基于社团检测算法的固件二进制比对技术
2022-01-19肖睿卿费金龙祝跃飞蔡瑞杰刘胜利
肖睿卿 费金龙 祝跃飞 蔡瑞杰 刘胜利
(数学工程与先进计算国家重点实验室 郑州 450001)
二进制比对是逆向分析领域的重要分支,其主要目的是通过比对不同程序的二进制代码,确定不同程序间的相似关系,如:函数相似性、文件相似性[1].该技术可用于固件比对[2]、补丁比对[3]、软件抄袭检测[4]、恶意软件检测[5]、漏洞分析[6]等领域.
固件比对属于二进制比对范畴,但固件较普通软件而言,规模更大.现有的二进制比对方法主要依靠函数语义特征提取(如三元组[7]),而后直接从待比较程序中依据特征序列(或特征序列映射后的值)挑选匹配函数.此类方法可以应用于固件比对,但由于固件的函数数量较多,因此,固件中语义特征相似甚至相同的情况频繁出现,导致函数比对时目标函数数量较大且包含大量语义特征相近的函数,给基于语义特征进行固件比对带来挑战.为解决这些问题,降低函数比对过程中的目标函数数量,本文根据复杂网络相关理论,研究了基于社团检测的固件比对方法.
本文的研究目标是设计临近版本固件的函数对应关系构建方法,旨在通过此法找到旧版本固件函数在新版本固件内的对应函数(亦称函数匹配),以对固件的补丁比对提供支撑.
本文的主要贡献有3个方面.
1) 基于网络科学理论中的ER随机图模型,分析了用社团检测算法指导固件比对的可行性.从目前梳理的文献来看,这是首次在二进制比对领域对函数调用图的性质进行分析,并应用复杂网络相关理论指导比对工作.
2) 提出了基于社团检测的固件比对方法.包括2部分:基于固件函数调用图的社团检测和匹配方法;基于社团匹配的函数匹配算法.前者设计了函数调用图压缩算法,提出了固件社团匹配算法.后者优化了函数相似性计算方法,设计了函数误匹配的修正方法.
3) 使用本文方法形成原型系统,通过实验验证可行性,确定合理参数,对样本固件进行二进制比对,并与Bindiff5[8]的匹配结果进行比对.实验表明,本文方法可以提升Bindiff比对结果5%~11%的准确率.
1 概 述
1.1 二进制比对技术
近些年,二进制比对领域的研究趋势倾向于固件比对、补丁比对和跨指令集比对.相关研究具有3个特点:
1) 多数研究者将工作重心放在了寻找函数刻画方法上,以此提高二进制比对的准确率.包括静态提取函数语义信息和动态执行获取输入输出对等多种思路.
其中,文献[9]从函数控制流图(control flow graph, CFG)提取特征向量,再使用谱聚类构建码本.而后计算函数与各个质心的编辑距离以构建新的特征向量,以此来刻画函数.通过这种函数刻画方法,完成固件比对工作.文献[10]在文献[9]的基础上开展工作,主要通过深度学习,将函数调用图(function call graph, FCG)中与目标函数有调用关系的函数的特征向量整合入目标函数的特征向量.此法能够将FCG的局部网络信息整合入函数节点,使得函数特征来源更全面.文献[11]将二进制程序切割为比函数更小的代码片段,通过对代码片段的语义进行相似性分析,再将相似性分析扩展到更大范围.文献[12]同样使用控制流图来刻画函数,但其选用特征强调了计算经济性,依据计算经济性的高低逐个进行特征的提取和使用,并以此来缩小匹配函数的搜索范围,避免从全局来进行搜索.文献[13]利用条件操作行为和系统调用信息提取函数签名,以此实现兼容不同指令集的函数刻画.文献[14]使用子图匹配来寻找克隆函数,并使用自适应局部敏感散列(locality sensitive hashing, LSH)来提高搜索效率.文献[15]首先使用基本块和执行路径的最大公共子序列进行函数匹配,而后利用匹配函数的邻居关系扩展匹配.文献[16]通过提取条件公式作为函数的高级语义特征,用以进行漏洞检索.文献[17]通过识别函数的参数和间接跳转目标,并模拟执行函数,以提取语义签名度量函数的相似性.文献[18]对于给定二进制程序的原始版本和已修补的版本,找到已修补的函数并标识可能包含安全补丁或非安全补丁的功能更新.而后,通过对差异点语义分析以识别安全补丁,并使用污点分析来总结模式.文献[19]通过计算和匹配反汇编的结构和句法,为二进制代码指纹识别提供一种准确且可扩展的解决方案,可用于二进制比对.文献[20]将二进制函数分解为可比较的片段,通过执行函数片段重优化降低语义分析的强度,再通过简单的语法比较来找到等效的片段.文献[21]从CFG、指令特征、统计特征等方面为库函数生成签名.并设计了一种新颖的数据结构来存储此类签名以实现针对目标函数的高效匹配.文献[22]提出了基于系统调用切片段等效的检查方法,通过识别细粒度语义相似性和执行轨迹间差异实现此法.文献[23]利用内存模糊测试进行二进制代码相似性分析,通过收集各种程序行为的痕迹,根据2段代码行为轨迹的最长公共子序列,计算它们的相似性得分.文献[24]利用操作码频率提取函数的语法特征;利用控制流图随机游走提取函数语义;将z分数(z-score)应用于规范化指令,以提取函数内指令的行为.
2) 随着深度学习相关技术的兴起,部分研究者选择了不直接提取函数特征的策略,尝试利用神经网络规避传统特征提取带来的信息丢失的情况.
其中,文献[25]仅靠指令序列和长短时记忆网络(long short-term memory, LSTM)实现了跨平台比对功能.主要通过将不同的汇编转化为特征值,而后利用LSTM训练以完成不同指令集指令对应关系的构建.文献[26]使用神经网络逐字节地提取函数特征.根据函数调用图,提取函数间和模块间(导入函数等)特征.然后,基于这3个特征计算距离用于相似性分析.文献[27]首先提取基本块特征构造函数的特征向量.然后,利用神经网络将其转化为函数的嵌入向量.最后,基于余弦距离来测量2个二进制函数的相似性.文献[28]使用神经网络同时学习基于汇编代码的词汇语义关系和向量表示.仅输入汇编代码以寻找并合并语义关系,根据语义判定函数相似性.文献[29]提出了一种基于自注意神经网络的函数嵌入模型.通过将嵌入向量与具体指令关联,直接用作模型输入,而后依据输出向量进行相似性分析,以表示函数相似性.
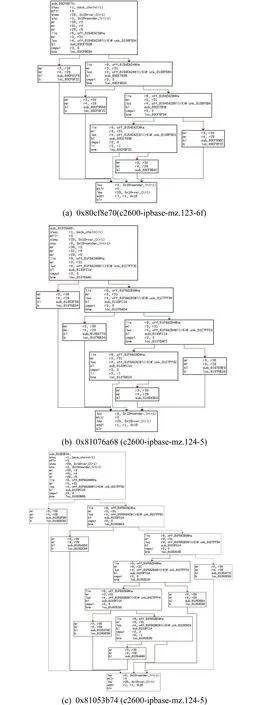
Fig. 1 Three CFGs of Cisco’s firmwares with two versions
3) 部分研究者意识到二进制比对过程中,选择待比对目标函数带来的开销,尝试用不同方法过滤目标函数.
其中,文献[30]提出了一种内联方法用来捕获函数完整的语义,同时,为了解决目标函数数量巨大的情况,引入了3种过滤器过滤目标函数,包括相同库函数、同类型库函数、相似指令类型和函数签名.文献[31]首先基于1组异类特征(包括:指令语义特征、结构特征、统计特征)滤除不相似的函数;再根据不同的执行路径进一步过滤剩余函数;最后基于模糊图匹配识别候选函数.
从上述3个特点不难发现,现有二进制比对领域的相关技术若应用于固件比对,仍具有一定缺陷:
1) 现有研究较少研究过滤器,过滤目标函数主要依靠函数自身的特征向量的相似性.然而,同一固件中往往存在若干完全一致的函数,将导致固件比对过程中的误匹配.以图1为例,其中图1(a)(b)所示函数同构但不匹配,图1(a)(c)函数匹配但不同构.这些误匹配会随着传播算法扩大误匹配范围.
2) 函数相似性判别较为依赖库函数、导入表等信息,部分研究依赖于动态调试,而固件分析往往不具备前文的3个特点.
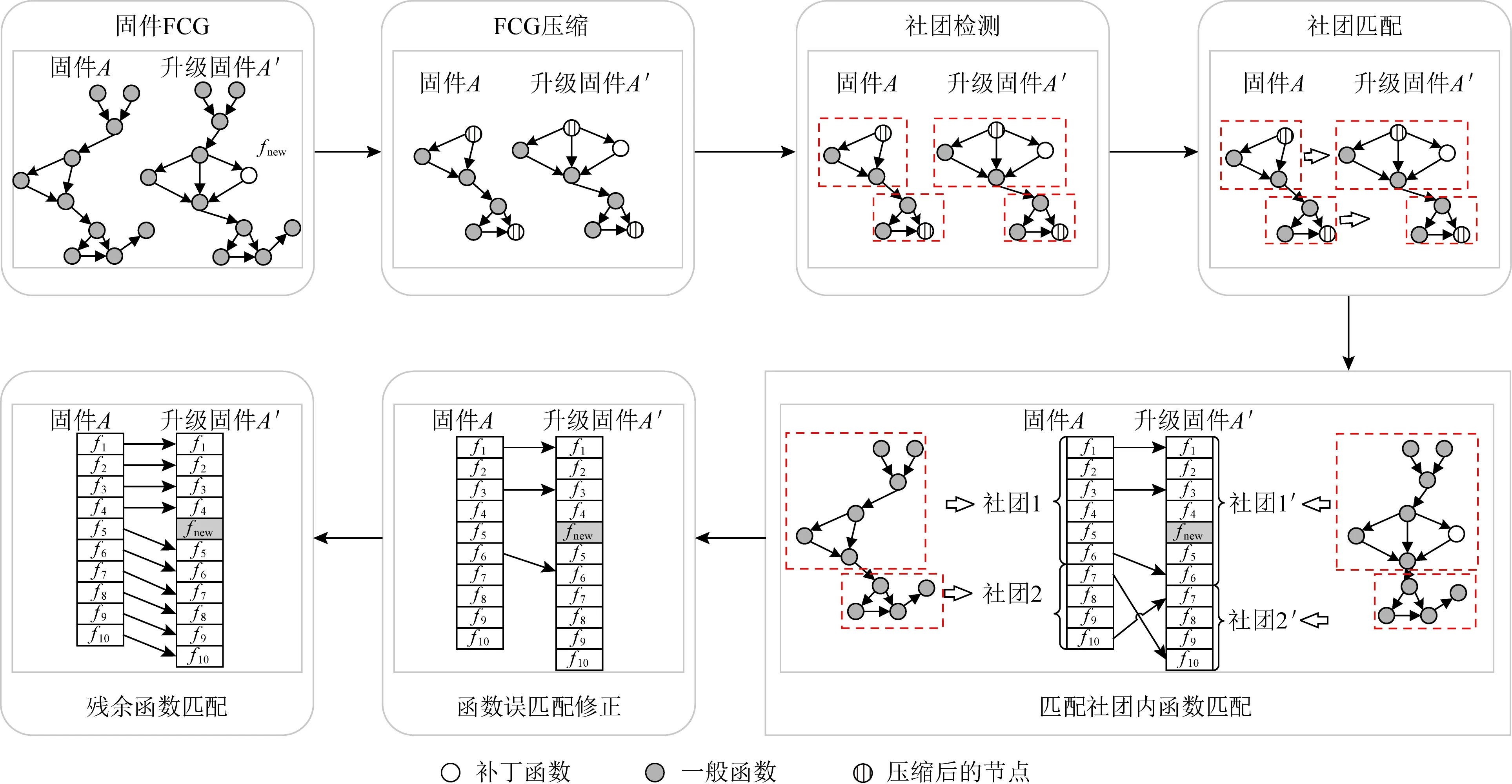
Fig. 2 Method overview of this paper
3) 实验验证对象函数规模较小且偏向于开源程序,不足以暴露研究成果在固件比对领域的缺陷.现有二进制比对的研究中,收集的软件普遍较小,甚至文件大小不足10 KB.部分关于固件的研究,由于固件可以解包,实际分析的文件也相对较小.但,固件中存在以Cisco IOS为代表的一体化固件,此类固件不可解包,文件大小常达到100 MB以上,函数数量几十万.且固件由于厂商的安全性考虑,基本不提供开源代码用于研究.此类场景下,依赖开源代码的分析研究无法适用.
1.2 社团检测技术
社团检测属于网络科学范畴,其主要目的是找到网络中的社团.社团是网络的子图,由网络中的1组节点(顶点)及组内节点间的连边构成,组内节点之间的连接较稠密,而节点与组外节点的连接较稀疏[32].
由于对社团的稠密与稀疏没有定量的划分,因此,不同研究者设计了多种社团检测算法.
其中,文献[33]提出了模块度的概念用以衡量社团划分标准.文献[34]提出了基于模块度和贪婪算法思想的社团检测算法CNM.文献[35]提出了一种层次化的社团检测模型,可用于加权网络,称为BGLL算法(亦称Louvian算法).
此外,文献[36-37]提出了基于派系过滤的社团检测算法.文献[38]提出了连边社团检测算法,通过边的唯一社团属性,以边为单位,构造树图,以此完成社团检测.
1.3 方法概述
针对1.1节中指出的问题,本文使用BGLL算法对固件的FCG进行社团检测,将函数划入不同的社团,以此引导函数过滤,弥补传统过滤器的不足;此外,本文增补了立即数和偏移量特征用以提升函数比对准确率.
本文方法的流程包括2个步骤,如图2所示.
1) 固件社团检测与匹配.包括固件FCG压缩、社团检测与社团匹配.
2) 函数匹配.包括匹配社团内函数匹配、社团内函数误匹配修正、残余函数匹配.
2 可行性分析
文献[32]指出,社团结构是复杂网络一个极其重要的特性,针对不同类型的大规模复杂网络,人们提出了很多寻找社团结构的算法.由此可以看出,社团检测算法主要的工作场景是大规模复杂网络.
本文要使用网络社团检测技术用于引导固件函数过滤,就有必要对固件FCG的性质加以分析,以确定使用此技术是否恰当.如果FCG规模与结构过于简单,使用社团检测算法可能意义不大.例如:对于完全图而言,其结构过于规则,并无使用此法的必要.
直观而言,从固件的FCG中一般可以直接观察到其复杂程度,甚至社团的存在.如图3所示,该图展示了固件c3725-ipbase-mz.124-5的函数调用关系,函数数量20余万.虽然调用图存在多个连通片,但依旧可以观察到最大连通片,其节点规模庞大、调用关系复杂,且有若干社团存在.但理论分析依然是必要的.
在本节中,我们将对样本固件FCG的性质进行分析,以确定社团检测算法用于固件比对的可行性.

Fig. 3 FCG of c3725-ipbase-mz.124-5
2.1 基本定义
在进行详细分析和方法描述之前,本节给出基本符号解释和定义.本文中的图和网络、节点和顶点、边和连边是等价概念.
定义1.函数调用图[39].一个由G=(VG,EG)构成的有向图.其中,VG表示节点集,每个节点对应一个函数,VG={fi|1≤i≤n,i∈},n为函数个数;EG为边集,表示函数调用关系的全集,EG⊆VG×VG,EG由序偶组成,若fi,fj∈EG,则存在fi对fj的函数调用.
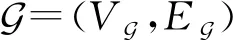
定义3.度.网络中与当前节点直接相连的边的数目称为该点的度,一般使用k表示.对于有向网络,一个节点指向其他节点的边的数量称为出度,记为kout;一个节点被其他节点指向的边的数目称为入度,记为kin.
对于一个网络,式(1)刻画了网络的度分布情况:
P(k)=n(k)/N,
(1)
其中,n(k)表示度为k的节点数量,N为网络节点数量.度数的平均值称为平均度:
k=2M/N,
(2)
其中,M为边数量.
定义4.k壳[40].对于一个图,如果图中已不存在度数小于k的节点,那么,只要反复剔除度数为k的节点及其连边,直至图中不存在度数为k的节点,剩余的图即为k核,而被剔除的节点和连边即为k壳.
定义5.余平均度.若节点fi的ki个邻居的度分别为ki,j,j=1,2,…,ki,则节点fi的邻居节点的平均度为knni,公式为
(3)
其中,i为节点在图内的索引值.
所有度为k的节点的邻居节点的平均度即为k的余平均度,记为knn(k).
定义6.模块度[37].又称模块化度量值,是一种衡量社团划分质量的标准,对于加权有向图,其公式为
(4)
其中,W是网络内所有边权重和,c表示社团的索引值,nc表示社团个数,Wc表示第c个社团权重和,Sc为所有与第c个社团内节点相关联的边的权重和.
定义7.密度.网络的密度定义为网络中实际存在的边数M与最大可能边数之比.
定义8.聚类系数.网络的聚类系数有2种计算方法,本文取其中的社会学定义.其公式为
(5)
其中,N表示节点数量,aij表示节点i和节点j是否为邻居,若为邻居,则aij=1,反之,aij=0.
定义9.同配系数.同配系数反映了节点与其邻居节点的度相关性,其公式为
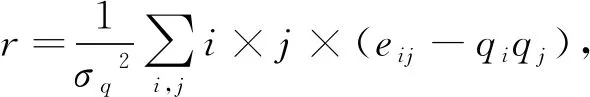
(6)
(7)
其中,eij表示度为i和度为j的节点的连边数占总边数的比例.qk表示余度分布,即随机取节点并随机取该节点的一个邻居节点度为k的概率.r为正表示同配,即度大的点邻居一般是度大的点,反之,r为负表示异配.
定义10.直径.网络中任意2个节点之间的距离的最大值为网络的直径.
定义11.ER随机图.对于N个节点,随机取M对节点连边,构成的图称为ER随机图.
2.2 固件函数调用图性质分析
由于大规模复杂网络并没有定量的衡量标准,只有一些定性的特征.因此,本节将从3个方面分析固件的FCG是否具备复杂网络的特征.
本节选择了Cisco IOS的3个系列1 382个固件进行实验分析(数据集T1,详见5.2节).这是实际研究过程中所遇到的函数规模最大的一类固件,且不开源,无API,具备分析价值.
2.2.1 稀疏性
文献[41]指出,大规模网络的一个共有特征是稀疏性,网络中边数远小于最大可能边数.文献[42]指出,也有许多现实网络中的网络节点数N与边数M,介于线性比例关系和平方关系之间,服从超线性关系,称之为稠密化幂律,如式(8)所示:
M~Nϑ,1<ϑ<2.
(8)
图4绘制了固件的节点数及其对应边数、密度的散点图,展示了Cisco IOS的3个系列1 382个固件的稀疏性.其中,f(x)是对节点数、边数对应关系的拟合,斜率5.445,可见固件的边数与节点数基本服从线性关系.g(x)是对节点数、密度对应关系的拟合,为反比例函数,其密度值随节点数增大而趋近于0.

Fig. 4 Firmware sparsity and density
固件的稀疏性服从线性分布可能受软件开发相关因素影响.开发人员在开发过程中,对于函数间调用和被调用数量存在一个习惯性的分布.若邻居节点过多会导致程序结构复杂,不利于调试;若邻居节点过少,则单个函数的规模变大、功能会出现重复.因此,这种分布并未随着开发对象大小的变化而产生明显差异.
由此可见,固件的FCG具备一种较为特殊而稳定的稀疏性,具备大规模网络的特征.
2.2.2 度分布
文献[43-44]指出现实中的大规模网络的度分布很多符合幂律分布.而复杂网络的研究一般是基于这样的初始条件开展的.文献[41]指出,现实网络度分布虽然很多服从幂律分布,但会出现截断现象,由于度的最大值有限,因此,度很高时幂律分布不成立.
本文根据数据集T1,汇总固件节点信息后,绘制了节点与度数相关的图例,如图5所示:

Fig. 5 Firmware degree distribution diagram
图5(a)反映了节点出度、入度、总度数与节点数量的关系.可以看出,固件中节点度数与节点数量的关系分为2个部分.度数在1 000以下时,近似幂律分布,图5(a)中拟合了直线,大致可以估计度分布的幂律为2.46;当度数大于1 000时,节点数量基本不再随度数明显变化.符合文献[41]的论述,具备大规模网络的特征.
需要说明的是,图5中的节点数量是对1 382个固件的累和,计算单个固件的度分布趋势应当将节点总数除以固件数量.因此,若图中节点个数小于1 382,则在单个固件中的节点量可能不足1.
图5(b)刻画了节点度数与对应节点数量占比的关系.可以看出,固件中约有10%出入度为0的孤立节点,此类节点将无法直接利用网络结构进行匹配,只能依靠自身特征结合函数相对固件基址的偏移范围来进行相似性分析.约有38%的根节点和23%的叶子节点,入度和出度为1的节点也达到了28%和18%,比例较高,这些节点的存在及其规模为网络压缩(3.1节)提供了条件.
此外,通过对度分布进行分析,一些基于调用关系传播的函数匹配问题得以解释.从图5(a)(b)中不难发现,由于度数高于100的节点比例不足1%,可知多数函数度数都在100以内.而在度数区间[3,100]内,在数值相等的情况下,入度节点比例低于出度节点比例.说明多数函数连接的子函数数量可能高于父函数数量.由此易知,对于基于调用关系的函数匹配传播过程,理论上,从根节点向叶节点传播更易扩展传播范围,而从叶节点向根节点的传播更容易降低待匹配目标函数的筛选难度.
根据固件节点的出入度对应关系与节点数量绘制图5(c).可以看出,函数节点的入度比出度更容易出现长尾现象.即节点数量较少,但入度极大.此类函数多为库函数.此现象解释了为何在固件节点入度普遍低于出度的情况下,实际操作中,向父函数方向进行节点匹配传播的时间开销远大于子函数方向.这或许是文献[7]研究[7]不采用被调用关系进行传播匹配的原因.
2.2.3 巨片
文献[41]指出,现实中的大规模复杂网络常是不连通的,但存在特别大的连通片,该连通片包含了网络中相当比例的节点,这种连通片称之为巨片(giant component).
现有复杂网络的研究工作多是基于巨片开展的,因为非同一连通片的节点不存在关联,无法分析其性质.而巨片的节点规模较大,基本可以代表其所处网络的性质.然而,对于多大规模的连通片可以定义为巨片,既往研究并无相关定义.
本文认为,巨片的规模应当是包括相对性和绝对性2个角度的.相对性是指巨片节点规模在所处网络达到一定比例,绝对性是指节点数达到一定量级.本文分析的固件节点数量都在万级以上,只要巨片的节点量达到一定比例,数量上是可以达到绝对性的要求的.
对于巨片规模的相对性.文献[45-46]指出,当ER随机图节点数N→∞,会出现巨片涌现的现象,即,每一个ER随机图都会出现巨片;对于ER随机图巨片节点占比Pgc与平均度k,给出关系式(9).可以理解为,当节点平均度达到k,会存在巨片且巨片包含的节点比例大于Pgc.
Pgc=1-e.
(9)
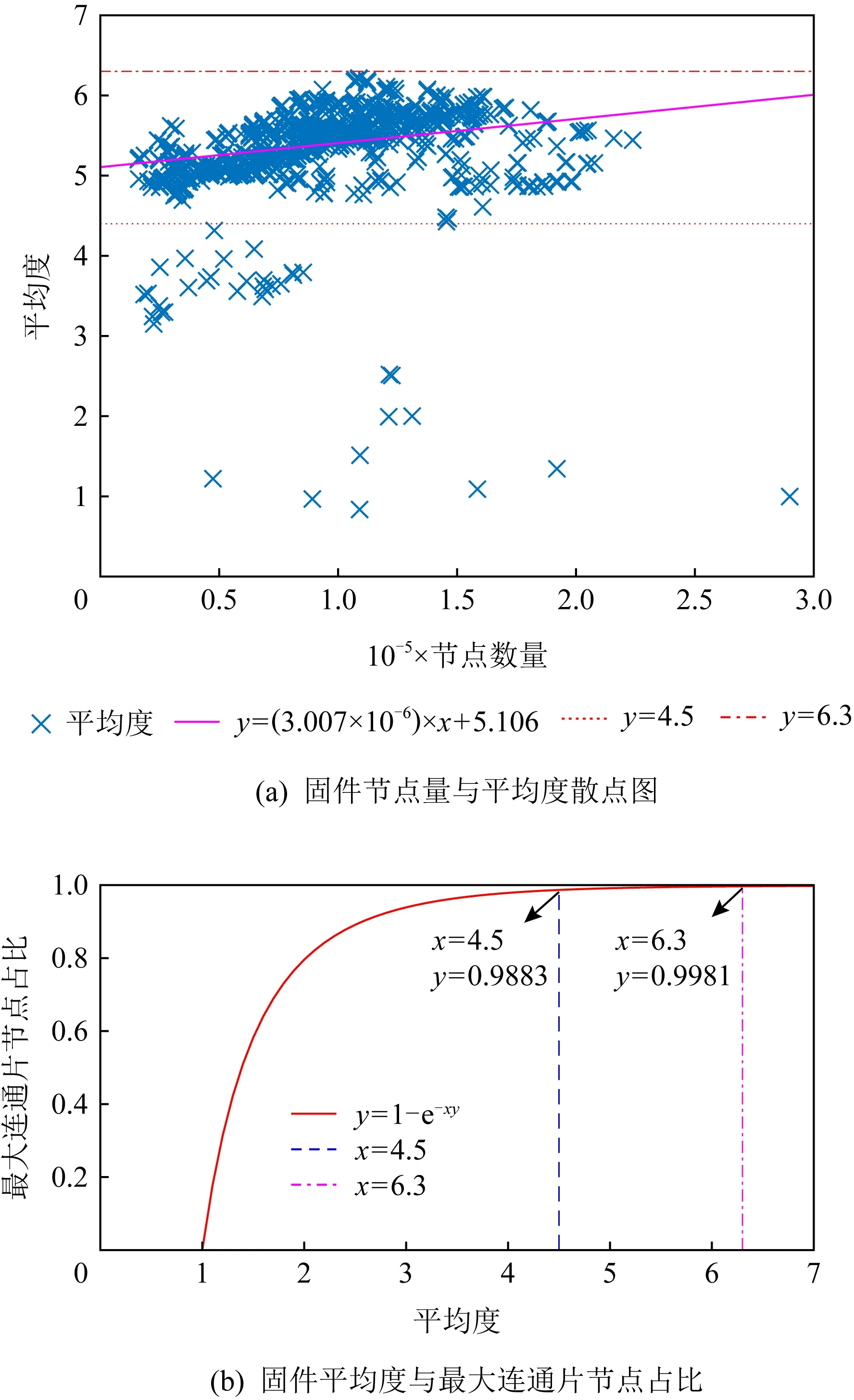
Fig. 6 The oretical derivation of firmware giant component scale
图6(a)绘制了固件节点数量和平均度的散点图,可以看出不同规模固件的平均度主要分布在区间[4.5,6.3]内.(分布在区间外的节点有38个,皆为7200系列2003—2006年发布的固件,其原因是该系列这一时期的固件ELF文件中的代码段和数据段标注为一个段,导致IDA静态解析错误,误将数据区的数据解析为函数,FCG中因而增加了1~5倍的错误节点,以至于平均度被拉低.考虑到后续研究者复现实验可能会遇到同样的问题,本文对此现象如实进行描述,以供参考.)
根据式(9)绘制图6(b),可以看出,若网络的平均度分布的区间[4.5,6.3],其巨片比例至少可以达到98.83%.
由于式(9)是理论推导,其前提条件是N→∞,而实际条件下N为定值,上述分析可以反映网络规模不断扩大带来的巨片规模变化趋势,对于有具体值的具体网络,仍然不够贴切.
为此,本文绘制了固件节点量和最大连通片占比的散点图,如图7所示.从图7可以看出,固件最大连通片的节点比例相当可观,普遍在[0.8,0.95]之间,虽然略低于式(9)的推导结果0.98,但与图5(b)的分析结果相呼应,因为固件中约有1成的节点是孤立节点.由此可知,固件FCG的巨片内密度可能要比预期的高一些.
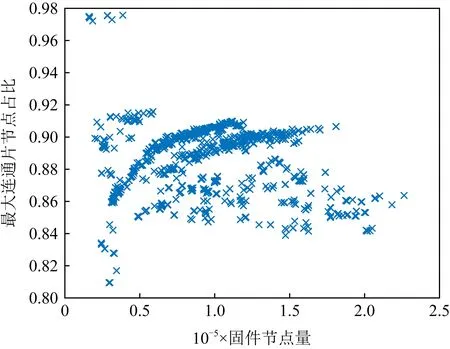
Fig. 7 The proportion of max component node in the firmware
通过上述分析,不难猜想固件的FCG有其特殊性,至少在巨片的规模上,其并不完全符合理论预期.
若要验证此猜想,首先应当分析与固件FCG同等规模条件下随机网络的巨片规模的一般性.为此,本文采用0阶零模型和1阶零模型[41]进行仿真,通过重复生成符合模型要求且和固件具有相似性的随机网络,分析其巨片比例的分布.
其中,0阶零模型是指和原网络具有相同节点数、边数的随机网络,即ER随机图;1阶零模型指和原网络具有相同节点数、度分布的随机网络.
通过将T1数据集中的固件按2种模型要求,各生成了100个随机网络(即进行100次仿真),绘制节点数、最大连通片比例关系图的散点图,如图8所示:
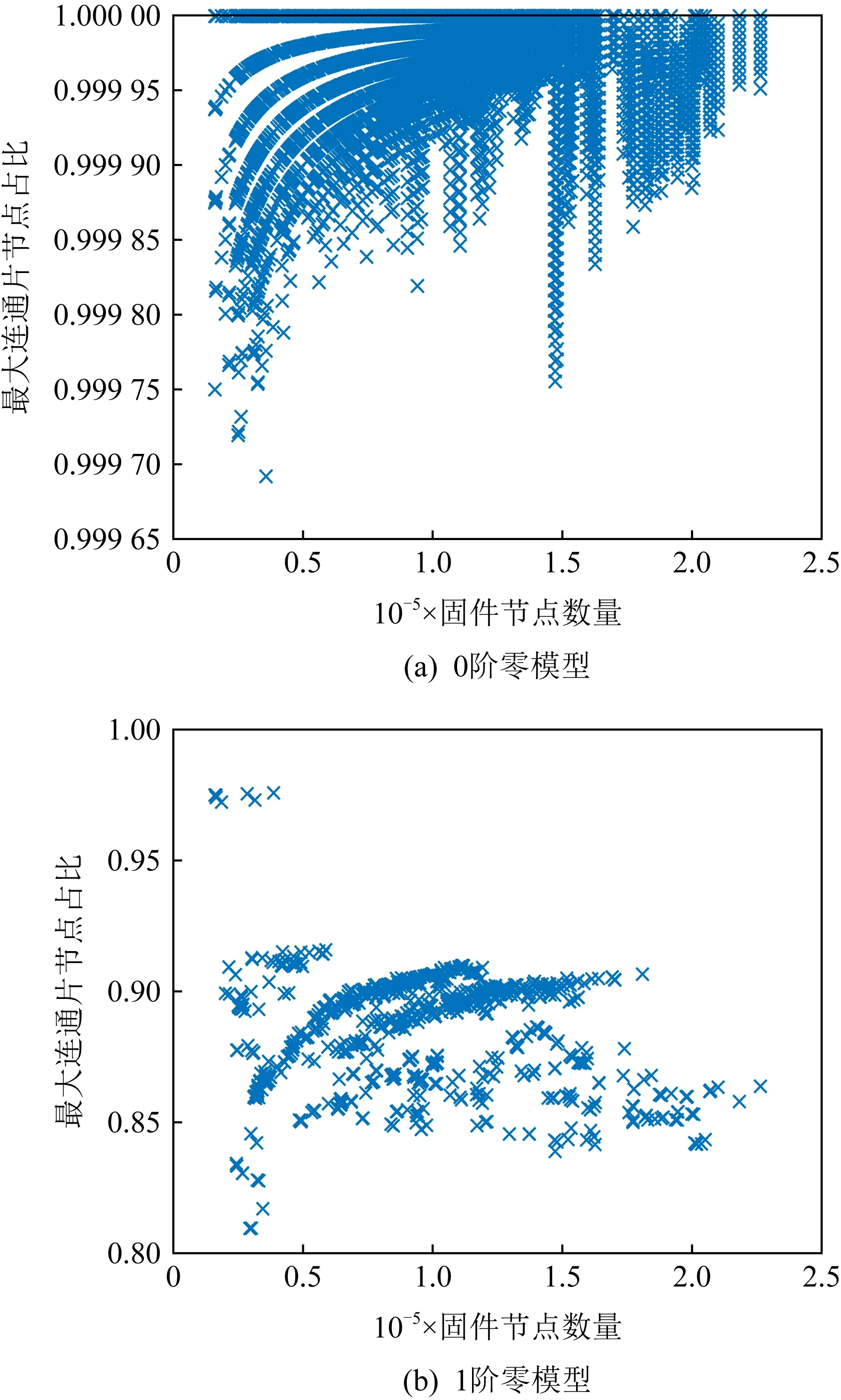
Fig. 8 The proportion of max component node in the simulation network of each 0-order and 1st-order null models
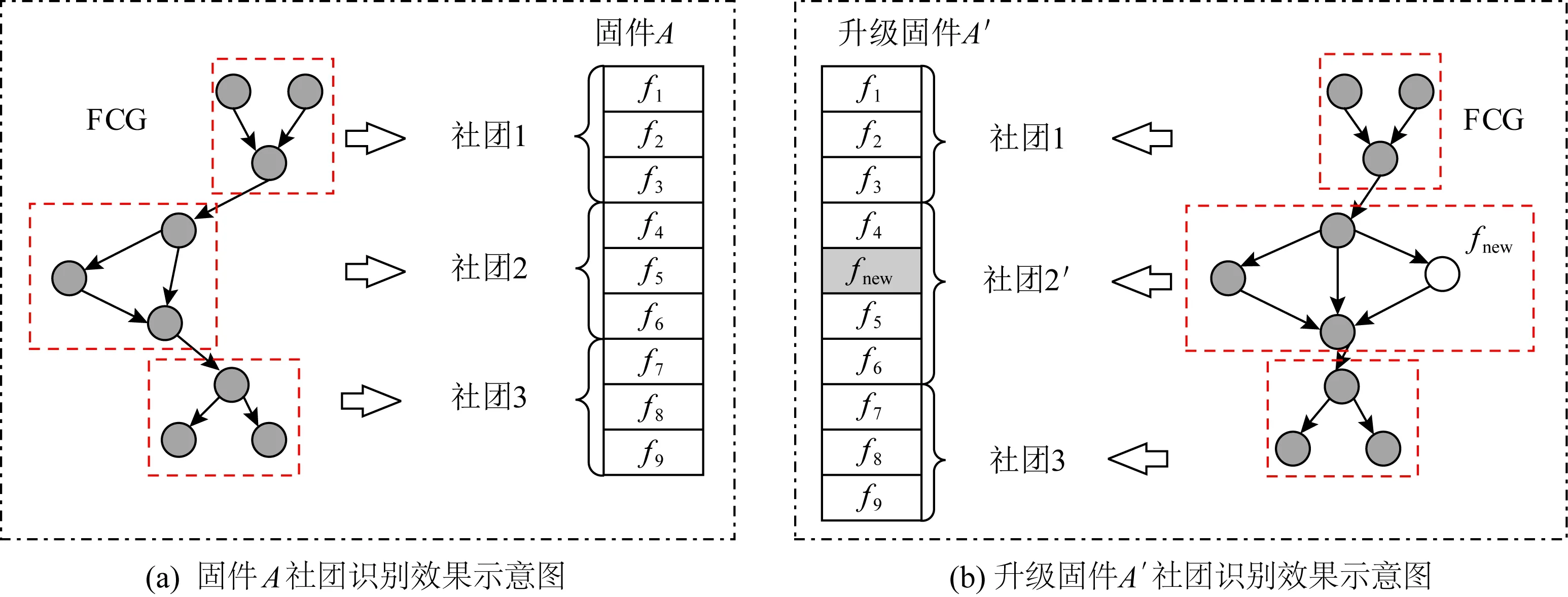
Fig. 9 Comparison diagram of firmware community
图8(a)是0阶零模型仿真结果,可以看出,最大联通片的节点比例在0.99以上,证明本文选择的固件,其平均度与巨片规模的关系符合式(9)的理论推导.而固件最大连通片实际节点比例与理论值产生差异的原因可以通过图8(b)的1阶零模型仿真看出,图8中的最大连通片节点比例与实际固件几乎一致,说明差异的原因是固件的度分布.如果固件FCG中除了孤立节点,存在一定规模的非最大连通片,那么通过1阶模型的重复仿真,一定会产生比例更大的最大连通片.但1阶模型多次仿真都没有产生明显更高或更低的最大连通片节点比例,说明了2点.一是固件FCG巨片的密度高于达到当前巨片比例的标准;二是固件FCG中不存在成规模的非最大连通片.这验证了前述猜想,即固件巨片节点比例达不到理论预期是因为固件中大量的孤立节点.
由此,可得出结论,数据集T1的固件FCG一般存在巨片,其巨片规模会受度分布的影响,但服从一定规律.此类固件的规律是,如果固件FCG中的节点不是孤立节点,那么基本会属于最大连通片,且构成巨片.
3 固件社团检测与匹配
固件社团检测的目的是,通过社团检测,将固件的FCG切割为若干有利于固件比对的子图.只要找到待比较固件间社团的对应关系,就可以缩小函数匹配过程中目标函数搜索的范围,其示意如图9所示.
其逻辑是,程序中往往包含若干功能模块,功能模块内的函数间应该具备比功能模块间函数更紧密的关系.例如:Linux协议栈里可以包括TCP和UDP这2个功能模块,TCP功能模块内的函数基本不会与UDP模块内的函数发生调用关系,但TCP模块内函数则存在较为密切的关系.理想状态下,固件社团检测算法检测到的社团应当是这样的功能模块.
本文设计的固件社团检测与匹配流程包括3个部分:
1) 固件FCG压缩.主要对FCG中节点进行合并,减少后续图分析的工作量.
2) 社团检测.利用BGLL算法对固件FCG中的社团进行检测.
3) 社团匹配.选择社团的统计特征,形成特征向量以刻画社团,依据特征向量进行社团相似性分析.
3.1 面向社团检测的函数调用图压缩
由于本文的应用场景主要是针对规模较大的固件,因此,对函数调用图的规模进行压缩十分必要.通过压缩,减少函数节点的数量,以减少后续分析的工作量.2.2节对图5(b)的分析中已经说明,现有固件具备网络压缩的条件.

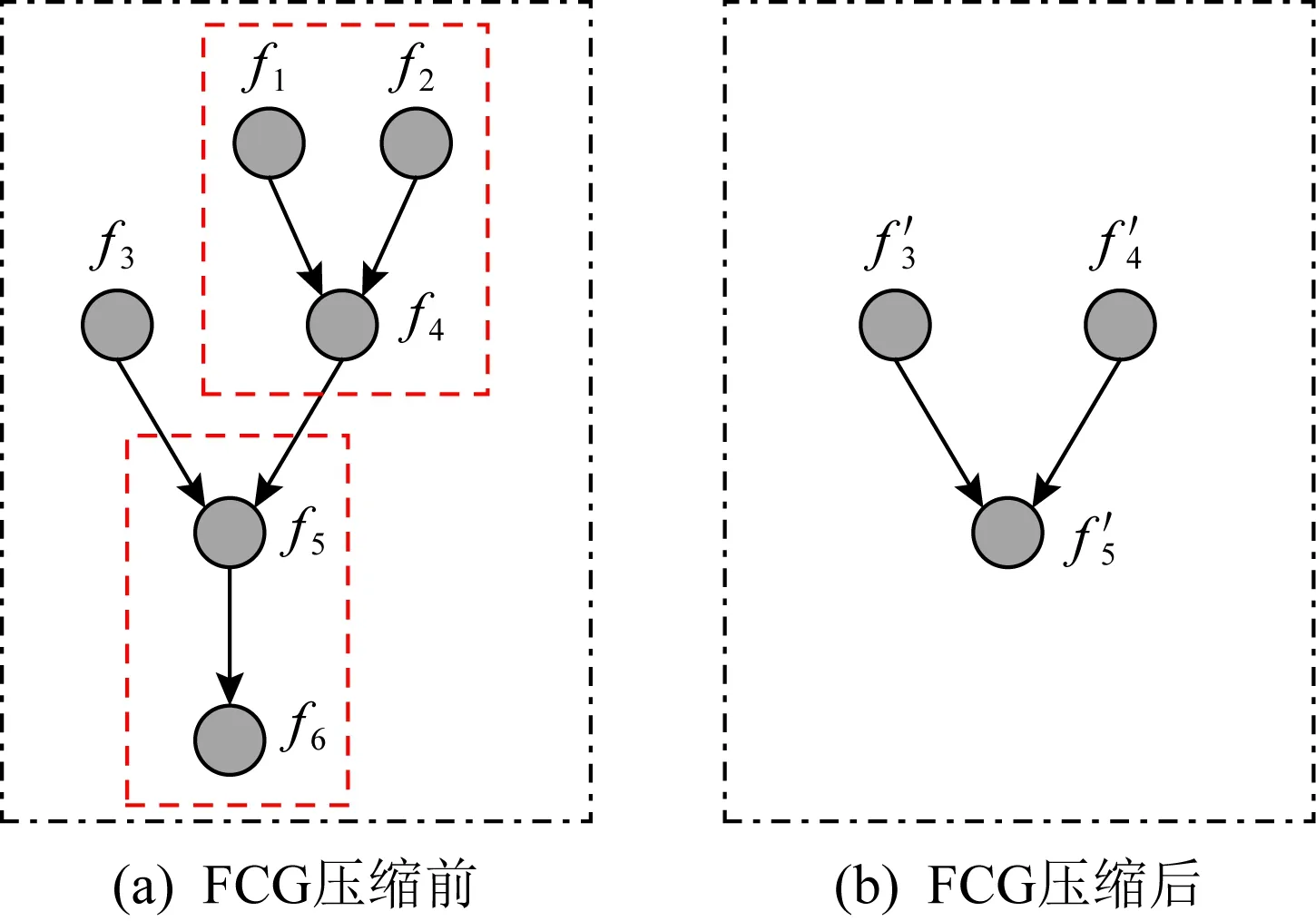
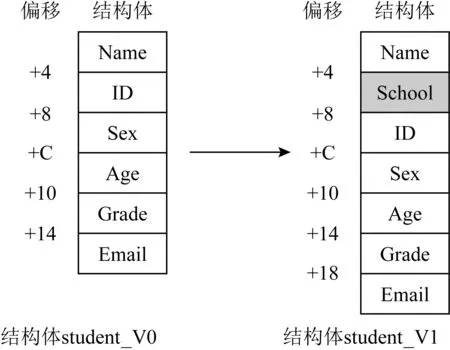
Fig. 10 FCG compression
算法1.函数调用图压缩算法.
输入:函数调用图G;
输出:函数压缩调用图G′.
① foreach_nodeinVG
② ifeach_node.in_dgree==1且
each_node.out_degree>0
③Add_Node_To_Parent(each_node);
/*将当前节点融入父节点*/
④ continue;
⑤ else ifin_dgree==0且out_degree==1
⑥add_flag=true;
⑦ foreach_parentinget_son(each_node)
⑧ ifeach_parent.in_degree≠0或
each_parent.out_degree≠1
⑨add_flag=false;
⑩ break;
/*将当前节点融入子节点*/
算法1的时间复杂度与FCG的度分布和余平均度有关,包括2种情况:
1) 对于子节点融入父节点的情况,其时间复杂度为O(P(kin=1)×n),n为函数数量,P(kin=1)表示节点入度为1的概率.
2) 对于父节点融入子节点的情况,其时间复杂度为O(P(K)×n×knn(K)),其中K表示事件kout=1,kin=0.
算法1仅表示对图进行1次遍历的情况.由于压缩后,图的结构会发生改变,部分节点的度值会由于邻居的融入而发生变化,可能会出现新的符合压缩条件的情况.因此,可以选择迭代压缩.
是否进行迭代压缩应当具体情况具体分析,其关键是不能对后续的社团检测造成过大影响,即,压缩前后社团检测结果出现较大变化.仍以图10为例,如果迭代压缩,最后将仅剩余一个节点,会对社团检测造成干扰.
本文在操作过程中选择了迭代压缩的策略,但这是基于实际分析的,实验表明,本文的实验对象压缩前后对社团检测的影响不大(详见5.4.3节).
此外,对于压缩判定条件,即出入度值的选择问题.逻辑上,是可以选择度数大于1的节点进行压缩的.但本文选择前述条件有3个原因:
1) 度数为1的叶子节点和根节点在社团检测过程中会归入其邻居节点的社团,详见式(10)~(12).因此,此类节点压缩不会对社团检测产生干扰.
2) 选择入度为1的节点进行合并,而不仅仅选择入度为1的叶子节点,主要是为了对抗固件升级过程中的函数再封装现象.即,一个调用关系中插入了新的节点,且新节点仅与原调用关系的2个节点存在调用/被调用关系,与其他节点不存在此关系.
3) 入度为1的节点,表示该函数仅为其父函数提供服务,基本排除库函数的可能.因此,对其进行压缩符合函数之间的功能关联性.
3.2 社团检测
本文选择BGLL算法[37]用以对FCG进行社团检测.BGLL算法处理的对象是连通图,而FCG一般是非连通图,故不能对整个FCG直接进行社团检测.鉴于第2节分析得到的固件FCG性质,固件FCG内的最大连通片多是巨片(如图7所示),节点若非孤立节点则基本属于巨片.本文选择FCG的最大连通片作为社团检测的分析对象.其算法分为2个阶段.
阶段1流程为:
1) 初始化目标网络,假设所有节点为独立社团.
2) 对于任意相邻节点fi和fj,计算将节点fi加入fj所在社团是对应的模块度增量ΔQ.
3) 计算节点fi与所有邻居节点的模块度增量,并选择最大项ΔQi,max.
4) 若ΔQi,max>0,将fi并入其邻居节点所属社团,否则保持不变.
5) 重复执行2)~4)步,直到无法合并节点.
阶段2需要根据阶段1的结果构造新网络,该网络的节点为阶段1检测出的社团,节点连边权重为社团连边权重和.而后利用阶段1的方法对新网络再次进行社团检测.重复阶段1的5个步骤,直至无法检测出新的社团.
模块度增量ΔQ,公式为:
ΔQ=Qnew-Qold,
(10)
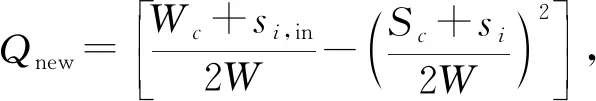
(11)
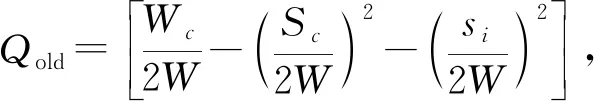
(12)
其中,c为目标社团的索引值,si表示节点fi的强度,即节点fi的连边权重和.si,in表示节点i的入边权重和.
BGLL算法适用于固件FCG分析的场景.首先,BGLL算法的处理对象是有向加权图,用此法分析FCG丢失信息相对少.其次,BGLL的过程是迭代的.单次社团划分一定程度上割裂了社团间的关联,而BGLL通过迭代可以得到节点的多重社团归属,使得节点可以关联到比单次划分更多的节点,有利于后续节点匹配工作的开展.
由于BGLL算法是迭代处理,在指定迭代次数为c的条件下,其时间复杂度应当为O(2×c×m),其中,m是边的数量.由此可见,其时间复杂度与节点数量无直接关联.
对于社团检测的效果,5.4.2节实验表明,BGLL算法可以将固件75%的节点进行归类,找到所属社团.
3.3 社团匹配
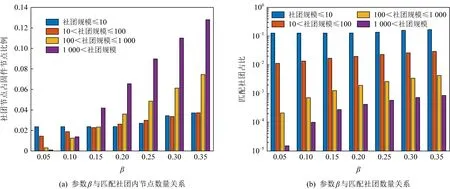
社团匹配的目的是找到固件间社团的对应关系,以对后续函数匹配提供支撑.由于社团涉及的节点数量较多,应当尽可能保证匹配准确,避免误匹配.而对于过小的社团,由于其特征易受节点规模变化影响等多种原因,不进行社团匹配(本文中认定节点个数小于10的社团为小社团,分析见5.4.2节).
本节主要阐述3个问题,社团表示方法、社团差异度量方法和目标社团过滤方法.
3.3.1 社团表示方法
社团是FCG的子图,因此从图的角度选择特征对社团加以刻画有其合理性.因此,社团表示方法的本质就是子图的表示方法.
本文选择了6个特征:
1) 社团节点数,反映社团的规模.
2) 社团密度,反映社团内边的稀疏性.
3) 聚类系数,反映社团内节点的紧凑程度.
4) 同配系数,反映社团内节点的余度分布趋势.
5) 直径,反映拓扑结构.
6) PageRank[47]值累和,反映整个社团内节点在FCG中的重要性.
上述6个特征中,前5个依据定义即可理解.现对第6点加以说明.
PageRank值累和,就是利用PageRank算法求得各个节点在FCG中的值,而后将一个社团内的所有节点的PageRank值求和,以表示该社团的重要性.
PageRank是一种衡量网页重要性的算法.由于该算法原始版本存在悬挂点的问题.本文使用的是一种修改后的PageRank算法,其流程为:
1) 初始化,对节点数为N的FCG中各个节点进行PageRank值(记为PR值)赋值,赋值为1/N.
2) 第h轮的PR值依据第h-1轮的PR值求得.每个节点的PR值,在下一轮运算中,首先通过比例因子α进行缩减,缩减的部分均分给所有节点;再根据出边的权重占当前节点出边权重和的比例,将未缩减部分分配给各子节点.对于节点i,PR值为
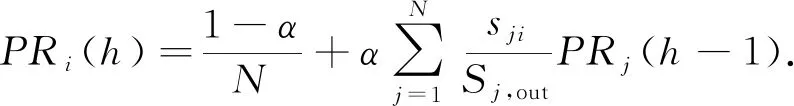
(13)
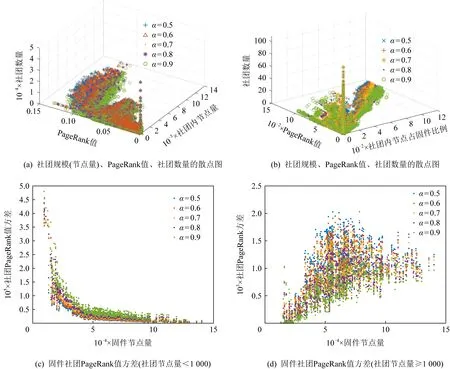
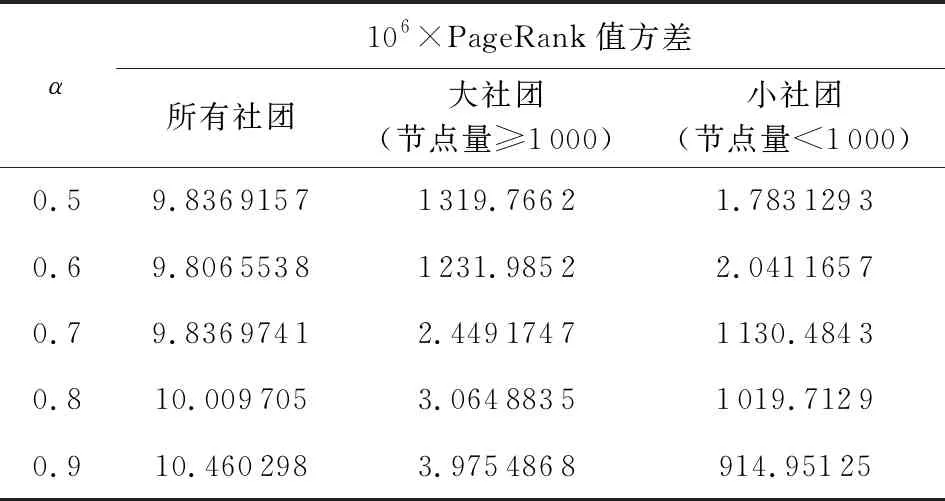
由于缩减比例α需要根据实际情况调整,并无定值,早期研究推荐α=0.85,本文在5.4.4节中对于适用于固件分析的α值进行了实验.依据实验结果,选择α=0.9作为后续分析的指定参数.
PageRank值累和对于社团表示十分重要,是上述6个特征中唯一可以反映社团外节点信息的特征,其信息来源可以涵盖到根节点.若一个固件内检测出同构的社团,则只能根据各社团在整个网络的价值差异加以区分.如Cisco IOS中TFTP,ICMP等功能模块常有独立的内存处理模块(memset_s,memcpy_s等函数),这些内存模块基本都是同构的(其原因可能是静态链接或者拷贝代码).此时,对内存模块的区分可以依靠PR值.
3.3.2 社团差异度量
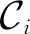
Diff(Ci,Cj)=(μ1,μ2,…,μ6),
(14)

(15)
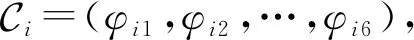
(16)
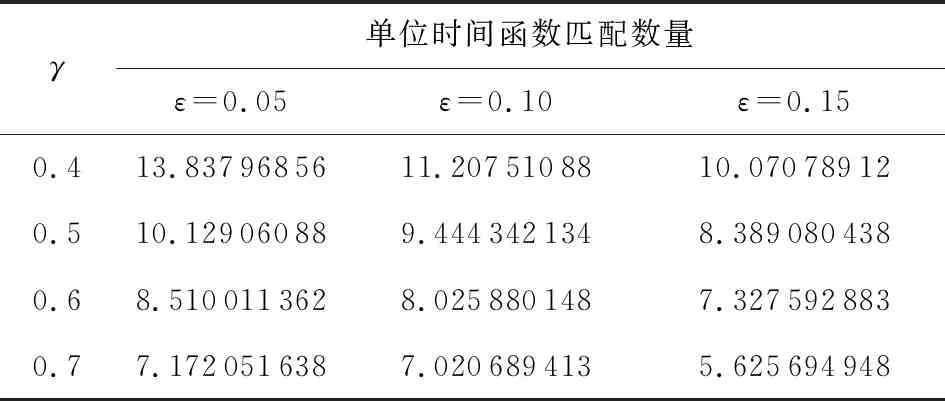
其中,φih表示社团Ci的第h个特征,h∈,0 3.3.3 目标社团过滤 目标社团过滤的目的是根据社团差异度确定社团的匹配关系. 由于不同的固件会存在函数数量和调用关系的不同,因此,即使具有对应关系的函数,其所属社团也常会存有一定差异性.而社团匹配结果影响到后期节点匹配的结果,应当选择较为保守的匹配策略.故既要允许匹配社团有一定差异性,又要避免误匹配,本文使用的策略为: 对于待比较固件A,B,现有社团Ci∈A,Cj∈B,若其差异度Diff(Ci,Cj)满足μi,j,h<β,h∈,0 在实际操作过程中,若固件本身相似性较低(如待比较固件的函数规模差异较大),可以适当放宽PR值特征的差异度衡量阈值,或者依据PR值大小排序后的索引值进行差异度衡量. 在5.4.7节,本文将对β的选值进行实验分析,实验表明β=0.35较为理想. 根据第3节的方法可以获取固件中部分社团的对应关系,但并未进行函数匹配.本节将阐释基于匹配社团的函数匹配方法. 首先,本节将介绍函数相似性度量方法,说明新引入的特征. 而后,阐释利用匹配社团引导函数匹配的方法.其流程包括:匹配社团的函数匹配、误匹配函数修正、残余函数匹配3部分.其中,匹配社团的函数匹配主要寻找匹配社团内的匹配函数;误匹配函数修正主要针对匹配社团的误匹配节点进行修正;残余函数匹配主要针对无社团节点、非匹配社团节点、匹配社团未匹配节点3类进行匹配处理. 对于函数fi和fj,本文计算其相似性: (17) 其中,Popc表示函数操作码相似性,Popn表示操作数相似性,Pcall表示调用关系相似性.w1,w2,w3是其权重,本文选择的权重为300,80,100. 权重选择的一个主要考量是,如果特征在不同版本的固件中具有稳定性,则权重应当相对高;反之,如果特征易受版本变化影响,应当适当降低其权重. 对于权重的具体参数,本文不再进行实验分析.一则本文的重点不在于单点函数相似性的计算方法而在于对新特征的选择;二则对于函数相似性度量的权重选择工作,前人已经有过研究,方法上并无改进,且当前参数的实验效果已经较为理想. 4.1.1 操作码相似性 对于函数操作码相似性,本文选择最长公共子序列(longest common subsequence, LCS)算法进行度量,而后计算LCS长度与最大函数长度的比值,作为操作码相似性.其公式为 (18) 4.1.2 操作数相似性 操作数相似性包括2部分,偏移量相似性Poff和立即数相似性PImmi.其计算公式为 Popn=max(Poff,PImmi). (19) 实际操作中,也可以使用算术平均或加权平均的思路,如式(20): (20) 本文较为推荐式(19),其原因在于,操作数值随固件版本变化而变化的情况相对常见.因此,若出现操作数相似度较高的情况,则函数可能较为相似.此时,若用加权平均的思想处理操作数相似性问题,将可能降低此特征的价值. 此外,如果分析了偏移量相似性和立即数相似性所反馈的现实意义,就可以理解,加权平均的思路是对函数同时在2个方面的相似性存在要求,这是一种较为苛刻的构想. 实际运算中,函数相似性Sim(fi,fj)的值也会因为Popn值较低而受到影响,在进行匹配函数筛选时需要避免赋予过高的权重(详见5.4.10节). 4.1.2.1 偏移量相似性 此处偏移量是指汇编指令中相对于寄存器的偏移值.以PowerPC语句为例,lbz r9,0x8F(r3)中,0x8F就是相对于寄存器值的偏移量. 偏移量反映了结构体信息.对于固件比较而言,在不同版本的固件中,匹配函数的结构体应当是保持稳定的.结构体中成员的偏移量应当是固定的,即使有成员增删,偏移量也应当是整体性的增大或减小,如图11所示: Fig. 11 Examples of structure changes 因此,对于函数fi的偏移量集合Soff(fi),函数fj的偏移量集合Soff(fj),偏移量相似性Poff的计算流程为: 1) 计算偏移量的均值Eoff(fi),Eoff(fj). (21) yh=xh-Eoff(fi),xh∈Soff(fi). (22) 3) 利用Jaccard指标J计算集合相似性,并按式(23)求得Poff. (23) (24) (25) 4.1.2.2 立即数相似性 立即数在函数中会反映一些特定信息.如:Cisco IOS中用0xDEAD表示异常,HTTP协议处理模块中立即数8080表示端口,指令解析器中使用字母的ASCII码表示指令的首字母缩略. 对于函数fi的立即数集合SImmi(fi),函数fj的立即数集合SImmi(fj),本文使用Jaccard指标J计算立即数相似性PImmi: PImmi=J(SImmi(fi),SImmi(fj)). (26) 4.1.3 调用关系相似性 对于一个存在m个父函数的函数fi,根据函数起始地址在固件中的先后顺序可以由小到大获得父函数的索引值,根据函数索引排序父函数,计算临近父函数之间的索引距离spi,可以构建具有m-1个元素的集合SPindex(fi)={sp1,sp2,…,spm-1},用以表示函数. 因此计算fi和fj父函数相似性: Pparent=J(SPindex(fi),SPindex(fj)). (27) 同理,可以计算出子函数相似性Pson.调用关系Pcall,由两者计算算术平均得出. 3.3.3节提到匹配社团之间允许差异存在.匹配社团并不代表社团同构,也不意味着社团节点数量相同.因此,并非社团内所有函数都存在匹配对象,在进行匹配社团间的函数相似性计算后,应当筛选匹配函数对.此外,虽然进行了社团划分,但依然存在一定比例的社团,其节点数量较大,甚至达到上万个节点(见5.4.2节).有鉴于此,匹配社团的函数匹配工作需要从候选函数过滤和匹配函数筛选2方面开展. 候选函数过滤的目的是在每个社团中找到1组候选函数节点用于比较,以降低匹配函数的筛选范围.匹配函数筛选则是要对2组候选函数节点进行相似性分析,并挑选出匹配函数. 对于匹配社团Ci和Cj,其函数匹配算法如算法2所示. 算法2.匹配社团函数匹配算法. 输入:匹配社团Ci和Cj; 输出:匹配节点集合Matched_Node. ①Max_k,I_ksdic,J_ksdic=Get_Kshell(Ci, Cj);/*对社团进行k壳剥离,完成初始 过滤,并提取k壳最大值*/ ② for (h=Max_k;h>0;h--) ③m_nodes=MatchGP(I_ksdic[h], J_ksdic[h]);/*从候选函数中挑选 匹配节点*/ ④Matched_Node.append(m_nodes); ⑤ end for ⑥Neighbors=Get_Neighbor(Matched_Node); /*根据邻居节点进行候选函数过滤*/ ⑦ whileNeighbors≠None ⑧m_nodes=MatchGP(Neighbors); /*从候选函数中挑选匹配节点*/ ⑨Matched_Node.append(m_nodes); ⑩Neighbors=Get_Neighbor(Matched_Node); 候选函数过滤,首先根据k壳值对2个匹配社团的节点进行划分,取k壳值相等的节点构建2个候选函数组,并对2组间的函数逐对分析相似性(5.4.5节对社团的k壳值分布进行分析). 在确定部分匹配节点后,候选函数过滤将基于调用关系,选择匹配函数的邻居节点构建候选函数组,并对2组间的函数逐对分析相似性. 匹配函数筛选是在已经计算过候选函数组间节点相似性的情况下进行的.对于函数组F1,F2,若函数fi∈F1,fj∈F2和其他函数fi′∈F1,fj′∈F2,fi≠fi′,fj′≠fj,满足3个条件,则认为函数fi与fj匹配. Sim(fi,fj)>γ, (28) Sim(fi,fj)-Sim(fi,fj′)>ε, (29) Sim(fi,fj)-Sim(fi′,fj)>ε. (30) 对于阈值γ和ε,本文将进行实验并于5.4.8节和5.4.9节讨论,取γ=0.5和ε=0.1是效果最好的值. 此外,由于本文采用的是BGLL算法,在完成低层次社团的节点匹配工作后,可以利用节点所属的高层次社团,在更大范围内挑选候选函数组进行函数匹配. 程序在编译过程中,如无特殊需求,服务于相同功能模块的函数往往存放在较为接近的内存区间.因此,如果社团内包含同一功能模块的函数,社团内函数地址应当较为接近.通过5.4.6节的实验可以发现,社团内节点确实分布在相近的地址区间. 基于4.3节所述构想和实验结果,本文提出了基于地址分布的误匹配函数修正方法,用以修正匹配社团函数匹配阶段的误匹配问题. 定义12.未匹配区间.对于固件A,B,有函数fi∈A,fj∈A,i 误匹配函数修正流程为: 1) 提取固件中的未匹配函数区间. 2) 误匹配函数修正.对于1对未匹配区间(i,j)和(i′,j′),若j-i<τ且j′-i′<0,则将未匹配区间边界的匹配函数重置为未匹配状态. 3) 反复执行上述2个操作,直到匹配函数数量不再变化. 对于2个待比较固件,如果发生误匹配,有函数匹配了对应功能模块外内的函数,那么该函数与其相邻函数会形成未匹配区间,如流程2中所示. 当然,固件中也会有功能模块因为升级而出现整体性位置迁移的情况.此时功能模块的边界会产生和误匹配相近的情况,如图12所示.其中,由于fi与节点fh的误匹配,形成了1对未匹配区间(i,i+1)和(h,i′+1)且h>i′+1.而对于社团整体性迁移,同样带来了1对未匹配区间(j+1,l-1)和(j′+1,l′-1)且j′>l′,两者成因不同而情况相似. Fig. 12 Examples of matching false positives 因此,误匹配修正使用τ对修正范围进行限制,避免把发生整体性位置迁移的功能模块的匹配函数全部重置.另外,误匹配修正工作仅在匹配社团的节点匹配工作之后进行,不在其他阶段开展,避免出现因修正带来匹配-重置的死循环. 本文中τ=10,对选值的大小不再进行比较分析.τ=10的合理性在于,若1个匹配社团存在跨度大于10的相邻匹配函数,而另一社团对应的匹配函数之间相距较远甚至发生错位,一般说明2个函数不属于同一功能模块.对于修正后的未匹配区间大小,于5.4.11节进行实验分析. 经过误匹配修正的固件仍然存在一定量未匹配函数,主要包括:匹配社团的未匹配节点、未匹配社团以及无社团节点.此时,固件被划分为若干个未匹配区间,若未匹配区间的大小较为合理,可以直接利用未匹配区域构造候选函数组完成剩余的匹配工作,对于残余函数节点的类型不再区分处理. 对于固件A,B,其残余函数匹配算法如算法3所示. 算法3.残余函数匹配算法. 输入:固件A,B; 输出:匹配节点集合Matched_Node. ①Add_Matched_Num=-1; ② whileAdd_Matched_Num≠0 ③U_Region=Get_U_Region(A,B); /*获取未匹配区间*/ ④N_match1=MatchGP(U_Region); /*基于候选函数组统计特征筛选*/ ⑤U_Region=Get_U_Region(A,B); /*获取未匹配区间*/ ⑥N_match2=Match_contin(U_Region); /*基于地址连续筛选*/ ⑦Matched_Node.append(N_match1, N_match2); ⑧Add_Matched_Num=max(len(N_ match1),len(N_match1)); ⑨ end while 候选函数组统计特征筛选采用和匹配社团节点匹配方法中相同的筛选策略,条件如式(28)~(30). 基于地址连续的筛选策略每次仅比较与匹配节点相邻的未匹配函数.具体而言,对于1对未匹配区间(i,j)和(i′,j′),若函数fi+1,fi′+1未匹配,且满足式(31),则认为两者匹配.fj-1,fj′-1判定匹配的条件一致. (31) 本节将对第3节和第4节提及的若干问题进行实验并说明,实验包括12个:函数调用图压缩效果、社团检测效果、FCG压缩对社团检测的影响、社团规模与PageRank值关系及参数选择、社团内节点的k壳值分布、社团内节点地址分布的局部性、社团匹配的参数选择、函数匹配的参数选择对匹配效率的影响、函数匹配的参数选择与Bindiff比较实验、操作数相似性与函数相似性关系、未匹配区间长度分布、匹配社团对节点匹配的贡献. 本文实验环境为Win10 x64操作系统,Intel Xeon W-3175X CPU@3.10 GHz处理器,384 GB内存,Samsung T5 SSD 2TB硬盘.使用软件IDA pro[48],进行辅助分析.实现语言是Python 3.7 x64. 本文测试主要使用2个数据集: 1) 数据集T1. 1.1节指出了既往研究使用开源软件编译数据集存在软件规模较小的情况,不适用于验证固件比对技术.因此,基于Cisco C2600(640个)、C1800(301个)、C7200(441个)系列共计1 382个固件,建立此数据集. 2) 数据集T2.从数据集T1每个系列固件中抽取80对固件,构成3组共计240对固件.本数据集用于评估同系列固件的社团匹配和节点匹配效果,共计21 990 414对函数需要进行匹配(每对固件取函数数量较小者进行统计). 进行固件比对分析前,需要对固件进行解析.主要依靠IDA pro进行反汇编,并提取函数比对需要的基本信息.本文对收集的1 382个固件进行了预处理,包括为Bindiff比对提前生成Binexport文件. 5.4.1 函数调用图压缩效果 本实验对数据集T1的所有固件使用3.1节中的函数调用图压缩算法进行压缩后,用压缩率对压缩效果进行衡量. 定义13.压缩率(compression rate).压缩率PCompression为 PCompression=N′/N, (32) 其中,N′是固件压缩后的节点数量,N是压缩前的节点数量. 根据固件节点数量和其进行执行压缩算法后的压缩率绘制散点图如图13所示.从图13中可以看出,对于现有样本,算法1的压缩率普遍在[0.55,0.7]区间.压缩算法为后续的社团检测降低了至少30%的节点规模. Fig. 13 Compression rate of FCG compression algorithm 5.4.2 社团检测效果 本实验对数据集T1的所有固件在使用FCG压缩后,利用BGLL算法进行社团检测,社团检测效果如图14所示. 图14(a)用散点图刻画了各个固件中无社团节点和小社团节点(社团节点量小于10)的占比;横轴为进行FCG压缩后的固件节点量,纵轴为节点占固件比例. 图14(b)用散点图刻画了各个固件通过BGLL算法检测出的社团数量以及各固件内小社团(社团节点量小于10)数量的占比.横轴为进行FCG压缩后的固件社团量,纵轴为小社团的数量占比. 图14(c)用条形图刻画了社团节点量在不同范围的社团,其数量占据所有固件社团的比例.横轴为社团数量占比,纵轴为节点个数在不同范围的社团. 图14(d)用条形图刻画了社团尺寸相对其所属固件在不同比例范围的社团,其社团数量占据所有固件社团的比例.横轴为社团数量占比,纵轴为社团内节点量与社团所属固件节点量的比值. 图14(e)用散点图刻画了固件规模、社团大小、社团数目的关系.x轴为进行固件FCG压缩后的节点量,y轴为社团内节点量,z轴为相应社团的数量. 图14(f)用散点图刻画了固件规模、社团相对大小、社团数目的关系.x轴为进行固件FCG压缩后的节点量,y轴为社团内节点量对其所属固件节点量的比值,z轴为相应社团的数量. Fig. 14 BGLL algorithm community detection effect 通过分析图14,可以得出3个结论: 1) 社团检测算法可以为使固件中75%以上的节点找到所属社团. 从图14(a)中可以看出,无社团归属的节点一般占固件总结点数的15%~25%,由此可知,固件节点的至少75%在二进制比对的函数匹配过程中,可以根据固件社团检测结果对匹配对象进行过滤.如果考虑到固件普遍有10%左右的孤立节点,也可知最大连通片中无社团归属节点的比例不到固件总节点量的15%.此外,鉴于社团规模小于10的社团,其节点量约占固件总结点量的10%~20%.可知,本文虽然排除了小社团(节点量小于10)进行社团匹配的情况,但仍可以保证固件55%以上的节点在二进制比对过程中对匹配对象形成有效过滤. 2) 不对小社团进行社团匹配,降低了工作开销,但基本保证了节点比对效果. 从图14(b)中可以看出,节点量小于10的小社团其数量达到固件总社团数的70%以上,不对其进行社团匹配减少了70%的工作量.而根据图14(a)可知,即使不对小社团进行社团匹配,仍然能保证固件至少55%节点其所属社团能够参与到社团匹配过程中. 3) 如果节点所属社团存在匹配社团,那么在节点匹配过程中,社团检测算法将该节点的匹配节点搜索范围减少了近90%. 通过图14(c)~(f)不难发现,99%以上的社团内节点量小于500、社团规模占其所属固件节点比例1%以下.说明社团检测算法检测出的社团,从减少节点匹配的目标节点搜索空间这一目的而言,具备较好的效果.而社团检测算法检测出的社团,其节点量最大不到15 000,占所属固件节点比例不到12%.由此可知,该社团内节点在完成社团匹配进行匹配节点搜索时,最多仅需搜索固件12%的节点. 此外,通过图14(e)(f)不难发现,固件中存在一些社团其规模大致随固件规模增大而增大,比例约为0.095和0.06.这类社团可能是固件的核心功能模块,用以将固件不同的功能模块联系到一起,但通过比例可以看出此类社团占比较少.而其他社团则受固件规模变化影响较小,相对具有稳定性,有利于开展不同规模的固件间的社团匹配工作. 5.4.3 FCG压缩对社团检测的影响 本文于3.1节提出了压缩FCG以降低社团检测时间开销的方法.FCG压缩会改变其拓扑结构,对社团检测结果会造成影响,因此需要分析FCG压缩带来的影响大小. 定义14.压缩前社团稳定率.对于FCG压缩前检测出的社团Ci,其节点量为|Ci|,有FCG压缩后检测出的社团Cj,2个社团交集的节点量为|Sc_inter,i,j|,且对于FCG压缩后检测的任何社团Ch,Ch≠Cj,有|Sc_inter,i,j|>|Sc_inter,i,h|,则压缩前社团稳定率PB_S满足: (33) 同理,易知压缩后社团稳定率PA_S,不做赘述. 本节设计实验如下.使用数据集T1,分别在压缩前和压缩后进行BGLL社团检测.绘制压缩前社团稳定率和压缩后社团稳定率的累积分布散点图,如图15所示.其中,x轴为社团相对大小(社团节点量比固件节点量),y轴为社团稳定率(红色叉为压缩前社团稳定率、蓝色点为压缩后社团稳定率),z轴为社团稳定率的累积分布值(小于y轴社团稳定率的社团数量占比). Fig. 15 Cumulative distribution diagram of community stability rate before and after compression 从图15中可以看出,压缩前社团稳定率低于50%的社团累积分布约为20%,意味着80%以上的压缩前社团可以保证50%以上的节点压缩后仍处于同一社团,而压缩后的社团可能包含来自多个社团的不同节点. Fig. 16 Relationship between community size and PageRank value 由此可见,FCG压缩会使社团规模更大,但对压缩前的社团破坏有限,可以基本保证主体社团结构的稳定. 5.4.4 社团规模与PageRank值关系及参数选择 本节探讨社团规模与PageRank值的关系,主要验证PageRank值是是否能在社团匹配过程中用于区分社团.基于这样的目的,对PageRank算法的缩减比例因子α的选择进行实验分析,挑选效果最好的比例因子. 本实验对数据集T1的所有固件在压缩并利用BGLL算法检测社团后,使用PageRank算法,根据社团内节点的PageRank值求和得到社团的PageRank值.在α取0.5,0.6,0.7,0.8,0.9的条件下,重复上述实验.根据实验结果,绘制图16和表1. 图16(a)用散点图刻画了社团节点量、社团PageRank值及相应的社团数量,在不同α取值条件下的实验结果. 图16(b)用散点图刻画了社团相对大小(社团节点量相对固件节点量)、社团PageRank值及相应的社团数量,在不同α取值条件下的实验结果. 图16(c)用散点图刻画了固件节点量、固件内社团(社团节点量)PageRank值的方差,在不同α取值条件下的实验结果. 图16(d)用散点图刻画了社团节点量、社团PageRank值的方差及相应的社团数量,在不同α取值条件下的实验结果. Table 1 Variance of PageRank Value of Communities with Different Node Amounts 表1展示了在不同α取值条件下,数据集T1所有社团的PageRank值方差、节点量大于1 000社团的PageRank值方差和节点量小于1 000社团的PageRank值方差. 根据图16(a)(b)可以看出,社团PageRank值最大不超过0.15,且社团规模小于1 000时PageRank值波动较大,而大于1 000时,存在一些社团PageRank值随社团规模增大而成比例的增大.此外,α取值不同对数据集内的PageRank值分布情况并无明显影响. 通过观察表1中社团的PageRank方差可以发现,对于所有社团而言,α取值带来的方差变化较小.对于节点量大于1 000的社团,α取0.5,0.6时PageRank具有较好的区分效果,而对于小于1 000的社团,取值0.7,0.8,0.9具有较好的取值效果. 如果观察各个固件内的PageRank值波动情况,如图16(c)(d),则可以发现,在节点量小于1 000的条件下,α=0.9时社团PageRank方差大于其他取值,说明可以更好地区分固件内社团.而在节点量大于1 000的条件下,α=0.9时PageRank方差相对小,区分度相对小. 本文认为,α=0.9是较为合理选择,基于如下考虑. PageRank值由2部分构成,其中节点PageRank值中有1-α的比例是平均分给固件内各个节点的(随机分配条件下,各个节点分到的PageRank期望值是相同的),而剩余的α则是依据节点间调用关系确定的. 由此可知,社团PageRank值一部分由社团内节点量构成,一部分依据调用关系构成.对于PageRank值受节点量影响的部分,α取值越小,相应值越大.对于大社团,可以直接通过节点量区分不同社团,无需利用此部分值区分社团;对于小社团,节点少量的波动,就会对此部分产生影响,而小社团节点波动较为常见,此时更应该关注社团内外的调用关系稳定性. 因此,对于大社团,α取值越小PageRank值的价值越小;而对于小社团,α取值越大,对社团区分效果越理想.在这样的条件下,α=0.9较为合理,实验结果也能支撑上述观点. 5.4.5 社团内节点的k壳值分布 4.2节提及,在匹配社团的节点匹配算法中,依据k壳值对社团内节点进行划分,以减小匹配函数的筛选范围,特别是针对节点规模较大的社团.使用k壳值对社团内节点进行划分是否合理需要实验验证. 现对数据集T1所有社团内的节点进行k壳值分析,绘制如图17所示: Fig. 17 Proportion of k-shell value of nodes in the community 图17(a)是社团内不同k壳值节点占比的累积分布散点图.x轴表示社团相对规模,即社团节点量与固件节点量的比例;y轴表示社团内相应k壳值节点的占比;z轴为符合条件的社团数量占比的累计分布,条件为,社团内小于等于指定k壳值的节点比例小于对应y轴的值. 图17(b)是社团相对规模与指定k壳值节点占比的散点图,每一个点对应一个社团的指定k壳值节点占比. 从图17可以看出,当k>4时,k壳值的增加不会带来社团内节点比例的明显变化,因此,在选择k壳值区分社团内节点时,取k=1,k=2,k=3,k≥4即可.整体而言,随着k壳值的增大,可以划分出的节点数量会有所下降;在社团规模较小时,较大k壳值的节点占比也可以达到很大(50%以上);但随着社团规模的增大,不同k壳值节点占比也趋于稳定,k值取1,2,3时,3种情况涉及的节点占比都在30%左右.而本文采用k壳值划分匹配社团内节点的初衷就是希望降低节点规模较大社团在匹配函数过程的计算量.从这个角度分析,可以得出结论,k壳值适合用于划分节点规模较大的社团. 5.4.6 社团内节点地址分布的局部性 4.3节提出猜想,对于社团检测算法检测出的固件社团,其社团内的节点地址分布较为密集. 本文对数据集T1所有固件检测出的社团计算了索引方差,并根据各社团的规模,通过随机抽取索引,对每个社团进行20次仿真评估,计算其索引方差.绘制实验结果如图18所示. Fig. 18 Locality of node address distribution in the community 图18(a)是社团规模、社团方差、社团方差的累积分布关系图.其中,x轴为社团相对大小(社团节点量相对固件节点量),y轴为社团方差,z轴为固定大小的社团的方差累积分布值(即所有方差小于等于y值的概率的和). 图18(b)是在图18(a)的结果中随机抽取了20个社团绘制的累积分布图,以便于读者观察. 通过图18可以看出,BGLL算法检测的社团,在方差值更小的情况下,具有远高于随机选择社团的累积概率,说明BGLL识别社团的局部性优于仿真结果.虽然对于个别社团,可能存在BGLL识别社团的方差高于随机仿真结果的情况,但就整体而言,基于BGLL算法识别的社团,其方差普遍低于仿真结果,且幅度差别较大.说明BGLL识别社团内的函数地址存在局部性. 5.4.7 社团匹配的参数选择 本节讨论社团匹配最大差异度阈值β对社团匹配效果的影响. 对于数据集T2,β取0.05,0.1,0.15,0.2,0.25,0.3,0.35共计7个值,分析参数变化对社团匹配效果的影响.实验结果如图19所示. Fig. 19 The influence of parameter selection on community matching effect 图19(a)是不同参数下不同大小的匹配社团节点占固件的比例.图19(b)是不同参数下不同大小的匹配社团占总社团量的比例. 根据图19不难看出,随着最大差异度阈值的增大,匹配社团节点量在增加,但小社团的增加并不明显,主要增加的是大社团.因此,应当尽可能取较大的差异度阈值.但就人工经验而言,0.35已经是可以接受的上限,因此本文推荐β=0.35. 5.4.8 函数匹配的参数选择对匹配效率的影响 本节探讨函数匹配过程中,阈值γ和ε的选择对函数匹配效率带来的影响. 定义15.匹配效率.对于1对完成匹配的固件,其匹配效率η为 η=NMatched/t, (34) 其中,NMatched是匹配函数总的节点数量,t是总时耗. 对于数据集T2,γ取0.4,0.5,0.6,0.7和ε取0.05,0.10,0.15.形成12组参数组合,每种情况都进行1次实验,统计不同参数组合条件下的函数匹配效率(定义13). 实验结果如表2所示.实验表明,随着2个参数的增大,函数匹配数量的效率会有所下降. Table 2 Influence of Parameters ε and γ on Function Matching Efficiency 5.4.9 函数匹配的参数选择与Bindiff比较实验 本节探讨函数匹配过程中,阈值γ和ε的选择对函数匹配结果的准确率带来的影响,并与Bindiff5的匹配结果进行比较. 实验结果如表3所示.Ns表示本文方法与Bindiff判别结果相同的函数对数量.Nd表示本文方法与Bindiff判别结果不同的函数对数量,在这部分不同的结果中,存在部分函数对的匹配结果不随参数ε和γ变化而变化,本文称这类函数对的匹配结果为基本差异结果(数量为Nd_com),并将之列入表格最后一行.Nd_i表示本文方法与Bindiff判别的不同结果中,各参数特有的函数对匹配结果的数量,其计算为 Nd_i=Nd-Nd_com. (35) 对于本文方法与Bindiff判别结果不同的函数对需要进行人工核验,以估算本文方法的识别准确率.对于基本差异结果,抽样80对函数进行核对,样本量为80;对于差异匹配结果中非基本差异部分,每组参数中抽样20对函数;共计320对函数.核验结果包括4种情况,本文方法正确的函数对数量TO;Bindiff正确的函数对数量TB;本文方法与Bindiff都错误的函数对数量Wr;人工无法判别的函数对数量Un. 为了评估本文方法和Bindiff的匹配效果,本文设计可信匹配率并使用准确率增量进行评估.对于本文方法的可信匹配率RCM_O,Bindiff的可信匹配率RCM_B和用本文方法修正Bindiff结果的准确率增量ΔU,其公式如式(36)~(38): (36) (37) ΔU=RCM_O-RCM_B, (38) 其中,NT2为T2数据集的函数对数量(21 990 414对),Sp,c为基本差异结果抽样的样本量,Sp,id为非基本的差异结果抽样的样本量,TO_c表示基本差异结果抽样中本文方法正确的结果数量,TB_c表示基本差异结果抽样中Bindiff正确的结果数量,TO_id表示非基本差异结果抽样中本文方法正确的结果数量,TB_id表示非基本差异结果抽样中Bindiff正确的结果数量. Table 3 Comparison of Bindiff Matching Results with the Matching Results of This Paper 对于评估指标的设计和实验结果的分析如下: 1) 本文设计可信匹配率作为评估指标,仅对匹配函数对进行分析,而没有直接使用准确率等包含未匹配函数的传统指标.其主要原因在于2点:一方面,未匹配函数不适合列入统计.固件比对是一种较为严苛的场景,需要尽可能降低误匹配.对于多数的二进制比对方法而言,未匹配并不仅仅是某个函数在对应文件中不存在匹配函数,也可能是函数可匹配的目标函数不只1个,但为了保证匹配函数中误匹配的比率尽量低,而放弃这部分函数的匹配,将其列入未匹配结果,等待其他方法加以解决.另一方面,就2种比对方法进行分析比较而言,新方法对老方法的匹配结果应当带来某种提升,而直接使用准确率进行评估未必能带来最好的效果.一般而言,随着匹配函数数量的不断提升,用于进行函数相似性分析和传播算法的时间开销会不断增大,但匹配结果中误匹配的比率也随之增大,此时,新方法修正老方法的可能性也随之降低,经济性(新方法运行单位时间开销可修正的误匹配结果数量)不断下降. 结合上述2方面原因,不难发现,一个方法即使准确率低于另一种方法,也存在提升其他方法准确率的可能. 因此,使用准确率等传统指标并不适用于衡量和评估本文的应用场景. 本文提出可信匹配率指标,其逻辑在于,对于2种方法一致的结果,基本可以视为可信结果;对于差异结果,通过人工核验确定其中的正确部分,可推算匹配正确的比率;最终,可以推定被比较对象(固件对)的相似性下限.而通过计算2种方法可信匹配率的差异(即ΔU),依然能得到用一种方法的分析结果修正另一种方法分析结果后可提升的准确率. 2) 本文方法的12组参数实验与Bindiff比较的基本差异结果有1 110 101对函数,约占数据集T2函数总量的5%.通过抽样和人工核验,其中93.75%的结果是本文方法正确,而仅有2.5%的结果是Bindiff正确.由此估算,使用本文方法,不论参数如何变化,至少可以为Bindiff带来约4.6%的准确率提升.这是本文方法效果的下限. 3) 对于本文方法12组参数差异结果中非基本差异结果部分,参数的变化会带来较为明显的变化.γ<0.7时效果相对理想,随着γ值的降低,会带来更多的差异匹配结果;而随着ε的增加,差异结果数量会增加;对于任何参数,其抽样核验的数据表明,本文方法对于非基本的差异结果正确的概率至少有70%,而Bindiff的正确的概率低于10%. 12组参数的实验结果表明,使用本文方法修正Bindiff比对结果,可以提升5%~11%的准确率.总体而言,ε/γ取0.10/0.5,0.15/0.4,0.15/0.5是较为理想的选择,此时,匹配效率较高,带来的准确率增量也较高.本文最终选择的参数为0.10/0.5. 此外,虽然受参数选择和抽样对象变化的影响,可信匹配率的计算结果也有不同,但依旧可以确定数据集T2至少有3成的函数是匹配的,可以证明实验用的固件确实有一定的相似性. 5.4.10 操作数相似性与函数相似性关系 4.1.2节中提及,操作数相似性与函数相似性具备一定关系,现进行实验分析如下. 针对数据集T2进行相似性分析,将分析过程中所有计算过的函数对的函数相似值和操作数相似值进行记录,并绘制如图20所示: Fig. 20 The relationship between operand similarity and function similarity 图20(a)是函数的偏移量相似性Poff与函数相似性Sim(fi,fj)对应关系的散点图;图20(b)是函数的立即数相似性PImmi与函数相似性Sim(fi,fj)对应关系的散点图. 从图20中不难看出,虽然图20中散点分布较广,但其分布基本满足函数相似性随偏移量相似性和立即数相似性增加而增加的关系.在偏移量相似性和立即数相似性较低时,对应的函数相似值较高的情况相对少,反映在图20中为函数相似值高的点相对函数相似值低的点分布更为稀疏. 对于立即数相似性和偏移量相似性较高的情况,最大函数相似值与立即数相似性和偏移量相似性的值存在线性关系,说明无法达到理论最大相似值为1的原因主要是操作数相似性不足造成的.验证了前文的推断,固件升级往往带来函数操作数的变化,无法保证操作数稳定. 因此,在计算函数相似性的过程中,既要融入操作数相似性的特征,又不能赋予操作数相似性过高的权重以至拉低匹配函数整体的相似值. 5.4.11 未匹配区间长度分布 本节对相似性分析的未匹配区间大小进行分析.实验选择T2数据集,参数ε/γ取0.10/0.5.在进行相似性分析后,绘制不同固件节点量下未匹配区间长度的累积分布图,如图21所示: Fig. 21 Cumulative distribution graph of the number of firmware nodes and the length of the unmatched interval 其中,对于1对未匹配区间(i,j)和(i′,j′),若j=i+1,j′>i′+1,长度取j′-i′,标记为Insert;若j>i+1,j′=i′+1,长度取j-i,标记为Delete;若j-i=j′-i′,长度取j-i,标记为Equal;若j-i≠j′-i′,长度取区间长度均值,标记为UnEqual-Mean. 上述4种情况中,前2种一般意味着一段连续未匹配函数在固件升级过程中是新增或删除的函数;第3种情况,一般是固件升级过程中函数结构变化较大,但函数数量变化不大,区间内的函数往往具有一一对应的关系.此3种情况,通过累积分布可以看出,一般区间长度都在100以内,量级为101. 而对于4种情况,其反映的是未匹配区间有函数数量差异的情况,一般是功能模块有较大改动或者未匹配区间的边界函数本身就不属于同一功能模块;其累计分布曲线也明显不同于其他3种情况,未匹配区间平均长度可以达到103~104. 籍此可以说明参数τ选值10在量级上有其合理性.此外,需要说明的是,固件函数数量对于未匹配区间的累计分布大小并无明显影响,说明相似性分析后的未匹配区间大小分布相对稳定. 5.4.12 匹配社团对节点匹配的贡献 本节对不同规模的匹配社团对匹配节点的贡献进行分析. 实验使用数据集T2,实验结果如图22所示.其中x轴表示匹配社团占总社团数量的比例,y轴表示社团内包含的匹配节点占固件节点的比例. Fig. 22 The relationship between the proportion of matching communities and the proportion of matching nodes 本节实验表明,节点规模介于100~1 000之间的社团在总节点量和社团数量上相较于其他2个规模的社团,既不是最高的也不是最低的.但是在贡献的匹配节点比例上,明显低于其他2个规模的社团,低了1~2个数量级. 对于这种现象,本文尝试给出解释.本文选择的数据集具有一定的特殊性,其中的固件属于同一厂商,基本都包含升级关系.造成上述现象的可能原因是固件在升级过程中,函数变化主要发生在节点规模在100~1 000的功能模块内.节点规模较小的功能模块功能单一且稳定,一般优化的价值不大.而节点规模在1 000以上的功能模块,功能过于复杂,一般不会轻易进行优化.这2类功能模块如果本身变化不大,那么匹配量一定会较高.而对于节点规模在100~1 000的功能模块,修改的成本不是特别高,也易于发现新的优化目标,因此函数相对不稳定,匹配节点比例就相对低. 1) 关于图的选择.本文选择了FCG,而大量的相关研究中使用CFG.诚然,CFG可以提供直接、间接跳转等多种关系,可以增加图中的连边;将FCG中的节点从函数替换为CFG中的基本块,会保留更多的可用信息.但是,这会带来更大的运算负担.即便是使用粒度较粗的FCG,本文也依然需要进行图的压缩工作(见3.1节),以减小后续分析开销,而CFG带来的边的激增会大幅增加时间开销(3.2节已分析BGLL算法的时间复杂度与图的边数相关). 2) 关于本文方法适用性问题.本文方法面向的固件主要为Cisco IOS.该固件是较为特殊的一类固件,其整个操作系统的存在形态是一个可执行文件,因此才会导致固件函数数量较大.而目前存在的嵌入式设备中,存在其他形态的固件,固件解包后包含不同的可执行程序和文件(如Cisco IOS-XE),其代表就是基于Linux开发的各类嵌入式设备固件.对于后一类固件,由于没有实验数据,不盲目推测本文方法的应用效果.从逻辑上讲,后一类固件的可执行程序也必定包含不同的功能模块,使用社团检测应当会具有效果.但,从使用前提上讲,社团检测一般是面向复杂网络的,如果程序内的函数数量规模不够大,使用此法未必是最优选择.毕竟,函数规模较小时,1.1节中提到的问题发生概率也较低. 本文提出了一种基于社团检测的固件比对方法.首先,分析了自建数据集中固件FCG的性质.而后,提出了面向社团检测的FCG压缩算法,设计了社团表示和匹配方法,可在使用BGLL对固件FCG进行社团检测后匹配社团.最后,基于匹配社团完成函数匹配,包括函数误匹配修正和残余函数匹配.此外,本文优化了函数相似性度量方法,引入了操作数相似性.通过实验,验证了本文方法的可行性,确定了文中参数的合理取值,并与Bindiff的比对效果进行比较.实验结果表明,本文提出的基于社团检测的固件比对方法可以提升Bindiff比对结果5%~11%的准确率.因此,本文的方法是可行且有效的. 作者贡献声明:肖睿卿负责形成研究思路、原型系统主体实现、实验设计和具体实现、实验数据整理和分析、实验结果可视化,撰写初稿;费金龙完成原型系统功能优化,降低实验成本;祝跃飞负责理论模型构建、理论可行性分析;蔡瑞杰协助完成匹配社团相关参数选择;刘胜利提出研究问题,确定研究思路,对实验进行监督和领导,审阅和修改初稿.4 基于匹配社团的函数匹配方法
4.1 函数相似性度量方法
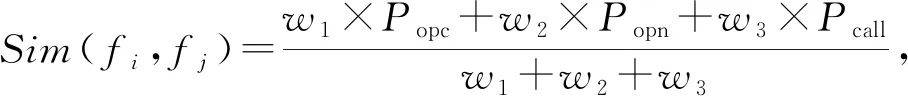
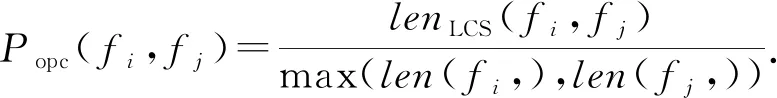
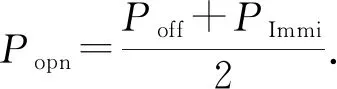
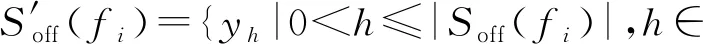
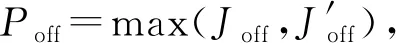
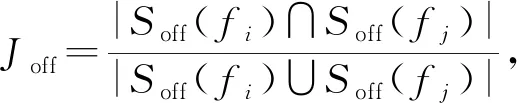
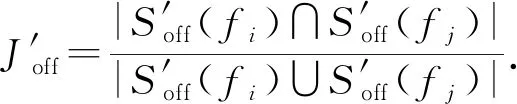
4.2 匹配社团的函数匹配
4.3 误匹配函数修正
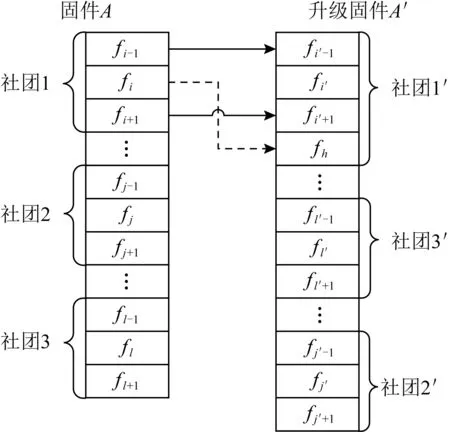
4.4 残余函数匹配
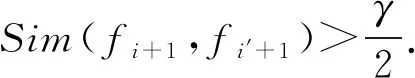
5 实验与结果
5.1 实验环境
5.2 数据集
5.3 预处理
5.4 实验与分析
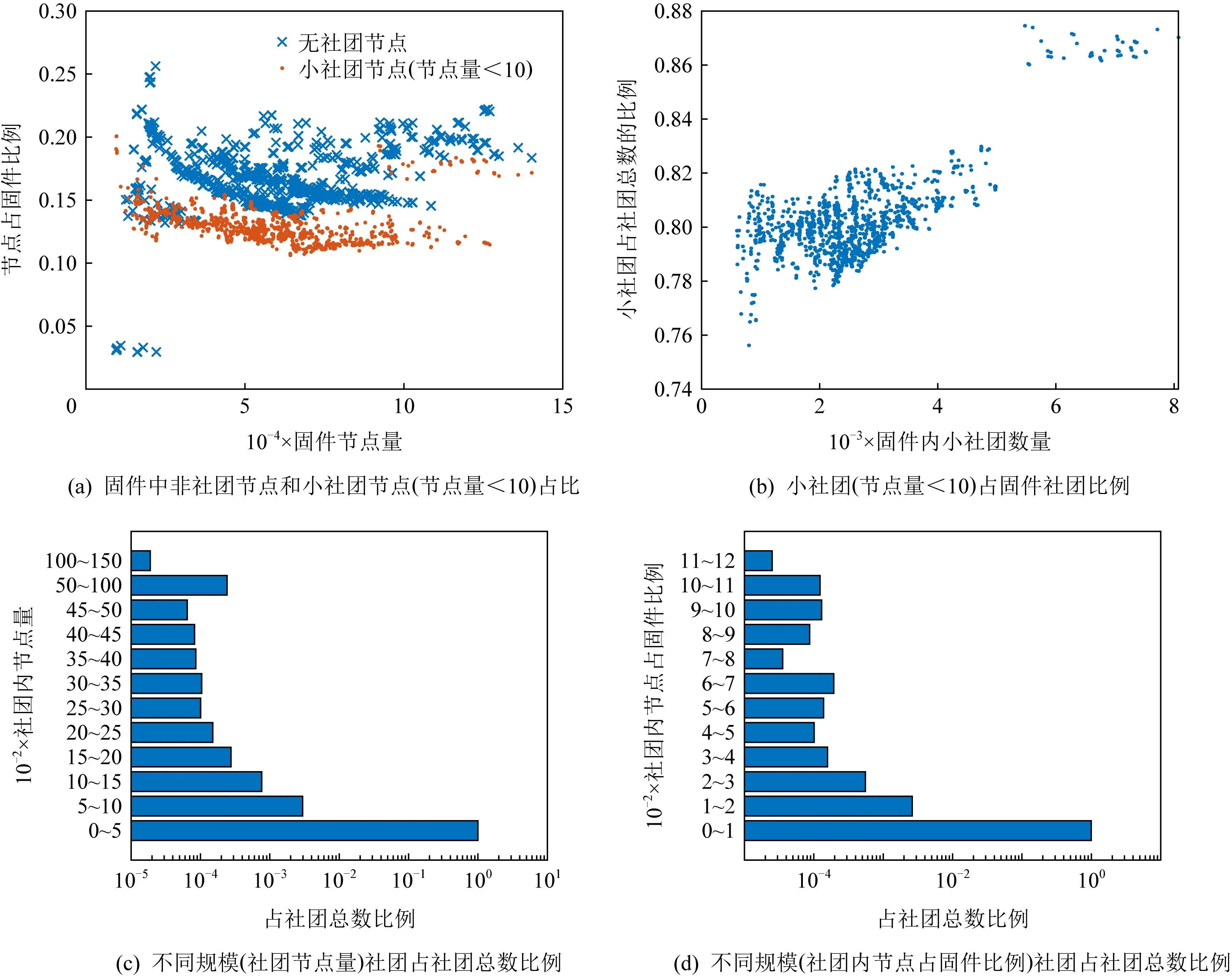
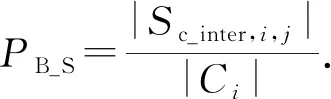

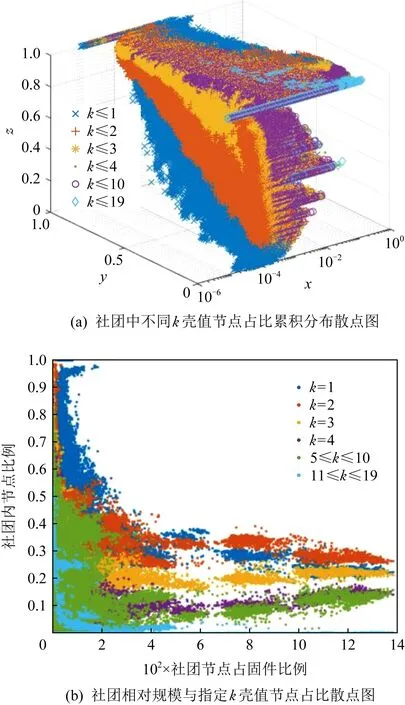
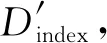
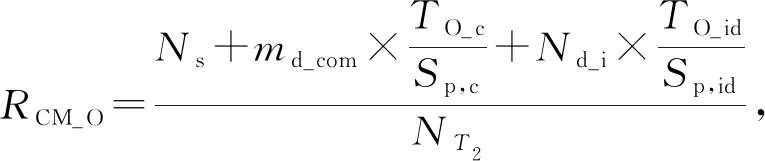
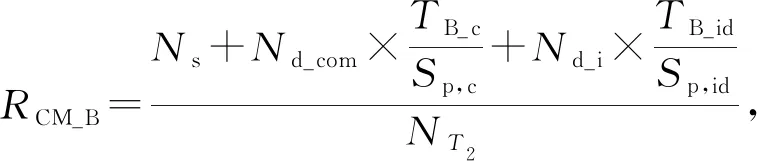
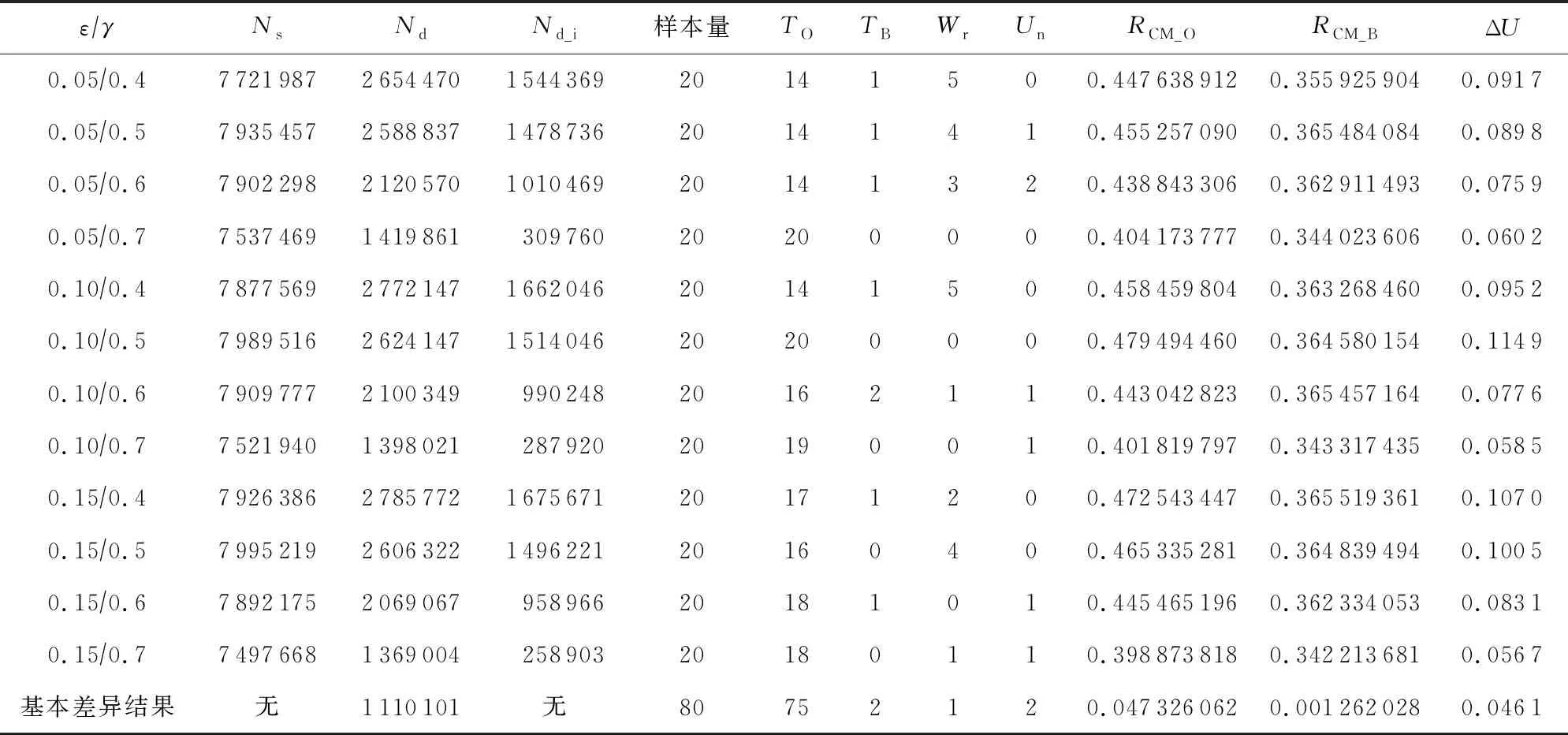
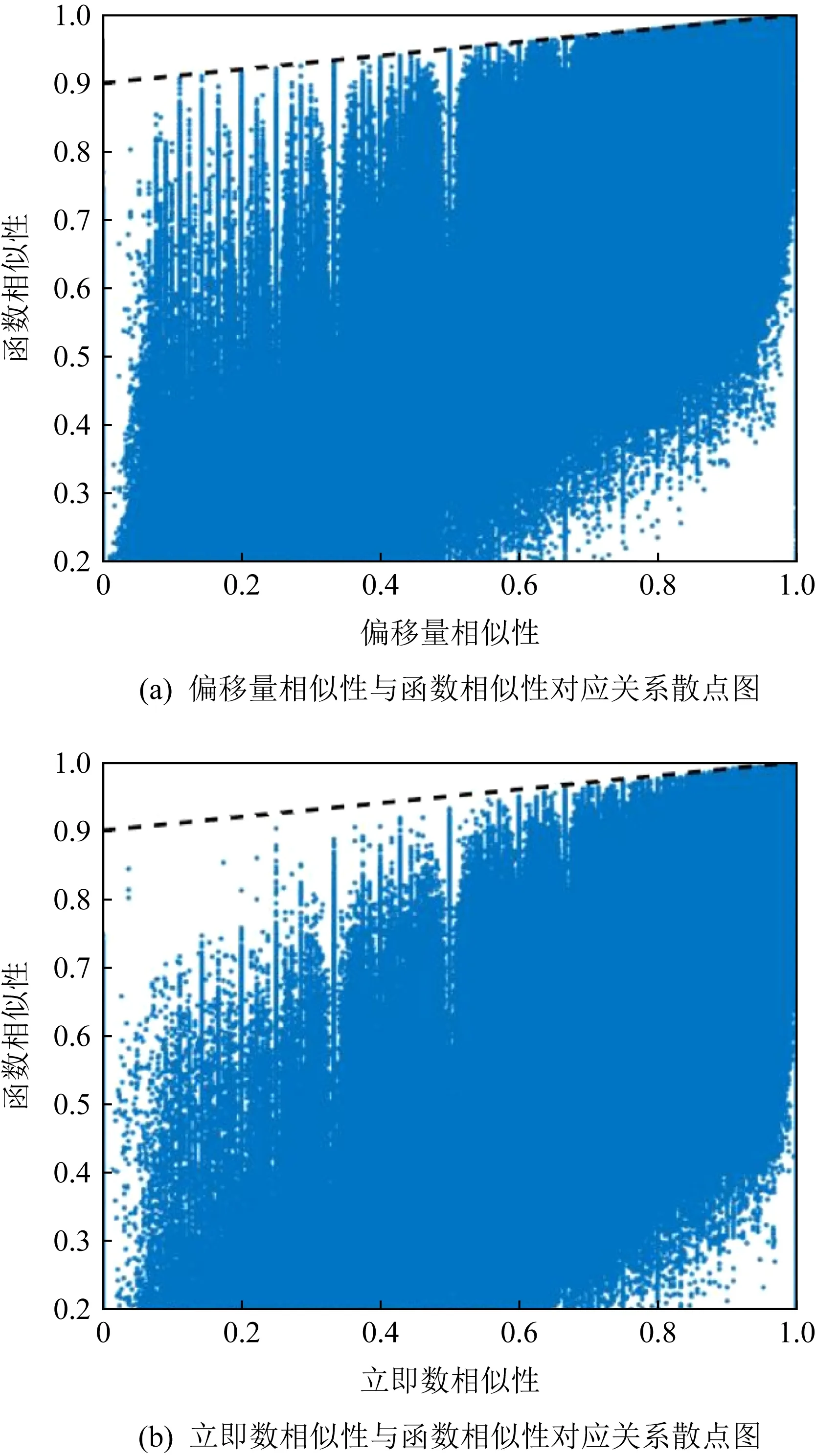
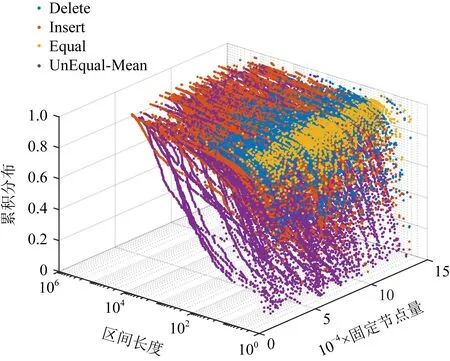
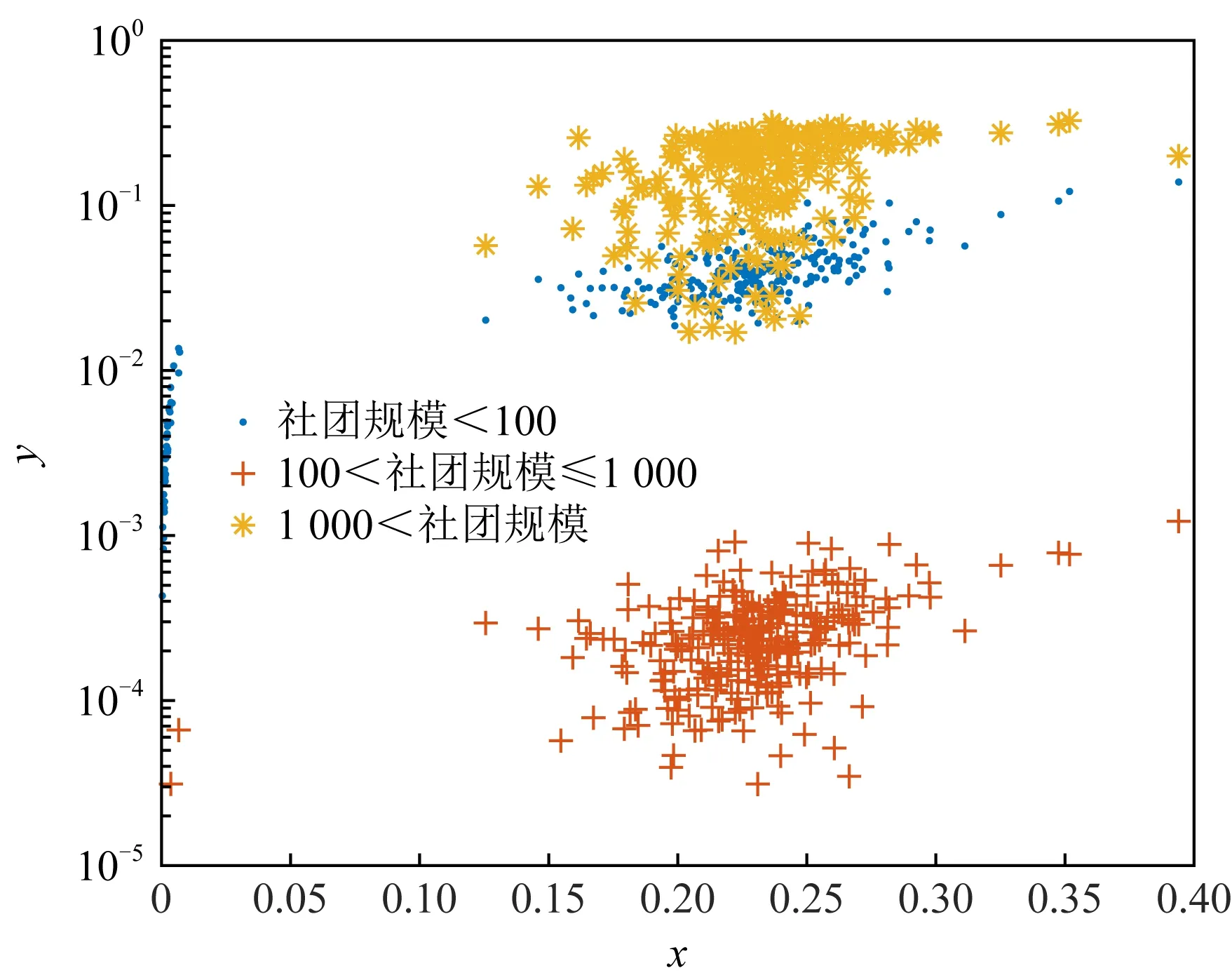
6 讨 论
7 总 结
