基于ARM和深度学习的智能行人预警系统
2022-01-05刘佳丽黄世震何恩德
刘佳丽,黄世震,,何恩德
(1.福州大学 物理与信息工程学院,福建 福州350116;2.福州大学 微电子集成电路重点实验室,福建 福州350002)
0 引言
交通安全问题已成为当前亟待解决的社会问题之一,尤其在交通环境下很多行人的注意力因集中在智能手机上而不注意周围是否有车辆威胁自身安全,往往造成悲剧的发生,故如何降低该类交通事故的发生率已成为急需要考虑的问题。
HOG(Histogram of Oriented Gradient)提出被检测的目标轮廓能够被光强梯度和边缘分布描述,SVM(Support Vector Machines)为二分类模型并可进行回归分析,通过将两种方法结合,使用HOG方法检测目标物体的边缘信息并提取特征SVM方法对目标物体区域进行筛选[1]实现了道路行人的检测;当今目标检测算法蓬勃发展,文献[2]中提出了一种基于改进的YOLOV3检测算法大大提高了对行人检测的精度并通过降低算法的复杂性和简化模型解决了长距离和小体积物体难以检测到的问题;文献[3]中提出了一种依据上下文信息和行人高宽比的特点改进的SSD行人检测方法,通过改进模型的整体框架和纵横比,生成浅层语义特征信息和深层语义特征信息以检测目标行人,提高了检测精度;HOG+SVM方法虽然能成功进行行人检测,但是对遮挡物体检测准确率极低以及不能完成对目标车辆的检测;基于YOLOV3网络模型检测的准确率很高,但是检测速度慢,不能达到实时性检测的要求;SSD属于轻量级检测模型,对于较大目标的检测可以满足要求,但对小目标物体(如较远处的车辆)的检测精度低且速度慢。
近年来,随着计算机图形处理器计算性能的不断提升和计算机视觉物体检测新算法的不断涌现[4],为交通场景中的行人以及车辆检测提供了技术支持。文献[5]中提出使用HOG提取目标物体的边缘与SVM技术对训练模型进行二分类相结合的方法,该模型使用大量数据测试后得出该方法使检测速度与检测精度综合提升,在行人检测问题的处理中实现了重大突破。随着目标检测算法的快速发展,逐渐将行人车辆的检测与目标检测结合。现阶段的目标检测有两类方法:一类是两阶段的目标检测模型,代表为R-CNN模型,首先生成可能包含目标物体的候选框,然后再使用卷积操作对候选框中的目标物体进行分类[6];另一类为一阶段模型,代表为YOLO系列和SSD系列,利用回归的处理方式对目标物体进行检测,即该神经网络模型对输入图像进行一次前向计算,预测出全部目标物体的位置类别以及置信度。文献[7]中提出了Fast R-CNN神经网络模型,在R-CNN的基础上Fast R-CNN引入了与SSPnet相同的池化方法,以区域推荐和特征提取作为模块设计并以PASCAL VOC作为数据集进行训练。与HOG+SVM方法对比,平均检测精度(Mean Average Precision,MAP)由35.1%提升至53.7%;YOLO系 列 模 型 从YOLOV1发 展 到 了YOLOV5。YOLOV1[8]基于GoogleNet的基本架构采用24个卷积操作最后连接两个全连接层作为模型的检测头,使用98个 边 界 框(bounding boxes,bbox)预测7×7个目标物体。YOLOV1虽然检测速度较快,但相比于其他目标检测模型检测精度并不高。YOLOV2[9]基于darknet网络框架,将YOLOV1的7×7的卷积结构优化为3×3和1×1的深度可分离卷积结构,使提取特征更加精确同时提高了模型的非线性。为了解决YOLOV1的检测精度的问题,引入了R-CNN模型的锚框概念并采用定位预测的方法大大提高了网络性能和精度,缺点在小目标物体的检测中YOLOV2的检测精度很低。YOLOV3[10]是基于darknet 53的模型框架并将池化层更改为下采样层的方法以减少特征的损失。下采样层分为了三个分支分别预测大、中、小目标物体,检测精度和速度有了明显的提升。在本文提出的行人车辆检测系统中必须满足两点要求:(1)检测精度高并且检测速度快,满足实时性检测的需求;(2)能够为轻量级的网络模型部署至开发板。为了解决上述问题:(1)采用单目摄像头人工采集的数据集进行标注并分析;(2)对目标检测神经网络模型进行分析优化训练并部署至NCNN平台进行测试,根据评估标准选择更适用于该系统的网络模型;(3)将模型移植至开发板对道路车辆以及行人进行实时性的识别,对车辆进行测速并对人行道上的行人进行实时安全警告。
1 YOLO-fastest算法原理
YOLO-fastest模型以darknet为基本框架,是轻量级通用目标检测算法YOLO的改进版,具有模型小、检测速度快与易于部署等优点,能够用PyTorch、TensorFlow、Keras、Caffe等 机 器 学 习 库 实 现。构 成 该模型的基本结构由“卷积+归一化+Leaky激活函数”组成。主干网络部分由74个卷积层构成并且采用随机丢弃和张量相加对特征图进行处理。检测头包括分类、回归和检测。下采样层分别为16倍下采样和32倍下采样,通过调整感受野故对不同尺寸目标物体的识别结果较精确。最终的输出为感受野较大的10×10×75尺寸预测大目标的物体和感受野较小的20×20×75尺寸预测小目标的物体。
1.1 深度可分离卷积
深度可分离卷积是将标准卷积拆解为深度卷积和逐点卷积在计算的过程。传统的卷积结构在每次的卷积操作都会考虑到所有通道使参数量大大增加,故使用深度可分离卷积操作解决该问题。先对每一通道的区域进行卷积计算,再进行通道间的信息交互,实现了通道内卷积和通道间卷积完全分离[11]。YOLO-fastest网络引入深度可分离卷积操作减少模型参数量,增加了网络深度,能更好地对特征进行提取,极大降低了模型参数量以及计算量,从而提高检测速率[2]。
1.2 反残差结构
深度残差结构为何凯明等人在文献[11]中提出的基本网络结构,该网络全部采用相同大小的卷积核使用卷积步长取代池化,全连接层替换成平均池化层减少了参数量,解决梯度消失问题并加深了网络结构[12]。在YOLO-fastest模型中由于使用了大量的深度可分离卷积结构使网络参数减少。故将反残差结构引入到YOLO-fastest模型中即在深度分离卷积之前添加一层1×1卷积结构,因此解除了深度分离卷积对网络模型的限制。
2 实验设计
为了确保该系统的性能更好、检测精度更高,故对学校门口人流量密集的地区采集真实交通环境下道路车辆以及行人图片,并进行人工标注。分别对主流的目标检测模型YOLOV3、YOLO-fastest、YOLOV4-tiny、MobilenetV3-ssd进行实验对比与分析评估,完成模型剪枝、微调以及优化。采用标注和分析完成的数据集对以上神经网络模型进行训练,将训练完成的网络模型转换为NCNN模型并进行模型量化处理以及部署至NCNN平台,最后将模型部署至Atlas200 DK开发板进行实时检测。
2.1 数据集
2.1.1 数据集采集
目标检测的结果与数据集的准确性密切相关,若数据集的精度较低或者噪声干扰较多将造成检测结果准确率低,并影响系统的整体性能。该实验采用的数据集为普通单目摄像头采集白天光线较好的交通场景图像,标注类别分为三类:行人、机动车、非机动车。其中汽车、卡车、公交车等较大型车辆分类为机动车,摩托、电动车等为非机动车,在人行道以及其两侧的人为行人,并采用labling进行标注并对数据集进行分析。本文共使用了1 500张交通图片,测试集随机选择150张,训练集为1 350张。
2.1.2 数据集分析
对数据集中每一类别的目标框个数进行分析,其中标签分别为Vehicle、Non-Motor Vehicle、pedestrian的目标框个数占比如图1所示。在数据集标注文件中的bbox的格式为(xmin,ymin,xmax,ymax),其中(xmin,ymin)表示目标左上角坐标以及(xmax,ymax)表示右下角坐标。对bbox的高宽比进行可视化分析,结果如图2所示,高宽比在0.3~0.5范围内的目标为行人类别,在0.5~1.3范围内的目标为非机动车类别,在1.3~4.0范围内的目标为机动车类别。
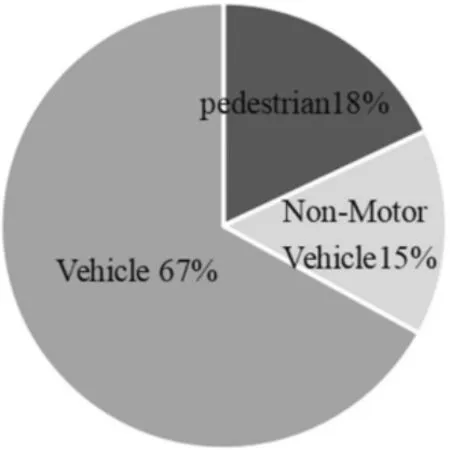
图1 目标框个数分析
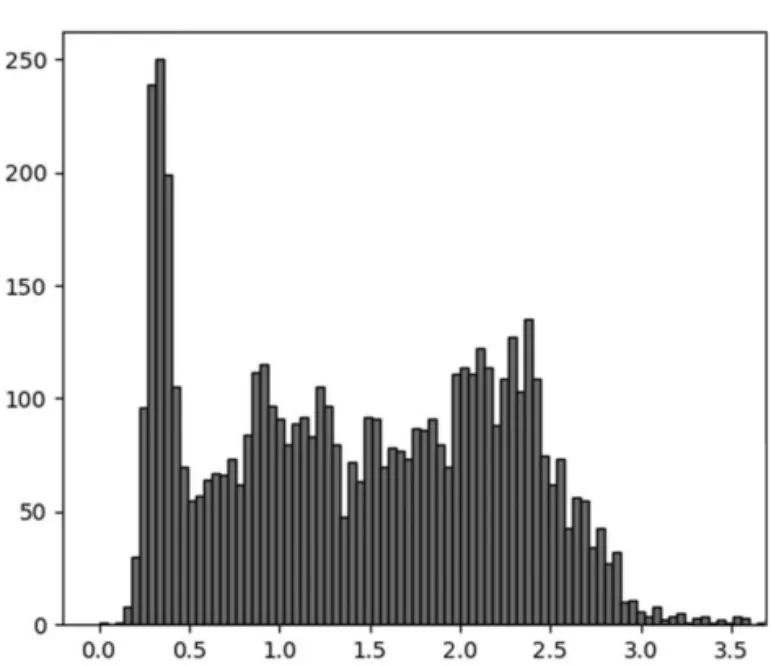
图2 bbox高宽比分析
2.2 速度检测
本文旨在通过目标检测算法识别交通场景的行人以及车辆,从而对斑马线上的行人进行安全提醒,当车辆的速度高于设定速度阈值时,显示危险信号以提醒行人注意安全。在完成目标检测的基础上,对目标车辆进行定位测速以及安全警告。本文采用文献[13]中的方案对视频车辆测速。
(1)通过目标检测的网络模型得到目标物体的中心坐标,则两帧视频间隔时间内目标车辆行驶的距离为式(1):

其中,xi为t时刻的目标物体的坐标,Δt为两帧之间的时间间隔,检测示意图见图3。xi(t-Δt)为上一帧目标物体的坐标,检测示意图见图4。

图3 t-Δt时刻检测图

图4 t时刻检测图
(2)通过进行相机标定获得映射矩阵,将摄像头捕捉到的车辆两帧之间行驶的距离转换为实际距离Ti。相机标定示意图如图5所示,映射矩阵见
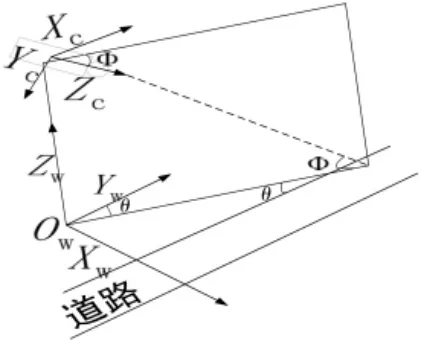
图5 相机标定示意图
式(2)。h为摄像头距地面的高度,Oc为相机坐标系,OW为真实世界坐标系,φ为道路平面与Zc轴的夹角,θ代ZWOWZc构成的平面与YW轴的夹角。
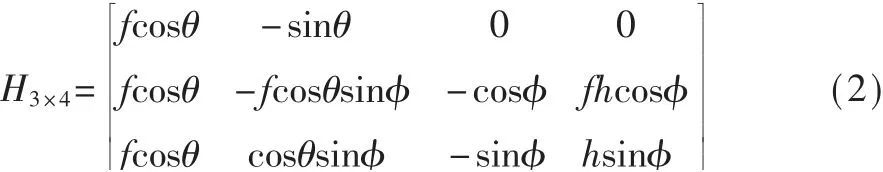
(3)最终计算实际速度见式(3)。

3 实验
本文训练以及实验环境的详细设置如下:CUDA版本为10.2,CUDNN版本为9.0,CPU配置为R7-4800H,开发板为Atlas200 DK,软件环境为Ununtu18.04,显卡配置为NVIDIAGTX-1650Ti,PyTorch版本为1.6.0。开发板实物图见图6。

图6 Atlas200 DK实物图
3.1 训练参数设置
分别对YOLO-fastest、YOLOV4-tiny、YOLOV3、Mobil enetV3-ssd进 行 训 练。YOLO-fastest在 训 练 过程中对部分参数进行调整以达到更好的训练结果。输入图片像素为320×320×3,并对其进行图像增强,饱和度与曝光变化分别设置为1.5和1.5,色调变化范围为0.1。每次迭代基于饱和度、曝光、色调产生新的训练图片。初始学习率设置为0.001,根据训练进程减小至0.000 1使损失函数更好地收敛,权值衰减设置为0.005以避免过拟合。YOLOV4-tiny、YOLOV3、MobilenetV3-ssd的输入图片像素为416×416×3、416×416×3、300×300×3,其他设置与YOLOfastest一致。
3.2 实验结果
将训练完成的YOLOV4-tiny、YOLOV3、MobilenetV3-ssd,YOLO-fastest神经网络模型分别部署至开发板上进行实时检测,以检测速度、MAP与模型大小作为评估标准。最终选择的神经网络模型既要满足检测精度的要求又满足检测速度的要求,能够完成对交通场景下的实时性行人车辆检测并提醒行人危险的到来。从表1中可以观察到YOLO-fastest的平均检测精度为96.1%,检测速度为33 f/s,模型大小为1.2 MB。MobilenetV3-ssd同样是轻量级神经网络模型,检测精度相当,但检测速度为6 f/s,明显慢于YOLO-fastest,并且模型大小为10.2 MB,也要大于YOLO-fastest,与YOLOV4-tiny和YOLOV3相比,虽然平均检测精度相对较低,但也满足该系统对检测精度的要求,检测速度有了很大的提升,模型大小也远远小于其他两种模型,完全达到了对实时性和轻量型的要求。检测原图与效果图对比如图7、图8所示。

图7 待检测原图

图8 YOLO-fastest检测效果图
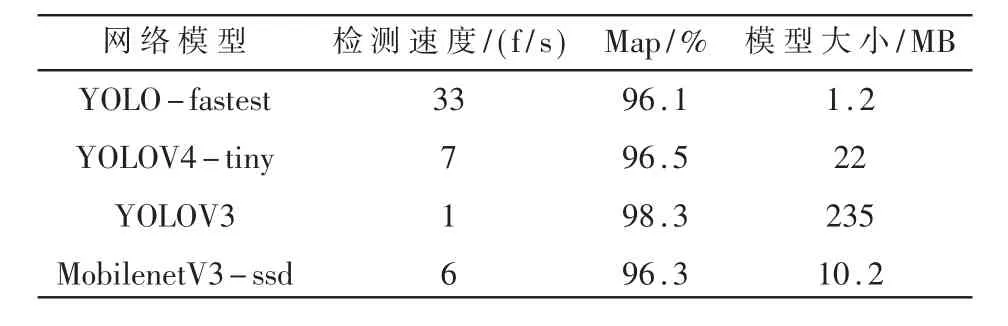
表1 网络模型性能对比
4 结论
该实验提出的智能行人预警系统分析并对比了主流的目标检测算法,选取了更轻量、检测速度更快的YOLO-fastest模型并将其部署至NCNN平台上,最终移植至开发板实现实时性检测并回馈给行人危险信号,平均精度为96.1%,检测速度达到33 f/s。
该文虽然做到了实时性的行人检测,但未充分考虑到天气的影响,如阴天、雨天、雾天等极端天气造成检测的准确率降低的情况,将考虑使用迁移学习的神经网络模型对该极端情况进行处理,迁移学习可以很好地解决雨天数据集难以采集的问题。
