基于CSM系统的JTC故障智能诊断方法
2022-01-07刘一博赵林海
刘一博,赵林海
(北京交通大学 电子信息工程学院, 北京 100044)
列车运行控制系统是保障行车安全和提高运输效率的重要设备。作为列车运行控制系统核心设备之一的ZPW-2000系列无绝缘轨道电路(Jointless Track Circuit,JTC),主要用于实现列车占用检查和地-车间相应控制信息的连续传输。一旦其发生故障,将会影响行车效率,甚至危及行车安全[1]。对此,我国研发出相应的信号集中监测(Centralized Signal Monitoring,CSM)系统,可以对包含JTC在内的设备运行参数和电气性能进行连续监测和趋势分析[2]。但在实际应用中,CSM的作用并没有得到充分发挥,同时还存在无效报警较多、故障报警后仍需现场维修人员逐个分析判断具体故障点、监测报警上下限设置无统一标准等不足[3]。如何充分利用好CSM系统,克服其现有不足,提升其对JTC的监测和诊断水平,已经成为目前的研究热点。
CSM系统对JTC进行智能分析的诊断理念于2008年被提出[4]。之后,文献[5]提出了基于信息融合的JTC故障诊断方法。文献[6]提出了将基于监测数据的BP-LM-PSO-GA混合算法用于JTC故障诊断,以解决单独设计神经网络带来的运算量问题。文献[7]提出了基于决策树的JTC故障诊断方法。文献[8]提出了基于最小二乘支持向量机的诊断方法。文献[9]提出了基于模糊推理的JTC故障诊断算法,能对发送端模拟网络断路等17种故障进行诊断。文献[10]结合决策树算法和专家系统,基于CSM系统监测数据对JTC进行故障诊断,并对决策树算法的连续属性离散化过程作了优化,提高了运算效率。文献[11]提出了基于粒子群支持向量机的JTC故障诊断模型,将粒子群算法用于支持向量机的参数优化,使其故障诊断率高于普通的SVM模型。文献[12]提出了基于模糊认知图模型的JTC故障诊断方法,随后文献[13]结合模糊认知图与粗糙集,利用模糊认知图构建出了基于属性约简和模糊认知图的故障分类器,并通过自适应遗传算法实现了模糊认知图权重的设定。
综合分析以上各文献可以得出:①文献[5,7-8,10-13]只能实现轨道电路10种以下故障的粗定位,即只能将故障划定在轨道电路中一个较大的范围内,要实现故障诊断,还需要相应维修人员基于此范围进行进一步的故障排查,故这些方法的维修效率不高;②文献[5-13]的算法训练样本均来自于铁路现场,而由于现场不同故障的发生频次差别很大,故会导致发生次数少的故障缺乏训练样本,没有发生过的故障,即未知故障,则没有机会得到训练,从而无法实现其故障诊断。
针对以上问题,本文基于JTC和CSM系统的基本结构和功能原理,首先对CSM系统的监测数据进行建模,通过半实物平台对仿真数据进行验证;然后,针对故障粗定位和故障样本有限的不足,采用故障注入技术[14],利用所建模型,采用人工方式有意识地主动产生故障,实现对JTC典型故障模式下CSM监测数据的仿真,以此建立故障特征集,从而有效增加故障样本类型和数量;最后,针对未知故障的处理难题,制定JTC故障智能诊断策略,基于随机森林模型设计相应的故障诊断算法。实验表明,本文算法具有诊断范围精准、算法泛化性高、对未知故障具有一定智能处理能力等优点,能够提升CSM系统对JTC的故障诊断性能。
1 JTC与CSM系统
JTC和CSM系统的基本结构与工作原理示意见图1。
JTC可分为发送端设备、主轨和小轨的接收端设备以及轨道线路。发送端设备主要包括发送器、发送电缆、发送端匹配变压器和发送端调谐区等;主轨接收端设备主要包括包含衰耗器的主轨接收器、接收电缆、接收端匹配变压器和接收端调谐区等;小轨接收端设备和主轨接收端设备结构一致,并与发送端共用调谐区;轨道线路主要包括钢轨和钢轨间并联的补偿电容等;调谐区由两根钢轨,以及并联在钢轨间的2个调谐单元BA1、BA2和1个空心线圈SVA构成[15]。
JTC信号Ufb(t)由发送器产生,经发送电缆、发送匹配变压器和发送端调谐区,在轨道线路无车时,一部分信号沿轨道线路向主轨接收端的接收器1传送,另一部分信号向小轨接收端的接收器2传送,最终主轨和小轨的接收器分别对所接收的信号进行处理。这里,Ufb(t)的数学表达式[16]为
(1)
式中:Amfb、fc、Δfp、φ0分别为Ufb(t)的振幅、载频频率、频率偏移度(频偏)、初始相位;sm(t)为占空比为1∶1、频率为fd的方波调制信号。
在CSM系统中,采集机实时采集JTC的状态信息,并由车站站机负责对其采集到的原始数据进行预处理、分析和存储,再通过网络设备将相关数据传送至电务段;各铁路局集团有限公司和中国国家铁路局集团有限公司负责建立相关通信连接和数据交换,以便相关人员实时查看和分析[17]。CSM系统对JTC的监测点共有6个,如图1所示,分别是发送电缆设备侧电压Ufb(t)、发送电缆电缆侧电压Ufd(t)、主轨接收电缆电缆侧电压Ujd(t)、主轨接收电缆设备侧电压Ujb(t)、主轨接收器接收电压Uzj(t)和小轨接收器接收电压Uxj(t)。
2 CSM系统监测数据的建模及验证
2.1 CSM系统监测数据的建模
基于传输线理论[18],对JTC调整状态下CSM系统监测数据进行建模,见图2。
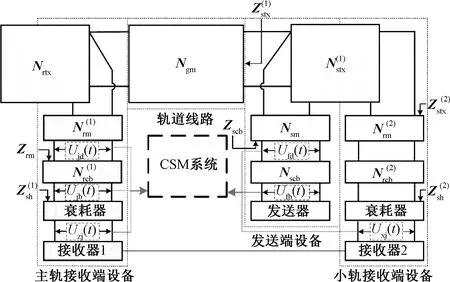
图2 CSM系统监测数据模型

发送电缆设备侧电压Ufb(t),即发送器输出的信号。
发送电缆电缆侧电压Ufd(t)为
Ufd(t)=Ufb(t)/|Nscb11+Nscb12/Zscb|
(2)
(3)
(4)
(5)

主轨接收电缆电缆侧电压Ujd(t)可以通过发送电缆到主轨接收端匹配变压器的等效四端网络模型Njd推导得到,即
Ujd(t)=Ufb(t)/|Njd11+Njd12/Zrm|
(6)
(7)
(8)
(9)

主轨接收电缆设备侧电压Ujb(t)可以通过发送电缆到主轨接收电缆的等效四端网络模型Njb推导得到,即
(10)
式中:Njb11、Njb12为Njb的特性参数,即
(11)
主轨接收器接收电压Uzj(t),由衰耗器的工作原理可知
Uzj(t)=Ujb(t)/nz
(12)
式中:nz为主轨接收端衰耗器初级线圈与对应次级线圈的匝数比,其值为常数。
小轨接收器接收电压Uxj(t)可以通过发送电缆到小轨接收电缆的等效四端网络模型Nxj推导得到,即
(13)
(14)

最终,分别提取Ux(t)∈{Ufb(t),Ufd(t),Ujd(t),Ujb(t),Uzj(t),Uxj(t)}的有效值Ax∈{Afb,Afd,Ajd,Ajb,Azj,Axj},即Ux(t)在一个周期T≈1/fc内的方根均值为
(15)
2.2 基于JTC半实物仿真平台的模型验证
基于JTC的半实物仿真平台主要包括:ZPW-2000无绝缘轨道电路的发送器、接收器、衰耗器,以及发送端和接收端的匹配变压器、调谐单元、空心线圈等实际设备;电缆采用专用模拟电缆网络;钢轨线路采用专用轨道模拟盘。仿真平台主要参数:发送电平3级,载频2 600 Hz,传输电缆总长度10 km,钢轨线路长度1 229 m,补偿电容数量15个,容值40 μF,道砟电阻2.0 Ω·km。
首先,利用万用表Fluke 8842A采集并测试图1中6个监测点的信号电压有效值Afb、Afd、Ajd、Ajb、Azj、Axj;然后,将其分别与式(1)、式(2)、式(6)、式(10)、式(12)、式(13)的仿真模型进行对比,对比结果见表1。

表1 基于半实物平台的测量值与基于仿真模型的仿真值及其误差
由表1可以得出,JTC半实物平台的测量值与基于本文模型的仿真值较为接近,其最大相对误差小于6%,最大绝对误差小于3 V。表明本文所建立模型可以准确表征各监测点的电压模型。
3 基于随机森林的JTC故障智能诊断方法
3.1 诊断算法设计
为了达到故障定位精准以及能有效处理未知故障的目的,本文提出一种基于随机森林的智能诊断算法,其结构框架见图3,主要包括特征提取和算法训练两部分。

图3 JTC故障智能诊断算法结构框架
特征提取:根据不同故障模式对CSM系统监测数据的影响规律,一方面,针对现有研究中的故障定位精度不高和故障样本有限等不足,采用故障注入技术[14],通过设置各元器件故障值,仿真模拟JTC典型故障模式下的CSM监测数据,并对仿真结果进行有效值特征提取,以构建用于训练故障诊断初始模型的故障特征集,有效增加故障样本类型和数量;另一方面,对于现场实时的CSM监测数据,基于同样的规则提取数据的有效值特征。
算法训练与诊断:基于故障特征集生成随机森林初始模型,通过训练确定随机森林参数及阈值,针对未知故障的处理难题,制定包含再训练过程的JTC故障智能诊断策略。对实时监测数据提取的特征,经过JTC故障诊断模型后,输出诊断结果及相应指标,根据指标值是否大于阈值决定模型是否进入再训练过程。当指标值大于阈值时,诊断JTC状态为典型故障并直接输出诊断结果;否则,将诊断结果作误判或未知故障处理,进入再训练过程,请求现场人员评判故障类型,利用现场评判结果及相应的监测数据特征,重新训练故障诊断模型,从而提高模型对该种故障的敏感性,使其不断完善。
3.2 JTC故障特征集的构建
根据现场调研和JTC的故障致因分析[19],本文将JTC故障划分为室内设备故障、室外设备故障、电缆故障、钢轨线路故障等。其中,室内外设备故障主要易出现断线、发送器发送电压偏小或偏大、匹配变压器参数值偏小等情况;电缆故障主要易出现断线和模拟网络参数值偏小等情况;钢轨线路故障主要易出现补偿电容值偏小或断线以及道砟电阻偏小或偏大的情况。最终总结出31种JTC典型故障,见表2。

表2 JTC典型故障类型分布表
考虑到故障特征集的完备性,基于上述模型对31种故障各仿真40组数据,提取特征,以构建故障特征集D。令#D为集合D中元素的数目,则#D=31×40=1 240。从#D个样本中分层随机抽取60%作为训练集DT训练随机森林模型,20%作为验证集DV用于模型调参,20%作为测试集DE评估性能。
3.3 随机森林初始模型的生成与再训练
随机森林[20]是一个由多个树分类器构成的现代机器学习算法,具有计算开销小、泛化性能好等特点。因为数值缩放对树模型的结构不造成影响,所以也无需对特征集作归一化处理。随机森林模型示意见图4。

图4 随机森林模型示意
图4中,每棵决策树根据输入特征A=[AfbAfdAjdAjbAzjAxj]输出故障结果对应的编号e,最后通过结合策略得到随机森林模型的输出。本文选取的随机森林基分类器为CART决策树,该树为二叉树,使用Gini指数计算结点的纯度,运算速度快。一棵决策树包含一个根结点、若干个内部结点和若干个叶结点;叶结点对应于故障诊断结果的编号e,其他每个结点则对应于一个特征测试;每个结点包含的样本集合根据特征测试的结果被划分到子结点中;根结点包含样本全集[21]。
随机森林初始模型的生成流程见图5。其特点主要是训练样本有放回随机抽取以及待选特征集随机组成两个随机特性。具体流程如下:

图5 随机森林初始模型的生成流程
Step1生成根结点样本集Dt。
利用自助法随机抽取技术[22],从训练集DT中有放回地随机抽取等量m个样本,构建单棵决策树的训练集Dt,即根结点的样本集。
DT={(Ai,ei)|i=1,…,m}
(16)
Ai=[Afb,iAfd,iAjd,iAjb,iAzj,iAxj,i]
(17)
ei∈{1,2,…,n}
(18)
式中:Ai为第i个训练样本的监测数据特征;ei为第i个训练样本的故障编号。
Step2生成待选特征集F。
若结点分裂不会使该决策树超过其最大深度g的限制,则从d=6个电压特征中随机抽取k个不同的特征生成待选特征集F,即
F⊆{Afb,Afd,Ajd,Ajb,Azj,Axj}∧(#F=k)
(19)
通常,令k=log2d[20];否则,遍历其他未遍历过的结点。
Step3选择最优划分特征A*和最优划分点r*。
A*的选择基于结点纯度最高原则,使用Gini指数来度量样本集合的纯度。分析即将进行分支的根结点,其包含的故障特征集Dt的Gini值定义为
(20)
式中:Cj为Dt中故障编号为j的子集,即
Cj={(Ai,ei)∈Dt|ei=j}
(21)
考虑到本文的电压特征为连续特征,所以在计算不同划分方式对应的Gini指数时,利用二分法处理机制[23]先将特征离散化。对于故障特征集Dt和某一监测数据特征
Ax∈{Afb,Afd,Ajd,Ajb,Azj,Axj}
(22)
假定Ax在Dt上出现了q个不同的取值,将这些值从小到大进行排序,记为
(23)

(24)
(25)
对连续特征Ax,在RAx中选取其最优划分点r*。
结合式(20),通过计算Dt基于Ax划分的Gini指数Gini_i(Dt,Ax)来确定最优划分点r*,即
(26)
(27)
式中:Gini_i(Dt,Ax,r)为样本集Dt基于划分点r二分后的Gini指数;r*为使Gini_i(Dt,Ax,r)最大化的划分点。在样本集Dt中,每个特征Ax都对应一个最优划分点r*。
在待选特征集F中,选择使得Gini_i(Dt,Ax)最小的特征作为最优划分特征A*,即
(28)
其对应划分后的样本集合纯度最高,从而确定了最优划分特征A*及对应的最优划分点r*。
Step4生成子结点与叶结点。
结点根据上述过程确定的A*、t*进行分裂,若产生的两个子结点包含的样本数量均满足设定的叶结点最小样本数b的条件,则生成这两个子结点;否则,不进行分裂,遍历其他未遍历过的结点进行分裂,即

(29)
当子结点满足Gini(·)=0或者包含的样本数量小于设定的拆分内部结点所需的最小样本数c等结点停止分裂条件时,该子结点成为叶结点,继续遍历其他未遍历过的结点进行分裂;否则,该结点继续分裂,即

(30)
Step5存储决策树与生成随机森林。
当遍历完所有的结点后,存储该决策树。当决策树数目达到随机森林所要求的规模s时,生成随机森林初始模型;否则,继续生成下一棵决策树。
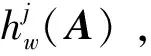
(31)

(32)
(33)
随机森林最终输出不同j对应Hj(A)中的最大预测概率H*(A)及对应的故障编号j*(A),即
(34)
Step6故障诊断模型的再训练。
从图3可知,针对未知故障的处理难题,故障诊断模型会参与一个再训练过程。该过程有一个阈值θ,实时监测数据经过特征提取与JTC故障诊断模型后,输出诊断结果j*及相应指标H*。当指标H*≥θ时,直接输出对应的诊断结果j*;当H*<θ时,则进入再训练过程,结合现场判断的JTC实际故障类型编号j#和对应提取的特征A#构建输入样本(A#,j#),添加到原训练集DT中,重新训练随机森林模型。
3.4 随机森林参数和阈值θ的确定
随机森林模型对JTC的诊断性能主要取决于森林的规模s、树的最大深度g、叶结点最小样本数b、拆分内部结点所需的最小样本数c这4个参数。在上述模型训练过程中,已知本文中单棵决策树训练样本数目m= #D×60%=744,故障类型数n=31。
针对验证集DV上的模型准确率a(DV),对上述4个参数进行随机搜索,最终a(DV)达到99.44%,对应s=70,g=9,b=13,c=14。模型准确率a(DV)为验证集DV中经过模型后预测的诊断结果j*正确的样本占比,即
(35)
(36)
在测试集DE上模型准确率a(DE)达到了98.25%,表明模型有较好的泛化性能。
基于DE,引入本文算法中的再训练过程,对阈值θ的取值进行确定。分别计算θ由0到1、步长为0.01的算法准确率aθ(DE)。与a(DE)稍有不同,aθ(DE)为DE中输出指标H*达到阈值θ且预测的诊断结果j*正确的样本占比,即
χ[j*(Ai)=ei)]
(37)
(38)
不同阈值θ下算法准确率aθ曲线见图6。可以看出,θ在[0,0.5]区间时,算法准确率保持在较高水平,均在97.14%以上,最高可达99.21%;虚警率FAθ(DE)和漏报率MAθ(DE)均为0;对于钢轨线路的故障存在少数例拒绝识别的情况,但它们的指标对应的诊断结果均是正确的,只是没达到θ,所以它们并没有被错分到其他故障类型。

图6 测试集DE在不同阈值θ下的算法准确率aθ曲线
FAθ(DE)和MAθ(DE)均考虑了θ的作用,即
χ(j*(Ai)≠1))
(39)
χ[j*(Ai)=1)]
(40)
由此可见,通过加入一个再训练过程对随机森林模型进行改进,在DE上的算法准确率aθ已经可以超过再训练之前的模型准确率a。显然,在保证较高aθ的同时,θ越大,算法输出结果对应的最大预测概率越高,即可以使结果更加可信。通过本文的分析结果,阈值θ设置为0.4。针对不同的实际情况,阈值θ通过在算法准确率和输出结果可信度之间的权衡进行调整。
4 基于JTC半实物仿真平台的算法验证
4.1 功能测试
4.1.1 已知故障
采用故障注入技术,在半实物平台上人工模拟JTC故障9,即使发送端调谐区BA1发生断线。通过对CSM系统监测数据进行有效值特征提取,得到数据Afb、Afd、Ajd、Ajb、Azj、Axj分别为137.71、45.39、3.67、0.47、0.24、4.71 V。
将数据A=[AfbAfdAjdAjbAzjAxj]传入训练好的随机森林模型的每棵决策树中,根据每个结点的划分条件逐级传递,直到到达叶结点。根据式(33)输出A属于不同故障编号j对应状态类型的预测概率Hj(A),对n个概率从大到小依次排序,前5位分别为H9(A)、H10(A)、H8(A)、H22(A)、H12(A),它们的值分别为0.425、0.156、0.107、0.054、0.051。
根据式(34)模型输出最大值H*(A)=H9(A)及对应的状态类型j*(A)=9。通过阈值判断,H*(A)≥θ(θ=0.4)条件成立,判断出此时JTC故障为对应于故障编号为9的状态类型。这与半实物平台实际故障状态一致,从而证明了本文所提算法对JTC典型故障诊断的有效性。
4.1.2 未知故障
通过半实物平台获取了4例本文仿真训练集中不包含的组合故障,见表3,其相应的编号依次延伸。

表3 部分未知的组合故障类型
同样将4组数据传入模型,根据式(33)输出4组数据属于不同故障编号j对应状态类型的预测概率Hj(A),对n个概率从大到小依次排序得到表4,同样仅显示前5位。

表4 不同未知故障n个概率Hj(A)从大到小排序后的前5位
根据式(34),4组数据的模型输出指标H*(A)均不能满足阈值判断条件H*(A)≥θ,所以算法进入再训练过程,用实际故障编号和输入数据构建输入样本,添加到原训练集DT中,重新生成随机森林模型。
在半实物平台再次获取上述组合故障的不同测试样本,得到不同阈值θ下的算法准确率aθ曲线,见图7。由图7可以看出,θ在[0.35,0.42]区间时,算法已经可以对该4种未知故障进行精准识别,与之前训练得到的阈值θ=0.4对应。

图7 部分未知故障数据集在不同阈值θ下的算法准确率aθ曲线
4.2 性能验证
通过半实物平台,利用故障注入技术,人为设置表2中传输电缆、调谐区调谐单元、空心线圈、补偿电容、衰耗器等13种断线故障的243组采集数据,构建算法性能测试集。利用本文提出的故障诊断方法,对这些数据进行诊断分析。不同阈值θ下算法准确率aθ曲线见图8。

图8 实时监测数据在不同阈值θ下的算法准确率aθ曲线
由图8可以看出,θ在[0.33,0.49]区间时,算法的准确率处于较高水平,均在92.18%以上,与之前训练得到的阈值θ=0.4对应;根据式(39)和式(40),其虚警率和漏报率均为0;对于调谐区和钢轨线路的故障分别存在少数例拒绝识别的情况,但由于其指标对应的诊断结果均是正确的,只是没有达到θ,故这些故障并没有被错分到其他故障类型。
进一步,利用本文表2所示的31种故障类型数据,分别对文献[5-13]所提方法的故障诊断结果进行分类统计,其统计结果见图9。

图9 本文方法与现有研究可区分的故障类型数目对比
由图9可知,对于表2所示的这31种故障,本文方法可实现完全有效区分;文献[6]和文献[9]将其划分为17类;文献[12]和文献[13]划分为9类;文献[10]划分为7类;文献[5]、文献[7]和文献[8]划分为6类;文献[11]划分为5类。可见,本文算法的故障识别度更高,能够更精确地实现设备的故障定位,提高设备维修效率。
5 结论
JTC是列控系统的重要组成部分,CSM系统能够实现对JTC的自动诊断。为进一步提高CSM系统的诊断性能,本文基于CSM系统的工作原理,提出了一种基于随机森林的JTC故障智能诊断方法。可得以下结论:
(1)通过传输线理论,对CSM系统的JTC数据采集过程进行建模,并在JTC半实物仿真平台上进行了模型验证。
(2)利用所建模型,采用故障注入技术,对JTC典型故障模式下的CSM监测数据进行仿真,建立了故障特征集。
(3)最后,制定包含再训练过程的JTC故障智能诊断策略,设计了基于随机森林的故障智能诊断算法。
(4)实验表明,本文算法基于CSM系统,在不增加额外采集点的情况下,能够准确定位JTC上31种典型故障,其故障分类识别能力优于参考文献中的现有算法,且准确率达到92.18%。此外,本文算法对未知故障具有较高的智能诊断和学习能力。
综上所述,本文算法具有故障定位准确、识别度高和适应性强等特点,能够提升CSM系统对JTC的故障诊断性能。
