基于特征分离的跨域自适应学习模型
2022-01-19李哲民魏居辉杨雅婷王红霞
李 鑫 李哲民 魏居辉 杨雅婷 王红霞
(国防科技大学文理学院 长沙 410073)
目前,绝大部分机器学习任务都需要假设数据满足独立同分布这一条件,但在语音语义、工业视觉检测、自动驾驶等诸多机器学习的应用场景中,传感器采集到的数据可能不满足独立同分布的假设,而是来自多个不同的分布(域).例如,手写数字识别中采集的数字可能来自多种不同的书写风格,或是字体大小、颜色等在不同的环境中具有不同的分布.此时,在监督学习过程中,模型会学习到书写风格、颜色等特征,由于这些特征与标签的相关性在不同环境下发生了变化,且不是识别手写数字的主要依据,因此称之为虚假特征.而手写数字的形状特征在各个域中是独立同分布的,也即在不同环境中与标签的相关性保持不变,因此称之为真实特征,其直观解释如图1所示:

Fig. 1 Intuitive interpretation of true and false features
跨域训练任务的训练集数据按不同的域分类给出,且可根据是否知道测试集所属域信息分为跨域泛化和跨域适应2个问题.当面对一个未知的测试环境时,其虚假特征的分布可能发生重大偏差,因此更倾向于使用真实特征对未知域进行预测,我们称此类问题为跨域泛化问题.另一方面,当预先知道待预测数据来自某个域时,更倾向于综合利用真实特征和虚假特征对目标进行预测,特别地,当收集到的新域数据量较少时,需要结合训练域中的足量数据共同训练出更好的识别模型,我们称此类问题为跨域适应问题.研究跨域任务具有很高的实用价值,例如,根据针对的发音人,语音识别技术可以分为特定人语音识别和非特定人语音识别,前者只需识别1个或几个人的发音,而后者则可以被任何人使用.由于不同发音人的所属地区、年龄、性别等差异可将采集的训练数据分为不同的域,此时训练语音识别模型可视为一个跨域训练任务.对于非特定人的语音识别,就必须提取到语音数据的真实特征,这对应于本项目研究的跨域泛化问题.而对于特定人的语音识别,我们希望能够综合利用真实特征和虚假特征实现更准确的预测.特别地,当采集到的特定人的语音数据较少时,我们希望可以从训练域中事先提取到真实特征和虚假特征,只需通过少量的特定人数据综合利用这些特征,就可以达到更好的识别效果,这对应于本项目研究的跨域适应问题.
本文旨在为上述跨域适应问题提供一种解决思路,其核心就是要分离并综合利用真实特征和虚假特征.由于该问题是最新提出的问题,因此还鲜有文献对其进行详细讨论,通常直接利用经验风险最小化[1]方法进行训练.而分离特征的关键在于稳定地提取真实特征,这又对应于上述跨域泛化问题,因此我们仍需要详细讨论并改进已有的关于跨域泛化问题的方法,进一步嵌入到本文新设计的模型中,可以在跨域任务中取得高效预测.
传统的机器学习方法通过最大程度地减少训练误差来学习复杂的预测规则,但数据常会有选择偏见,一些混杂因素和虚假特征会损害输入数据[2-5],导致模型学到一些虚假的特征[6-8].为了只提取真实特征,目前主要有2种研究思路:一种思路是提升分类模型的鲁棒性[9-12],Engstrom等人[13]指出简单的平移或旋转变换足以蒙骗基于神经网络的视觉模型,需要设计鲁棒的分类模型.后来Jacobsen等人[14]发现神经网络可能对任务无关的输入变化过于敏感,而通过对抗训练提升模型鲁棒性的方法会限制与任务相关的输入.Arpit等人[15-16]从熵的角度出发通过剔除低相关性特征,增强了预测模型的鲁棒性.尽管文献[9-16]的研究较好地增强了模型的鲁棒性,但在部分训练环境中,虚假特征的相关性甚至高于真实特征的相关性,此时这些方法仍会失效.而另一种研究思路发展于Arjovsky等人[17]提出的不变风险最小化,该文认为不稳定特征与标签之间具有虚假相关性,且这种相关性的大小会因环境的不同而发生变化,而稳定特征Φ(x)具有不变性,也即基于稳定特征对标签Y的预测概率P(Y|Φ(x))在不同环境下都相同,且认为这种不变性特征与标签之间具有因果关系[18-20].基于这一思想,提出了用于跨域泛化任务的不变风险最小化(invariant risk minimization, IRM)模型,通过增加了跨域不变性的惩罚项,使得模型能从不同训练域中学习到稳定特征.基于这个结果,Ahuja等人[21]将IRM问题转化为博弈论问题,给出了一种求解新思路.Krueger等人[22]提出了MM-REx和V-REx这2种训练风险函数,使得跨域泛化的准确率得到进一步提升,从而更好地提取稳定特征.
尽管基于IRM的4种方法已经在分离真实特征方面取得了不错的效果,但仍存在一些不足:
1) 各种方法的惩罚项在形式上差异明显,如何解释和评价这些不变惩罚项,以及如何设计合适的不变惩罚项还需要进一步讨论;
2) 这些方法无法预先选择最佳的训练轮数,训练易过拟合.实验表明随着训练轮数的增加,训练准确率会继续增加(上界由训练环境中的标签与虚假特征的相关性大小决定),但测试准确率会先增加后减小,这表明随着训练轮数的增加模型绕过了不变性惩罚学习到虚假特征.
针对上述问题,本文在充分讨论跨域泛化问题的基础上,设计了一种更加稳定风险损失函数,在此基础上,构建了一个基于特征分离的跨域自适应学习模型,很好地解决了跨域适应问题.具体有3方面贡献:
1) 提取真实特征的关键在于设计合适的训练风险函数,我们发现总体预测风险中引入不变性惩罚应与虚假特征在不同环境下和标签的相关性差异有本质联系.基于这一思路,比较了各种分布差异惩罚的优劣,并根据准确率差异设计了一种新的不变性惩罚.
2) 基于上述不变性惩罚提出了一种新的风险损失函数ADR(accuracy difference risk),该风险函数不仅可以更好地提取真实特征,而且有效地避免了IRM等方法容易过拟合的缺点,因此,该风险函数便于嵌入应用到后续模型中,更具实用价值.
3) 基于ADR风险函数,我们构建一个可以综合利用稳定特征和不稳定特征的自适应学习模型CDGA(cross-domain generalization and adaptation model).该模型分为数据特征表达和分类器2部分,通过设计的训练方法训练后,该模型不仅可以提升了解决跨域泛化问题的效果,还充分利用训练域的足量数据和新域的少量数据很好地解决跨域适应问题.
1 背 景
1.1 跨域泛化任务
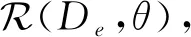
1) 经验风险最小化[1](ERM).设环境e中的误差风险为
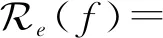
(1)
(2)
2) 鲁棒性优化[10](ROB).在鲁棒性优化中,需要最小化风险函数:
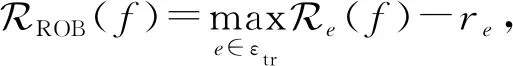
(3)
其中,re为环境基准,当设定re=0时,也就是最小化误差最大的环境误差.选择这个基准是为了去除环境噪声对学习的影响.
3) 不变风险最小化[17](IRM).Arjovsky等人[17]最新提出了一种不变风险最小化的方法,将预测模型f分成2个部分f=ω∘Φ,其中Φ:X→H为数据特征表达,ω:H→Y为分类器.并提出当分类器ω可以使得所有环境中的预测风险一致达到最小时,则认为预测模型用的是不变特征进行预测的,而这种不变的特征正是在跨域泛化问题中需要提取的真实特征.该方法的数学表示为
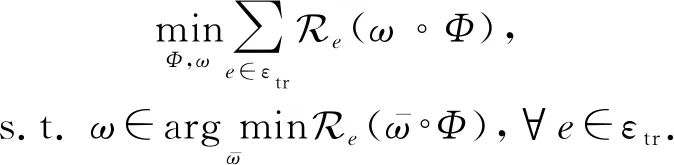
(4)
这是一个很有挑战的2级多目标优化问题,因此作者进一步将其简化为一种可操作的版本IRMv1,转化成一个2级单目标优化问题,即要最小化风险函数:
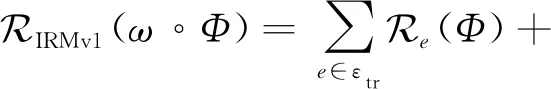
(5)

4) 最小化最大风险(MM-REx)和风险方差最小化[22](V-REx).Krueger等人[22]基于各环境中的预测风险,分别提出了最小化最大风险和风险方差最小化2种风险函数.MM-REx方法考虑将最大环境风险与其他环境风险加上权重,以增加不同环境风险的相似性:

(6)
其中,m为训练环境数量,超参数β为平衡参数.而V-REx方法可以进一步增强不同环境风险的相似性,以它们之间的方差作为惩罚项加入到风险函数中:
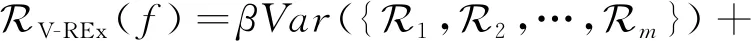
(7)
该方法通过控制不同环境中输出风险的差异,使得模型学习训练数据中的真实特征.
这4种方法在风险函数中引入了不同的不变性惩罚项,从而学习了原始数据的真实特征.但为了更好地嵌入到后续提出的CDGA模型中,我们需要对式(5)~(7)中的风险函数进一步优化,在跨域泛化任务中的测试准确率和训练稳定性这2个方面达到更好的效果.
1.2 跨域适应任务
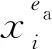
针对此问题,我们在改进分离真实特征中训练风险函数的基础上构建了一个解决跨域任务的CDGA模型,可以很好地分离出并综合利用真实特征和虚假特征,在跨域泛化和跨域适应问题中均取得了很好的效果.
2 基于ADR风险分离真实特征
本文的最终目标是构建一个能够综合利用真实特征和虚假特征的学习训练模型,在跨域泛化和跨域适应问题上都具有很好的效果.而该模型的核心在于如何更好地学习不同环境数据中的真实特征,因此本节先详细讨论了学习跨域稳定特征的关键是在总体预测风险中引入不变性惩罚,并提出该惩罚项与模型预测分布的差异有本质联系.进一步,通过比较了各种分布差异惩罚的优劣,基于准确率差异设计了一个更好的不变性惩罚,从而提出ADR风险函数,在分离真实特征中取得很好的效果,提升了跨域泛化能力.
2.1 多种分布差异作为不变性惩罚项
跨域泛化问题的核心是提取不同环境下训练数据的真实特征.如果模型提取了真实特征,对于同一标签的预测结果,预测为各类别的概率近似相同,也即P(Y|Φ(x))在不同环境中都相同,因此其在不同环境下对相同标签数据的预测分布应近似相同,大多数文献都基于此将构建的不变性惩罚项加入到总体训练风险函数之中,从而提取真实特征.Arjovsky等人[17]提出了不变风险最小化方法,预测模型分为数据表达Φ和分类器ω这2个部分,训练目标是优化ω和Φ的参数使得所有环境中的预测风险达到一致最小,其风险函数由式(5)给出.Krueger等人[20]提出了最大风险最小化和风险方差最小化2种方法,训练目标是优化不同环境中预测风险的差异达到最小,风险函数分别由式(6)(7)给出.以上3种方法是目前提取真实特征效果较好的方法,从本质上而言,各种风险函数都专注于刻画不同环境下模型预测分布差异.如果学习到真实特征进行预测,那么其在不同环境下的预测结果应当具有类似的分布,与之相反,当学习到虚假特征时,模型在不同环境下预测结果的分布会产生较大差异.为此基于4.1节所构造的Colored MNIST数据集考察了不同的风险函数下模型训练输出的分布,其平均预测准确率见表1,预测分布情况如图2所示.
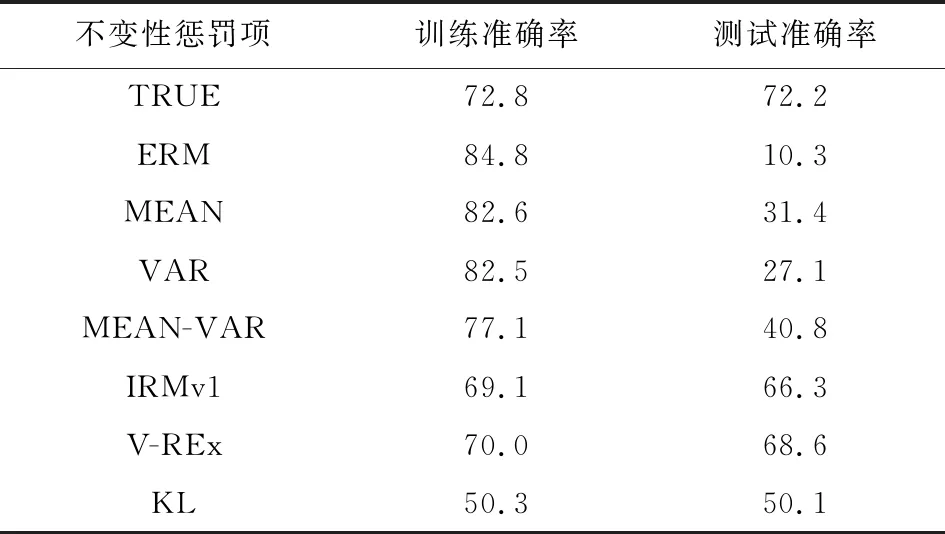
Table 1 Average Accuracy of the Model Under Different Penalty Items
首先,训练之前人为去除训练集的颜色特征(4.1节中构造的Colored MNIST数据集仅有颜色这一个虚假特征),此时模型只能学习到真实特征,因此期望的训练结果是训练和测试准确率均超过了72%,其在不同环境中的预测分布见图2(a1)(a2);随后,引入颜色特征,并考察多种方法的预测效果.
1) 不采用任何不变性惩罚时的预测分布见图2(b1)(b2)(即ERM方法),此时模型学习了虚假特征进行预测,训练准确率达到84.8%,但由于虚假特征在测试集中与标签的相关性发生较大变化,测试准确率仅有10.3%,该方法失效.
2) 采用分布均值差异作为不变性惩罚项的预测分布见图2(c1)(c2)(即MEAN方法),该方法惩罚了不同环境下预测分布均值的差异.此时,训练准确率为82.6%,测试准确率上升为31.4%,可见该惩罚一定程度上增强了对真实特征的学习,但并不严格,仍能学习到很多虚假特征.
3) 采用分布方差差异作为不变性惩罚项的预测分布见图2(d1)(d2)(即VAR方法),采用分布均值差异和分布方差差异相结合的方式见图2(e1)(e2),此时预测分布差异得到更细致的刻画,测试准确率上升到40.8%,可见进一步严格预测分布惩罚可以学习到更多稳定特征.
4) 采用IRMv1作为不变性惩罚项的预测分布见图2(f1)(f2),该方法考虑到在不同环境下的预测结果分布应当是平移不变的,更加严格地限制了分布的差异,其测试准确率提升到66.3%.
5) 采用V-REx作为不变性惩罚项的预测分布见图2(g1)(g2),该方法惩罚了不同训练环境下预测误差的方差,适当放宽了IRMv1对分布差异的限制,训练准确率可进一步提升到68.6%.
6) 采用更严格的KL散度作为不变性惩罚项的预测分布见图2(h1)(h2),KL散度从信息的角度表征了分布之间的差异大小.此时,模型更倾向于在不同环境下作出更一致的预测结果,而随机的预测结果比任何一种预测都更能缩减其中的差异,从而导致模型无法学习到任何有用的特征.
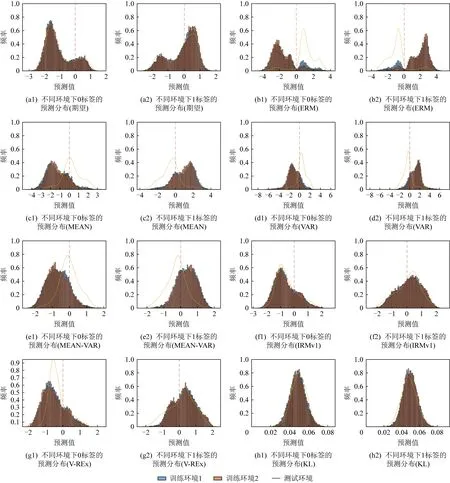
Fig. 2 Distribution map of label prediction under different methods
通过分析不同方法下的不变性惩罚项,发现其本质在于刻画模型在不同环境下的预测分布差异.但需要注意是,若严格限制不同环境下的预测结果的分布,会导致分类器更倾向于一个随机的预测结果,而不对任何特征进行学习,为此,需要在模型的准确性和模型的泛化能力之间作出取舍,折中设计一种更好的不变性惩罚.
2.2 ADR训练风险函数
在设计风险函数时,要尽可能地惩罚虚假特征,且保留真实特征.为实现这2个目的,我们从2个方面考虑:1)要在学习真实特征的基础上,尽可能多地惩罚虚假特征的影响.因此,我们在设计风险惩罚函数时,要能充分反映虚假特征的影响,也即,当模型学习到虚假特征进行预测时,风险函数会明显增大.2)要在惩罚虚假特征的基础上,尽可能多地保留真实特征.为此,我们需要放宽对预测分布的一致性约束.主要有2个原因:1)不同训练环境中的样本的随机性和数据量的有限性,造成了真实特征在不同环境下与标签的相关性产生差异;2)在一些实际系统中,真正决定样本分类的特征与虚假特征不具有明显的界限(如手写数字的形状特征和书写风格这一虚假特征),因此,虚假特征在不同环境下与标签的相关性差异会一定程度上影响了真实特征在不同环境下与标签的相关性.所以,我们在惩罚虚假特征的同时,也要保护形状特征不被明显“过滤掉”.基于此分析,我们基于预测准确率差异设计了一种非参数估计的惩罚项,有效权衡了“惩罚虚假特征”和“保留真实特征”两个目标,在此基础上设计了ADR训练风险函数.
ADR风险函数的设计基于思想为:当模型进行学习时,会同时学习到真实特征和虚假特征,从而在不同环境下作出不一致的预测,而在这些不一致的预测中,那些预测错误的结果是由虚假特征主导的,这是因为不同环境下虚假特征与目标的相关性会发生改变,因此我们更加关注不同环境下分类错误部分的差异并施以惩罚.因此,构建了ADR训练风险函数:
(8)
其中,labels表示分类标签集合,Nei(f)表示环境e下的i标签被分类错误的数目,μ为调节超参数.

3 构建跨域任务中的CDGA模型
我们在第2节详细讨论了如何分离提取出训练数据中的真实特征,该特征可以对跨域泛化问题作出稳定的预测.事实上,在学习过程中引入了预测分布差异惩罚项后,数据表达Φ将自动地过滤掉虚假特征,而仅保留真实特征.但当已知数据来自哪个域时,应当更倾向于综合利用真实特征和虚假特征共同预测,基于此,本文建立了可以同时处理跨域泛化和跨域适应问题CDGA模型.
3.1 原理描述
d(D(Φs(xe1)),D(Φs(xe2)),…,D(Φs(xem))),
(9)
其中,D(·)为数据的分布,在后文的CDGA模型中采用式(8)所示的ADR风险函数.从而,通过训练可以使得Φs在保证训练准确率的基础上满足:
D(Φs(xep))≈D(Φs(xeq)),∀ep,eq∈εtr,
(10)


算法1.CDGA模型参数训练算法.
输入:训练数据De(e∈εtr)、少量新域数据Dea;
输出:预测模型ωs∘Φ,ωa∘Φ以及ωe∘Φ,e∈εtr.
① forstep=1 toNφdo
② fork=1 toNωdo
③ forj=1 tomdo
④logitj=ωej∘Φ(xej);
⑤lossj=(logitj-yej);
⑥lossj反向传播更新参数λej;
⑦ end for
⑧logita=ωa∘Φ(xea);
⑨lossa=(logita-yea) ;
⑩lossa反向传播更新参数λea;
D(Φs(xe2)),…,D(Φs(xem)));
/*step小于阈值Γω,μ取较小值*/
μ(D(Φs(xe1)),D(Φs(xe2)),…,
D(Φs(xem)));
/*step小于阈值ΓΦ,μ取较小值*/
算法1便是CDGA模型的学习过程,通过交替学习分类器和数据表达,最终学习出可分离特征的数据表达Φ,以及与环境适应的分类器ω.当只有2个训练环境时,训练过程示意图如图3所示:
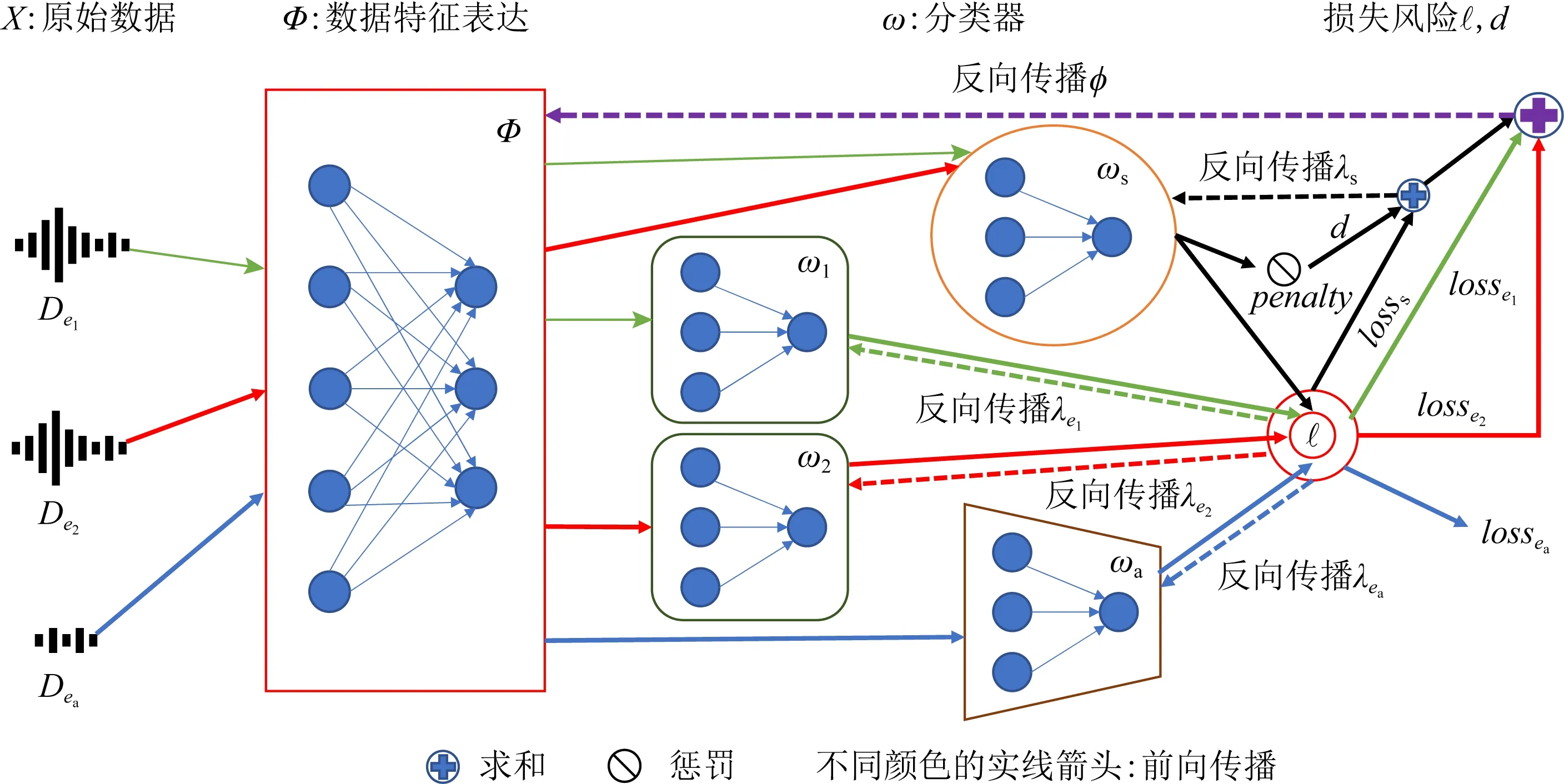
Fig. 3 Schematic diagram of CDGA model training in two training environments
如图4所示,对于跨域泛化任务,我们可以用返回的模型ωs∘Φ进行预测.对于跨域适应任务,若待预测数据来自训练环境ej,则用模型ωej∘Φ进行预测,若待预测数据来自新环境ea,则用模型ωa∘Φ进行预测.因此,该模型可以同时实现跨域泛化和跨域适应2项任务.
3.2 CDGA模型的可行性分析
对于分类器ω,每次迭代我们都会学习出适应各训练环境的最优分类器ωe,e∈εtr和不变预测分类器ωs,它们可以对Φ表达的真实特征和虚假特征进行加权结合,从而使得预测模型更加适应特定环境进行预测.对于未知域的待预测数据,我们可直接采用不变预测分类器ωs和Φ进行预测,也即使用真实特征进行预测,可以保证预测效果.
综上,通过交替训练各环境下的分类器和数据表达,我们可以分离真实特征和虚假特征,从而在跨域任务中实现高效预测.
4 实 验
4.1 实验设定
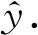

(11)
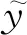
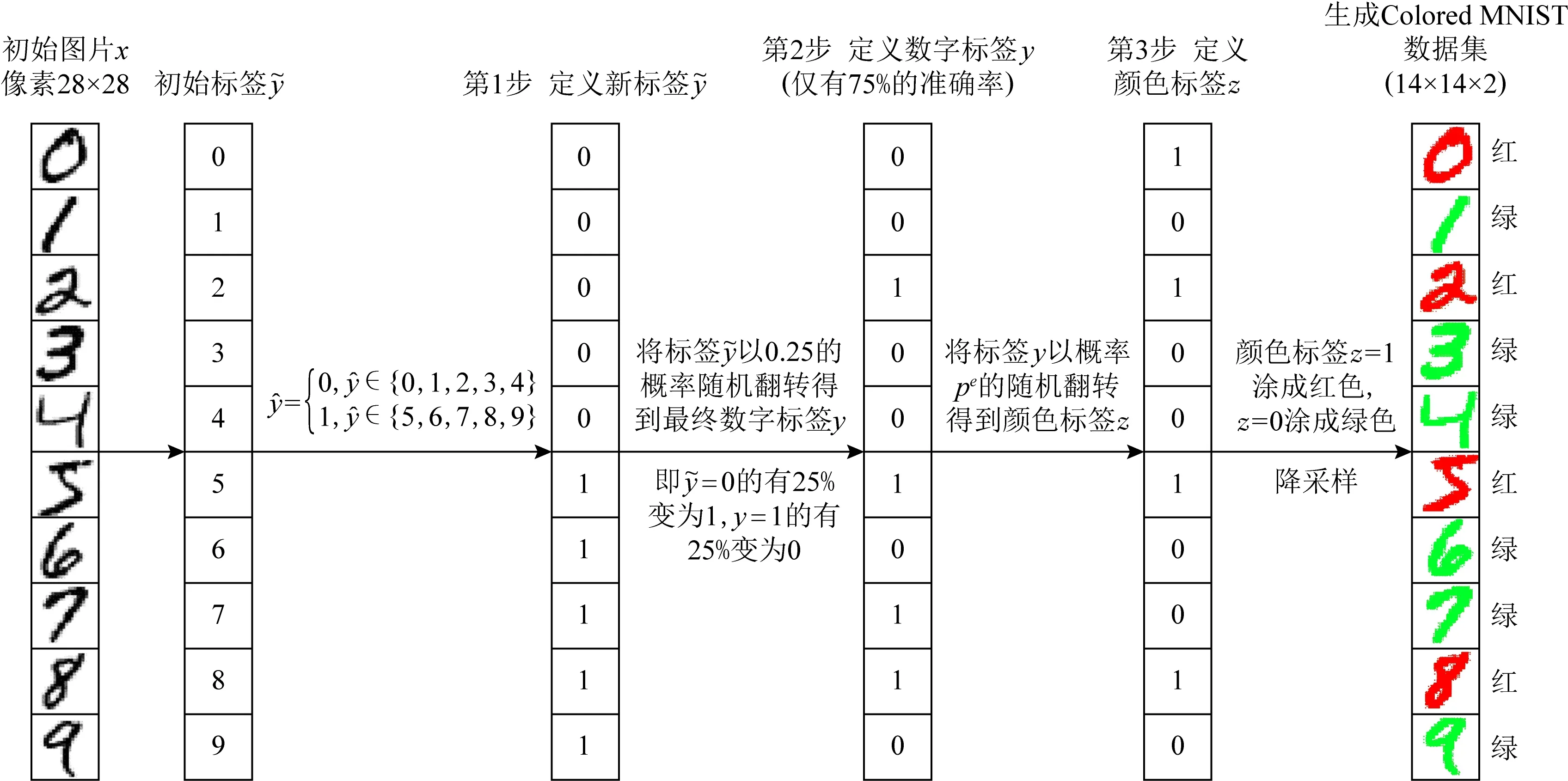
Fig. 5 Flow chart of constructing Colored MNIST data set
4.2 基于ADR风险函数提取真实特征
当模型学习到样本中的真实特征时,其能够在不同域中均具有不错的表现.为了验证本文提出的ADR模型能够较好地提取样本的稳定特征,我们取pe=0.1,0.2分别生成25 000张图像作为2个训练环境,以pe=0.9生成10 000张图像作为测试环境.当采用ADR风险函数训练模型,模型的预测结果数据分布情况如图6所示.可以发现相比较于其他方法,其在错误预测上具备更稳定的分布特征,由此削弱了模型对虚假特征的学习程度,可以更好地学习真实特征进行模型预测.
然后,我们将采用ADR风险函数的实验结果与经验风险最小化模型(ERM)、不变风险最小化模型(IRMv1)、鲁棒性优化模型(Rob)和风险方差模型(V-REx)进行了对比.每种方法进行20次训练实验,每次训练2 000轮.选取模型在测试集上的准确率作为模型优劣的度量指标.实验结果如图7和图8所示,图中的各种线表示不同方法下20次实验的准确率均值,阴影区域表示20次实验结果的包络区域.图7展示了不同方法在训练环境中的准确率随训练轮数的变化情况.我们可以看出ERM方法和Rob方法的训练准确率超过90%,可见模型充分学习了颜色特征.而其他3种方法的训练准确率均在70%左右,有效地抑制了对颜色特征的学习.而图8展示了模型在pe=0.9的测试环境中的准确率随训练轮数的变化情况,我们提出的方法的平均测试准确率为69.0%±1.8%,具有最高的测试准确率.另外,随着训练轮数的增加,其他方法的测试准确率逐渐开始下降,而我们的方法保持不变,这就避免了因迭代轮数选择过大而影响训练效果,有效地克服了其他方法容易过拟合学习到颜色特征的缺点,解决了测试准确率因迭代轮数增加而明显降低的问题.因此,ADR方法可以稳定地提取真实特征,可很好地嵌入到我们的CDGA模型中.
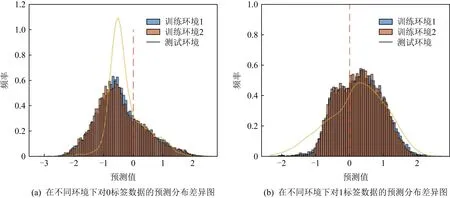
Fig. 6 The label prediction distribution map using the ADR risk function
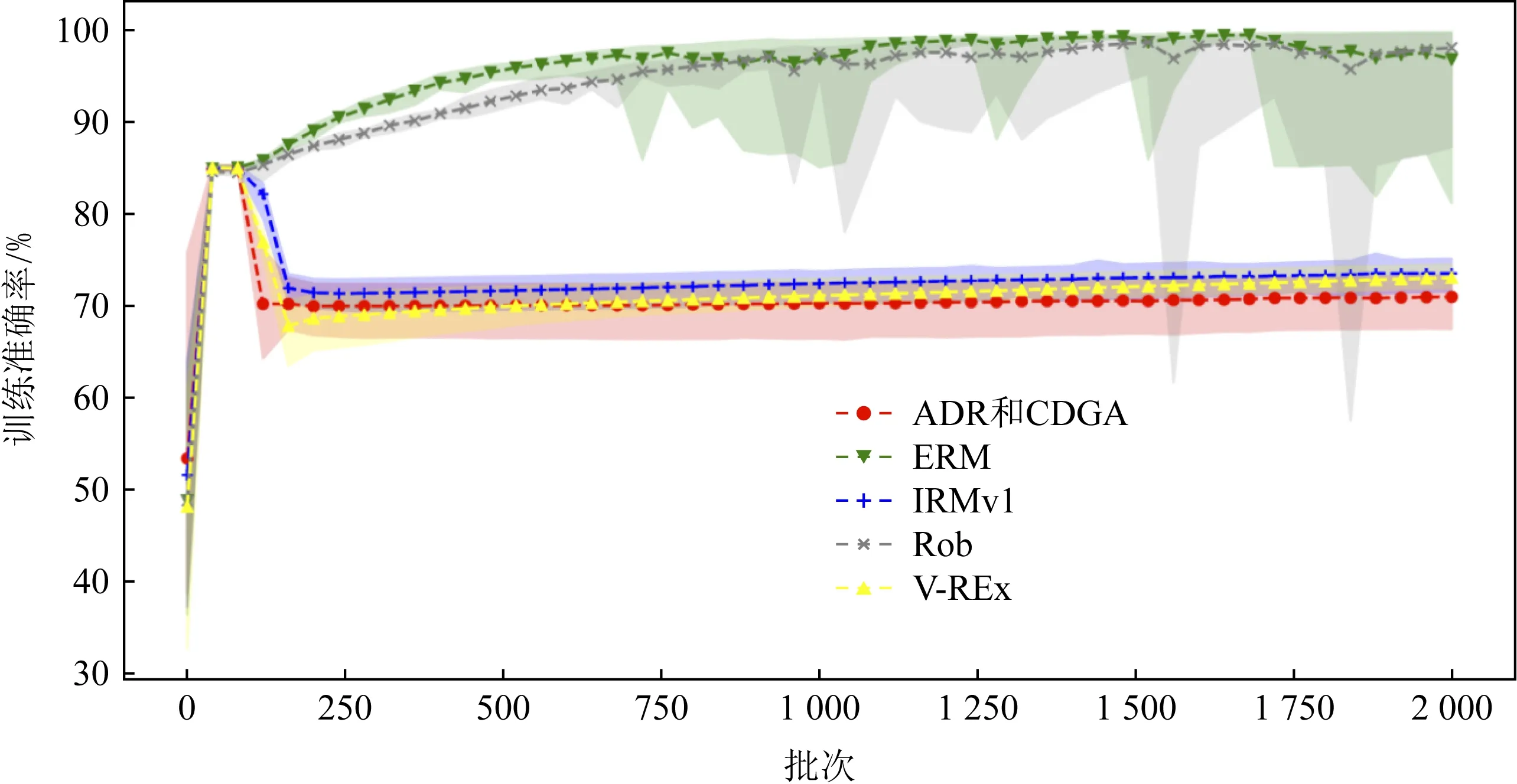
Fig. 7 Comparison of training precision under different methods
4.3 基于CDGA模型解决跨域训练问题
在实际运用中,仅使用真实特征去识别往往会导致识别准确率不高,因为一些虚假特征往往对识别准确率的提升有一定的积极作用.而这些虚假特征的分布会随着域的变化而改变,在已知某个样本来自某个域的情况下对该样本进行识别被称之为跨域适应问题.例如,在实际问题中,有时可能需要去识别一些具备不同背景颜色的数字,而这些来自新域的数字很少被标注,经常直接使用这些样本训练模型后,模型在测试集表现不佳.而直接使用MNIST作为训练集进行训练会面临跨域适应的难题.已有的工作提出了能够学习真实特征的模型,但是没有对如何结合适用少量新域数据中的虚假特征进行讨论.本文对于跨域适应问题的讨论,基于假设域的信息通过来自该域的其他少量标注样本给出,这一假设和实际背景契合,具有合理性.
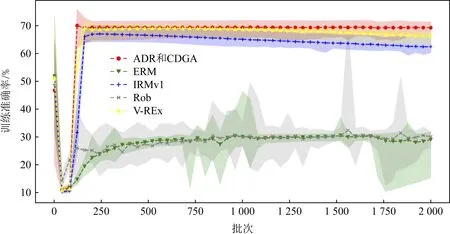
Fig. 8 Comparison of test precision under different methods
实验以pe=0.1,0.2分别生成25 000张图像作为2个训练环境,分别以pe=0.4,0.5,0.6,0.7,0.8,0.9生成10 000张图像作为测试环境.此外,以pe=0.4,0.5,0.6,0.7,0.8,0.9生成1 000张来自新域的标注图像,且这些图像的原图像与测试集不相同.实验选取了3种模型:第1种为本文提出的跨域泛化模型,该模型使用生成的50 000张训练集进行训练;第2种为经验风险最小化模型(ERM),该模型分别在pe=0.4,0.5,0.6,0.7,0.8,0.9的1 000张新域图像上进行训练;第3种为本文提出的CDGA模型,使用50 000张训练集和1 000张新域图像进行训练.
实验结果如表2所示,我们不难看出本项目提出的CDGA模型对新域的预测结果要显著优于跨域泛化和ERM方法.当虚假特征与标签的相关性较弱时(pe的值接近0.5),CDGA模型侧重利用真实特征作出预测,且少量利用虚假特征使预测结果比泛化模型更好;当虚假特征与标签的相关性较强时(pe的值接近0或1),CDGA模型侧重利用虚假特征作出预测,且少量利用真实特征使预测结果比ERM方法还要好,从而验证了CDGA模型在跨域适应问题中的优势.
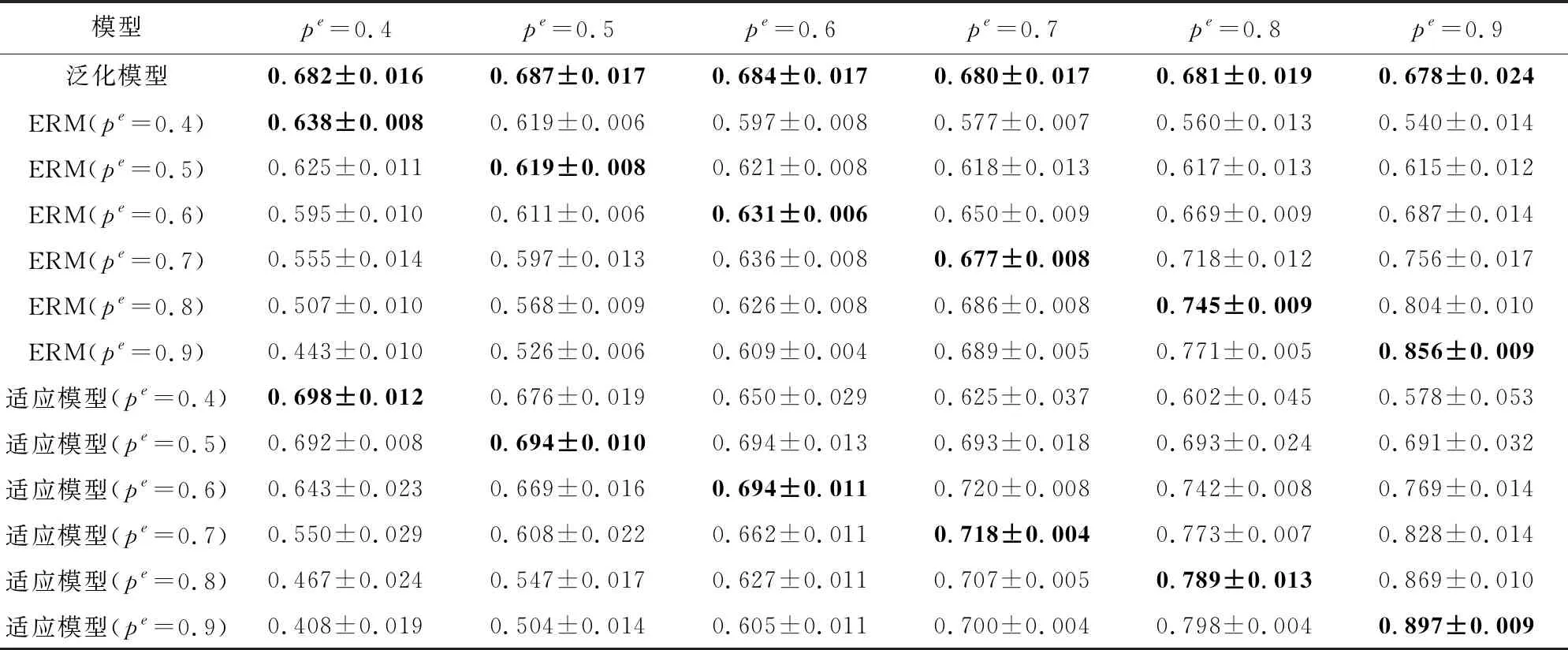
Table 2 Comparison of the Effects of Different Models with a Small Amount of New Domain Data
综上,我们的模型在跨域适应问题中可以综合利用真实特征和虚假特征作出很好的预测.而且在训练过程中也学习了跨域泛化预测模型ωs∘Φ,因此我们初步验证了CDGA模型可以同时在跨域泛化和跨域适应任务中作出高效预测.
5 总结与展望
本文基于机器学习领域中的跨域任务的最新研究,构建了一个能够实现特征分离的自适应学习模型——CDGA模型,该模型在跨域泛化和跨域适应问题上都具有不错的表现.
一方面,对于跨域泛化问题,需要使用真实特征对未知新域数据进行预测.由于真实特征在不同环境下的分布保持不变,因此考虑在训练风险中引入不变性惩罚来剔除虚假特征.通过分析发现,该惩罚项的本质是表征模型在不同环境下输出分布的差异.基于这一思路,比较了现有方法的优劣,并提出了一种新的训练风险函数ADR,可以更好地学习到数据中的真实特征.该方法不仅具有更高的测试准确率,还克服现有方法容易过拟合的缺点,解决了测试准确率因迭代轮数增加而明显降低的问题.
另一方面,基于稳定的跨域泛化学习方法,本文构建的CDGA模型可以在跨域适应任务取得很好的效果.该模型训练出的数据表达Φ同时可以表达真实特征和虚假特征.若已知待测数据来自某个训练域,则只需选择相应域的分类器即可;若已知待测数据来自某个新域ea,则只需收集该域的少量数据Dea训练相应的分类器ωa即可;若待测数据来自未知域,则选择稳定预测分类器ωs∘Φ进行预测.因此,不论是跨域泛化任务还是跨域适应任务,该模型均可选择相应的分类器ω作出高效预测.
本文提出的模型可以应用于跨域适应和跨域泛化2项任务,相较于原有方法取得一定的进展.但对于跨域学习任务,仍然有不少问题值得进一步研究.例如,如何寻找新的不变性惩罚项以更好地提取真实特征并过滤虚假特征;如何拓展该模型在多种虚假特征混杂的训练数据中的应用;如何将不变性惩罚方法与鲁棒性增强的方法相结合以解决跨域训练任务等.
作者贡献声明:李鑫负责提出研究选题、提出模型、论文撰写;李哲民负责编写代码和实施实验过程;魏居辉负责论文作图和撰写论文;杨雅婷负责调研整理文献并设计论文框架;王红霞负责修订和完善论文.
