美国商业管制清单与专利自动映射方法及实证研究
2022-01-24吕璐成王学昭赵亚娟郭世杰
吕璐成,韩 涛,陈 芳,王学昭,赵亚娟,郭世杰
(1.中国科学院文献情报中心,北京 100190;2.中国科学院大学经济与管理学院图书情报与档案管理系,北京 100190)
1 引言
近年来,我国科技呈现多点突破、成果涌现的态势,但在国际活动中频繁遭遇美国的科技制裁、技术封锁、出口管制等问题。2018年,中兴公司在美国被封杀制裁,2019年华为公司遭遇特朗普政府主导的芯片断供危机,国内一批高校、科研机构和企业也被列入技术出口管制实体名单。这些现象引发了我国社会各界对于美国技术管制的重视。
美国的对外出口管制的历史可以追溯到1774年[1],后来逐步推出了由《出口管理法》(Export Administration Act,EAA)及其实施细则《出口管理条例》(Export Administration Regulations,EAR)组成的民用品出口管制法律体系和《武器出口管制法》(Arms Export Control Act,AECA)及其施行条例《国际武器贸易条例》(International Traffic in Arms Regulations,ITAR)构成的军品出口管制法律体系[2]。管制清单是美国实施出口管制的重要手段,美国出口管制清单包括《商业管制清单》(Commerce Control List,CCL)、《美国军用品清单》(United States Munitions List,USML)与《核管理委员会管制目录》(Nuclear Regulatory Commission Controls,NRCC)[3]。目前,关注度较高的是CCL,由美国商务部工业和安全局(Bureau of In‐dustry and Security,Department of Commerce,BIS)逐年发布,其记载了该年度管制的商品类型(包括产品和技术等)。一般认为,CCL中记载的技术是我国有待进一步发展突破的技术,及时了解并掌握这些技术的中美技术差距,对于我国宏观决策、资源配置以及引导技术研发具有重要意义。
那么如何刻画并揭示中美在这些技术上的差距?专利信息集技术、法律、经济和战略信息于一体,记载着技术研发和设计成果的进展和动向,是当前国际竞争中的重要武器,通过分析专利布局情况能够反映技术布局情况。因此,本研究从专利布局的角度分析管制清单中涉及技术的中美技术差距。
但是,CCL清单涉及技术的数量繁多,数据描述格式多样,且经常更新,对分析工作的开展造成了极大挑战。因此,本研究针对商业管制清单与专利自动映射方法进行研究,以实现在管制技术布局上的中美技术差距的高效揭示。
2 相关研究现状
本节从基于管制清单的专利分析研究开展情况以及专利文本与其他数据关联映射的研究进展情况两个方面分析相关研究现状。
2.1 基于管制清单的专利分析研究
目前,国内基于管制清单开展专利分析的研究数量不多,且主要依靠人工解读技术清单提炼关键技术,进而拟定检索表达式获取技术相关专利开展定量分析,例如,祝捷频等[4]以数控系统为例,通过对《瓦森纳协议》和美国商务部制定的《出口管制条例》中涉及的相关技术解读,拟定检索式获取专利数据开展定量分析,揭示中美数控领域专利布局差异。
此外,有些研究围绕管制清单本身采用定性分析方法和定量分析方法开展分析解读。定性分析方法方面,魏简康凯等[5]采用文献资料研究、案例分析和历史分析方法,以美国《2018年出口管制改革法案》为研究文本分析其核心内容、主要特点以及给中国带来的影响;陈峰[6]采用文献资料研究方法解析了国外科技强国实施技术出口管制的竞争情报含义,指出中国实施高技术出口管制需要高度倚重竞争情报[7]。在定量分析方法方面,陆天驰等[8]运用词频统计和共词分析对美国商品管制清单中与人工智能相关的行业数据进行分析,进而揭示领域管制重点;周磊等[9]基于2019年的实体清单数据,综合管制商品目录及出口控制分类编码体系,分析国内受限机构类型、技术出口管制领域、技术出口管制形式、技术出口管制原因。这些研究尚未涉及将管制清单数据与其他数据关联分析。
2.2 专利文本与其他数据自动化关联映射
目前,针对专利文本相似性的方法研究已经有较多研究产出,包括基于专利分类、专利引证和文本挖掘的方法[10]。由于将专利文本与其他数据关联映射时缺乏共类关系以及引证关系,因此,主要通过文本挖掘,即计算文本相似度的方法实现专利文本与其他数据自动化关联映射。
跨技术领域关联方面,Passing等[11]采用TF-IDF(term frequency-inverse document frequency)方法,识别特定技术领域的专利文本关键术语,通过计算其他技术领域与目标技术领域的语义相似度来分析技术领域之间的融合关系。
专利与论文关联方面,曾文等[12]改进基于TFIDF的词频向量空间模型,将词频统计改为术语频率统计,提出了一种计算科技期刊文献与专利文献之间相似度的方法;徐红姣等[13]针对采用Word2Vec对文本主题进行聚类,通过计算主题语义相似性实现论文和专利的关联。
专利与产业映射方面,田创等[14]基于TF-IDF和Z-score标准化方法,提出了专利数据与产业数据的自动化映射方法。
专利与需求匹配方面,詹文青等[15]采用依存句法分析识别专利文本和技术需求文本的动宾(verbobject,VOB)结构,基于语义TRIZ(theory of inven‐tive problem solving)框架对其技术问题、技术功能和技术效果进行标注,通过相似度计算分析专利和技术需求的匹配性。
综上可知,开展管制清单与专利的自动化映射方法研究具有较高的创新性和探索性;同时,在专利数据与其他数据自动化关联映射方面,也有相对有效的文本相似度计算方法可被应用。因此,本研究提出了基于文本相似度的美国商业管制清单与专利自动映射方法,并开展实证研究。
3 研究方法
3.1 方法框架
首先,图1展示了本研究采用方法的整体框架,即基于美国商业管制清单数据和专利数据,构建“管制技术-专利”自动映射模型;其次,应用模型将管制清单数据与专利数据建立映射关系,该映射关系为“一对多”关系,即一个管制清单技术类别会对应多件专利,而一件专利仅属于一个最合适的管制技术类别;最后,基于该映射关系,开展各国在各管制技术类别上的专利布局差异对比,并形成分析结论。
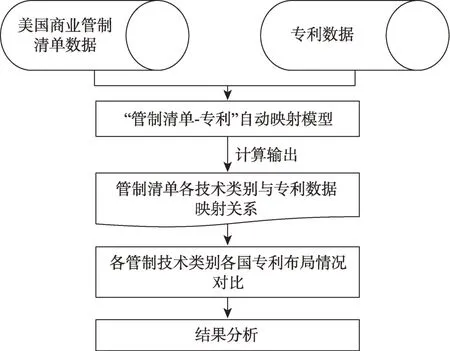
图1 方法整体框架
3.2 “管制清单-专利”自动映射模型
“管制清单-专利”自动映射模型是本研究的核心内容,模型框架如图2所示。核心步骤包括:
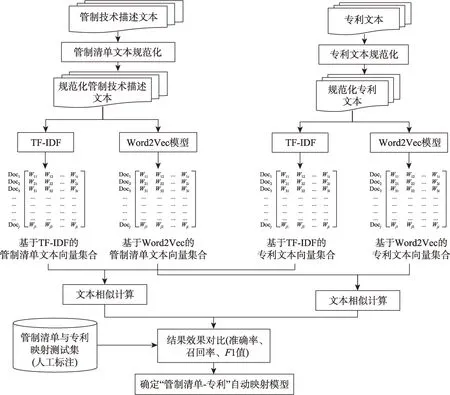
图2 “管制清单-专利”自动映射模型框架
Step1.对于管制清单文本和专利文本分别进行规范化。
Step2.对于规范化管制清单文本和专利文本分别进行向量化。
Step3.采用两套方案对于管制清单文本向量和专利文本向量进行相似计算;
Step4.通过测试集评判效果较优的模型和相似度阈值,确定其为开展后续分析的“管制清单-专利”自动映射模型。
以下针对各个步骤的实施过程分别进行论述。
3.2.1 文本规范化
3.2.1.1 管制清单文本规范化
管制清单文本是一类特殊的文本形式,具有专属特征。从文本挖掘的原理看,直接将其与专利文本进行相似计算,会在特征提取过程中产生文本特征被淹没的问题。因此,本研究对商业管制清单文本进行了深入的人工解读和分析,从中归纳出了管制清单文本特有的一些特征,这些特征属于文本相似计算时的噪声,可以在进行文本匹配之前予以过滤,从而提升自动映射的效果。
图3 展示了管制清单文本规范化的流程,包括关键短语识别、噪声文本过滤、停用词剔除和词干化四个步骤。
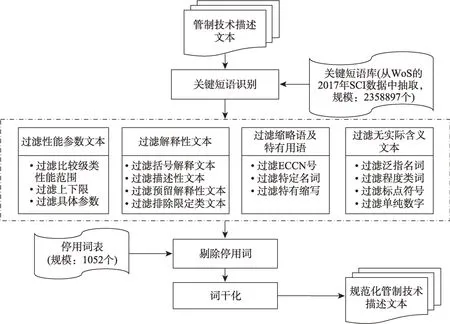
图3 管制清单文本规范化流程
为了避免词组被切分造成特征被稀释的问题,本研究首先对文本进行了关键短语识别。关键短语识别采用基于词典的方式进行识别,短语词典通过从Web of Science(WoS)数据库2017年收录的SCI(Science Citation Index)论文中抽取非单词的词组(如optical sensors、optical detectors)构建,关键词典包含关键词组的规模为2358897个。
停用词剔除基于停用词表进行,停用词表通过人工判读文本构建,包含停用词1052个。
词干化的目的是消减英文单词形态多样造成的干扰,本研究采用Python的NLTK(natural language toolkit)工具包中集成的SnowballStemmer工具对文本进行词干化。
噪声文本过滤是过程中的关键步骤。本研究将噪声文本按照类型分为性能参数文本、解释性文本、缩略语及特定用语文本以及无实际含义文本,采取词性标注规则过滤(本研究采用NLTK工具中集成的词性标注工具实现)、正则过滤和直接过滤三种方式进行噪声文本数据的过滤剔除,具体如下文所述。
1)性能参数文本
管制清单中会对管制技术或产品的性能参数进行明确的限制,包括性能范围和具体参数。其中,性能范围包括比较级(性能参数高于或低于某个数值)和上下限(性能参数在某个区间),但是这些参数作为文本特征的区别度不高,与专利文本进行相似计算时发挥作用甚微,因此本研究将其剔除。性能参数文本的特征、示例以及处理方法示例如表1所示。

表1 性能参数文本特征及处理规范示例
2)解释性文本
解释性文本,是指对管制清单中的某项技术或产品进行内涵限定,包括括号解释文本、描述性文本和预留解释性文本。其中,描述性文本又包括成分限定、组成限定、类别限定和过渡用语。这些文本作为文本特征同样没有特别高的区别度,因此需要剔除。解释性文本的特征、示例以及处理方法示例如表2所示。
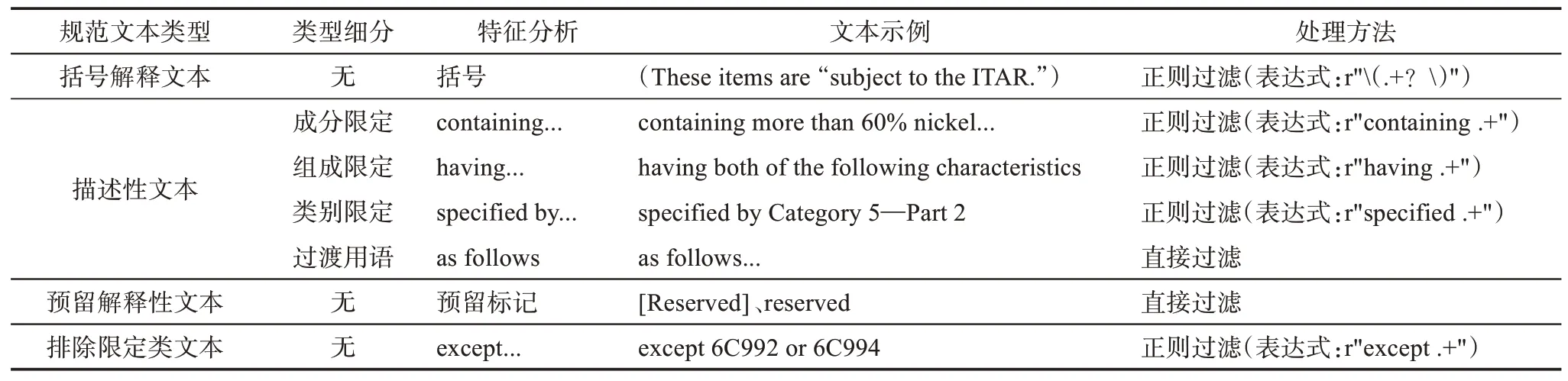
表2 解释性文本特征及处理规范示例
3)缩略语及特定用语
缩略语及特定用语,是指管制清单中出现的特有的缩略语或短语,包括ECCN(export control classification number)号、特定名词和特有缩写(这种词一般CCL中会有全称)。这些文本属于专有文本,在专利中基本不会出现,属于噪声数据,因此需要剔除。缩略语及特定用语文本的特征、示例以及处理方法示例如表3所示。

表3 缩略语及特定用语特征及处理规范示例
4)无实际含义文本
无实际含义文本,是指管制清单中出现的一些通用的泛指类词和其他噪声文本,这些词没有明确含义,包括泛指名词、程度类词、标点符号和单纯数字。这些文本在文本相似计算时也属于噪声数据,因此需要剔除。无实际含义文本的特征、示例以及处理方法示例如表4所示。

表4 无实际含义文本特征及处理规范示例
3.2.1.2 专利文本规范化
专利的标题和摘要记载了专利的主要技术方案和实现的技术效果,因此本研究选取专利数据的标题和摘要文本与管制清单进行文本相似计算。
图4 展示了专利文本规范化的流程,包括关键短语识别、停用词剔除和词干化三个步骤,这三个步骤与管制清单规范化中对应的三个步骤一致,在此不再赘述。
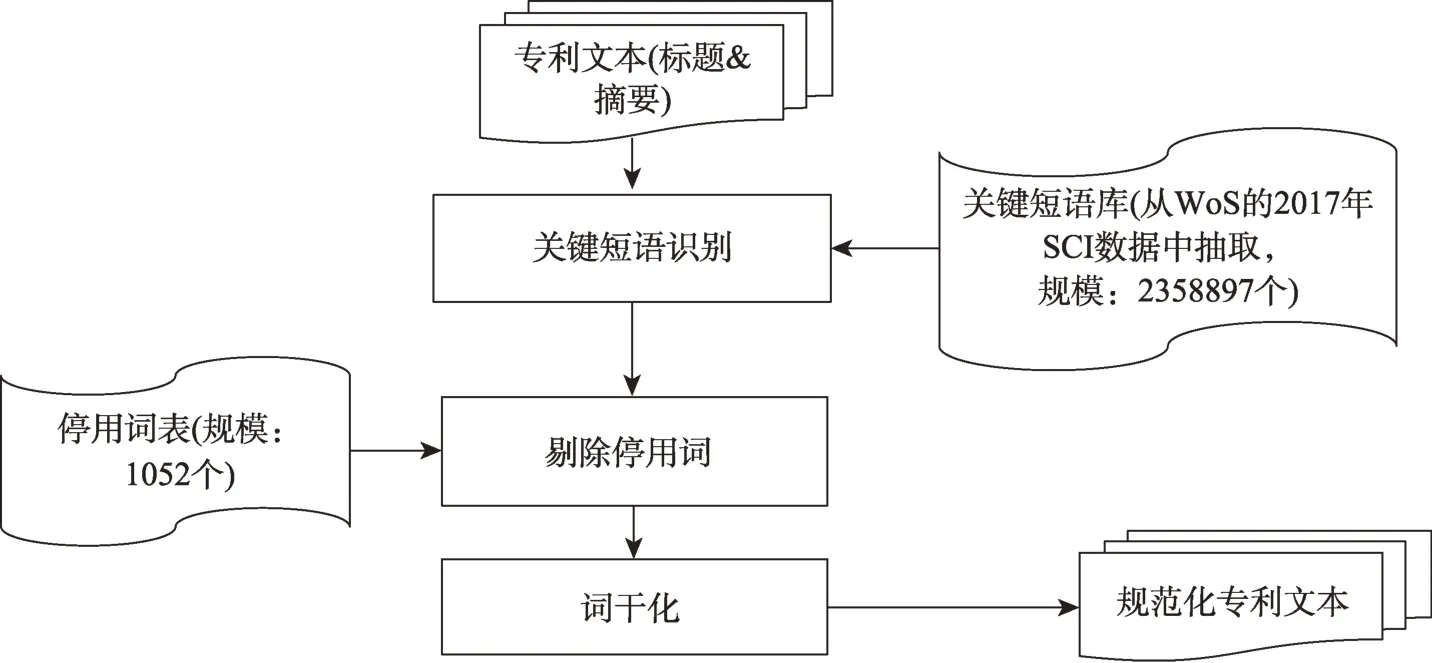
图4 专利文本规范化流程
3.2.2 文本向量化
文本向量化是文本相似计算的重要步骤。基于国内外专利文本与其他数据自动化关联映射的方法,本研究采用两种文本向量化方法进行管制清单和专利文本向量化,即基于TF-IDF的文本向量化方法和基于Word2Vec的文本向量化方法。
1)基于TF-IDF的文本向量化
TF-IDF可以用于评估一个词对语料库中一份文件的重要程度,能够凸显有区别能力的特征词。实际上,基于TF-IDF的文本向量化是构造了目标文本的向量空间模型(vector space model,VSM),即将文本表示成实数值分量所构成的向量,分量采用词的TF-IDF值进行表示。本研究采用了Python的Gensim包中集成的TF-IDF模型实现文本向量化。
2)基于Word2Vec的文本向量化
虽然基于TF-IDF的向量空间模型具有清晰明确易解释的优点,但是其存在向量维度随着词表增大而增大且向量高度稀疏的问题,同时其也无法处理同义词、近义词的语义问题[16]。
对此,Google公司Tomas在2013年提出的Word2Vec技术能够使用低维度连续分布式向量来表示一个词的语义[17],并且能够有效表征同义词、近义词等语义相近的词之间的相似关系,因此,在文本向量表示方面具有更高的可用性。Word2Vec模型是一个三层的浅层神经网络,有两种训练方法:CBOW和Skip-Gram。由于Skip-Gram在实际应用时训练效果优于CBOW,因此本研究采用Skip-Gram方法,基于英文专利语料训练了用于后续文本相似性计算的Word2Vec模型。
本研究利用Python语言编程实现了基于Word2Vec的文本向量化方法,具体步骤为:
Step1.从Word2Vec模型中获取每个词特征的词向量,依次组合形成一个二维数组。
Step2.将二维数组的元素逐个求和,形成一个跟词向量长度一致的一维数组Array。
Step3.将一维数组归一化,归一化利用一维数组对应的向量模长,公式为
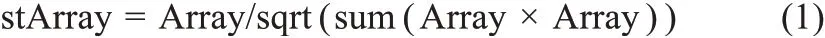
Step4.最后得到的stArray即句子向量。
本研究得到的管制技术向量和专利文本向量的

其中,i表示第i类管制技术;j表示第j件专利;n表示向量维度(本研究中,n=300);Wi,k表示第i类管制技术向量的第k个元素;wj,k表示第j件专利向量的第k个元素。
3.2.3 文本相似性计算及阈值设定
在通过文本向量化获得管制清单各类别文本向量和专利文本向量后,本研究采用余弦相似度的方法进行两两文本相似性的计算,公式为
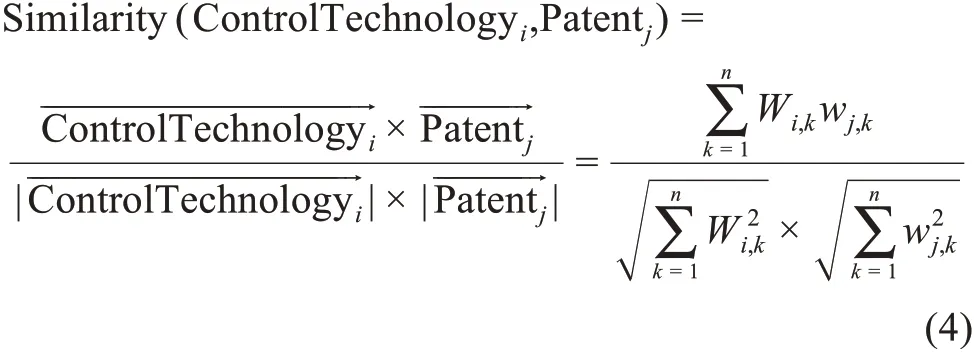
通过逐项两两计算,获得每一篇专利与对应管制清单类别的相似度列表。相似度数值越大,表示专利与该管制技术类别的语义相似性越高,即专利属于该管制技术类别的可能性越大。
由于并非每件专利都属于管制技术类别,因此,本研究通过设定相似度阈值来确定属于管制技术类别的专利,相似度阈值的设定基于模型在测试集上的映射效果来判断。最终,选择不低于相似度阈值的专利作为管制技术专利集合,这些专利所属的管制技术类别为与其相似度最大的类别。
3.2.4 效果评估指标
本研究选用准确率、召回率和F1值三个评价指标来评估模型效果,分别采用宏平均的方式进行计算,即先对每一个类别分别计算准确率、召回率和F1值,然后对所有类别计算出算数平均值,公式为

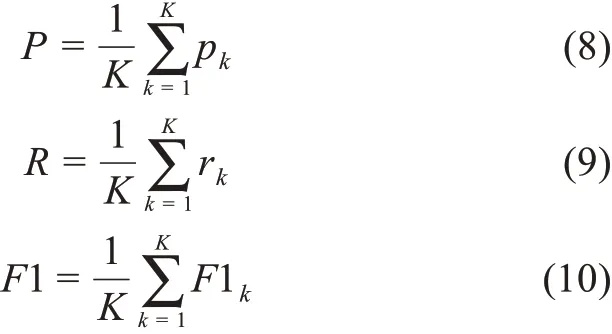
其中,K代表管制技术类别数目;k表示第k类管制技术;p k、r k和F1k分别代表k类别的准确率、召回率和F1值;pk是衡量正确划分到k类别的专利占模型预测出的划分到k类别的专利的比例,pk越大,说明模型对于k类别专利分类越准确;召回率r k是衡量正确划分到k类别的专利占测试集中属于k类别的专利的比例,r k越大,说明模型在k类别上漏掉的样本越少;F1k综合考虑准确率和召回率,F1k越高,说明k类别的分类效果越理想;P、R、F1分别表示模型的准确率、召回率和F1值。
3.3 管制技术专利布局态势分析框架
基于计算得到的管制清单各技术类别与专利数据映射关系,本研究提出一套可用于技术差距分析的管制技术专利布局态势分析框架,如图5所示。即分别进行各管制技术类别的专利布局国家分布对比和布局机构分布对比,从而量化判断各国在管制技术类别上的技术差距。
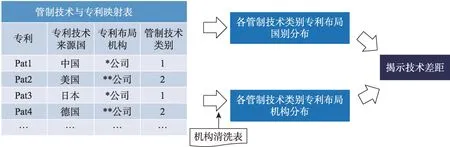
图5 管制技术专利布局态势分析框架
4 实证研究
4.1 实证数据来源及测试集
4.1.1 管制清单数据
本研究选择的管制清单数据是美国商务部工业和安全局于2019年发布的商业管制清单。因商业管制清单中编号为0的大类“NUCLEAR MATERI‐ALS,FACILITIES,AND EQUIPMENT[AND MIS‐CELLANEOUS ITEMS]”除了包含核材料、设施和设备的少量描述外,还包括大量杂项技术,类别内容不聚焦,经分析后,在本研究中不予考虑,并将其与未管制技术共同放入一类,即“未管制或0类”,类编号为“10”,其他编号1~9的技术正常进行分析。管制技术类号及名称如表5所示。

表5 管制技术类别
4.1.2 专利数据
由于2019年的商业管制清单是较高程度上依据前一年的技术布局情况而拟定的,因此,本研究选取2018年作为实证研究的时间节点;另外,考虑到各国通过PCT(Patent Cooperation Treaty,专利合作条约)途径申请①PCT是一项国际合作条约。根据PCT的规定,参加该条约的国家的专利申请人可以通过PCT途径递交国际专利申请,向多个国家申请专利。中国、美国、日本、韩国、德国、法国等均是PCT成员国。的专利遵守同样的约定,不存在明显地域差异,且更能代表各国的技术研发实力以及在全球的技术布局策略,因此,本研究选择了2018年全球申请的PCT专利与商业管制清单进行映射研究。专利数据通过Incopat专利数据库②https://www.incopat.com/下载,检索式为AD=[20180101 to 20181231]AND PN=WO*,检索日期为2019年11月13日,共获取2018年全球PCT专利申请213161件。图6展示了专利数据的Top 10技术来源国的分布情况,美国、日本、中国位列PCT专利申请量的前三位,三者的专利数量占全球总量的63%,专利布局优势较为明显。
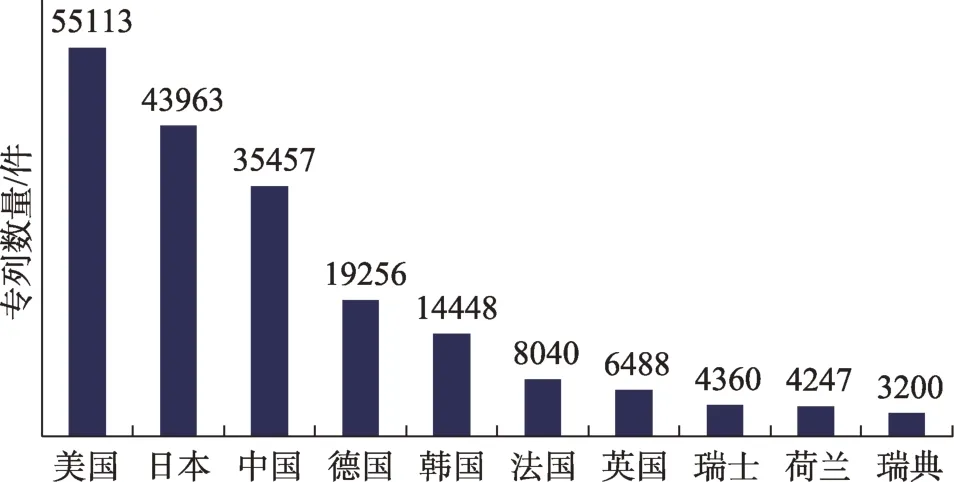
图6 2018年全球PCT专利申请量Top 10技术来源国分布图
4.1.3 测试数据集
本研究邀请具有领域背景知识的情报专家通过人工标引构建分析结果评估测试数据集。共获得标引数据1015条。10个类别的数据分布如图7所示。其中,“10-未管制或0类”的专利数据最多,为357件;其次是“4-计算机”类,专利数据为121件,“8-海洋装备”专利数据最少,为27件。
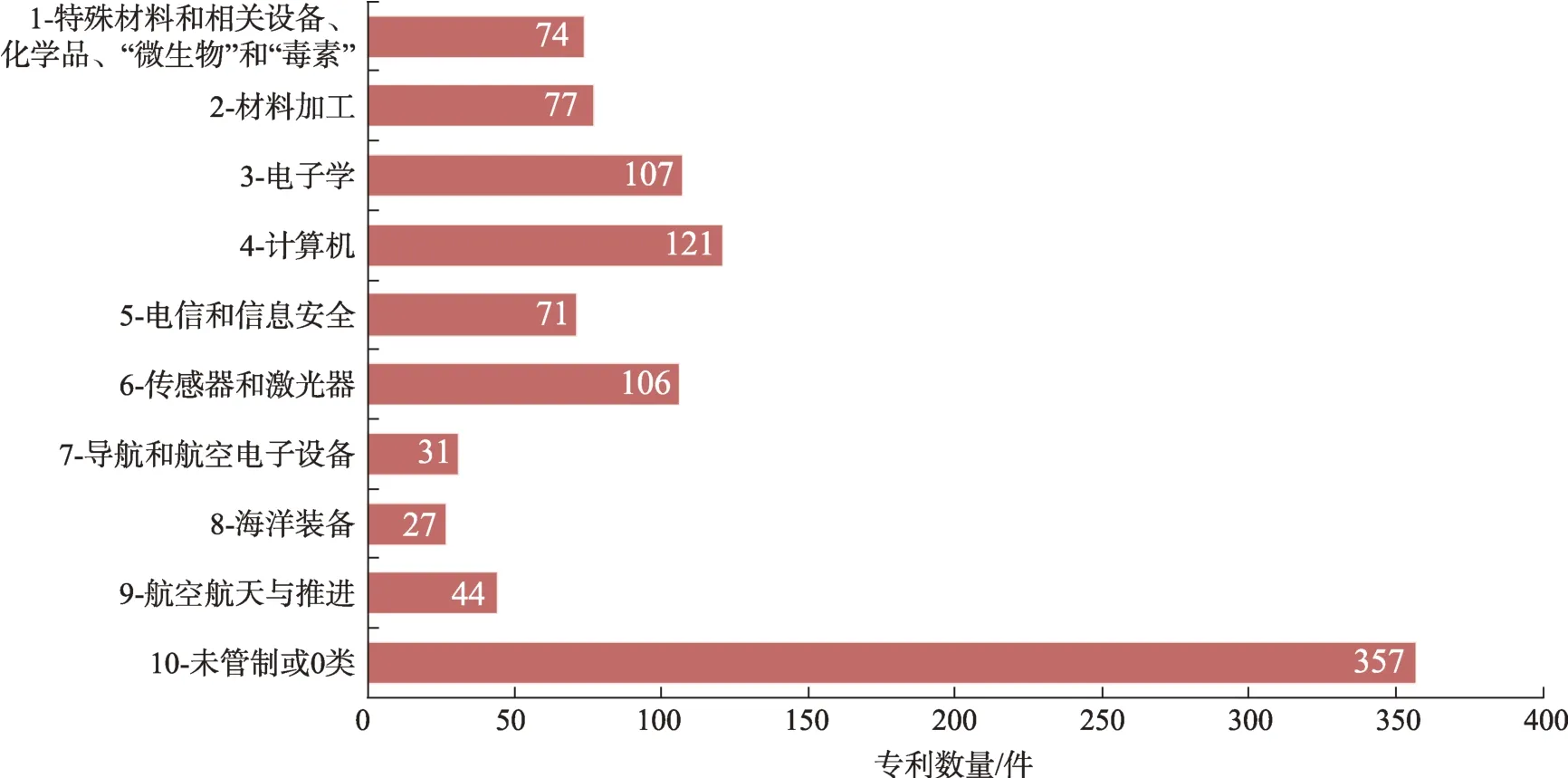
图7 测试数据集中各类别的专利数量分布
4.2 模型效果分析
本研究采用基于TF-IDF和基于Word2Vec两套方案对2019年美国商业管制清单数据与2018年全球PCT专利申请数据进行自动映射计算,并利用测试数据集分别计算宏平均准确率、召回率和F1值指标。
由于两套方案的自动映射模型均受到文本相似度阈值的影响,因此,本研究选取多个阈值参数,对其分别判断各项指标值。计算结果如表6所示。
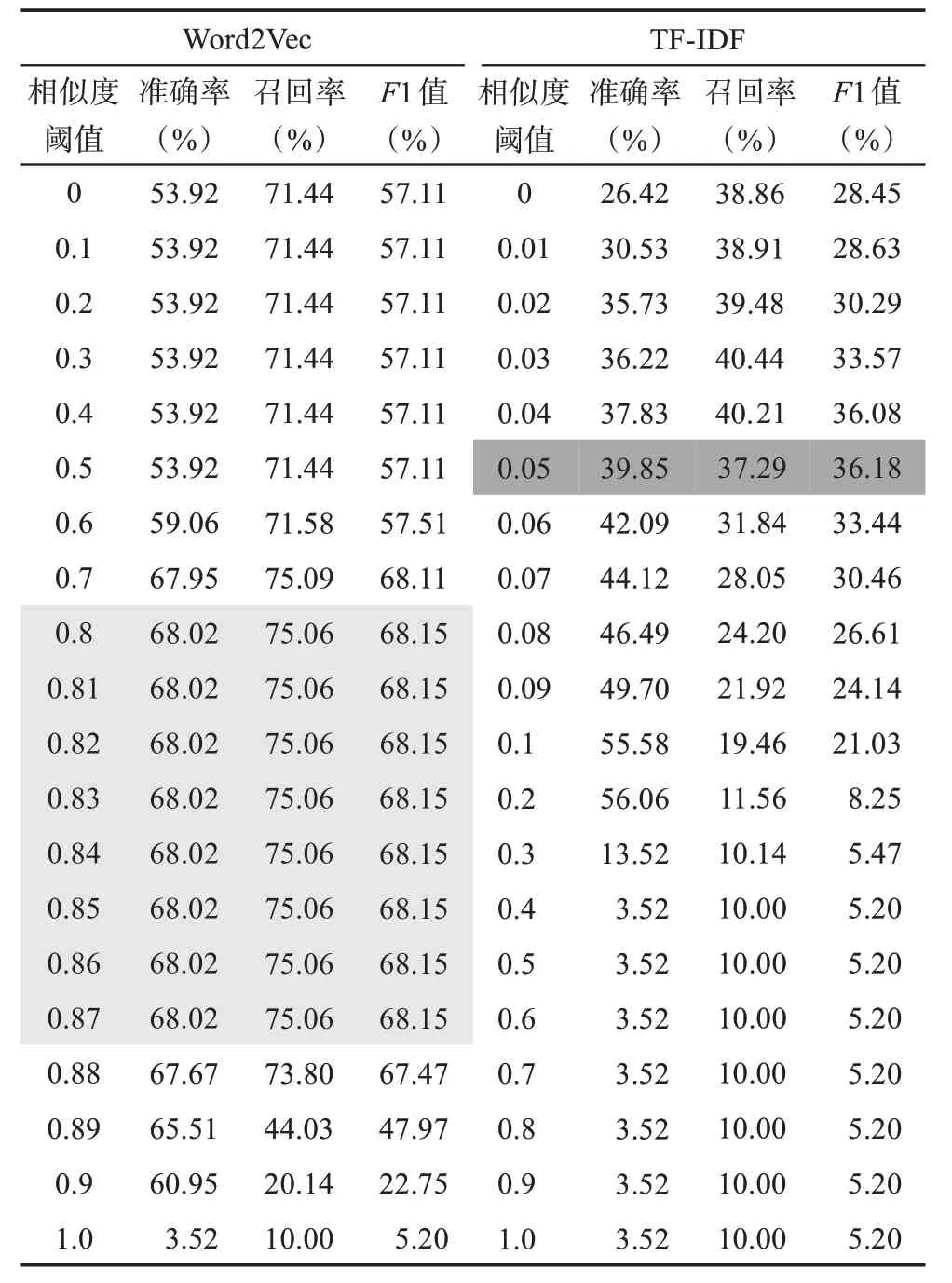
表6 Word2Vec模型和TF-IDF模型调整阈值对应的评估指标计算结果
具体地,首先在[0,1]区间按照0.1的步长分别取相似度阈值。研究发现,Word2Vec模型在阈值为0.8时,宏平均F1值最大;TF-IDF模型在阈值为0时,宏平均F1值最大。然后,进一步对Word2Vec模型以步长0.01在[0.8,0.9]区间取阈值,对TF-IDF模型以步长0.01在[0,0.1]区间取阈值,发现Word2Vec模型在阈值取值范围为[0.8,0.87]①这是由于在该区间,Word2Vec模型预测的各个类的准确率、召回率和F1值均相同。时,宏平均F1值均取最大,取值为68.15%(表6中浅灰色底纹标出),TF-IDF模型在阈值为0.05时,宏平均F1值最大,取值为36.18%(表6中深灰色底纹标出)。
从上述对比数据来看,Word2Vec模型的映射结果明显优于TF-IDF模型。究其原因发现,管制清单与专利文本用词差异很大,基于TF-IDF从管制清单中直接提取的词特征很可能在专利中找不到对应特征,因此,相似计算效果不佳;但是,Word2Vec能够识别同近义词的语义关系,所以,能够将管制清单中的词特征与专利文本的词特征建立相似关系,进而实现较为准确的相似度计算。
对于Word2Vec模型而言,相似度阈值在[0.8,0.87]区间时,F1值最大,映射效果最优,此时的准确率为68.02%,召回率为75.06%。从数据检索的经验来看,相似度阈值越高,一般检索准确率越高。因此,为了保证分析准确性,本研究选择Word2Vec模型文本相似度阈值为0.87时的映射结果开展后续的技术差距分析。
4.3 管制技术PCT专利布局态势分析
本研究基于Word2Vec模型相似度阈值为0.87时取得的自动映射结果,进行2019年美国商业管制技术类别的PCT专利布局态势对比分析。
经过自动映射计算,2018年全球申请的213161件PCT专利中,有17232件被识别为管制技术专利,占比8.08%。从整体结果来看,美国的相关专利布局最多,为5799件,优势较为明显;中国由在全部专利数据中所处的第三位上升到第二位,这在一定程度上证明了我国在管制技术的布局上重视程度的提升(图8)。

图8 各国围绕管制技术的PCT专利申请量分布
4.3.1 管制技术专利国别分布
图9 展示了九类技术的Top 3布局国别分布图。从图中可以发现,2018年中国和美国在九大领域中的PCT专利申请量均在全球前三位,呈现“角逐”态势,但是美国的优势明显大于中国。
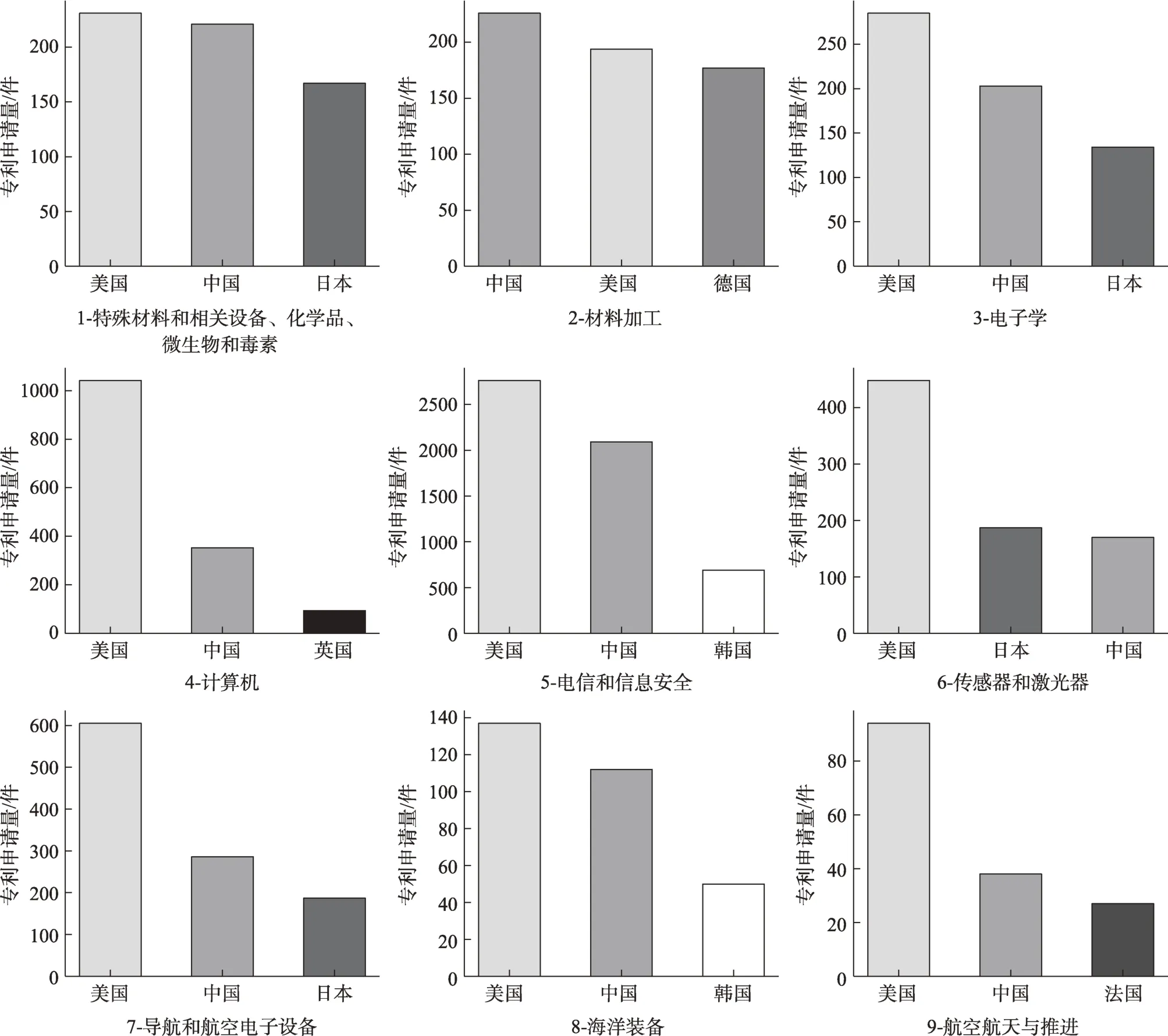
图9 九类管制技术对应的Top 3 PCT专利布局国
从分析结果来看,美国在除了材料加工之外的其他8个技术领域的PCT专利申请量均居于全球首位。尤其在计算机、传感器和激光器、导航和航空电子设备以及航空航天与推进四个领域,较排名第二的国家均有明显优势。
中国在材料加工领域PCT专利布局数量排名全球第一,但是优势较美国和德国并不明显。此外,中国在除了传感器和激光器之外的管制技术领域排名全球第二,与美国初具“对抗”之势。在传感器和激光器领域,中国位居全球第三,日本位居第二,这与我们对日本在精密仪器和物联网方面具有较强技术储备的认知一致。
4.3.2 机构分析
进一步地,对九类管制技术的Top 5布局机构分布进行分析,如表7所示。可以发现,除传感器和激光器技术领域外,我国均有机构进入各类别的Top 5排名机构清单。虽然我国整体专利布局数量不及美国,但是我国的诸多机构在各个管制技术类别里表现突出,例如,华为在电信和信息安全技术类别下排名第一,这与当前美国对华为的管制措施升级现象吻合;还有京东方科技集团在电子学技术类别排名第一,平安科技在计算机技术类别排名第一,大连理工大学在海洋装备技术类别排名第一。此外,华南理工大学和南通德亿新材料有限公司在特殊材料和相关设备、化学品、微生物和毒素技术类别下排名第二和第五。大疆科技公司在导航和航空电子设备、航空航天与推进两个技术类别下分别排名第二和第四,青岛海尔公司在海洋装备技术类别下排名第三等。由此可以推断,目前我国机构在管制技术布局方面正在逐步取得突破。
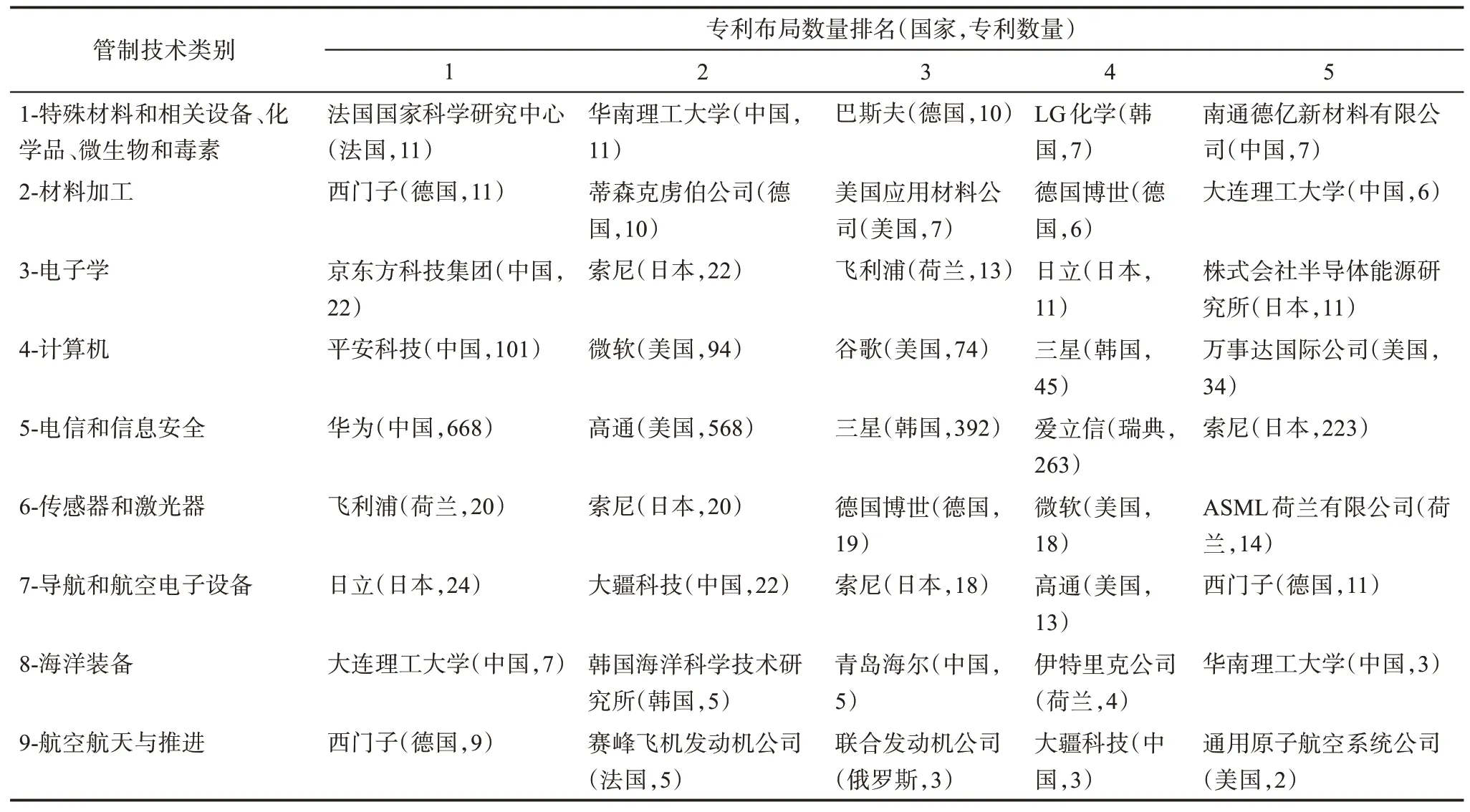
表7 九类管制技术对应的Top 5 PCT专利布局机构
反观美国,虽然美国整体PCT专利数量排名位居全球首位,但是美国机构的PCT专利布局数量并不突出。出现在Top 5清单中的美国机构包括计算机技术类别下的微软、谷歌和万事达国际公司,材料加工类别下的美国应用材料公司,电信和信息安全技术、导航和航空电子设备技术类别下的高通公司,传感器和激光器技术类别下的微软公司,以及航空航天与推进技术类别下的通用原子航空系统公司。
5 总结与展望
在当下全球科技对抗形势持续胶着的时代背景下,本研究面向高效率揭示中美在美国商业管制清单记录的管制技术上的差距的情报需求,针对管制技术清单非结构化程度高的问题,提出了从专利分析的角度对比中美在管制技术上的差距的思想,采用文本挖掘手段研究了美国商业管制清单与专利自动映射方法,并以2019年美国商业管制清单和2018年全球PCT专利申请数据为例开展了实证研究,实现了专利视角的中美管制技术布局差距的高效揭示。
本研究的实证结果在一定程度上印证了当前美国对华出口管制持续升温的现象,能够较好地解释华为等中国机构接连被管制的原因。此外,对于情报研究而言,本研究提出的方法能够高效地关联管制清单数据和专利数据并开展情报分析,是提升情报分析时效性的有力手段,具有较高的实际应用价值。
但是,本研究提出的方法得到的分析结果缺乏鲁棒性,仅能作为情报研究工作的阶段性辅助参考。如果需要准确、深度的国家间知识产权差距对比,仍需专利情报分析人员介入,利用领域背景知识,保证管制技术相关专利检索的查全率和查准率,进而实现中美技术差距的精准揭示。
在方法层面,本研究依靠初步构建的停用词库、关键词库提升文本相似度的计算结果,在知识图谱技术蓬勃发展的背景下[18],高质量的知识图谱的引入能够进一步提升方法的准确率和可用性。
