基于改进自编码网络的轴承振动异常检测
2022-01-18李贝贝
李贝贝,彭 力
江南大学 物联网工程学院,江苏 无锡214122
轴承作为各种工业现场机械设备的重要零部件之一,对工业流程的顺利进行和设备运行安全有着重要意义。但在长期的高强度、大载荷的复杂工况下,轴承极易出现异常状况,导致故障发生。若能准确、及时地检测到异常数据,则有助于设备及时维护,避免严重事故的发生。在大数据时代,随着传感器和机器学习技术的飞速发展,通过先进理论和方法使用历史采集的状态监控数据提取特征,构建数据驱动的轴承异常检测模型,并保证异常检测的准确性和稳定性,成为了当前研究的热点并具有明确学术价值与应用意义。
轴承的振动监测数据是最直观最方便判断轴承是否出现异常的数据,通过加速度传感器可以方便快速地采集数据并实时检测。振动数据的采集通常需要在多个位置放置多个采集传感器,因此振动数据的特点主要包括:数据量大、维度较低、各维度之间具有一定相关性。
轴承振动异常的检测主要使用许多异常点检测方法。检测方法主要包括:(1)基于统计学的方法,假定大部分正常数据服从相同的数据分布,异常数据则不属于该分布,但此类方法确定数据的概率分布模型以及参数比较困难。(2)基于邻域的异常检测方法,如近邻算法(-nearest neighbor,NN)和局部异常因子算法(local outlier factor,LOF)。NN算法易于实现,但对于异常数据占比较少、样本不平衡的轴承振动数据表现较差。LOF 算法通过局部可达密度弥补NN 算法对于样本不平衡的数据集表现较差的缺点,但是LOF 算法对于参数的确定极为敏感,且算法复杂度高,时间成本高。(3)支持向量机(support vector machine,SVM),通过训练数据对象的边界或特征来确定异常数据。此方法需要大量能用于训练的正常数据,并确定相应参数,且参数的设置对于检测效果影响较大。(4)孤立森林(isolation forest,iForest)算法,通过构建隔离树检测异常数据,具有线性时间复杂度。但其采用无监督的方式,忽略数据特征之间的相关性进行随机选取特征构建隔离树,因此检测准确度较低。
近年来,深度神经网络(deep neural network,DNN)已在特征的自动提取和识别上成功应用,可自适应地提取信息丰富的重要特征,简化繁重且有挑战性的特征提取过程,具有较好的普适性。自编码器(autoencoder,AE)最早由Rumelhart 等人提出,并将其用于复杂数据处理。随后,Hinton 等人提出了深度学习神经网络,由此产生了深度自编码器。在深度自编码器的基础上,Ng提出高维而稀疏的隐层,对隐层加入稀疏性限制提高自编码器特征学习能力,提出了稀疏自编码器。如今,自编码器和深度神经网络被广泛应用于故障诊断、图像识别、异常检测等领域中。自编码器和神经网络也被研究应用于轴承振动等工业数据的异常检测问题上,自编码器因其优越的特征提取能力得到了大量研究与应用。
由于传感器技术的发展,轴承振动数据的采集更加方便快速,但导致数据量庞大,在自编码器和神经网络的训练过程中,过大的数据量使得训练效率较低并且检测准确度无法得到有效提升。为了减少自编码器和神经网络的训练数据量,本研究通过正常振动数据样本的马氏距离(Mahalanobis distance)得到判定阈值,计算数据与正常数据均值的马氏距离,将没有超过判定阈值的数据记为不确定数据并将该部分数据用于自编码器和神经网络的训练。
对于神经网络参数初始化问题,传统的权值随机初始化方法依然会有陷入局部最优的风险。本研究结合自编码器和Sigmoid 分类器构建自编码网络(autoencoder network,AN)解决了神经网络参数初始化问题,并且减少了网络训练次数和时间,提高了训练效率。本研究将训练完成的自编码器中编码层输出作为分类器输入,利用自编码器获得的编码层权值和偏差解决神经网络参数初始化问题,最后使用标签化数据进行有监督的微调以完成整个自编码网络的训练。
轴承振动数据各特征之间具有相关性,马氏距离可用作判断数据异常与否的重要特征,因此本研究将数据的马氏距离作为特征添加到数据的特征中用于自编码网络的训练过程,有效提高了自编码网络对轴承振动数据的异常检测准确度。
自编码器常被用在高维数据的特征提取和降维过程中,而对于特征较少的低维轴承振动数据,自编码器的特征提取和降维作用并不显著。为了增强自编码器的特征提取能力以获得更好的编码层参数,提高整个自编码网络的异常检测效果,本研究加入了稀疏约束条件并构建先升维再编码的改进自编码器结构,提高了自编码器特征提取能力,并通过实验证明了该结构具有更好的收敛性和异常检测效果。
本研究的主要贡献如下:通过马氏距离快速判别出一部分异常数据以减少自编码网络的训练数据量;将自编码器和分类器结合解决了神经网络的参数初始化问题,减少了网络训练时间;通过数据加入马氏距离特征、先升维再编码的自编码器结构、稀疏约束条件,构建了一种改进自编码网络用于轴承振动异常检测;通过实验证明了该方法对于低维轴承振动数据具有较好的异常检测效果。
1 基本概念
1.1 马氏距离
印度统计学家Mahalanobis 提出了一种考虑到各变量之间相关性的广义距离,称为马氏距离(Mahalanobis distance),其主要思想是利用向量间的协方差矩阵来表示其马氏距离。
对于包含个数据、每个数据维度为的数据集=(,,…,X),其中均值为=(,,…,μ),协方差矩阵为,其中一数据为=(,,…,x),则其马氏距离如下所示:

其中,为协方差矩阵的逆矩阵,马氏距离可看作数据与总体数据均值的距离。
由于马氏距离的计算需要使用数据集的协方差矩阵,较欧式距离等其他距离的最大优势为马氏距离考虑数据特征之间的相关性。在数据集中,如果一个数据的马氏距离越小,则说明其与数据集中均值数据的相似度越大。在轴承振动数据等低维工业数据中,由于工艺流程和采集设备等缘故,数据的每个特征之间有着不可忽视的相关性,马氏距离更适合用于轴承振动数据的距离表达。
考虑在轴承振动异常检测中,假设某数据为正常数据,使用正常数据集的均值和协方差矩阵根据式(1)计算其马氏距离。若该数据马氏距离与正常数据马氏距离接近,说明该数据与正常数据相似度较大,该数据大概率为正常数据;若该数据马氏距离与正常数据马氏距离相差较远,说明该数据与正常数据相似度较小,则该数据大概率为异常数据。因此能够使用轴承振动数据的马氏距离来判断数据为异常数据的可能性,该思想在2.1 节中详细说明。
如上所述,轴承振动数据的马氏距离可以用来判断该数据为异常数据的可能性,故考虑将数据的马氏距离作为轴承振动数据的一个特征。由于正常数据和异常数据的马氏距离有较大的差别,在神经网络的训练过程中,加入的马氏距离特征将作为重要特征,有利于提升神经网络的异常检测效果。因此在本研究提出的改进自编码网络训练和检测过程中,将数据的马氏距离加入数据特征中,5.1 节中通过对比实验证明了该思想的优越性。
1.2 自编码器
自编码器主要包括编码和解码阶段,且结构对称,即若存在多个隐层时,编码和解码阶段的隐层数量及结构相同。主要结构由输入层、隐层和输出层组成,如图1 所示。隐层对输入层数据进行编码,输出层对隐层表达进行解码重构原始数据,最小化重构误差以获得最佳的隐层表达。其目标是拟合一个恒等函数,使得每个输出值尽可能等于相对应的输入值。
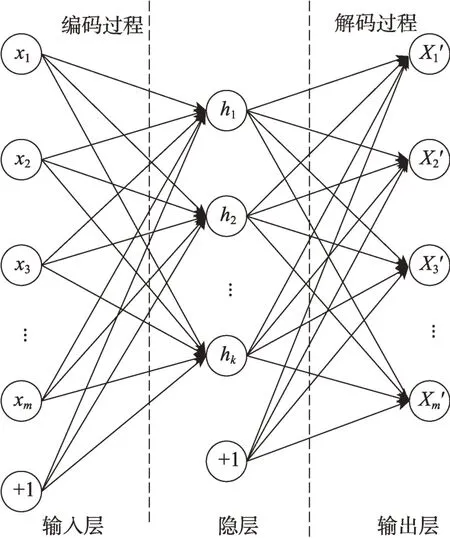
图1 自编码器结构Fig.1 Structure of AE
对于数据集=(,,…,X),为数据个数,每个数据维度为,即X∈R(=1,2,…,)。每一个数据X经过编码过程得到隐层表达,编码过程可描述为:

其中,和为编码权重和偏置,σ为编码层激活函数,目前比较常用的有Sigmoid、Tanh、ReLU 等。然后隐层表达经解码过程得到重构数据X′,解码过程可描述为:

其中,′和′为解码权重和偏置,取′=,σ为解码层激活函数。
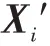

其中,为单个数据的损失函数,在式(4)中为均方误差损失函数。同时为了防止出现过拟合,给代价函数添加一个L2 正则化权重衰减项,为惩罚因子,控制正则化项影响权重衰减的程度,得到最终的损失函数为:

文献[17]证明,使用Sigmoid 激活函数时,交叉熵损失函数要优于均方误差损失函数,由于本研究构建的自编码网络最终输出为二分类,且通过实验得到,无论是自编码器的训练阶段还是编码层结合分类器阶段,Sigmoid 作为输出层激活函数效果最理想,因此本研究采用交叉熵代价函数为:

在自编码器的训练过程中,通过编码和解码过程使代价函数最小来学习并提取数据重要的特征,即获得最佳的隐层表达。
2 结合马氏距离和自编码网络的异常检测
2.1 使用马氏距离快速检测异常数据
假设采集到的轴承振动数据集记为=(,,…,X),数据维度为。其中正常数据集记为X=(,,…,X),正常数据均值为μ=(,,…,μ),协方差矩阵为Σ,根据式(1)计算得到正常数据集中每个数据的马氏距离记为:

其中,M表示在正常数据集中第个正常数据的马氏距离。
接下来根据式(1)计算整个数据集中所有数据的马氏距离。由于某一数据的变化会影响到数据集均值的变化,马氏距离夸大了微小变化向量的作用,从而影响其他数据的马氏距离计算。为了改善上述马氏距离的缺点,在计算所有数据的马氏距离时使用的均值和协方差矩阵仍然为正常数据集中的μ和Σ,显然独立的μ和Σ不受向量变化影响;根据1.1节,得到的某个数据的马氏距离可看作该数据与正常数据集均值的距离。则数据X的马氏距离记为:

根据统计学相关知识以及后续对轴承振动数据的实验分析可知:如果数据X为正常数据,则其马氏距离D(X)应符合正常数据马氏距离数据集即M的统计分布;如果X为异常数据,则D(X)不符合M的统计分布。


通过实验验证,马氏距离不在(,)区间内的数据均为异常数据。将马氏距离在(,)区间内的数据判定为不确定数据,记为X,然后使用不确定数据集X训练自编码网络以完成模型构建。同时将数据的马氏距离加入到数据特征中,用于自编码网络的训练。
于是,通过马氏距离检测出了一部分异常数据,将剩余的不确定数据输入自编码网络中。对于数据量大的轴承振动数据而言,减少了用于自编码网络的训练数据,并且能够根据马氏距离判别阈值快速判别出一部分异常数据,提高了检测效率。
2.2 自编码器的构建
为了提高自编码器学习数据特征的能力,在自编码器基础上添加约束条件,在其代价函数上加入稀疏惩罚项,使其形成稀疏自编码器。稀疏自编码器代价函数为:
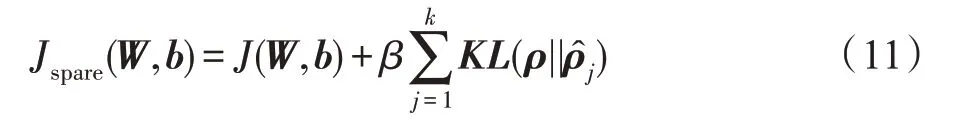


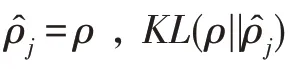
本研究使用自编码器的主要目的是利用其学习并提取数据特征的能力提取数据更有用的特征,得到更好的隐层表达用于结合分类器。而对于低维轴承振动数据,由于其维度较低、特征较少,不利于自编码器提取其特征,导致自编码器的收敛性较差。在实际应用中已证明了自编码器对高维数据优秀的特征提取能力,因此考虑将数据先升维再编码的自编码器结构,通过升维结构提高了数据的维度,类似于增加了数据的特征。增加了升维层必然增加自编码器训练的运算复杂度,也相应地增加了自编码器单次训练的时间,但是自编码器通过较少的训练次数便可以得到最佳的隐层表达,其收敛速度增大。就总体时间而言,先升维再编码的自编码器能够用较少的时间完成训练,得到最佳隐层表达。因此不同于一般自编码器直接降维编码的结构,本研究基于稀疏自编码器,构建先升维再编码的网络结构以提升对轴承振动数据的特征提取能力,同时在解码阶段保持与编码阶段的对称结构。5.2 节中通过实验证明了先升维再编码的自编码器结构收敛性更好,训练时间更短,提升了自编码器对低维数据的特征提取能力。
本研究构建的改进自编码器结构如图2 所示,X为输入数据,数据维度为维,通过升维过程得到隐层表达U,其中>,维度升为维,同时解码过程保持对称结构。 h为编码层输出,为编码之后的维度,使用训练数据通过无监督贪婪算法使代价函数最小,从而完成自编码器的训练以得到最终编码层输出h作为分类器的输入。

图2 改进自编码器结构Fig.2 Improved structure of AE
2.3 自编码器与分类器结合构建自编码网络
通过自编码器的训练,得到了最优的权值和偏差,将h作为分类器的输入,把最优的和作为网络的初始化参数,解决了神经网络参数初始化问题。如图3 所示,S为使用Sigmoid 激活函数的分类层,h作为其输入,X为一维输出结果,表示正常或异常数据,通过输入标签化训练数据,结合误差反向传播算法和随机梯度下降进行有监督的参数微调,最终完成整个自编码网络的构建。

图3 有监督的微调Fig.3 Supervised fine-tuning
通过自编码器的训练得到了较为合适的网络初始化参数,因此在自编码网络有监督的微调阶段,能够减少所需训练次数,提高整个网络的训练效率。在5.3 节中,通过与普通DNN 的对比证明了将自编码器与分类器结合的方法能显著减少网络的训练时间。
文献[19]指出,神经网络的隐层数量比学习算法和自编码器结构对性能的影响更加重要,本研究主要关注自编码器用于轴承振动异常检测,因此在此只使用单层的神经网络分类器结构,由于是二分类任务,故单层使用Sigmoid 激活函数,输出分类结果。
2.4 整个异常检测模型构建过程
首先对所有振动数据归一化处理,并从中提取出部分正常数据,计算正常数据的马氏距离,根据式(9)、式(10)得到马氏距离判别阈值。
根据式(8)得到所有数据的马氏距离,将马氏距离超过阈值的数据判定为异常数据,没有超过阈值的数据记为不确定数据,并将数据的马氏距离加入数据特征中。
将加入马氏距离特征的不确定数据集作为图2 所示的改进自编码器的输入,以无监督的方式训练自编码器,得到最优的编码层输出h以及最优的权值和偏差参数。
将h作为Sigmoid 分类器的输入,使用带标签的不确定数据作为图3 所示的结构中的输入,进行有监督的微调以得到整个网络的最优参数,完成自编码网络的构建。
随机选取全部振动数据的一部分作为测试数据,根据式(8)得到其马氏距离,将超过马氏距离判别阈值的数据判定为异常数据,将没有超过阈值的数据加入马氏距离特征后放入训练好的自编码网络中,得到最终检测结果。从而测试整个异常检测模型的异常检测效果。
3 实验准备
实验环境为CPU Intel Core i5-6500 3.20 GHz、12 GB RAM 和Windows10 操作系统,使用python3.6下Keras框架实现。
3.1 实验数据
实验过程所用数据集为美国国家航空航天局(National Aeronautics and Space Administration,NASA)提供的智能维护系统(intelligent maintenance system,IMS)采集的轴承振动数据集,记作IMS Bearing data。该数据集通过加速度传感器按照一定频率采集机械设备的轴承振动数据,每隔10 s 能够采集到20 480 条数据;共包含3 个子数据集,每个数据集均经过长时间数据采集,包含从正常到异常的振动数据。本实验先选择数据集1 描述实验过程,该数据集是通过4个加速度传感器采集同一轴承的各部分振动数据得到的,故该数据有4 个特征,由于传感器分布于同一轴承设备,各特征具有一定相关性。之后,使用IMS Bearing data 剩余的数据集2、数据集3 以及XJTU-SY数据集进行实验,进一步观察本研究提出方法的异常检测效果。
3.2 具体实验流程
为了进一步提高实验中异常检测模型的构建效率,更好地体现异常检测效果,本实验需对数据集进行一定的预处理。首先由于轴承振动数据不具有突变性,为了提高实验效率,本实验将每10 s 的数据求平均值,将其归并为1 条数据,用该平均值表示。然后将数据归一化到[0,1]区间,有利于更好地进行自编码网络的训练。随后,根据2.2 节中的模型构建过程,经过马氏距离快速检测异常数据并得到不确定数据,随后进行自编码器的训练,与Sigmoid 分类器结合,构建自编码网络检测模型。整个异常检测模型如图4 所示。

图4 轴承振动异常检测模型Fig.4 Bearing vibration abnormal detection model
3.3 评价指标
为了更易说明实验的评价指标,本实验定义异常数据为正类,正常数据为负类,因此评价指标混淆矩阵如表1 所示。

表1 评价指标混淆矩阵Table 1 Evaluation index confusion matrix
研究中使用准确率(Accuracy,)、精确率(Precision,)、召回率(Recall,)、F1 值(1)这4个度量标准来评价异常检测效果,这4 个指标越接近1,则表明效果越好。
准确率()为所有预测正确的数据量占总数据量的比重,表达式为:

精确率()也称查准率,即数据正确预测为异常数据的数据量占全部预测为异常数据的数据量的比重,表达式为:

召回率()也称查全率,即数据正确预测为异常数据的数据量占全部实际为异常数据的数据量的比重,表达式为:

F1 值(1)为精确率和召回率的调和平均数,在异常检测中,1 值能更全面地说明检测方法的效果,取值范围从0 到1,越接近于1 表示算法效果越好,其表达式为:

4 实验过程
实验使用的数据集1包含4个特征,即通过加速度传感器在4个位置采集到的振动数据,记为Bearing1、Bearing2、Bearing3、Bearing4。其变化如图5 所示,在时间点“2004-02-16 4:02:39”开始出现异常数据,由于轴承异常为不可逆的,该时间点之后采集到的数据均为异常数据。经过预处理后的数据集1 样本大小如表2 所示。

图5 数据集1 的轴承振动数据Fig.5 Bearing vibration data from dataset 1

表2 数据集1 样本大小Table 2 Size of dataset 1
4.1 使用马氏距离快速判别异常数据
实验中选择正常数据中时间点“2004-02-13 11:02:39”到“2004-02-14 23:52:39”之间的数据用于计算马氏距离判别阈值,该部分数据如图6 所示。

图6 正常轴承振动数据Fig.6 Normal bearing vibration data
将实验数据集进行预处理之后,根据式(1)计算上述正常数据的马氏距离,结果如图7 所示。同时根据式(9)、式(10)得到马氏距离判别阈值为19.23,为-0.38。

图7 正常数据的马氏距离Fig.7 Mahalanobis distance for normal data
接下来根据式(8)得到所有数据的马氏距离,如图8 所示,并通过马氏距离判别阈值快速判别异常数据与不确定数据。

图8 所有数据马氏距离Fig.8 Mahalanobis distance for all data
由图8 可知,许多异常数据的马氏距离明显超过了,将马氏距离超过的数据判定为异常数据。通过实验,根据式(14)得此次异常检测精确率为1,说明此次检测结果为异常的数据均为真实异常数据,所有正常数据的马氏距离均未超过。将马氏距离未超过的数据作为不确定数据集进入自编码网络的训练阶段,其中包含正常数据与异常数据。
判定为异常数据样本个数为362,得到不确定数据样本个数为622,不确定数据集如表3 所示。将超过阈值的异常数据快速检测出来,提高了检测速度,同时明显减少了训练样本数量,有利于提高自编码网络的训练效率。

表3 不确定数据集Table 3 Uncertain dataset
4.2 自编码器的构建及训练
在得到各数据的马氏距离之后,将其马氏距离也作为数据的一个特征,因此数据的特征即维度增加到5 个,在后续的实验中,将证明加入马氏距离作为数据特征可增强异常检测的效果。
本实验构建以式(11)为代价函数的稀疏自编码器,首先构建如图2 所示的先升维再编码的改进自编码器结构。由于输入数据为5 维,自编码器的输入层为5 维。升维层和编码输出层的维数需通过实验进行确定,而这两层的维数关系到自编码器与分类器结合的自编码网络异常检测效果,因此升维层和编码输出层的维数通过4.3 节中自编码网络异常检测实验确定。在此,构建结构为5-10-2-10-5 的先升维再编码的改进自编码器以调节其他参数。
由于在代价函数中加入了稀疏性限制,稀疏惩罚项权重系数和稀疏常数的设置尤为重要。为了更为明显地观察自编码器重构误差随参数的变化,将自编码器的训练次数设置为10,进行5 次实验取最后重构误差的平均值。图9给出了稀疏惩罚项权重系数与自编码器重构误差的关系,图10 给出了稀疏常数与自编码器重构误差的关系。由图9、图10可得稀疏惩罚项权重系数和稀疏常数的最佳值分别为0.20 和0.04。自编码器的参数设置如表4 所示。

图9 自编码器训练误差随β 的变化Fig.9 Training loss changes with β

图10 自编码器训练误差随ρ 的变化Fig.10 Training loss changes with ρ

表4 自编码器参数设置Table 4 Parameter setting of autoencoder
4.3 自编码器结合分类器构建自编码网络
将上述训练完成的自编码器编码(隐层)输出层作为Sigmoid 分类器的输入层以构建如图11 所示的改进自编码网络,将通过自编码器得到的最优和作为网络的初始参数。通过输入标签化的数据进行如图3 所示的有监督的微调,迭代训练次数为50。
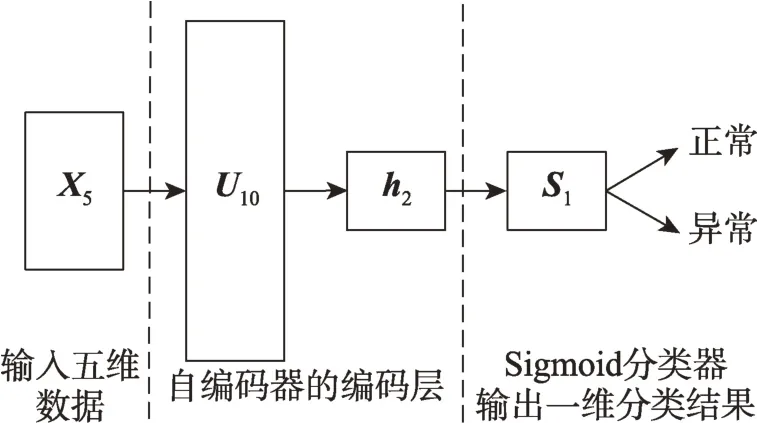
图11 改进自编码网络Fig.11 Improved autoencoder network
对于本研究提出的改进自编码网络中的升维层和编码输出层的维数,在此通过改进自编码网络对不确定数据集的异常检测实验来确定。为了增强实验的可靠性和准确性,采用5 折交叉验证方法进行实验,将不确定数据集随机均匀分为5 份,轮流将其中1 份作为测试数据,剩余4 份作为训练数据。将5 次实验结果数据的平均值作为实验结果。实验结果随两个层的维数的变化如图12、图13所示。从图12可知,将升维层的维数设置为10 最合适;另外观察到维度小于5 即没有升维时,异常检测效果较差,而当维度高于5 即升维时,效果较好,进一步证明了先升维再编码的网络结构有利于提高自编码网络异常检测效果。从图13 可知,将编码输出层的维数设置为2 最合适,从自编码器原理可知,由于输入数据维度为5 维,编码输出层的维度必须小于5。

图12 实验结果随U 层维度变化图Fig.12 Experimental result changes with dimension of U layer

图13 实验结果随h 层维度变化图Fig.13 Experimental result changes with dimension of h layer
5 对比实验
为了从不同角度进一步考察提出方法的有效性,设计4 组不同对比实验:(1)数据是否加入马氏距离特征进行构建自编码网络的异常检测效果对比;(2)传统自编码网络和改进自编码网络的对比;(3)本研究提出的异常检测方法与其他传统异常检测方法的对比;(4)将本研究提出的方法用于IMS Bearing data 的另外两个数据集以及XJTU-SY 数据集,观察其检测效果。
5.1 数据是否加入马氏距离特征的对比
为了研究将数据的马氏距离作为数据的特征放入改进自编码网络中进行训练对异常检测效果的影响,将加入马氏距离作为特征的不确定数据集和不加入马氏距离作为特征的不确定数据集分为两个数据集,分别训练本研究提出的改进自编码器和改进自编码网络并测试。
不加入马氏距离作为特征的不确定数据具有4个特征,因此输入层维度改为4。将自编码器的迭代训练次数设置为15,改进自编码网络的训练次数设置为25,此时已经得到较低的训练误差。同样采用4.3 节中提到的5 折交叉验证方法进行实验,实验结果如表5 所示。可证明,将数据的马氏距离作为数据的一个特征,可有效提高本研究提出的改进自编码网络异常检测效果。

表5 训练数据是否加入马氏距离的对比Table 5 Comparison of training data with or without Mahalanobis distance
5.2 传统自编码网络和改进自编码网络的对比
首先,需要构建传统自编码器并结合分类器构建传统自编码网络。于是在本实验中,构建结构为5-2-5 的直接降维编码的如图1 所示的传统自编码器,除网络结构外的参数与4.2 节中构建的改进自编码器相同。同4.2 节所述,将不确定数据集用于训练传统自编码器。同4.3 节所述,将训练完成的传统自编码器的二维编码(隐层)输出层作为Sigmoid 分类器的输入层以构建如图14 所示的传统自编码网络,并通过输入标签化的数据进行有监督的微调,迭代训练次数仍然为50。

图14 传统自编码网络Fig.14 Traditional autoencoder network
首先进行传统自编码器和改进自编码器的训练重构误差的比较,将不确定数据集作为两种自编码器的输入进行50 次迭代训练,两者的训练重构误差曲线如图15 所示。可知,在迭代训练次数到达15 次左右时,改进自编码器的训练误差基本达到了最小值,因此在后续对比实验中,将改进自编码器的迭代训练次数设置为15。

图15 自编码器误差曲线比较Fig.15 Comparison of autoencoder loss
传统自编码器和改进自编码器的训练时间对比如表6 所示,为得到最佳的隐层表达,传统自编码器需要50次迭代训练,而改进自编码器只需15次迭代训练。
如图15 所示,先升维再编码的改进自编码器通过更少的训练次数达到了最小的训练误差即收敛速度更快,因此改进自编码器较传统自编码器具有更好的收敛性;如表6 所示,虽然先升维再编码的结构增加了单次迭代训练的时间,但是由于训练次数所需更少,改进自编码器的训练所需总时间更短。综上,先升维再编码的改进自编码器具有更好的低维数据特征学习能力。

表6 自编码器训练时间的对比Table 6 Comparison of autoencoder training time
接下来进行传统自编码网络和改进自编码网络在收敛性上的比较。将不确定数据集中的数据放入上述两个自编码网络进行训练,训练误差曲线如图16 所示,训练准确率()曲线如图17 所示。可知,在迭代训练次数到达30 次左右时,改进自编码网络的训练误差基本达到了最小值且训练准确率也基本达到最大值,而传统自编码网络需要50 次以上的迭代训练次数才能够将训练误差降低到最小值并得到最大的训练准确率。因此在后续对比实验中,将改进自编码网络的迭代训练次数设置为30。

图16 自编码网络误差曲线比较Fig.16 Comparison of autoencoder network loss

图17 自编码网络准确率曲线比较Fig.17 Comparison of autoencoder network accuracy
传统自编码网络和改进自编码网络的训练时间对比如表7 所示,改进自编码网络训练次数设置为30,而传统自编码网络迭代训练次数为60 时才获得与改进自编码网络相同的训练误差和准确率。

表7 自编码网络训练时间的对比Table 7 Comparison of autoencoder network training time
如上所述,改进自编码网络的收敛速度要明显优于传统自编码网络,前者能够用更少的迭代训练次数得到不小于传统自编码网络的收敛精度,故改进自编码网络的收敛性更好;在训练时间方面,虽然改进自编码网络的单次迭代训练时间较长,但其所需迭代训练次数较少,训练所需总时间更短。综上,改进自编码网络能达到更好的训练效果。
仍然采用5 折交叉验证方法进行传统自编码网络和改进自编码网络的异常检测效果对比实验,同样将不确定数据集随机均匀分为5 份,轮流将其中1份作为测试数据,剩余4 份用于网络训练数据。将5次实验结果数据的平均值作为实验结果,如表8 所示。由表8 及以上实验可知,对于低维轴承振动数据,本研究提出的改进自编码网络异常检测效果要优于传统自编码网络。

表8 传统自编码网络与改进自编码网络的对比Table 8 Comparison between traditional autoencoder network and improved autoencoder network
为对比自编码网络的稳定性,进行在不同训练量的情况下传统自编码网络和改进自编码网络的异常检测效果对比。在网络训练阶段,分别选用20%、40%、60%、80%的不确定数据集进行训练,其余数据用于测试。自编码器迭代训练次数为15,自编码网络迭代训练次数为30,每个实验重复20 次取实验结果平均值,不同训练量下的实验结果对比如表9所示。

表9 不同训练数据量下的实验结果对比Table 9 Experimental results comparison under different amounts of training data
由表9 可知,改进自编码网络在不同训练数量的情况下,异常检测效果均比传统自编码网络要好。如图18 所示,随着训练数据量的增加,改进自编码网络检测效果越来越好,具有一定的稳定性。

图18 实验结果随训练数据量变化图Fig.18 Experimental result changes with amount of training data
5.3 与其他异常检测方法的对比
同样采用5 折交叉验证方法进行实验,使用IMS Bearing data 中的数据集1,将本研究提出的轴承振动异常检测方法与其他异常检测方法进行对比实验。实验结果如表10 所示。

表10 异常检测算法与所提方法的对比Table 10 Comparison of anomaly detection algorithms with proposed method
由表10 可知,本研究所提方法对低维轴承振动数据的异常检测要优于其他异常检测方法。
在表10 中,DNN 的结构设计为5-10-2-1,并将马氏距离添加进特征,与改进自编码网络结构相同,但是没有自编码器的训练阶段。实验中发现,由于不恰当的初始化而陷入局部最优的情形,DNN 需要更多的训练次数而且稳定性差。实验中,DNN 平均需要80 次迭代训练才能达到最小的训练误差,每次迭代训练时间平均为141 μs,因此DNN 所需训练总时间为11 280 μs;本研究所提网络的训练时间包括自编码器的训练时间和自编码网络的训练时间,通过5.2节可知训练总时间为6 990 μs。可见通过自编码器训练后结合分类器构建的自编码网络比同结构的普通神经网络所需训练时间更少,训练效率更高。
综上,本研究所提方法通过自编码器训练得到的隐层参数用于初始化分类器网络,减少了网络训练次数,大幅提高了网络的训练效率。
5.4 使用其他数据集的实验
IMS Bearing data 中的数据集2 通过8 个不同位置的加速度传感器获取数据,因此数据集2 特征为8个,在时间点“2003-11-21 12:08:36”开始出现异常数据,其数据变化如图19 所示。IMS Bearing data 中的数据集3 通过4 个不同位置的加速度传感器获取数据,数据集3 特征为4 个,在时间点“2004-04-15 10:21:53”开始出现异常数据,数据集3 的数据变化如图20所示。XJTU-SY数据集使用两个加速度传感器采集轴承水平和竖直方向上的振动数据,每分钟采样32 768个样本,因此其数据特征为2 个,数据预处理时将每秒钟采集到的数据使用平均值归为1 条数据。经过预处理之后的3 个数据集样本大小如表11 所示。
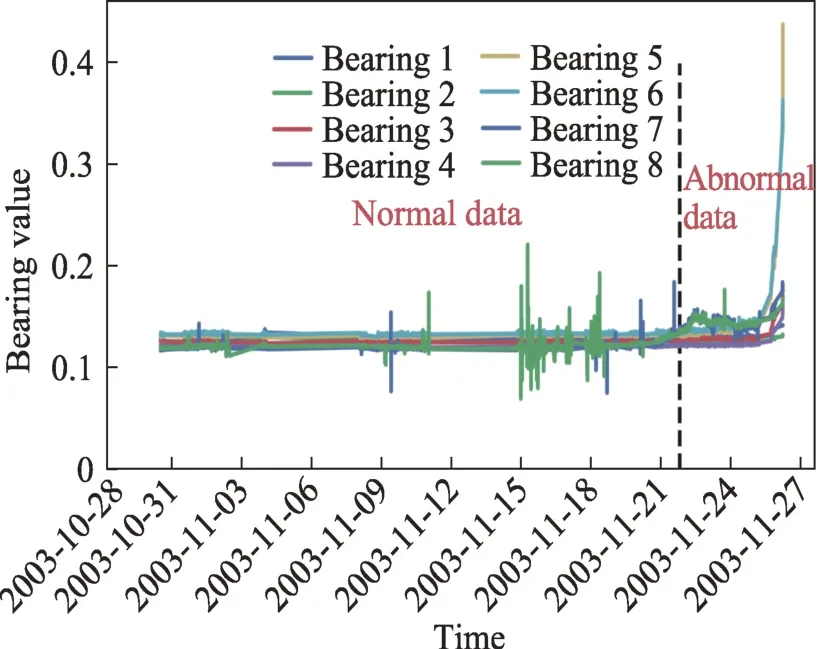
图19 数据集2 的轴承振动数据Fig.19 Bearing vibration data from dataset 2

图20 数据集3 的轴承振动数据Fig.20 Bearing vibration data from dataset 3

表11 3 个数据集样本大小Table 11 Size of 3 datasets
同样采取上文所提的5 折交叉验证方法进行实验,实验结果如表12 所示。可知本研究提出的方法在另外3 个数据集上保持了较好的检测效果,因此对于低维轴承振动数据具有一定的泛化能力。尤其数据集3 为异常数据占比较少的不平衡数据集,本研究提出的方法依然具有良好的检测效果。

表12 在3 个数据集上的实验结果Table 12 Experimental results on 3 datasets
6 结束语
本研究针对轴承振动数据维度低、数据量大、各特征之间具有一定相关性的特点,提出了一种结合马氏距离与自编码网络的异常检测方法。通过正常数据的马氏距离,得到判别阈值以快速检测出部分异常数据,减少了自编码网络的训练数据量;将自编码器与分类器结合,解决了网络参数初始化问题;提出先升维再编码的自编码器结构,而且将数据的马氏距离作为特征加入到网络训练中,有利于自编码网络的训练,提升了异常检测效果。实验证明了本研究所提方法较其他异常检测算法有着更好的检测效果,并且具有一定的稳定性和泛化能力。在未来的工作中,考虑引入时序深度学习模型研究如何实现快速在线检测和分类。
