其他深度学习模型进行了比较。
在以上RUL预测的研究中,一般可以概括为以下3个步骤:①提取原始数据特征;②建立设备HI曲线;③预测设备RUL。该方法的关键是对原有HI曲线进行向后的多步预测,即当 HI 值超过预先设定的阈值时视为失效,从而可计算得到RUL。提出的模型性能严格取决于故障阈值定义,这在实践中并不简单,不仅需要大量专家经验参与,而且模型预测的鲁棒性和准确性也会受到阈值取值的影响。此外,这些研究为预测RUL值的回归问题,其准确性严格取决于预测范围(从当前时间到实际系统故障时间的时间段)。因此,若使用预测准确性较低的RUL值可能会导致错误的决策。
针对以上问题,本文提出一种新的航空发动机预测性维护模型。采用滑动时间窗口方法标记训练样本,充分表征了多元传感器数据的退化信息。运用LSTM分类器强大的特征提取能力处理时间序列数据,估计系统将来在特定时间窗口内发生故障的概率。与以往研究相比,所提出的预后方法不需要设定故障阈值,而是将预测RUL转化为二分类问题,即预测设备在特定时间窗口内是否会失效,有效提高了维修决策的准确性。通过分析窗口大小对模型性能的影响,得到最优性能的模型参数。由于这些时间窗口是根据运营计划者的要求定义的,因此所提出的方法对进一步的维修决策具有重要的研究意义。
1 模型算法描述
1.1 LSTM分类器
LSTM 是在RNN基础上的改进,通过多个序列的组合和前后连接,RNN能够根据当前信息和历史信息来进行预测。然而,随着神经网络的复杂度逐渐提高,RNN往往出现信息过载和局部过优化的问题。作为RNN的变体,LSTM 能够利用门控制单元使网络的信息提取更有选择性,从而有效地提高信息的利用率和时间序列预测的准确率。LSTM通过引入长时记忆单元、输入门、遗忘门、输出门、短时记忆单元等概念,让整个网络模型的运行时间更短、误差更小。


图1 LSTM单元结构Fig.1 LSTM unit structure
首先,遗忘门控制LSTM层哪些长期记忆可以被遗忘:
=(-1++)
(1)
接下来,输入门计算可以从输入中获取的信息,并了解其中哪些部分应该存储到单元状态中:
=tanh(-1++)
(2)
=(-1++)
(3)
然后,更新单元状态中的长期记忆:
=-1⊗+⊗
(4)
最后,使用输出门根据输入,单元状态和先前的隐藏状态更新当前隐藏层的状态:
=(-1++)
(5)
=⊗tanh()
(6)
在以上公式中,,,,是当前隐藏层和先前隐藏层之间的隐藏层权重值,而,,,是当前输入层和当前隐藏层之间的权重值;,,,是偏差向量;⊗是逐元素乘法运算符;是Sigmoid函数;tanh是激活函数。
1.2 基于LSTM分类器的预测性维护框架
在生产实践中,通常需要长期提供预测信息,以制定不同的维护计划。此外,由于技术和后勤方面的限制,无法在任何时间和任何地方执行航空发动机的维护操作。因此,运营计划者需要先了解设备在确定时间段内的故障概率,进而根据这些预测信息做出相应的预测性维修决策。
为了解决这一问题,本节提出一个基于LSTM分类器的预测性维护模型,该模型包含从数据预处理、模型的训练和测试到提供确定时间窗口内故障概率的整个过程,如图2所示。

图2 基于LSTM分类器的预测性维护流程Fig.2 Predictive maintenance process based on LSTM classifier
首先,针对航空发动机全寿命周期的预测性维护过程,利用具有多个传感器的监控器系统,采集各项发动机运行性能参数,建立数据集。其次,将预处理后的数据集分成训练集和测试集。将训练集和测试集输入到LSTM分类器中,进行模型训练,通过调整时间窗口得到最优性能的LSTM模型。最后,预测设备在特定时间窗口的故障概率,以指导发动机维修决策。
2 实验数据处理与模型构建
2.1 数据集描述
本文使用美国国家航空航天局的 C-MAPSS涡扇发动机退化数据集进行模型仿真。C-MAPSS数据集包括4个子集:FD001,FD002,FD003和FD004。其具有不同数量的运行条件和故障模式,每个子数据集进一步分为训练集和测试集。表1列出了C-MAPSS数据集的构成部分。第1行和第2行分别代表每个引擎的发动机单元编号和退化周期,第3行描述了发动机的运行设置,而最后的21列由来自21个传感器的多元时间数据组成。在以后的实验中,将考虑用FD001数据集对所提出模型进行验证和评估。在该数据集中,包括100个从运行到失效的时间序列,其中包含20 631个不同时间的测试数据,所有序列中测试数据的最大数量和最小数量分别为303和31。

表1 C-MAPSS数据集的构成
2.2 数据预处理
在训练LSTM网络之前,有必要对来自多个传感器源的异构数据进行预处理。
(1) 数据归一化
输入数据是从多个传感器源获得的,这些传感器源的范围不同。为了使用这些异构数据来训练LSTM分类器,有必要对它们进行归一化。本文采用Min-Max方法对训练集与测试集数据进行归一化,这种归一化将确保所有功能在所有工作条件下的平等贡献[26];归一化的数据将在[0,1]之间。
(2) 时间窗处理
为了对模型进行训练和测试,需要对训练集和测试集的数据进行标记。本文采用滑动时间窗口来定义数据标签。对于几个连续时间序列的数据,采用滑动时间窗以获得特征向量,可以获取更多有用的时间信息,这些信息可能会大大改善RUL分类性能。具体而言,就是利用先前的时间步长预测下一个时间步长,窗口沿时间方向滑动一个时间单位,便构造出单个训练样本,最后一个时间节点对应的RUL作为该训练样本的标签。
所提出的方法根据时间窗口来定义数据标签,在该时间窗口中,运营计划者需要故障预测信息来安排维护和生产活动。例如,运营计划者需要系统在规定时间窗中发生故障的概率,则将数据标记为两个类别。第一类记为Deg0,表示设备RUL大于的情况,即RUL>。第二类为Deg1,表征其中设备RUL小于,即RUL≤。如果RUL属于给定的类别,则其对应元素将设置为1,而输出数组的其余元素设置为0。
2.3 网络模型参数设置
本文提出的深层LSTM分类模型由Python 3.7.6 keras/tensorflow深度学习库构建,处理器为Intel(R) Core(TM) i7-9700 CPU @ 3.00 GHz 3.00 GHz,内存为8 GB,操作系统为Windows 10。图3显示了深度LSTM中3种类型的层:输入层,隐藏层和输出层。

图3 提出的深层 LSTM分类模型Fig.3 The proposed deep LSTM classification model
输入层是将数据带入LSTM的网络层。输入数据为三维格式,即[样本,时间步长,特征数量]。这里的时间步长是指每个特征的信息能够传递给下一个特征的长度。为了对全部设备的RUL预测值进行二进制分类,时间步长需要满足测试集中记录数据的最小长度。由于数据集FD001中记录的最小长度为31,则本文设定的时间步长为30。
隐藏层介于输入层和输出层之间,是模型训练和测试的核心部分。在构建的隐藏层中,先后设置了100个和50个单元的层。另外,在每个LSTM层之后应用Dropout,以减少神经网络训练数据的过拟合,从而提高网络的特征提取能力。
输出层是包含一个前馈神经网络的全连接层。该层用作网络和输出之间的原型。其允许将隐藏层输出处的三维张量转换为分类器输出处的一维数组。在本文中,将分类器输出定义为两个元素的向量,这些特征描述了观察结果属于两类的概率:Deg0(RUL>),Deg1(RUL≤)。然后,在输出层中有两个单元,并使用“ Sigmoid” 激活函数。输出层提供了两个类别(Deg0和Deg1)上的概率分布。
为了训练LSTM分类器,将目标函数的损失(loss)定义为“binary_crossentropy”,该函数专门用于解决两类别分类问题。接下来,本文采用Adam优化算法,其是随机梯度下降算法的扩展式,具有计算效率高、内存需求小以及对大数据适用性高等优点,被广泛用于深度学习模型。为了评估模型的性能,将度量功能定义为“ binary_accuracy”。类似于目标函数,其为所有分类问题提供了所有预测的平均准确率。
2.4 性能评价指标
如表2所示,对于二分类问题来说,根据预测的结果得到混淆矩阵,对角线元素显示每个类别的正确观测值。

表2 二分类模型的混淆矩阵
本文选择准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F值(F1-score)来衡量二分类中不同模型算法的好坏,同时选择ROC(receiver operating characteristic)曲线和ROC曲线下面积(area under ROC curve, AUC)来完善二分类的评价指标。Accuracy表示分类正确的样本数占总样本数的比例。但是,对于不平衡数据的表现很差;Precision表示预测为正类的样本中真正类所占的比例;Recall是在所有正类中被预测为正类的比例;F1-score是Precision和Recall的调和平均,一般用来衡量分类器的综合性能。ROC曲线又称作“受试者工作特性曲线”,横坐标为假正率(false positive rate, FPR),纵坐标为真正率(true positive rate, TPR),曲线越靠近左上角的点,效果越好。AUC定义为ROC曲线下的面积,取值范围一般为(0.5,1.0)。AUC就越大,表示模型分类性能越好。

(7)

(8)
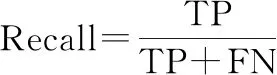
(9)

(10)

(11)

(12)
2.5 概率混淆矩阵


(13)
式中:TL表示真实标签;PL表示预测标签;∑((PL=)∩(TL=))是观测值的预测标签为而其真实标签为的概率。
3 实验结果
3.1 实验设定及说明
定义LSTM分类器的相关参数如表3所示。在模型训练过程中,本文采用keras.callbacks中的回调机制来加快训练过程并保存最佳分类模型。当损失值或准确率达到最优值后,就停止训练,进而提高训练效率和模型拟合精度。

表3 LSTM分类器的相关参数
3.2 RUL分类结果分析
首先,时间窗和的大小划分如表4所示,分析对发动机RUL分类效果的影响;其次,将准备好的C-MAPSS FD001数据集分成训练集、验证集和测试集;然后,利用滑动时间窗方法对数据集进行标记,将标准化后的数据集输入建立的深层LSTM分类器中,预测设备在特定时间窗口内的失效概率。通过设置时间窗口大小,输出如表4所示的9组实验结果。其中,一个Epoch(时期)表示使用训练集的全部数据对模型进行一次完整训练。

表4 分类模型的实验结果
图4 为RUL二分类性能评价指标的可视化展示。可以看出,当=35和=40时,模型的分类准确率最高为099。然后,随着时间窗口增大,Accuracy逐渐减小到083,降幅为162%;当=35和=40时,F1-score取值达到最大值098,可知两组实验具有相近的综合分类性能。由图4可知,当>40时,F1-score随增大而逐渐减小;另外,第3组的AUC取值最大为0976,这与第4组的结果无明显差别,=40时的二分类ROC曲线如图5所示;图6为模型运行时间随的变化趋势(红色虚线为平均运行时间),可以看出第3组的运行时间最长为281,第5组的运行时间最小为57,两组的AUC取值相近,因此在选择模型时可优先选择第5组。另外,与第2组相比,第4组具有更小运行时间,即更高运行效率。

图4 RUL二分类性能评价结果Fig.4 RUL binary classification performance evaluation results
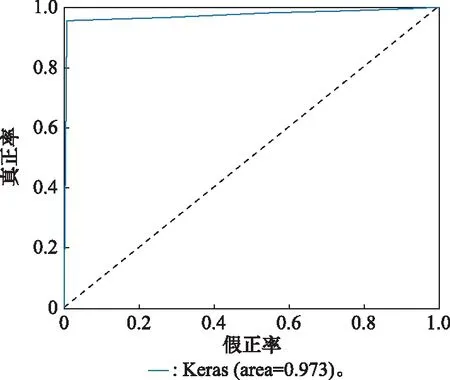
图5 w1=40时的二分类ROC曲线Fig.5 Two-class ROC curve when w1=40
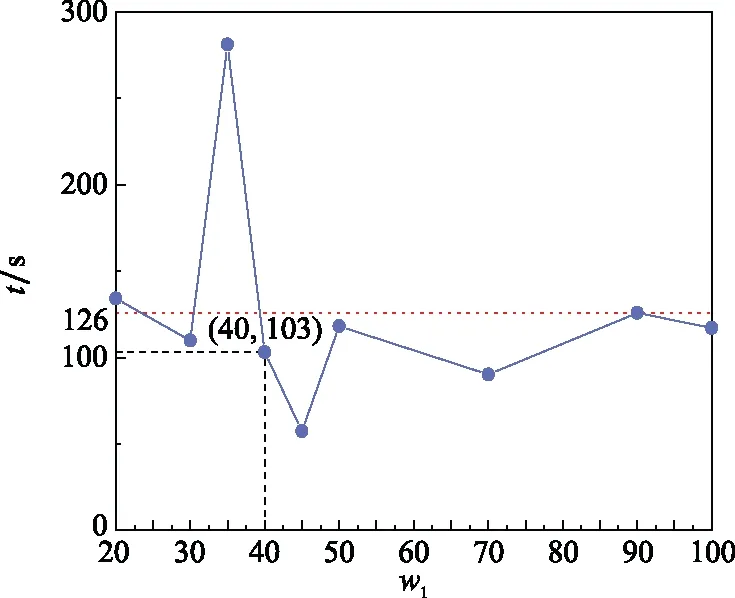
图6 模型运行时间随w1的变化趋势Fig.6 Trend of model running time with w1
综合以上分析可知,本文选择第4组为最优二分类模型,即时间窗口为=15和=40。图7描述了=40时的模型训练过程,随着时间的增加,训练集和验证集的loss逐渐减少。在运行20 Epochs以后,训练集与验证集的loss误差趋于平稳,并在Epoch=24时达到最优的模型训练性能。训练集和验证集的Accuracy呈现出与loss相反的变化趋势,同样在Epoch=24时达到最优值。图8为二分类模型测试集的概率混淆矩阵(=15,=40)。当系统属于Deg1时,对于测试集,系统预测状态为Deg0的概率非常低,仅为3.57%,而预测状态为Deg1的概率为96.43%;当系统属于Deg0时,对于测试集,系统预测状态都为Deg0,这表明此时模型具有优良的分类性能。


图7 w1=40时的模型训练过程Fig.7 Model training process when w1=40

图8 测试集的概率混淆矩阵(w0=15,w1=40)Fig.8 Probability confusion matrix of the test set (w0=15, w1=40)
3.3 与其他方法的比较
本文将提出的方法与Python scikit-learn库中现有方法进行了对比,包括逻辑回归、决策树、随机森林(random forest, RF)、支持向量分类(support vector classification,SVC)、K近邻(K-nearest neighbors,KNN)、高斯朴素贝叶斯分类器(Gaussian naive Bayesian classifier, Gaussian NB),各种方法的窗口大小设置均为=15和=40。
在Logistic Regression中,分类方式参数为“ovr”,并采用“lbfgs”作为求解器,利用海森矩阵对损失函数进行迭代优化,最大迭代次数为100;在Decision Tree中,特征选择标准为“entropy”,决策树最大深度为4,最小叶子节点为1,最小内部节点为2,不考虑叶子节点的权重;在Random Forest中,特征选择标准为“entropy”,决策树最大深度为6,最小叶子节点为1,最小内部节点为2,决策树个数为50,并行工作数为1;在SVC中,核函数为“rbf”,函数维度为3,核函数参数为“auto”,不限制最大迭代次数,停止训练的误差值为0.001;在KNN中,数的大小为30,树的距离度量为欧几里德度量,并行工作数为1,近邻数为13,预测的权函数为平均加权;在Gaussian NB中,先验概率priors=None,即获取各类别的先验概率。
表5中比较了所提方法和在发动机测试数据集FD001中的性能,性能指标的可视化对比结果如图9所示。与其他方法相比,本文所提方法具有最大的Accuracy、Precision、Recall和F1-Score。特别地,F1-Score为反映模型分类性能的综合指标,由图9可以直观地看出所构建的LSTM分类器较现有方法具有显著的优越性,尤其适用于多元长序列传感器数据的处理过程。对比其他方法中最优方法的性能,所提方法的准确率提高了5.31%,而F1-Score提高了10.11%。这意味着所提出的方法具有最好的分类性能,表明了所提方法对发动机RUL分类问题的有效性。

表5 与现有方法的性能对比

图9 与其他方法的性能指标对比Fig.9 Comparison of performance indicators with other methods
4 结 论
(1) 本文提出了基于LSTM分类器的航空发动机预测性维护模型,与一般预测RUL值的方法不同,所提方法提供了设备RUL落入特定时间窗口的概率。
(2) 采用滑动时间窗口定义训练样本标签,然后将预处理后的数据集输入建立的深层LSTM分类器中,预测设备在特定时间窗口内的失效概率。通过分析对故障概率的影响,得到最优性能的LSTM分类模型,以更好地适应实际维护需求。在特定的时间窗口内,维护工程师可以根据RUL分类信息来安排维护和生产活动。
(3) 提出的模型在美国国家航空航天局的 C-MAPSS的数据集上进行了验证,评价指标均优于其他现有分类模型,验证了LSTM分类器的有效性。同时,更加准确的RUL分类模型可降低维护成本,提高维护效率。
