高铁建设环境人员防入侵安全检测方法研究
2022-02-23马利伟周明阳刘国宁
马利伟,周明阳,刘国宁
(郑州大学机械工程学院,河南 郑州 450001)
1 引言
高铁建设场景中,运行着大型特种装备,其具有尺寸大,自重大,运行负荷大等特点。典型的高铁建设装备,如高铁提梁机,运梁车和高铁架桥机等,最大尺寸可达45米或更大,如表1所示。它们担任着提梁、运梁和架桥等任务。相应地,高铁大型装备运行过程中,操作人员会存在多个大面积盲区。这不但影响到现场工作人员的安全,也会影响到工作效率。因而,给装备添加“眼睛”和赋予“视觉感知”,应用图像识别技术实时发现施工和作业区域的人员就变得很重要。

表1 高铁建设装备主要参数Tab.1 Main Parameters of High-Speed Railway Construction Machine
视觉检测在经过一个机器学习训练的过程,从样本中抓取目标物体的特征,组建分类器,用组建好的分类器在视频图像中将特定目标物体识别出来。近年来,许多场景引入视觉检测的方法。文献[1]针对城市交通场景,借助深度网络分层提取视觉场景中候选区域多类目标的深度特征,完成了对目标物的识别检测。文献[2]针对变电站场景,提出将计算机视觉领域的深度学习技术应用于变电站场境下行人检测问题中。文献[3]针对铁路轨道场景,对传统的深度卷积网络神经做出改进,应用到铁路入侵行人识别。文献[4]针对煤矿井下的场景境,提出一种改进的Faster RCNN煤矿井下行人检测方法,并做了验证。文献[5]针对普通道路场景,提出一种基于深度学习的车辆和行人检测算法型训练,实现了在普通道路场景中的车辆检测和行人检测的功能。文献[6]针对高铁检票环境,提出一种改进的基于梯度直方图特征与Adaboost分类结合的行人检测算法,并用于高铁闸机智能系统的行人检测模块。提高了检测速度,满足了闸机对行人的实时检测要求。
目前,针对高铁建设大型装备作业区域内人员检测和监控报警的研究较少。本研究采用在装备端布置监控的方法,获取现场图片信息,利用OpenCV级联分类器训练框架和Python编程语言,基于Haar-like特征与Adaboost算法对高铁建设装备典型作业环境图像进行描述与学习的方法,构建高铁建设作业环境内的人员在线检测系统,在保证作业过程中的人身安全的同时,提升人机协同能力,提高作业效率。并对训练方法做改进,加入正样本更新的方法,以提升分类器的准确性和自适应性。
2 研究基础与方法
机器学习需要选用合适的特征方法来描述图像中的工人。目前主流的图像特征描述方法有边缘特征、形状特征、统计特征和变换特征等,其中具有代表性的特征有Haar-like特征、HOG(Histogram of Oriented Gradient)特征、LBP(Local Binary Patterns)特征等[7-8]。Haar-like特征能够较精确地描述出图像局部区域的灰度变化,并可使用积分图的方法快速计算出特征值,使得对目标的检测速度获得提升;HOG特征是对图像局部区域的梯度方向直方图进行统计与计算来获取特征数据,但HOG特征数据具有维数较高的特点,造成HOG特征运算速度较慢;LBP特征对图像的局部纹理特征有很好的描述,具有旋转不变性和灰度不变性的特点[9-12]。考虑到计算难度及高铁建设装备典型工作场所的特点(如箱型梁钢筋骨架会产生复杂纹理影响特征识别),选用Haar-like特征。
目前常用到的分类器有Adaboost、支持向量机(SVM)和神经网络分类器。Adaboost分类器是一种自适应的boosting方式分类器,针对同一个训练集训练出若干个不同的分类器,然后把这些分类器结合起来,构成一个级联分类器。在Adaboost分类器训练过程中,会剔除一些不必要的训练数据特征,将重点放在更重要的数据特征上,加快了训练的过程[12];SVM分类器是基于结构风险最小化原理的有监督统计学习方法,常用于解决小样本、非线性及高维模式的图像识别问题[13];神经网络分类器是利用神经网络算法构建的分类器,通过调整神经元之间的联接权,使得网络输出更为合理的结果,但该分类器易出现过拟合的问题[14-15]。考虑到典型的样本特征,即人员特征与环境特征区别相对明显及识别训练时训练速度等因素,选用Adaboost分类器。
2.1 Haar-like特征
Haar-like特征是用于物体识别的数字图像特征,分为三类:边缘特征(图1a-d)、中心环绕特征(图1e-f)、线性特征(图1g-n):

图1 Haar-like特征Fig.1 Haar-Like Feature
使用Haar-like特征值来描述图像,Haar-like特征模型可通过放大/缩小和平移的方式产生子特征模型,并利用这些特征模型填充铺满整个检测区域。使用不同的特征值描述不同的物体,特征值CHɑɑr的计算方法如式(1)所示,第i检测区域的所有白色区域内像素和与黑色区域内像素和的差值乘以第i检测区域相应的权重系数TiSBTi。SB

式中:SW、SB、Ti—白色区域、黑色区域、第i区域相应的权重系数。
2.2 Adaboost算法
Adaboost算法的基本原理是将多个分类器进行合理的权重组合,最终形成一个级联分类器。它是采用迭代的思想,每一次的迭代过程都会产生一个分类器,同时该分类器也参与下一次迭代过程。每一次的迭代过程会根据上一次迭代产生的分类器的效果进行权重修正,将能正确分类的样本权重减小或剔除,错误分类的样本的权重加大。如此重复,直到分类器的个数达到一个指定的级数阈值N就停止学习,最后再将各个分类器进行合理的权重组合,即得到一个级联分类器。
3 在线人员检测系统开发
3.1 系统整体结构设计
该系统总体结构设计,如图2所示。(以运架一体机为例),包含了设备盲区车载相机、视频存储服务器、分析处理服务器、报警服务器和无线网桥传输网。

图2 系统结构图Fig.2 System Structure Diagram
车载相机通过无线网桥将视频数据传输至视频存储服务器,分析处理服务器从中读取实时视频进行入侵物监测,并将结果传输至报警服务器,报警服务器可以借助网络实现报警信息的发布,设备端报警装置执行报警动作。
系统整个运行流程,如图3所示。首先准备初始正/负样本集,正样本集是含有目标物的图片所组成的集合,每张图片宽高像素值均一致;负样本则是不含有目标物的图片所组成的集合,负样本每张图片宽高像素值需大于正样本,无需尺度归一化处理;其次,将样本集作为输入,进行分类器训练,创建分类器;最后,进行在线监测。

图3 检测流程图Fig.3 Detection Flowchart
为了提升分类器的正检率与自适应性,并使分类器对当前环境具有更强的针对性,对方法做出以下改进:在整个检测过程中加入样本自更新功能,具体流程,如图3所示。在分类器测试过程中,当检测到物体是目标物的置信度P>75%时[16],即视为检测到目标物,同时开启报警策略;如果检测到的物体是目标物的置信度P>95%时,便保留数据,并作进一步的图像处理(截取、筛选、加时间戳、灰度化、尺度归一化等),更新替换掉原正样本训练集中创建时间较早的样本,并进入下一次分类器训练过程。之后,将相邻两次的分类器对同一个测试样本进行测试,将正检率高的分类器用于下一次在线检测中。以此循环即不会使训练样本集无限增加;同时也使分类器更加契合当前工况。
3.2 构建样本库
训练集选取过程主要是正负样本的收集与处理。以梁场为例,图像正负样本收集处理情况,如表2所示。

表2 正负样本集属性Tab.2 Attributes of Positive and Negative Sample Sets
梁场内工作涉及制梁、质量检测、安全监督和辅助梁的提升搬运等。人员典型姿态有站立、弯腰、蹲坐。人员身着工装,佩戴安全帽。当前,工业界未发布任何高铁梁场环境背景下的行人检测数据。因此,所收集的正样本图片来自多个高铁梁场作业区域内正在施工的工人现场图片。正样本的处理具体流程,如图4所示。

图4 正样本处理流程图Fig.4 Positive Sample Processing Flowchart
首先,对原始图片收集,并将目标物(工作人员)截取出来;其次,将这些图片进行尺度归一化处理,参考目前广泛应用的INRIA行人数据集正样本尺度,将正样本宽×高尺度定为70px×134px。简单的拉伸与缩放,极易造成图片中目标畸形现象发生,为了避免畸形现象发生,并保证原始图像在新图像的区域最大,加入以下正样本处理方法:获取截取图像的宽高像素值(W*H),判断70/W与134/H的关系。当70/W较小时,整张图像扩大/缩小70/W倍,接着在高度方向填充至134px;当两值相等时,直接将图片放大/缩小134/H倍;当134/H较小时,图片放大/缩小134/H倍,宽度方向边缘填充至70px。这里利用OpenCV的resize函数进行放大与缩小,放大使用的是INTER_CUBIC(双三次插值)方式;缩小使用的是INTER_AREA(区域插值)方式。这样处理方式可有效避免波纹现象出现,使效果达到最好。之后,将尺度归一化的图片进行灰度化处理,并保存图片;接着,创建描述文件pos.vec文件,将每一个样本的信息,如绝对路径、目标个数(人员个数)、检测起始坐标、样本宽与高的像素等信息写入其中。处理好的正样本集图片共计700张[17],宽高像素值均为70px×134px,如图5所示。

图5 正样本集示例Fig.5 Examples of Positive Sample Sets
负样本是不含有工人的图片,数量一般是正样本数量的(2~3)倍。所收集的负样本同样是来自梁场环境,总数为2000张,如图6所示。图片只做灰度化处理,不做尺度归一化处理,但图片的宽高像素值均大于70px×134px,并用neg.txt文件描述负样本。此文件只记录每一个负样本的绝对路径。正样本要求目标物与背景有较高的辨识度。在高铁梁场作业区域内,工人穿着工装,在灰度化的图像中与背景区别较大,辨识度高,所以灰度图像已完全满足正样本集要求;同时,考虑原始图像数据量大,计算复杂且耗时长,所以将所有样本进行灰度化处理,以简化计算,减少运算耗时。

图6 负样本集示例Fig.6 Examples of Negation Sample Sets
3.3 分类器训练
训练过程采用级联分类器训练方法,该方法采用Haar-like特征与Adaboost算法结合的训练方式进行深度学习。训练方法的系统框架,如图7所示。用Haar-like特征描述输入的正负样本集,并计算Haar-like特征值,得到特征集;然后训练产生多个弱分类器,从中选取最优弱分类器,调用Adaboost算法训练出强分类器,当强分类器达到预设定级数后停止训练,并将这些强分类器进行权重组合构建出一个级联分类器。

图7 训练系统框架Fig.7 Framework of Training System
级联分类器训练过程中,参数的设置对训练时长和分类器的精确性有着非常大的影响。重要参数的设置,如表3所示。根据样本容量及所需精度选取训练分类器的级数(nstages),这里选用15级;nsplits为每个弱分类器特征个数,一般设定为1;Mem为内存空间分配大小,空间越大,计算速度越快,根据计算机硬件配置情况,这里设定为4096MB;Mode为Haar-like特征类型参数,训练框架提供两种参数值BASIC与ALL。①BASIC表示只使用垂直特征,②ALL表示使用所有垂直特征和45°旋转特征,这里选用ALL;Symmetric对称参数用来描述目标是否垂直对称,对称选用-sym,不对称选用-nonsym,这里目标物为梁场工人,所以选用-nonsym;最小正检率(minhitrate)为每级分类器正样本的正检率,这里选取默认值0.995;最大误检率maxfalsealarm参数分类器的每一级强分类器的分负样本分错的最大比例,训练过程中,当分错比例小于此设定值,便说明此级强分类器训练成功,并跳入下一级的强分类器的训练,这里设定此参数为0.5;weighttrimming为样本剔除比例,在每级强分类器的训练中,每训练一个强分类器前将所有样本(包括正样本与负样本)按权重从小到大排列,并将权重最低的weighttrimming*sum(正负样本总和)个样本去除,因为当某个样本权重很小,就说明这个样本总能被正确的分类,删除这些已经能被正确分类的样本,让训练更多集中于还不能正确分类的样本上,以提高训练效率。这里选取默认值0.95。参数设定之后开始训练。

表3 训练参数设置Tab.3 Training Parameter Setting
4 实验对比与分析
训练好分类器,进入测试阶段。测试硬件条件为:Windows 10系统,处理器为Inte(lR)Core(TM)i5-4200 CPU@2.80GHz,显卡为NVIDIA GeForce GT 710,工业相机一个,分辨率为1280*720。整个测试流程,如图8所示。首先,加载第一次训练构建的分类器WorkerCascadeClassifier.xml文件;其次,开启监控摄像头,获取监控图像数据,考虑到计算速度,将获取的帧图像数据进行灰度化处理,以简化下一步检测运算;接着,进行在线检测。根据检测返回值判断是否有人员侵入,返回值为空,则表示无工人,直接进行图像回显。返回值非空(即目标物在图像中的起始坐标和所占宽高像素值),则表示有工人侵入,并在彩色图片中对目标物进行框选定位,同时作彩色图像回显和执行报警策略。

图8 测试系统流程图Fig.8 Test System Flowchart
在框选过程中,通常会出现多个矩形框对同一个目标同时进行多次框选的现象。为了避免这一现象,这里使用非极大值抑制法,只选取最大的矩形框进行目标物的框选定位。
为逐步提高分类器的正检率和自适应性,加入正样本自更新方法。当检测到的物体是目标物的置信度P>95%时,则便保留数据,并作进一步图像处理(筛选、加时间戳、截取、尺度归一化、灰度化等),更新替换掉原正样本训练集中创建时间较早的样本,并进入下一次分类器训练过程,构建新的分类器。然后,判断新分类器的正检率是否大于原分类器,若大于原分类器,则使用新分类器进行在线检测;否则,继续沿用原分类器。以此循环,提高分类器的正检率和自适应性,使分类器对当前环境具有更强的针对性和适用性。
测试阶段共进行了四次分类器循环迭代训练,得到四个分类器。并通过同一个测试集对这四个分类器进行测试评估,测试阶段所使用的测试集由两大部分组成,一部分是500张设备当前工作的高铁建设现场图片组成,包含高铁建设环境中工人工作中典型的姿态(站立、弯腰、蹲坐等),其中含有工人的图片有350张,共有437人,负样本150张。另一部分由当前使用最广泛INRIA行人数据集[18]组成,选取其中100张正样本(共有132人)和100张负样本。经过识别检测结果,如图9所示。
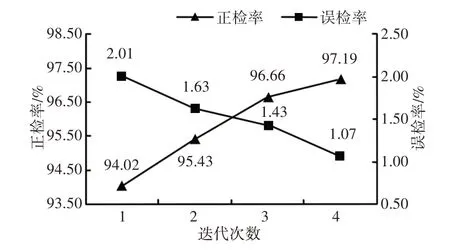
图9 分类器的正/误检率实验曲线Fig.9 Experimental Curve of Classifier’s Correct/Error Detection Rate
自更新方法共经过四次循环迭代训练,由图9可知:分类器的正检率整体呈上升趋势,误检率也相应地减少,第四次循环构建的分类器的正检率与误检率分别为97.19%、1.07%,相比首次训练构建的分类器的正检率增加了3.17%,误检率减少了0.94%。为了验证自更新算法的有效性,还将改算法还与文献19中HOG+Adaboost的行人检测方法进行对比。对比结果,如表4所示。

表4 检测结果Tab.4 Detection Result
由表4可以看出,文献19中HOG+Adaboost算法人员检测的正检率为95.61%,自更新算法经过四次迭代得到的分类器,其正检率比HOG+Adaboost算法大1.58%,并且误检率比其小0.38%。由图9与表4可得,自更新算法在经过两次迭代时,分类器的正检率基本与文献19中HOG+Adaboost算法相持平;自更新算法在经过三次迭代后得到的分类器,其误检率基本与HOG+Adaboost算法的误检率相持平,但正检率已经超HOG+Adaboost算法1.05%。
选用第四次循环构建的分类器对高铁梁场现场进行系统功能测试。该系统具有监控设备选择;调整监控设备所对方位、背光补偿、日/夜模式;当光线暗时,还可开启辅助照明;对检测结果进行呈现;对历史监控数据进行回放呈现;对采集到的目标物图像进行查看与管理和报警日志查询和进行分屏显示等功能。系统对正在捆扎箱型梁钢筋骨架的工人进行了识别检测,测试结果,如图10所示。该系统成功地检测出工人,并做出了报警信息提醒。之后,又进行长期的现场系统测试,结果显示该分类器达到了预期设计的目的要求;验证了该系统的可靠性和检测方法的可行性。

图10 在线测试结果Fig.10 On-Line Test Results
5 结语
利用Python语言和OpenCV级联分类器训练框架,用Haarlike特征描述梁场环境图像中工人的典型姿态特征(站立、弯腰、蹲坐等),用Adaboost算法进行迭代训练,训练出工人级联分类器WorkerCascadeClassifier.xml。并对该方法做了改进,加入正样本自更新的方法,进行了四次循环迭代训练。经过静态图检测测试,从第一次训练构建的分类器的正检率到第四次构建的分类器的正检率依次提升,第四次分类器的正检达到97.19%;并用第四次构建的分类器作了长期的现场测试,系统既能长期的稳定运行,也能成功检测出监控中的工人,实现了预设的功能。为工人的人身安全提供了保障,提升了人机协同作业能力,提高作业效率。此外,该方法还可运用到其他智能设备中,如车辆自动驾驶,为目标物智能识别功能的实现提供参考意义。
