基于事件相机的无人机目标跟踪算法
2022-02-21朱强王超毅张吉庆尹宝才魏小鹏杨鑫
朱强,王超毅,张吉庆,尹宝才,魏小鹏,杨鑫
(大连理工大学计算机科学与技术学院,辽宁 大连 116000)
0 引言
如今无人机已在各个领域发挥着不可替代的作用,而目标跟踪是无人机一项极为重要的功能,当无人机仅搭载RGB相机时,无法有效适应较为复杂的跟踪场景:(1)由于桨叶拉力和离心力产生共振和受外界风力影响,拍摄的图像较模糊,无法有效利用计算机视觉算法进行单目标跟踪;(2)无人机的工作环境较为复杂,用传统相机结合视觉算法在复杂光照场景下鲁棒性低,在夜间或过曝光场景下无法有效跟踪物体。为解决上述无人机视角下的目标跟踪问题,本文采用无人机搭载动态和有源像素视觉传感器(DAVIS)事件相机[1]的方法进行目标跟踪。利用DAVIS事件相机特殊的成像机制,避免因目标物体快速运动出现成像模糊,从而有效适应无人机抖动、特殊光照等复杂场景,采集的待跟踪物体的边缘信息较RGB相机更有效。据此,设计了基于事件与灰度图的双模态融合跟踪网络,有效利用事件域数据的边缘信息和APS域数据的纹理信息。为更好地训练事件与灰度图双模态融合跟踪网络,用运动捕捉系统Vicon制作了无人机视角下的目标跟踪Event-APS 28数据集。实验结果证明,设计的网络能更好地适应无人机复杂的跟踪场景。
1 国内外研究现状
1.1 相关滤波跟踪算法
相关滤波跟踪算法最初在信号处理与分析领域用于描述2个信号之间的相似程度。BOLME等[2]最早提出最小平方误差输出总和(MOSSE)算法,将相关滤波应用于目标追踪。对待跟踪的目标视频帧需要寻找其对应的滤波模板,并和视频帧做相关性操作,得到响应图。为加快运算速度,MOSSE算法还引入了快速傅里叶变换[3]操作,将卷积操作变换为点乘操作,从而大大降低了模型的计算量。
基于MOSSE算法的循环结构跟踪相关滤波(CSK)算法[3],在MOSSE算法基础上加入了正则项,且为防过拟合,引入了核函数和循环矩阵。核化相关滤波(KCF)算法[4]将多通道梯度直方图作为输入,以提高目标跟踪的精度,采用“岭回归”和“核函数”等技巧简化运算,是对CSK算法的进一步改进。相关滤波跟踪器具有较高的跟踪速度,应用广泛。
虽然相关滤波跟踪方法在目标跟踪中具有不错的效果,但仍存在一些问题。首先,鲁棒性较差,遇到遮挡等情况难以满足跟踪要求;另外,准确率不及深度学习跟踪算法。
1.2 深度学习跟踪算法
近年来,随着深度学习的发展,单目标跟踪领域涌现出很多优于传统跟踪方法的深度学习算法。BERTINETTO等[5]提出基于全卷积孪生网络的单目标跟踪算法(fully convolutional siamese network,SiamFC),顾名思义,孪生神经网络的结构是对称的,2个分支的输入分别是第1帧的目标区域和待搜索的视频帧,如果输入的视频帧不符合尺度要求,则需要用均值进行填充。SiamFC通过AlexNet[6]提取2个分支的图像特征,并对得到的模板帧特征和搜索帧特征进行互相关操作,得到待搜索视频帧的目标框。之后BO等[7]在SiamFC基础上引入了区域推荐生成网络(region proposal network,RPN),实现了多个尺度的图像处理,准确回归出目标位置。WANG等[8]提出的SiamMask,通过在SiamFC网络上添加mask分支,以适应由物体形状位置实时生成的包围框。
基于循环神经网络的目标跟踪算法不同于基于卷积网络的跟踪算法,可针对视频跟踪序列的时序信息进行建模,利用循环神经网络保存视频的帧连续性信息[9]。经典的有结构关注网络(SANet)、基于动态记忆网络等跟踪算法。
虽然基于深度学习的算法已表现出优异的性能,但由于RGB相机有限的帧率和有限的动态范围,使得无人机在复杂光照场景下的鲁棒性较差,在夜间低光照或过曝光场景下无法有效跟踪目标。
1.3 事件相机
事件相机在流体力学、显微镜、粒子跟踪、荧光成像、机器人等领域有广泛应用[9]。传统的RGB相机因受成像机制影响,存在数据冗余、欠采样和处理延迟等不足,而仿生的事件相机其成像机制类似于视网膜,采用的是异步事件驱动机制,当某个像素的亮度变化累计达到一定阈值时,输出一个“事件”。“事件”是具有横纵坐标值、像素极性、时间戳的一个四维向量:

其中,posi为事件的像素坐标,ti为发生该事件的时间戳,pi为极性,其值为-1和+1,分别表示光强的减弱和增强。
2 方法综述
首先,引入DAVIS事件相机,用其代替传统的RGB相机,DAVIS事件相机既可以传输事件信息(Event图像),又可以传输灰度图(APS图像);其次,设计事件与帧图像融合的目标网络。在网络中设计事件成像和APS成像的特征融合模块,有效利用事件域和APS域的优点,以应对复杂光照、快速抖动等场景下无人机的目标跟踪。为更好地训练网络,用事件相机和Vicon运动捕捉系统构建了无人机视角下的Event图像和APS图像跟踪数据集。
2.1 Event-APS 28数据集制作
为同时利用事件域信息和APS域信息,设计了能融合2个模态的信息特征提取网络,APS图像能有效描述待跟踪目标的纹理信息,而在低光照、快速运动场景下,Event图像更注重目标物的边界轮廓信息,且受光照影响较小。目前的开源目标跟踪数据集中尚未见APS和事件相机相融合的数据集,为更好地训练网络,笔者制作了Event-APS 28目标跟踪数据集。
本文用DAVIS事件相机和Vicon运动捕捉系统采集数据集,通过相机校准、创建对象、跟踪拍摄等步骤得到数据集中待跟踪物体的目标框,避免人工标注每帧的真值。Vicon主要基于计算机图形学原理,通过用分布在空间不同角度的相机记录待跟踪目标物,得到不同时间维度的空间坐标(x,y,z)。用12个光学相机环绕场地,在待跟踪物体的边界用双面胶粘贴“Marker”反光点[10],运动捕捉系统的视觉识别设备实时记录Marker在三维空间中的位置信息,当粘贴了Marker的物体运动时,相机会连续拍摄其运动图像,并保存标志点的轨迹序列,事件相机也进行同步拍摄。对无法遥控的模型,用吊绳悬挂,通过牵引使其运动。
2.2 Event-APS 28数据集分析
为模拟无人机的视角目标跟踪,选用28种目标模型物体制作Event-APS 28数据集,包括迷彩目标物体、工程车辆、民用交通工具、动物、其他常见运动物体5个类别,分别占28%,16%,24%,24%,8%。表1为Event-APS 28数据集与目前主流的事件数据集对比。

表1 Event-APS 28数据集与其他事件数据集对比Table 1 Comparison of Event-APS 28 dataset and other event datasets
Event-APS 28数据集分为正常光照、过曝光、运动模糊和低光照4种场景。图1从上到下依次为这4种场景下数据集视频序列展示图,4种场景图中,上方的为APS图像,下方的为叠加Event图像。
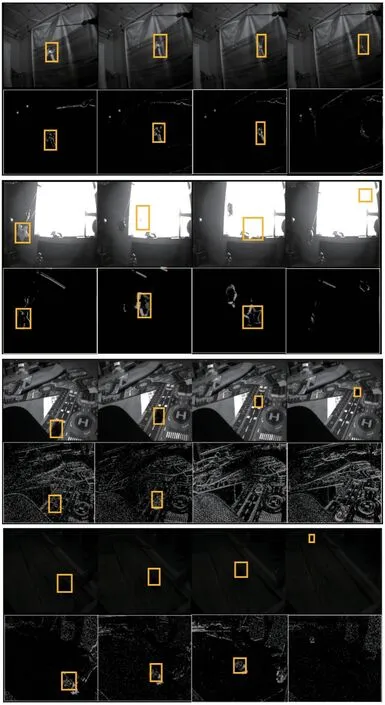
图1 Event-APS 28数据集部分展示Fig.1 Partial display of the Event-APS 28 dataset
3 无人机目标跟踪算法
3.1 网络架构
借鉴ATOM网络结构的设计思想,将目标跟踪分为目标分类器和目标框回归模块两部分。目标分类器用于目标分类,对目标进行粗跟踪,目标框回归模块用于精细定位目标。图2为本文设计的事件与灰度图双模态融合跟踪网络,该网络包含2个孪生分支,上半部分为参考分支(reference),下半部分为测试分支(test)。参考分支输入的为参考帧的灰度图与两帧之间叠加的事件域图像;测试分支输入的为当前视频帧的灰度图与两帧之间叠加的事件域图像。提取特征部分借鉴的是迁移学习的思想,即训练网络加在线微调的思想,其中预训练网络采用已在ImageNet[13]数据集上进行预训练的VGG-16网络。

图2 事件与灰度图双模态融合目标跟踪网络架构Fig.2 Target tracking nework architecture of event and grayscale image dual-mode fusion
在参考分支中,APS域与事件域的特征提取网络采用预训练好的VGG-16网络,提取VGG-16网络第10个卷积层(低维特征)与第13个卷积层(高维特征)的中间结果输出,分别得到参考分支APS域的低维特征与高维特征,参考分支事件域的低维特征与高维特征。通过特征融合模块(feature fusion module),将对应维度的APS域特征与事件域特征融合,得到融合后的结果:

由于本文采用的是孪生网络结构,参考分支与测试分支结构相同,同理可得测试分支低维特征信息与高维特征信息融合后的中间结果:
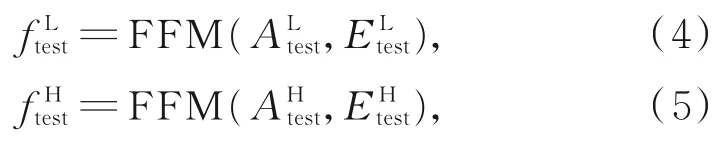
高维特征具有更强的语义信息,但分辨率很低,对细节的感知能力较差;而低维特征的分辨率较高,包含的细节信息更多[14],故将2个分支的APS域和事件域的低维特征信息融合,得到低维特征图,并将其输入分类器,完成目标分类任务。分类器的网络结构较为简单,首先,对参考分支低维特征信息的中间结果进行卷积和精准区域池化(PrPooling)操作,将得到的中间结果视作卷积核,对测试分支融合后的低维特征信息进行卷积操作。分类器对输入特征信息的操作可表示为

其中,C3代表对特征图进行3×3卷积操作,Scorecls为概率矩阵。
在设计目标框回归模块时,综合利用低维特征和高维特征的优点,将两者共同作为输入,将参考分支的特征信息经3×3卷积操作、通道注意力机制(CA)和PrPooling操作后,分别与通过3×3卷积操作的测试分支特征进行元素级乘,并将得到的特征图分别经过一个全连接层(FC),得到中间结果φL,φH:

目标框回归模块,利用2个维度的中间结果进行连接组合操作,最后通过全连接层得到最终结果:
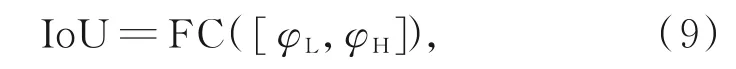
其中,中括号代表2个特征按照通道进行串联组合的操作。
事件域与APS域双模态融合网络的损失函数为

其中,Loss由分类器的损失函数Lcls和目标框回归模块的损失函数共同组成,超参数μ为加权系数,用以平衡目标分类器和目标框回归模块2个分支,IoUi和IoUgt分别为目标框回归模块的预测值和真实值,Nreg为预测的IoU数。
虽然回归模块可提供精准的目标框,但为增强其判别能力[15],本文增加了分类器模块,为分类器模块设计的L2目标函数为

其中,ω为网络层权重,Ncls为预测模块数,γm为对应训练样本的权重,描述其重要程度,xm和ym分别为网络的输入和输出。为防止出现过拟合,在L2目标函数后添加了正则项,ρk为正则项系数。
3.2 特征提取模块
为有效提取事件域和APS域图像的特征,采取迁移学习中的预训练网络与在线微调的方法。用经ImageNet数据集预训练的VGG-16网络,提取事件域和APS域2个模态的信息特征,VGG-16网络由13个卷积层加3个全连接层组成,采用的卷积核较小(3×3),其中比较特殊的1×1卷积核,可视作对图像特征图进行线性空间映射,网络的前几层为卷积层,后几层为全连接层,最后为softmax层[16]。
通过VGGNet网络提取的低层特征感受野较小,保留了细粒度的空间信息,便于跟踪器精确定位待跟踪物体;而高层特征的感受野较大,主要反映的是图像的目标语义特征,对目标变化的鲁棒性较好。本文在参考分支提取事件域和APS域特征时,用第10个卷积层的输出作为低维特征信息、第13个卷积层的输出作为高维特征信息(式(12)~式的计算式分别为:
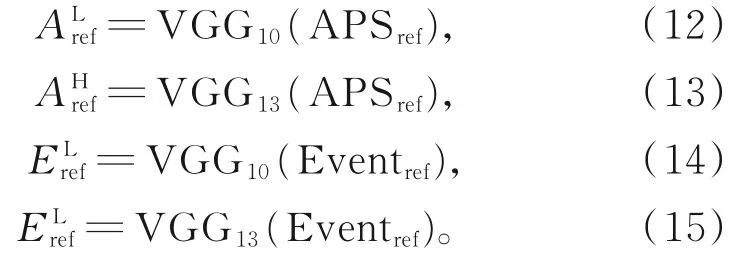
由于本文采用孪生网络结构,参考分支和测试分支具有相同的分支结构,同理可得测试分支APS域和事件域的低维与高维特征信息:


3.3 特征融合模块
APS域包含更多待跟踪物体的纹理信息,而DAVIS事件相机拍摄的事件域数据更关注目标的边缘信息,为使网络更好地适应无人机场景下的目标跟踪,针对事件域与APS域成像的特点,设计了特征融合模块(feature fusion module,FFM)。图3为FFM的网络架构图,其本质是利用事件域信息引导APS域图像的表达。

图3 FFM网络架构Fig.3 Network architecture of FFM
FFM的输入为事件域特征E与APS域特征A,针对事件域的特征信息,求每个通道的均值,并用Sigmoid激活函数处理,Avg表示均值操作,得到特征图τE:

将通过Sigmoid激活函数处理的特征图τE与E进行元素级乘,得到的结果送入通道注意力(channel attention,CA)模块,得到中间结果φE:

中间结果φE与输入的APS域特征进行元素级乘,得到融合后的特征图fout:

将融合后的低维特征图fout作为后续分类器的输入,融合后的高维与低维特征信息作为目标框回归模块的共同输入。
为更好地融合事件域与APS域的特征信息,在FFM中引入CA。FFM在训练网络过程中会增加重要通道的权重,减小不重要通道的权重,从而有效提高网络的性能。FFM中采用的CA机制网络架构如图4所示。

图4 CA机制网络架构Fig.4 Network architecture of CA mechanism
对输入后的特征图X,其特征的通道数为C0,用C个卷积核进行卷积得到特征图U;对特征图U,通道数为C,将通道数分为上、下2个分支,其中上分支中,一部分采用全局池化的方法将每个通道的二维特征(H×W)压缩为一维特征,计算式为
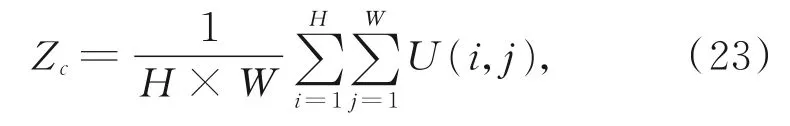
通过对特征图U(C×H×W)全局池化得到Z(1×1×C);另一部分将生成特征图Z中通道对应的权重值。首先通过全连接层,压缩特征的维度,再通过ReLU函数激活,第2个全连接层负责将前面的特征值变为C个通道,最后通过Sigmoid函数激活。经Sigmoid函数激活处理,依次得到C个通道的权重,其中全连接层的参数随损失函数更新。
3.4 网络训练
根据事件域与APS域融合跟踪网络的特点,为有效平衡学习率过大和过小问题,采用Poly策略对学习率进行动态更新:

其中lrnew表示当前学习率,lrbase表示初始学习率,iter表示当前训练的迭代次数,itermax表示总的训练迭代次数,power控制该函数曲线的凸凹性。
事件域与APS域双模态融合跟踪网络在一台配置了20核i9-10900K 3.7 GHz CPU,64GB RAM和NVIDIA RTX3090 GPU的电脑上进行训练。网络训练选用自制的Event-APS 28数据集,用TenosrFlow网络框架进行编写,训练的初始学习率为0.001,epoch为50,BatchSize为16,采用Poly策略实时更新学习率。
4 实验结果与性能分析
4.1 实验结果的定性分析
将拍摄的数据集分为正常光照、过曝光、运动模糊和低光照4种场景,每种场景均按7∶3的比例划分训练集和测试集,并在Event-APS 28数据集上将传统方法和其他深度学习方法与本文方法进行比较,对 比 实 验 中 的 传 统 方 法 有MIL[17]、KCF、TLD[18]、MedianFlow;深 度 学 习 方 法 有SiamFC、CLNet[19]、ATOM、PrDiMP[20]。其中传统方法通过OpenCV提供的工具包实现,深度学习的对比实验利用了这几种算法在Github的开源代码[12],由于上述深度学习方法并未结合事件域信息,因此,实验时用APS域目标跟踪视频序列并进行对比。为有效对比各算法的优劣,绘制不同颜色、不同格式的矩形框,以便定性对比算法效果。
图5为4类场景下各算法跟踪结果的定性对比,其中,(a)为正常光照场景的跟踪结果对比,场景为在跑道上运动的模型卡车,干扰因素为背景杂斑,传统的MedianFlow、MIL、TLD算法跟踪失败,KCF算法能持续跟踪,但精度和成功率不及深度学习算法。由于正常光照低速运动的场景较为简单,APS域图像可提供较为丰富的信息,因此在初始阶段,几种深度学习算法表现均较好,在后续跟踪过程中,本文算法和PrDiMP算法效果相差不大,均略优于ATOM算法,SiamFC算法偏移较大。(b)为运动模糊场景的跟踪结果对比,场景为在木质图案壁纸下快速运动的模型油罐车,干扰因素为快速运动产生的运动模糊和目标尺度变化,传统的TLD、MIL算法均无法跟踪,由于目标物体运动速度较快,KCF和MedianFlow算法丢失目标,由于目标尺度发生变化,SiamFC、ATOM算法的预测精度大大降低,PrDiMP略优于SiamFC算法,虽然本文算法和PrDiMP算法均发生了不同程度的轻微漂移,但跟踪效果明显优于其他算法。(c)为过曝光场景的跟踪结果对比,场景为在较强光强下运动的模型飞机,主要干扰因素为光强和目标物体的尺寸变化,其中MIL、KCF、TLD、MedianFlow、SiamFC、PrDiMP算法丢失跟踪目标,ATOM跟踪偏移较大,而由于本文算法事件域成像不受特殊光照强度影响,APS域图像虽然丢失目标信息,但可在事件域的特征中学习目标位置信息,跟踪结果优于其他算法。(d)为低光照场景的跟踪结果对比,场景为在低光照条件下运动的球体,干扰因素为特殊光照强度、尺寸变化和场景中存在相似物体,在初始阶段,本文算法和PrDiMP算法均保持前几帧的学习特征对目标物体进行定位,随着运动的持续,目标物体尺寸变小,捕捉难度增大,加上在低光照条件下目标纹理信息不丰富,PrDiMP算法出现定位不准确情况,进而丢失目标;KCF、TLD、MedianFlow、SiamFC、ATOM等算法均在后续的跟踪中丢失目标;而本文算法由于事件相机不受特殊光照强度影响,在低光照条件下仍可从事件域中学习目标物体的位置信息,虽然预测框有轻微偏差,但跟踪效果总体上优于同类算法。

图5 不同算法跟踪结果对比Fig.5 Comparison of tracking of different algorithms
4.2 实验结果的定量分析
为客观评价不同目标跟踪网络在Event-APS 28数据集上的性能,用目标跟踪领域常用的2个评判指标:精确度(precision plot,PR)和成功率(success rate,SR)衡量跟踪算法的优劣。PR是视频序列中网络预测的真值中心位置坐标和中心位置的距离误差小于给定阈值的视频帧数量的百分比[21]。对于SR,首先计算目标跟踪视频序列中帧的网络预测目标框与该帧的真实值的重叠面积比,若该比值大于给定阈值,认为成功;反之,则认为失败。
图6为本文算法与其他8种算法在Event-APS 28数据集上的对比实验曲线,其中,(a)为PR曲线,横坐标为位置误差阈值,纵坐标为PR;(b)为SR曲线,横坐标为重叠率阈值,纵坐标为SR。由图6可知,本文算法优于其他算法,本文算法能有效适应无人机场景下的目标跟踪。

图6 各算法对比实验Fig.6 Comparative experimental of different algorithms
表2为各算法在低光照、运动模糊、过曝光和正常光照4种场景下低速运动时跟踪的SR与PR对比,每栏的第1行为SR,第2行为PR,本文中SR的重叠率阈值选择65%,PR的位置误差阈值选择20。由表2可知,在3种挑战性场景下,本文算法均优于其他算法,在正常光照场景下,本文算法PR略低于PrDiMP算法。本文算法SR的整体性能指标达60.2%,PR的整体性能指标达81.6%,均优于其他算法。

表2 SR和PR对 比Table 2 Comparison of SR and PR
通过以上对实验结果的定性和定量对比知,在常规场景下,本文算法和其他几种深度学习算法性能相近,但在富有挑战性的场景下,尤其是在受特殊光照影响丢失图像信息时,本文算法可通过在事件域学到的物体位置信息弥补APS域的不足,从而具有更高的SR和PR。
5 结语
根据事件相机的成像特点,提出了无人机搭载事件相机进行单目标跟踪的方法。由于目前开源的与事件相机相关的目标跟踪数据集较少,本文利用DAVIS事件相机和运动捕捉系统Vicon制作了包含正常光照、过曝光、运动模糊和低光照4种场景的目标跟踪Event-APS 28数据集。根据事件域信息特点,设计了事件与灰度图双模态融合的跟踪网络,将事件域和APS域的特征信息送入特征融合模块进行融合,将低维特征信息送入目标分类器,低维和高维特征信息送入目标框回归模块,得到最终的预测结果。用PR和SR衡量跟踪算法的优劣,实验结果的定性和定量分析表明,在Event-APS 28数据集上,本文算法均优于其他目标跟踪算法,尤其在富有挑战性的场景下,APS域信息失效,本文算法仍可在事件域学习目标物体的轮廓信息,进而实现对目标的跟踪。
