基于无监督图神经网络的学术文献表示学习研究
2022-01-24任卫强曹高辉
丁 恒,任卫强,曹高辉
(华中师范大学信息管理学院,武汉 430079)
1 引言
科学研究是人类认知世界的手段,对社会、科技、经济、文化的发展具有重大的影响。学术文献是科学研究活动的重要成果,也是科学工作者之间交流思想的主要工具。文献计量学研究表明,学术文献发表的数量以每年8%~9%的速度快速增长[1],展现着科研活动和学术交流的繁荣景象。然而,爆炸式增长的文献数量也为科研活动带来了负面影响,研究人员难以处理海量的学术文献,面临着严重的信息过载问题。基于此,以计算机信息处理技术为核心,面向海量学术大数据的信息服务(如Web of Science、Google Scholar、Mendeley等),已成为研究人员不可或缺的科研工具。
如何从学术文献中抽取重要的信息,将学术文献表示成计算机算法更易处理的形式,是实现学术文献的分类、组织、检索和推荐的一个核心问题。传统方法主要是依靠专家经验构造人工特征对学术文献进行表示,例如,在学术信息检索中以论文标题和摘要文本构建倒排索引,文献分类和推荐系统中以词袋模型、向量空间模型、主题模型构建学术文献表示向量[2-3]。
近年来,基于深度学习的学术文献表示学习受到了广泛关注。例如,文献[4-6]采用神经语言模型从大规模学术文献语料库中自动学习文献的语义特征,将学术文献表示成稠密向量,进而实现分类、检索和推荐,其主要缺点在于神经语言模型仅考虑了学术文献的文本语义信息,忽视了学术文献之间的关系结构信息。有鉴于此,文献[7-9]提出用图神经网络从文献引文网络中提取文献间的关系结构信息,并与文献文本语义信息相融合,从而构造学术文献表示向量的思路。然而,现有研究大多采用有监督图神经网络学习文献特征表示,其存在两个缺点:①有监督图神经网络需要针对具体的任务构建大量的、高质量的标注数据;②有监督图神经网络获取的文献特征表示与标注数据集的任务高度耦合,难以直接迁移到其他任务上,导致特征表示的普适性较差。
相较于有监督图神经网络,无监督图神经网络可直接从无标注文献网络数据中学习通用的文献特征表示,进而应用于文献分类、学术检索、论文推荐等不同的下游任务,被认为是一种更具优势的学术文献表示学习方法。然而,无监督图神经网络在学术文献表示学习上的效果尚不明确。基于此,本文将无监督图神经网络方法应用于学术文献的表示学习,自动从不同类型的学术文献网络中学习论文的特征表示向量,并且进一步探讨特征向量在文献分类、学术检索、论文推荐等下游任务的应用情况。本文旨在通过系统性的模拟实验回答以下三个研究问题,为构建基于预训练文献表示向量的学术大数据应用提供有效参考依据。
问题1:在文献分类和论文推荐两个下游任务场景中,哪种无监督图神经网络方法具有更好的效果?可能的内在原因是什么?
问题2:无监督图神经网络特征表示维度变化对文献分类和论文推荐任务的最终效果有何影响?
问题3:哪种类型的学术文献网络(引文网络、共被引网络和文献耦合网络)更适合学习文献的通用特征表示?
2 相关研究
2.1 表示学习研究
机器学习应用的效果很大程度上取决于特征表达,即如何构建样本数据的特征表示。传统的机器学习时代,特征表达主要依靠人类的先验知识,通过人工分析提取样本的重要信息,将其组织为特征向量,即所谓的特征工程[10]。然而,特征工程严重依赖专家知识且耗时耗力,因此,自动从原始数据中学习数据的有效表示(即表示学习研究)逐渐成为研究热点[11]。近年来,深度学习技术使得表示学习在图像识别、语音和信号处理以及自然语言处理等领域取得了显著成果。例如,计算机视觉领域,相较于人工视觉特征,利用卷积神经网络的自动提取视觉特征大大地降低了图像识别的错误率[12];语音识别应用中,在传统声学特征梅尔倒谱系数(Mel-frequency cepstral coefficients,MFCC)的基础上,通过神经网络增强特征表示能够进一步提升语音识别的最终效果[13];自然语言处理研究中,通过训练大规模预训练语言模型获得文本的向量表示,例如,基于词上下文预测的Word2Vec[14]、基于上下文Word Embedding双向动态调整的ELMo[15]以及基于Transformer的双向语言模型BERT(bidirectional encoder representation from transformers)[16-17]已成为当前自然语言处理任务的标准基线。
如何针对不同的具体任务构建合适的神经网络结构,是基于深度学习的表示学习研究的一个重要问题。从已有的实证研究来看,卷积神经网络(convolutional neural networks,CNN)、递归神经网络(recurrent neural network,RNN)和基于注意力机制的Transformer神经网络已成为图像、音频和文本数据表示学习的关键组件。实证研究表明[11],通过深度神经网络学习特征,表示学习能够具有较强的数据表征能力,可以不依赖于某一特定任务,学习到更通用的先验知识。因此,将表示学习引入学术数据处理和表征,对论文、作者、期刊、机构、研究问题、方法、技术、数据集等学术实体的识别、分类、组织、检索和推荐具有较大的潜在价值。
2.2 图嵌入研究
图结构广泛存在于现实场景中,如社交网络、通信网络、分子结构、引文网络等,真实的图数据具有高维度、难处理的特点,如何将高维图转化为低维向量表示,即图嵌入研究(graph embedding)一直是学术研究的热点[18]。目前,图嵌入领域主要有基于因子分解的、基于随机游走的和基于深度学习的三大类方法。基于因子分解的图嵌入有局部线性嵌入[19]、拉普拉斯特征映射[20]、图因子分解机[21]等方法,该系列方法以线性代数为理论基础,依靠特征值分解、奇异值分解等矩阵分解技术,将原始高维向量转换为低维特征向量,且保留原始矩阵中的重要信息。基于随机游走的图嵌入有DeepWalk[22]和Node2Vec[23]等,该系列方法受自然语言处理研究中的词向量(Word2Vec)研究启发,以图中任一节点为起始点,通过无偏或有偏随机游走获得节点序列,再使用Word2Vec算法学习节点的嵌入向量,嵌入向量能够表征节点在图中局部结构信息。基于深度学习的图嵌入有基于自编码器和邻接矩阵的SDNE(structural deep network embedding)[24]、基于卷积神经网络的图卷积神经网络GCN(graph convolutional network)[25]以及基于编码器-解码器结构的图自编码器GAE(graph auto-encoder)[26]等,该系列方法能够利用深度神经网络模拟高维非线性函数,从而获得更精准的节点嵌入向量,具有更强的图数据表示能力。
在图嵌入研究中,以图自编码器(GAE)为代表的无监督图神经网络方法,不仅能够编码节点的网络结构信息,而且能够利用节点的属性信息,从多种角度学习到图数据中蕴含的先验知识。由于学术数据的先验知识不仅存在于学术文献的文本语义信息中,还蕴藏于学术文献构成的关系网络里,且学术数据的表示可应用的领域和任务较多,利用图神经网络获取学术数据的通用表示有利于促进学术大数据的挖掘与应用。
3 基于图的学术文献表示学习
3.1 文献关系网络
学术文献往往并非孤立存在,而是通过相互联系形成网络结构,比如引文网络、共被引网络、文献耦合网络等。网络在数据科学、计算机科学中又称为图,是一种常见的数据结构,一般用G=(V,E)表示。其中,V表示网络中所有节点的集合;E表示网络中所有边的集合;vi∈V表示V中第i个节点;eij=(vi,vj)∈E表示节点vi和vj之间的边。对于学术文献网络G而言,vi表示一篇学术论文,eij表示论文vi和论文vj之间的引用、共被引或文献耦合关系。在数学上,网络G的结构信息可用n×n的邻接矩阵A表示,矩阵A的第i行第j列元素记为Aij,Aij=1表示节点vi与节点vj之间存在一条边;反之,则Aij=0。网络G中所有节点的属性信息用属性矩阵X∈Rn×d表示,矩阵X中一行xv∈Rd表示节点v的属性向量。因此,具有节点属性的图又可以表示为G=(X,A)。在学术文献网络中,属性矩阵X代表着所有论文的文本语义信息,而A则代表学术文献之间构成的网络结构信息。
学术文献表示学习,是指利用神经网络从大规模、高维度学术文献数据中自动地获取文献的低维向量表示,是表示学习研究在学术数据领域的具体应用。目前,学术文献表示学习主要有以下两大类方法。
(1)基于文本数据的文献表示学习。主要利用神经语言模型,将篇幅较大、词项较多的论文的文本信息编码成低维稠密实数向量,解决传统词袋模型下论文表示向量词项空间过大的问题。
(2)基于图数据的文献表示学习。主要利用图神经网络模型,从文献关系网络中提取有效信息,进而将论文编码成低维向量,其核心思想是论文之间的关系结构一定程度上能够表达论文本身的特征。
从数学形式上看,前者可记为f(X)→Z,只利用了论文的文本语义信息X;后者可记为f(X,A)→Z,不仅利用文本语义信息X,同时利用文献网络的结构信息A。Z是神经网络f输出的文献特征表示矩阵,矩阵Z中任一行zv表示文献v的特征表示向量,该向量可被应用于文献分类、学术检索、论文推荐等下游任务中。模糊的学科边界、高度交叉融合的学科体系,导致“一词多义、一义多词”的现象普遍存在于学术论文中,纯粹基于文本语义信息的文献表示学习方法具有先天的缺点,因此,本文主要探讨以图神经网络为基础,可综合利用两种信息的学术文献表示学习方法。
3.2 无监督图神经网络
目前,图神经网络主要分为有监督、半监督和无监督三大类型。其中,无监督图神经网络不仅具备图神经网络能够同时编码文献文本语义信息和文献关系结构信息的能力,同时具有无需标注数据的优势,且网络训练过程与下游任务解耦,所学习到的文献表示具有较强的通用性。因此,本文聚焦于多种代表性无监督图神经网络方法在学术文献表示学习上的应用效果,选择的代表性无监督图神经网络有图自编码器(GAE[26])、变分图自编码器(variational graph auto-encoders,VGAE)[27]、对 抗正则化变分图自编码器(adversarially regularized variational graph autoencoder,ARVGA)[27]和深度互信息图神经网络(deep graph infomax,DGI)[28]。
无监督图神经网络主要由编码器、解码器以及学习目标三个部分构成。
(1)编码器。以文献网络的邻接矩阵A和文献文本语义信息矩阵X为输入,通过编码函数f获得文献特征表示矩阵Z,记为f(X,A)→Z。
(2)解码器。在文献特征表示矩阵Z的基础上,通过解码函数获得重构邻接矩阵记为
(3)学习目标。在文献网络的邻接矩阵A、重构邻接矩阵A^、文献特征表示矩阵Z等的基础上,根据目标函数评估、优化文献特征表示矩阵Z的表达能力。
表1 列举了四种无监督图神经网络各部分的差异。

表1 四种无监督图神经网络差异分析表
在编码器部分,四种无监督图神经网络都采用了图卷积神经网络GCN,图卷积神经网络的计算公式为
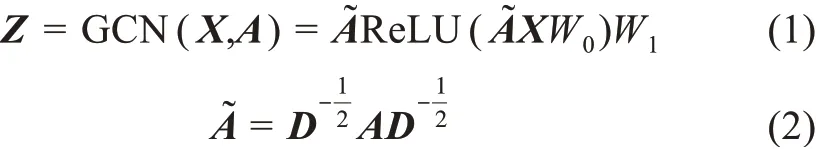
其中,GCN表示图卷积神经网络;D表示邻接矩阵A对应的度矩阵;ReLU为线性整流函数;W0和W1为图卷积神经网络待学习的参数。图自编码器通过1个图卷积神经网络GCN输出文献特征表示矩阵Z。变分图自编码器则和对抗正则化变分图自编码器用GCNμ(X,A)和GCNσ(X,A)输出文献特征表示矩阵Z,且GCNμ(X,A)和GCNσ(X,A)是W0相同、W1不同的两个图卷积神经网络,分别捕获文献特征表示的均值μ和文献特征表示的方差σ,且不仅生成文献特征表示矩阵Z,还通过标准正态分布N(z v|0,1)采样获得的先验表示矩阵深度互信息图神经网络则用图卷积神经网络编码随机扰动矩阵从而输出噪声特征表示矩阵在解码器部分,图自编码器、变分图自编码器和对抗正则化变分图自编码器都采用内积运算θ(ZZT)获取重构邻接矩阵其中,ZT表示Z的转置矩阵,θ表示Sigmoid函数。深度互信息图神经网络则通过矩阵运算θ(ZWs→T)和输出重构矩阵A′和其中,θ表示Sigmoid函数,W是一个大小为d×d可学习的参数矩阵,s→表示文献全局特征表示向量,具体计算公式为

其中,z v是文献特征表示矩阵Z的其中一行,代表文献v的特征表示向量,大小为1×d;表示向量的转置。注意,与前三种神经网络不同,深度互信息图神经网络解码器输出的重构矩阵时,不仅考虑了各个文献的特征表示,而且考虑了整体特征表示s→的信息。
在学习目标部分,四种图神经网络采用了不同的损失函数作为网络学习优化目标。涉及的损失函数有LCE交叉熵损失函数、KL相对熵损失函数和JS散度损失函数。交叉熵的计算公式为
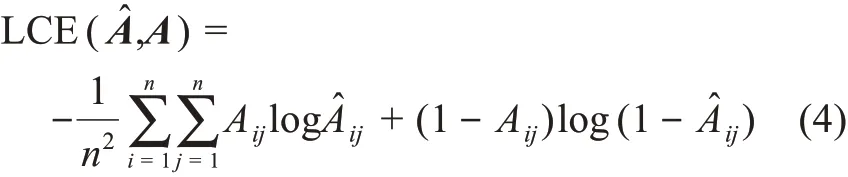
其中,n表示文献网络中论文数量;Aij为原始邻接矩阵A的第i行第j列;为重构邻接矩阵的第i行第j列;LCE(A^,A)实质上衡量了矩阵A和矩阵的差异。
KL相对熵的计算公式为
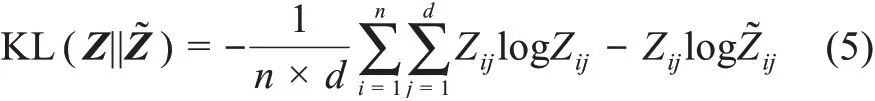

min||·||和max||·||分别表示最小化和最大化目标函数,因此,四种无监督图神经网络学习目标及含义分别为:
对抗正则化变分图自编码器中判别器D(Z)的计算公式为
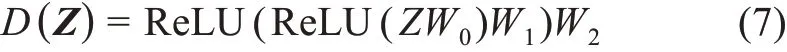
其中,D是一个三层的多层感知机,以文献特征表示矩阵Z为输入时,判别器可输出一个n×1的矩阵D(Z);W0、W1和W2为多层感知机中待学习的参数。同理,以先验表示矩阵为输入时,判别器也将输出一个n×1的矩阵
3.3 特征学习算法与过程
学术文献表示学习的根本目标是获得一个具有较强特征表达能力的文献特征表示矩阵Z。在基于无监督图神经网络的学术文献表示学习框架下,文献特征表示矩阵Z是由编码器输出而得,即f W(X,A)→Z,其中,f代表编码器中的图卷积神经网络,W表示图卷积神经网络中所有可学习的参数。算法1描述了学术文献特征表示矩阵Z的学习过程,学习到的文献表示向量zv可作为特征向量应用于下游任务;迭代次数T为250,特征维度d的取值范围为[32,64,128,256,512]。
算法1:基于无监督图神经网络的学术文献表示学习算法
输入:文献关系网络G=(X,A),训练的迭代次数T,特征维度大小d。
Step1.随机初始化编码器参数W;
Step2.编码器进行运算,输出文献特征表示矩阵Z;
Step4.根据学习目标计算损失函数;
Step5.采用随机梯度下降更新编码器参数W;
Step6.反复执行Step1~Step5T次;
Step7.输出Z作为最终学习到的文献特征表示矩阵,文献v的表示向量为zv∈Rd。
4 实验构建
4.1 任务场景设计
本文选择文献分类和论文推荐为下游任务场景,从而分析学习到的学术文献特征表示的有效性。具体而言,在文献分类任务中,实验执行以下4个步骤:①文献表示学习,将文献网络G=(X,A)输入无监督图神经网络获取文献特征表示Z;②数据集切分,将文献网络G中的所有文献切分为两个训练集Z1:v={z1,…,zv}和测试集Zv:n={zv+1,…,zn},样本比例分别为70%和30%;③分类模型训练,将训练集数据输入逻辑回归分类器训练分类模型;④评价指标计算,将训练好的分类模型运用到测试集上,获取MarcoF1(宏平均F1值)和MicroF1(微平均F1值)两个评价指标。
在论文推荐任务中,实验执行以下5个步骤:①文献表示学习,将学术文献网络G=(X,A)输入无监督图神经网络获取文献特征表示Z;②测试文献采样,从文献网络G中随机抽取30个文献,作为论文推荐任务的测试文献;③推荐列表获取,依次从文献特征表示矩阵Z中取出测试文献对应的特征向量z v,利用余弦相似度公式计算其与学术文献网络G中所有其他文献的相似性,并筛选相似性最大的前20篇文献为候选推荐列表;④相关性标注,两位标注专家查看测试文献和推荐列表候选文献标题和摘要的内容,判断测试文献与推荐列表中每个文献之间的相关性大小并进行打分,分值为1~5;⑤评价指标计算,在相关性标注的基础上计算Hit@K和Ndcg@K指标,K的取值为[5,10]。
4.2 数据集处理
基于无监督图神经网络的学术文献表示学习算法,必须执行在既包含文献网络关系又包含文献文本语义特征的数据集上,因此,本文以三个大小不同的学术文献网络数据集Cora、CiteSeer和DBLP(database systems and logic programming)为基础,针对文献分类和论文推荐两个任务进行预处理,从而构建了实验数据集。表2列举了处理后数据集的具体信息。
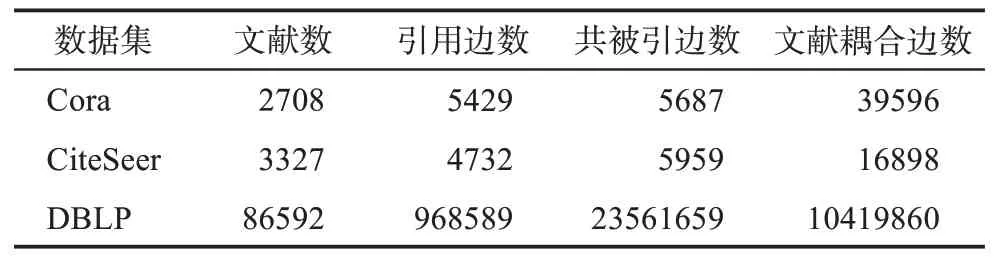
表2 三个学术文献数据集的具体信息
具体而言,Cora原始数据集共包含2708篇文献,每篇文献的文本特征为1433维的one-hot向量,文献引文网络的边数为5429。本文根据Cora原始引文网络抽取出共被引关系5687条和文献耦合关系39596条,从而构建了Cora数据集的共被引网络和文献耦合网络,且从此网站①https://people.cs.umass.edu/~mccallum/data/获取到Cora数据集中每篇文献对应的标题和摘要。CiteSeer原始数据集共包含3327篇文献,每篇文献的文本特征为3703维的one-hot向量,文献引文网络的边数为4732,共被引网络边5959条、文献耦合网络边16898条。本文从原始DBLP数据中随机采样出86592篇文献及其对应的引文关系968589条,共被引关系23561659条,文献耦合关系10419860条,每篇文献的文本语义特征向量通过Spacy中的Word2Vec模型获取②https://spacy.io/,文献的文本语义向量为文献标题中所有词的词向量的均值向量。。为了提升实验结论的可拓展性,本文对每个下游任务都采用两个数据集进行实验,具体信息如表3所示。

表3 任务数据集选择及其说明
4.3 实验组设置③https://scholarbank.nus.edu.sg/handle/10635/146027
为了回答在第1节中提出的三个研究问题,本文共设计了两组实验,相关设置如下。
实验组1:以三个数据集的文献引文网络为输入邻接矩阵,依次采用四种无监督神经网络,选择不同大小的特征维度d,执行文献分类和论文推荐任务获取评价指标,并以深度随机游走(Deep-Walk)[22]、Doc2Vec[29]、Paper2Vec[30]的结果作为对比基线。该实验组在固定文献网络结构的条件下,通过改变无监督图神经网络的结构和文献特征表示维度大小获取实验结果,以期回答问题1和问题2。
实验组2:以Cora数据集的引文网络、共被引网络、文献耦合网络为输入邻接矩阵,以固定的无监督图神经网络,通过贪心算法选择最优特征维度d,执行文献分类和论文推荐任务获取评价指标。该实验组在固定任务和确定无监督图神经网络模型的条件下,通过改变输入网络的结构获取实验结果,以期回答问题3。
5 实验结果分析
5.1 学习方法比较分析
表4 显示了三种基线方法和四种无监督图神经网络在Cora和CiteSeer两个数据集上执行文献分类实验的最优结果。由研究结果可知,在文献分类任务上,无监督图神经网络全面优于深度随机游走,表明在文献关系结构信息之上,融合文献文本语义信息能够有效提升文献特征表示能力。深度互信息图神经网络在两个数据集中均获得了最高评价指标,在Cora数据集上,宏平均F1和微平均F1值分别为0.808和0.820;在CiteSeer数据集上,宏平均F1和微平均F1值分别为0.657和0.692。变分图自编码器仅次于深度互信息图神经网络,在两个数据集的多项指标上均获得了较好的结果。图自编码器和对抗正则化变分图自编码器则表现相当,在不同数据集的不同指标上互有胜负。
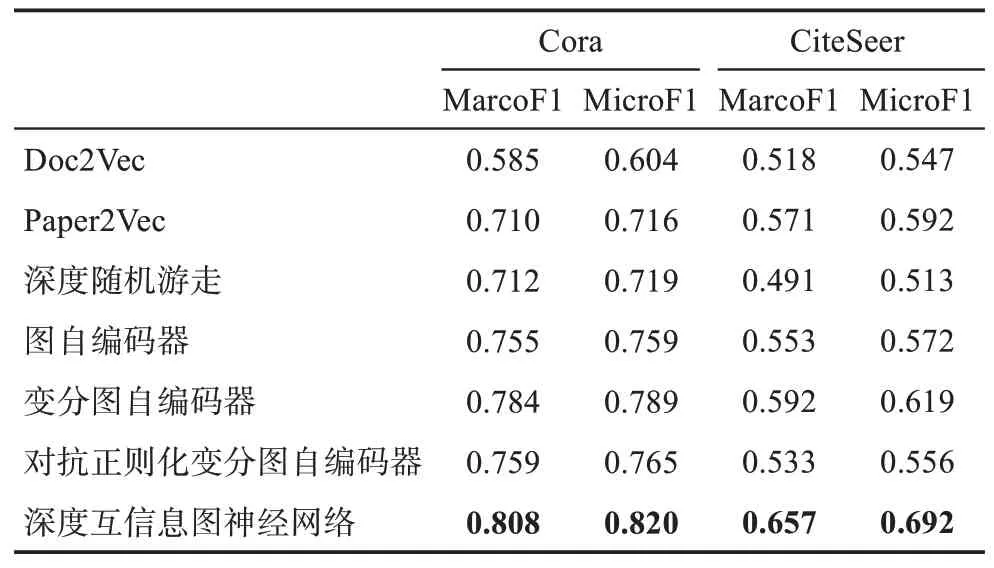
表4 三种基线方法和四种无监督图神经网络在文献分类任务上的最优结果
表5 显示了三种基线方法和四种无监督图神经网络在Cora和DBLP两个数据集上执行论文推荐实验的最优结果。在Cora数据集上,对抗正则化变分图自编码器表现最好,其Ndcg@5、Ndcg@10、Hit@5、Hit@10分别为0.596、0.646、0.571、0.660。在Hit@10指标上,深度互信息图神经网络的表现最优,而其他三个图神经网络则表现相当。在Ndcg@5和Ndcg@10指标上,对抗正则化变分图自编码器远高于其他三个神经网络,图自编码器则表现优于变分图自编码器和深度互信息图神经网络。在DBLP数据集上,对抗正则化变分图自编码器在Ndcg@5、Ndcg@10、Hit@5和Hit@10上都得分最高,其他三个神经网络表现则相差不大。尽管深度互信息图神经网络和对抗正则化变分图自编码器的Hit@5指标均为0.457,但是对抗正则化变分图自编码器的Ndcg@5得分为0.573,相比于深度互信息图神经网络提高了6.5%,这说明对抗正则化变分图自编码器能够将相关性更高的文献排在推荐列表顶部。
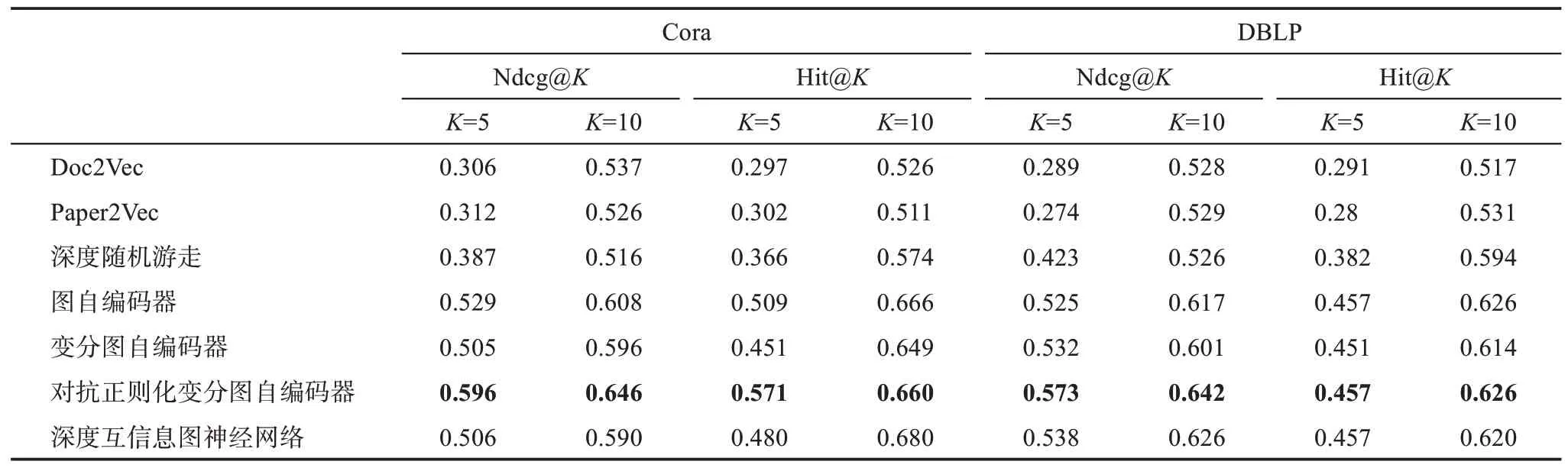
表5 三种基线方法和四种无监督图神经网络在论文推荐任务上的最优结果
上述实验结果表明,相较于其他图神经网络学习到的特征表示,深度互信息图神经网络学习到的文献特征表示具有更强的文献差异区分能力。这可能是由于深度互信息图神经网络学习的目标是最大化局部文献特征表示和全局文献特征表示的互信息,即学习到更能够表示每一篇文献独特性的特征向量,因此,其特别适合于文献分类这种下游任务。而其他三种图神经网络的学习目标均希望使得重构邻接矩阵和原始邻接矩阵的相接近,实质上是让文献网络中具有关联关系的文献具有更相近的特征表示向量。从这个角度来看,理论上图自编码器、变分图自编码器和对抗正则化变分图自编码器学习到的文献特征表示更适合于论文推荐任务。然而,在Cora和DBLP两个数据集上,深度互信息图神经网络表现并非最差,与图自编码器和变分图自编码器表现相当。本文认为,这可能与Cora和DBLP两个数据集包含的所有文献皆属于计算机领域有关。正是由于Cora和DBLP数据集中文献都属于同一领域,执行论文推荐任务时深度互信息图神经网络捕捉到的细节差异,有利于从主题领域相似的小文献集合中找到更相关的推荐文献。
5.2 特征维度影响分析
图1 显示了采用不同大小的特征维度d时,四种无监督图神经网络模型学习的文献特征表示在文献分类任务上的效果变化。由图1可知,对于深度互信息图神经网络而言,当特征维度增大时,文献分类各指标均呈现递增的趋势。而对另外三种无监督图神经网络来说,特征维度的增大反而使得文献分类各指标呈现波动或降低的趋势。理论上看,更大的特征维度能够存储更多的细节信息,从而使得学习到的文献特征能够刻画文献之间更细节的差异。正如第5.1节分析所述,深度互信息图神经网络通过最大化局部文献特征表示和全局文献特征表示的互信息,使得每篇文献自身独特的信息能够保留在学习到的文献特征表示向量中,因此,文献分类结果受益于更大的特征维度。然而,图自编码器、变分图自编码器和对抗正则化变分图自编码器的学习目标并不能更有效地区分不同文献之间的差异,只能让文献网络中相连接的文献具有更相似的表示向量,因此,分类任务上这三种图神经网络不能受益于更大的特征维度。
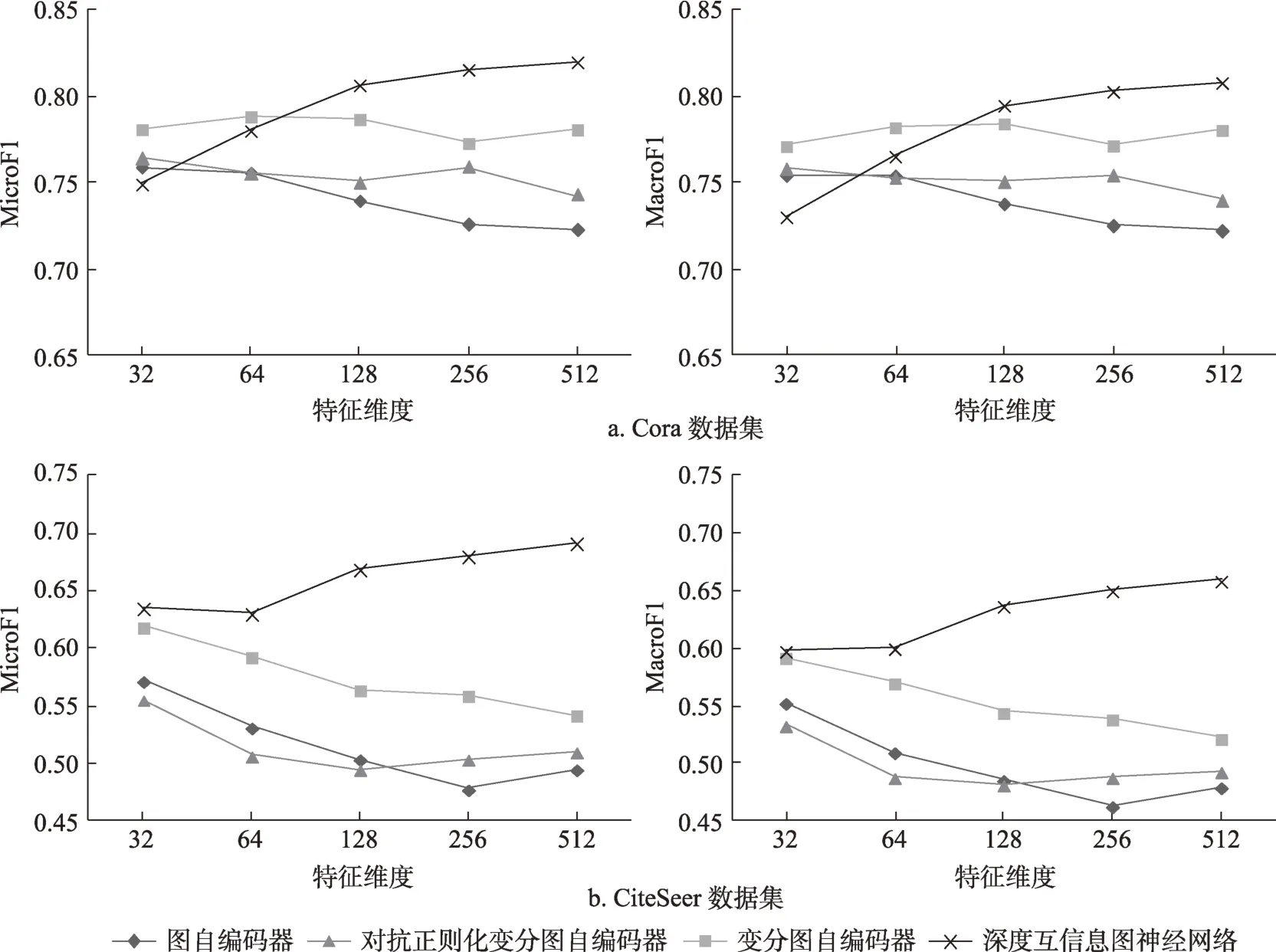
图1 特征维度变化对文献分类任务的影响
图2 显示了采用不同特征维度大小d时,四种无监督图神经网络模型学习的文献特征表示在论文推荐任务上的效果变化。在DBLP数据集上,深度互信息图神经网络各指标均呈现先增后减的趋势,且在d=128附近得到最大得分。图自编码器和变分图自编码器在各指标上呈现增减波动,没有稳定提高或降低的趋势。对抗正则化变分图自编码器各指标最小值均出现在d=64或d=128时且形成上凹抛弧线。在Cora数据集上,除图自编码器外的三种无监督图神经网络在d=32处已取得最优指标。深度互信息图神经网络各指标形成S形波动,其他三种图神经网络指标变化较平缓。总的来说,特征维度的增大不能够给论文推荐结果指标带来提升,本文认为,这代表四种无监督图神经网络的学习目标都无益于论文推荐任务。

图2 特征维度变化对论文推荐任务的影响
5.3 网络类型影响分析
由于CiteSeer数据集只提供了文献onehot文本特征,缺乏文献的原始文本数据,而DBLP数据集没有提供文献分类标签,故仅有Cora数据集可同时执行文献分类和论文推荐两个任务。图3中的每个子图都显示了同一个数据集下(Cora数据集),采用同一种无监督图神经网络时,以三种不同文献网络为输入而获得的6个任务指标(包括文献分类2个和论文推荐4个)的数值得分。由图3可知,无论是文献分类还是论文推荐任务场景,在其他条件相同时,相比于其他两个文献网络,引文网络似乎更适合学习文献的通用特征表示,并且文献耦合网络在绝大多数情况下比共被引网络更好。

图3 文献网络类型变化对文献分类和论文推荐指标的影响
为了进一步解释文献网络类型变化而导致文献分类任务效果的差异,本文统计了三种文献网络中不同类型边的数量,具体如表6所示。其中,同类文献节点间边的数量是指文献网络中边两侧的文献节点属于同一类别文献时边的总数,非同类文献节点间边的数量是指文献网络中边两侧的文献节点不属于同类别文献时边的总数。由表6可知,Cora数据集引文网络中一共有5429条边,其中连接同类文献节点的边的数量占81.4%,非同类文献节点的边的数量占18.6%。从引文网络构造共被引网络后,共被引网络中同类文献节点间边的数量占比下降到73.6%,非同类文献节点间边的数量占比上升到26.4%。这表明从引文网络构建共被引网络时,网络中不同类型文献节点间的联系(边的数量)密度增大,本来不属于同一类型的文献节点被连接起来,从而弱化了从网络中学习到的文献表示向量的类别区分能力。同理,在文献耦合网络中,同类文献节点间边的数量占75.8%,非同类文献节点间边的数量占24.2%,低于引文网络但略高于共被引网络,因此,其在文献分类任务上的效果排名第二(图3)。

表6 Cora数据集三种文献网络中边类型统计数据表
为了洞察文献网络类型导致论文推荐任务效果差异的原因,本文从Cora数据集中随机选择了3个文献节点,并人工统计了这些节点在不同类型文献网络中邻居节点相关性得分的平均值,结果如表7所示。由表7可知,对于同一个文献节点,其在引文网络中的邻居节点的相关性得分平均值高于其他两个文献网络。这表明相较于其他两个文献网络,引文网络中由边相连的节点之间可能具有更强的关联性,更利于图神经网络学习文献间的相似性,从而有利于论文的推荐任务。

表7 邻居节点相关性得分统计数据表
6 结 语
学术文献的表示学习是优化学术文献搜索、学术文献分类组织、学术文献个性化推荐等学术大数据服务的基础。本文将自编码器、变分图自编码器、对抗正则化变分图自编码器和深度互信息图神经网络这四种无监督图神经网络方法引入学术文献的表示学习研究,以文献分类和论文推荐为下游任务进行了相关实验。本文的主要贡献:①分析了四种无监督图神经网络的差异,提出了以“编码器-解码器-学习目标”为核心的、基于无监督图神经网络的文献表示学习框架(见表1),并梳理出四种图神经网络的矩阵表达形式;②通过实验发现深度互信息图神经网络的学习目标更适合于文献分类任务,而对抗正则化变分图自编码器更适合于论文推荐任务;③实验发现特征维度的增大能够有效提升深度互信息图神经网络的文献类别差异表征能力,而四种无监督图神经网络的学习目标似乎都无益于论文推荐任务;④Cora数据集上的实验表明,相较于共被引网络和文献耦合网络,引文网络更适合于学习通用的文献表示向量。
尽管本文选用了Cora、CiteSeer和DBLP等多个数据集进行了实验,然而这些数据集都仅只是从真实学术文献网络中抽样的部分数据。从理论上看,通过图神经网络学习文献的表示向量会受到文献邻居节点文献的影响,因此,采样部分文献数据可能会学习到有偏的文献表示,即文献最终的表示向量由采样到的邻居节点决定,而不是真实学术网络中所有邻居节点决定。未来将分析不同的采样策略如何影响文献表示学习和相应的下游任务指标,这是一个有趣且值得研究的问题。
