基于混合表征学习的专利分类方法研究*
2022-01-05王庆才,刘贵全
王 庆 才,刘 贵 全
(1.中国科学技术大学 计算机科学与技术学院,安徽 合肥230027;2.大数据分析与应用安徽省重点实验室,安徽 合肥230027)
0 引言
专利分类是专利挖掘和管理中重要的基础任务。其主要目的是通过自然语言处理等方法提取专利文档中的重要特征,然后将这些特征输入分类器中,其输出结果表示专利文档所属的标签。通常一个专利具有一个或多个标签。面对每年快速增长的专利申请数量,实现高效的、自动化的专利分类算法可以大大减少专利机构的人工成本和时间成本。目前,自动化专利分类算法已被专利机构广泛使用,为专利检索[1]、专利价值评估[2]、专利诉讼风险评估[3]等专利智能服务提供支持。
因此,这吸引了许多研究人员来研究自动专利分类问题[4-6],并且这些方法中的大多数将其视为多标签文本分类任务[4-5]。专利的主要内容为其组件和创新的详细说明文档,该任务的目标是针对专利自动化预测一组标准化的类别。传统的专利分类方法大多基于统计学和自然语言处理方法人工构造特征信息,输入到机器学习模型中进行训练,然后预测未知专利的类别信息。这些方法大多属于浅层模型,仅仅学习了专利文本简单的词义信息,无法获取深层的上下文语义信息。而且专利中包含了大量的非结构化信息,如专利之间的引用信息,通常将专利作为网络节点构建专利引用网络,然后基于网络分析的方法对专利节点进行分类。此类方法专注于学习网络的结构信息,忽略了专利文本信息对预测专利类别的影响。
本文提出一个基于专利混合表征的专利分类框架,可以同时学习专利的文本信息和网络结构信息,充分保留专利的结构化信息和非结构化信息,为多元异构属性场景下的专利分类提供了新思路。在真实的专利数据集中的实验结果表明,本文提出的专利分类方法具有较高的准确性。
1 相关研究
1.1 传统的专利分类方法
传统的分类方法将专利分类作为一项有监督的机器学习任务,以人工构造的专利特征作为输入,训练不同的分类器预测专利文档的标签。Wu[7]等人将专家筛选方法与基于遗传的混合支持向量机模型相结合,提出具有高分类精度和泛化能力的专利分类系统。Ko[8]等人提出一种基于期望最大化算法和朴素贝叶斯分类器的组合,基于有标签样本训练分类器,预测出标签缺失的样本的标签,然后基于所有样本训练新的分类器,并在新样本上进行分类。Cai[9]等人提出了一种基于共享近邻的KNN文本分类方法,在BM25相似度的基础上,通过结合词频和文档频率并平衡文档的长度来计算专利文本的相似度,然后引入共享近邻的概念,利用样本间的共享近邻信息对BM25相似度进行修正,最后使用KNN算法计算专利类别。
以上方法都是基于特征工程和传统机器学习的方法,甚至需要依赖专家的领域知识,几乎无法挖掘专利文本的深度语义信息,导致专利分类结果的准确性和泛化能力较低。
1.2 基于深度学习的专利分类方法
近年来,随着深度学习在许多应用中取得了巨大的成功,部分学者使用深度学习技术进行专利分类,例如卷积神经网络(Convolutional Neural Network,CNN)和循环神经网络,可以学习专利中的语法和语义信息以获得更好的分类结果。Julian[10]等人提出了针对专利领域的词嵌入预训练,先使用FastText在大规模专利数据集上训练专利领域的词向量,然后提出一种基于门控回归单元的深度学习方法,基于预训练的词嵌入实现专利自动分类。Li[4]等人提出deeppatent模型,以TextCNN为核心组件,通过设置多个不同大小的卷积核捕获连续语句的局部关键信息,丰富专利的语义表示。Lin[11]等人提出BiLSTM-SA模型,基于双向循环神经网络和自注意机制捕获具有非连续和长距离语义的上下文信息。Lee[5]等人提出基于预训练模型的PatentBert模型,在超大规模语料库进行预训练,然后在专利数据语料库进行微调实现专利文本分类。
在数据库中,专利具有更加丰富的信息,如专利之间的宏观相似关系。现有的研究大多只关注于单个专利的文本内容进行分类,而忽视了专利及其标签的宏观关系。一方面,存在引用关系或描述相似实体的两项专利很有可能属于相同的类别。另一方面,经常分配给相同专利的标签之间的相关性更高。这些宏观关系可以提供重要的辅助信息,提高分类性能。
2 问题定义
本节给出专利引用网络、专利实体共享网络、标签共现网络和专利分类任务的相关定义,三个网络的详细统计信息如表1所示。
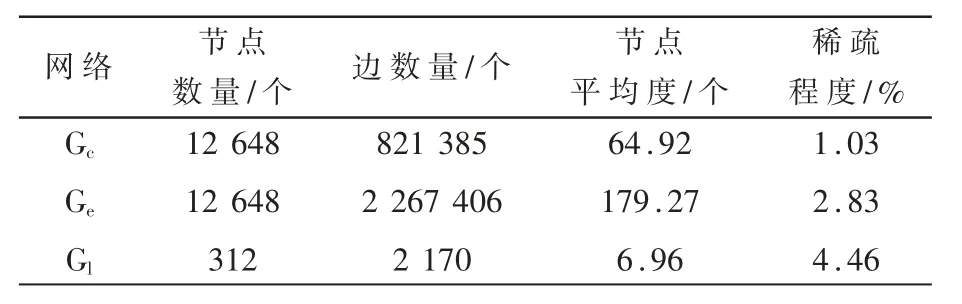
表1 网络的统计信息
专利引用网络:专利引用网络定义为Gc=(Vc,Ec),其中Vc表示专利节点集合,Ec表示专利引用链接集合,Ec中的每条边表示两个专利之间存在引用关系。
实体共享网络:实体共享网络定义为Ge=(Ve,Ee),其中Ve表示专利节点集合,Ee表示专利实体共享链接集合。Ee中每条边表示两个专利之间具有多个相同实体链接。
标签共现网络:标签共现网络定义为Gl=(Vl,El),其中Vl表示标签集合,El表示标签共现链接集合。El中每条边表示两个标签之间的逐点互信息(Pointwise Mutual Information,PMI)为正值。具体地,Ei,j=log(p(i,j)/(p(i)p(j))),其中p(x)表示标签x的出现频率。
专利分类:给定一个包含专利文档的文本信息、引用信息及其标签信息的数据集D,本文的目标是预测新加入专利文档的可能的标签。
3 方法设计
基于前文所述相关研究工作及其可改进之处,本文提出了一种融合专利和标签宏观关系进行专利分类的方法。首先,利用专利的引用关系、共享实体关系和标签的共现关系构建专利引用网络、专利共享实体网络和标签共现网络,这三个网络分别表示专利和标签的宏观结构关系。在此基础上,本文提出了一种基于混合表征的专利分类框架(Hybrid Representation Based Framework for Patent Classification,HRPC),该框架由专利表示学习(Patent Representation Learning,PRL)和标签表示学习(Label Representation Learning,LRL)组成,框架结构如图1所示。其中PRL结合专利的文本信息和结构信息学习专利的向量表示。对于专利文本信息,采用CNN和注意力机制学习专利文本的语义表示;对于专利结构信息,基于专利引用网络和专利共享实体网络设计了多通道图神经网络,从多个专利关联网络中学习专利的结构表示。LRL使用图卷积神经网络(Graph Convolutional Neural Network,GCN)在标签共现网络中学习标签的表征,用于保留标签之间的共现依赖关系。最后,利用专利和标签的表征,使用协同过滤(Collaborative Filtering,CF)策略预测标签概率。
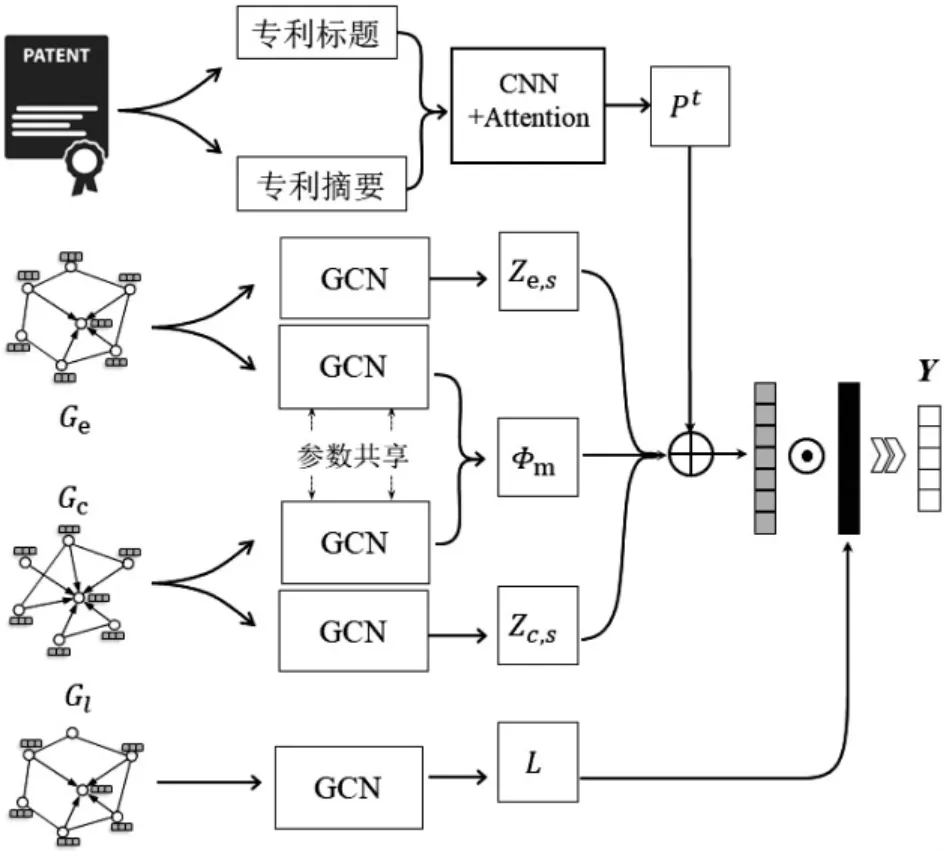
图1 HRPC的结构图
3.1 专利表征
3.1.1 专利文本表征学习
在研究[5]、[12]中,描述专利细节的文本内容对于专利分类的准确性非常重要。为了不失一般性,本文同样选择专利的标题和摘要来作为相应的文本信息。其中标题是单独的语句,而摘要则是由多个语句组成的序列。基于CNN的深度学习模型可以有效地学习语句的表征,本文将CNN作为专利文本表示模块的基本单元。标题PTi和摘要PAi作i个专利的文本输入,其中每条语句视为一个单词序列s=[v1,v2,…,vn],其中n表示句子中单词的数量,vi∈Rd0表示通过Word2vec[13]算法训练的d0维词嵌入向量。因此第i个专利的摘要可以表示为PAi=[s1,s2,…,sm],其中m表示摘要中语句的数量。通过对输入文本的预处理,得到标题和摘要的初始化表征PTi∈Rn×d0和PAi∈Rm×n×d0。CNN具有稀疏连接、权值共享和降采样的特点,对于提取输入语句的局部信息具有高性能,且速度较快。因此使用CNN作为基本单元学习专利文本中每个语句的信息表征,输入为x的卷积计算公式如下:
Conv(x)=ReLU(k⊙X+b) (1)其中⊙为对应位置元素相乘,k为卷积核,b为偏置项,ReLU为非线性活函数。经过多个卷积层和池化层后,专利的标题表征向量为Vt∈Rd1,其中d1为卷积神经网络的输出维度。通过相同的卷积与池化操作,得到摘要中第i句的表征向量为Vai。
摘要中不同语句存在语义上的差异,并且与特定任务的相关性也不同。因此,本文使用注意机制为摘要中每个句子分配不同的权重,通过加权求和的方式获得摘要的单一表征。由于标题包含了专利的核心信息,本文根据标题与每个句子的相关性来计算相应的权重分数。摘要V^a的具体计算方式如下:
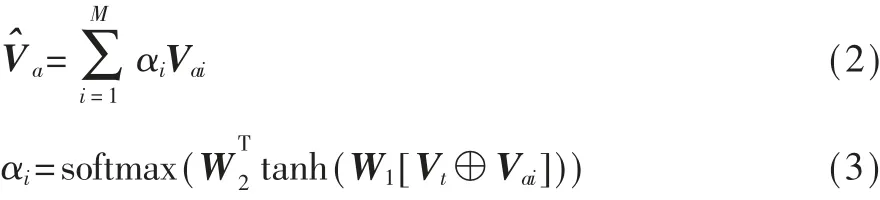
其中αi表示第i个句子的权重,W*表示参数矩阵。最后,本文对专利的标题表征与摘要表征进行拼接操作,得到专利的文本表征。对于第i个专利,文本信息表征的计算方式如下:

3.1.2专利网络表征学习
专利关联网络,即专利引用网络和实体共享网络,代表了专利的宏观关系。GCN是CNN在非结构化数据上的迁移应用,在图表征领域得到广泛研究。本文选择GCN作为基本模型学习专利节点的表征向量。首先分别在多个网络上训练GCN模型,然后将多个GCN结果进行合并得到专利节点在网络中的表征向量。然而,该方法忽略了多个网络之间的相关性,无法得到全面的专利网络表征向量。具有引用关系的两个专利可能使用相同的技术或解决同一问题,这使得专利包之间含有相同的科技实体。因此,考虑不同网络之间的相关性可以获得更加全面的专利网络结构表征。
本文参考AM-GCN[14],使用多通道图神经网络联合学习专利在两个图网络上的表征向量。其核心思想是学习专利在特定网络中的特定信息和在多个网络中共享的公共信息,以便同时保留多个网络的共性与差异。为专利节点定义的两个表征向量分别表示专利的个性表征和共性表征。个性表征向量用于学习专利节点在每个网络中的特定信息,共性表征向量则用于学习专利节点在多个网络中的公共信息。
如图1所示,首先构造两个特定的GCN,分别学习专利节点在专利引用网络和专利实体共享网络的个性表征向量,Ac和Ae分别表示专利引用网络和实体共享网络的邻接矩阵。然后,初始化专利节点的特征矩阵X∈RN×d2,其中N表示专利节点数量,d2表示特征矩阵的初始化维度。在两个特定的GCN中,使用相同的特征矩阵作为输入。对于专利引用网络,第l层GCN的输出表 示 如 下:
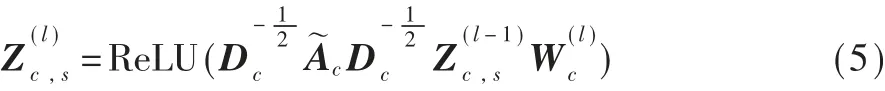
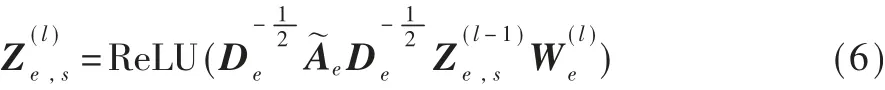
然后,构造两个特定的GCN,分别从专利引用网络和专利实体共享网络中学习专利节点的共性表征向量Zc,m和Ze,m。为了能够从多网络中学习专利节点的共性信息,两个GCN在相同层共享参数矩阵。 因此,第l层计 算 方 式 如 下:
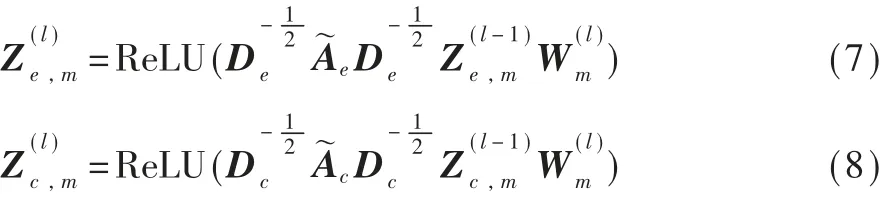

在得到专利的个性表征向量和共性表征向量之后,通过简单拼接操作获得专利节点的结构信息表征:

在获得专利的文本信息表征和结构信息表征后,第i个专利的表征向量Pi表示为:

3.1.3 表征约束
本文借鉴AM-GCN[14]的方法,添加一致性约束项和差异性约束项来增强专利节点在多网络结构中的个性表征和共性表征。
对于专利节点的共性表征向量Zc,m和Ze,m,添加一致性约束项增强在多个网络中学习的共性信息。其中,一致性约束的目的是确保不同网络中通过共性表征向量计算的专利相似性是相似的。专利节点在两个网络上的相似性矩阵由Zc,m和Ze,m通过以下方式计算:

其中Sc和Se分别是引用网络和实体共享网络的相似性矩阵。定义一致性约束项Lc表示两个相似性矩阵的差异。Lc值越小,表示学习到的共用信息越多,Lc值越大,则表示学习到的共用信息越少。Lc计算方式如下:

对于专利节点的个性表征向量Zc,s和Ze,s,添加差异性约束项,确保它们学习专利在网络中的特定信息,目的是确保同一网络中专利的共性表征向量与个性表征向量之间具有较大的差异。本文中同样使用希尔伯特-施密特独立标准(Hilbert-Schmidt Independence Criterion,HSIC)来衡量这种差异,HSIC指标已被广泛用于衡量向量之间的独立性。在专利 引 用 网 络 中,Zc,s和Zc,m的HSIC指 标 计 算 方 式如下:
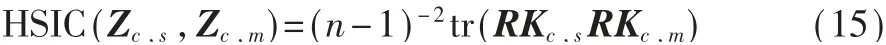
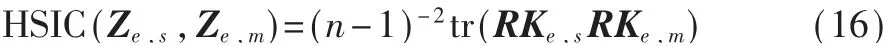
定义差异性约束项为Ld,Ld值越小,表示专利在特定网络中的个性表征和共性表征的差异越大,更能表示两个表征向量分别学到了不同的结构信息。
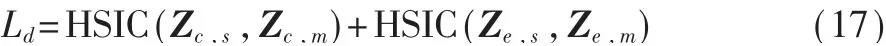
3.2 专利分类
如图1所示,将专利的表征向量Pi应用于专利分类任务,实现端到端的专利分类框架。
3.2.1 标签表征学习
部分标签频繁出现在相同专利中,这些标签可能含有相似的语义信息,表示标签之间存在一定程度的相关性或依赖性。因此,在标签共现网络中使用GCN学习标签的表征向量,同时捕获标签之间的相关性。本文使用PMI衡量标签之间的相关性:

其中,p(i)和p(j)表示第i个标签和第j个标签的出现频率,p(i,j)表示第i个标签和第j个标签同时出现的频率。依据PMI矩阵中的正值构建标签共现网络中的邻接矩阵:

然后,初始化标签特征矩阵Xl∈RC×d3,其中C表示标签数量,d3表示初始化的维度。将标签的特征矩阵Xl和邻接矩阵Al作为GCN的输入,第l′层的输出如下:其 中是 第l′层 的 权 重 矩 阵的对角度矩阵最后一层GCN的输出表示标签的表征向量L。
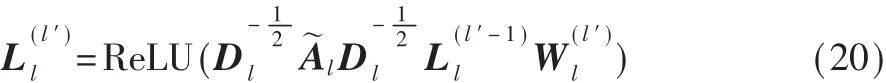
3.2.2 专利分类
现有的专利分类方法是将高维的专利特征或专利表征直接输入到全连接神经网络中,并将其输出结果作为输入样本的分类结果。当样本集的标签分布不均衡时,这些方法可能使分类器倾向于频繁出现的标签,忽视处于长尾部分的标签。因此,采用CF的策略进行专利分类,将专利和标签的共现信息作为监督信息增强专利和标签的表征学习。通过式(21)的方式得到专利的标签概率。

其中Pi是第i个专利的表征,Lj是第j个标签的表征,y^i,j是预测第i个专利第j个标签的概率。一个专利可能具有多个标签,因此使用二进制交叉熵损失函数作为目标函数,如下所示:
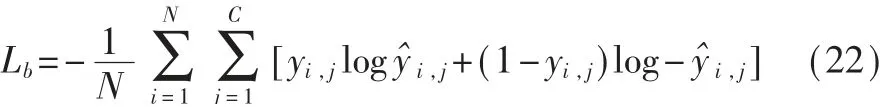
其 中,N表 示 专 利 的 数 量,C表 示 标 签 的 数 量,yi,j表示第i个专利第j个标签的真实值。本文使用L2正则化约束模型参数,缓解模型过拟合现象。

最后,将交叉熵损失函数、一致性约束项、差异性约束项和正则化约束项相加,作为HRPC的目标函 数,λ1、λ2和λ3分 别 为 一 致 性 约 束 项 系 数、差 异性约束项系数和正则化约束项系数。

4 实验结果与分析
4.1 数据与预处理
实验中用到的真实专利数据集来自美国专利及商标局,数据集包含超过600万项专利。专利文本中包含多个实体,每个实体是句子中具有实际含义的单词或短语。本文先使用NLTK工具对专利文本进行预处理,单词小写、词形还原和去除停用词,去除在语料库中出现次数少于5的单词。然后在TAGME接口中设置获取实体链接的置信度阈值ε,得到与专利关联度较高的实体链接。当专利之间共享的实体数量不少于2时,建立专利之间的实体共享链接,并根据共享链接构建实体共享网络。同时通过专利引用数据构建专利引用网络,使用NetworkX工具过滤网络中节点度小于30的专利,过滤孤立节点并增加网络密度。本文选择专利的子类作为专利分类任务的标签,该类别为联合专利分类体系中的第三层分类标准。最后,通过上述过程得到的专利数据集包含12 648条专利样本和312个子类标签。数据集的统计信息如表2所示。
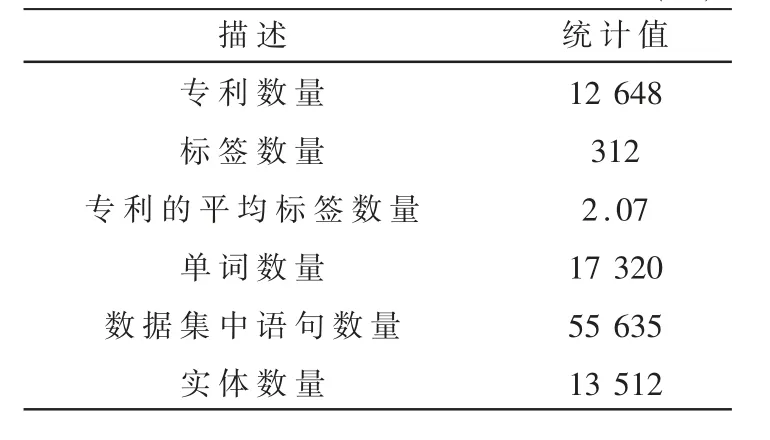
表2 专利数据集的统计信息(个)
4.2 评价指标
为了准确、全面的评估模型的性能,实验中采用准确率(Precision)、召回率(Recall)和归一化折损累计增益(NDCG)作为评价指标,然后使用top_K的评价指标量化实验性能,分别记为P@K、R@K和NDCG@K。本实验中,为了与现有模型进行对比,K值分别取1、3、5。

4.3 对比实验
本文选择了多个对比算法,其中FastText[15]、BiLSTM-SA[11]、DeepPatent[4]、PatentBert[5]、STCKA[16]为基于文本分类的专利分类方法,Deepwalk[17]、GCN[18]、GraphSAGE[19]、AM-GCN为基于网络节点分类的专利分类方法。为了公平起见,本文构造了几种结合文本信息和网络结构信息的方法,其中GCN-Texts的构造方法为由文本表征模块与GCN学习的结构表征拼接组成专利的表征向量,仅学习专利节点在引用网络中的表征,拼接两个表征向量后通过MLP预测专利标签;GCN-Text-d的构造方法与GCN-Text-s相似,使用两个GCN分别学习专利节点在引用网络和实体相似网络中的结构信息表征,拼接三个表征向量得到专利的表征向量,同样使用MLP预测专利的标签;AM-GCN-Text的构造方法与上述相似,通过AM-GCN学习专利节点在多通道网络上的结构信息,然后进行专利分类。该方法同样使用MLP进行专利分类。
实验结果如表3所示,与所有的对比方法相比,HRPC在多个评价指标上均取得了明显提升。在基于文本分类的方法中,FastText仅仅关注字符级的语义信息,忽略了更加重要的上下文信息,因此取得了较快的运行速度和较差的精度。DeepPatent和BiLSTM-SA都是基于深度学习的模型且关注于文本的上下文信息,因为BiLSTM-SA采用了双向循环神经网络和自注意力机制,学习了更加丰富的上下文信息,因此略优于DeepPatent。PatentBert使用预训练模型BERT,通过设置大量的参数和在超大规模的语料库上进行训练,获得了更强的文本表征能力,因此比前几个方法效果要更好。同样,经过外部知识的信息增强,STCKA也取得了很好的分类性能。
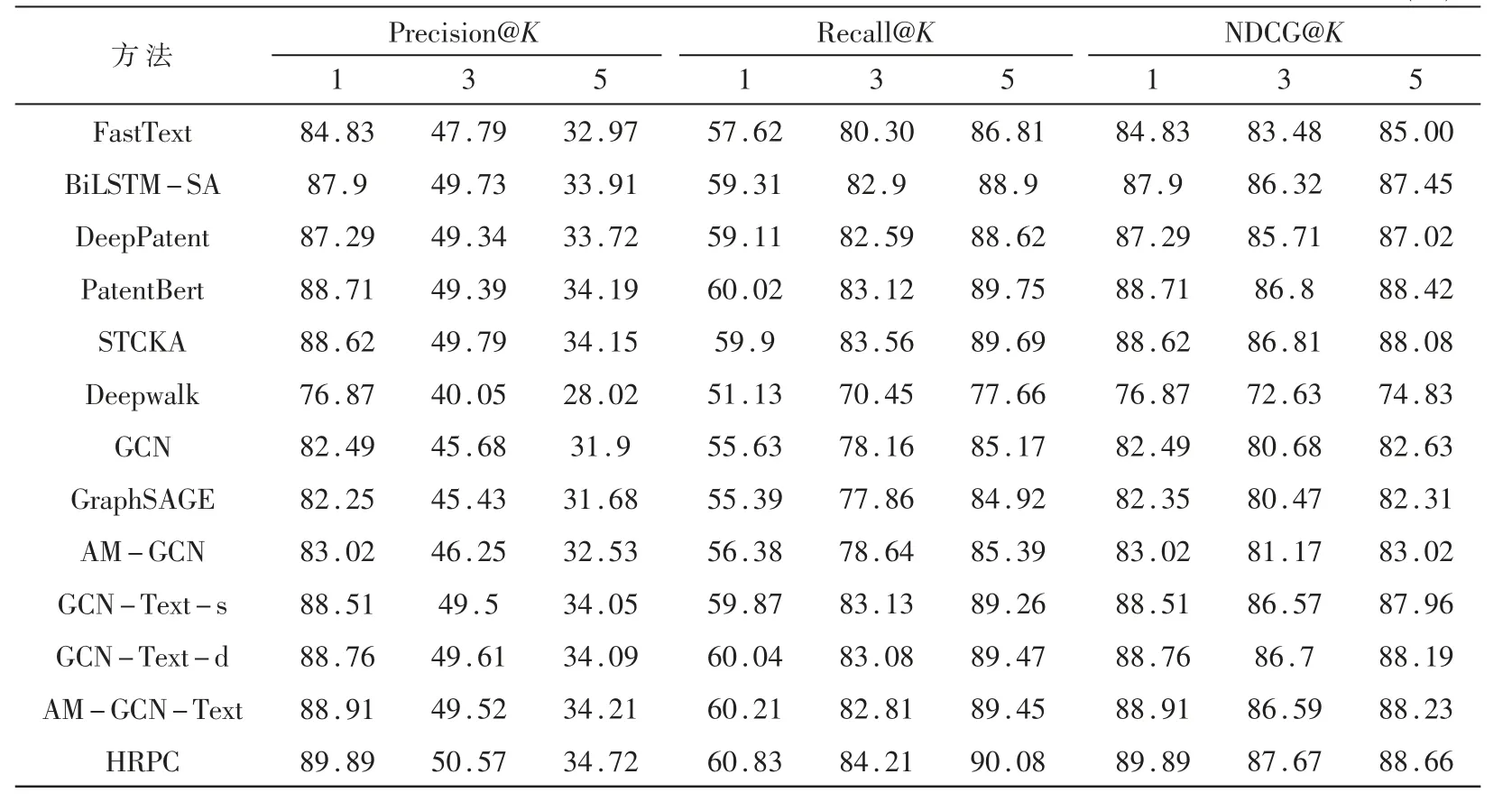
表3 不同方法在数据集中的指标对比 (%)
在基于网络表征的方法中,Deepwalk通过截断的随机游走捕获整个网络的结构信息能力较弱,而GraphSAGE由于采样邻居节点缺失了部分邻居的信息而具有相同的缺点。GCN聚合了所有邻居节点的特征取得相对较好的实验结果。AM-GCN使用GCN作为基础组件,学习了更加丰富的结构信息取得了更好的性能。显然,基于文本的分类方法通常都优于基于网络的分类方法,这表明在专利分类任务中,专利的文本信息比结构信息更重要。
最后,将HRPC与GCN-Text-s、GCN-Text-d和AM-GCN-Text的组合方法进行对比,仅使用引用网络的GCN-Text-s由于缺少足够的信息而获得最差的评价指标。此外,GCN-Text-d的性能比HRPC差,这表明简单拼接两个网络结构表征无法有效学习节点在多网络下的表征。同样,AM-GCN-Text的性能也弱于HRPC,这表明通过学习标签的共现关系可以达到更好的分类效果。综上所述,HRPC的性能优于所选取的基准算法。
4.4 参数敏感性实验
为了探究数据集中不同训练比例的训练数据对HRPC实验性能的影响,本文随机抽取20%、30%、40%、50%、60%、70%和80%的专利数据集作为训练集,其余的作为测试集。在实验中,选择以下三个指标评估模型的性能,Precision@1、Recall@5和NDCG@5。实验结果如图2所示,随着训练比例的增加,HRPC的相关评价指标得到快速提升,当训练比例达到80%时,HRPC的分类性能最高。表明增加训练样本时,模型可以学习更加充分的先验数据分布,得到更好的分类效果。
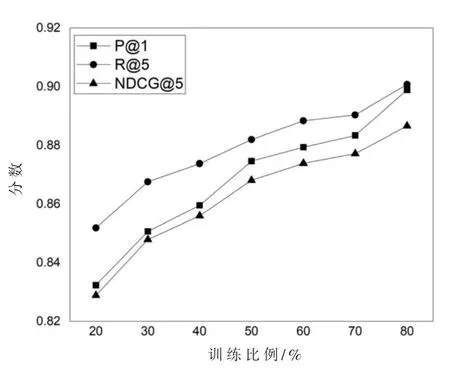
图2 不同比例的训练数据对专利分类性能的影响
为了探究关联实体的置信度阈值对模型性能的影响,本文针对置信度阈值的多个取值进行实验。测试获取实体链接的置信度阈值ε分别取不同值时对专利分类性能的影响。当阈值ε取较小值时,可以通过TAGME工具获得较多的关联实体,然而当阈值ε取较大值时,仅能得到较少的关联实体。实验结果如图3所示,随着阈值ε的增长,NDCG@1、NDCG@3和NDCG@5均是先上升然后下降。这是因为阈值ε较小时,提取了较多的实体单词,其中包括与专利主题相关度较低的实体,增加了过多的噪音信息,干扰模型的训练。随着阈值ε的增加,过滤掉部分无关实体,降低了噪音实体带来的负面影响,使得HRPC的性能得到提升。随着阈值ε的继续增加,过滤噪音实体的同时,也过滤掉了过多的有效实体,使得HRPC无法有效学习实体信息,导致模型的性能受到抑制。最终置信度阈值ε取值为0.15。
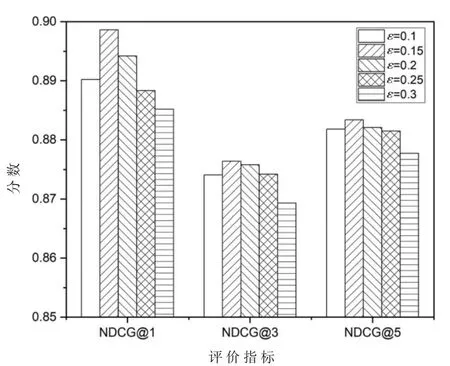
图3 置信度阈值ε对实验性能的影响
为了探究一致性约束项和差异性约束项对模型性能的影响,本文针对不同的取值范围进行实验。λ1和λ2分别表示一致性约束和差异性约束的程度,其中λ1的取值变化范围是1×10-6~1×10-1,λ2的取值变化范围是1×10-10~1×10-5,实验结果如图4所示。如图4(a)所示,随着λ1的增大,NDCG指标均先上升后快速下降,当λ1取值为1×10-4时,模型达到最佳性能。如图4(b)所示,与λ1相似,随着λ2的增大,NDCG指标先缓慢上升后快速下降,当λ2取值为1×10-7时,模型取得最优结果。综上所述,当λ1取值为1×10-4,λ2取值为1×10-7时模型性能达到最优。
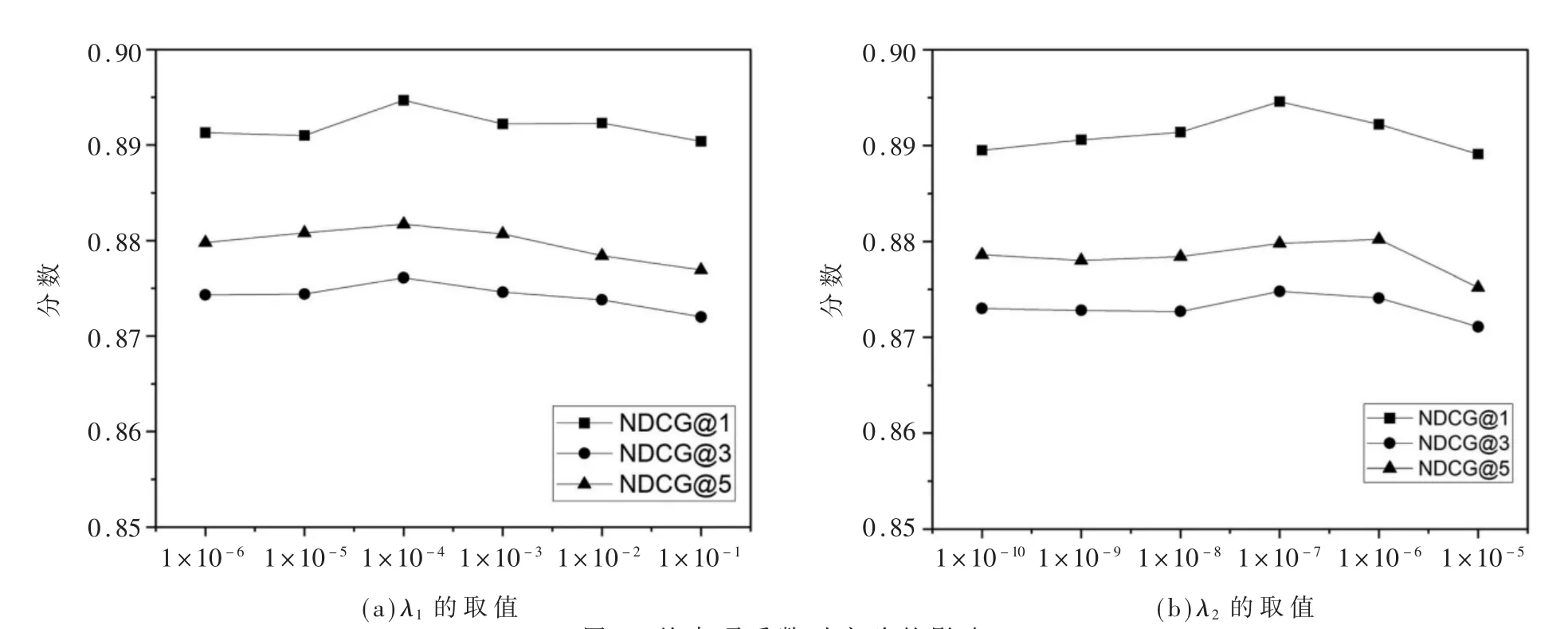
图4 约束项系数对实验的影响
5 结论
本文提出了一种基于混合表征的专利分类框架,该框架同时学习专利的文本信息和网络结构信息,然后和标签向量相乘计算专利属于每一个标签的概率。进一步,本文使用图卷积神经网络在标签共现网络上学习标签的表征,使模型在计算专利的标签概率时,可以融入标签之间的共现信息,提高模型预测专利标签的准确性。实验结果表明,本文提出的融合专利文本信息和网络信息的混合表征保留了更加丰富的专利信息,在专利分类任务中取得了较高的准确性。下一步的研究目标是挖掘更加有效的专利信息,进一步提高专利分类的准确性。
