近红外光谱协同BP神经网络的泰国茉莉香米掺伪含量快速鉴定
2022-03-05李楠楠刘也嘉林利忠曹珍珍赵思明贾才华张宾佳
李楠楠,刘也嘉,林利忠,曹珍珍,赵思明,牛 猛,贾才华,张宾佳,,*
(1.华中农业大学食品科学技术学院,湖北 武汉 430070;2.金健米业股份有限公司,湖南 常德 415001)
泰国茉莉香米外观品质优良、气味芳香,深受各国消费者喜爱,但由于其产量有限、价格较高,泰国茉莉香米中混掺普通白米的现象日趋严重,因此,国内外科技工作者建立了系列用于鉴别大米掺伪的方法,包括感官检验法、水煮法[1]、碱消度法[2]、DNA法[3-5]、蛋白质电泳[4-5]、近红外光谱技术[4]等。其中,近红外光谱技术具有无损、快速、无污染等优点[6-8],已应用于大米新鲜度鉴别[9]、成分含量预测[10-11]、品种真伪鉴别[12]、产地 溯源[13-14]、定性定量预测[7,15]等方面。利用近红外光谱技术研究不同地区(湖南、安徽、江西等7 省)的30种稻米储藏时间与品质的变化关系,可建立用于稻谷新陈度判别的预测模型[16];以不同地域和品种的233 份大米为研究对象,利用近红外光谱的特征波段能够快速鉴别查哈阳大米[17];利用近红外光谱技术对建三江和五常地区的291 份大米进行产地溯源,也具有较好的判别效果[16]。
若要解决泰国茉莉香米掺伪的问题,必须在定性鉴别的基础上,建立泰国茉莉香米的快速定量鉴定方法。作为常见的人工神经网络模型,BP神经网络具有操作简单、预测精度高、自适应性好等优点[17],适用于解决函数逼近、模式识别等问题[18]。将BP神经网络与近红外光谱结合可提高大米定量鉴定的准确度和效率[19]。相关方法在大米的蛋白质含量预测、水分含量预测等方面呈现出较好的应用前景[20-22]。然而,对于如何建立基于红外光谱和BP神经网络的泰国茉莉香米快速定量鉴定方法仍需系统研究。
因此,本研究以泰国茉莉香米及其掺伪样品为研究对象,提取样品的近红外光谱特征信息并结合BP神经网络模型,建立泰国茉莉香米的快速定量鉴定方法,以期解决近红外光谱等方法鉴别泰国茉莉香米时定量准确率偏低的问题,具有重要的实际应用价值。
1 材料与方法
1.1 材料与试剂
本实验选取8种大米(表1),均来源于金健米业股份有限公司。取普通米分别与5种泰国茉莉香米以90∶10、80∶20、70∶30、60∶40、50∶50、40∶60、30∶70、20∶80、10∶90比例进行混合,每种混和米样品制备3 份,每份300 g,3种普通米和5种泰国茉莉香米各1 份,共413 份混合样品,用于后续近红外光谱测试。

表1 大米基本信息Table 1 Information about rice samples tested in study
1.2 仪器与设备
Supnir-2720型近红外光谱仪 杭州聚光科技股份有限公司。
1.3 方法
1.3.1 近红外光谱采集
仪器条件:波长范围1 000~2 500 nm,光谱分辨率10 nm,波长准确性0.2 nm,扫描速率5 次/s。
将仪器预热30 min后进行仪器自检、性能测试和白板参比,然后将混合均匀的90 g大米放入仪器自带的直径70 cm的样品盒中,用样品盒盖压平,将样品盒放入指定位置,开始光谱测定。测定条件:环境温度15~25 ℃,波长范围1 000~1 799 nm,扫描间隔1 nm,仪器带宽1 nm,采样点数800,光谱重复性优于0.2 nm,信噪比优于2 000∶1。每个样品重复装样扫描6 次,取平均值。
1.3.2 样本集划分及特征波长筛选
采用Kennard-Stone法将样本集划分为校正集和验证集[4,23],其中校正集样本数占80%,验证集样本数占20%。考虑变量之间的欧氏距离,在样本光谱的特征空间中均匀选取样本,依次选取欧氏距离最远的点进入校正集[24],留下马氏距离居中的点在验证集中,使光谱差异较大的样本全部进入校正集。
采用竞争性自适应重加权采样(competitive adaptive reweighted sampling,CARS)法筛选模型的特征波长,主要包括4个步骤:1)利用蒙特卡洛采样法从校正集中选取样本建立偏最小二乘模型;2)利用指数衰减函数去除回归系数绝对值相对较小的点,继续利用蒙特卡罗采样法采样并建立偏最小二乘模型;3)评价每个变量的权重进行变量筛选;4)利用交互验证法计算每次采样后建立的偏最小二乘模型的交叉验证均方根误差(root mean square error of cross validation,RMSECV),RMSECV越小表明剔除的无关变量数越多,RMSECV最小时对应的变量子集即为最优变量子集[25]。更为详细的CARS算法过程及参数参考文献[26-27]。
1.3.3 光谱预处理
为降低仪器状态、样品状态与测量条件的差异造成近红外光谱的平移或旋转,产生随机误差和系统误差[28]。 本实验采用未处理、多元散射校正(multiplicative scatter correction,MSC)、Savitzky-Golay平滑、Savitzky-Golay导数、基线校正、标准正态变换(standard normal variate,SNV)等方法研究光谱预处理对模型性能的 影响[25],从而选出不同情况下最佳的预处理方式。
1.3.4 BP神经网络算法结构设计和参数选择
基于BP神经网络的非线性拟合算法,采用Matlab R2014a软件研究BP神经网络算法的结构设计与参数选取,确定最佳的BP神经网络结构。关于BP神经网络算法原理,参考文献[29-30]。
1.3.4.1 训练函数的确定
BP神经网络训练过程中,权值和阈值的调整、修正通过训练函数完成,当输出层输出值的误差在允许范围内即停止训练[31]。常见的训练函数有traingd、traingdm、traingda、traingdx、trainlm,本实验研究5种训练函数对网络性能的影响,选择最适宜的训练函数。
1.3.4.2 节点传递函数的确定
常用S型函数作为BP神经网络的传递函数,函数表达式见表2[17]。一般隐含层节点传递函数为对数S型函数或正切S型函数,输出层节点传递函数选择线性函数或正切S型函数[32]。本实验隐含层节点传递函数、输出层节点传递函数分别选择对数S型函数、正切S型函数或线性函数,确定最佳的节点传递函数。

表2 BP神经网络激活函数Table 2 BP neural network activation functions
1.3.4.3 网络学习函数的确定
网络学习函数在BP神经网络训练过程中主要是控制权值和阈值的变化量,调整小范围的权值和阈值,最小化单个神经元的误差。利用BP学习规则learngd函数和带动量项的BP学习规则learngdm函数,确定本研究最适宜的网络学习函数。
1.3.4.4 隐含层层数与节点数的确定
对BP神经网络结构的设计即为对BP神经网络的输入层、隐含层和输出层的设计。本实验输入层的输入值为近红外光谱经预处理后挑选的特征波长,输出层的输出值为泰国茉莉香米的预测含量。隐含层采用单隐层,神经元数取3、4、5、6、7、8、9、10。
1.3.4.5 学习速率的确定
BP神经网络在学习训练过程中利用梯度下降法使权重沿误差曲面的负梯度方向调整。本实验学习速率取值0.1、0.15、0.2、0.25、0.3、0.35、0.4、0.45、0.5、0.55、0.6、0.65、0.7、0.75。
2 结果与分析
2.1 混合泰国茉莉香米近红外光谱特征
由图1可知,不同浓度的泰国茉莉香米在波峰、波形十分相似。光谱在1 200、1 440、1 570、1 720 nm附近有明显吸收峰,在波段1 000~1 100、1 200~1 300、1 420~1 799 nm范围内,吸光度具有明显差异。但是由于大米近红外光谱图谱背景复杂,测量环境、时间不同等原因,导致光谱信息谱峰重叠严重、噪声多,反映泰国茉莉香米含量的信息在近红外光谱中谱峰强度较弱,因此需要采用不同的预处理方法,提取弱信息、减少背景干扰。
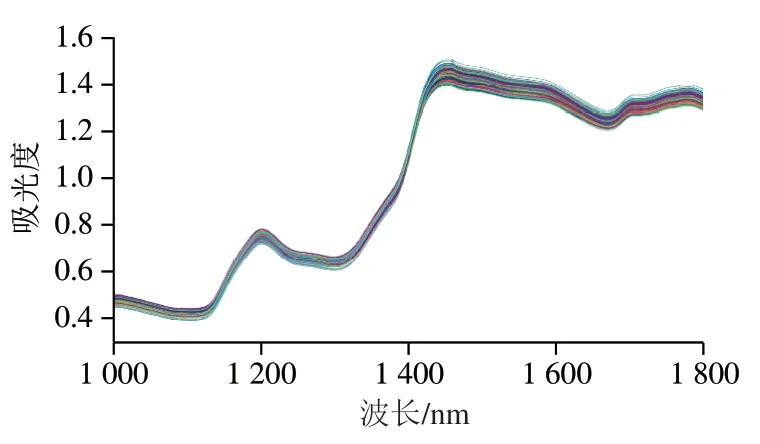
图1 混合泰国茉莉香米近红外光谱Fig. 1 Near infrared spectra of mixed Thai jasmine rice
2.2 特征波长的筛选
图2显示了大米预处理后的光谱图及特征波长。大米样品近红外光谱的噪声主要来源于颗粒大小、表面散射以及光程变化等因素,因此选择一阶导数、MSC、SNV、小波变换、去趋势校正(de-trending correction,DT)5种预处理方式处理近红外光谱,处理后的光谱数据采用CARS法挑选的特征波长分别为48、128、48、18、69、128个。
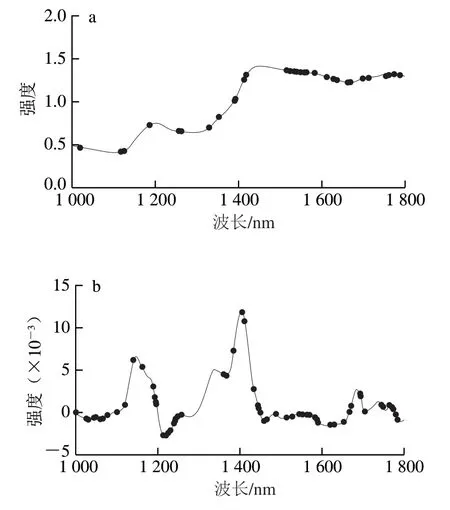
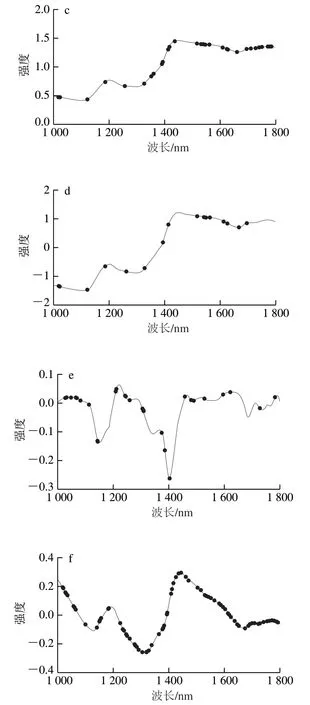
图2 光谱预处理后特征波长分布情况Fig. 2 Distribution of key wavelengths in pretreated spectra
2.3 BP神经网络结构与参数设计
2.3.1 训练函数的确定
训练函数对模的预测效果见表3。采用traingd、traingdm、traingda、traingdx作为训练函数时,均方根误差(root mean square error,RMSE)偏大,模型预测精度较低[7,17,32]。Levenberg Marquardt BP算法的trainlm函数取得了较理想的预测效果,不同预处理并挑选特征波长后的RMSE、R校正集、R验证集、R测试集分别为0.000 134~0.000 990、0.984 5~0.999 1、0.950 5~0.981 1、0.949 9~0.983 6,具有较好的预测效果。因此,确定trainlm为BP神经网络的训练函数。

表3 预处理光谱定量预测模型的训练函数优化Table 3 Optimization of training function for quantitative prediction model with different spectral data pretreatments
2.3.2 节点传递函数的确定
由表4可知,对于未处理的大米近红外光谱,隐含层节点传递函数为tansig,输出层节点传递函数为purelin,或隐含层节点传递函数为logsig,输出层节点传递函数为purelin时,模型的R校正集较大,分别为0.983 7和0.988 7,但模型预测精度低。隐含层节点传递函数为logsig,输出层节点传递函数为tansig时,模型均方差最小,R验证集和R测试集最大,模型预测效果较好。因此,选择logsig作为隐含层节点传递函数,tansig作为输出层节点传递函数。

表4 光谱定量预测模型的节点传递函数优化Table 4 Optimization of node transfer function for quantitative prediction model
对于一阶导数处理后的泰国茉莉香米近红外光谱,隐含层节点传递函数为logsig,输出层节点传递函数为tansig时,模型的均方差最小为0.000 125,R校正集、R验证集和R测试集分别为0.981 3、0.940 5、0.962 5,模型预测效果较好。
对于MSC预处理后的泰国茉莉香米近红外光谱,隐含层节点传递函数为logsig,输出层节点传递函数为tansig时,模型的均方差最小为0.000 620,R校正集最大为0.995 5,模型的R验证集、R测试集分别为0.974 1、0.972 7,此时模型的预测效果较好。
对于SNV预处理后的近红外光谱,隐含层节点传递函数为logsig,输出层节点传递函数为purelin时,或隐含层节点传递函数为tansig,输出层节点传递函数为tansig时,模型的R校正集较大,分别为0.989 8、0.990 1,综合比较模型的均方差、R验证集、R测试集,选择logsig作为隐含层节点传递函数,purelin作为输出层节点传递函数。
对于小波变换预处理后的泰国茉莉香米近红外光谱,隐含层节点传递函数为tansig,输出层节点传递函数为purelin时,模型的R校正集最大,为0.994 5,均方差较小为0.000 791,模型的预测效果较好。
对DT预处理后的泰国茉莉香米近红外光谱,隐含层节点传递函数为tansig,输出层节点传递函数为tansig,或隐含层节点传递函数为logsig,输出层节点传递函数为tansig时,模型的均方差最小,模型预测效果较好,综合比较R校正集,选择tansig作为隐含层和输出层节点传递函数。
综上所述,隐含层节点传递函数为tansig函数或logsig函数,输出层节点传递函数为tansig函数或purelin函数时,RMSE小于0.001,达到训练的精度要求。
2.3.3 网络学习函数的确定
由表5可知,网络学习函数的选择对网络预测效果有较大影响。采用未处理、一阶导数、MSC、DT预处理后的近红外光谱训练BP神经网络模型时,适宜的网络学习函数为BP学习规则learngdm。采用SNV或小波变换预处理后的近红外光谱训练BP神经网络模型时,适宜的网络学习函数为BP学习规则learngd。
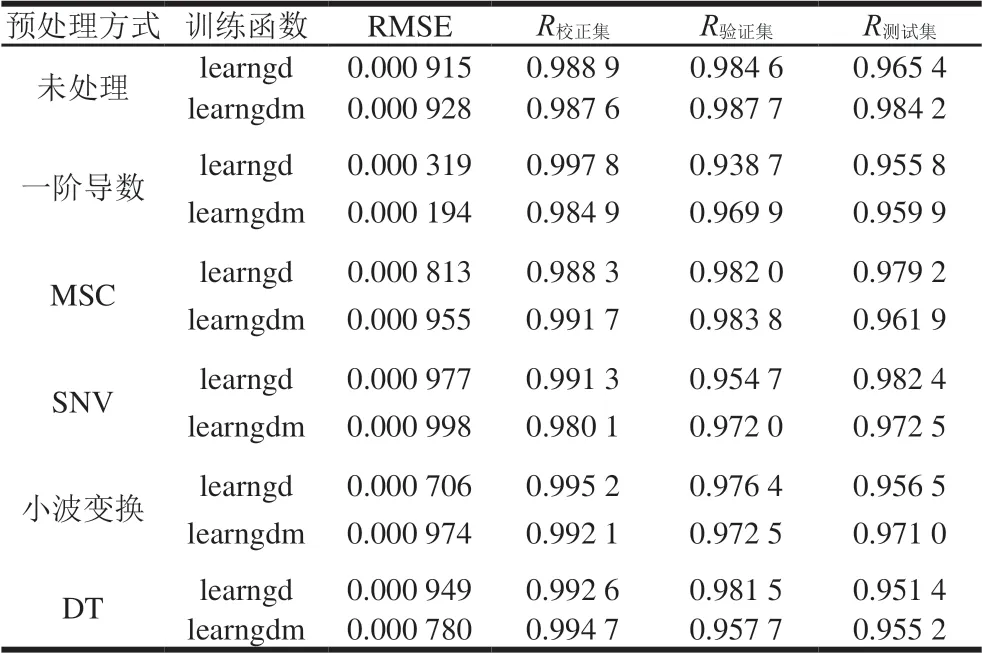
表5 光谱定量预测模型的网络学习函数优化Table 5 Optimization of network learning function for spectral quantitative prediction model
2.3.4 隐含层神经元数的确定
隐含层神经元数对泰国茉莉香米含量的预测见表6。对于未处理大米近红外光谱,神经元数为6或7时,BP神经网络RMSE较小,分别为0.000 907、0.000 921,综合考虑模型的R校正集、R验证集、R测试集,将模型隐含层神经元数设为7,此时模型的预测效果较好。

表6 处理光谱定量预测模型的隐含层神经元数优化Table 6 Optimization of hidden layer neurons for spectral quantitative prediction model with different spectral data preptreatments
对于一阶导数预处理后的大米近红外光谱,神经元数为7和10时,BP神经网络RMSE较小,分别为0.000 152、0.000 161,综合考虑模型的R校正集、R验证集、R测试集,将模型隐含层神经元数设为10,此时模型的预测效果较好。
对于MSC、SNV和小波变换预处理后的大米近红外光谱,综合考虑模型的RMSE以及R校正集、R验证集和R测试集, 确定神经元数为7,此时模型的预测效果较好。
对于DT预处理后的大米近红外光谱,神经元数为5时,BP神经网络预测效果较好,模型的RMSE、R校正集、R验证集、R测试集分别为0.000 868、0.993 5、0.979 1、0.973 2。
2.3.5 学习速率的确定
学习速率是决定权重调整量的关键因素。学习速率取值过小,网络收敛速度慢。学习速率取值过大,可能导致网络在误差的最小值附近来回跳动,产生振荡现象,导致网络发散而不能收敛。对于标准BP神经网络,学习速率取值范围在0.1~0.75之间。学习速率对泰国茉莉香米含量预测的影响见表7~12。未处理、一阶导数、MSC、SNV、小波变换、DT处理后的近红外光谱预测泰国茉莉香米含量时,当学习速率分别为0.30、0.30、0.35、0.20、0.60、0.35时,BP神经网络模型取得最佳的预测效果。
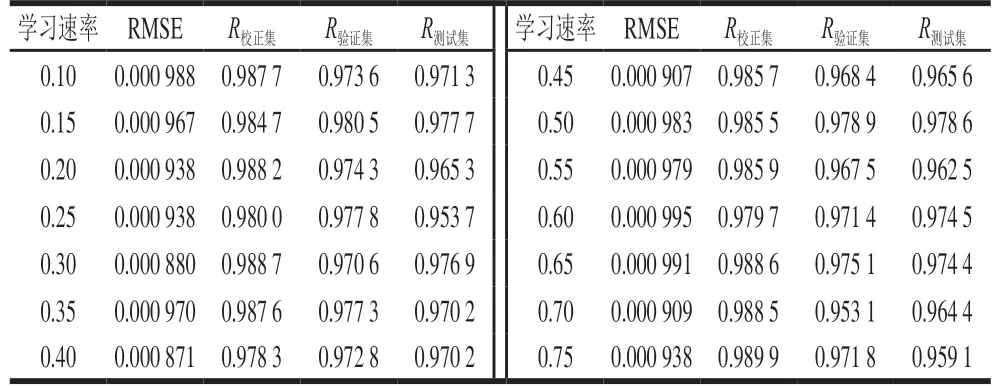
表7 未处理光谱定量预测模型的学习速率优化Table 7 Optimization of learning rate for spectral quantitative prediction model without spectral data preprocessing
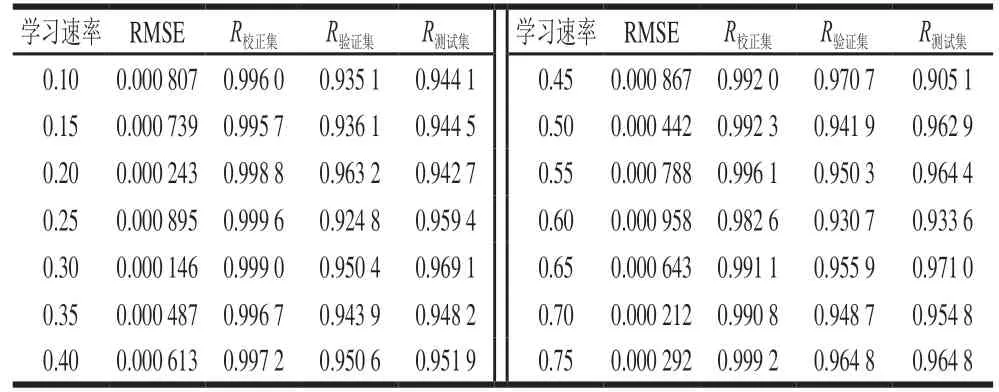
表8 一阶导数处理光谱定量预测模型的学习速率优化Table 8 Optimization of learning rate for spectral quantitative prediction model with first derivative preprocessing
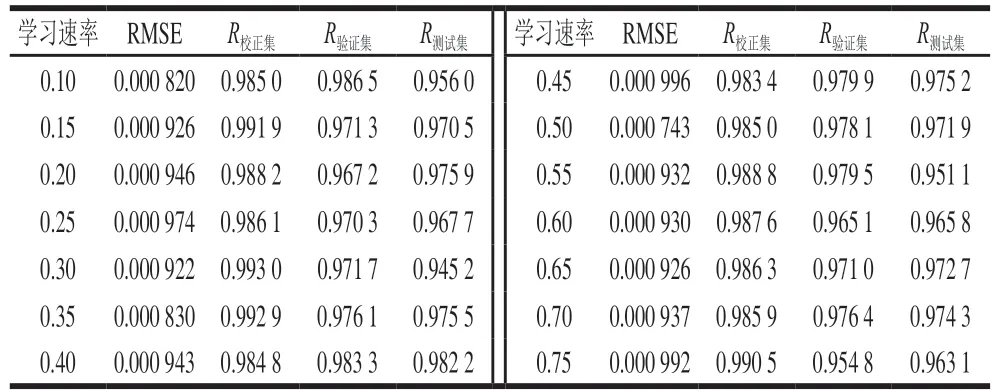
表9 MSC处理光谱定量预测模型的学习速率优化Table 9 Optimization of learning rate for spectral quantitative prediction model with MSC preprocessing
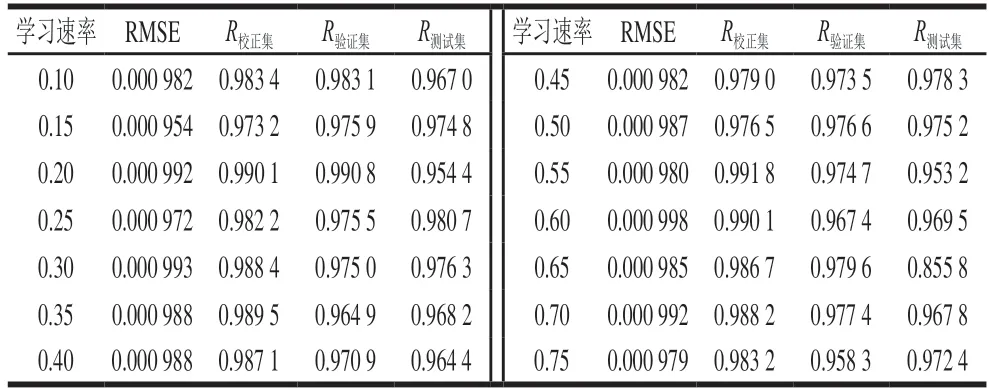
表10 SNV处理光谱定量预测模型的学习速率优化Table 10 Optimization of learning rate for spectral quantitative prediction model with SNV preprocessing
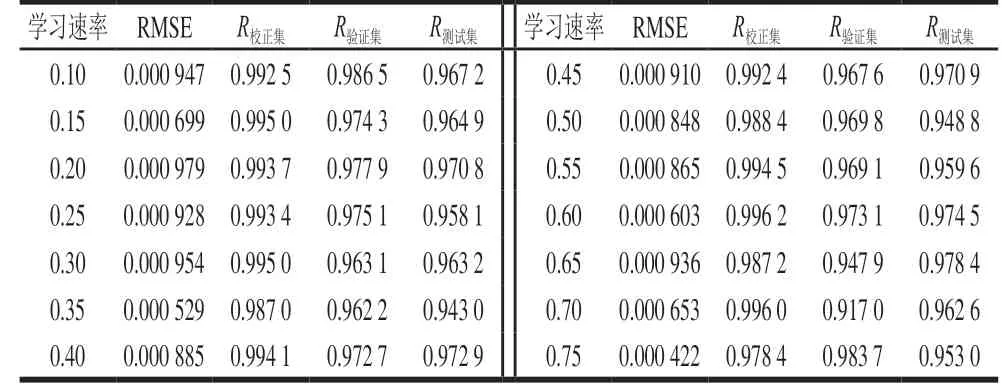
表11 小波变换处理光谱定量预测模型的学习速率优化Table 11 Optimization of learning rate for spectral quantitative prediction model with wavelet transform preprocessing
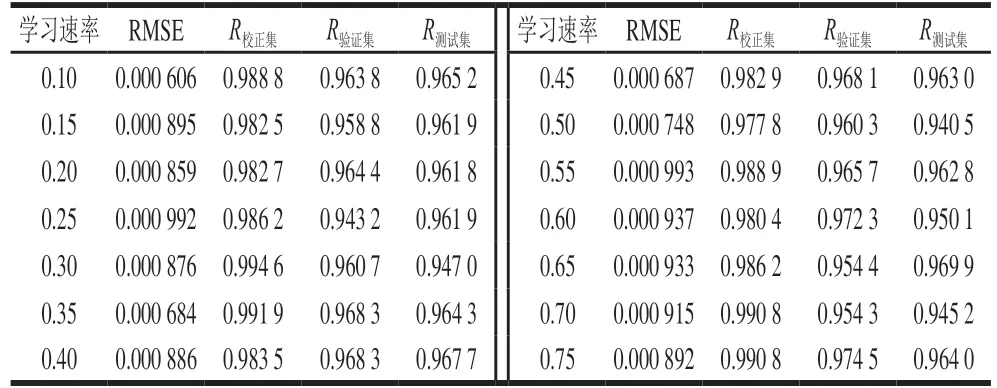
表12 DT处理光谱定量预测模型的学习速率优化Table 12 Optimization of learning rate for spectral quantitative prediction model with DT preprocessing
2.4 BP神经网络预测结果及性能测试
选择每种处理方式最优的BP神经网络过程参数组合进一步优化,泰国茉莉香米含量预测的最优BP神经网络结构及预测效果见表13,与未处理光谱相比较,除SNV函数外,其余预处理函数RMSE都较低,说明模型的预测精度得到提高。而且处理光谱R校正集显著提高,均达到0.99以上,接近于1,说明模型预测效果好。其中与其他预处理函数相比,综合考虑MSC预处理后的BP网络预测效果最好,此时,模型的RMSE、R校正集、R验证集、R测试集分别为0.000 830、0.992 9、0.976 1、0.975 5。
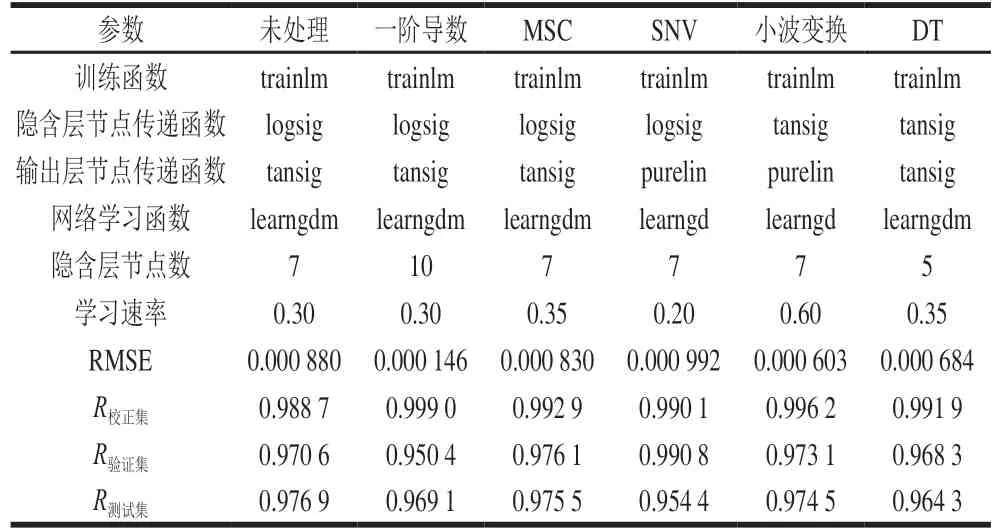
表13 BP神经网络结构的泰国茉莉香米纯度定量预测结果Table 13 Results of quantitative prediction of Thai jasmine rice purity based on optimal BP neural network structure
3 结 论
采集不同含量泰国茉莉香米的混合大米近红外光谱。结果表明,所有样品近红外光谱在波峰、波形上十分相似,在波长1 200、1 440、1 570、1 720 nm附近有明显吸收峰,在波段1 000~1 100、1 200~1 300、1 420~1 799 nm范围内,吸光度具有明显的差异。通过对光谱数据做一阶导数、MSC、SNV、小波变换、DT 5种预处理,并采用CARS法挑选特征波长。结果表明,未处理、一阶导数预处理、MSC预处理、SNV预处理、小波变换预处理、DT预处理后的光谱分别得到48、128、48、18、69个和128个特征波长。
以特征波长对应的吸光度为BP神经网络输入层神经元,以大米样品中泰国茉莉香米的含量为输出层神经元,设计BP神经网络算法的结构和参数,研究泰国茉莉香米含量预测模型。结果表明,MSC预处理后的光谱用于建立BP神经网络预测泰国茉莉香米含量获得了较好的预测效果,此时BP神经网络算法的结构为:训练函数trainlm,隐含层传递函数logsig,输出层传递函数tansig,网络学习函数learngdm,网络输入层神经元数为48,隐含层神经元数为7,输出层神经元数为1,学习速率0.35。所建立模型的RMSE、R校正集、R验证集、R测试集分别为0.000 830、0.992 9、0.976 1和0.975 5,具有较好的定量预测效果。
