蒙特利尔认知评估量表在中国社区老人中的应用
2022-01-27夏安琪肖世富刘园园
夏安琪,李 军,岳 玲,洪 波,严 峰,苏 宁,肖世富,刘园园#,王 涛#
1.上海交通大学医学院附属精神卫生中心老年精神科,上海 200030;2.上海交通大学阿尔茨海默病诊治中心,上海 200030;3.安徽医科大学附属巢湖医院,合肥 238000
轻度认知功能损害(mild cognitive impairment,MCI)是介于正常衰老和痴呆之间的阶段,此类患者存在主观上的记忆力下降和客观上的认知障碍,但未达到痴呆的临床状态[1]。有纵向研究[2]显示,MCI 患者的痴呆发病率为每年10%~15%,而正常人的痴呆发病率为1%~2%,因此MCI 患者是罹患痴呆的高风险人群。2018年,全球用于阿尔茨海默病防治护理的费用约为1 万亿美元。随着人口老龄化进程不断加深,这一数字将不断上升[3]。由于痴呆的不可逆性,在MCI 阶段即开始干预是减轻社会重担的重要途径[4]。一项纳入41项研究的meta分析[5]表明中国55岁以上老人MCI 的患病率为12.2%,说明中国老人中受MCI影响的人群甚广,因此早期发现MCI 至关重要。
在临床实践中许多老人认为自己的记忆力下降是正常衰老所致,因此为识别MCI 与正常老化需要进行标准化测试以提高筛查率。研究发现,正常衰老表现为单词、句子语音识别[6]以及视觉空间功能[7-8]的下降,而在命名和自我中心定向力方面无功能受损[9-10]。因此,为识别MCI 与正常衰老,在认知功能筛查测试中自我中心的定向力检验及命名能力必须包含在内且应占据较大比重。
目前临床使用最广泛的认知筛查测试是简明精神状态检查(Mini-Mental State Examination,MMSE)。由于MMSE 存在天花板效应,故对MCI 的识别能力不足。蒙特利尔认知评估量表(Montreal Cognitive Assessment Scale,MoCA)能够检测出90%的MCI 受试者,是一种可广泛用于人群筛查MCI 的评估量表[1]。自2005 年MoCA 原版量表诞生,多个不同语言地区相继将其本土化后形成多个版本,不同语言的MoCA 在各个国家和地区表现出不同的敏感度和特异度,总体来说低于原版。因此,为更好地进行临床使用,不同国家地区有必要建立适合本土文化环境的筛查量表,并需要随时间进行修订。
我国使用最广泛的是由英文直译的MoCA 北京版(下文MoCA 均指MoCA 北京版)。对北京市1 001 名社区老年人的MoCA 评估结果表明,在推荐的分界值26 分时,MoCA 的敏感度为90.4%,特异度为31.3%;当分界值降至22 分时, 敏感度为68.7%, 特异度为63.9%[11]。在我国其他地区也发现了同样的高敏感度和低特异度特征[12-13]。本研究针对中国城市老人进行MoCA 的测评,依据年龄、受教育程度进行分层分析,以期为未来认知功能筛查提供建议,并界定其区分正常老人与MCI 受试者的分界值,为早期筛查MCI 提供更可靠的工具。
1 对象与方法
1.1 研究对象
本研究于2011年对北京、上海、宁波、沈阳、合肥、杭州、吉安、南昌、西安、杭州等10 个城市社区老年人进行了认知功能评估调查。依据所在地2010 年全国人口普查数据,在选定社区中对60 岁及以上老人进行随机抽样,随机化由SPSS 软件完成。本调查充分考虑受试者的状态和合作程度,为保证评估的准确性,评估分2次进行以避免疲劳效应。正常老年人(normal elderly,NE)组纳入标准:①认知功能正常。②无严重躯体疾病。③能够配合并完成相关检查。MCI 组纳入标准:①患者自觉存在记忆障碍,或知情者认为患者存在记忆障碍超过1 年。②整体认知功能正常。③客观认知功能评估有记忆障碍存在,且认知功能评分低于同年龄、同文化程度的平均值1.5 个标准差。④临床痴呆评定量表评分为0.5 分。⑤日常生活功能正常。⑥不符合痴呆诊断标准。MCI组排除标准:①各种原因所致痴呆。②抑郁障碍、精神分裂症等重性精神疾病患者。本研究通过上海交通大学医学院附属精神卫生中心伦理委员会批准,所有受试者均签署知情同意书。
1.2 一般资料采集和评估工具
1.2.1 一般资料调查表 包含姓名、年龄、性别、民族、受教育程度、家庭住址、职业、联系方式、生活习惯(吸烟史、饮酒史、饮茶史、运动习惯、业余爱好、睡眠习惯)等。
1.2.2 认知功能评估部分 MMSE:包括定向力(10 分)、计算能力(5 分)、瞬时记忆(3 分)、延迟记忆(3 分)、命名(2 分)、语言流畅性(1 分)、阅读能力(1 分),表达能力(1 分),执行能力(3 分)、视空间能力(1分),总分30分。
MoCA:包括视空间功能(5 分),命名(3 分),注意力(6 分),重复句子(2 分),流畅性(1 分),抽象能力(2 分),延迟回忆(5 分),定向力(6 分),总分30分;若被试受教育年限≤12年则总分加1分。
1.3 统计学方法
2 结果
2.1 人口学特征
最终,共2 920例社区60岁及以上老人纳入研究,其中NE受试者2 367例,MCI受试者553例;男性1 319例,女性1 601 例;平均年龄(70.7±7.6)岁,平均受教育年限(8.7±5.2)年。分组分布情况见表1。
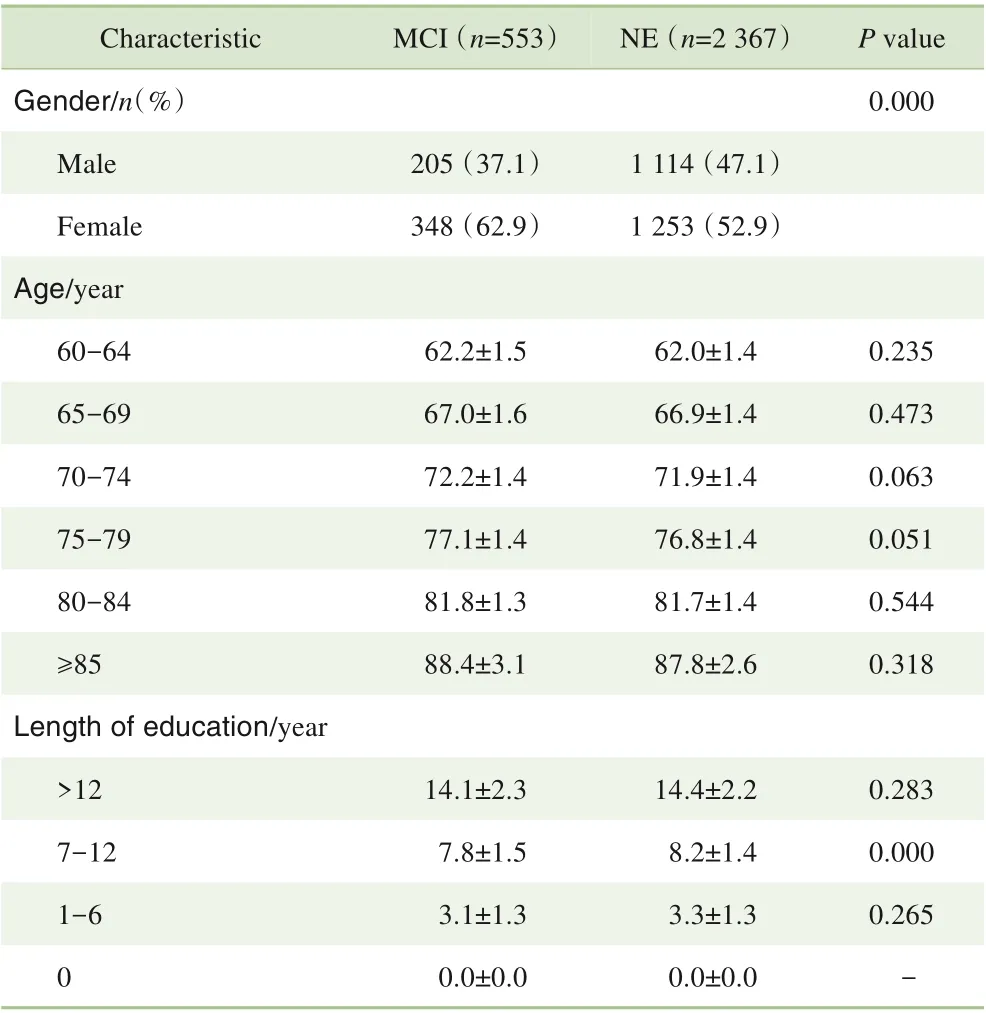
表1 受试者人口学特征Tab 1 Sociodemographic characteristics of the study sample
MCI 与NE 2 组间性别、年龄、受教育程度差异均具有统计学意义。女性患MCI 可能性更高(χ2=13.5,P=0.000)。MCI组平均年龄为(74.1±8.0)岁,NE组平均年龄为(69.8±7.2)岁,2 组间差异具有统计学意义(t=12.3,P=0.000)。MCI 组平均受教育年限为(6.1±5.1)年,NE 组平均受教育年限为(9.3±5.0)年,2 组间差异有统计学意义(t=-13.5,P=0.000)。而不同年龄组的平均年龄在2 组间差异无统计学意义(均P>0.05)。不同受教育年限组除7~12 年组以外,其余组的受教育年限在MCI与NE组间差异无统计学意义(均P>0.05)。
2.2 NE组MoCA总体评分情况
NE 组总体MoCA 评分为(22.7±5.1)分。根据受教育年限(0 年、1~6 年、7~12 年、>12 年)、年龄(60~64岁、65~69 岁、70~74 岁、75~79 岁、80~84 岁、≥85 岁)和性别(男、女)对NE 组进行划分后,各组MoCA 评估分值见表2所示。

表2 中国不同年龄、性别和受教育年限正常老人MoCA得分Tab 2 MoCA scores of normal elderly people of different ages,genders and years of education in China urban area
2.3 回归分析
在多变量模型中,性别、年龄和受教育年限与MoCA总分相关(R²=0.467)(表3)。
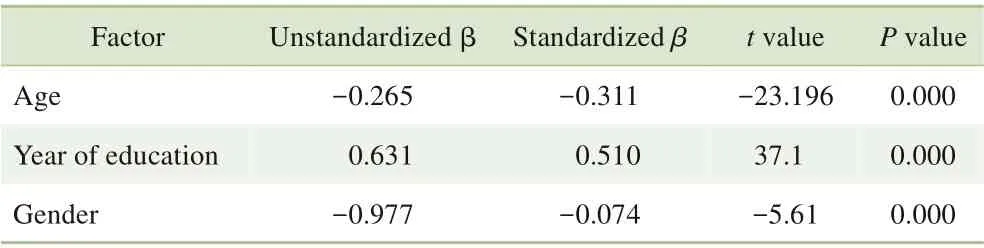
表3 多元回归模型中MoCA总分显著预测因子Tab 3 Significant predictors of MoCA score in the multivariate regression model
2.4 分量表得分
选取数据稳定性较好的≥60岁且<70岁年龄组按照受教育年限6年为分界对分量表得分进行分析,得到分量表得分数据如表4所示。

表4 不同受教育年限正常老人MoCA分量表分Tab 4 Sub-scale score of normal elderly of different years of education
不同受教育程度组被试在各个分量表认知域上皆存在显著差异。总体在定向力、注意力测试部分被试表现较好,视空间功能、延迟回忆、句子重复及抽象能力得分率较低。被试在延迟回忆等较难题目上得分标准差较大,说明即便在正常老人中测定亦存在较大差异性,不能以某一认知域的功能下降断定老人为MCI。
2.5 信度和效度
本研究中MoCA 的Cronbach´α系数为0.933。总分与MMSE的相关系数为0.825。采用主成分分析法进行探索性因子分析对量表的结构效度进行评价,结果显示,提取了5个公因子,总解释能力>65%。旋转成分矩阵显示公因子1包括注意力、重复句子、流畅性、抽象能力,公因子2为定向力,公因子3为视空间结构功能,公因子4为延迟回忆,公因子5为命名,各维度划分比较合理。以上结果表明MoCA具有良好的信度和效度,适合用于认知功能评估。
2.6 难度分析
MoCA中难度系数<0.4的问题(40%以下的被试回答正确)包括命名中的犀牛、单峰骆驼,延迟记忆中的教堂、面孔,视觉空间功能和钟表画实验中的指针位置。其中,视空间功能和延迟记忆是MCI 的主要认知功能受损区域,辨别力较强。命名部分犀牛的难度系数最低,只有37%的被试回答正确。延迟回忆部分题目包括一些不符合中国文化背景的词汇,包括天鹅绒和教堂。同时,一些题目的表达也比较书面化,例如面孔,临床应用中常有被试者回答为“脸”造成失分。在重复句子部分由于汉语表达方式的多样性,在翻译相同的短句后,有许多词语表达相似的含义。在临床实践中,受试者往往出现添加虚词来表达相同的意思最终造成失分。视空间功能部分难点在于交替连线题目中“甲乙丙丁戊”的使用,受教育程度较低的受试者对该表达不熟悉可造成失分。
各分测验区分度如表5所示。视空间功能、命名、延迟回忆、注意力4 个分测验区分度均高于0.4,证明题目设置区分度良好;定向力与流畅性分测验区分度低于0.2,证明此2 项分测验区分度较低,参与测验的社区老人表现相对良好。

表5 不同分测验区分度Tab 5 Degree of differentiation in subscales
2.7 分界值分析
本研究中,采用受试者操作特征曲线(receiver operator characteristic curve,ROC 曲线)分析(图1)计算约登指数最高的整体最佳分界值为20 分(敏感度63.7%,特异度75.7%),曲线下面积为0.76。低年龄(≥60 岁且<70 岁)+高文化程度(>12 年)组的最佳临界值为25(敏感度70.5%,特异度63.5%),而其他组最佳分界值波动于15~25 分之间。忽略年龄差异,较高学历组(>6 年)推荐分界值为23 分,较低学历组(≤6 年)为16分。
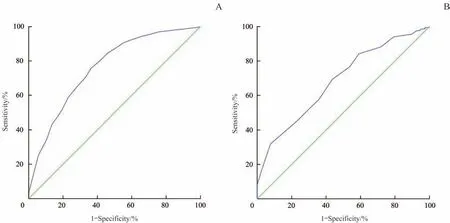
图1 整体ROC曲线(A)及低年龄高文化程度组ROC曲线(B)Fig 1 ROC curve of total(A)and ROC curve of low age and high education level group(B)
3 讨论
既往多项研究中MoCA 的Cronbach's α 系数均高于0.75,说明量表内部一致性信度良好[14-16]。同时,MoCA在重测信度与调查员信度方面均高于0.85[14,16]。在以MMSE 为检验校标时两者相关性高[14,17-18],效度良好。本研究结果仍旧证实了MoCA 量表(北京版)具有良好的信度和效度。
除了证实了MoCA 量表信效度的可靠性外,我们的研究结果也与之前多项研究一致,性别、年龄和受教育程度与MoCA 评分相关。本研究中,在受教育年限超过12 年的高学历组中,女性的MoCA 得分与男性差异无统计学意义,甚至在≥65 岁且<70 岁年龄组中女性表现更好,因此提高女性教育水平可能有助于辅助改善人群整体认知功能。在既往研究中,65 岁以上老年人的年龄每增加5岁,阿尔茨海默病的发病率即出现显著上升。因此我们将2 920 例受试者按年龄分为6 组,每5 年一组,发现MoCA 总分随年龄增长而下降。差距在10 年以上的各年龄组与其他年龄组MoCA 总分差距均有统计学意义。受教育程度是认知评估的重要影响因素,在MoCA 测评过程中,当受教育年限低于12 年时,分数应加1 分得到最终分数。本研究中,老年人的平均受教育年限为8.7 年,NE 组平均受教育年限为9.3 年,MCI 组平均受教育年限为6.1 年;以6 年为分界线将案例分为高受教育程度组(>6 年)和低受教育程度组(≤6 年),2 组得分之间差异具有统计学意义。
难度分析发现,延迟回忆的难点在于词频的差异。通过Google Books Ngram 进行词频检索,中文词汇词频来自2019 年简体中文数据库,英文词汇词频来自2019 年英文数据库。高频词汇“教堂”(英文为church),在英语国家的词频为0.009 07%,而汉语为0.000 99%(教堂)。“daisy”菊花在英语世界的词频为0.000 7%,而在汉语中为0.000 84%。“velvet”(天鹅绒) 在英语中的词频为0.000 55%,在汉语中的词频为0.000 02%;“面孔”中文词频为0.000 316%,英文为0.034%。由于词频的巨大差异,高频词汇教堂(church)和面孔(face)应在新版本中进行修改。同时因原版MoCA 中“velvet”设计为低频词汇用以提高测试难度,中文“天鹅绒”则无需进行修改。通过词频检测,可考虑将“面孔”替换为“手”(词频0.008%),“教堂”替换为“工厂”(词频0.006%)。在命名部分,MoCA 量表测试3种不常见动物的命名。犀牛的词频为0.000 048%,是其中最难的题目。而在初始设计中为检测命名困难,题目难度较高,因此命名部分的题目无需修订。
本研究涉及北京、上海、宁波、沈阳、合肥、杭州、吉安、南昌、西安、广州10 个城市,推荐分界值为20 分(敏感度63.7%,特异度75.7%),该结果相对于原版量表敏感度及特异度均较低。在以往研究中,不同的国家使用各自语言的MoCA 版本分界值推荐各不相同。例如,韩国版MoCA[19]最佳分界值为23, 而土耳其版MoCA[20]最佳分界值为21。在汉语言文化人口中有多个经过验证成型的MoCA 版本,包括我国北京、广东、长沙、香港和新加坡,为区分MCI和NE人群研究建议的分界值范围为13~26 分[21]。新加坡推荐以受教育程度10 年为界纳入区分标准[22],本研究同样发现受教育程度以6 年为界时高低2 组得分具有显著差异,在较低学历组中得分个体差异较大。因此可将受教育年限6年及以下纳入区分标准,同时保留受教育年限12年及以下加分的策略。在我国香港的一项研究[23]中,315 名粤语母语参与者的MoCA 测评结果显示敏感度为0.861,特异度为0.723。一项由1 552名捷克老年人参与的研究[24]中,MoCA-CZ 量表常模经计算推荐分界值为≤25,显示出94%的敏感度,而特异度较低为62%。在瑞典的一项研究[25]中,由于年龄和受教育程度的不同,700余名认知正常的老年人平均得分为16~24 分。因此,在不同的文化背景下老年人MoCA 测评结果不尽相同,这与量表本身题目设置与文化背景的贴合性相关。本土化后MoCA 测试结果较接近原版的是日本版本,当根据单词频率将延迟回忆部分单词转换为符合日本文化习惯的日语单词时,MoCA-J 在MCI筛查中的敏感度为93.0%,特异度为87.0%[26]。本研究样本量较大,平均MoCA 得分减1 个标准差对应于第16 个百分位,平均MoCA 得分减1.5 个标准差对应第7 百分位;平均MoCA 得分减2 个标准差对应第2 百分位。有其他MoCA 相关研究[20]认为,平均MoCA 得分减1 个标准差是较合适的下限标准;对于其他许多神经心理学测试,如韦氏智力量表,依据人口学资料进行分组后正常人群的平均数减1.5 个标准差被定为异常标准。但在以往的MoCA 相关研究中,同样有研究[27]表明调整后的标准并不合适,以平均值减1.5 个标准差或平均值减1 个标准差为异常标准,会显著降低灵敏度造成筛查效率下降。本研究结果显示ROC 曲线计算所得分界值明显高于平均值减1 个标准差,因此不采用平均值减1 个标准差进行判断。本研究存在一定的局限性,本研究未进行重测信度及调查员信度检验,但后期随访已经开始,后续将观察参与本项目受试者的转归,同时将对词频修订后版本的信度和效度进行进一步研究。
综上所述,通过神经心理量表进行MCI 筛查更易大范围推行,是目前一项经济易行的认知障碍筛查手段。MoCA 量表测试时间短,灵敏度高,适于进行MCI 的筛查。本研究调查中国城市地区老人的认知水平,通过MoCA 量表进行量化,建立可用于未来对比研究的队列。老年人整体认知水平随受教育程度的提高而显著提高。老年人总体中MoCA 测试的最佳分界值为20(敏感度63.7%,特异度75.7%)。基于量表分项的难度分析,我们将把MoCA 延迟记忆部分词语的“面孔”和“教堂”进行替换,以评估其是否能够达到更好的MCI筛查效力。
