一种改进的lp-RWMKE-ELM故障诊断模型
2022-01-14赵建印
刘 星,赵建印,朱 敏,张 伟
1) 海军航空大学,烟台 264001 2) 中国人民解放军 91576 部队,宁波 315020 3) 海装西安局驻咸阳地区军代室,咸阳 713100
随着服役时间的增加和故障案例的缓慢积累,军事装备的故障数据往往呈现不同程度的类不平衡、小样本的特点.此外,由于装备中各类电气元件参数存在容差[1]、普遍存在非线性和反馈回路[2],故障机理往往难以用准确的数学模型来表达.这对装备的故障诊断构成了巨大的挑战.
在当前的故障诊断领域中,机器学习是解决上述问题的常用方法,其本质是将故障诊断转化为模式识别问题,以数据驱动的方式构建诊断模型并最终形成诊断策略.其中,基于极限学习机(Extreme learning machine , ELM)的研究近年来取得了许多优秀的研究成果[3].ELM属于单隐层前馈神经网络[4],其输入层到隐藏层的输入权重和偏置均为随机生成,其输出权重则通过矩阵求逆直接获取,具备学习速度极快、训练参数不多、泛化能力较强的优势.
对于类不平衡问题[5],通常的做法是利用过采样或欠采样方法建立数据的平衡分布[6],或者为每个训练样本分配不同的错误分类代价[7].在ELM领域,也衍生出一系列改进版本用于处理类不平衡条件下的多分类问题[8].Deng等[9]提出了加权正则化ELM.Zong等[10]提出了加权极限学习机(Weighted extreme learning machine,WELM),并对其实现了核化,即加权核极限学习机(Weighted kernel extreme learning machine,WKELM),其依据两种策略为每个训练样本赋予不同的权重,使WELM及WKELM适用于不平衡分类问题.Mirza等[11]提出了加权在线序贯极限学习机(Weighted online sequential ELM,WOS-ELM),实现了加权增量学习.Mao等[12]针对时间序列不平衡数据集,提出了基于加权极限学习机的稀疏化改进模型,其核心思想是根据敏感性及特异性的变化为每个连续样本动态分配权重.上述方法虽然在ELM框架内融入了不平衡分类的处理方法,但并未给出合理的核函数的确定及核参数的选取方法,并且模型的整体分辨力仍然较低.
针对上述问题,与多核学习(Multiple kernel learning, MKL)或集成学习相结合是近年来ELM研究的重点方向[13].MKL因能找到一个相对合理的组合核函数而备受关注,并且在故障诊断[14−15]、图像分析[16−17]等领域得到了充分的应用.集成学习[18−19]的本质是基于多个弱分类器得出一个性能更加优异的强分类器,达到提升模型整体分辨力的目的.文献[20]提出了在线ELM的集成版本,解决了概念漂移和数据类不平衡问题.文献[21]将加权ELM融入到Adboost模型中,用于解决数据类不平衡的分类问题.然而,上述方法的改进方向相对单一,并不能同时有效应对装备故障数据小样本、不平衡且整体诊断精度偏低的问题.
注意到WKELM与集成学习在关注个体样本重要性方面的共通性,本文以Adaboost集成学习框架为基础,同时将每层的WKELM的单核扩展为多核,提出lp范数约束下正则化加权多核集成极 限 学 习 机 (Regularized weighted multiple kernel ensemble ELM underlp-norm constraint,lp-RWMKEELM).其创新点和先进性体现在:
(1)将各类样本的自适应加权、Adaboost集成学习策略及MKL纳入到一个统一的学习框架内,推导出了融合后的诊断决策的数学表达式;
(2)选用6个UCI公共数据集和实装数据进行了仿真实验,与核极限学习机(Kernel based extreme learning machine,KELM)[22]、加权核极限学习机(Weighted kernel based extreme learning machine,WKELM)、在1范数和p范数约束下的多核极限学习机(分别简记为l1-MKELM、lp-MKELM)、融入散度秩的多核极限学习机(Incorporating Trace of Data Scattering Matrix MKELM, ITDSMM-KELM)[23]相比,实验结果表明,所提模型具有更高的诊断准确性和稳定性.
1 理论基础
1.1 多核 ELM
其中,||·||F表示F范数,为预定义的r个基核表示基核的组合权重,表示模型总的输出权重,βq∈ R|ϕq(·)|×m表示对应于基核的输出权重,为对应于基核的特征映射;m表示ELM的输出节点个数; ξi=[ξi1,···,ξim]T表示对应于第i个故障样本的训练误差向量,yi=[yi1,···,yim]T表示第i个故障样本的理想输出向量;C为正则化因子,p为范数约束形式.对式(1)对应的Lagrange函数中各变量分别求偏导,并采用两步交替优化策略求解Lagrange乘子矩阵 α以及基核组合权重 γ,得出模型最优化参数 α∗和 γ∗,则决策函数为

其中,α为Lagrange乘子,并且有 α =[α1,···,αn]T,αi=[αi1,···,αim]T.
1.2 权重分配方式
本文采用Vong等在文献[24]中提出的权重分配方法,为每个样本分配权重,寻求各类样本在规模上的再平衡,将分隔超边界推向多数类来减轻样本类不平衡的影响,实际上属于代价敏感学习范畴.两种权重分配方式如下:

其中,#(yi)表示故障模式yi的训练样本数.通过权重分布,使得少数样本被赋予更大的权重.显然,数据的类不平衡程度越高,各类样本之间的分布权重相差就越大.

其中,AVG表示所有类的平均训练样本数,这样可以减少少数群体和多数群体之间的平衡步长,使其达到0.618∶1的比率.在多类分类中,少数类是指样本数量低于所有类平均样本数的那些类别,而多数类是指样本数高于所有类平均样本数的类别.
2 改进的 lp 范数约束加权多核多故障集成学习诊断框架
2.1 正则化加权多核极限学习机
对于输入空间中的n组故障样本,假设其权重分布为,并且有.为便于运算,将其扩展为主对角线元素为wi的n×n对角矩阵,表示为W=diag[w1,···,wn].

将式(3)代入优化问题(1),同时,将样本分布权重矩阵W融合到优化问题中,得到lp范数约束下正则化加权多核极限学习机:

对比新的优化问题(4)与原优化问题(1),分布权重W的融入使得模型可以根据样本的类不平衡程度合理分配样本权重,确保诊断模型能够聚焦到一些富含优化信息的训练样本上,从而有效提高模型的解释能力.
为了求解优化问题(4),给出其对应的Lagrange函数.



以下采用两步交替优化策略求解Lagrange乘子矩阵 α以及基核组合权重 γ.
(1)在固定 γ的条件下求解 α.
将公式(6)、(7)依次代入式(8)中,得到

由公式(10)可得到,

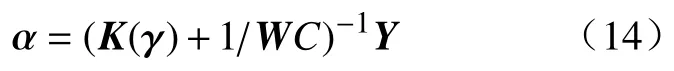
(2)在固定 α的条件下求解 γ.
由式(9)得到



其中,γq表示第q个基核在上一次迭代中的权值;表示第q个基核在本次迭代中的权值更新.由式(6)得到,根据,进一步有因为有所以可以得到


2.2 基于 Adaboost的多核集成学习诊断框架
为进一步提升lp范数约束下正则化加权多核极限学习机的诊断模型性能,本文采用集成学习中广泛应用的Adaboost集成策略[25](权重分别取W(1)、W(2)两种形式),构造三层集成诊断框架,每层为一个分类器,将基核的集合定义为KZ={1;2;3},其 中,1={kLin}表示线性核;2={kPoly,1,kPoly,2,···,kPoly,pr}表示pr个不同参数的多项式核集合; ∆3={kGauss,1,kGauss,2,···,kGauss,gr}表示 gr个不同参数的高斯核集合,并且有1 +pr+gr=r.
令wu,i表示第i个样本在第u层分类器中的权重值,则

I(·)为指示函数,其定义为

(2)计算决策函数fu(·)的重要度系数κu.
重要度系数 κu表示Gu(x)在最终分类器中的重要程度,定义为

(3)更新各层训练样本的权值分布.
将文献[24]中的初始化权重W0赋予线性分类器层的W1,当由下层向上层传递时,第i个故障样本的权值更新关系为

其中,Zu是所有训练样本权值的归一化因子,表示所有训练样本权值的加权和.当∑Gu−1(xi)=yi时,a=1;而Gu−1(xi)≠yi时,a=−1,权重分布的传递使下层分类器中被错误分类的样本获得更大的权重,这会使上层分类器更多地关注这些难以正确分类的样本.
2.3 诊断决策
基于以上讨论,lp-RWMKE-ELM的最终决策函数表示为:

令f(·)=[f(1)(·),f(2)(·),···,f(m)(·)],式中f(l)(·)是诊断模型中第l个输出节点的输出值.对于需要进行诊断的测试样本,其诊断结果为

lp-RWMKE-ELM的基本框架如图1所示.

图1 lp-RWMKE-ELM 诊断模型Fig.1 Diagnosis model based on lp-RWMKE-ELM
2.4 算法流程
lp-RWMKE-ELM算法流程如下.
步骤1输入训练数据;设置正则化因子C,范数约束形式p,最大迭代次数N;设置基核,并确定各层基本分类器
步骤2令u=1,根据训练样本初始权重的自适应加权原则(W(1)或W(2)),生成初始权值矩阵W0,根据公式(17),令r=1,求得基于u的KELM模型的决策函数fu(·)fu(·),并记录fu(·)fu(·).
步骤3根据公式(23)重分布wu,i→wu+1,i;且u=u+1.
步骤4根据公式(22)计算 κu,并记录 κu.
步骤5当u≤3时,用表示u中包含的基核个数,令h=1,
步骤6当h≤N时,根据wu、∆u及由公式(12)计算MK-ELM模型参数.根据公式(15)更新;根据公式(16)计算
步骤7如果,根据公式(17)计算决策函数fu(·),并记录fu(·).根据公式(23)更新数据权值分布wu→wu+1;根据公式(22)计算 κu,并记录 κu,u=u+1.若u≤ 3,转步骤5,若u>3,转步骤9.
步骤8如果若h≤N,转到步骤6,若h>N,转步骤5.
步骤9输入测试样本,对于计算利用公式(24)计算利用公式(25)得到所对应的故障标签
3 类不平衡数据集分类问题的评价指标
在传统的分类问题中,通常以分类正确率作为分类器准确性的重要评价指标.然而,对于不平衡数据集的分类诊断,仅用分类正确率难以评价分类器的综合性能.针对该问题,本文采用文献[26]提出的G-mean、F-measure作为分类器性能的度量指标.
G-mean是所有m类分类精度的几何平均值,其定义为

其中,Acc为准确率.F-measure广泛用于评估二元分类系统.它被定义为Precision(π)和Recall(ρ)的调和均值,即公式(29),其中,Precision是预测值为正的例子中真实值为正的比例,Recall是真实值为正的例子中被预测为正的比例.表1给出了分类器在二分类问题中的混淆矩阵.

表1 混淆矩阵Table 1 Confusion matrix

为了将F-measure扩展到多类分类问题,通常使用两种平均类型,即 F-measure-micro和F-measuremicro.
F-measure-micro定义为:
F-measure-macro定义为:
由F-measure指标的定义可知,只有当各类的分类的准确率和召回率都较高时,F-measure才会较大.因此,在综合体现各类别样本数据的分类精度时,F-measure更加侧重对少数类的分类性能评价.
4 实验仿真
4.1 UCI公共数据集实验
本文选取机器学习领域中广泛使用的6个UCI数据集(Diabetes,Ionosphere,Vowel,Cancer,Bupa,Thyroid)进行仿真实验,各数据集均不同程度地呈现类不平衡特征.实验选取KELM、WKELM[21]、MKELM、l1-MKELM、lp-MKELM、ITDSMM-KELM六种相关算法作为对比以验证模型的诊断性能.其中,KELM算法通过文献[22]所给出的方法来实现、WKELM、l1-MKELM、lp-MKELM、ITDSMM-KELM算法通过文献[23]给出的方法来实现,加权模型所涉及到的样本加权方法分别选用上文给出的W(1)、W(2)加权方式.首先对各数据进行归一化预处理,然后将所提出的方法应用于每次训练/测试.各UCI数据集描述表2所示.
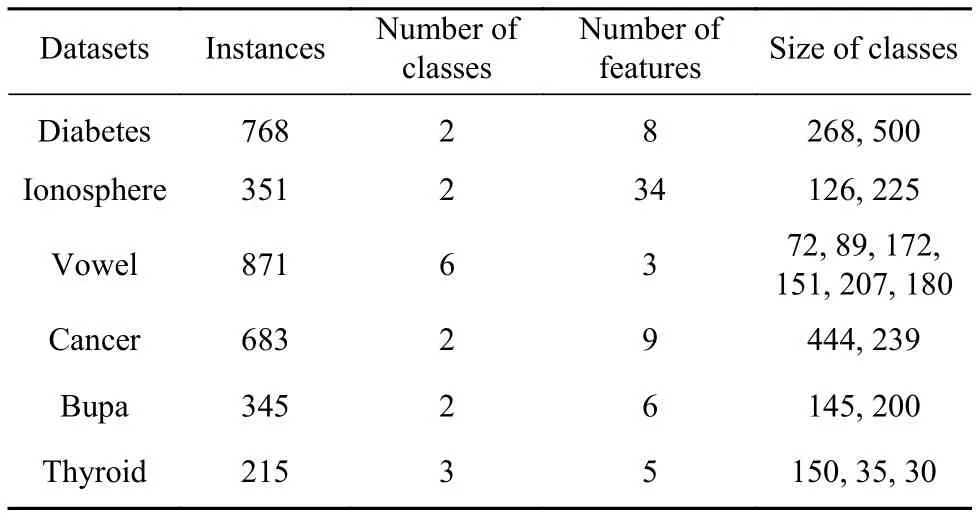
表2 UCI数据集描述[22]Table 2 UCI data set description[22]
相关实验的条件设置为:第二层线性核个数为3,第三层高斯核个数为8;每次试验中,针对每个数据集,随机选择80%的数据作为训练数据,其余20%的作为测试数据;单核的核函数采用高斯核,以 5 倍交叉验证的方法从{2−20, 2−19,···, 220}和{2−10, 2−9,···, 210}中分别选取正则化参数C和核参数;各算法中所涉及到的正则化参数C和核参数设置,在具体的实验中有具有相应表述.
以Vowel数据集为例,将第一层分类器中各类样本的权重分布与第三层进行对比,说明权重在模型中的变化,如图2所示.
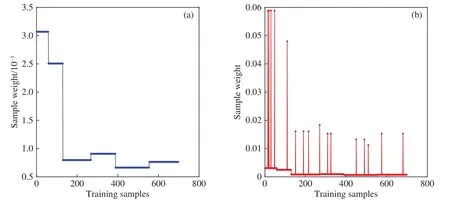
图2 权重分布.(a)线性层分类器权重分布;(b)高斯层分类器权重分布Fig.2 Weight distribution: (a) weight distribution of classifier on linear layer; (b) weight distribution of classifier on gaussian layer
由图2(a)和图2(b)可知,6 类样本分别赋予了不同的初始权重,其中,小样本类数据的权重得到了增加;经过三层AdBoost策略优化后,第三层分类器中,大部分样本权重趋于一致,个别样本权重(分类错误样本)得到了显著增强.显然,经过分类器权重的逐层更新,模型提高了对分类错误样本的特征信息的关注.
将WKELM在W(1)、W(2)加权方式下的算法分别简记为WKELM-W1和WKELM-W2,将所提模型在W(1)、W(2)加权方式下的算法分别简记为lp-RWMKE-ELM-W1 和lp-RWMKE-ELM-W2.对每个数据集,进行20次试验,然后取均值和标准差,表3给出了相关算法的实验结果,图3对表3的结果进行了图形化对比.

图3 各模型在各个 UCI数据集上诊断性能比较Fig.3 Comparison of the diagnostic performance of various models on various UCI data sets

表3 各模型在各个 UCI数据集上诊断性能比较Table 3 Comparison of the diagnostic performance of various models on various UCI data sets
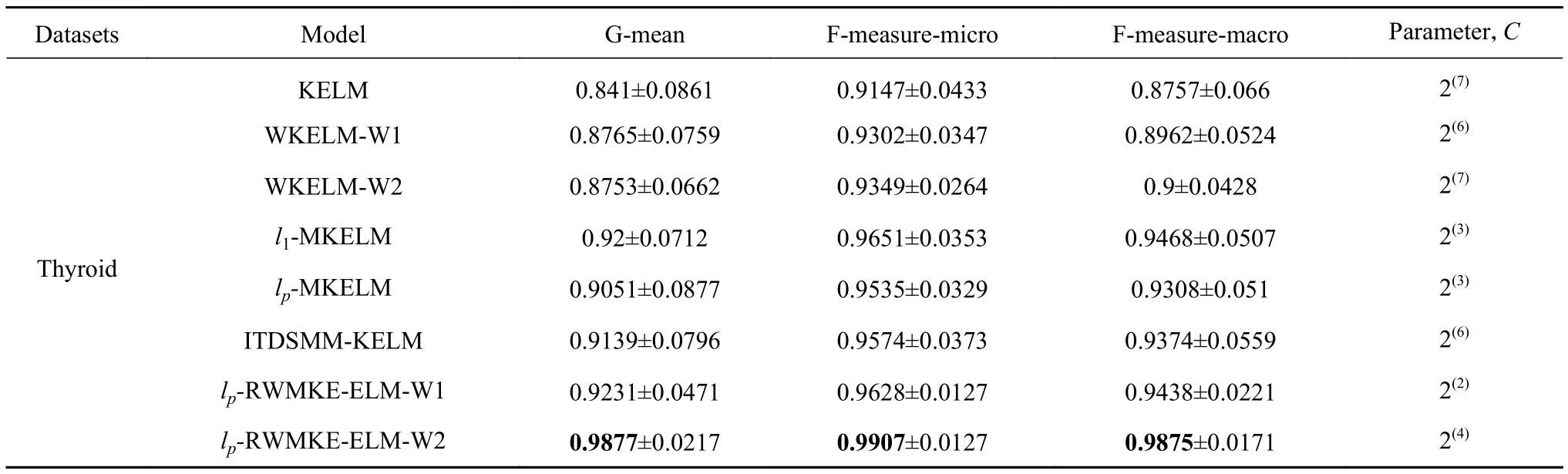
表3 (续)Table 3 (Continued)
由表3和图3可知,所提方法的诊断精度均优于其他方法,以Thyroid数据集和lp-RWMKE-ELMW2模型为例,与单核学习的KELM、WKELMW1、WKELM-W2和多核学习的l1-MKELM、lp-MKELM、ITDSMM-KELM相比,lp-RWMKE-ELMW2在G-mean指标上分别提升了17.44%、12.69%、12.84%、7.36%、9.13%、8.08%,在F-measure-micro指标上分别提升了8.31%、6.50%、5.97%、2.65%、3.90%、3.48%,在F-measure-macro标上分别提升了12.77%、10.19%、9.71%、4.30%、6.09%、5.34%.
可以看到,使用样本加权的WKELM的诊断精度优于未使用样本加权的KELM,使用多核的lp-MKELM优于使用单核的KELM,集成多核分类器的lp-RWMKE-ELM的诊断精度优于WKELM、lp-MKELM和ITDSMM-KELM.这是因为多核学习相对单核学习具有更高的映射灵活性,多个核函数组合映射的高维空间兼具各个子空间独特的特征映射能力,将各类样本数据中的不同特征向量分别通过最合适的单个核函数进行映射,因此,在新的组合空间里,可以更加精确地对样本进行合理表达,有效提高故障样本的诊断精度.同时,运用AadBoost策略对基于线性核、多个多项式核、多个高斯核的基分类器进行集成,令样本权重逐层更新和传递,使高层分类器进一步聚焦于下层易分错的样本上,可以达到提高最终分类器的辨识性的目的.
为检验范数约束的选择对模型诊断性能的影响,以Vowel数据集为例,随机抽取80%的样本作为训练集,其余为测试集,加权方式选择W(2),在同样的训练集与测试集下,分别选用不同的范数约束,模型的诊断性能如表4所示,相应的图形化表示如图4和图5所示.

表4 范数约束形式对模型诊断性能的影响Table 4 Influence of norm-constrained forms on model diagnostic performance

图4 范数约束形式对模型诊断精度的影响Fig.4 Influence of norm-constrained forms on the diagnostic accuracy of the model

图5 范数约束形式对模型时间开销的影响Fig.5 Influence of norm-constrained forms on model time cost
由表4可知,在区间[32/31,15]中选择不同的范数值,虽然范数的取值间隔很大,但是各评价指标变化并不明显.由图4可知,随着范数值的增大,模型的各评价指标表现出递增趋势.由图5可知,训练时间和测试时间随着范数值的增大存在递减的趋势.由此可知,范数值的增大有利于提高诊断模型的精度,同时可以减小时间上的开销.值得注意是,范数值的增大并未显著提高模型的诊断性能,即在范数的取值变化不大的情况下,模型的综合诊断性能趋于一致.
4.2 某型装备前端接收机故障诊断实验
本文的研究应用背景主要是为了适应现役装备的三级维修体制中的基层级维修,完成模块级的故障诊断,实现内场可更换单元的故障诊断,为维修保障提供技术支撑.为验证lp-RWMKE-ELM诊断模型在装备故障诊断领域的实用性,将所提方法应用在某型装备的前端接收机的故障诊断中.图6为前端接收机的工作原理图.

图6 前端接收机工作原理图Fig.6 Front-end receiver working principle diagram
本文进行模块级的故障诊断,根据前端接收机的使用功能,选择4种模式来验证lp-RWMKEELM的有效性,正常模式用F0来表示,放大单元、微波单元1和微波单元2功能模块的故障模式,分别用F1,F2,F3来表示.主要包括12个测试项目,对应12维的故障特征,即:5个频点的灵敏度、5个频点的动态范围,2个射频增益.各频点分别为 4、8、12、16、35,频点灵敏度单位为dBm,动态范围单位为dB,射频增益单位为dB.
基于前端接收机出厂维护保养手册中的测量方法,依据该型装备的自动测试系统ATS,利用标准信号源、功率计和频谱仪等设备进行数据采集,共采集到123组指标值,实验数据按特征进行Z-score标准化预处理,相关结果如表5所示,特征1到12分别对应12个测试项目的(归一化处理后)测量值.其中,F0模式样本数据30组,F1、F2、F3故障模式的样本数据分别为48组、28组、17组.样本集的规模具有一定的类不平衡特点.

表5 前端接收机数据集Table 5 The front-end receiver data set
随机选择80%的数据作为训练数据,其余作为测试数据,进行20次试验,相关指标的均值和均方差记录于表6,对应的图形化表示如图7.

图7 前端接收机的诊断精度对比图Fig.7 Comparison of the diagnostic accuracy of the front-end receiver

表6 前端接收机的诊断精度Table 6 Diagnostic accuracy of the front-end receiver
由图7可知,在两种加权方式下,与4.1节UCI公共数据集的结果一致,得益于多个核函数映射到的高维空间的强大表达能力、Adaboost策略对易分错样本的关注能力以及样本权重重新分配带来的对不平衡性的缓解能力,对于前端接收机的实测数据,lp-RWMKE-ELM的诊断精度依然明显优于其他几种方法.
由表7和图8可知,从时间开销上来看,所提方法训练时间高于其他算法,而测试时间则略低于其他算法(除最原始的KELM外),这是由于lp-RWMKE-ELM在训练过程中加入了基核权重的优化过程,而Adaboost策略则进一步增加了该优化过程的次数(等于层数).作为一种离线的故障诊断方法,这种以少量时间开销的增长换取诊断精度的提升的做法是可取的.此外,众多装备在服役的大部分时间里,其故障数据都呈现小样本的特点,因此,模型训练带来的时间开通常是可控的.

图8 前端接收机实测数据时间开销对比图Fig.8 Comparison chart of the training and testing time for the models of front-end receiver

表7 前端接收机诊断时间开销Table 7 Diagnosis time cost of the front-end receiver
5 结论
本文针对装备普遍存在的各类故障样本数据规模不平衡、故障诊断精度偏低的问题,在AdaBoost集成学习框架下,将加权策略、p范数约束的多核学习策略与超限学习机进行了集成,提出了lp-RWMKE-ELM故障诊断模型.基于UCI数据集和某型装备的前端接收机的实测数据进行实验,验证了所提方法的有效性,得到如下结论:
(1)lp-RWMKE-ELM通过多核函数构建高维空间,使得样本数据在新的组合空间中能够得到更加准确的表达;根据各类样本自身规模的特点,预先分配权重,并融入到多核极限学习机的优化目标函数中,使每类样本通过自适应分配权重达到再平衡;同时使用三层AadBoost策略对基于线性核、多个多项式核、多个高斯核的基分类器进行集成,使高层分类器进一步聚焦于下层易分类错误的样本上,从而显著提升故障诊断的精度.
(2)在诊断精度方面,在时间开销基本可控的前提下,与单核的KELM、WKELM以及多核的l1-MKELM、lp-MKELM、ITDSMM-KELM相比,所提方法的诊断精度有显著提高,以Thyroid数据集和W2加权方式为例,lp-RWMKE-ELM在F-measuremicro指标上分别提升了8.31%、5.97%、2.65%、3.90%、3.48%.
(3)范数约束形式对诊断方法的性能影响有限.随着范数值的大幅增大,模型的诊断精度有小幅提升,时间开销呈现下降趋势.在范数的取值变化不大的情况下,模型的整体性能趋于不变.
