基于重构误差的同构图分类模型
2022-01-18蒋光峰胡鹏程仰燕兰
蒋光峰,胡鹏程,叶 桦,仰燕兰
东南大学自动化学院,南京210096
近年来,由于结构化和半结构化数据的爆炸式增长,人们越来越重视对图神经网络(graph neural network,GNN)的研究。来自生物信息学、化学信息学、社交网络、城市计算和网络空间安全等数据都可以自然地表示成标签图数据。此外,企业常常希望以知识图谱的形式存储信息并应用各种机器学习技术来充分挖掘数据价值。
深度学习的发展促进了数据挖掘技术的更新,确切地说是通过对卷积神经网络(convolutional neural network,CNN)和循环神经网络(recurrent neural network,RNN)结构的复用,分别在两种欧几里德空间数据(如图片和序列)上取得了较好的成绩,因此人们尝试在非欧几里德空间应用CNN。以往的研究大多是重新定义卷积层和池化层来处理图数据。
现有的图神经网络(GNN)方法,通常可分为基于谱图卷积和基于空间域卷积。典型的基于谱图卷积有Spectral CNN、ChebNet和GCN等;基于空间域卷积有GraphSAGE、GAT等。
图池化比图卷积的方法要少很多,以往的方法只考虑网络的拓扑结构。随着人们对图神经网络领域的研究加深,更多的图池化方法被提出,如SortPool利用最后一维节点特征排序节点;DiffPool引入基于分配学习的可微池化;SAGPool利用注意力机制学习节点的得分,并保留Top节点。
全局图池化,又称图读出层(readout layer),目的是将图映射到有限维的欧几里德空间。基于统计的方 法 有MeanPooling、MaxPooling 和SumPooling 等。这些方法简单有效,不会增加额外的参数,但损失了大量的结构信息。
上述图卷积和池化方法设计的初衷是解决节点分类、连接预测等图节点级别问题,对图分类等图级别任务所需要的拓扑结构信息提取不充分。此外现有的图读出层设计过于简单,同样损失了大量的拓扑结构信息。
本文提出一种基于重构误差的多重注意力机制同构图分类模型(multi-heads attention wave graph isomorphic convolution based on reconstruction error,RMAWaveGIC),主要贡献如下:
(1)提出同构图卷积WaveGIC。对比现有的算法(GCN、GraphSAGE),WaveGIC 能更有效地提取图拓扑结构信息,更适合图分类任务。
(2)提出基于多重注意力机制的图全局池化(图读出)方法,能更全面地表征整张图,减少全局池化带来的信息损失。
(3)提出基于重构误差的图分类训练算法,训练不仅考虑分类器分类性能,同时考虑图卷积过程中对拓扑结构信息的损失。
实验表明,本文方法在现有的基准数据集上取得了最好的识别准确率。
1 相关工作
1.1 图神经网络
近年来大量的图神经网络模型被提出,包括图卷积神经网络、图残差网络以及图循环神经网络。大部分方法都遵循Gilmer 等提出的神经信息传递(neural message passing)框架,即节点被邻近节点使用可微的聚合函数表达。文献[18-19]详细叙述了GNN 领域近年来的重要研究成果。文献[20]分析了主流GNN对捕获图结构的表达能力,并提出图同构网络(graph isomorphism network,GIN)。
1.2 图池化层
在CNN 中池化层也称下采样卷积核,其操作与卷积操作基本相同,不同的是下采样的卷积核只取对应位置的最大值或平均值,并且在反向传播时参数不需要更新。图池化方法可以划分成三种类别:基于拓扑池化、全局池化和分层池化。
基于拓扑的池化早期通常使用图粗化算法(graph coarsening algorithms)。基于谱聚类算法使用特征分解来得到粗化的图,但是特征分解的时间复杂度高,需要更快更简洁的算法。
全局池化方法考虑图节点特征,使用求和、最大值、均值或神经网络等方法表达整张图。Vinyals 等利用Set2Set方法获取整张图的表征,提出一种通用的图分类框架。SortPool 利用GCN 网络提取的特征值排序节点并传递给下一层网络,首次实现了端到端训练的图分类模型。
全局池化方法无法学习到图结构信息及其关键的分层表征。现实应用中,很多图信息都是层级表征的,例如地图、概念图和流程图等。分层池化方法的设计初衷是使网络既能学习节点特征,也能学习图的拓扑结构信息。可微图池化方法DiffPool学习分类矩阵,将节点映射到一组簇中,输入到GNN 下一层。DiffPool 的空间复杂度高,当处理大图时对硬件要求较高。gPool 使用可学习的向量计算节点得分,并选择得分排名靠前的节点,数学表达式如式(1)~(3)。

其中,表征第层节点特征矩阵;表征第层的邻接矩阵。gPool 虽解决了DiffPool 的空间复杂度问题,但忽略了图的拓扑结构信息。
SAGPool 在合理的空间和时间复杂度下同时考虑拓扑结构和特征信息生成分层表达,式(4)~(9)是其数学表达。

其中,表征节点特征矩阵;表征第层的节点特征矩阵;表征第层的邻接矩阵。
1.3 图自编码


文献[23]提出一种正则化对抗图自编码模型,该模型同时学习图的拓扑结构和节点特征隐向量表示(embedding),并在此基础上训练解码器来重构图的结构。若能从高层特征矩阵中恢复原始邻接矩阵,说明网络能够学习图的拓扑结构信息。
2 方法
2.1 问题定义
使用(,)表示图,其中∈{0,1}代表邻接矩阵,∈R代表节点特征矩阵,每个节点有维特征。给定图数据集D={(,),(,),…,(G,y)},其中y∈У 表示图G∈G 的标签,图分类的目标是学习映射:G →У 将图映射到标签。和标准的有监督学习相比,图分类的困难是在使用常规的机器学习方法(如SVM、DNN 等)分类时,需要从输入图中提取高效的有限维特征向量R。
2.2 同构图卷积层
同构图指的是图中的节点类型和关系类型都仅有一种的图。GNN 利用图邻接矩阵和节点特征矩阵X来学习节点的表征h或图的表征h。GNN 遵循邻居聚合策略,通过式(12)、式(13)聚合邻节点的表示迭代更新当前节点的表示。
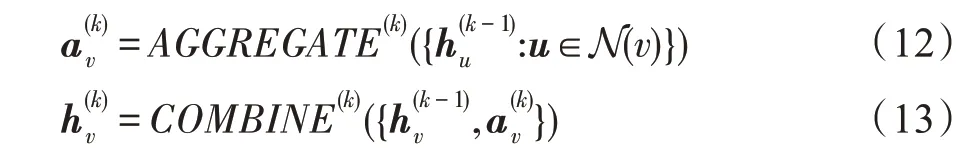

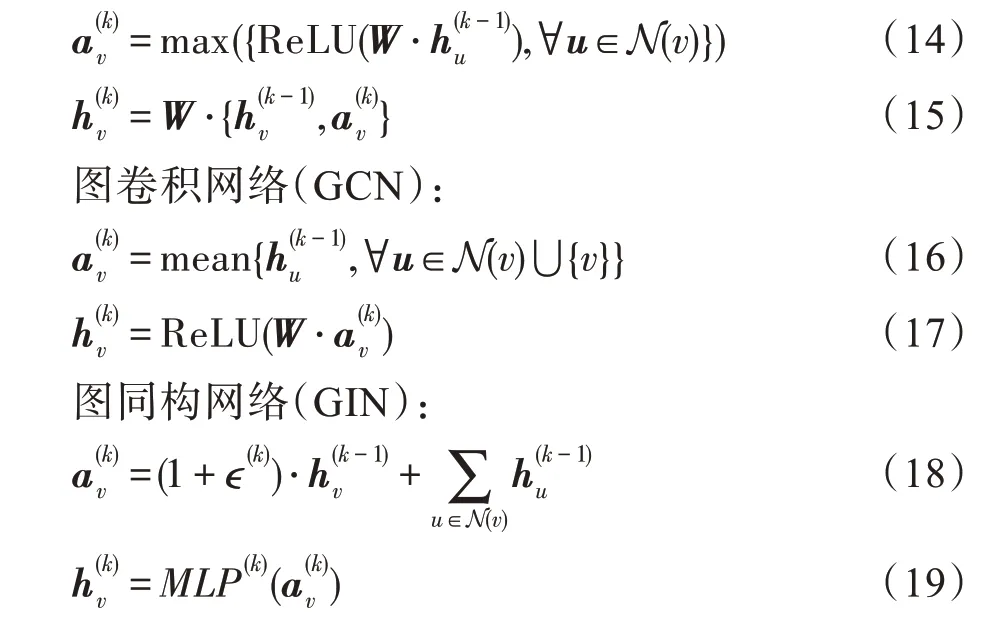
其中,可设置成固定值或可学习的变量,表征中心节点的衰减程度。
本文提出一种能更好学习图拓扑结构特征的卷积单元WaveGIC,其表达形式如式(20)、式(21)。


图1 不同聚合策略的表达能力Fig.1 Expressive ability of different aggregation strategies
在COMBINE 阶段,使用图2 所示结构,门控激活单元使用tanh 和sigmoid 控制信息选通来调整单元状态。ReLU 激活所引起的稀疏性适用卷积神经网络而不适合图数据,因为图数据需要以更平滑的梯度在多层图卷积体系结构上流动。在实验中发现,采用WaveNet中的门控激活函数,即用一个非线性的tanh 函数选通sigmoid 函数的激活函数比使用单一的激活函数,如ReLU、LeakyReLU 等效果好。

图2 WaveGIC 层Fig.2 WaveGIC layer
2.3 基于重构误差学习
2.2节的WaveGIC 相比GCN 等具有更强的拓扑结构表征能力,但随着模型深度的加深,局部拓扑结构的特征表达越来越不明显。因此本文提出一种基于重构误差的图分类学习,即利用WaveGIC 高层表征尝试恢复图的邻接矩阵,如式(22)、式(23)所示:

模型训练的损失函数包含二分类交叉熵损失和图重构误差损失,如式(24)所示:
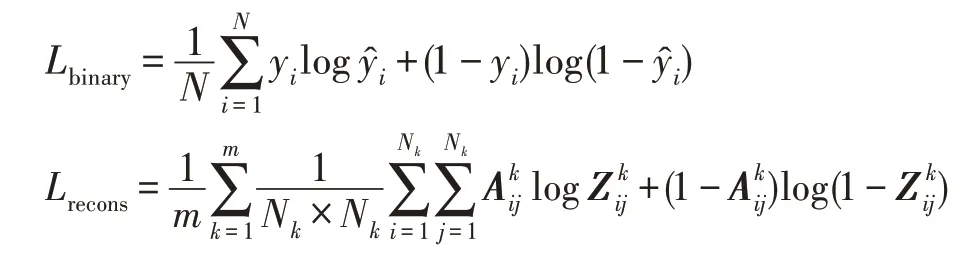

式中,是超参数,实验中设置为0.5。
2.4 多重注意力机制读出层
图读出操作用来生成图的表示,它要求操作本身对节点的顺序不敏感。在欧式空间,旋转图像形成新的图像;但在非欧式空间,图的旋转(如对节点重新编号)不形成新的图,这是典型的图重构。要使重构图与原图表示一致,图读出操作就需要对节点顺序不敏感。在数学上,能够表达这种操作的函数称为对称函数。
本文使用注意力机制以不同权重组合节点特征生成图的表征,使用Multi-Heads 从多角度以不同的注意力权重生成多种图表征,合并作为最终的表征结果。
式(25)到式(27)是多重注意力机制读出层的数学表达式。

其中,F∈R是可学习参数,att代表每个节点的得分,readout代表第重读出层的图向量表示,表示重图读出表示。通过多重注意力机制读出层,将图节点以不同的权重组合,最终形成整张图的表示。
2.5 整体框架
在图3中,输入D=(G,y),首先经过层WaveGIC提取节点的高层特征,并且每层的输出连接多重注意力机制读出层,用于表征不同层次的图嵌入;随后通过Concat 层拼接每层的图嵌入表示,送入后续的1-D 卷积神经网络;最后用DNN 网络学习分类提取的图表示向量。同时,利用WaveGIC 提取的节点高阶表征矩阵,重构原始图的邻接矩阵。

图3 RMAWaveGIC 模型框架Fig.3 RMAWaveGIC model framework
3 实验与结果
3.1 数据集
表1 是5 个来自医学、化工等领域的基准数据集。AIDS是一组化合物数据集,标签表示化合物是否可以抗艾滋病毒活性。FRANKENSTEIN是一组包含节点特征的分子图,标签表示一个分子是诱变剂还是非诱变剂。NCI数据集中每个图表示一个化合物,节点和边分别表示原子和化学键,标签表示抗癌活性分类。NCI1 和NCI109 通常被用来当作图分类的基准数据集。PROTEINS是一组蛋白质图,具有边的节点处于氨基酸序列中或在封闭的三维空间中。
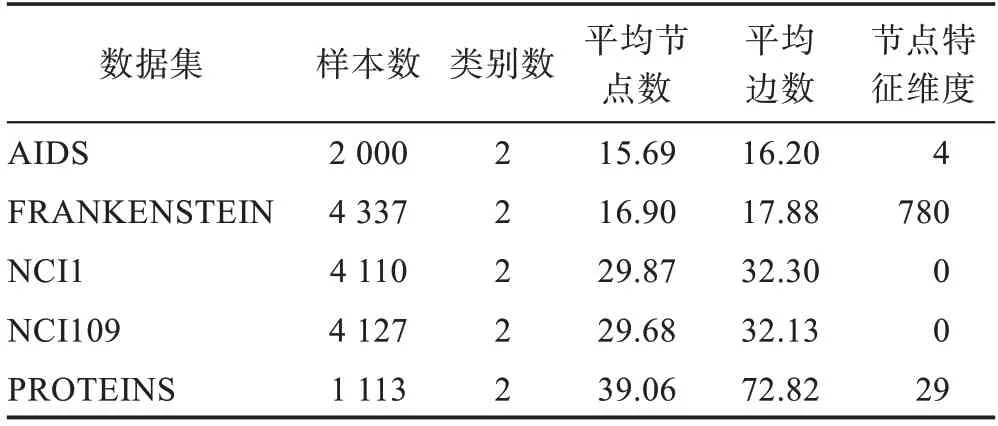
表1 基准数据集基本信息Table 1 Basic information of benchmark data set
3.2 基准模型
常规的图分类方法分为三部分,即卷积层提取节点高层表征、读出层表征整张图和顶层分类网络。把现有的解决图分类的基础算法如Set2Set、SortPool和SAGPool 等作为基准模型,与本文所提WaveGIC、重构误差训练与多重注意力机制读出层构成模型的结构对比。对比模型的基本信息如表2 所示。

表2 基准模型与RMAWaveGIC 模型对比Table 2 Comparison of Base and RMAWaveGIC model
3.3 GNN 评估
实验中采用相同的迭代次数、早停轮数、学习率以及GNN 层数等训练超参。模型评估采取准确率和ROC_AUC 评价指标。准确率的定义如式(28)所示,反映分类器正确分类占总样本的百分比;ROC 全称“受试者工作特征”曲线,AUC 则是该曲线与横坐标的面积,ROC_AUC 反映了分类器将某个随机正类别样本排列在某个随机负类别样本之上的概率。

其中,是正例,是反例,是真正例,是真反例。
3.4 训练步骤
文献[30]论证了不同的数据划分影响GNN 模型的表现。实验中,使用十折交叉验证评估训练结果,减少因训练集划分造成的结果评估不准确的问题。在图4 中,全局模型结构仅使用最后一层表征进行分类学习;分层模型拼接每一层表征进行分类学习。针对每种方法,同时训练全局结构和分层结构模型。

图4 全局模型结构(左)和分层模型结构(右)Fig.4 Global model structure(left)and hierarchical model structure(right)
实验在NVIDIA GTX1080Ti GPU 上进行,使用PyTorch和DGL图深度学习库实现所有的基准模型和所提模型。
4 结果分析
4.1 WaveGIC 对比GCN
从图5 上可以看出,在使用相同的图读出层,WaveGIC 分类损失远远低于GCN;对比表3、表4 中WaveGIC与GCN模型的实验结果可以发现,WaveGIC在5 个基准数据上ROC 平均提升5.13%,并且在节点特征丰富的数据集(PROTEINS)上的结果提升更显著(13.55%)。表明门控激活函数使得梯度更平滑地在多层图卷积体系结构上流动,模型能够得到更充分的学习。此外,门控激活函数增强了模型的复杂度,WaveGIC 可以更好地从拓扑结构与节点特征中提取更加高效的节点表征。

表3 全局模型实验结果Table 3 Experimental results of global model

表4 分层模型实验结果Table 4 Experimental results of hierarchical model
4.2 多重注意力机制读出层
对比WaveGIC 与MHAWaveGIC 模型实验结果,基于多重注意力机制读出层的分类模型比Sum&MaxPooling 读出层模型的分类损失更小(图5),基准数据集上的准确率和AUC 值得到提升,分类性能进一步提高。
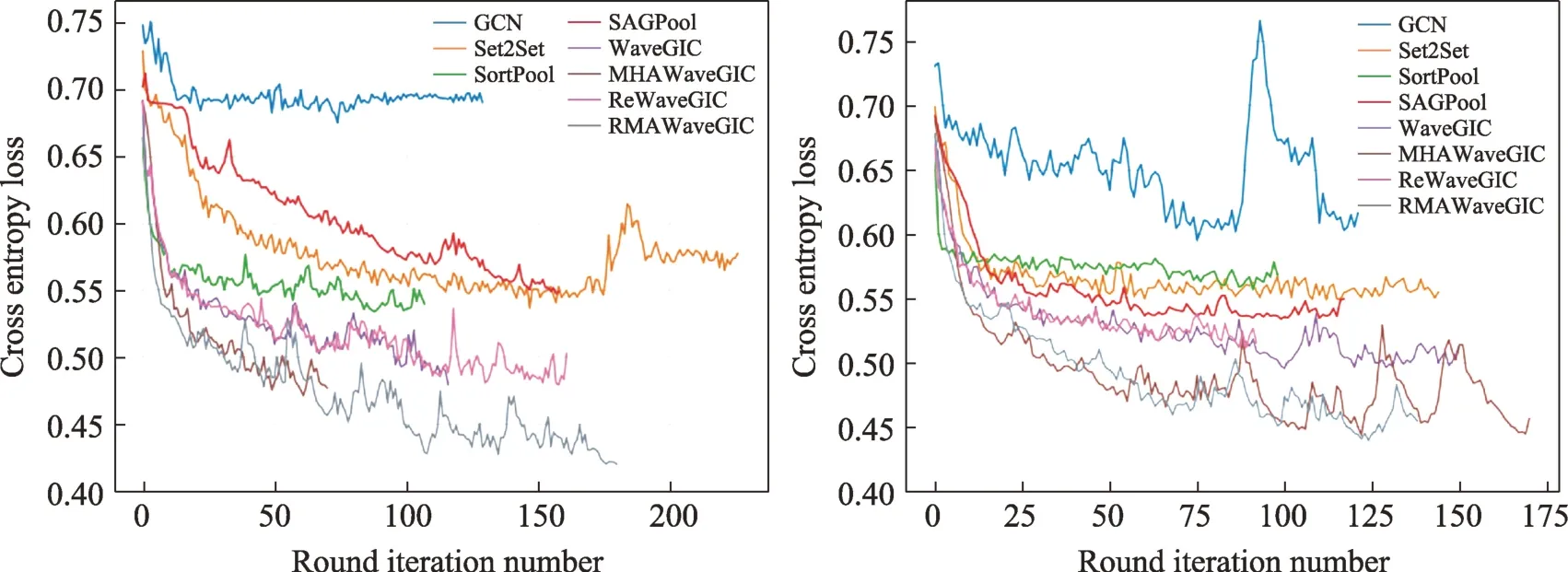
图5 全局结构(左)和分层结构(右)在PROTEINS 数据集上训练损失Fig.5 Train loss of global structure(left)and hierarchical structure(right)on PROTEINS dataset
注意力机制是一种能让模型对重要信息重点关注并充分学习吸收的技术,本文注意力机制主要是让模型能够更加关注关键节点。只从一个角度去学习关键节点,存在偏差,因此设计种不同角度的注意力权重。本文提出的多重注意力机制读出层可以为图的分类任务提供新的图读出方法。
4.3 重构误差损失
图6 展示了ReWaveGIC 模型在PROTEINS 上重构误差损失的收敛曲线。随着迭代轮数增加,损失逐渐减小,说明高层表征学习到图的拓扑结构信息。对比MHAWaveGIC 与RMAWaveGIC 模型,使用结构误差和分类误差共同指导训练(RMAWaveGIC)比仅使用分类误差训练(MHAWaveGIC)的模型结果更加准确。表3 全局结构准确率平均提升1.58 个百分点,表4 分层结构准确率平均提升1.876 个百分点。在分类误差损失保证分类精度的基础上,重构误差损失指导使得高层表征能够恢复图的邻接矩阵,赋予模型学习图的拓扑结构的能力。图由拓扑结构和节点特征组成,综合考虑拓扑结构和节点特征对图的分类是极有裨益的。
图6 ReWaveGIC 全局模型的重构损失Fig.6 Reconstruction loss of ReWaveGIC global model
4.4 全局结构对比分层结构
对比RMAWaveGIC 的全局结构与分层结构模型,分层结构模型的分类准确率在FRANKENSTEIN数据集上比全局结构高0.73 个百分点,在PROTEINS上高1.63 个百分点。节点特征丰富的图数据,各层WaveGIC 都能提取到有效的节点特征与局部结构信息。而节点特征不足的图数据,网络提取的更多是结构信息,高层结构表征可以覆盖低层结构表征。故分层结构适合节点特征丰富的图数据,全局结构适合节点特征不足的图数据。
5 总结
本文提出WaveGIC 卷积层、基于重构误差训练和多重注意力机制读出层,可以同时进行节点特征和拓扑结构信息的端到端学习。RMAWaveGIC 的泛化性能较好,在不同的数据集上都能取得最优的分类准确度和ROC-AUC 得分,尤其适用于小规模并且节点信息丰富的同构图场景,如化合物、蛋白质等分类任务。
目前存在的局限是:(1)重构误差时需要利用特征矩阵重构邻接矩阵,当图结构十分庞大时极其消耗内存空间;(2)对于大规模图,边的连接是稀疏的,这导致计算重构误差时正负样本不均衡,训练偏向无连接边,不利于模型学习。
