面向不平衡数据集的汽车零部件质量预测
2022-01-24李敏波董伟伟
李敏波 董伟伟
1.复旦大学软件学院, 上海,2004332.复旦大学上海市数据科学重点实验室, 上海,200433
0 引言
随着“工业互联网”和“工业4.0”等概念的提出,工业领域的信息化、智能化发展愈发受重视,越来越多的制造企业建立了生产过程数据采集系统与制造执行系统,积累了大量工业数据。这些工业数据分布在不同的孤立信息系统中,存在实时性高、复杂多样和类别不平衡等问题。现有的产品质量预测方法往往使用单一系统的数据集,且只面向于特定的制造领域,具有较大的局限性,难以满足制造企业实时质量抽检的预测需求。常见的产品质量预测研究往往局限于质量预警和预测性维护等方面,这些研究难以用于实际的工业场景[1-3]。汽车零部件制造存在大批量生产、小样本抽样检测的特点,例如轮胎动平衡为全检,而部分轮胎企业的均匀性检测为抽检,柴油和汽油发动机的部分试车工况测试为抽检。大批量生产的汽车零部件合格率一般在95%以上,而小样本抽检的随机性会造成不合格产品检出率较低,增加产品售后返修及物流成本。
制造数据集中,合格与不合格的产品数量差距悬殊,存在严重的类别不平衡问题。现有的类别不平衡解决方法分为预处理方法、代价敏感方法、算法中心方法和混合方法[4-6],其中,预处理方法包括特征选择方法、过采样方法、欠采样方法和混合采样方法。一般来说,过采样方法具有更高的性能,文献[7-10]分别利用Lowner John椭球理论、元启发式方法、构造覆盖算法的无参数数据清洗方法和自组织图方法对少数类样本进行过采样,极大提高了对多领域不平衡数据集的分类性能。然而在面对信息繁杂且蕴含众多领域业务特征的制造数据集时,现有方法仍有进一步的改善空间,由此本文提出了基于密度聚类与多工序制造特征的质检数据过采样方法。
对制造数据不同层次的类别属性预测包括故障预测和产品质量预测。产品质量预测在本质上是一个二分类问题,即将生产制造数据集训练出的有效分类模型用于产品的良率预测与抽检产品的选择。文献[1-3]利用支持向量机(SVM)、随机森林、决策树和深度学习等方法,对车辆气压系统和机床进行故障检测及预测的研究。朱海平等[11]应用遗传算法改良 EWMA控制图,量化产品质量不合格的概率并优化相关参数。吕旭泽[12]针对发动机多工序装配的回转力矩检测误差波动大、影响装配质量的问题,构建了基于粒子群参数优化与最小二乘支持向量机的发动机多工序装配预测曲轴回转力矩模型。赵双凤[13]提出了结合BP 神经网络和灰色模型的质量预测模型来预测轴类零件车削加工测量值。于文靖[14]研究了汽轮机模锻叶片加工质量预测,建立了基于粒子群优化(PSO)算法与SVM算法并结合统计过程控制(SPC)的多工序质量预测控制系统。冯尔磊[15]针对表面安装工艺中锡膏印刷环节,提出一种基于层次聚类和PSO优化的 RBF神经网络的锡膏印刷体积预测模型。本文提出了将LightGBM、XGBoost、SVM和MNB模型进行Stacking集成的汽车关重件质量抽检预测方法。
1 MCDC-MF-SMOTE过采样方法
大数据下的质量预测控制研究主要集中于质量管控过程框架、数据挖掘方法、在线质量诊断与监控、在线质量预测等领域[16]。常用质量预测方法主要有灰色预测模型、人工神经网络预测模型、支持向量回归(support vector regression, SVR)预测模型、模糊预测控制模型以及上述算法的整合模型。针对产品质量预测及其关键的类别不平衡问题,本文研究基于密度聚类与制造业务特征(multi class density cluster-manufacture feature-synthetic minority over-sampling technique,MCDC-MF-SMOTE) 的过采样方法。
SMOTE(synthetic minority over-sampling technique)-Regular算法采用K最近邻 (K-nearest neighbor,KNN)分类算法模拟生成新样本来解决数据集分类的类别不平衡问题,但面对高维且分布复杂的数据集时,该算法的分类模型准确率不高,因此出现了SMOTE-borderline、k-means-SMOTE、Random-SMOTE和CURE-SMOTE等改良方法,这些方法考虑了不同类别的数据分布情况和少数类噪声问题,利用分布边界、聚类和生成权重调整等方法解决了SMOTE-Regular的诸多问题[17]。制造数据集不仅具有高维且复杂的分布特征,不同类别的样本数据还有重叠,直接使用上述SMOTE改进方法,难以有效学习到数据中所有质量影响因素的信息,使得产品质量预测模型难以用到实际的生产场景。
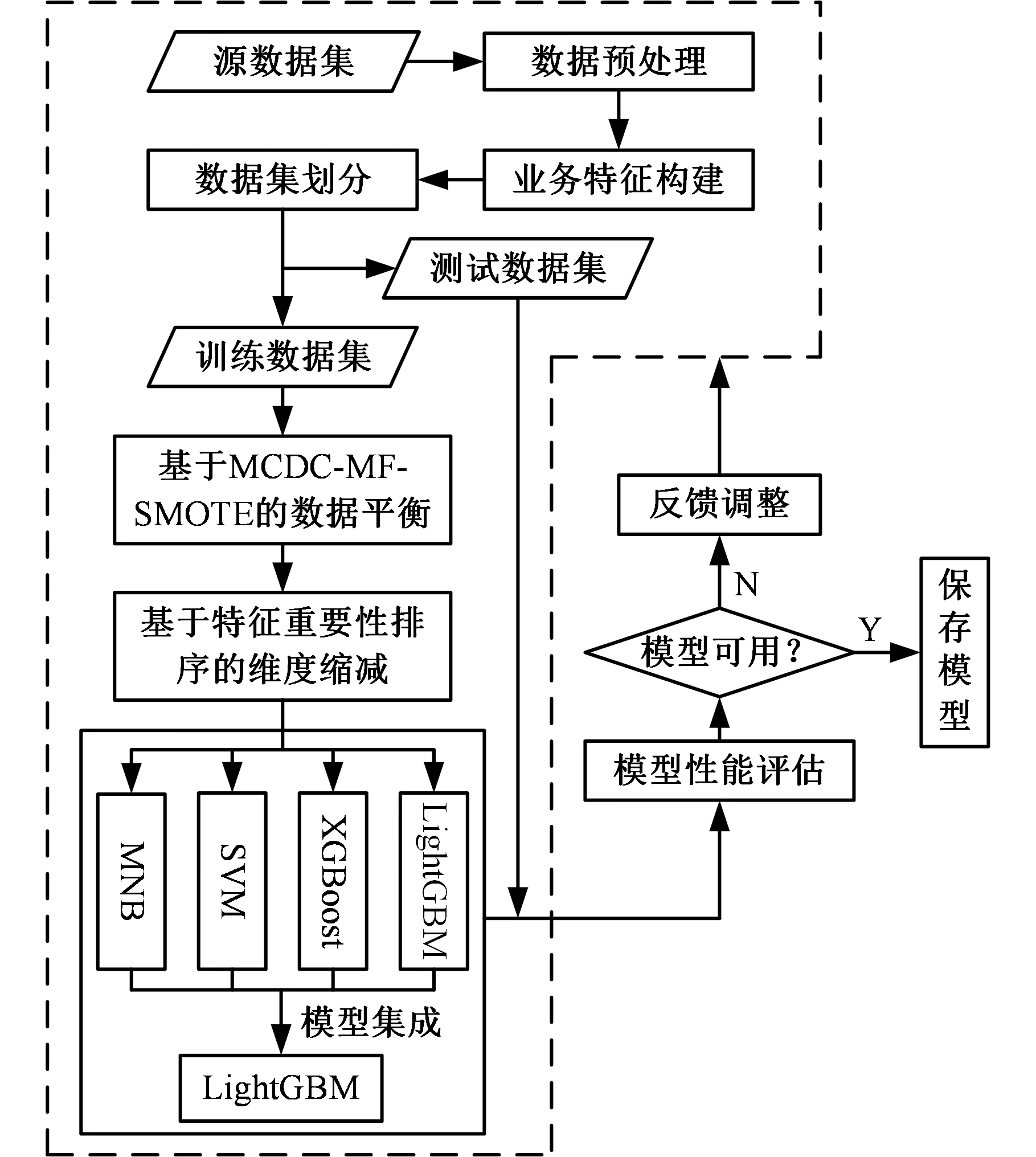
图1所示为基于密度聚类和制造业务特征的数据过采样方法框架。首先对制造数据集进行适当的预处理(包括缺失值处理、错误数据修正、数据标准化等操作),形成高质量且适合模型训练的数据集。笔者将数据集按产品质量类别标签分成两个数据集:一个包含所有不合格产品(少数类)样本,另一个包含所有合格产品(多数类)样本。接着对这两个数据集进行密度聚类,形成对应的类簇集合。利用多工序制造特征计算少数类簇的数据生成权重,然后利用数据生成权重对少数类簇进行数据生成,并对利用多数类簇判断生成的数据是否合理。最终按照分类模型需要重组数据,形成平衡后的数据集。
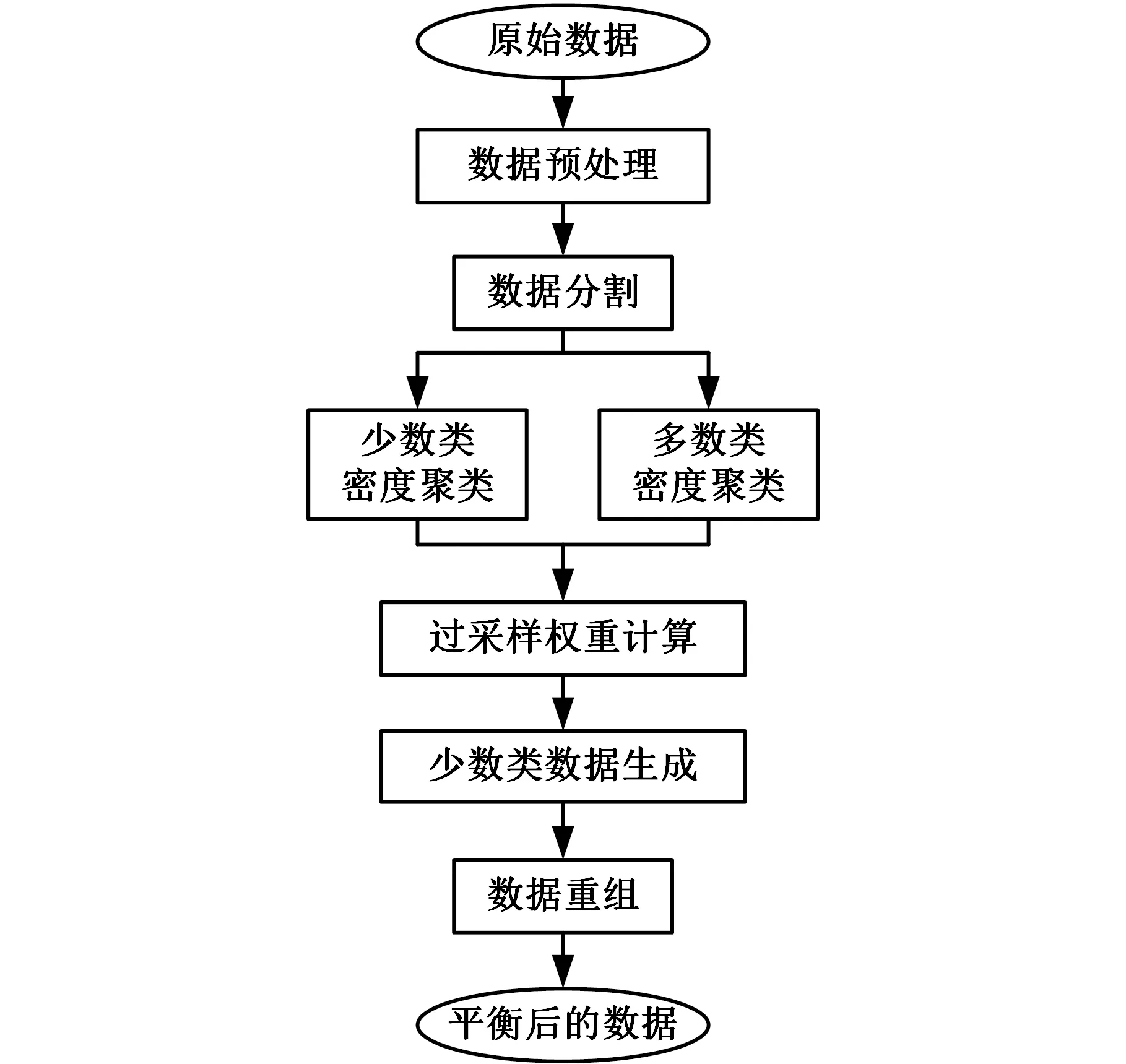
图1 MCDC-MF-SMOTE过采样方法架构Fig.1 Architecture of MCDC-MF-SMOTEoversampling method
1.1 密度聚类方法分析与选择
密度聚类方法可以根据数据的分布密集程度考察数据间的相似性,相比于k-means等方法,不需要指定类簇数量就能发现任意形状的类簇,且对噪声数据有更高的鲁棒性。
为分析不同聚类方法的适应性,利用scikit-learn软件的datasets工具包合成6种不同分布的数据集。选择6种基于不同理论的聚类方法对合成的数据集进行聚类实验,图2中,从左向右依次为K-means、Agglomerative Clustering、Birch、MeanShift、DBSCAN、OPTICS 6种聚类方法对合成的数据集进行聚类实验的结果,可以看出,k-means、Birch和MeanShift算法会拆分密度分布相同的类簇,如第六行的数据集6,2个弧形分布数据被错误地截断为不同类簇(第六行的第1、3、4列)。Agglomerative Clustering算法易将数据集4、5中不同的类簇识别为同一类簇。OPTICS算法会将一些密度分布松散的类簇识别为噪声,且多次参数调整后的效果仍不理想。DBSCAN算法在每一种数据集下都有最好的分类表现,能有效区分不同形状的类簇,且会引入更少的噪声数据。所以最终选择DBSCAN算法对制造质量相关数据集进行聚类,并在不同类簇中生成少数类数据。
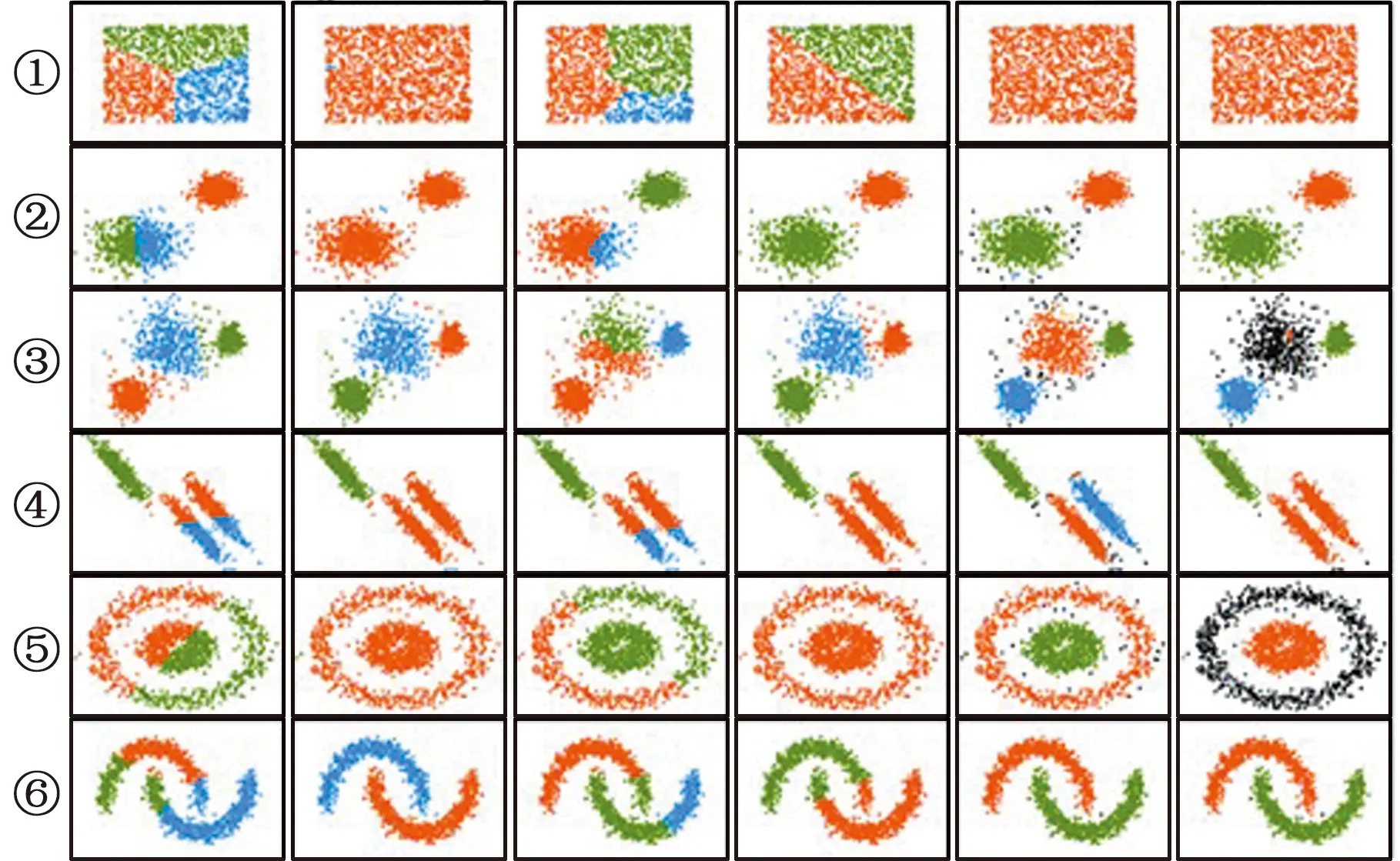
图2 聚类实验结果Fig.2 Experimental results of clustering
1.2 基于多工序制造特征的过采样权重定义
产品制造数据集包含人员、设备、物料和操作等影响产品质量的制造特征,这些特征在一段时间内通常会保持相似的状态。产品质量问题往往是由某一工序环节的制造偏差造成的,整体来看,不合格产品会在某一时间段内重复出现。图3为轮胎动平衡检验的产品质量趋势图,横坐标为动平衡检验时刻,纵坐标表示产品质量,1表示合格产品,0表示不合格产品。红框标注了聚集出现较多不合格品的情况,可利用滑动窗口的方法判断一定时间内生产的不合格产品数量是否超过阈值。若超过阈值,则滑动窗口内的数据包含更多的低质量产品的信息,应该受到更多的关注,过采样时,可将此类数据赋予更大的过采样权重。
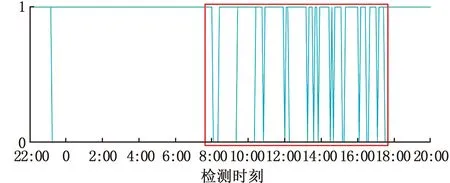
图3 轮胎动平衡质量趋势Fig.3 Quality trend of tire dynamic balance
利用上述分析的制造数据集特征和数据的密度分布情况,设计对少数类簇进行数据生成时的过采样权重。首先定义样本D={(x1,y1), (x2,y2), …, (xn,yn)},其中,n为样本数量,xi表示样本i,yi∈{0,1},其中,1表示质量合格,0表示不合格。定义滑动窗口Ls-e为固定时间长度,s、e分别为滑动窗口的开始时间与结束时间;minA为低质量产品的最小出现次数,N0(Ls-e)为滑动窗口内出现的低质量产品数量;deplen为滑动窗口移动步长。N0(Ls-e)>minA时,窗口为有效滑动窗口,属于某个有效滑动窗口的样本称为有效滑动样本;按照指定步长移动滑动窗口,最终得出有效滑动窗口集合T={Ls,1-e,1,Ls,2-e,2,…,Ls,l-e,l}。由于样本具有时间属性,因此可以判断出每个样本是否归为有效滑动样本。
接着利用基于混合类型距离的DBSCAN算法对原始样本进行密度聚类,形成少数类簇Ca={ca,1,ca,2,…,ca,v}和多数类簇Cb={cb,1,cb,2,…,cb,w},其中,v、w分别为少数类簇和多数类簇的数量。N(ca,v)为ca,v类簇的样本数量,D(ca,v)为ca,v类簇空间所包含的多数类样本数量,S(ca,v)为ca,v类簇含有的有效滑动样本的数量。类簇包含的有效滑动样本越多,该类簇的数据权重越大。最终定义的类簇过采样权重为
(1)
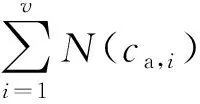
(2)
1.3 过采样算法流程
基于密度聚类和过采样权重定义方法,介绍基于MCDC-MF-SMOTE的整体流程。定义Doriginal为原始样本;过采样率ηOR为数据生成后的少数类样本数量与原始多数类样本数量的比值;J为生成数据无效时所进行的重试次数,防止出现死循环;WDMC表示不同类簇的过采样权重计算过程算法;Dbalanced为经过该算法处理后的样本。使用基于混合类型距离Dmix的密度聚类算法DBSCANDmix对原始样本进行密度聚类,具体算法如下:
输入:数据集Doriginal←{(x1,y1),(x2,y2),…,(xn,yn)},yi={0,1};
DBSCANDmix; 密度聚类算法参数:半径∈,最小数量MinPts;
输出:Dbalanced←{(x1,y1),(x2,y2),…,(xz,yz)},yz={0,1}.
方法:
1./* (1).初始数据集预处理*/
2.Dprocessed←P(Doriginal);
3./* (2).类分割与每个少数类簇的权重定义 */
4.初始化GenWht←∅,Dmin←∅,Dmaj←∅,
Gq←0,i←0,Ca←∅,Cb←∅,Dnoise←∅;
GenWht,Dmin,Dmaj,Ca,Cb←WDMC(Dprocessed,ε
minPts,deplen,Ls-e,minA,β1,β2,β3);
5.Dnoise←Dprocessed(Dmin,Dmaj);
/* (3).根据少数类簇的权重值生成数据,通过多数类簇去除无效数据*/
6.initializeGq←0,Wall←0,Gc←∅.
9.fori←1∶vdo
11.endfor
12.whileGq>0do
13.i←i+1,i←i%v;
14.ifGc,i>0do
15.randomly select (xold,0,xold,1)∈Ca,i;
16.initializej←0;
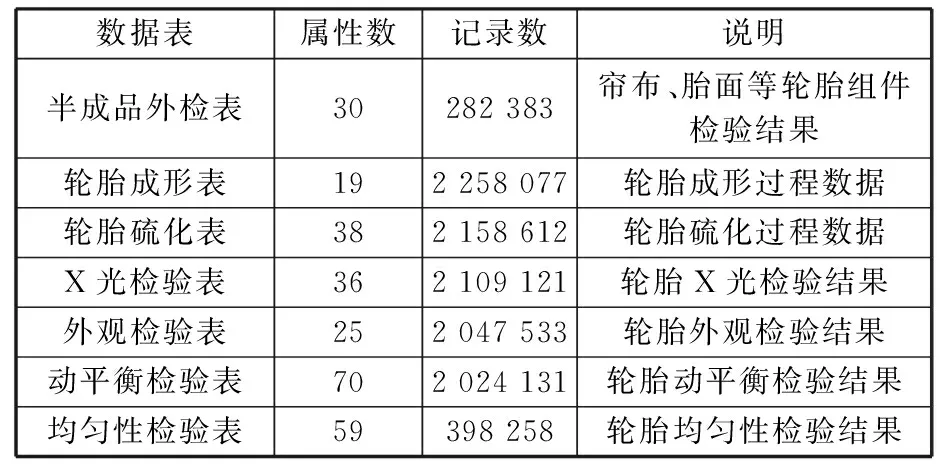
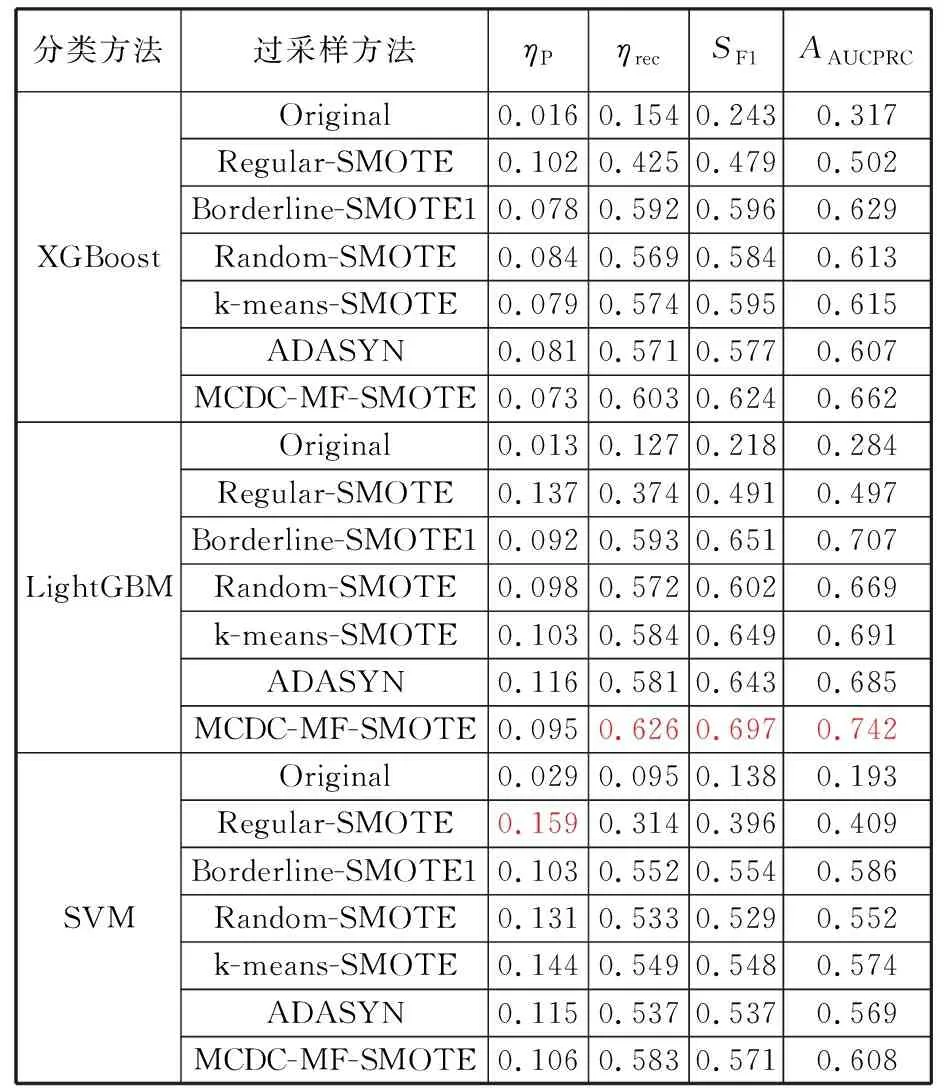
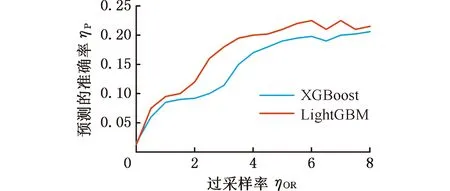
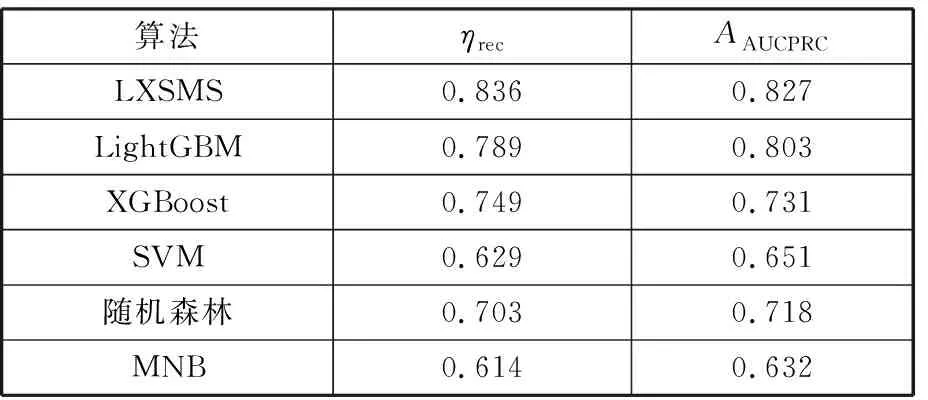
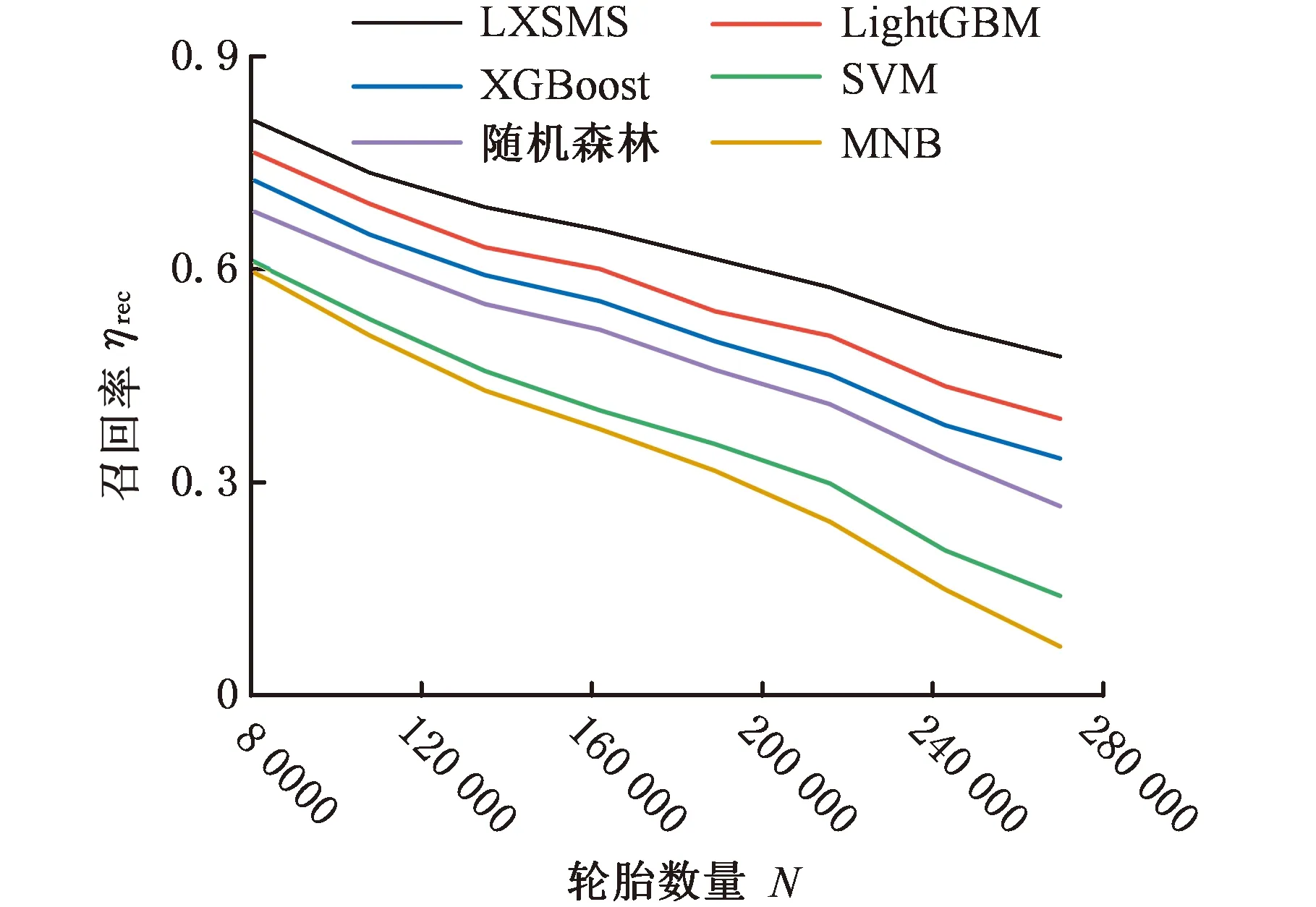
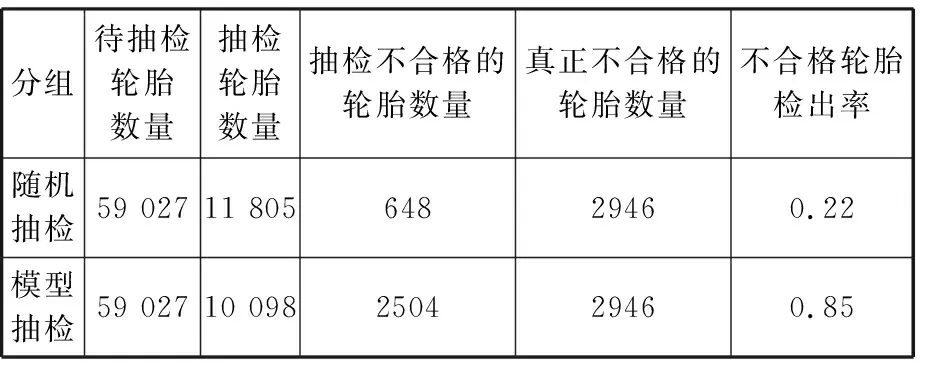
17.whilej 18.j←j+1,xnew←xold,0+Udynamic(0,1)·(xold,1-xold,0); 19./* judge data valid byCb.*/ 20.ifxnewis validthen 21.Gq←Gq-1, 22.Dmin _balanced←Dmin _balanced∪xnew; 23.break; 24.endif 25.endwhile 26.endif 27.endwhile /* (4).数据集重构 */ 28.initializeDbalanced←∅; 29.Dbalanced←Dmaj∪Dmin _balanced∪Dnoise; 重点为步骤(3),即根据少数类簇权重生成数据,根据多数类簇判断生成数据的有效性。数据无效时,重新生成数据并判断其有效性。 图4所示为不同的少数类簇与多数类簇的分布,用min标识的红色区域表示少数类簇,用maj标识的绿色区域表示多数类簇,横纵坐标都为数据的x、y值坐标,它们共有3种分布方式:非重叠分布、包围分布、重叠分布。对于非重叠分布,从少数类簇区域中随机选择2个样本点,取两点连接线之间随机一点为新生成数据。对于包围分布,当生成数据落在多数类族区域时,重新选择2个样本点,并用迭代折半的方法在距离样本点更近的位置生成数据。对于重叠分布,首先将重叠区域设置为invalid area,然后判断独立少数类簇区域是非重叠分布还是包围分布,并按照响应方法进行数据生成。 (a)非重叠分布 (b)包围分布 MCDC-MF-SMOTE方法能产生有效的平衡数据集,提高多个分类算法的泛化性能,并使LightGBM(light gradient boosting machine)模型获得最好的产品质量预测结果。考虑到汽车零部件生产过程和相关制造数据集的复杂性,单一分类算法难以适应各种的制造场景。例如Expo和Higgs数据集上的二分类问题,极限梯度提升(extreme gradient boosting,XGBoost)模型的分类性能强于LightGBM模型。本文提出基于Stacking集成的LXSMS(LightGBM- XGBoost-SVM-MNB Stacking)方法,如图5所示,具体步骤如下: 图5 LXSMS方法整体流程Fig.5 Overall flow of LXSMS method (1)数据预处理。该步骤初步梳理制造数据集,需要考虑数据的类型,如数值型、时间型和文本型的属性以及属性背后的实际质量相关性。 (2)多工序制造特征构建。经过对制造数据集的预处理和对多工序制造质量相关影响因素的了解,利用多个已有特征构建新的组合特征,这些组合特征往往在最终模型中起决定作用。 (3)数据集划分。为保证训练出的模型符合真实的产品质量预测场景,需在数据平衡及降维之前进行数据集划分。首先按照业务发生时间对数据进行先后排序,之后将前80%的数据作为训练数据集,将余下的数据作为测试数据集。 (4)MCDC-MF-SMOTE算法的数据平衡。制造数据集存在类别不平衡问题,严重影响分类方法的性能,MCDC-MF-SMOTE算法充分考虑了数据分布和制造业务特征,能生成高质量的平衡数据集,有效解决该问题。 (5)基于特征重要性的维度缩减。数据集特征过多时,部分特征往往是质量影响度很小的冗余特征,且模型需要耗费更长的时间去训练和调整参数,因此使用随机森林对所有特征进行重要性排序并剔除部分排名靠后的特征。该方法能在保证特征蕴含足够知识的前提下,缩短模型训练时间,提高模型分类性能。 (6)Stacking集成。第一层基分类器主要采用分类模型LightGBM、XGBoost、SVM(支持向量机)和MNB(多项式先验分布朴素贝叶斯),每个模型都采用五折交叉验证的方法训练并输出预测结果到第二层元分类器层。需要注意的是,五折交叉采样需采用分层抽样的方式,以保证不同模型使用同样分布的数据。LightGBM模型训练极快且比逻辑回归模型的分类性能高,所以选择LightGBM模型作为元分类器,利用第一层得到的预测数据进行训练并得出最终的产品质量预测结果。 (7)模型评估与参数调整。评估模型需综合考虑模型的训练时间和受试者工作特征曲线 (receiver operating characteristic curve,ROC)、ROC曲线下的面积(area under curve, AUC)等指标,并利用网格搜索方法调整参数。模型达到要求时,保存模型为PMML(预测模型标记语言)格式,并将其应用到实际生产业务。 本文实验数据源于青岛双星股份公司MES数据库,轮胎生产均匀性检验阶段采取的是20%随机抽检的方式。利用均匀性检验之前的所有数据训练模型来预测均匀性检验阶段的产品质量,辅助进行均匀性抽检工作,降低不合格轮胎的漏检率。表1所示为相关数据的说明。经过数据预处理,最终使用2019年1月到4月的269 835条轮胎生产制造数据,其中,合格轮胎254 370条、不合格轮胎15 465条,合格率为94.27%,不平衡比为15.4。 表1 轮胎制造数据说明 准确率(Precision)和召回率(Recall)仅关注单一维度的模型性能,难以综合评估不平衡数据下的模型对不同类别的泛化能力。AUC、ROC等指标有一定偏向性,使用准确召回率曲线面积(precision-recall curve,AUCPRC)能在一定程度上修正AUC、ROC的偏向性,它是以准确率ηp为Y轴、召回率ηrec为X轴所形成的曲线下的面积。针对批量生产的汽车零部件工序抽样检验的质量预测希望预测更多的不合格产品,召回率ηrec允许值更小,针对此类场景,选择AUCPRC来综合评价产品质量预测模型更有意义。同时结合抽检比例的业务特征,最终选择预测为合格样本数量与总样本数量的准确率ηP、召回率ηrec、综合评价指标F1-Score(SF1)和AAUCPRC作为模型的评价指标。 本次实验主要使用算法XGBoost、LightGBM和SVM(支持向量机),其中,GBoost和LightGBM均以binary:logistic为目标函数(objective),已定义评价函数(eval_metric)为AUCPRC,提升类型(booster_type)为梯度提升树(gradient boosting decision tree,GBDT)算法,学习率(learning_rate)、树深(max_depth)和树的个数(n_estimators)参数采用网格搜索选取最优值,其他参数取默认值。SVM使用sklearn.svm.SVC方法,kernel设置为rfb,class_weight设置为balanced,利用网格搜索调整惩罚系数C,其他参数均取默认值。过采样方法中,Original表示不进行过采样,其他过采样方法均使用python算法库对原始数据进行处理,MCDC-MF-SMOTE算法设置ε=10,minPts=3,ηOR=1,β1=β2=β3=1,jump=3,Ls-e=600,minA=3,deplen=10。最终的实验结果取五折交叉验证的平均值。结果如表2所示,可以看出, MCDC-MF-SMOTE方法取得最大的SF1、ηrec和AAUCPRC且ηP均小于0.2,符合轮胎均匀性检测按20%比例随机抽检的业务要求。相比除了Original的其他过采样方法,MCDC-MF-SMOTE的AAUCPRC增大了5%~49%。此外,LightGBM配合MCDC-MF-SMOTE过采样方法取得了最大的ηrec、SF1和AAUCPRC值。 表2 不同过采样方法实验结果 用过采样方法处理不平衡数据集时,过采样率ηOR设为1表示少数类样本采样数量与多数类样本数量相同。不同的过采样率会影响分类模型的最终性能,应用轮胎制造数据集探讨MCDC-MF-SMOTE方法的不同过采样率对分类性能的影响。LightGBM和XGBoost使用默认参数设置,MCDC-MF-SMOTE仅更改ηOR的参数设置,采用五折交叉验证,最终结果取平均值。 实验结果如图6所示,横轴表示过采样率ηOR,ηOR=0表示不进行过采样。纵轴分别表示ηP、ηrec和AAUCPRC的性能指标值。可以看出,ηOR较小时,XGBoost有更好的性能。随着ηOR的增大,XGBoost和LightGBM整体性能都在提升,但LightGBM整体性能的提升速度更高。XGBoost在ηOR超过4.5、LightGBM在ηOR超过3后,ηrec和AAUCPRC都趋于稳定,且满足ηP小于0.2。特别是LightGBM的AUCPRC指标已经到达了0.803, 比ηOR=1时的性能提升了约8%。随着ηOR的进一步增大,XGBoost和LightGBM的性能趋于稳定,但是ηP却在逐步增大,超过了0.2的抽检阈值,不满足辅助质量抽检的业务需要。整体来看,LightGBM有着更好的性能,且模型训练耗时约为XGBoost的1/10。 (a)准确率 本实验主要对比算法LXSMS、LightGBM、XGBoost、SVM、随机森林和MNB。选取轮胎制造数据集的80%数据为训练数据,余下20%数据作为测试数据。每个算法都采取MCDC-MF-SMOTE方法平衡数据,并设置ηOR为其最优性能时的过采样率,设置ε=10,minPts=3,ηOR=1,β1=β2=β3=1,jump=3,Ls-e=600,minA=3,deplen=10。 LXSMS在集成模型的第一层中使用了五折交叉验证,所以除了LXSMS,其他方法的最终实验结果取五折交叉验证的平均值。 由表3的实验结果可以看出,相比单一模型中表现最好的LightGBM,LXSMS的ηrec和AAUCPRC分别提高了约6%和3%;相比表现最差的MNB,LXSMS的ηrec和AAUCPRC分别提高了约36%和31%。这表明基于Stacking集成的LSXMS方法有着更高的产品质量预测性能。 表3 不同分类算法的产品质量预测性能 产品制造是一个持续的过程,会源源不断产生新的数据,随着时间的推移,产品质量预测模型的预测能力往往会持续下降。为了分析不同模型的稳定性即模型对新数据的预测能力,本次实验将269 835条轮胎制造数据按照时间进行排序,取前30%的数据为训练数据,后70%的数据为测试数据,测试算法LXSMS、LightGBM、XGBoost、SVM、随机森林和MNB的稳定性。 由图7可以看出,在每一种数据划分下,LSXMS的ηrec都最大且下降缓慢,有较高的稳定性。随着轮胎数量的增长,模型的预测性能持续降低,不适应产品抽检的业务要求,所以需要在适当时刻,采取增量更新的方式训练新的模型。 图7 不同分类方法产品质量预测稳定性Fig.7 Stability of product quality prediction bydifferent classification methods 为进一步验证LXSMS方法在真实产品制造场景中的适应性,将已标记检验质量的269 835条轮胎生产数据,按照时间节点划分,将2019年3月之前的210 808条数据作为模型训练数据,将2019年4月的59 027条数据作为轮胎检验数据。对于轮胎检验数据,设置随机抽检和模型抽检对照实验,并分别进行两种检验处理:随机抽检从轮胎检验数据中重复10次随机取出20%的轮胎并标记为抽检轮胎,结果取平均值(轮胎数量如果为小数则四舍五入为整数);模型抽检使用LXSMS方法从训练数据中构建出初始质量预测模型,并利用该模型模拟实时预测过程,将预测不合格的轮胎标记为抽检轮胎。最后使用已知的轮胎质量结果来判断两种抽检方式的性能,如表4所示。 表4 随机抽检与模型抽检的性能 从实验结果可以看出,模型抽检在抽检了17.1%的轮胎后,达到了85%的不合格轮胎检出率,而随机抽检只检出22%的不合格轮胎。由此可见,本文提出的LXSMS方法能显著提高不合格轮胎检出率,在更低检验成本的情况下,检测出更多的不合格轮胎,帮助企业提升经济效益。 深度学习常用于图像、音频和文本等领域。对于汽车零部件质量抽检预测及其相关的多工序制造数据集来说,由于质量不合格品的负小样本数据较少,因此深度学习难以取得良好的应用效果。 从数据量来说,制造数据集中的有效数据往往是较小规模的样本,相比动辄过千万的图像与文本数据,深度学习算法难以训练出高泛化能力的模型。基于集成方法的LSXMS能从小样本数据集中充分学习到数据特征,且支持加入业务规则进行精细化调整,更加适合中小规模数据集的制造数据分析。 从效率来说,深度学习需要耗费更多的计算成本和更长的训练时间,且往往需要高性能GPU的支持,而LSXMS使用CPU即可进行训练。模型训练需要能在普通配置的服务器中进行,更符合企业应用要求。 从业务来说,训练出的质量预测模型不仅要适应复杂多变的产品质量场景,还能对多工序制造特征进行分析,为产品工艺参数优化提供优化方向。LXSMS模型能够提取出小样本特征的重要性,重要性高的特征蕴含着更高的业务影响能力;模型支持反馈训练及调整,能满足企业质量预测的需要。 综上所述,对于有限规模的制造数据集来说,采用何种模型需要结合业务目标来定,并综合考虑数据量、数据特征、训练成本和应用场景等问题。 基于双星轮胎制造业务背景,设计了图8所示的服务框架,将LXSMS产品质量预测方法应用于实际的轮胎制造质量抽检预测。 图8 产品质量预测服务框架Fig.8 Service framework of product quality prediction 对于历史质量检测与生产制造数据,直接使用Logstash工具将数据从不同系统中批量导入到Elasticsearch集群,方便对数据进行可视化质量分析、构建初始产品质量预测模型。 对生产的实时数据来说,由于PLC只包含终端设备的生产数据,轮胎描述和人员编号等信息需要从MES和ERP等系统抽取集成,而Logstash难以支持复杂的中间数据处理,因此使用Kafka分布式消息队列对所有数据进行集成,并将数据实时推送到Elasticsearch集群,为实时产品质量分析提供数据来源。由于涉及到数据的重复消费问题,故可以采用“发布-订阅”的消息传递模式,构建多个consumer.group.id来实现数据的多次消费。其中,待检验产品数据对应动平衡检验工序后所构建的待质量抽检预测数据。检验后产品数据对应均匀性检验工序后所构建的包含实际已检验的轮胎数据。最终所有数据都会归档到Hadoop中,用于构建产品质量预测模型,并导出为支持跨平台运行的PMML格式文件。该文件由质量预测模型管理服务负责管理,可以方便地被Java解析并完成实时轮胎质量预测任务。 针对轮胎制造数据与轮胎检测数据的不平衡、轮胎均匀性检测中不合格品检出率的预测需求,提出了基于密度聚类与多工序制造特征的质检数据过采样MCDC-MF-SMOTE方法。与其他数据过采样方法相比,该方法的AAUCPRC提高5%~49%,有效地解决了合格与不合格的产品数量不平衡对不合格品抽出率预测的影响。为进一步提高产品质量预测方法的适应性,提出了基于Stacking集成的汽车零部件抽检不合格品预测LXSMS方法,利用MCDC-MF-SMOTE方法解决小样本检测数据类别不平衡问题,将LightGBM、XGBoost、SVM和MNB模型进行Stacking集成来预测抽检工序的不合格品。实验表明,该方法具有更高的稳定性和不合格品检出率的预测性能,相比于随机抽检,不合格产品检出率提高了63%。 对于汽车零部件大批量生产、小样本抽检的不合格品检出预测问题,虽然本文所提出的LXSMS集成学习方法性能优异,但是集成学习算法一直存在着模型训练时间长的问题。未来需要针对制造业小样本不平衡的数据集,研究更高效的模型训练方法,以及更加实时稳定的模型应用策略。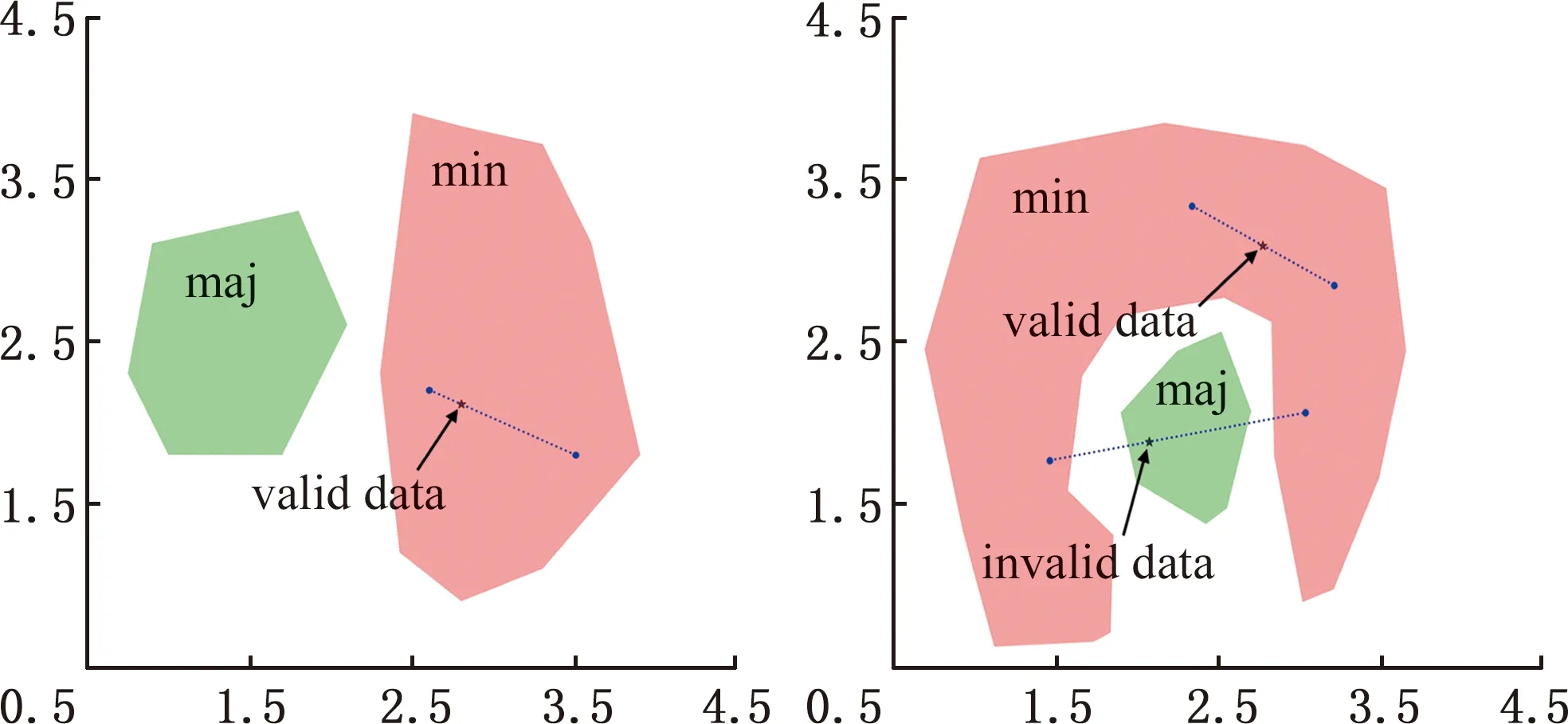
2 Stacking集成的产品质量预测方法
3 实验设计与结果分析
3.1 不同过采样方法分类性能对比实验
3.2 不同过采样率分类性能对比实验
3.3 不同分类方法的产品质量预测性能对比实验
3.4 不同分类方法产品质量预测稳定性实验
3.5 随机抽检与模型抽检性能对比实验
3.6 深度学习对不平衡制造数据集的适用性分析
3.7 实时产品质量预测应用设计

4 结论
