多生成器生成对抗网络
2022-01-14申瑞彩翟俊海侯璎真
申瑞彩,翟俊海,侯璎真
(河北大学 数学与信息科学学院,河北省机器学习与计算智能重点实验室,河北 保定 071002)
随着深度学习技术的发展,深度神经网络[1]已在计算机视觉、语言识别、自然语言处理等领域取得成功,然而这些成就大都集中在判别模型上.因深度生成模型自身存在弊端导致其发展缓慢,直至Goodfellow等[2]提出生成对抗网络,生成模型才得以快速发展.
生成对抗网络(generative adversarial networks,GAN)依据纳什均衡思想采用对抗训练来进行数据生成,在理想情况下可拟合出真实数据分布.然而在训练时模型经常出现训练不稳定、难以收敛、模式崩溃、梯度消失或爆炸等问题.为解决这些问题相继出现许多GAN的变体,在2018年提出的MAD-GAN[3](multi-agent diverse generative adversarial networks)模型中,作者认为不同模式之间存在较大差异,因此引入多个生成网络并最大化网络间的差异,以强制网络学习更多模式来缓解上述问题.与MAD-GAN不同,本文认为相同数据集下不同模式间虽有差异,但仍有联系,因此在本文的模型中引入协同工作机制以允许多个生成网络进行信息交流,加速网络学习.一味地放大数据间的差异,无疑会增加网络负担.因此如何在保证性能的基础上不增加额外参数量,成为了一项值得研究的内容.
本文针对在生成模型中存在的问题,提出了一种具有集成学习思想的多生成器生成对抗网络模型,包含多个生成网络,每个生成网络均采用残差网络进行搭建,并在生成网络间引入协同工作机制,加快模型获取信息;最后将多个生成网络的特征图进行融合作为最终图像输入到判别网络中.传统GAN中采用JS(Jensen-Shannon)散度作为损失函数,易产生梯度消失问题,从而加大GAN的训练难度,为避免这一问题,本文引入WGAN(Wasserstein GAN)[4]中提出的Wasserstein距离以及梯度惩罚作为模型的损失函数.为了验证模型的有效性,在多个数据集上进行大量的实验,结果表明本文提出的模型优于以往的许多模型.
本文的主要贡献包括以下几个方面:
1) 在各生成器间引入协同工作机制,使得该网络对图像特征进行充分提取;
2) 引入Wasserstein距离来度量2个分布之间的差异,并加入梯度惩罚方法;
3) 使用加权特征图融合方法增加样本细节信息;
4) 较大地改善了模式崩溃问题并提高了生成样本质量和多样性以及加快了模型的收敛速度.
1 相关工作
生成模型可成功学习数据的概率分布,愈来愈成为研究热点.应用较多的有基于有向图模型的赫姆霍兹机[5](Helmholtz machines)、变分自编码器[6](variational auto-encoder, VAE)、基于无向图模型的受限玻尔兹曼机[7](restricted Boltzmann machines, RBM)和深度玻尔兹曼机[8](deep Boltzmann machines, DBM)等.当被建模变量为高维度时,上述模型将带来指数级别的计算量,为解决这一问题,提出了生成对抗网络(GAN),随后根据不同任务出现了不同变体.
该模型在训练时易出现模式崩溃[9-10]、训练难以收敛以及梯度消失或爆炸[11]等问题.为改善这些问题,Denton等[12]提出拉普拉斯金字塔算法实现了GAN生成图像从粗略到精细的转变,从而改善了生成图像的质量;Liu等[13]提出耦合式生成对抗网络(coupled generative adversarial network, Co-GAN)在不同域中训练可共享参数的生成器以学习数据的联合分布.Mirza等[14]提出条件生成对抗网络(conditional generative adversarial nets, CGAN)将带标签数据作为输入,通过引入类别信息显著提高生成图像质量,但获取带标签数据仍十分困难,因此该方法并未广泛使用.Oord等[15]提出的模型可以任意向量为条件从而提高生成图像的质量.Arjovsky等提出WGAN(Wasserstein GAN)模型,通过使用Wasserstein距离并将判别网络约束在1-Lipschitz函数范围内,使得生成器更好地获得梯度信息,有效地改善了模式崩溃问题,这一方法在后续的许多工作中均有使用.
Ghosh等[3]提出的MAD-GAN(multi-agent diverse generative adversarial networks)模型在Co-GAN的基础上提出,通过最大化生成网络间的差异,强制网络去学习真实数据的不同模式.本文的工作正是受这一模型启发,但与之不同.虽然同一数据集的不同模式间存在差异,但不可否认其仍存在相似性.因此本文在构造多个生成器的同时引入协同工作机制,使生成器间相互学习,在保留全局相似的同时具备局部差异.实验证明这种全新的具有集成学习思想的协作式生成对抗网络不仅可提高模型的生成能力还克服了模型存在的不足.另外,MAD-GAN采用与GAN相同的损失函数,生成网络采用卷积叠加的方式,这对模型的性能并无太大帮助,为提升模型性能,生成器采用残差网络进行搭建,并创新性的引入加权特征图融合的方法提升生成图像的细节,同时将Wasserstein距离以及梯度惩罚引入损失函数中,通过实验证明了该方法的有效性.
2 基础知识
本节主要介绍用到的基础知识,包括生成对抗网络、残差网络[16]以及集成学习[17].
2.1 生成对抗网络
GAN由生成网络与判别网络2部分组成,二者在训练过程中构成一种动态的“博弈”[18]过程,模型如图1所示.在GAN中生成网络和判别网络本质上均为可微函数,二者紧密耦合,互相对抗.生成网络通过输入随机变量z产生假样本,从而拟合出真实数据的潜在分布.判别网络的输入包含2部分,生成网络的输出以及真实数据,其目标为正确区分二者.

图1 生成对抗网络模型Fig.1 Model of generative adversarial networks
2.2 深度残差网络
2015年何凯明等首次提出残差网络(ResNet),该网络结构既未增加额外参数,又未提高计算复杂度,其中的快捷连接(shortcut connection)还可解决网络退化问题,在图像生成中具有广泛应用.恒等快捷连接可越过1个或多个卷积层,通过执行恒等映射将输出添加到堆叠层的输出中,从而保证信息完整性.实验结果表明,ResNet模型比VGGNet和GoogleNet的分类准确率都高[19].
残差网络中的主要组成部分为残差块,其基本结构如图2所示.

图2 残差块的基本结构Fig.2 Basic structure of the residual block
图2中x为输入,F(x)表示x经过2层的加权和激活函数得到的输出,可表示为F(x)=W2σ(W1x),其中W1和W2代表网络中的参数,σ代表使用的激活函数.
2.3 集成学习
集成学习是通过构建并集成多个弱学习器来完成学习任务的一种方法,也可称为基于委员会的学习、多分类器系统等,其模型如图3所示.
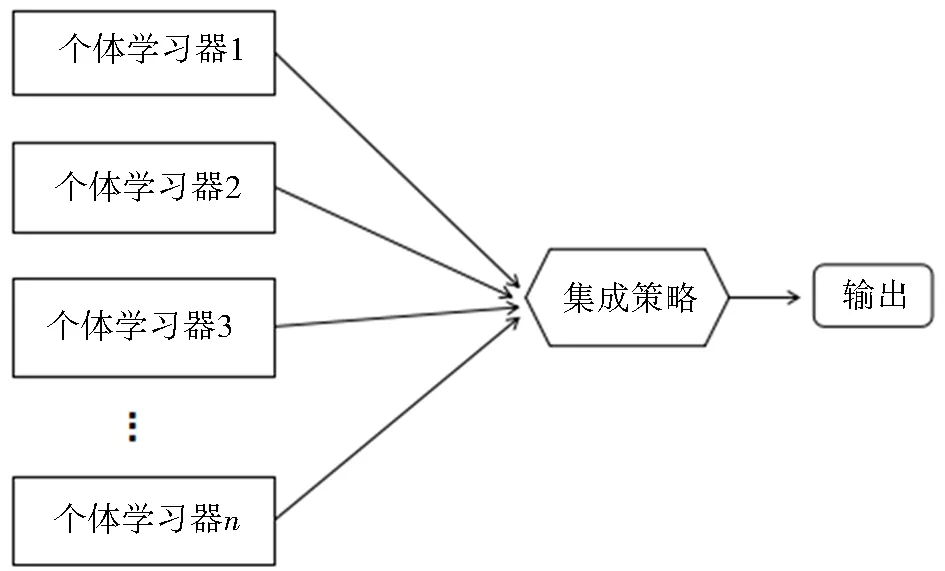
图3 集成学习示意Fig.3 Ensemble learning diagram
根据集成学习方法中的基学习器间是否存在依赖关系可分为2类:存在强依赖关系,即基学习器必须串行,代表为boosting算法;不存在强依赖关系,即基学习器可以并行生成,代表为bagging算法.
集成学习的集成策略主要分为3种.平均法:常用于回归问题,分为算术平均与加权平均;投票法:常用于分类问题,可分为相对多数投票法、绝对多数投票法、加权投票法;学习法:将得到的一系列初级学习器的结果作为次级学习器的输入,从而进行集成,该方法的典型代表为Stacking方法.
3 提出的模型
传统GAN网络由单生成网络与单判别网络组成,训练中采用的JS散度易带来训练不稳定、梯度消失或爆炸等问题,而WGAN模型中提出的Wasserstein距离很好地解决了这一问题.另外,仅使用卷积的叠加对网络进行搭建,会导致网络获取信息受限以及训练不稳定,从而使得生成图像质量较差、多样性较低,由于残差网络独特的网络结构,较好地缓解了这一问题.因此为解决在GAN中存在的一系列问题,本文提出一种具有集成学习思想的多生成器生成对抗网络模型,主要包含集成生成网络与判别网络2部分,模型如图4所示.
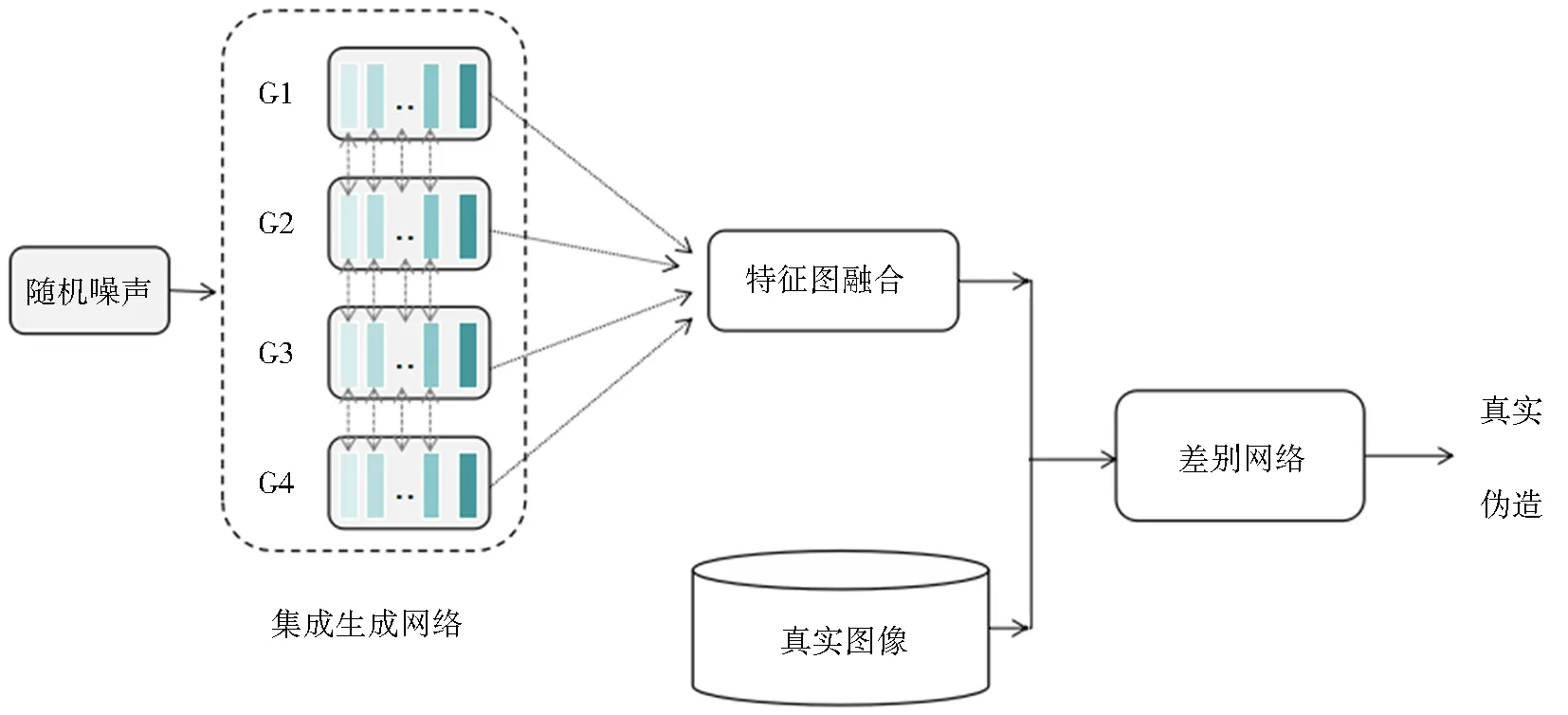
图4 本文提出的模型Fig.4 Model proposed in this paper
3.1 集成生成系统
集成生成系统采用深度残差网络进行搭建,每个生成器中包含3部分,前部、中部和后部共9层.前部包含3个卷积层,后部对应2个转置卷积以及1个卷积层,中间为3个残差网络模块,这些模块通过恒等快捷连接来解决网络存在的问题,每个生成网络的结构如图5所示.各生成网络间的卷积核大小与卷积步长均不相同,不同大小的卷积核意味着感受阈大小不同,这促使了每个生成网络获取不同的图像信息,加上使用不同的卷积步长进一步保证了各生成网络间生成图像的差异.
该集成生成系统主要包括生成器间的集成与协同工作2部分.

图5 单个生成网络结构Fig.5 Single generative network structure diagram
3.1.1 生成器间的集成
模型中集成生成器的数量为k,由于各生成器具有相同的目标,不存在影响强弱之分,因此模型中的生成器采用并列排列.若各生成器采用相同的结构进行搭建,在训练时将趋近于一种网络表达.因此,为避免这种情况,在搭建网络时秉承大体相同细节不同的方法,具体表现为各生成网络拥有相同的卷积层数,不同之处在于使用的卷积核大小以及卷积步长.
3.1.2 协同工作
以CelebA数据集为例,发现不同图像特征间存在差异.例如男性与女性,老人、中年人与孩童,或是人物背景间明暗的不同.首先本文认同这种差异的存在,但分析人脸五官的结构形状、所处位置以及明暗关系等发现这些模式间又存在一定的相似性.因此本文决定使用多个生成器捕捉信息并加速网络学习,同时由于特征间相似性的存在本文引入了可让多生成器进行交流的学习方式,称为生成器间的协同工作.这一学习方式可加速网络拟合真实数据特征从而减少训练中易出现的问题.
该协同工作机制主要包含各生成器的参数共享以及特征图融合2部分.
由于同一数据集中图像的低维特征往往是相似的,采用参数共享不仅可减少参数量,还可缩短网络的训练时间.具体地参数共享策略为在多个生成网络中除了输入层以及最后2层卷积层不进行参数共享,其余部分均进行参数共享.同时为了保证各生成器生成样本的多样性,文中对多个生成网络设置不同大小的卷积核以及卷积步长.在每次进行卷积操作前对特征图进行边缘补零(zero-padding)处理,以防止图像边缘信息点丢失,并确保输入与输出维度相同.卷积结束后对特征图进行实例归一化(instance normalization)处理.最后卷积激活层中采用LeakyReLU(leaky rectified linear unit)作为激活函数,转置卷积激活层中使用ReLU(rectified linear unit).
关于特征图融合,本文采用加权融合的方法将多张特征图融合为一张图像,如图6所示.根据各生成网络的性能赋予不同的权重,加权得到最终的特征图.该方法有效地规避了单生成器学习能力有限的弊端,通过融合各生成器生成的图像,极大地提升了特征图含有的信息量.

图6 加权特征融合示意Fig.6 Weighted feature fusion schematic
3.2 判别网络
判别网络采用卷积串联的方式,包含4个卷积层,分别有64、128、256、512个卷积核.末端为2个全连接层,第1个全连接层有1 024个输出,第2个全连接层有1个输出,网络结构如图7所示.
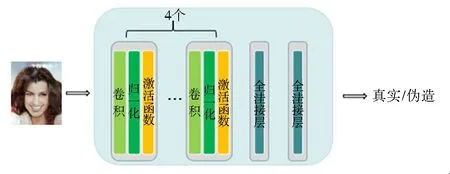
图7 判别网络结构Fig.7 Discriminator structure diagram
3.3 损失函数
GAN采用JS散度作为评价函数,由于真实数据分布与生成数据分布之间总是出现不可忽略的重叠,此情况下JS散度为常数log 2,在采用梯度下降法更新参数时,生成网络学习不到任何信息,从而带来梯度消失问题.然而,WGAN中的Wasserstein距离的平滑性可以很好地提供有意义的梯度.因此模型中引入Wasserstein距离作为评价函数.
集成生成网络系统的损失由2部分组成:原始GAN的对抗损失以及各生成器的协同工作损失,其损失函数如式(1)所示:
G*=argmin(W(Pdata‖Pg)-βJSDπ(PG1,PG2,…,PGK)),
(1)
其中,Pg代表多个生成网络的联合分布,前一项是原始GAN中的损失,以驱使生成分布接近真实数据分布,后一项用来调节生成网络间生成更多的细节信息.判别器将判别误差传回到各生成网络以更新其参数.
判别网络通过引入梯度惩罚来衡量生成样本与真实样本之间的推土距离,可表示为式(2)的形式.
LD=Ex~PdataD(x)-Ex-pgD(x)+λE(‖xD(x)‖-1)2,
(2)
其中最后一项是梯度惩罚项,Pg是多个生成器生成样本的联合分布.
4 实验
除了介绍实验的相关信息(实验的数据集、实验环境、实验的评价指标)外,还从引入集成学习、引入协同工作机制等方面验证了提出的模型的有效性,最后将文中的模型与多种模型进行了对比.
4.1 实验数据集及实验环境
本文在验证模型的有效性时,采用了训练GAN常用的数据集,具体的数据集信息如表1所示.文中所有实验均在Tensorflow平台下进行构建,使用Python进行编程,实验软硬件配置信息如表2所示.

表1 数据集的使用信息

表2 实验软硬件环境配置
4.2 实验的评价指标
对于各模型生成的样本除了采用主观观测之外,还引入了常用的评价指标进行评价.具体地使用了InceptionScore(IS)、FréchetInceptionDistance(FID)、KernelInceptionDistance(KID)3种评价指标.
若生成样本与真实样本越接近则IS值越大;若生成样本与真实样本在特征层上的距离越相近,其FID值越小;若生成样本与真实样本之间的差异越小,则其KID值越小.
4.3 引入集成学习方法对实验的影响
以往许多工作大都在单生成器的基础上进行,实验效果往往不太理想,为避免这一问题引入了集成学习思想.设置2组实验进行对比,分别记为采用集成学习组与不采用集成学习组,分别在MNIST、Cifar10、CelebA数据集下进行实验,结果如图8~10所示.

a.不采用集成学习思想;b.采用集成学习思想.图8 MNIST数据集上结果对比Fig.8 Comparison of the results on the MNIST

a.不采用集成学习思想;b.采用集成学习思想.图9 Cifar10数据集上结果对比Fig.9 Comparison of the results on the Cifar10
通过图8~10可明显看出,不采用集成学习思想的模型生成样本在多样性以及质量方面均不如采用集成学习方法的模型.在图8a中,生成的手写字符出现难以辨认的现象;而右图采用集成学习思想的模型样本较为清晰与左图形成鲜明的对比.在图9a中,矩形框标注处为梯度弥散区,该部分样本出现异常现象,生成样本可辨识性较差;图9b采用集成学习思想的模型样本较为清晰,多样性较强.在图10a中由于不采用集成学习思想,生成样本多样性较差,且多次出现“鬼脸”现象,而在图10b上很大程度地缓解了这一问题.

a.不采用集成学习思想;b.采用集成学习思想.图10 CelebA数据集上结果对比Fig.10 Comparison of the results on the CelebA
4.4 引入协同工作机制对实验的影响
为验证这一方法的可行性,在3个数据集下进行了可协同工作与不可协同工作2种对比实验,并从参数量以及训练一轮所需时间上进行了比较.结果如表3所示.

表3 3种数据集下2种方法的总参数量以及每轮迭代所需时间对比
通过表3可知,在3种数据集下,可协同工作机制的参数量与不可协同工作机制的参数数量相比减少了近26%,这在节省资源开销方面具有重大意义.
4.5 对比实验
该部分主要与DCGAN、MAD-GAN以及WGAN进行对比,在相同的环境下进行实验,并采用相同的评价指标对生成样本进行评价.
MNIST数据集:
在MNIST数据集上生成模型的输入为64维的向量,经reshape后为4*4*128,后经过一系列变换为28*28*1.不同模型生成样本如图11所示.通过图11可知,几种模型在10 epochs时均达到收敛状态,且本文所提方法无论是在生成样本质量还是多样性上均最优,其次为采用了强制学习思想的MAD-GAN模型,由于DCGAN模型使用的损失函数以及网络的搭建都存在一些问题,因此DCGAN模型表现不佳.

图11 MNIST数据集上不同模型生成的样本对比Fig.11 Comparison of samples generated by different models on the MNIST
为了更精确地验证几种模型性能上的差异,在不同评价指标下进行了评价,实验结果如表4所示.通过表4可看出本文提出的模型表现最佳,其次为MAD-GAN以及WGAN模型,由于DCGAN模型易出现梯度弥散情况,导致了DCGAN表现较差.

表4 MNIST上各模型的评价指标得分情况
Cifar10数据集:
在Cifar10数据集上生成模型的输入为128维的向量,经reshape后为4*4*128,后经过一系列变换为32*32*3.不同模型生成样本如图12所示.

图12 Cifar10数据集上不同模型生成的样本对比Fig.12 Comparison of samples generated by different models on the Cifar10
通过图12可看出本文提出的模型无论是在生成样本质量还是多样性上均明显优于几种对比模型.
为了进一步的验证本文提出的模型与几种对比模型在性能上的差异,在不同评价指标下对生成样本进行了评价,实验结果如表5所示.通过表5可知,本文模型在3种评价指标上均最优,其次为MAD-GAN以及WGAN模型,最后为DCGAN模型,这很好地证明了本文提出方法的有效性.
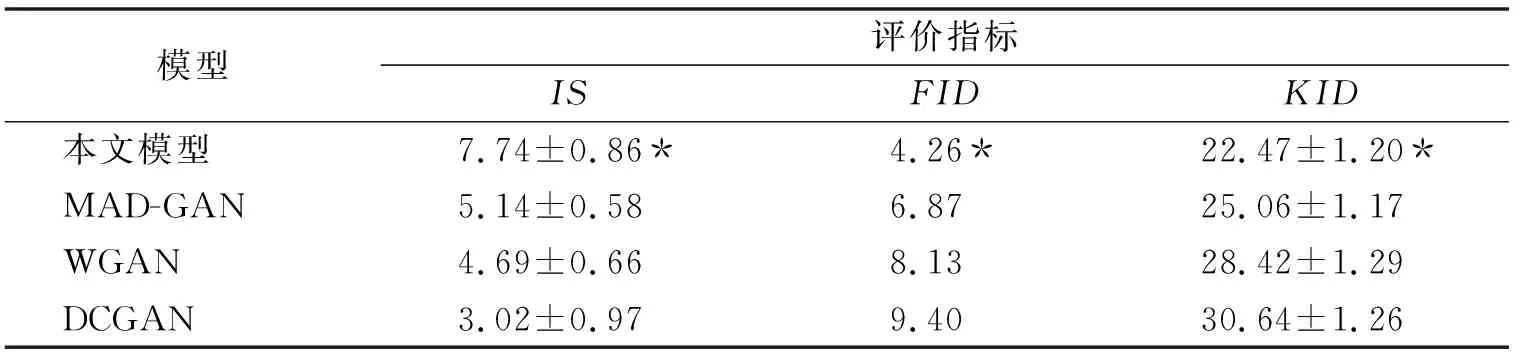
表5 Cifar10上各模型的评价指标得分情况
CelebA数据集:
在CelebA数据集上生成模型的网络结构设置可大致参考MNIST上的网络结构.与MNIST的结构的主要区别为输入输出形状的不同.输入为128维的向量,经reshape后为4*4*128,后经过一系列变换为64*64*3.
本文提出的模型黄色方框下很好地体现了生成样本的多样性特点,具体体现在性别、发色、年龄、表情、有无配饰等方面;MAD-GAN模型绿色方框处出现了头发与背景融合的现象;WGAN模型一定程度上缓解了模式崩溃问题,但生成的图像在这一模型中更关注于同一面部特征;DCGAN模型多次出现了“鬼脸”以及弥散的情况.如图13所示.

图13 CelebA数据集上不同模型生成的样本对比 Fig.13 Comparison of samples generated by different models on the CelebA
为了进一步验证本文提出的模型与几种对比模型在性能上的差异,在不同评价指标下对生成样本进行了评价,实验结果如表6所示.

表6 CelebA上各模型的评价指标得分情况
通过表6可知,模型在3种评价指标上均最优,这很好地证明了本文提出方法的有效性.通过上述的一系列实验,可以得出模型在生成图像方面极大地增加了图像的多样性与质量.采用的协同工作机制在减少参数量的同时加快了模型的训练速度,还增加了各生成器捕捉细节的可能.在研究更换损失函数方面将Wasserstein距离引入进来,极大地改善了模型训练的稳定性;最后验证的使用残差网络中通过结果更是清晰地看到了残差网络在这一模型中起到的作用.
5 总结
针对在生成对抗网络中存在的问题,提出了一种基于集成学习思想的多生成器生成对抗网络模型,该模型包含多个生成网络,每个生成网络均采用残差网络进行搭建,同时为了加快模型收敛速度在生成网络之间引入协同工作的机制,允许各生成网络在前几层进行参数共享,这有效地帮助了网络获取信息,而在最后2层分开,极大地丰富了生成样本的细节信息.最后将各生成网络的特征图进行融合作为最终的特征图像,输入到判别网络中.通过在相同的实验环境下进行大量的实验,并采用一系列的评价指标进行评价,验证了本文方法是可行且高效的.
