基于文本相似度的新闻自动摘要算法研究
2022-03-10李栋凯张永昌
李栋凯 张永昌
1. 河北工程大学信息与电气工程学院 河北 邯郸 056038;2. 河北工程大学土木工程学院 河北 邯郸 056038
引言
互联网的快速发展孕育了自媒体并带动自媒体飞速发展,但很多自媒体新闻的正文与其所写的标题并不完全相符,甚至有些自媒体为“博眼球”把新闻标题和标题完全无关的内容生硬的进行捆绑,这消耗了读者的有效阅读时间。新闻自动摘要技术可以快速形成新闻汇总,聚焦新闻热点,提高读者的阅读效率,改善阅读体验。
本文将textrank[1]、word2vec[2-3]和MMR[4-5]三种语言模型用于新闻自动摘要算法的研究。通过仿真实验结果的对比发现:①textrank算法得到的摘要语句可读性差,理解困难;②在textrank算法基础上增加word2vec模型后对整篇新闻的概括度较高,但将并不能很好的解决信息冗余和效率低的问题;③MMR可以有效去除信息冗余,体现语义的多样性。
1 算法简介
1.1 textrank算法
textrank被用来做文本摘要[1]的步骤如图1所示。首先逐条提取目标文本中的句子,并把提取到的句子表示成向量形式,用非稀疏矩阵来表示文本中所有句子之间的相似性;然后,将句子作为节点,句子之间的相似度作为边的权重,将矩阵转换成一个图的表示形式;最后,对所有句子节点按照其边的权重重新排序,提取出排名靠前的句子作为摘要。
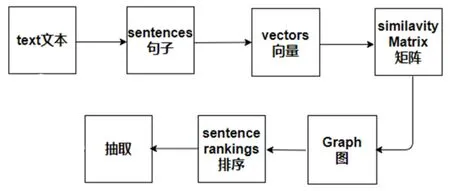
图1 textrank摘要步骤
Textrank中计算两两句子间的相似度通过式(1)来计算,等式的右边表示目标文本中第i个句子和第j个句子的相似度,等式右侧的分子代表第i个句子和第j个句子所有单词的数量。
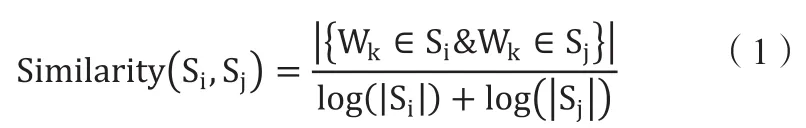
1.2 word2vec模型
实现textrank算法中有一步需要把文本中的句子转化为向量的表示形式。这一步骤可以通过TF-idf,word2vec以及characterbased等方法来实现。其中,TF-idf是依据词语在文本汇总出现的频率计算;word2vec生成的向量可以进一步表示出词与词之间的联系;character-based仅是把一个词语转换为一个字符来表示。本文采用word2vec模型用于改进textrank算法的新闻摘要生成质量[2-3]。
word2vec模型本质上是去掉了隐藏层的人工神经网络模型。该模型认为上下文中词义相近的词,它们对应的向量之间距离相近。它主要是对比某个词和与它相邻的词之间的关系。比如“她给小明做午饭”。如果“小明”作为中心词,那么和它相邻的词有“她”、“给”、“做”、“午饭”。在“她给小李做午饭”。中选取“小李”为中心词,与这个词紧邻的同样有“她”、“给”、“做”、“午饭”。因此与这两个中心词的相邻的词是完全相同的,经过向量计算我们希望得到“小明”等于“小李”。
1.3 MMR算法
MMR算法又被称为最大边界相关算法,是在研究查询结果的多样化时提出[4-5]。最初MMR被用来计算Query文本与被搜索的文档两者的相似度,后来也被用于rank排序。MMR的数学计算公式如式(2)所示:


采用MMR最后生成摘要的句子有两个特性,一是该句子的重要性更高,二是这个句子和其他句子之间的相似度更低。因此,通过MMR算法得到的最终摘要,句句都很重要,但句句都不一样。抽取的句子既能表达整个文档的含义,又可以兼具语义的多样性。
2 仿真实验
本文选取2008版的搜狗实验室的全网新闻数据(SogouCA)作为实验数据集,该数据集来自若干新闻站点包含国内,国际,体育等18个频道。全网新闻数据(SogouCA)中的数据格式为图2所示,它提供了URL、标题以及新闻正文的内容。该数据集中有的新闻正文长句较多,有的正文则很短甚至没有正文,且不是所有的新闻都有标题。

图2 数据集中的数据格式
新闻文本里的正文内容含有特殊的符号比如:表情符号、空格、英文字母等,且全角半角使用较混乱。实验前需要通过数据预处理对给新闻文本进行整理,以去除特殊符号,将全角转换为半角,从而便于随后实验步骤的进行。
本文采取Anaconda(python3.8)与Pycharm搭配使用作为仿真实验工具。使用jieba分词工具的精确模式去停用词。使用anaconda中的opencc库来进行繁体简体之间的转换。具体仿真平台参数如表1所示。

表1 仿真工具平台
以搜狗实验室的全网新闻数据(SogouCA)中一条体育新闻为例,原文如图2所示,展示了三种文本摘要算法生成的摘要结果分别如图3-5所示。

图2 新闻原文

图3 textrank摘要结果

图4 增加word2vec后的textrank摘要结果

图5 MMR算法摘要结果
对比摘要生成情况可以发现,textrank提取了新闻的最后一句话,使用了词向量生成模型的textrank提取到了新闻的第一句话。在实验中发现采用textrank算法倾向于提取文本最后一句话作为摘要句,而采用word2vec模型的textrank算法同时提取了文本第一句话。因此,增加了word2vec模型的textrank算法对整篇新闻的概括度较高。
MMR摘要方法抽取出来的句子之间的关联性不大,比较跳跃性,可读性差。但MMR相比于textrank提取的句子多样性较好,冗余较小,可以较完整概况新闻整体内容。
3 结束语
考虑到新闻文本结构的特殊性,新闻中句子位置的特征以及不同种类新闻对摘要的不同要求,当前自动摘要评测技术只能对句子间“皮相”进行评估,不能通过语义辨别摘要质量的好坏。从而一定程度上需要人的主观评测。因此本文未对摘要结果进行评测,仅分析了基于三种算法生成的摘要之间的差异。
新闻文本中的第一条语句通常是对整篇信息的高度概括,阐述了新闻的核心观点;而最后一条语句通常是对本文的简单总结或新闻报道方的信息罗列。本文选取的三个算法都是基于抽取式的摘要生成技术,只要目标新闻的内容质量具备一定层次性和逻辑性,基本都能不偏离新闻报道的主题,但均不具备对新闻较高的概括能力。
