一种用于语音挖掘和聚类的嵌入式分段KMeans方法
2022-01-15杨小虎朱苍璐
杨小虎 程 锦 朱苍璐
(1.安徽医学高等专科学校公共基础学院;2.安徽三联学院计算机工程学院 安徽合肥 230601)
零资源语音处理领域的发展旨在开发无监督的方法,在转录、词汇和语言建模文本不可用的情况下,可以直接从原始语音音频中学习。这些方法对于在转录数据难以收集的语言中提供语音技术是至关重要的,例如,一些不成文或濒危的语言[1]。此外,这些方法的发展可能会揭示人类是如何进行语言的学习[2,3]。现有的几个零资源学习任务主要包括声学单元发现[4-6],无监督表示学习[7-9],示例查询搜索[10,11]和主题建模[12,13]。早期的工作主要集中在无监督的术语发现上,目标是在一组语音中自动找到重复的单词或短语模式[14-16]。虽然有用,但发现的模式通常是分散在数据上的孤立片段,留下许多语音作为背景。这促使了一些关于全覆盖方法的研究,其中整个语音输入被分割并聚集成类似单词的单元[17-21]。两种典型应用在零资源语音挑战中赛上的全覆盖系统提供了一个有用的对比基准:1、贝叶斯嵌入的分段高斯混合模型[22]:一种概率模型,它将潜在的词段表示为固定维的声学词嵌入,然后在这个嵌入空间中构建一个全词声学模型,同时共同进行分割。2、循环音节单元分割器[23]:这是一种认知驱动的快速启发式方法,它应用无监督音节分段和聚类,然后预测作为单词的循环音节序列。这两个模型代表了零资源系统中常见的两个方法论极端,即要么使用具有收敛保证的概率贝叶斯模型[6,19],要么在管线方法中使用启发式技术[18]。
针对该问题,本文提出了一个介于这两个极端之间的高斯混合模型近似,即嵌入式分段K-Means模型,使用硬聚类和分段,而不是完全基于贝叶斯的推理过程。然而,与启发式方法不同的是,它有一个明确的目标函数。与贝叶斯嵌入分段的高斯混合模型相比,由于不需要概率抽样,因此嵌入式分段K-Means方法超参数少,优化算法简单,效率更高。从监督语音识别发展以来,就一直使用硬近似法进行概率建模,因此本文也遵循使用这种方法。然而,所有这些研究都将其应用到逐帧建模方法中,而本文的方法是对整个语音片段的嵌入式表示进行操作。人们越来越关注这种声学单词嵌入方法[11],因为它们使得在固定维度空间中容易且有效地比较可变长度的语音片段成为可能。本文分析了相对于原始的贝叶斯嵌入分段高斯混合模型等方法,嵌入式分段KMeans方法的硬近似是如何影响速度和精度的。在英语和聪加语数据上,我们表明嵌入式分段K-Means在分词方面优于循环音节单位分割器,并给出与贝叶斯嵌入分段高斯混合模型相似的分数,同时速度快5倍。然而,嵌入式分段K-Means的聚类纯度落后于其他两种模型,贝叶斯嵌入分段高斯混合模型的高纯度是因为它倾向于产生更小的聚类,这种聚类不同于嵌入式分段K-Means,也可以使用超参数来改变。
一、嵌入式分段K-Means方法
从标准的K-Means方法出发,本节描述了嵌入式分段K-Means算法的优化目标和具体算法实现。
(一)从K-Means到嵌入式分段K-Means目标函数。给定一个由声学帧组成的语音y1:m=y1,y2,…,yM(例如MFCC),我们的目标是将序列分解成类似单词的片段,并将这些片段聚类成假设的单词类型。如果已知分段(即在单词边界出现的地方),数据将由几个不同持续时间的段组成,如图1的底部所示。为了对这些数据进行聚类,我们需要一种方法来比较可变长度的向量序列。一种选择是使用基于对准的距离测量,例如动态时间扭曲。这里我们采用声学单词嵌入方法[11]:嵌入函数fe用于将可变长度的语音段映射到固定维度空间中的单个嵌入向量x∈RD,即将段yt1:t2映射到一个向量xi=fe(yt1:t2),用水平向量表示。其基于的思想和假设是,声学上相似的语音片段应该在RD中紧密地放在一起,允许片段在嵌入空间中直接有效地比较,而无需先进行对齐。目前已经存在各种各样的嵌入方法,从基于图的方法到无监督的递归神经方法。我们对每个片段进行均匀的下采样,使其成为相同固定数量的向量表示,然后对其进行展开,以获得嵌入的特征向量。嵌入式分段K-Means对嵌入的方法是不可知的,所以后续可以直接合并对嵌入的改进。
将数据集中所有的片段进行嵌入会得到一组向量,可以使用K-Means将其聚类成K个假设的词类,如图1顶部所示。标准的K-Means方法旨在最小化每个聚类均值的平方欧几里德距离之和。在将向量重新分配给最接近的聚类均值,然后更新均值,并反复交替迭代。
如果分段是已知的,则常规的K-Means方法是比较合适的,但在零资源设置中则相反,嵌入X可以根据当前的分段而变化。对于一个话语的数据集S,我们把分段表示为Q={qi}Si=1,其中qi表示话语i的边界。X(Q)用于表示当前分段下的嵌入。我们的目标是联合优化聚类分配z和分段Q。
其中Xc∩X(Q)是分段Q下分配给聚类c的嵌入。但这是有问题的,我们不是为每个片段指定一个分数,而是为每个帧指定一个分数。该分数由该帧所属的片段获得的分数统一给出,这意味着片段分数由持续时间的加权获得:

其中len(x)是序列中用于计算嵌入x的帧数。
整个嵌入式分段K-Means算法随机初始化单词的边界,然后通过在保持聚类分配z和均值{μc}Kc=1固定的同时利用公式1来交替优化分段Q (图1中从上到下所示),然后在保持分段固定的情况下优化聚类分配和均值(图中从下到上)。

图1 用于语音无监督分段和聚类的嵌入式分段K-Means模型
(二)分段。在固定的聚类z的情况下,目标(1)变为:

公式2可以针对每个话语分别进行优化。我们希望找到每个话语的分段q,并给出该分段下的嵌入分数总和的最小值。这正是最短路径算法(Viterbi)使用动态规划来解决的问题。
假设qt是在假设的以帧t结束的分段(词)中的帧数:如果qt=j,那么yt-j+1:t是一个词。我们将前向变量γ[t]定义为直到边界位置的最优得分,其中q:t是直到t的分段决策序列。可以通过如下公式进行递归计算:

具体来说,从γ[0]=0开始,我们对1≤t≤M-1分别递归计算公式3。我们跟踪每个γ[t]的最佳选择,然后通过从最终位置t=M开始并向后移动,重复选择最佳边界来给出整体最佳分段。
(三)聚类分配和均值更新。对于固定的分段Q,目标(1)变为:
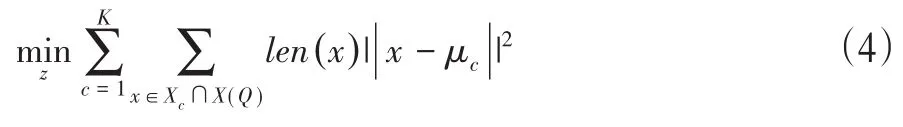

最后,我们修正分配的聚类中心z并更新其均值:

公式6是分配给聚类c中所有向量的平均值,由持续时间进行加权,保证公式1的正向优化。我们使用近似值,即如果所有分段具有相同的持续时间,该近似值也是准确的,以再次进行K-Means方法的匹配过程,Nc是当前分配给聚类c的嵌入数量。
(四)贝叶斯嵌入分段高斯混合模型。贝叶斯高斯混合模型将其混合权重π和分量均值作为随机变量,而不是点估计,就像常规高斯混合模型的做法一样。我们使用共轭先验:π上的狄利克雷先验和μc上的球协方差高斯先验。所有分量共享相同的固定协方差矩阵σ2I。模型定义为:

在这个模型下,组件分配和分段可以使用折叠吉布斯采样器进行联合推断。然而,对于贝叶斯嵌入分段高斯混合模型,组件分配和分段是遵循的概率抽样。当方差接近零时,标准的K-Means由高斯混合模型产生。以类似的方式,可以证明贝叶斯嵌入高斯混合模型方法中的分段和分量分配过程分别和(3)和(5)步骤相似,当所有其他超参数都固定时,σ2趋近0。
二、实验
本文分别进行两组实验。首先,我们在零资源语音挑战赛2015的数据上比较嵌入式分段K-Means与循环音节单元分割器以及贝叶斯嵌入分段高斯混合模型。后两个方法都曾应用于该较小的语料库,是用于方法比较分析的理想选择。
(一)实验设置和评估。正如在[20,22]中一样,我们使用几个指标来进行方法评估。通过将每个发现的单词标记映射到与其重叠最多的真实标记,然后将每个聚类映射到其最常见的单词,可以计算平均聚类纯度和无监督单词错误率(WER)。相反,通过将每个标记映射到与其重叠最多的真实音素序列,可以计算同一聚类中所有片段之间的归一化编辑距离(NED);NED越低越好,分数从0到1。而词边界精度、召回率和F-score通过比较提出的和真实的词边界来评估切分性能;同样,单词标记精度、召回率和F-score衡量提出的单词标记间隔的准确性。单词类型精度、召回率和F-score将唯一音素映射的集合与真实词典中的集合进行比较。在该数据集中不考虑聚类(簇)纯度和WER指标,因此对于某些方法并没有报告这些指标。
本文嵌入分段K-Means方法的实现尽可能遵循[22]中的贝叶斯嵌入分段高斯混合模型的实现。两者都使用均匀下采样作为嵌入函数fe:一个段由10个等间距的MFCCs通过适当的插值来表示。两种模型都使用无监督音节预切分[23]来限制单词边界。对于贝叶斯嵌入分段高斯混合模型,我们使用模拟退火,一个全零矢量的和σ2=0.001。
(二)与其他方法的比较和分析。在第一组实验中,我们使用了两个数据集:一个是来自12个说话者的大约5个小时的英语语料库,一个是来自24个说话者的2.5个小时的聪加语料库。我们还使用一套单独的6小时英语语料库进行开发。为了与以前方法的结果[22,23]进行比较,这里的所有系统都应用于与说话者相关的设置,并且结果在不同说话者之间进行平均。如[22]中所述,对于嵌入式分段KMeans和贝叶斯嵌入式分段高斯混合模型,K被设置为首过分段音节数的20%。候选单词最多只能跨越6个音节,并且持续时间必须至少为200毫秒。
表1显示了三种模型在英语和聪加语料库上的表现。循环音节单元分割器的一些分数是未知的,因为这些分数不是该挑战赛中评估的一部分[23]。与贝叶斯嵌入分段高斯混合模型相比,嵌入分段KMeans的纯度、WER以及NED指标更差,但边界、标记和F-score相似。这带来了5倍的运行时间提升。同时,其NED指标也比循环音节单元分割器差,但单词边界、标记和F-score要好得多,然而循环音节单元分割器的速度是它的两倍。

表1 模型在两个测试语料库上的表现
因此,在分词分数(边界分数、标记分数)和词汇质量(类型分数)方面,嵌入分段K-Means是有竞争力的,但在基于纯度的度量标准(纯度、WER、NED)方面落后。与贝叶斯嵌入分段高斯混合模型的区别特别有趣,因为σ2被设置得相当小,而嵌入分段K-Means是在σ2趋于0的限制下从贝叶斯嵌入分段高斯混合模型得到的结果。为了理解纯度上的差异,我们在一个英语说话者身上分析对比了这两种方法。
图2显示了两种模型的5个最大聚类(簇)。与嵌入分段K-Means相比,贝叶斯嵌入分段高斯混合模型输出更多更小的具有更高纯度的团簇(通常在不同的团簇上分离相同的词)。通过观察嵌入分段K-Means分配给同一个聚类的标记,发现尽管标记与不同的真实标签重叠,聚类分配在质量上是可感知的。例如图3显示了分配给图2中“be”簇标记的光谱图,也显示了具有最大重叠的真实单词标签。对于“seventy”和“already”标记,这些段只覆盖了一部分真实单词(粗体),而“that you”标记实际上在上下文中发音为[dh uw]。因此,尽管映射到不同的真实标签,这些片段形成一个合理的声学组。

图2 嵌入分段K-Means和贝叶斯嵌入分段高斯混合模型的最大5个簇(聚类)(圆半径根据簇的大小;阴影表示纯度。还显示了聚类到真实单词的映射)

图3 图2中映射为“be”的嵌入分段K-Means群的随机标记的光谱图。每个真实单词中被该段覆盖的部分以粗体显示
通过将发现的令牌更均匀地分布在聚类上(图2),贝叶斯嵌入分段高斯混合模型产生了一个聚类,可以更好地匹配评价指标,虽然嵌入分段K-Means的聚类可能主观上是更加合理的。贝叶斯嵌入分段高斯混合模型的这种扩展(或稀疏性)可以通过固定的球形协方差参数σ2来控制,该参数影响嵌入到聚类的软分配和分段。表2显示了σ2变化时开发集上的性能。当σ2太大时,大部分标记被大量的大无关簇吸上来;当σ2较小时,更多的标记被分配给单独的簇。相比之下,嵌入分段K-Means方法没有σ2参数,只考虑单个最接近的聚类。

表2 随着方差的变化,在英语开发集上的表现(%)
三、结语
本文提出了一种嵌入式分段K-Means模型,这是一种介于完全贝叶斯嵌入分段高斯混合模型和认知驱动启发式方法之间的方法。其分词性能与贝叶斯嵌入式分段高斯混合模型不相上下,优于循环音节单位分割器,但聚类纯度比其他两种方法都差。就效率而言,它比贝叶斯嵌入式分段高斯混合模型快5倍,但只有循环音节单位分割器的一半。尽管使用了硬聚类和分段,嵌入式分段K-Means仍然有一个明确的目标函数,保证了到局部最优解的收敛。由于其效率的显著提高,我们还能够将嵌入式分段K-Means应用于更大的语料库,并展现出更好的性能。
