基于指令流访存模式预测的缓存替换策略
2022-01-19王玉庆杨秋松李明树
王玉庆 杨秋松 李明树
1(中国科学院软件研究所基础软件国家工程研究中心 北京 100190)2(中国科学院大学 北京 100049)
缓存是现代处理器中的一种重要机制,将常用数据从内存拷贝到缓存中,后续数据访问可以直接从缓存读取,从而减少慢速DRAM内存的访问次数,提升处理器性能.缓存的容量是有限的,在实际使用中发生缓存内容的替换是不可避免的,缓存的性能受缓存容量和缓存替换策略的影响很大.从优化缓存替换策略着手减少缓存缺失次数是近些年学术界的研究热点.
缓存替换策略是指缓存内容替换发生时,从所有的候选行中选择被替换行的算法.理论上最好的缓存替换策略是Belady[1]提出的MIN.发生缓存替换时,MIN算法总是将重引用距离最远的候选行从缓存中踢出,从而达到最优的替换性能.但是MIN算法替换时需要精确的未来访存序列,通常被认作是一种不可实现的算法.在实践中尝试应用MIN算法时,需要对访存行为进行抽象建模,利用模型来预测未来的访存行为.由于访存行为的多样性和复杂性,定义出一个准确的访存行为模型适用于所有的应用场景是很困难[2-3].当前的大部分缓存替换策略研究都是基于经验主义,比如基于时间局部性原理的最近最少使用(least recently used, LRU)算法和它的各种变种,将最近使用的数据保留在缓存中.但是基于经验主义的缓存替换策略都具有局限性,只适用于一部分特定的应用场景.
使用预测技术提高缓存替换的准确性是当前缓存替换策略研究的一种趋势.随着研究的深入,预测算法越来越复杂,以应对复杂多变的缓存访问场景.但即使深度学习这样的复杂算法,也很难保证能够适应所有的应用场景.同时,处理器中缓存系统接收到的访存序列会受到乱序执行机制的干扰,即便某条访存指令行为是简单的步长模式,该访存序列到达缓存系统的次序也是不确定的.因此,直接在缓存系统中预测访存序列是困难的,要面对很大的不确定性,而现有的缓存替换策略并不能真正减小这些不确定性.
访存序列预测过程中的不确定性,主要表现在3个方面:
1) 缓存访问行为的复杂性.这种复杂性更多体现在整体行为上,在缓存系统中接收到的访存序列是若干条指令执行后的结果,不同指令间的执行次序以及每条指令的行为模式都将对缓存系统最终接收到的访存序列产生影响.在这样复杂多变的访存序列基础上学习访存行为模式是困难的.
2) 在缓存系统中学习指令级的行为模式容易受到乱序执行机制的干扰.为了学习类似固定步长这样的访存模式,预测模块需要计算访存序列中相邻访问之间的差值.乱序执行会打乱访存执行的次序,使预测过程变得不准确.为解决该问题,文献[4]引入了额外的存储结构记录所有地址的访问.
3) 在开启了缓存预取机制的处理器中,缓存系统中接收到的访问序列中包含了预取请求.预取算法的投机性很高,一部分预取请求是无用的,并不能代表程序对数据的真实需求.若缓存替换策略不能识别预取项,就有可能保留不必要的预取数据在缓存中,从而影响到程序的执行性能.文献[5]分析了这一现象,并说明在开启预取的前提下,MIN算法也达不到缓存替换的最优效果.
为了解决上述问题,本文提出了一种新的预测缓存访问序列的方法,通过程序的指令流来预测缓存访问序列.根据分支预测技术推测程序指令流,定位指令流中访存指令的位置,借助于访存指令模式的学习,对访存指令的地址逐一进行预测,生成访存序列.相比访存指令的行为,分支指令的行为(跳转方向和目标地址)更容易预测.分支预测技术的研究已经比较成熟,现有的分支预测算法[6]准确率很高.
现有基于预测技术的缓存替换策略[7-11]需要在缓存系统中重新实现一套预测器,本文在处理器中已有的分支预测单元基础上扩展出对访存序列的预测.该方法预测对象具体到每条访存指令,降低了预测的复杂性;通过访存指令的提交序列进行模式学习,避免乱序执行的干扰;预测过程基于程序指令流,预测的访存序列只包含真实的程序需求,不受缓存预取机制的影响.通过上述方式本文方法减少了访存序列预测过程中所面对的不确定性.
基于预测出的访存序列,在选择替换候选项时将重引用距离最远的候选项从缓存中踢出.在进行缓存替换决策时,如果所有的候选项都未命中访存序列,将路号最小的候选项从缓存中踢出.新分配的缓存行有可能在下一次缓存替换时被选为踢出项,本文算法可以将一部分缓存数据保持在缓存中,因此对于缓存访问中的抖动和扫描等行为具有一定的抵抗性.
本文的主要贡献有3个方面:
1) 提出了基于指令流访存模式预测的缓存替换策略IFAPP(instruction flow access pattern prediction).根据分支预测技术预测程序指令流,确定程序指令流中的访存指令,对每条访存指令的行为进行预测.该方法可以减少预测过程中所面对的不确定性,不依赖于特定分支预测算法,具有良好的可扩展性.
2) 提出了一种学习指令级访存模式的方法.对访存指令的执行结果进行记录,按照提交次序学习访存模式.同时改进了步长模式访存行为的识别,在普通步长模式基础上扩展对循环行为的支持.
3) 在GEM5模拟器上实现了原型系统,通过在SPEC CPU2006程序集中实验评估,验证了IFAPP缓存替换策略的有效性.同时实验证明了当分支预测和访存模式两者均充分学习的情况下,本文算法预测出的访存序列是比较准确的.
1 相关工作
理论上最优的缓存替换策略是Belady提出的MIN算法,每次将重用距离最远的候选项从缓存中踢出.基于该算法原理的缓存替换策略在实际应用中需要借助访存行为模型产生访存序列从而确定重用距离.一些早先的研究使用独立引用模型(independent reference model, IRM)[12]对访存行为进行建模,该模型假设所有的访存行为是互相独立的,并且单个访存行为具有固定的、已知的概率.应用该模型进行缓存替换时,每次将访问概率最小的候选项从缓存中踢出,等价于最不经常使用(least frequency used, LFU)算法.IRM模型忽视了临近访存之间的相关性,在分析处理器缓存时表现不佳.近来,一些缓存系统研究[3,13-15]提出了更复杂的模型来分析访存行为,但是这些复杂模型只适用于对特定替换策略(如LRU)进行分析.
由于现有的访存模型不能很好地反映真实程序的行为,大部分的缓存替换策略是基于经验主义的.基于经验主义的缓存替换策略分析应用场景中访存行为的模式,通过总结出的规律指导替换候选项的选择.比如大部分的程序都具有时间局部性,最近访问的缓存行大概率会被再次访问,由此衍生出了LRU算法和它的派生算法[16-18].与此相反,若程序不具有时间局部性,则采用最近最常使用(most recently used, MRU)替换策略更优.还有一部分研究认为经常被访问的缓存行很有可能会被再次访问,因此基于缓存行的访问频率构建替换策略[19-22].使用上述单一模式构建的缓存替换策略往往不能适用复杂的应用场景,后续的研究多采用混合策略,通过静态选择[19,22-23]或者动态选择[24-27]的方式从多种经验主义替换策略中进行选择.但是基于经验主义的缓存替换策略都具有局限性,只适用于一部分特定的应用场景.在实际应用中访存行为很可能同时具有多种规律,一部分访存行为具有时间局部性,另一部分与此相反.在此情形下,无论是LRU或者MRU都不能很好地工作.
使用预测技术提高缓存替换的准确性是当前缓存替换策略研究的一种趋势.预测技术一方面可以用于强化经验主义算法,另一方面也可以直接指导缓存替换.预测的内容可以是死块(dead block)[10,28-31],也可以是重用距离[7-11,32-33].随着研究的深入,缓存替换策略中使用的预测算法也变得越来越复杂,从最简单的基于饱和计数器的方法[7],发展到使用二级自适应的方法[10],直到最近的感知器算法[34]和深度学习算法[35].为了对复杂的缓存行为进行准确预测,除了预测算法本身在不断加强外,缓存访问行为中与重用距离相关的特性也不断被挖掘.访存指令的PC(program counter)、访存的物理地址、访存序列历史信息等和重用距离相关的因素都被应用到预测算法中.如MPPPB算法[32]扩展了感知器算法[34],选择了7种与重用距离相关的因素作为算法的输入.预测技术的应用使缓存替换策略能够动态地学习访存行为的特征,增强了缓存替换策略的适应性.现有使用预测技术的缓存替换策略依然属于经验主义的范畴,并不能从根本上弥补经验主义算法和MIN算法之间的差距.
缓存访问行为是复杂的,里边包含了大量的不确定性,在设计缓存替换策略时必须要考虑到如何处理这些不确定性[36].处理器中缓存系统接收到的访存序列会受到处理器乱序执行和缓存预取机制的干扰,这进一步增大了在缓存系统中预测访存行为的难度.当前的缓存替换策略均不能有效减少这些不确定性.
本文提出的缓存替换策略依然需要使用历史信息进行规律学习,与其他基于预测的缓存替换策略相比较,本文的预测对象比较简单.访存行为的复杂性更多体现在整体上而不是个体上,无论是分支指令行为还是指令级访存行为都是比较容易学习的.本文提出的算法预测访存指令流,进行指令级别的访存模式分析,可以天然规避预测过程中很多的不确定性,避免使用像深度学习这样的复杂算法.本文的实验结果证明预测出的访存序列是比较准确的,说明本文方法确实减小了缓存访问行为预测中的不确定性.
2 背景知识介绍
本文的算法基于处理器中的分支预测单元进行扩展,在指令级访存行为中比较常见的是步长访问模式.下文简单对这2方面的内容进行介绍.
2.1 分支预测
分支预测技术对程序中分支指令的跳转方向和跳转地址进行预测,减少分支指令刷新导致的处理器性能损失.研究表明,当前分支指令的跳转行为是受过往分支指令影响的.分支指令之间的相关性是分支预测的基础.分支预测器设计就是将分支指令之间的关系归纳为模式,通过模式识别的方式预测分支指令行为.分支预测器可以细分为方向预测器和地址预测器,分别预测分支指令的跳转方向和跳转地址.
以图1中的TAGE-ISL算法[6]为例,其方向预测器由多个预测模块组成,不同类型的分支指令由其专用预测模块处理.循环类型的分支会被循环预测器捕获;带有强偏向性的分支由TAGE中的bimodal部分进行预测;具有特定模式的分支则由TAGE中的全局预测器进行预测.该算法中还包含2个辅助器(统计纠正和立即更新),对主预测器TAGE的结果进行修正.
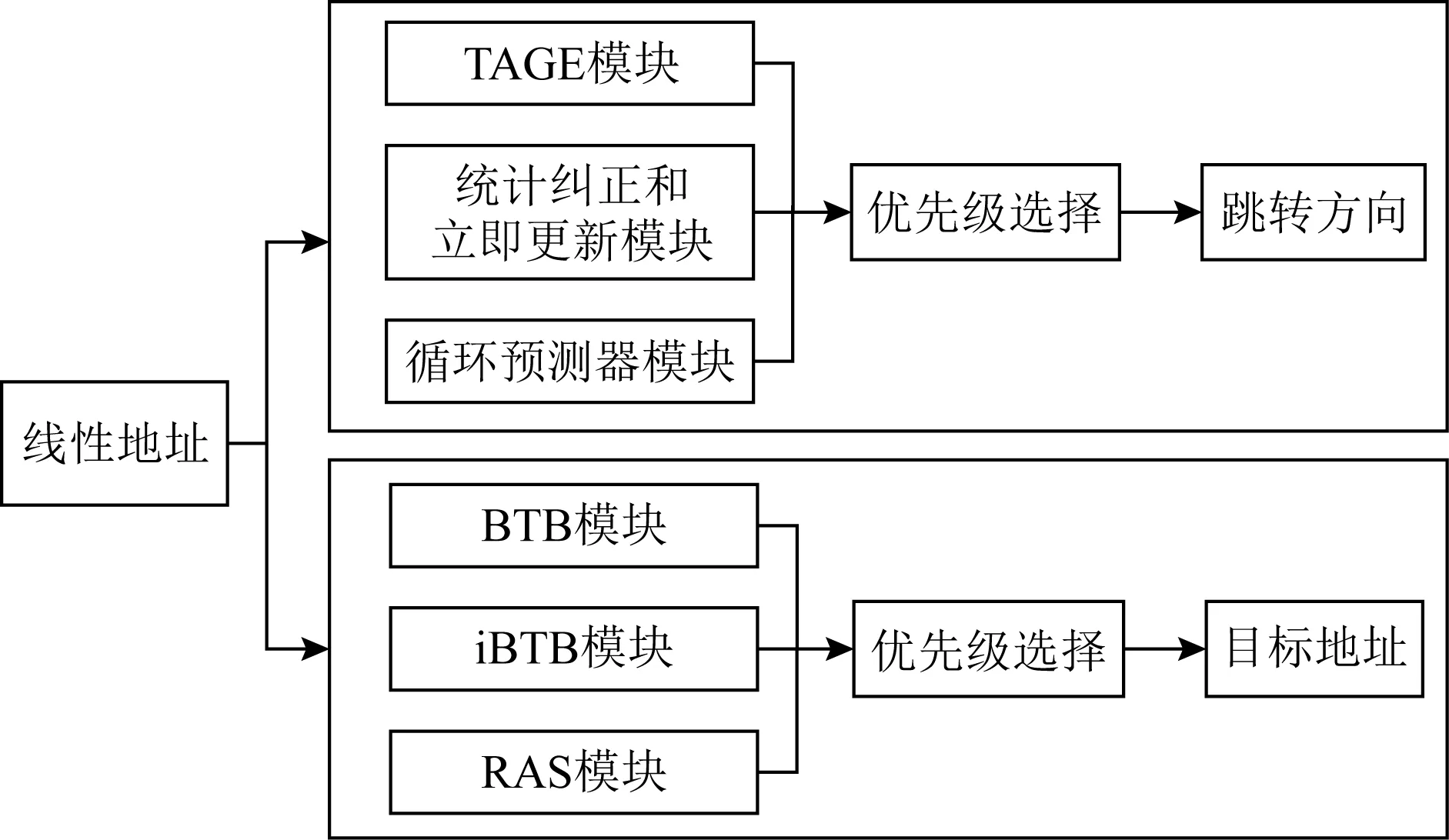
Fig. 1 The algorithm of TAGE-ISL
地址预测器的设计同方向预测器类似,也由多个专用预测器组成.若分支指令的跳转目标地址是固定的,则可以通过分支目标缓冲(branch target buffer, BTB)[37]中记录的上一次跳转地址进行准确预测;返回指令的返回地址是由CALL指令确定的,可以通过返回地址栈(return address stack, RAS)进行预测;若分支指令的跳转地址和某个模式是一一对应的,则通过间接分支目标缓冲(indirect BTB, iBTB)进行预测,其查询过程类似于方向预测器中的二级自适应算法.
BTB主要作用在于解决2个问题:1)如何判断在某个位置分支指令是否存在;2)如何确定分支指令的类型以及跳转目标地址.这2个问题同样也是本文中进行读写访存指令预测时首先要解决的问题.因此本文参照BTB结构和功能设计访存目标缓冲(memory access target buffer, MATB),记录访存指令的PC、访存指令类型和上一次访存物理地址.
2.2 步长模式访存行为
基于步长的数据访问模式是指连续的数据访问的间隔是一个固定值,例如依次访问A,A+K,A+2K等.这种访问类型在应用程序中是十分常见的,当程序操作多维数组或者使用指针遍历元素大小相同的数据结构时,其数据访问都符合基于步长的模式.
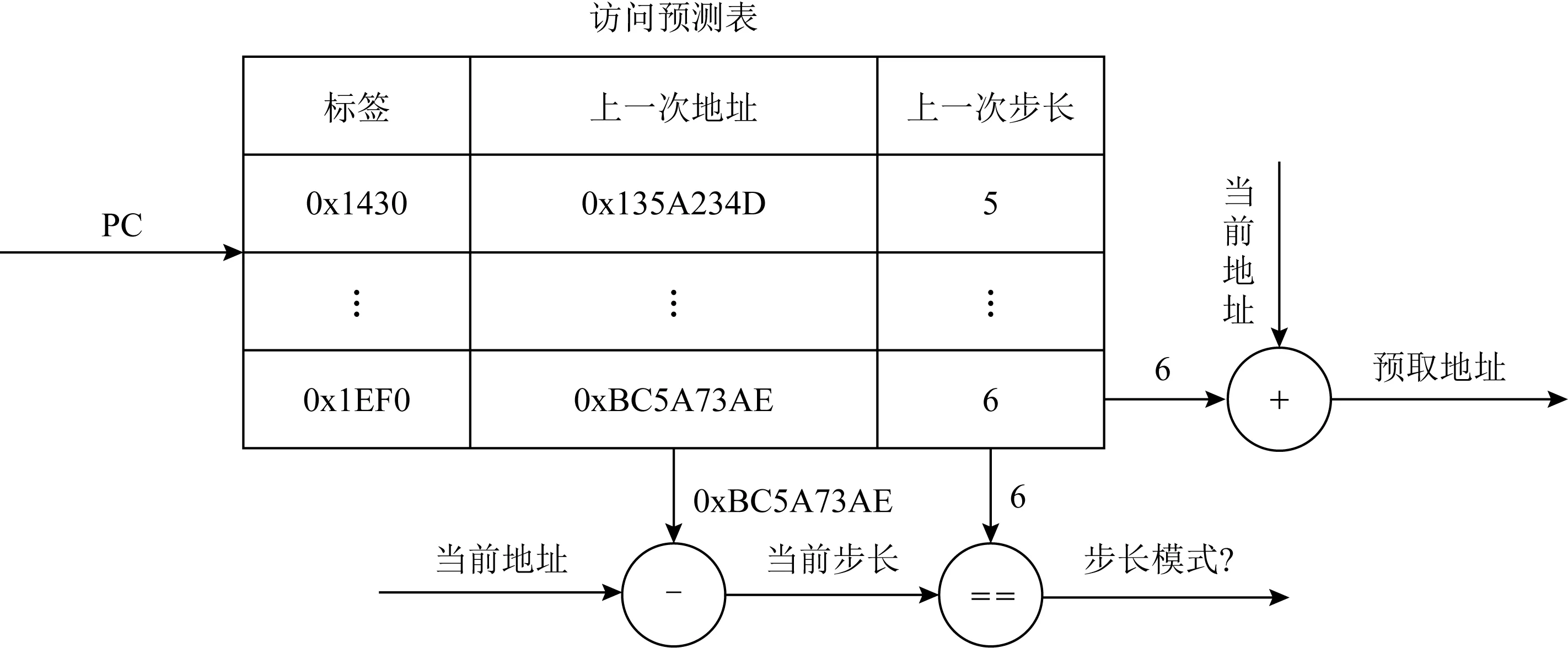
Fig. 2 Step predictor IBSP
在处理器中最常见的步长预测算法是IBSP[38],其主要结构是访问预测表,如图2所示.访问预测表使用访存指令的线性地址进行索引,表中记录上一次访问的地址以及上2次访问的地址差.当访存指令未命中缓存时,使用访存指令的线性地址查询访问预测表.若标签命中,则使用当前的访存地址减去上一次访存地址,计算出当前的步长.若当前步长与访问预测表中记录的上一次步长相等,则说明当前访存指令的行为符合步长模式.预测访存地址为当前访存地址加上当前步长.
3 基于指令流访存模式预测的缓存替换策略
本文提出的IFAPP缓存替换策略使用预测技术预测未来访存序列,使用同MIN算法相同的决策进行缓存替换——将重用距离最大的候选项踢出.未来访存序列的预测分为2个步骤:1)判断访存指令是否存在于指令流中,确定其发生的次序;2)为每条访存指令的每次执行进行独立的地址预测.第1个步骤依赖于分支预测技术对指令流进行预测,第2个步骤需要对每条指令的访存模式进行学习.
IFAPP缓存替换策略基于分支预测技术,通过提前流水设计(ahead pipeline)[39]将分支预测过程做成单独的子流水.分支预测流水的预测结果是一个个指令块,其宽度为分支预测流水带宽.若指令块中存在跳转分支指令,则分支指令末尾字节的位置作为指令块的结束,这些指令块组成了程序的指令流.利用分支预测技术预测缓存访问序列需要解决2个问题:1)如何判断某个指令块中是否存在访存指令;2)如何确定访存指令的访存地址.
为了解决第1个问题,本文定义访存目标缓冲MATB,接收处理器写回阶段反馈的访存指令信息.MATB中记录流水线中执行过的访存指令的线性地址、访存指令的类型和访存物理地址等信息.通过检索MATB,我们可以确认某个指令块中是否存在访存指令,以及该访存指令上一次执行所访问的物理地址.
为了解决第2个问题,本文在MATB的基础上添加访存指令类型识别功能.访存指令的行为是复杂的,某条访存指令的目标物理地址可能是随着时间变化的.访存物理地址不固定的访存指令是不能通过MATB进行准确预测的,因为MATB只能记录上一次执行的物理地址.本文算法将访存指令划分为不同的类型,不同的访存指令类型使用专用的预测器进行.本文可以识别多种常见指令级访存模式,对步长模式访问行为使用步长预测器进行地址预测;对具有时间关联性的访问行为使用时间关联预测器进行预测.对指令级访问模式的学习过程按照指令提交的次序进行,不会受到乱序执行的干扰.
通过分支预测和MATB我们可以确定访存指令的位置和先后次序;通过指令级访存模式的学习我们可以预测每条访存指令的目标地址.这两者结合起来就可以生成未来访存序列.该访存序列用于在缓存替换发生时计算重用距离,将重引用距离最远的候选项从缓存中踢出.访存序列中实现了读写指针,读指针随着取指过程自增,读写指针之间是有效预测项.计算候选项重用距离的过程从读指针开始遍历访存序列,查询候选项第1次出现的位置,该位置与读指针之间的距离即为候选项的重用距离.
本文的系统总体架构如图3所示.基于指令流访存模式预测的缓存替换策略系统分为以提前预测为主体的取指预测单元、以MATB为主体的访存预测单元和替换决策单元3个部分.取指预测单元和访存预测单元分别预测指令缓存和数据缓存的未来访存序列;替换决策单元进行重用距离的计算,选择候选项进行踢出.
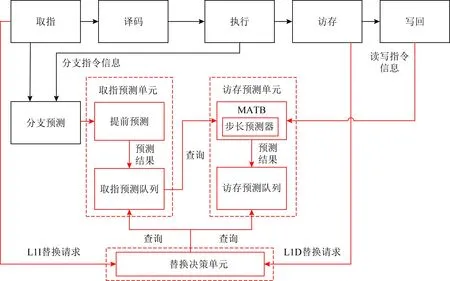
Fig. 3 IFAPP framework
取指预测单元在处理器的分支预测单元中添加提前预测功能,维护提前预测线性地址和提前预测分支历史信息.提前预测作为CPU中的一个子流水独立运行,同取指过程解耦合.提前预测的预测结果写入取指预测队列中,对取指单元中的一级指令缓存而言,取指预测队列中保存的就是未来一段时间的访存序列.提前预测过程中使用的地址是线性地址,预测结果在写入取指预测队列之前经过转译后备缓冲(translation lookaside buffer, TLB)的检索就能得到物理地址.
访存预测单元的主要功能是实现MATB,记录流水线中执行过的访存指令信息.每当取指预测队列添加新项时,用该指令块的起始地址查询MATB,预测指令块中的访存指令位置及其访存地址,并将预测结果写入访存预测队列.本文在MATB的基础上实现了步长预测器和时间关联预测器,能够对符合特定模式的访存指令进行预测.
替换决策单元的实现缓存替换的决策过程.取指预测队列和访存预测队列中的内容分别是一级指令缓存和一级数据缓存的未来访问序列.当一级指令缓存L1I发出替换请求后,替换决策单元接收到所有候选项的物理地址,使用这些物理地址检索取指预测队列,得到每个候选项的重用距离.将重用距离最大的候选项作为踢出项反馈给一级指令缓存.一级数据缓存L1D的替换请求处理与此类似.
下文中我们将详细介绍取指预测单元、访存预测单元和替换决策单元中的关键组件.
3.1 取指预测单元
取指预测单元是为了预测一级指令缓存的未来访问序列,本文的设计中在处理器中取指单元和分支预测单元基础上进行扩展,添加提前预测逻辑和取指预测队列.提前预测逻辑和取指预测队列用于缓存访问序列预测,提前预测逻辑的结果写入取指预测队列,并不影响取指过程.原有的取指单元和分支预测单元间的交互过程仍照常进行.
如图4所示,在分支预测单元中新增提前预测地址逻辑、提前预测历史、提前预测分支目标缓存(Ahead BTB, ABTB),提前预测的结果选择逻辑以及指令预测队列等模块,这些模块共同实现了取指预测单元.此处借鉴了分支预测设计中的提前流水设计,通过引入取指预测队列,将提前预测过程和取指过程解耦合.在取指单元处于阻塞状态时,依然会发送提前预测流水的有效信号,以此保证提前预测流水远远领先于取指单元.只有这样取指预测队列中才能够填充足够多的预测信息.当取指预测队列填满时,停止提前预测流水.提前预测逻辑与分支预测单元中的原有预测逻辑是互相独立的.
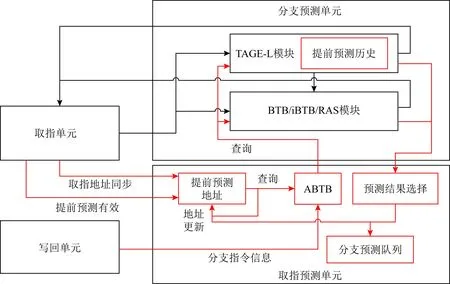
Fig. 4 The module of instruction fetch predictor
3.1.1 提前预测
提前预测的“提前”是相对于处理器中取指流水而言的.提前流水设计本意是解决慢速分支预测和取指速率不匹配的问题.在本文设计中我们故意加快分支预测的速率,以产生足够多的指令块支持访存序列预测过程.提前预测逻辑主要由提前预测地址逻辑、提前预测历史和提前预测分支目标缓存组成.
定义1.提前预测地址.提前预测地址逻辑生成提前预测流水的线性地址,表示为pc,op,其中pc表示提前预测流水中的基地址,op表示当前周期对基地址的更新操作.在初始化或者流水线刷新时,pc与取指单元中的线性地址进行同步.提前预测流水每周期以pc为起点,预测2个连续64 B的指令块.若预测过程未发现跳转的分支指令,pc按照128 B对齐的方式进行自增.如果在提前预测流水识别到跳转的分支指令,则将pc更新为分支指令跳转目标地址.
定义2.提前预测历史.提前预测流水专用的历史并在提前预测流水中进行投机的更新.分支预测单元中已有的历史信息保持原有逻辑不变.以TAGE-L算法为例,其TAGE模块内会同时包含提前预测历史和原分支历史,两者在各自的预测流水中使用,是互相独立的.流水线刷新时不仅要更新提前预测线性地址,还需要对投机更新的提前预测历史信息进行回滚.当发生流水线刷新时,原分支历史会先进行回滚,然后将2个历史进行一次同步.
定义3.ABTB模块.提前预测地址并不是某个分支指令的地址,而是一个指令块的起始线性地址.分支预测单元中原有的BTB模块只能处理单个分支指令地址的检索,因此需要扩展一个ABTB模块,用来处理一个指令块中多条分支指令并行检索.ABTB根据流水线后端反馈的分支指令信息进行分配.
ABTB模块采用组相联结构,共4 096项.每一项的结构表示为valid,tag,offset,branch_type,target_addr,phys_addr,instlen.其中valid表示有效位;tag表示标签;offset表示偏移;branch_type表示分支类型;target_addr表示预测跳转目标地址;phys_addr表示行物理地址,在分支指令提交时根据其线性地址查询TLB获得,用于写入取指预测队列;instlen表示指令长度,用于计算分支指令的首字节线性地址.
ABTB模块中以分支指令的结尾字节作为分支指令的地址,将分支指令的线性地址拆分为高位的标签和低位的指令块内偏移2部分.ABTB在进行检索时,首先进行高位标签的比对,在标签相等的同时其块内偏移部分必须大于提前预测地址的低位才算命中.提前预测地址作为指令块的起始地址,分支指令的地址大于提前预测地址才能说明该分支指令位于这个指令块中.
提前预测流水的分支指令方向预测需要检索分支预测单元中原有的分支预测模块,这些模块是用分支指令的首字节地址进行索引的.每个指令块中可能包含多个分支指令,相对应的ABTB在提前预测流水检索的过程中可能会命中多项.每个命中项都是一条分支指令,其分支指令地址会再次检索分支预测单元中原有的分支预测模块(BTB,TAGE-L等).命中ABTB的多条分支指令的预测结果汇总在一起,输入到预测结果选择模块.预测结果选择模块从分支指令中选择偏移最小的跳转分支作为预测结果写入取指预测队列.若指令块中存在跳转的分支指令,则提前预测地址作为指令块的起始地址,分支指令的地址作为指令块的结束地址写入取指预测队列.若指令块中不存在跳转的分支指令,则指令块内是连续的,其结束地址就是该64 B指令块的最后一个字节.
3.1.2 取指预测队列
取指预测队列用来存放提前预测的结果,在本文的设计中取指预测队列有4 096项.文献[40]指出预测序列长度是缓存容量的8倍以上时MIN算法才具有良好的性能,本文算法在一级缓存容量为512项的基础上乘以8作为取指预测队列深度.取指预测队列每一项的结构可以表示为valid,line_addr,phys_addr,begin_offset,end_offset,taken.其中,valid表示有效位;line_addr表示行线性地址;phys_addr表示行物理地址;begin_offset表示起始偏移;end_offset表示结束偏移;taken表示跳转位.行线性地址和起始偏移/结束偏移确定了64 B指令块内有效字节的范围.
取指预测队列以64 B指令块为单位记录提前预测流水的预测结果.64 B的宽度是为了和取指单元访问一级指令缓存的带宽匹配.取指预测队列中实现了提交指针、读指针和写指针,如图5所示.当某个指令块中的所有指令都提交后,该指令块可以从取指预测队列中移除,此时提交指针加1.当取指模块读取过某个指令块后,读指针加1.提交指针和读指针之间指令块已经处于流水线中,读指针和写指针之间的指令块才是有效预测指令块.流水线刷新发生后,读写指针会回滚到分支刷新的位置或者提交指针的位置.
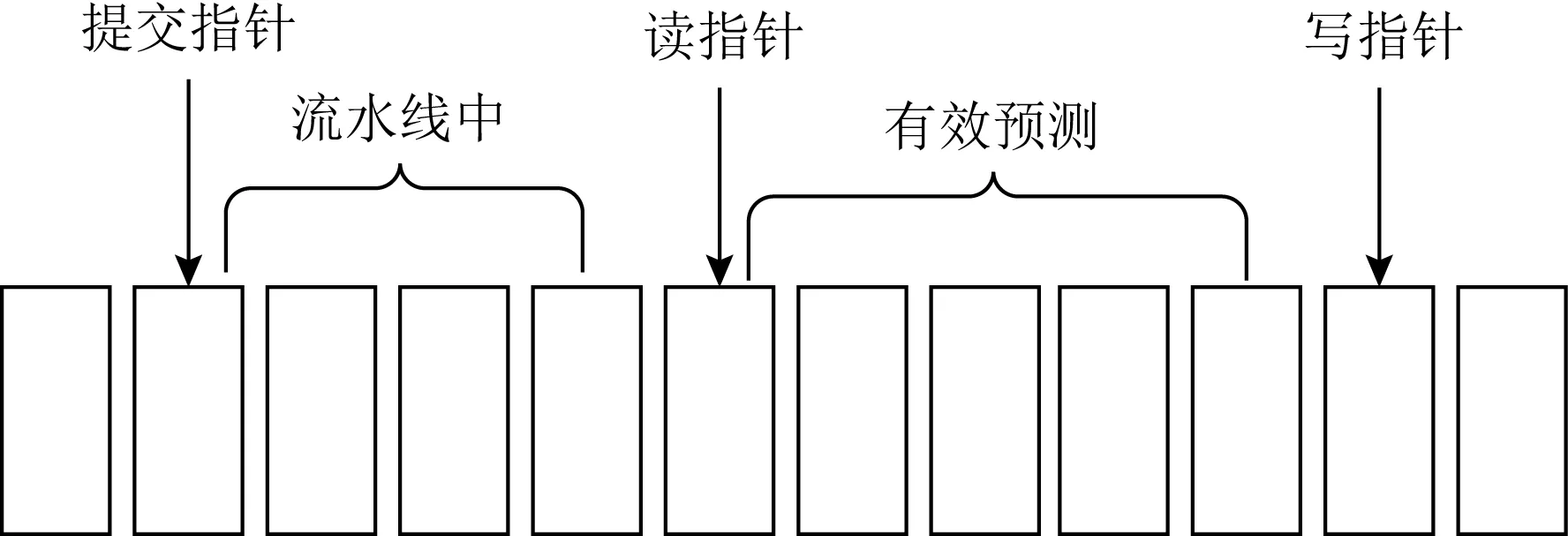
Fig. 5 Pointer in the queue of instruction fetch predictor
在进行一级指令缓存的替换决策时,使用一级指令缓存反馈的候选项物理地址检索取指预测队列.此检索过程使用64 B对齐的物理地址进行匹配,检索从读指针开始,到写指针结束,第1个命中的条目项位置就是候选项的重用距离.若候选项未命中,则将重用距离设置为最大值.当出现多个候选项未命中时,选择缓存中路号最小的候选项作为踢出项.
3.2 访存预测单元
访存预测单元是为了预测一级数据缓存的未来访存序列,本文的设计中通过设计MATB来预测未来访存序列,并将结果放入到访存预测队列.取指预测队列中的每一个条目项代表一个指令块,每个指令块都包含起始偏移和结束偏移.各个指令块连起来构成了程序的指令流.每当取指预测队列添加新项时,用该指令块的起始地址查询MATB,预测指令块中的访存指令位置及其访存地址,并将预测结果写入访存预测队列.访存预测队列条目项中包含取指预测队列编号,因此访存预测队列中的每一条访存指令,都能对应到取指预测队列中的一个条目项.建立这样的对应关系方便在流水线刷新时进行取指预测队列和访存预测队列的同步刷新.
3.2.1 访存目标缓冲MATB
访存目标缓冲MATB存储结构有4 096个表项,MTAB接收写回单元的反馈,记录已经提交的访存指令的线性地址以及访存目标物理地址,还有指令类型等信息.每一项的结构表示为LineAddr,PhyAddr,InstType.其中,LineAddr表示访存指令的线性地址,线性地址分为标签和偏移2部分;PhyAddr表示访存指令的目标物理地址;InstType表明访存指令类型,InstType∈{DirectInst,InDirectInst},其中DirectInst表示直接访存指令,InDirectInst表示间接访存指令.MATB在查询过程中使用访存指令的线性地址进行命中判定,查询命中后输出访存指令的目标物理地址和访存指令类型.
MATB的查询过程如图6所示.MATB的命中判定是一个包含关系的判定,预测指令块是一个区间范围,我们需要判定访存指令的线性地址是否在这个区间范围内.取指预测队列新添加的项中包括指令块的起始地址和结束地址,可以转化为高位的标签和低位的起始偏移和结束偏移.使用指令块的标签和偏移查询MATB,当一条访存指令的线性地址高位标签和指令块相同,并且低位偏移大于等于起始偏移,小于等于结束偏移的时候,即说明该访存指令位于该指令块中.
访存指令的线性地址在程序运行过程中一般是不变的,使用该线性地址检索MATB识别对应的访存指令应当是准确的.这一过程同分支预测算法中使用分支指令的线性地址检索BTB是类似的.分支指令占程序总指令数的比例大约是1/4,分支预测技术的论文中对BTB的尺寸进行过实验,选用4 096个表项是比较合适的.本文假设程序中访存指令的比例同分支指令是类似的,在实现MATB时直接参照了BTB的尺寸.
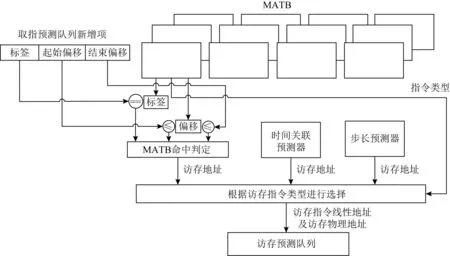
Fig. 6 Queries of MATB
命中MATB后,根据MATB中记录的访存指令类型选择访存目标物理地址.若是直接访存指令,则访存目标物理地址来自MATB.若是间接访存,如果访存指令满足步长模式,则使用步长预测器获取物理地址;如果访存指令满足时间关联模式,则使用时间关联预测器获取物理地址.将访存指令线性地址和访存目标物理地址等信息写入访存预测队列中.MATB的查询可能会命中多项,表明一个指令块中包含多条访存指令,这些访存指令按照指令块中出现的先后次序,将预测结果写入访存预测队列中.
3.2.1.1 步长预测器
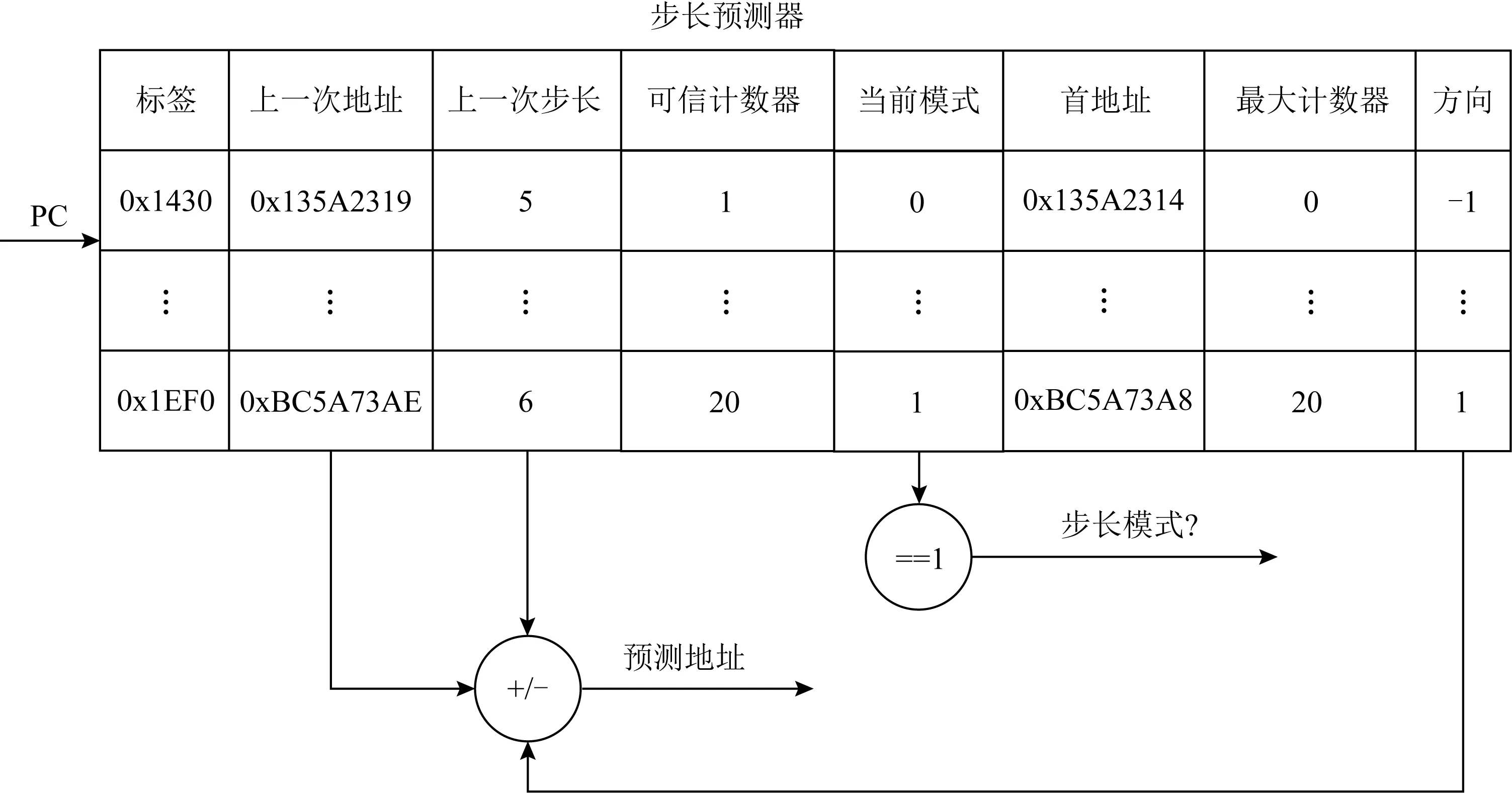
Fig. 7 Step predictor
在缓存系统中比较常见的访存模式是步长模式,为了支持对符合该模式的访存指令的目标地址进行预测,本文设计了步长预测器.本文中设计的步长预测器的设计参考了IBSP[38]算法,在其基础上进行了扩展.在实现中步长预测器是整合在MATB中的,扩展了每个MATB表项的属性.
步长预测器的结构如图7所示,相比IBSP算法,本文的步长预测器中扩展了可信计数器、当前模式、首地址以及最大计数器等内容.原本的IBSP算法只需要记录步长信息,因为数据预取操作是在当前访存地址的基础上计算出来的.针对{A,A+K,A+2K,…,A+NK}这样的固定步长访存序列,本文的步长预测器不仅要记录其步长K,同时也要记录序列的起始地址A以及最大计数值N.为了增加步长预测器的准确性,增加了可信计数器和当前模式.当上一次步长和当前步长相同时,可信计数器加1,否则可信计数器清零.当可信计数器的数值大于某个阈值时,将当前模式位置1,表明当前访存指令的行为确实是符合步长模式的;若当前模式位为0,则表明当前尚处于学习阶段,学习阶段步长预测器不输出预测结果.步长始终是正值,方向位决定步长序列是递增还是递减.在MATB分配时首地址域设置为当前物理地址.在步长模式计数过程中,首地址域是不更新的,只更新上一次地址为当前最新值,通过这种方式将一个步长序列的首地址保存下来.当MATB为某条符合步长模式的指令进行更新时,发现当前地址恰好等于首地址,说明步长访存序列又重新执行了一遍.此时将可信计数器的值更新到最大计数器中,步长序列的头和尾都被记录下来.
步长模式识别算法如算法1所示:
算法1.步长模式识别算法.
输入:提交的访存指令PC和物理地址PhyAddr;
输出:是否是步长模式.
① if(当前模式==步长模式);
② if(当前方向和步长与历史记录不符)
③ if(PhyAddr==首地址&&(最大计数器==0‖可信计数器≠最大计数器))
④ 最大计数器=可信计数器;
⑤ else
⑥ 清空步长相关信息;
⑦ end if
⑧ else
⑨ 可信计数器++;
⑩ if(最大计数器≠0 &&可信计数器>
最大计数器)
步长预测器的查询和MATB一致,发生在取指预测队列写入新的项之后.MATB命中说明该指令块中存在访存指令,同时可以获取该指令的步长预测器信息.若访存指令非步长模式,则预测物理地址同上一次物理地址相同;若访存指令为步长模式,则需要根据首地址和步长信息计算当前访存物理地址AddrA.此计算过程需要统计当前取指预测队列中该访存指令(指令块)已经出现的次数.
算法2.步长预测器的访存地址预测.
输入:当前是否是步长模式、步长预测器表信息;
输出:预测地址.
① if(当前模式==步长模式)
② 根据编号检索取指预测队列,得到未提交的包含该指令的指令块个数N;
③ 预测地址=首地址+(N%最大计数器)×
上一次步长;
④ if(最大计数器≠0)
⑤NUM=(可信计数器+N+1)%(最大计数器+1);
⑥ 预测地址=首地址+方向×NUM×上一次步长;
⑦ else
⑧NUM=1+N;
⑨ 预测地址=上一次地址+方向×
NUM×上一次步长;
⑩ end if
3.2.1.2 时间关联预测器
时间关联访存行为[41]是指一段访存序列以固定的次序重复出现.例如我们观察到{A,B,C,D,A,B,C,D}这样的访存序列之后,{B,C,D}这样的序列有很大概率紧接着在A之后出现.指令级访存行为中也存在时间关联访存模式.
算法3.时间关联行为识别.
输入:过去M次访存地址;
输出:时间关联信息.
① 将过去M次访存地址记录在
lastPhyVector[M-1:0]中;
② if(lastPhyVector[3n-1:0]匹配
{A1,A2,…,An,A1,A2,…,An,A1,A2,…,An})
③ 时间关联模式=1;
④ 时间关联序列长度=n;
⑤ 时间关联序列=lastPhyVector[n-1:0];
⑥ end if
时间关联预测器集成在MATB中.时间关联预测器记录每一条访存指令过去M次的访存地址,根据这M次历史信息识别时间关联访存行为.本文的算法中相同访存序列重复3次才能确认为时间关联模式,lastPhyVector的长度设置为12,支持序列长度不超过4的时间关联访存行为.除此基本的时间关联行为模式之外,本文算法还支持形如{A,B,C,A+n,B+n,C+n,A+2n,B+2n,C+2n,…}这样的步长——时间关联行为模式.
3.2.2 访存预测队列
访存预测队列用来存放检索MATB得出的预测结果.在本文设计中访存预测队列有65 536项,65 536是在取指预测队列有4 096项的基础上得出,每个取指预测队列项代表一个64 B指令块,我们假设其中最多有16条访存指令.每一项的结构表示为:valid,inst_line_addr,mem_phys_addr,memlen,inst_queue_index.其中valid表示有效位;inst_line_addr表示指令线性地址;mem_phys_addr表示访存物理地址;memlen表示访存长度,根据访存物理地址和访存长度可以识别跨行的访存指令;inst_queue_index表示取指预测队列索引,便于在流水线刷新时进行取指预测队列和访存预测队列的同步刷新.
访存预测队列中也实现了提交指针,读指针和写指针.在进行一级数据缓存的替换决策时,使用一级数据缓存反馈的候选项物理地址检索访存预测队列,此过程同取指预测队列的检索类似.
3.3 替换决策单元
替换决策单元接收一级缓存发送的候选项物理地址,使用这些物理地址检索取指预测队列/访存预测队列,得到每个候选项的重用距离,将重用距离最大的候选项编号反馈给一级缓存.
若取指预测队列或者访存预测队列中没有足够多的有效预测结果,替换决策单元向一级缓存反馈相应信息,此时一级缓存使用默认替换策略进行候选项选择.在进行缓存替换决策时,如果所有的候选项都未命中访存序列,本文算法将路号最小的候选项从缓存中踢出.
4 实验与验证
为了验证本文提出方法的有效性,本节首先说明了实验环境和实验中使用的测试程序.然后从2个方面说明IFAPP算法的有效性:1)分析IFAPP算法的适用场景;2)对比IFAPP算法和其他算法的性能.
4.1 实验设置
本文采用GEM5模拟器[42]作为基础实验环境,使用alpha指令集.实验过程需要对CPU内部结构进行扩展,因此使用了GEM5中的DerivO3CPU细粒度模型.使用的分支预测算法为TAGE-L.GEM5的基本配置如表1所示:
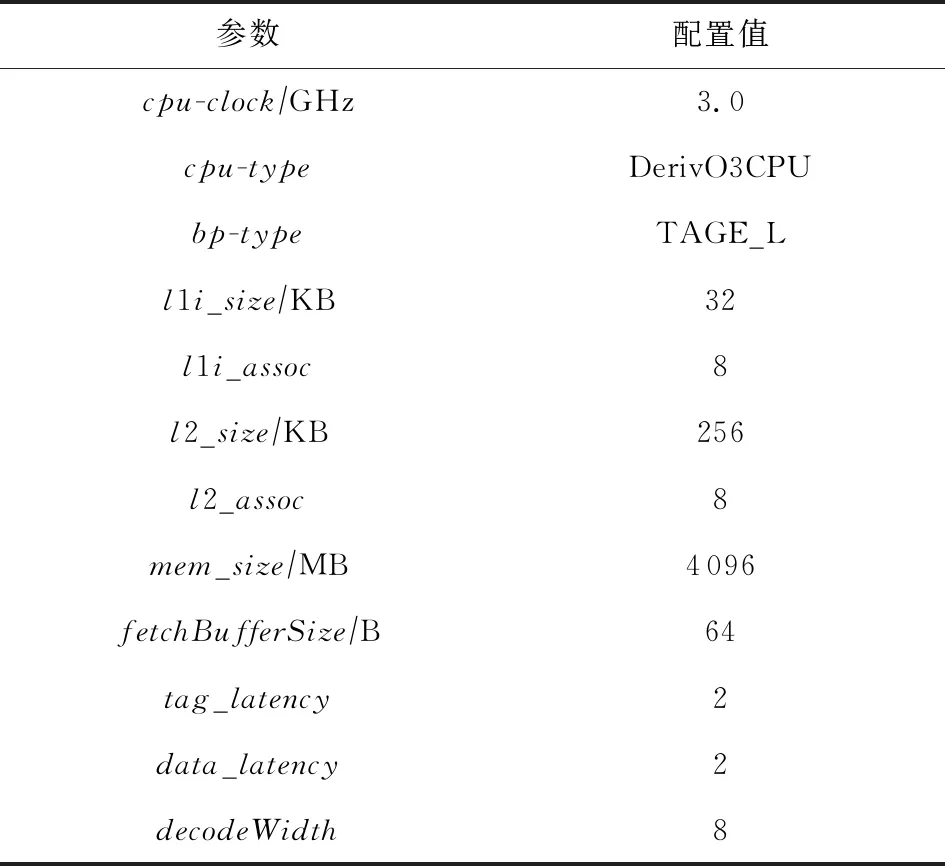
Table 1 Configuration of GEM5
表1中取指缓冲(fetchBufferSize)的宽度和一级缓存访问的时延(tag_latency/data_latency)影响GEM5模拟器取指阶段的执行速度.在设计中我们期望提前预测流水能够显著领先于取指流水,从而在取指预测队列和访存预测队列中填充足够多的预测信息.因此在实验评估环节我们会观测取指参数的变化对IFAPP算法的影响.
实验的测试集为SPEC CPU2006测试程序.完整的SPEC CPU2006测试程序在GEM5模型中可能需要运行几个月的时间,现在比较认可的做法是从simulation point开始运行.本文参考文献[43]中提供的采样点实验数据进行仿真.整型和浮点程序的检查点如表2和表3所示.
实验中从表2、表3检查点开始执行1 000万条指令,统计IFAPP算法生效的次数和缓存替换发生的次数.
实验的对比算法为LRU,BRRIP[7],BIP[24].BIP算法是动态选择LRU/MRU插入模式的典型经验主义算法,BRRIP是基于重用距离预测的典型算法.为了保证IFAPP算法的准确性,当前的实验设置为只有当取指预测队列/访存预测队列中有超过4 096个预测结果时才使用IFAPP算法进行缓存替换,否则采用默认缓存替换策略(LRU).选择4 096这个阈值是因为文献[40]指出预测序列长度是缓存容量的8倍以上时MIN算法才具有良好的性能,按照当前GEM5配置一级缓存中包含512个缓存行,因此需要4 096个预测结果.

Table 2 Checkpoints of Integral Programs

Table 3 Checkpoints of Floating Programs
4.2 实验评估
在本节中首先分析IFAPP算法的适用场景,探讨流水线刷新和架构参数对IFAPP算法的影响;然后通过和对比LRU,BRRIP,BIP算法的性能进行对比,说明本文方法的有效性.
4.2.1 流水线刷新对IFAPP算法的影响
当分支预测错误产生刷新时,或者因为其他原因导致提交单元进行流水线刷新时,取指预测队列和访存预测队列都会响应该刷新.当前的实验设置为只有当访存预测队列中有超过4 096个有效预测结果时才使用IFAPP算法对一级数据缓存的替换请求进行处理,当处理器刷新比较频繁时IFAPP算法生效的次数会受到明显影响.为了评估流水线刷新对IFAPP算法的影响,我们首先统计不同SPEC程序中IFAPP算法的生效次数.
如表4所示,当处理器刷新比较频繁时(bzip2,h264ref,soplex,gobmk),IFAPP算法生效的次数占总替换次数的比例会显著减低.其中大部分的处理器刷新是由分支预测失败引起的.IFAPP算法并不依赖于特定的分支预测算法,通过使用更准确的分支预测算法取代TAGE-L,可以减小分支预测失败刷新的次数,增大IFAPP算法的生效次数,从而提高IFAPP算法的性能.
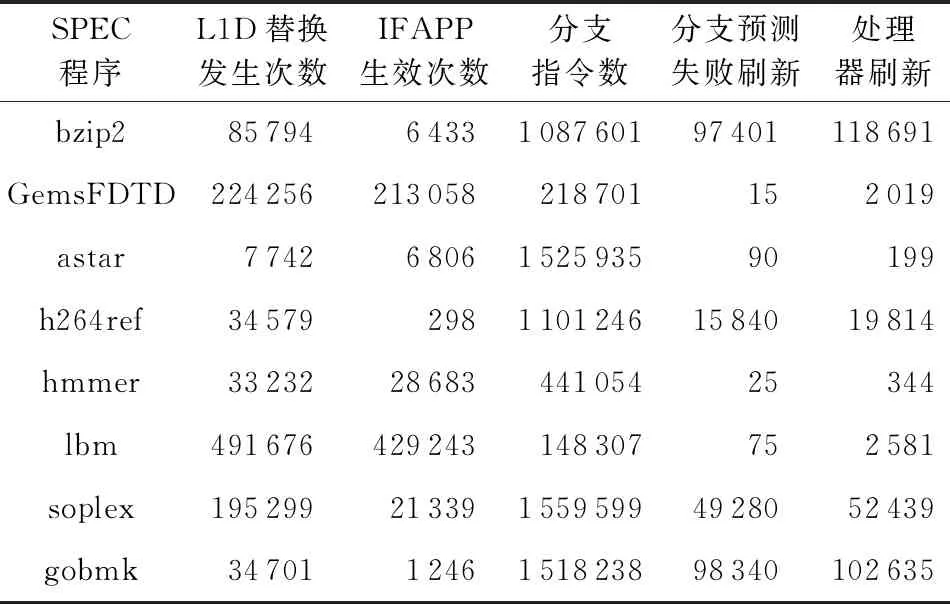
Table 4 Efficient Times of IFAPP with Different SPEC
4.2.2 架构参数对IFAPP算法的影响
影响IFAPP算法生效次数的因素除了刷新以外,还有提前预测流水领先于取指流水的程度.若模拟器中取指阶段执行速度比较快,提前预测流水只能轻微地领先于取指流水,也会导致访存预测队列中没有足够的预测结果.以bzip2测试程序为例,我们修改模拟器取指阶段的参数,分析取指执行速度与IFAPP算法生效次数的关系.
实验过程中,我们保持取指单元的带宽(fetch-BufferSize)不变,修改一级缓存的访问时延(tag_latency/data_latency)和解码单元的带宽(decode-Width).增大一级缓存的访问时延或者减小解码单元的带宽都会导致取指阶段的执行速度降低.根据表5可以看出,当我们逐渐增大缓存访问时延,并减小解码带宽,提前预测流水就会更明显地领先于取指流水,此时IFAPP算法生效的次数也相应地增长.在处理器设计中,缓存的访问时延和解码的带宽一般是固定的架构参数,并不能动态调整,此时通过增大提前预测流水的带宽(当前预测带宽为128 B,2倍于取指带宽)也可以起到相似的效果.
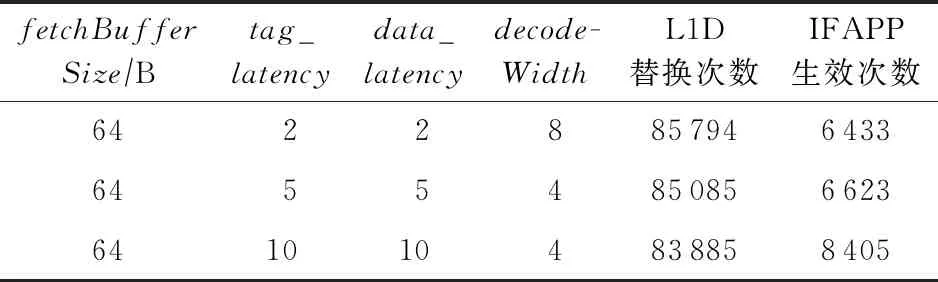
Table 5 Efficient Times of IFAPP with Different Parameters
4.2.3 性能对比
在本节中我们对比了LRU,BRRIP,BIP算法和本文提出的IFAPP算法.
4.2.1节中提到IFAPP算法受流水线刷新次数的影响比较明显,当IFAPP算法生效次数很少时,其缓存替换性能基本等同于LRU算法.在这样的SPEC程序中对比IFAPP算法和其他算法的性能没有实际意义.根据表6中的实验结果,我们选择IFAPP算法生效次数占比较高的GemsFDTD,astar,hmmer,lbm,bwaves这5个SPEC程序对比IFAPP算法和其他算法的性能.
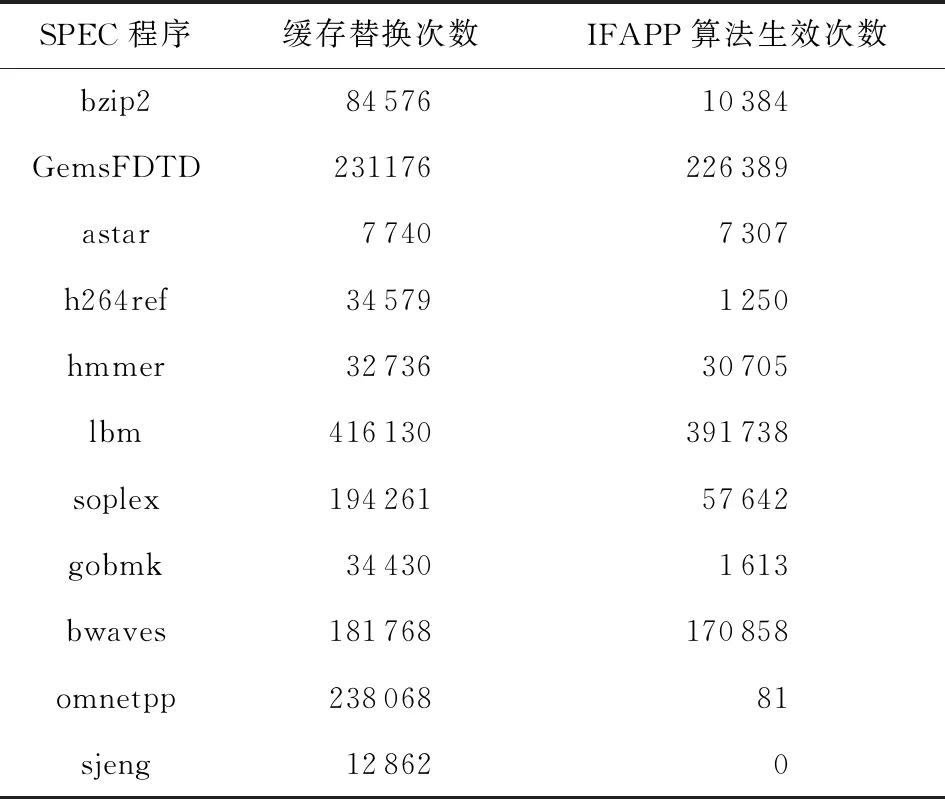
Table 6 Relationship Between Efficient Times of IFAPP and Times of Cache Replacement
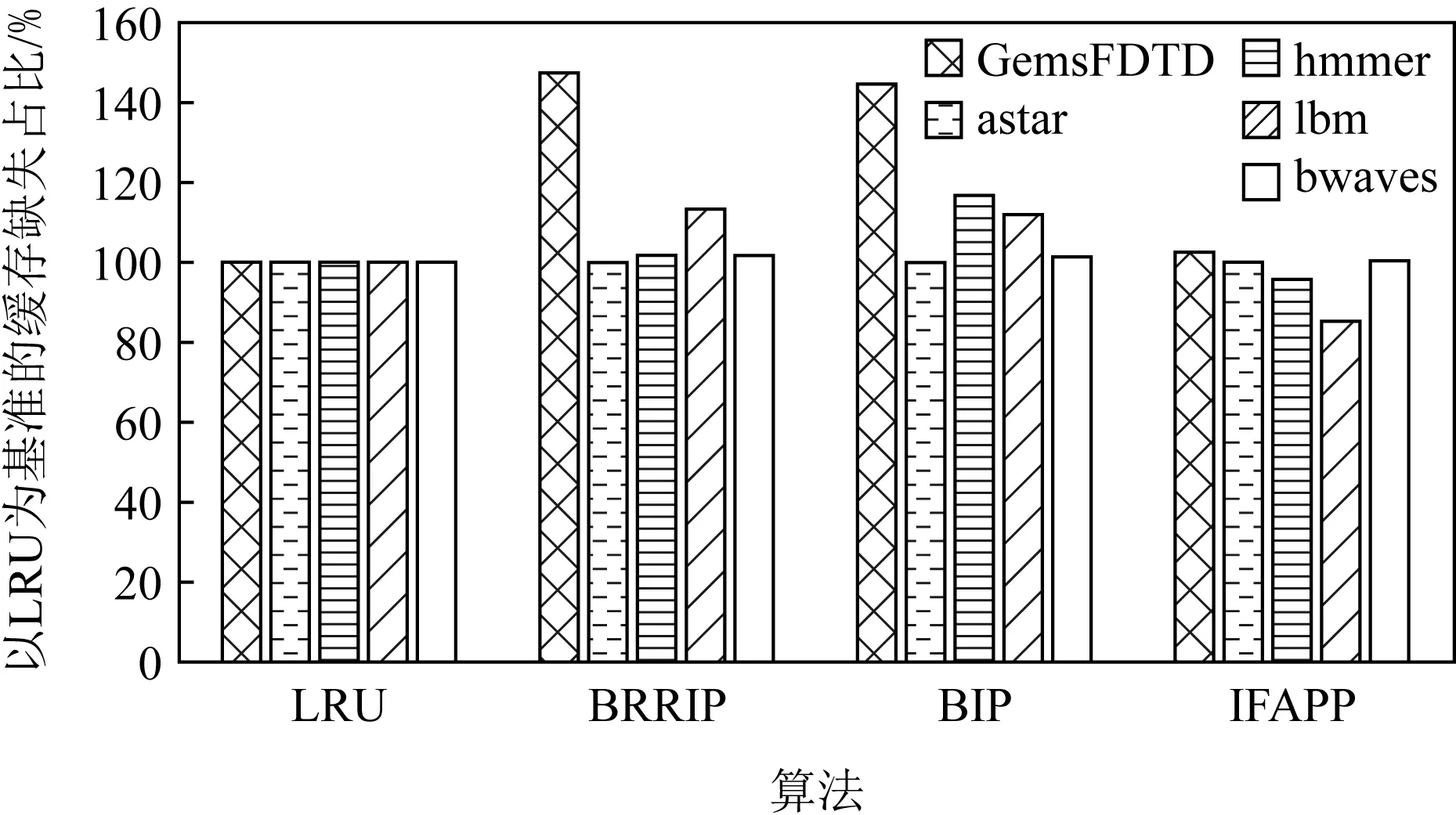
Fig. 8 Performance comparation of four algorithms
如图8所示,IFAPP算法相比LRU算法平均提高3.2%的性能.与BRRIP算法和BIP算法相比,IFAPP算法分别平均提高12.3%和14.4%的性能.在一级缓存中程序执行的局部性可以得到充分的体现,LRU算法应用在一级缓存替换上已经可以取得相当好的效果.BRRIP算法和BIP算法应用在一级缓存时,其性能要比LRU算法差.
IFAPP算法在一级缓存能够比LRU算法更加有效是因为多数访存指令的行为并不复杂,IFAPP算法可以对其访存地址进行准确预测.相比LRU算法,使用IFAPP算法进行缓存替换更能反映应用程序对数据的真实需求.如图8所示,IFAPP算法在lbm程序上的性能明显优于LRU.这是因为lbm程序中有很多访存指令行为符合步长模式,在整个采样片段中其地址一直自增.很多新分配的缓存行之后再也不会被访问,这样的行为是不利于LRU策略的.对于IFAPP算法来说,即便是新分配的缓存行,如果其重用距离过远也会被很快替换出去.因此IFAPP算法对于缓存访问中的抖动和扫描等行为具有一定的抵抗性.
本文统计了不同SPEC程序中IFAPP算法访存地址预测错误的次数,如表7所示.在百万量级的访存指令中,IFAPP算法预测错误的次数很少.本文实验中使用的分支预测算法并是准确率最高的,所支持的访存模式也是最基本的,但IFAPP算法对访存序列的预测依然很准确.这说明预测访存序列的方法是很重要的,相比在缓存系统中直接预测访存序列,本文算法结合分支预测和访存模式学习这2种技术可以规避访存序列预测中的很多不确定性.实验结果证明了在分支预测和访存模式学习的共同作用下,IFAPP算法可以减少访存序列预测中的不确定性.

Table 7 The Accuracy of Memory Address Prediction of IFAPP
4.2.4 算法开销
IFAPP算法的存储资源开销主要集中在ABTB、MATB、取指预测队列和访存预测队列上.ABTB有4 096个表项,每个表项96 b,总共占用48 KB的存储空间.MATB有4 096个表项.每个表项中包含了71 b的访存指令信息、69 b的步长预测器和523 b的时间关联预测器.时间关联预测器需要保存访存指令过去12次物理地址,占用空间较多.MATB总共占用约331 KB的存储空间.取指预测队列有4 096项,每一项86 b,占用43 KB的存储空间.访存预测队列有65 536项,每一项94 b,占用752 KB的存储空间.
ABTB和MATB的分配过程只需要几个时钟周期.取指预测队列和访存预测队列的分配过程在提前预测流水中进行,在本文的配置下提前预测流水明显领先于CPU正常流水,取指预测队列和访存预测队列的分配时间会被掩盖掉.IFAPP算法的时间开销主要集中在使用一级缓存发送的候选项物理地址检索取指预测队列/访存预测队列,得到每个候选项的重用距离.实际应用中65 536项的访存预测队列应实现为16路的组相联结构,访存预测队列指针转换为组号/路号.在这个存储阵列上实现4个读端口,每周期可以读取64项(4×16),读取4 096项需要64个周期.加上后续的计数和比较过程,整个缓存替换决策大约需要70个周期.这个过程的时间开销是可以避免的,我们可以在缓存替换行为发生之前,提前检索取指预测队列/访存预测队列,计算好每个候选项的重用距离.
4.3 实验结论
通过4.2.1节的分析,我们可以看出流水线刷新对IFAPP算法的生效次数有明显的影响,这在一定程序上限制了IFAPP算法的应用场景.当前的算法设计为了保证准确性会在流水线刷新之后清空取指预测队列和访存预测队列.我们可以只进行写指针的回退,不进行数据的刷新,新的预测数据将覆盖原有数据,未覆盖的投机预测数据可以被保留.这样将降低IFAPP算法的准确性,但是可以降低流水线刷新对IFAPP算法生效次数的影响,扩宽IFAPP算法的应用场景.
本文提出的IFAPP算法在一级数据缓存上相比LRU算法提高了缓存替换的性能.这主要是因为借助分支预测和访存模式学习技术,我们可以准确地预测访存序列.通过使用更准确的分支预测算法,支持更多的访存模式,IFAPP算法的性能还可以进一步提升.
5 总 结
本文提出了一种基于预测技术的缓存替换方法.根据分支预测技术推测程序指令流,定位指令流中的访存指令流,然后对每个访存指令的地址进行预测,生成访存指令预测信息.在访存指令预测信息的基础上应用MIN方法进行缓存替换.该方法可以避免乱序执行的干扰,预测对象是指令级行为模式,大大减少替换预测过程中所面对的不确定性.本文在GEM5模拟器上搭建了原型系统,分析了基于预测技术的缓存替换策略的适用场景,并通过性能对比实验说明了该算法的有效性,IFAPP算法相比LRU算法平均提高3.2%的性能,和BRRIP算法和BIP算法相比IFAPP算法分别平均提高12.3%和14.4%的性能.在后续工作中,我们将研究如何减少本文算法的开销,以及在多核环境下预测共享二级缓存的访问序列,并分析未来访问序列在缓存预取算法中的应用.
作者贡献声明:王玉庆提出研究思路,设计研究方案,进行实验和数据分析,起草论文;杨秋松设计研究方案,审阅论文;李明树参与论文审阅和最终版本修订.
