均匀分布场合下异常数据的检验
2022-03-06梁米李云飞
梁米,李云飞
(西华师范大学 数学与信息学院,四川 南充,637009)
均匀分布是应用统计中常见的分布之一,同时也是连续性随机变量中简单的分布[1],虽然简单,但由于其特殊性,在理论研究中具有重要的地位。均匀分布在交通流、电流、误差分析和生物学等方面都得到了广泛的应用。国内外学者针对均匀分布的统计推断问题开展了大量的研究。时凌等[2]对均匀分布U(θ-a,θ+a)的参数θ的估计量以及这些估计量的优效性进行了研究,并证明了最小顺序统计量是最优的统计量。赵志文等[3]研究了在缺失数据情形下混合均匀分布总体参数的估计和检验问题。丁勇[4]研究了均匀分布样本均数的分布,推导出了标准均匀分布样本均数的分布函数。RIFFAT等[5]定义了可用于估计连续均匀分布参数的不同方法,并使用总偏差和均方作为性能索引来识别其中的最佳估算器,通过重复的模拟研究比较了这些估计方法。WANG等[6]采用了线性贝叶斯方法来估计均匀分布。
统计数据质量问题引起了社会各界的关注[7]。在实际应用中,由于一些主观或外界原因,在数据收集过程中往往会产生异常数据。异常数据是指一批数据中与其余数据相比明显不一致的数据,这些数据的产生往往会导致统计分析的误差增大[8]。因此,在利用收集的数据进行统计分析之前,有必要对其进行异常数据的检验。对于异常数据的检验问题,国内外一些学者进行了研究。费鹤良等[9]构造了Fisher型统计量,分别用Tn(1)和Tn(n)检验样本极值x(1)和x(n)是否异常。王蓉华等[10]提出了一种适用于各种分布且能一次检验多个异常数据的检验方法——均值比检验。此外,国家标准GB 17378.2—2007《海洋监测规范 第2部分:数据处理与分析质量控制》中提出Dixon型检验统计量用于检验异常大和异常小数据的标准[11]。针对指数分布、双参数指数分布等常见异常数据的检验问题,已有一些学者对其进行了研究[12-19]。对于均匀分布异常数据的检验,目前研究较少。唐年胜[20]针对均匀分布U(a,b)中参数a已知、b未知和a,b均未知的情况,提出了多个异常值的似然比检验。张慧娟等[21]利用假设检验的基本原理和方法,在Dixon型统计量的基础上,构造了基于顺序统计量的S型统计量来检验异常大数据,但此方法仅适用于样本数据服从标准均匀分布时。在实际问题中,样本数据并不是简单地服从标准均匀分布,针对该问题,本文将基于Dixon型检验统计量,利用样本中位数具有较好抵抗异常数据的影响这一性质,构造检验统计量,对服从一般均匀分布的数据进行异常数据的检验。
1 检验统计量及其分布
1.1 检验统计量的构造
假设随机变量X服从区间(θ1,θ2)上的均匀分布,记作X~U(θ1,θ2),其中,θ1,θ2为未知参数。则X的分布函数和密度函数分别为
设X1,X2,…,Xn是来自均匀分布总体X~U(θ1,θ2)的独立同分布样本,X(1),…,X(n)是来自该总体的样本容量为n的顺序统计量,x(1),x(2),…,x(n)是顺序统计量的观测值。
引理1[22]设X1,X2,…,Xn是来自均匀分布总体X~U(θ1,θ2)的独立同分布样本,X(1),…,X(n)为来自该总体的样本容量为n的顺序统计量,令
则Y~U(0,1),Y1,Y2,…,Yn独立同分布于U(0,1),Y(1),Y(2),…,Y(n)与均匀分布总体U(0,1)的容量为n的前n个顺序统计量同分布。

1.2 检验统计量的精确分布
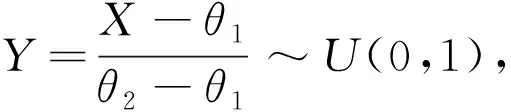
又由于
因此,不管参数θ1,θ2为何值,T的分布都与θ1=0,θ2=1的标准均匀分布相同。
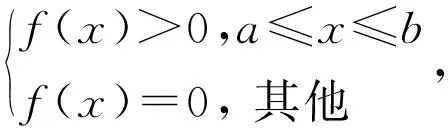
其中,
G(x,y,z)=[F(x)]i-1[F(y)-F(x)]j-i-1[F(z)-F(y)]k-j-1[1-F(z)]n-k


由引理2可知:X(1),X(m),X(n)的联合密度为
作以下变换:
则有

该变换的Jacobi行列式为|J|=v,故U,V,W的联合密度函数为
其中,0 可求出U的密度函数为 其中,0 若x(n)为异常大数据,则统计量T的值会过小。故可用统计量T来检验x(n)是否异常。 表1 显著性水平为α的临界值表 给定样本容量为n=20,通过Monte-Carlo模拟产生一组服从参数为θ1=6,θ2=8的均匀分布的随机样本[26]:7.504 8,6.962 9,6.873 9,7.173 1,7.179 7,7.386 8,7.213 2,7.120 7,7.924 5,6.469 0,6.610 1,6.301 6,7.082 4,6.720 1,6.380 3,6.734 4,7.896 0,7.313 0,7.530 1, 6.042 5。 首先,将20个数据按照从小到大的顺序排序,得到顺序统计量x(1)<… 表2 排序后的数据 与表1中的临界值对比,可以得出T>Tα(n=20),所以,x(20)不是异常大数据。 若由于人为输入错误,使得原始数据中出现异常大数据,不妨假设将x(8),x(14)和x(19)的值输入为16.873 9,17.213 2和19.893 2。此时,20个数据的大小顺序混乱,重新对20个数据进行排列得到其新的顺序统计量y(1),…,y(20),见表3。 表3 重新排列得到其新的顺序统计量 与表1中的临界值对比,可以得出T′ 接下来继续对y(19)进行检验(此时n=19): 与表1中的临界值对比,可以得出T″ 用同样的方法继续对y(18),y(17)进行检验,检验结果如下: 与表1中的临界值对比,可以得出T‴ 综上,y(20),y(19)和y(18)为异常大数据。 本文研究了均匀分布场合下异常大数据的检验。利用样本中位数能够抵抗异常数据干扰的性质,构造了适用于一般的均匀分布场合的检验统计量并得到其密度函数,给定了异常大数据判别标准,通过实例验证了方法是可行、有效的。该方法可以避免异常大数据的干扰,具有稳健性,因此,也可用于对多个异常大数据进行检验。


2 算例分析




3 结论
