一种Linux安全漏洞修复补丁自动识别方法
2022-01-19武延军
周 鹏 武延军 赵 琛
1(中国科学院软件研究所 北京 100190)2(中国科学院大学 北京 100049)3(计算机科学国家重点实验室(中国科学院软件研究所) 北京 100190)
随着软件系统复杂度的增加、开源软件日益广泛的应用对漏洞(vulnerability)披露的透明度和效率提升、各国政府和企业对软件安全愈加重视而增加投入,软件漏洞的披露数量逐年增加[1-2].同时软件正渗透到经济、社会生活的方方面面,Linux内核、基础库(如OpenSSL)被不同软件系统广泛共用,其安全漏洞被利用往往波及到广泛的软件系统和大量的用户[3-4].因此帮助用户及时应用安全漏洞补丁修复至关重要.
观察开源社区安全漏洞生命流程,总结科研工作者和企业安全漏洞阶段划分惯例[1,4-6],开源软件漏洞生命周期主要分为4个阶段:1)发现新漏洞;2)开发发布漏洞修复补丁;3)将漏洞修复补丁通知用户;4)用户应用漏洞修复补丁到软件系统.我们对这4个阶段进行分析发现,软件漏洞生命周期第3阶段很容易被忽视并存在安全提示信息不足,进而造成第4阶段存在明显的管理不足,影响安全补丁的及时应用从而给用户带来安全威胁.
第1阶段:该阶段已经引起学者们的广泛关注,比如漏洞检测、漏洞挖掘、漏洞分析、漏洞利用(是评估新漏洞的重要手段之一)一直是安全领域的研究热点,持续受到科研、企业、政府机构等密切关注[1,7-8].
第2阶段:该阶段反应快速,易获得优先处理.新安全漏洞一旦被发现确认,开源社区维护者(maintainer)会积极做出反应,快速开发、评审、处理漏洞修复补丁[5],例如文献[9]统计发现安全漏洞的修复反应速度比性能Bug快2.8倍,安全漏洞分配的开发者人数是性能Bug的3.51倍,是其他Bug的4.7倍;文献[1]跟踪分析的包括Linux内核、Ubuntu等600多个开源项目和Snyk安全公司发布的开源软件安全状态工作报告[5],统计发现维护人员对待安全漏洞和安全修复补丁的响应速度、重视程度要明显高于其他Bug.
第3,4阶段:第2阶段研究表明通过补丁注释特别是补丁的commit message明确告知补丁是修复安全漏洞、明确给出对应的CVE ID(common vulnerabilities and exposures identifiers)[10],对软件的用户(安全软件工程师、操作系统发行版、软件集成商、运维工程师等)识别安全漏洞修复补丁,尽早应用到软件系统至关重要.但是,研究发现开源软件维护者经常悄无声息地修复安全漏洞,即漏洞修复补丁的代码部分和commit message中未给出安全描述和CVE ID信息是很常见的.比如研究报告[5]统计发现,在漏洞修复补丁发布时,维护者在文件中明确标注CVE ID的只占9%,及时主动通知安全监控服务提供者只有3%,88%的维护者在新版本发布的发布说明里才通知修复了安全漏洞,但是相对于安全补丁的发布,软件新版本发布要滞后很多,而且很多生产环境的基础服务,出于安全性、稳定性考虑,管理员更偏向于补丁升级而非升级整个软件版本,管理员不得不去识别具体的安全修复补丁;同时我们编写工具统计了收录到NVD[11]数据库的Linux内核全部漏洞(2002—2020年5月23日),Linux内核一共有4 064个被NVD数据库收录确认的漏洞,然后我们的工具追踪NVD和Linux内核源码仓库,发现修复补丁被登记到NVD追踪的只有1 633个,即NVD已经确认收录的Linux内核漏洞,其中只有40.2%的内核漏洞修复补丁登记关联到NVD数据库,从而可以NVD数据库反向识别;我们的工具直接追踪Linux内核源码仓库,发现其中只有380个漏洞修复补丁的提交信息给出了CVE ID等漏洞描述信息,仅占Linux内核NVD确认漏洞总数的9.35%,占NVD反向可追踪数的23.27%,因此Linux内核维护者在安全修复补丁文件中明确标注CVE ID的情况跟开源软件整体情况一样比例很低.由此用户(即便是专业的安全工程师)识别安全漏洞修复补丁,从而避免遗漏和尽早应用安全补丁面临挑战.
基于这些观察分析,开发安全修复补丁的智能化自动识别工具,实现对漏洞修复补丁的及时识别、及时通知、降低人工识别的工作量和遗漏,从而促进安全补丁的及时应用是本文的主要研究动机.
因此,本文以代表性的Linux内核源码社区为案例,设计实现了一种Linux安全漏洞补丁的自动化识别方法.该方法核心思想是为合并到Linux内核源码的补丁的代码和描述部分分别定义漏洞特征,构建机器学习模型,训练学习可识别安全漏洞补丁的分类器.该方法的实现主要包括3个步骤:1)如何持续收集和标注安全漏洞补丁和非安全补丁;2)跟其他的Bug修复、功能增强补丁相比,分析安全漏洞修复补丁的特点,对原始补丁文件进行特征定义和特征抽取;3)设计、实现机器学习模型,使用收集的数据集训练生成可识别漏洞修复补丁的分类器.
本文的主要贡献包括3个方面:
1) 给出了一种可以自动识别漏洞修复补丁的机器学习建模方法,并详细给出了如何做Code特征、Log特征的定义与提取,以及联合Code和Log如何基于半监督的Co-Training方法建模.以代表性的Linux内核为应用实例,实验表明该方法将识别精确率提升到91.3%,准确率到92%,召回率到87.53%,误报率降低到5.2%,因此具有实用价值.并且该方法有很好的可扩展性,可以直接扩展支持其他开源项目.
2) 实现了一个可持续收集和标注安全漏洞修复补丁和Bug修复补丁的工具系统,并给出其设计与实现细节,该系统可以扩展支持其他以Git,SVN等版本控制工具管理的开源软件.
3) 本文研究也启示,不应盲目相信,或过度依赖NVD、开源软件社区漏洞通告,因为其全面性、有效提示性和及时性存在不足.分析表明其通告质量存在漏、错、未更新等问题.这要求我们需结合人工和自动化识别工具去主动识别漏洞修复补丁,及时修复.
1 相关工作
近年来,使用机器学习技术对程序源代码进行分析和处理成为研究热点之一,其中分析软件漏洞、Bug修复是重要的研究方面.下面介绍跟本文最相关的工作,以及我们的工作跟相关工作的区别.
文献[12]提出了使用补丁的说明信息(Log message)和Bug报告抽取特征自动识别安全漏洞补丁的研究方法,该类方法只使用补丁的自然语言相关的素材信息,不涉及代码;我们的方法同时从补丁的Log message和Code抽取特征,结合2方面的特征信息构建模型,因此在建模的特征工程和建模方法上都明显不同.
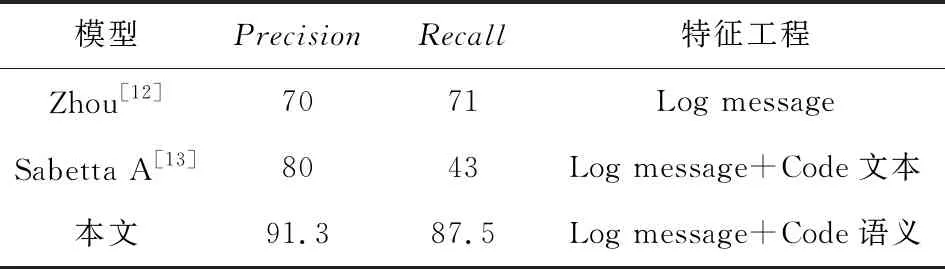
文献[13]提出了使用补丁的Log message和Code部分抽取特征识别漏洞修复补丁的方法,我们虽然都使用了补丁的Log message和Code部分,但是我们的特征工程和建模方法有明显区别,比如文献[13]将Code只做纯文本对待抽取关键字,然后跟Log自然语言部分一起合并;而我们的方法将Code部分按照编程语言进行分析,抽取其标识符、循环、代码修改等细粒度信息构建特征,并且我们将Code和Log部分的特征分开构建机器学习模型,因此建模方法也明显不同.
文献[14]提出了结合使用补丁的统计量(局部性、复杂度、控制循环)结合关键字抽取特征,然后用机器学习的方法对安全修复补丁进行更细粒度分类,如划分为Buffer错误(如栈溢出)、Injection错误(如错误注入)、Numeric错误(如整数溢出)等,我们都是借助补丁的统计特征建模,但我们的研究目标和构建模型的方法完全不同,从其实验效果可知文献[14]细粒度补丁类型分类有效但并不显著(其最佳准确率是54.75%),因此并不能达到本文研究目标的可实用的程度.
文献[15]提出一种从Bug修复补丁中识别出漏洞修复的研究方法(漏洞修复补丁是Bug补丁的子类,所以我们在本文中称纯Bug修复补丁以做区分.),该方法使用LLVM编译器将补丁修改的文件源码预编译为IR,然后使用手动建立的补丁模式(安全操作、关键变量、漏洞操作)对IR对照补丁模式进行预处理收集到模式数据,最后将收集的数据作为约束提供给手动定义的符号规则做约束求解,求解结果做出是否为安全补丁的判断.该方法为应用程序的语法信息提供了一种可借鉴的思路,但其每个步骤都需要人工建立模式、规则,导致人工负担较重,规则和模式的完备性需要验证,这限制了其应用规模.因此我们的研究方法和应用规模都有明显差异.
文献[1,9,16-17]从经验软件工程角度对不同补丁的统计特性进行了大量实证研究,研究表明功能补丁、Bug修复补丁、安全漏洞修复补丁表现出统计上的显著差异,这些经验是本文对代码补丁做特征工程时进行特征定义与选取的主要依据.但本文工作跟这些研究的研究方法和目标都是不同的.
文献[18-19]等标注源码的研究方法,我们的研究目标和研究方法都差别很大.
2 设计与实现
2.1 补丁持续收集与标注方法
每个源代码补丁(简称补丁)由Log message和Code部分组成,前者是自然语言描述的补丁性质和行为,后者指定对源代码文件的修改(增、删、替换).开源软件是以补丁合并(merge)的方式发展演化,可分为Bug、功能、漏洞修复3类补丁.从Linux内核社区直接获取补丁是很容易的;但是,因为补丁描述信息和补丁代码有很强的随意性,根据补丁信息对补丁进行直接自动化归类(标注)比较困难.而模型训练和更新需要足够的标注补丁,这就要求给出能够持续收集、标注补丁的方法,并设计开发自动化工具.
2.1.1 收集标注漏洞修复补丁的方法
因为直接根据补丁提交信息从Linux仓库收集安全漏洞补丁识别困难,不可靠.而NVD数据库里分配了CVE ID的漏洞是经过确认而具有可靠性.因此,我们采取了从NVD数据库解析信息,然后反向追踪Linux内核的Git源码仓库[20]的方法,其方法流程如图1所示:
1) 从NVD站点自动下载NVD安全漏洞数据,每天更新一次.
2) 数据以JSON格式存储,以名字为“CVE_Items”的JSON数组管理,数组的每一项是一个被确认的安全漏洞的信息,图2是一个CVE Item格式和记载字段的例子,这里只列出重要字段,省略大部分字段.
3) 通过解析CPE[21]“cpe23Uri”字段判断该漏洞是否属于linux_kernel.
4) 通过解析“references”字段的所有选项,匹配是否存在“git.kernel.org”或“github.com/torvalds/linux”的url,如果有则表明可能提供了补丁链接.“references”字段一般有多项,是描述该漏洞情况的来自于互联的相关说明链接.
5) 解析漏洞补丁URL,提取其中的Commit Hash ID字段,Linux内核是使用git管理的代码仓,每次commit补丁提交对应一个唯一的Hash ID.
6) 通过Hash ID从Linux内核仓的主干分支(Linus Torvalds维护)提取相应的补丁.
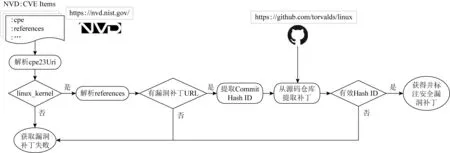
Fig. 1 Continuously collect and label vulnerability fix patches of the Linux kernel

图2 一个CVE安全漏洞例子
通过以上方法流程,我们可以巧妙地为Linux内核自动收集、标注可靠的漏报补丁数据集,并可持续更新.显然该漏洞补丁标注方法很容易扩展支持其他开源项目.
2.1.2 收集标注功能和Bug修复补丁的方法
该部分工作是收集明确不是安全漏洞修复的补丁.其方法是收集可以明确是功能增强或纯Bug修复的补丁.这些补丁最后都统一标注为“nonvulns”.
收集明确的Bug修复补丁:首先通过“fix(fix的派生词)”过滤Log message做初步筛查,然后剔除掉有安全关联敏感关键字的补丁[12],然后剔除掉在被明确做了安全标注的补丁,最后剔除掉有引用安全机构链接的补丁.
收集功能增强补丁:Log message出现Add support,Clean,Clean up,New feature等关键字,同时不属于收集的安全漏洞修复、Bug修复补丁.
2.1.3 收集未标注补丁
收集无法做出安全漏洞标注、Bug修复标注、功能增强标注线索的补丁.这类补丁的分类标注为“unknowns”.
2.2 特征定义与特征提取
如图3所示提交到Linux内核的修复CVE-2020-11494安全漏洞的补丁,可以看出该补丁并未给出可直接引人注意的安全提示信息.该补丁包括Log message文字说明部分(行⑤~所示)和代码修改描述部分(行~所示).前者是自然语言,后者是严格的代码规则语言,差别很大;因此需分别定义特征,分别给出特征提取方法.
2.2.1 补丁的代码部分
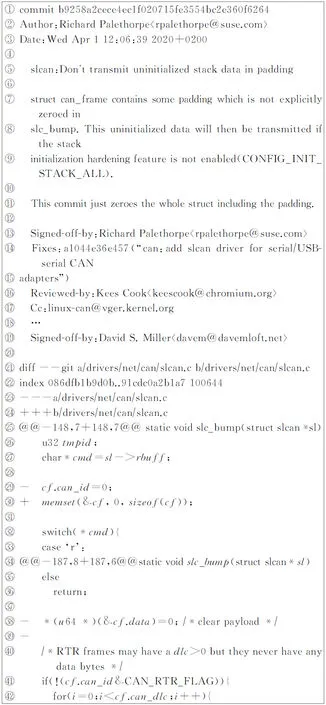
图3 一个CVE-2020-11494漏洞修复补丁例子

Fig. 4 Flow of feature extraction for commit log messages
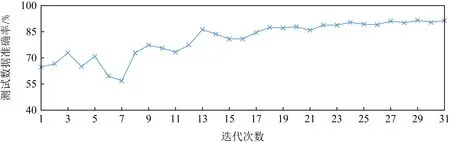
Fig. 5 Test accuracy versus number of iterations for a training experiment
[1,9,16-17]
F01:跨越的函数体个数,度量局部性.
F02:改动的文件数,度量局部性.
F03:修改块(hunk)数,局部性和复杂性.
F04:增加的行数,逻辑复杂性.
F05:删除的行数,逻辑复杂性.
F06,F07:增加/删除IF分支个数,逻辑复杂性.
F08,F09:增加/删除循环数(for,while,goto),逻辑复杂性.
F10,F11:增加/删除括号表达式,逻辑复杂性.
F12,F13:新增/删除文件数,局部性,分别通过匹配“---/dev/null”“+++/dev/null”模式统计.
F14,F15:增加/删除sizeof、取变量地址、指针运算操作.
F16至F19:增加/删除函数调用数,逻辑复杂性.
F20,F21:增/删函数返回(return),复杂性.
F22至F25:增加/删除的continue,break控制数.
F26,F27:增加/删除复制操作行数,复杂性.
F28,F29:增加/删除关系运算(>,!=,<,|,&&等).
F30,F31:增加/删除宏数,如#ifdef,#define,#undef,#endif,#elif.
F32:|F04-F05|,增加的减去删除的,取绝对值.
F33:F04+F05,增加的加上删除的.
F34至F54:特征F06至F11、F14至F31是以类似计算F32和F33的方式计算的特征.
2.2.2 补丁的Log message部分
特征抽取流程的详细说明如下:
1) Log message文本抽取.提取每个补丁的Log message部分,并以commit Hash字符串命名文件存储,这些文件按照vulns,nonvulns,unknowns这3个目录组织管理.
2) 数据预处理.原始Log message文本包含噪音干扰信息,需在特征抽取前做清理.包括:剔除作者行(Signed-off-by,Reviewed-by,Acked-by等);统一小写(避免大小写增加词汇库);stemming处理把派生词统一到词根减小词汇库,如fixed,fixing,fixes都替换为fix,因为派生词的提示信息是一样的;停用词(stop words)处理,剔除掉英语语言中信息量低的高频词,如his,hers,at,just,my,and等;最后Log message文档的多行合并为一行,作为语料库的一个文档单元.
3) 构建语料库.以前面步骤预处理后在vulns,nonvulns,unknowns目录下管理的所有Log文档为文档单元构建BoW语料库,该语料库建设过程包括:收集所有的词汇;统计语料库全局空间词频(global term frequency),记为TFg;词频最高的前50的词汇构成词汇库(Vocabulary);计算50个词在语料库全局空间的逆文档频率(inverse document frequency),记为IDF.选取的50个词构成了每个Log文档的特征分量.
语料库中词频为
(1)
其中ngi是单词i在所有Log文档中出现次数,Ng是语料库中所有单词出现次数的和.
IDF的计算需要先计算DF(词汇的文档频率):
DFi=Di,
(2)
其中Di={dj|ti是语料库中的单词,ti∈dj}.
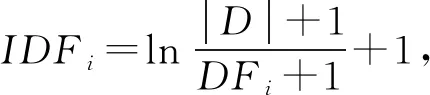
(3)
其中,D={d1,d2,…,di,di+1,…,dn|di是Log文档,n是文档总数}.
4) 生成Log message特征.有了第3步统计学习得到的语料库的Vocabulary,TFg,IDF信息,可以为每个Log message计算生成其TF-IDF特征表示(记为TFIDF).任意文档di抽取的特征表示为
TFIDFi=‖[TFIDFi1,TFIDFi2,…,TFIDFij,…,TFIDFiV]‖2,
(4)
其中V=|Vocabulary|=50,特征权重分量TFIDFij为
TFIDFij=TFij×IDFj,
(5)
其中TFij是词汇单词j在文档di中出现的次数.
流程的步骤4)完成了对Log message文档的特征抽取,抽取50个特征,每个Log文档用50维的向量表示,向量权重分量是相应特征的TF-IDF值表示.
2.3 漏洞补丁分类器模型
收集的训练数据集包括标注数据集(vulns,nonvulns)和未标注数据集(unknowns),其中未标注数据数量远多于标注数据集,因此我们尝试采取半监督(semi-supervisied)的Co-Training[24-25]方法建模.将vulns视为正数据点P,将nonvulns(包括功能和单纯的Bug修复补丁)视为负数据点N,将unknowns视为未标注数据点U,P和N构成了标注数据集L.
算法1描述了训练可识别安全漏洞补丁分类器的流程,该算法执行过程中我们设置nP=2,nN=4,nU=80,iter=30;算法2是使用由算法1学习的分类器做预测的流程,因为分类器有2个构成,分别是基于补丁的Code特征训练和基于补丁的Log特征训练得到,该算法描述了在预测推理阶段如何整合这2个分类器构建1个统一安全漏洞补丁识别分类器.
注意:算法描述中的[begin:end]操作是从特征集中截取从begin索引开始到end结束的部分特征,end未指定表示到序列结尾,begin未指定表示从序列开头;算法中用到的子分类器模型是基于SVM LinearSVC[26]构造.
算法1.模型训练过程.
输入:XL为标注样本,y为补丁样本标注,XU为未标注样本,nP为每次迭代各分类器从XU中取出标注为正样本的个数,nN为取出标注为负的个数,nU为未标注样本缓冲池大小,iter为训练迭代次数;
输出:clfCode是用补丁的代码特征训练的分类器,clfLog是补丁的Log特征集训练的分类器.
① FUNCTION:runTrain(XL,y,XU,nP,nN,nU,iter)/*将补丁的特征集分为Code和Log特征集*/
②XLCode=XL[0:CodeFeatureCount],
XLLog=XL[CodeFeatureCount:];
/*使用SVM LinearSVC建模初始化分类器*/
③clfCode←LinearSVC,clfLog←LinearSVC;
④c=0;/*Co-Training训练迭代次数计数器*/
⑤UP←从XU随机取nu个元素构建缓冲池;
⑥ WHILE(c ⑦clfCode←Train(clfCode,XLCode,y); /*使用补丁的Log特征集训练分类器*/ ⑧clfLog←Train(clfLog,XLLog,y); /*Code分类器对池子样本做预测*/ ⑨yPredByCode←Infer(clfCode,UP[0:CodeFeatureCount]);/*Log分类器对池子样本做预测*/ ⑩yPredByLog←Infer(clfLog, UP[CodeFeatureCount:]);/*用Code推理标注nP个正样本,nN个负样本*/ set(Pl)∪set(Nl)); set(Nc)∪set(Pl)∪set(Nl))); 算法2.模型推理预测过程. 输入:clfCode是算法1生成的代码特征分类器、clfLog是算法1生成的Log特征分类器、x是数据点; 输出:1预测为正(漏洞修复补丁),0为负. ① FUNCTION:vulInfer(x,clfCode,clfLog) ②pred1=pred2=-1; ③pred1←Infer(clfCode, x[0:CodeFeatureCount]); ④pred2←Infer(clfLog, x[CodeFeatureCount:]); ⑤ IF(pred1==pred2) ⑥ RETURNpred1; ⑦ ENDIF/*Code和Log分类器预测一致Code预测为正、负的置信概率*/ ⑧ (pp1,pn1)←InferProbability(clfCode,x[0:CodeFeatureCount]);/*Log预测为正、负的置信概率*/ ⑨ (pp2,pn2)←InferProbability(clfLog,x[CodeFeatureCount:]); ⑩ IF (pp1+pp2>pn1+pn2) /*正、负置信度和相等,随机预测*/ 在本节中,首先介绍数据集的情况;然后给出模型训练收敛性的实验测试评估,接着实验评估了模型的性能、跟代表性研究的对比;最后评估了安全漏洞补丁的报告情况分析.实验表明本文给出的漏洞修复补丁识别方法可行、效果明显,跟代表性研究对比其预测性能有明显提升.同时安全漏洞补丁的追踪情况现状分析表明,完全直接依托NVD和补丁的Log信息识别、管理,难以实现及时、全面地响应安全漏洞威胁;因此通过自动化识别等方法提升对漏洞修复补丁的识别准确率和推送效率很有必要. 我们定义准确率、召回率和精确率公式为: (6) Recall= (7) (8) 其中,#TruePositive表示在测试时正数据点被正确识别为正的个数.#TrueNegative表示负数据点被正确识别为负的个数.#FalseNegative表示正数据点被错误识别为负的个数.#FalsePositive表示负数据点被错误识别为正的个数.#Positive表示正数据点的个数,等于#TruePositive+#FalseNegative.#Negative表示负数据点的个数,等于#TrueNegative+#FalsePositive. 准确率、召回率和精确率这3个指标方便跟相关研究做对比.在工程实践中我们也关心误报率和漏报率这2个直观指标,前者影响补丁识别工作量,后者影响工具可靠性.因为漏报率是召回率的相反指标,所以我们只需定义误报率公式为 (9) 本文使用2.1节给出的方法收集和标注数据,收集的数据集整理为正数据、负数据和未标注数据.正数据是安全漏洞修复补丁,标注为1;负数据是非安全漏洞修复补丁,标注为0;未标注数据是分类未知的补丁,标记为-1.表1给出了收集的Linux内核补丁数据集的构成与使用分配情况.覆盖了2002—2020年5月23日Linux内核补丁. Table 1 Data Set Composition and Assignment 实验参数设置:设置从无标注样本集选择标注的训练迭代次数(参数iter)为30,设置参数nP=2,nN=4,nU=80.模型的内部子分类器选型SVM LinearSVC(只需完成正和负2个分类).正样本1 633个、负样本2 613个、未标注样本42 359个;标注样本的3/4用做训练数据,1/4为测试数据.图5所示,当迭代训练到第18轮时模型可以趋于稳定收敛. 关于参数选取的说明:参数nP,nN,nU的设置参考Co-Training原始文献[25]里的论述.Co-Training模型对内部子模型的选择并没有特别的限制,本文考虑到识别漏洞修复补丁是二分类问题,因此使用SVM LinearSVC可以满足实验验证的需要;实际上选择或构建其他模型(如构建二分类的神经网络模型)代替这里的SVM LinearSVC作为参数传递给Co-Training,充当内部子模型二分类器也是可行的. 本节通过实验测试模型的准确率、召回率、精确率和误报率,对模型的预测效果进行评估.跟代表性研究模型的性能指标对比表明,本文的方法模型能明显提高预测性能. 表2是实验测试的主要性能指标,其精确率、召回率和准确率指标表明本文建模方法对安全漏洞修复补丁识别效果显著.同时误报率5.2%是可接受的. Table 2 The Test Results of Model Performance 表3是跟主流模型的性能对比.文献[12]建模只使用了补丁的Log message信息;文献[13]同时使用了Log message信息和补丁的Code信息,但是对Code信息只做纯文本,因此特征抽取比较粗糙;我们的方法同时使用Log message和Code信息,并且将Code部分按照代码对待,抽取其标识符、结构、语言构造等程序信息,因此特征提取更充分.性能指标对比表明我们的方法可以明显提升模型的预测性能. Table 3 Performance Comparison with State-of-the-Art 实验目的是检验模型从未标注补丁中发现漏洞修复补丁的能力.表4给出了自动检测报告的13个补丁的情况,其中前11个是漏洞修复补丁,后2个是被工具误报的纯Bug修复补丁.该实验表明本文方法可以有效检测漏洞修复补丁. Table 4 Automatic Detection of Vulnerability Fix Patches 实验方法是从unlabled数据集中随机抽取1 500个交由训练的模型做检测,然后对检测结果报告为正(即漏洞修复补丁)的补丁做人工检查.众所周知,Bug具有漏洞的特点并不表示很快可以找到该漏洞的利用方法,从而确定性证实或者证伪该漏洞.即该实验的严格验证比较困难.因此人工检查是按照补丁是否修复典型的漏洞特征进行界定.工具报告了13个安全漏洞修复补丁,经过手动检查11个被确认,2个是误报(纯Bug修复补丁). 我们的工具自动收集了从2002年起到2020年5月23日止,收录于NVD数据库的Linux内核全部登记漏洞.这些漏洞状态的汇总统计如表5所示: Table 5 Statistics of Linux Vulnerability NVD Status 登记信息的完整性:一共有4 064个被NVD数据库收录确认的漏洞,只有380个漏洞修复补丁的Log message给出了CVE ID信息,仅占内核确认漏洞的9.35%,占NVD反向可追踪数的23.27%;漏洞修复补丁在NVD的CVE信息中被记录追踪的只有1 633个(关联1 497个CVE),即只有40.2%的漏洞修复补丁在NVD数据库端有引用、只有1 497个CVE的登记信息是完整的.因此用户如果通过Linux社区补丁提交的Log message信息收集漏洞修复补丁,只能及时识别9.35%. 登记信息的正确性:我们的工具分析发现,NVD数据库汇总有51个内核CVE登记的补丁链接已经失效,涉及Linux内核的55个失效补丁,因此错误率为51/1 497=3.4%. 因此无论从源码仓库端或NVD数据库端收集、识别安全漏洞修复补丁都存在全面性、有效提示性和及时性的不足,这表明完全依靠NVD和开源软件社区漏洞通告做安全维护是不可靠的.同时这也表明智能自动化的漏洞修复补丁识别研究具有重要价值. 1) 局限性.本文实验表明,从补丁的统计量构建特征,将补丁区分为安全漏洞修复和非安全漏洞修复准确率很高.但如果进一步将安全漏洞修复补丁做细粒度分类(比如区分为缓冲区溢出、整数溢出、错误注入、访问控制错误等)则面临挑战.同样,如果某个补丁违背了实证软件工程的一般统计规律,本文的研究方法很难区分这类异常补丁,考虑到在规范的大型开源项目比如Linux,Xen,OpenStack,实践中出现可能性很少,所以总体而言这种少量异常补丁的可能存在不影响本文方法的应用价值.如果一个社区的补丁管理严重不规范,比如功能混淆、缺乏一般的统计规律,对本文方法将是很大的挑战,这不仅对工具是挑战,对自然人手动识别也会带来困难.我们认为结合补丁的语法语义解析构建特征,有可能对这类补丁的识别带来帮助,这是我们下一步工作重点考虑的建模因素. 2) 模型的可扩展性.本文给出的识别漏洞修复补丁的建模方法是通用的,即可以直接扩展支持其他开源项目.虽然,因为一方面不同开源项目存在编程语言、功能代码粒度、项目功能、编程规范等差异,另一方面当前AI技术尚存在泛化能力瓶颈(即一般地,一个训练好的AI模型只能解决一个专门的问题,难以像人类智能做到触类旁通、举一反三),因此用Linux数据集训练的模型并不能直接应用于其他开源项目的检测;但是可以用同样的建模方法,必要时对特征工程的参数做适当调整,为其他开源项目训练预测模型.另外,如果想复用在一个项目上的训练经验,迁移学习是值得探讨的. 在实际应用中,我们提供了2套部署场景. 场景1:识别上游Linux内核最新合并的补丁是否是漏洞修复补丁.脚本程序周期性地将Linux官方分支拉取(Pull)到团队的内部内核仓库,脚本检测到更新则通过git show获取新补丁,然后传递给我们的模型识别,模型将识别结果邮件推送给安全工程师. 场景2:内核开发团队补丁评审(review).工程师创建PR(pull request)请求新补丁评审,机器人评审员(reviewer)对补丁进行安全识别,如果识别为安全漏洞修复补丁,则在评审中要求在Log message里增加安全提示性说明,并邮件通知安全工程师确认. 本文提出了一种漏洞修复补丁自动化识别的机器学习建模方法.帮助用户和安全工程师更及时、全面地识别安全漏洞修复补丁.实验结果表明,本文实现的漏洞补丁识别模型可以明显提高识别性能,取得91.3%的精确率、87.53%的召回率,降低误报率,因此,本文的方法是可行且高效的.下一步,有必要对以下工作进行探讨: 1) 语法特征.为补丁构建特征工程时将补丁语法结构作为特征定义、提取的要素.这对于识别复合补丁(可能存在的一个补丁同时涉及漏洞修复、增加新功能、或普通Bug修复)是否涉及安全漏洞修复,以及进一步提高模型预测性能可能是有帮助的; 2) 跨开源项目的迁移学习.出于提升模型的训练效率、预测性能或泛化能力考虑,以及解决一些开源项目可标注数据稀缺问题,应用迁移学习的方法将一个项目的训练学习经验在另一个开源项目的训练中进行迁移复用,是下一步很值得探讨的工作. 作者贡献声明:周鹏负责论文观点的提炼与细化,完成论文撰写,负责试验设计、试验实施、专家意见修改回复等;武延军负责研究方向指引、论文框架、论文评审与详细修改,参与试验设计、专家意见讨论评审等;赵琛负责论文指导、论文评审与修改,参与试验框架设计、对专家意见的改进方法进行改进,开发试验环境保障等.3 实验评估
3.1 度量标准
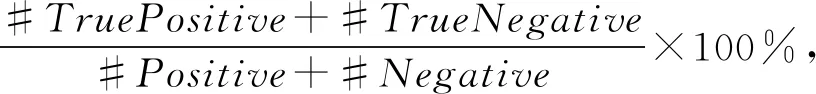
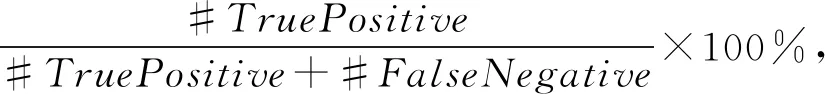
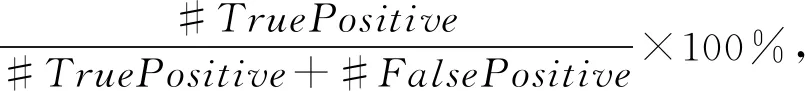
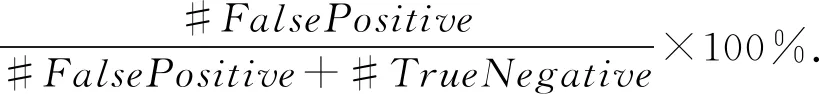
3.2 数据集

3.3 模型训练收敛过程
3.4 模型的预测性能

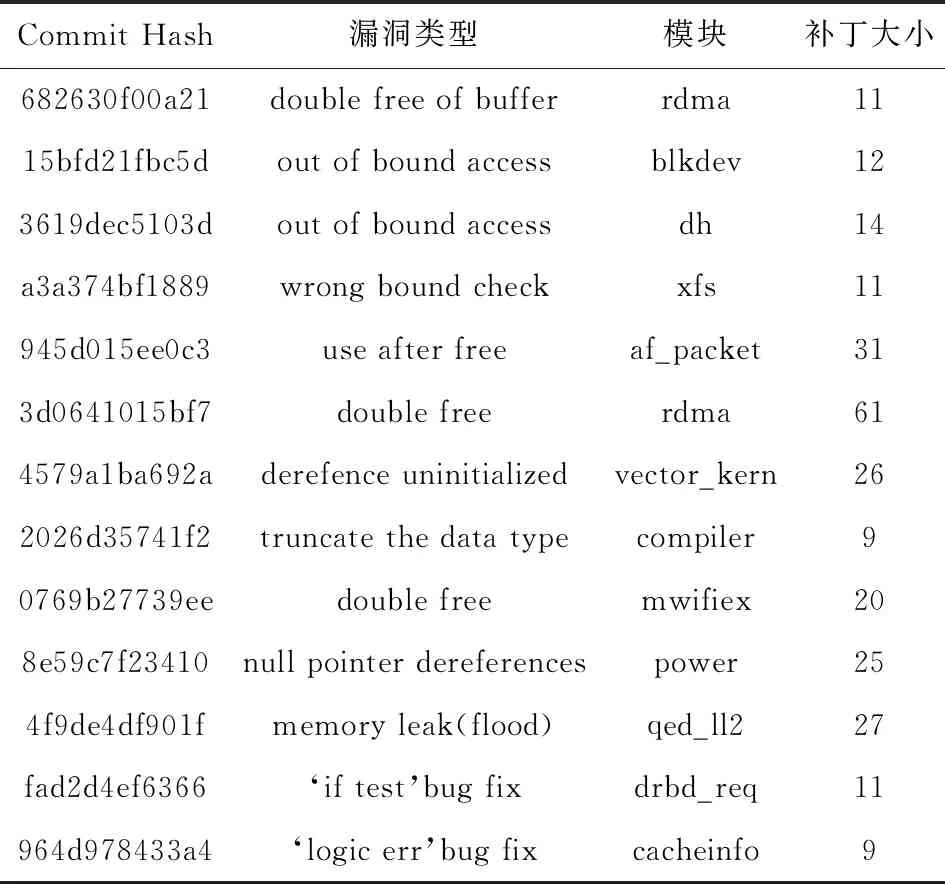
3.5 对unlabled补丁的自动检测
3.6 Linux安全漏洞补丁报告概况

3.7 讨 论
4 系统部署
5 总 结
