基于Simhash算法的文本查重系统的设计与实现
2022-01-20张晨阳段国云文春生
张晨阳 段国云 文春生
基于Simhash算法的文本查重系统的设计与实现
张晨阳a段国云b文春生a
(湖南科技学院 a.信息工程学院;b.信息与网络中心,湖南 永州 425199)
为解决文本数据的个性化查重问题,提出基于Simhash算法的文本查重的方法,设计并实现了系统原型。首先,阐述了文本相似度模型和计算算法;其次,根据需求规划设计了系统整体实现架构并详细描述其设计过程;再次,描述了查重算法和查重功能模块实现的详细流程;最后,对系统原型进行功能测试和算法相似度计算准确性测试。实验证明:在小规模文本文档样本中,系统能较好的实现文本相似度的计算和特征库的个性化定制,可集成并适用于小规模企业办公系统等平台的文本相似性查重环境。
Simhash算法;文本相似度;余弦相似度;文本查重;Flask框架
随着互联网、云计算等信息技术的高速发展,用户正在从数据的接受者向数据的制造者转变,远端数据存储容量呈爆炸式增长[1]。用户利用网络可在个人云盘、企业网盘、社交网等平台上发布视频、上传文档和图片等资料,用户在为互联网做出贡献的同时也制造了大量的冗余数据。相关研究表明,当前一些存储系统中的数据冗余量已达到60%[2],且呈现上升趋势。如何对文本进行原创性检测、对文本中内容进行相似度对比检测,成为文本检测领域亟需解决的重要问题。
近年来,研究者在文本检测领域取得了大量的研究成果,突出成果在工业界得到了应用和推广。其中Simhash算法成为近似文本检测领域的主流方法之一,文献[3]针对Simhash算法中近似文本指纹位数单一而丢失一定信息量的缺点,提出了基于多Simhash指纹和K维超曲面的近似文本检测方法。文献[4]从提升Simhash算法去重效果、提高准确率的角度出发,提出了基于信息熵加权的改正算法E-Simhash。文献[5]基于LDA(Latent Dirichlet Allocation,狄利克雷分布)和Doc2Vec模型提出HybridDL文本相似度检测算法,以便提高文本检测的准确度。文本查重算法被广泛应用于知网、百度网盘、阿里云盘等大型平台并融入到文本检测产品中。文本相似度检测技术虽然应用广泛,但市场上没有出现针对有保密要求、个人文档对比需求等特殊场景的文本检测工具。本文设计一款基于Simhash算法的文本相似度检测系统,该系统可以个性化定制内部文本查重库,以解决企业文件、原创性文档等特殊场景下用户文本检测的问题。
1 相关技术
1.1 文本相似度模型
判断两个文本内容是否重合其实质是对两个文本的相似性进行计算[6]。相似度为0则表明对比的两个文本完全不同,相似度为1则说明两个文本内容完全相同,其相似程度取值在[0,1]之间,通常采用百分率表示。如有文本文件M和参照文档N,其内容相似性定义为M、N之间相匹配元素变量的个数之和与M中所有元素个数的绝对比值,而Sim用于性能衡量,Sim越趋近于1说明两个文件越相似,sim越趋近于0则两个文本相似度极低。设向量集合是文件的元素集合,向量集合是文件的元素集合,是文件和元素集合之间匹配后的交集,文本文件的相似度模型如图1所示。

图1 文本相似度模型
1.2 余弦相似度算法
1)余弦相似度原理
余弦相似度是通过比较两个向量内积空间夹角余弦值的大小来对他们之间的相似度进行比较。当两个向量完全重合且方向相同时夹角余弦值为0,两个向量指向相反时其余弦相似度值为-1,余弦值的取值范围为[-1,1],其值的大小与向量指向的方向有关,而与向量长度无关[7-8]。但对文本而言,在比较过程中只考虑向量的方向而不考虑其规模的大小。向量夹角的取值通常小于90°,由此得知取值范围是[0,1]。因此,它可以用于任何维度向量的比较中,尤其在高维度向量空间的比较中应用更为广泛。当进行信息检索时,每个词条都拥有不同的权重,每一个文档由一个拥有权值的特征向量来表示,权值的大小取决于该词在文本中出现的频次大小,通过计算余弦相似度就可以给出两个文本在其内容上的相似度。
2)TF-IDF权重计算
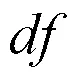
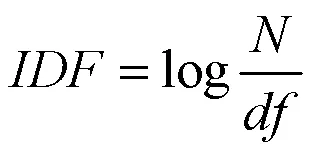
通过IDF值的计算,可做到少数罕见单词的值比较高,多数低频单词的值比较低。然后通过TF-IDF的计算公式TF-IDF = TF * IDF进行计算,对文档向量化后的每个词项分配一个权重,若不含这个词则权重值为0。
3)余弦相似度计算
基于余弦相似度计算的原理,文中将每个已经分好词和去停用字的文本进行文本向量化,分别记为向量D1和向量D2,并且将文本中每个词项的权重进行精确计算,由于每个文本的向量维度相同,因而比较这两个文档的相似性就是通过计算这两个词项向量之间夹角的 cos值来进行判断。相似度值的计算方法如公式(2)所示:

公式中分母代表的是每篇文档经TF处理后的向量模的乘积,分子代表的是经比较文档中TF后的两个向量的乘积,如果两个向量夹角的余弦值越趋向于1,则说明两个文档的相似度越高,反之越低。
2 系统设计
2.1 性能需求分析
本节以文本文件对比查重的性能优化为需求展开系统的设计和实现工作。设计初期充分调研现有的查重系统,分析其使用过程中所出现的问题,分析影响系统性能所面临的问题,结合优化设计目标按问题类型对其进行细分,带着提高系统性能的目标进行文本查重系统的设计。影响系统性能的要素有很多,在此选择提高结果精度和计算速度为设计目标,研究解决影响因素以提高系统的整体性能。系统性能优化设计出发点在于提高结果精确度和计算速度,结果精度将从文本查重的匹配度和相似度算法两个角度展开研究,计算速度将从文本的相似度算法的时间复杂度、返回文本数的设置和文本检索速度三个方面下手以提高整体性能。系统性能需求分析要点如图2所示:
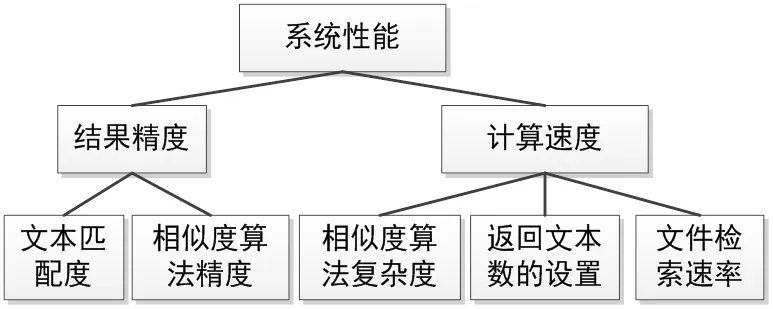
图2 系统性能需求分析
2.2 系统整体框架
文中系统采用B/S(Browser/Server,浏览器/服务器)结构进行设计,由用户端和管理端两个部分组成,以数据库为枢纽完成用户端和管理端数据的交互,设计两级权限管理体系实现不同用户、不同层级权限针对不同操作模块的精细化授权。普通用户端和管理端两个部分所设计的功能不同,用户端设计注册、登录、文本上传、查重和报告管理五个二级模块;管理端设计对比库管理、用户管理、文本库上传、统计分析、报告模板管理和系统管理六个模块;相似度和权重计算算法单独设计模块供查重模块调度使用;为方便管理,文本特征库通过管理端授权独立管理;系统数据的传输加密、存储加密由安全检测模块负责。系统功能模块划分及整体架构如图3所示:

图3 系统功能整体架构
普通用户在用户端经注册并审核通过后可登录系统,通过权限认证、系统装载后进入用户主界面进行权限内功能模块的操作,可上传查重目标文件、选择查重参照文本库后进行相似度计算,系统调用用户组指定的模板进行对比数据填充形成相似度检测报告,用户在报告管理模块对查重报告进行删除、管理并下载使用。管理员权限分超级管理员、审计管理员和普通管理员,超级管理员之外的管理用户ID均通过初始化超级管理员后进行分配,超级管理员可定制其他管理员的功能权限。管理员登录后,可以对文本特征库、查重报告模板进行增加、删除、修改、查询操作,可以针对某一特殊需求创建某一类型的文本特征库,文本特征可线下编辑并上传到新创建的特征文本库中以便系统对其进行初始化操作。
2.3 查重模块设计
采用余弦相似度算法对查重模块进行设计,工作时调用相似度算法和权重算法模块,其中Simhash算法的设计由文本分词、Hash计算、加权赋值、向量合并、降维五个步骤组成。首先,对于目标文档中的文本语句按选定对比库的特征进行分词,按1-5级划分得到其中有效的特征向量等级;如果特征向量是文本中的词且其值落在等级范围之内,那向量值就代表这个特征向量出现的次数,词的权重值与向量值相等。其次,通过Hash函数把文本中每个特征向量的Hash值计算出来,其中Hash值由0和1组成。再次,给拥有Hash值的特征向量进行加权,加权的计算方法为W=Hash*Weight,当遇到Hash值为1时,向量与权值正相乘,反之则与权值负相乘。然后,合并累加单个文本中所有特征向量的加权结果,形成一个序列串。最后,我们可以对权值进行降维,如果合并的累加结果大于0则置为1,反之置为0,从而可以得出文档文本的Simhash值。由此,根据文档中不同文本之间的海明距离(Hamming Distance)计算得到其相似度。
3 关键功能的实现
文中所设计的系统采用Python语言结合Flask框架和MongoDB数据库实现系统的开发,如下详细介绍相似度查重算法、用户查重流程两个关键功能的实现过程。
3.1 相似度查重算法
文本相似度主要采用Simhash算法、分词算法并结合海明距离计算进行实现。Simhash算法的主要思想是降维[10],将高维的特征向量映射成一个f-bit的指纹,通过比较两个文本f-bit指纹的海明距离来确定内容是否重复并计算出两者的相似度值。具体计算过程分为五步[11]:
1)基于传统的IR方法,将分词后的文本数据转换为由加权特征值构成的向量组。
2)初始化一个多维(定义为维)向量,其中每维的初始值为0。
3)针对文本特征向量集中的单个特征做签名计算。计算思路是将传统的Hash算法映射到一个f-bit的签名,如果签名的第维上为1,则对向量V中第维加上这个特征的权值,否则对向量的第i维减去该特征的权值。
4)对整个特征向量集合进行-bit迭代计算,由中每维向量符号确定生成-bit指纹值,如果第维为正数,则第维指纹为1,否则为0。
5)计算海明距离。通过将文本向量化后,如得到10101和00110两个比特数,通过海明距离计算算法对两个比特串进行计算得到其值为3。
通过上述五个步骤,由相似度查重算法模块计算文本之间的相似度,其实现过程中关键函数的代码如图4所示:
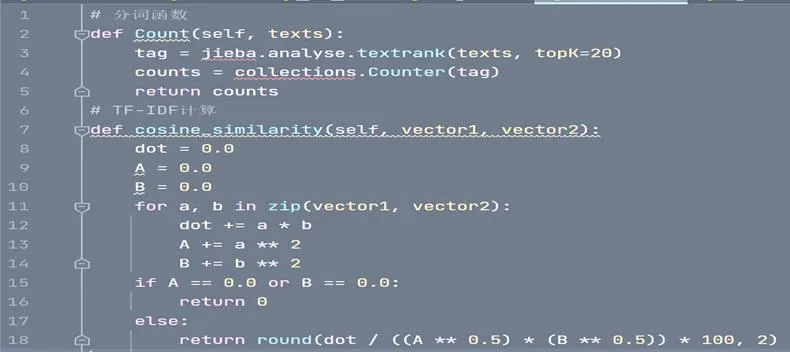
图4 相似度计算函数关键代码
针对文本分词进行测试,从0分词到利用海明距离对两个文本向量进行对比分析,通过关键代码进行测试。测试时创建3个txt文档,第一个文档内容为“基于Simhash算法的文本查重系统的设计与实现”,第二个文档内容为“基于Selenium的在线文本查重的设计与实现”,第三个文档添加前两个文档的全部内容,定义前两个文档为测试文档,第三个文档作为中文停词库。首先定义Simhash算法,利用jieba分词对两个文档进行分词操作,接下来是按照相对应的权重对分词后的词进行分词操作,然后设计文本对比函数,打开第三个文本,将前两个文本与第三个文本中的分词进行对比分析,最后可得出两个文本的文本相似度。文本查重效果如图5所示:
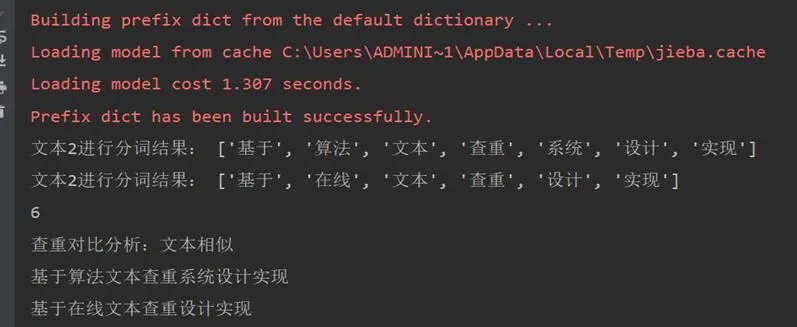
图5 文本查重实现测试
3.2 查重功能的实现
文本查重功能的实现流程是文中系统的核心工作,由文本上传、特征库选择、查重计算和报告生成四个流程协调完成。用户通过登录验证和权限鉴别后进入文本查重功能区,通过上传文本文件后选择特征库进行查重计算,通过调用相似度和权重计算算法完成目标文本与特征库内容相似度值的计算,最后将计算结果存入数据库,调用报告模板生成查重报告。其实现的流程如图6所示:
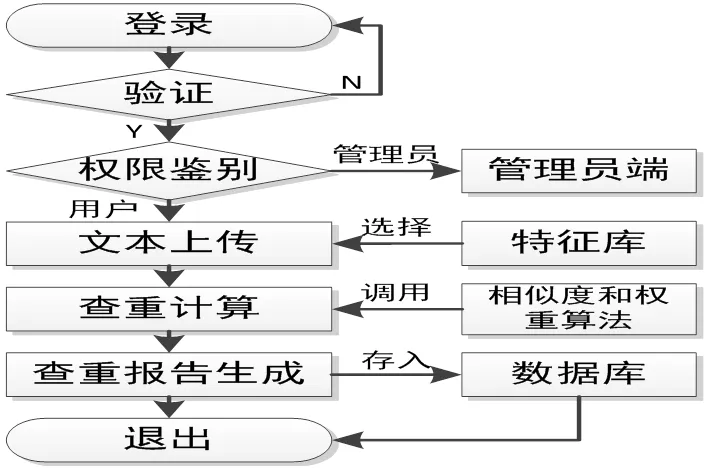
图6 文本查重实现流程
文本上传模块主要目标是为用户提供文本文件上传的入口,通过识别并转化文本编码后以指定的编码格式存入数据库中;查重时系统从库中读取与特征库相同编码的被测文本完成相似度计算,调用过程中如发现编码不同需采用转换函数对其进行转换。查重模块首先需对目标文本进行预处理,包括对文本进行分词、加权、权值、降维等操作,其次将处理后的目标文本内容与特征库文本逐次进行相似度检验,通过逐次对比后获取重复的部分,最后统计相似内容数量得出相似度值和相似内容后存放于数据库中,为查重报告的生成提供依据。文中系统以查询时间生成报告文件名,管理员根据特征库为用户配置报告模板供生成查重报告使用。
4 系统测试实验
4.1 实验环境
文中开发了系统原型,在实验室部署了测试环境,服务器硬件为单路Intel(R) Xeon(R) E5-2683 V4 CPU,提供2.1GHz的频率和32个线程,配64G ECC内核;网络环境采用RG-S2910-24GT4XS-E二层交换机连接服务器和测试笔记本;操作系统是Windows Server 2016,数据库系统选用MongoDB 4.4.6,采用Python3.7作为解释器并安装好所需的依赖包,选用Flask 2.02作为Web服务框架,在Pycharm中运行原型系统提供测试服务。
4.2 查重功能测试
系统主要针对企业内部文件查重和个人重复文本对比的个性化需求应用场景,实验过程中没有知网、万方、Paperyy等论文查重平台对比特征库,无法完成此类大型平台的对比。本文通过上传50篇技术文档构建一个文本特征库,每个文本文档限定为1000字50个句子;再从50篇文档中任意抽1个、5个、10个句子构建测试用例,通过普通用户端权限上传目标文档并选择文本特征库对其进行测试。测试结果表明文中系统能够计算目标文档重复文字相似率、能按系统设计的文字颜色将其中重复的文字较好地标记出来、能根据模板和计算结果生成查重报告,实现了系统设计的功能。
4.3 查重性能测试
性能实验主要针对文中系统文本查重相似度计算的准确率展开测试,测试算法在检测过程中分词、对比等性能的稳定性。实验中构建10个特征库从管理端上传到系统中,再构建10个目标测试文本文件,目标文件从特征库文本数据中取一定比例的重复内容,比例控制分别与对应测试库的相似率从0%到100%按10%递增。将测试目标文件从用户端上传并选择对应的特征库进行测试,每个目标测试文件测5次,取相似度数据的平均值后再与制定的重复比例对比,计算测试的准确率。测试结果表明文中系统能较精确的计算目标文档重复文字相似率,算法测试的平均准确率在99.7%以上,当文本相似度越高时查重相似率计算的准确度越高,反映出相似度算法计算的稳定性。
5 结 语
本文基于Simhash算法开发了可自定义特征库的文本查重系统原型。通过对被测目标文本进行分词、Hash、加权、合并、降维等系列操作后,再使用海明距离与特征库文本进行相似度对比,完成文本的相似度检测。经功能和性能实验测试,所开发的系统能较好的完成系统的设计目标,算法有较好的稳定性。系统适用于个性化定制需求,可用于文本对比、日志文本数据处理分析等应用场景,但离大规模企业应用还有一定的距离。
[1]Chen T.Analysis of computer data processing mode based on big data era[J]. Agro Food Industry Hi-tech, 2017, 28(1): 828-831.
[2]Clements A T,Ahmad I,Vilayannur M,et al. Decentralized deduplication in SAN cluster file systems[C]// Usenix Technical Conference, 2009.
[3]董博,郑庆华,宋凯磊,田锋,马瑞.基于多SimHash指纹的近似文本检测[J].小型微型计算机系统,2011,32(11):2152- 2157.
[4]张航,盛志伟,张仕斌,等. Simhash算法在文本去重中的应用[J]. 计算机工程与应用,2020,56(11): 246-251.
[5]肖晗,毛雪松,朱泽德. 基于HybridDL模型的文本相似度检测方法[J].电子技术应用,2020,46(06):28-31+35.
[6]王寒茹,张仰森.文本相似度计算研究进展综述[J].北京信息科技大学学报(自然科学版),2019,34(01):68-74.
[7]严李强,田博,梁炜恒,杨欢欢.藏文文本相似度计算方法研究[J].高原科学研究,2021,5(03):70-77+114.
[8]吕烨鑫. 基于Android恶意行为分析的移动终端取证研究[D].哈尔滨工程大学,2017.
[9]甘秋云.基于TF-IDF向量空间模型文本相似度算法的分析[J].池州学院学报,2018,32(03):41-43.
[10]Charikar M S. Similarity estimation techniques from rounding algorithms[C]//Proceedings of the thiry-fourth annual ACM symposium on Theory of computing. 2002: 380-388.
[11]张云.海量Android应用相似性检测方法研究[D].湘潭大学,2017.
TP391.1
A
1673-2219(2021)05-0051-04
2021-05-26
永州市科技计划项目资助(永科发[2014]17号);湖南省教育厅科学研究重点项目资助(20A212);湖南科技学院应用特色学科建设项目资助。
张晨阳(1998-),男,河南驻马店人,湖南科技学院2017级计算机科学与技术专业本科学生,研究方向为日志分析;
段国云(1982-),男,湖南永州人,博士生,副教授,研究方向为系统安全、隐私保护。
(责任编校:文春生)
