基于LUT的多目机场视频实时拼接算法设计与实现
2022-01-05张兴超陈贤富
张兴超,陈贤富
(中国科学技术大学 微电子学院,安徽 合肥230027)
0 引言
全景图像拼接,指把几幅彼此之间有重叠区域的图像拼接成一幅视角更广、信息更全面的图像。而全景视频拼接,指对多路读入视频的每一帧进行全景拼接,得到一个新的全景视频。读入视频为实时视频流,拼接得到实时的全景视频流,即为实时全景视频拼接。实时全景视频拼接技术的应用十分广泛,可运用于视频监控、实时直播、视频会议等领域。本文的研究对象为机场监控的多目实时视频拼接。
全景实时视频拼接可以采用硬件方法,也可采用软件方法。硬件方法是指使用专门的拍摄设备实现全景拍摄,例如鱼眼摄像机、超宽视角的广角镜头等。采用硬件方法,可以满足实时性、图像质量等要求,但由于需要使用专门的硬件设备,成本较高。软件方法指通过算法、程序来实现全景视频拼接系统。采用此种方法,只要算法性能足够优良,就可以使用常规的硬件平台实现全景实时视频合成的目标,而不需要依赖昂贵的硬件设备。因此,软件方法成本相对较低。本文就是用软件方法实现8路960×540实时视频流的全景实时拼接。
本文采用的方法,其读入的视频,是机场跑道一侧8台摄像机采集的实时视频流。8台摄像机位于机场飞机跑道的同一侧,大致覆盖180°的视野范围。8台摄像机的位置是固定不变的,所以全景画面到每一路图像的像素映射关系也是固定的。本文采用拼接方法的总体思路如下:(1)使用现有的全景图片拼接软件拼接采集到的8个视频帧,得到一幅全景图;(2)图像配准,即找出全景图与8幅原图之间的像素坐标映射关系,并将此映射关系存成查找表(Look Up Table,LUT);(3)通过LUT完成每一帧的实时拼接,包括重叠区域的融合;(4)全景视频每一帧的显示和存储。实验结果表明,本文采用的方法可实现8路视频的实时全景拼接,并且能够实时显示、存储拼接后的全景视频。
1 相关工作
在已有相关研究中,文献[1]提出一种基于特征的全景视图生成算法,该算法能够适应视差较大的情况,而无实时性要求;文献[2]研究出一种移动设备视频全景并行生成技术,该技术利用OpenMP并行加速,提高了视频全景的合成速度,但所处理的是拍摄好的视频而非实时视频流;文献[3]提出一种并行实现图像配准和拼接的技术,该技术使用OpenMP多核并行加速,可实现2路320×240视频信号的实时拼接,达到35 f/s的实时处理要求;文献[4]研究出一种基于CUDA的全景图生成技术;文献[5]提出一种实时全景拼接算法,通过多数据流和GPU加速,实现了3路分辨率640×480、帧率30 f/s的视频信号的自动配准和实时全景拼接;文献[6]研究出一种基于GPU加速的实时4K全景视频拼接技术,可对6路2K视频进行实时拼接,得到4K输出视频。上面提到的几种方法都使用了GPU加速,实际上均对硬件平台有一定的要求。2020年,北方自动控制技术研究所的强勇勇等人研究出一种基于局部多层次特征的嵌入式视频全景拼接技术[7],该技术使用查找表方法和最佳拼接线查找法,实现了2路1 000×750分辨率、30 f/s帧率视频的实时全景拼接。
在国外,2007年,Brown等人在尺度不变特征转换(Scale-Invariant Feature Transform,SIFT)算法提出之后[8],研究出一种基于SIFT算法的全景图片合成算法[9],该算法用于全景图片拼接,对实时性无要求;2013年,Termoe等人研究出一种基于多模块化编程的全景视频处理技术[10],该技术使用GPU加速,可完成4路1 280×960分辨率、30 f/s视频信号的实时合成;2020年,Meng等人研究出一种基于非对称双向光流的高质量全景图拼接技术[11],该技术采用了鱼眼摄像机采集输入图像信号,远景与近景拍摄的图像信号皆能处理。
本文提出的全景视频实时拼接方法,读入视频为8路960×540分辨率、25 f/s帧率的实时视频流,采用SIFT算法进行特征点匹配以实现图像配准,采用LUT方法和OpenMP加速以实现实时拼接。相邻两路图像间的过渡区域融合,本文使用线性融合法。输出的全景视频分辨率为3 636×932,帧率为25 f/s。平均每一帧视频的读取、拼接、显示、存储整个过程的耗时小于40 ms,基本满足实时性要求。本文所使用的方法,可在使用常规硬件平台(不需要使用专门的拍摄设备,亦不需要使用GPU加速)的条件下完成8路960×540分辨率、25 f/s视频流的实时拼接。
2 算法设计
2.1 图像配准
如前所述,实现视频实时拼接,首先要完成图像配准。图像配准,指找出全景图与原图之间的像素坐标映射关系。本次实验中,8台摄像机的位置全程都是固定不变的,因此图像配准过程只需要做一次,并且可以离线完成,对时间复杂度不作要求,配准结果足够准确即可。完成配准过程之后,就可以利用找出的映射关系,实现视频的实时拼接。
图像配准分为以下步骤:特征点匹配、计算单应矩阵(原图到全景图的像素坐标变换矩阵)、构建LUT表。下面分别对这三个步骤进行阐述。
2.1.1 特征点匹配
要找出全景图和原图间的像素映射关系,首先需要在全景图和原图中找出足够数量的特征点,并找出特征点之间的匹配关系。通过特征点匹配对,可以计算每幅原图到全景图的像素坐标变换矩阵(即8个单应矩阵),从而得到8幅原图中所有像素点与全景图中像素点的映射关系。
常用的特征点匹配算法有尺度不变特征变换(Scale-Invariant Feature Transform,SIFT)算法[8,12]、加速稳健特征(Speeded Up Robust Features,SURF)算法[13]和Oriented FAST and Rotated BRIEF(ORB)算法[14]。其中,SIFT算法时间复杂度最高,但可以找出最多的特征点匹配对,匹配结果最准确;SURF算法是SIFT算法的改良加强版,时间复杂度低于SIFT算法,但找出的特征点匹配对数量少于SIFT算法;ORB算法原理较简单,速度较快,但能找到的匹配点数量较SIFT、SURF少。
由于本次实验对图像配准的时间复杂度不作要求,且需要配准结果尽可能准确,本文采用SIFT算法进行特征点匹配。首先,获取8路视频的各一帧,并使用Panorama Studio软件对这8个图片进行拼接,得到一幅全景图片。然后,使用SIFT算法分别找出8幅原图和全景图片之间的特征点匹配对。Panorama Studio软 件 拼 接8幅960×540图 片 需2~3 s的时间。SIFT算法使用OpenCV中的库函数实现。图1为Panorama Studio得到的全景图与原图1之间的特征点匹配示意图。为确保特征点匹配的准确程度,在与原图1进行特征点匹配时,全景图只保留了原图1大致对应的区域(图1中左侧画面即为保留的全景图区域,右侧画面为原图1)。8幅原图都采用此种方法完成特征点匹配。
2.1.2 计算单应矩阵
单应矩阵即像素坐标映射矩阵,其描述两图像之间的像素坐标映射变换。平面的单应性被定义为从一个平面到另一个平面的投影映射。描述这样变换关系的矩阵,就叫单应矩阵。它是一个3×3浮点数矩阵。8台摄像机分别位于不同位置,摄像头的角度各不相同,因此8幅原图到全景图的映射变换属于透视变换。
令原图中一像素点的坐标为(x,y),变换到全景图后坐标为(x′,y′),单应矩阵为:

则(x,y)与(x′,y′)的变换关系为:

可以发现,单应矩阵H乘以任意非0值,最终得到的变换后坐标值都是不变的。因此可令h33恒为1,仅需计算另8个元素的值,即可得到有效的单应矩阵。
理论上,只需要知道4个不共线的原图点坐标以及它们各自变换后的坐标,即可算出一组单应矩阵元素的值。然而本文需要找出的是整幅原图变换到全景图的单应矩阵,要求计算出的单应矩阵适用于原图中所有的像素点,因此,只用4个匹配点对计算单应矩阵,并不能够得出适用于整幅原图的单应矩阵。所以,计算单应矩阵,本文采用随机抽样一致算法(RANdom SAmple Consensus,RANSAC)[15],用OpenCV中的findHomography()函数实现。
2.1.3 构 造LUT表
如果拼接每一帧都对8幅原图(视频帧)中的像素点和单应矩阵作相乘运算,则时间开销较大,无法满足实时性要求。故本文采用LUT表方法实现实时拼接。具体方法如下:首先构造一个二维矩阵(称之为矩阵M),其行列数与全景图相同,矩阵中的元素为像素点的地址信息;然后,通过单应矩阵进行逆变换运算,得到全景图上每个点对应于原图中的点;之后,将此原图点的地址存放在矩阵M的相应位置。比如,如果总合成图中第1行第1列的点对应于第1幅原图的第2行第3列点,那么就将第1幅原图第2行第3列这个点的地址存放在矩阵M的 第1行 第1列。
通过单应矩阵进行矩阵逆变换运算的原理如 下:如2.1.2节 所 述,变 换 之 后 的 点 坐 标 可以用变换前的原坐标与单应矩阵中的元素表示出来,那么,变换前的原坐标也能够用单应矩阵中的元素和变换后坐标表示。由式(2)~式(4)可得:
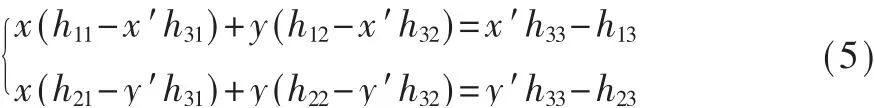
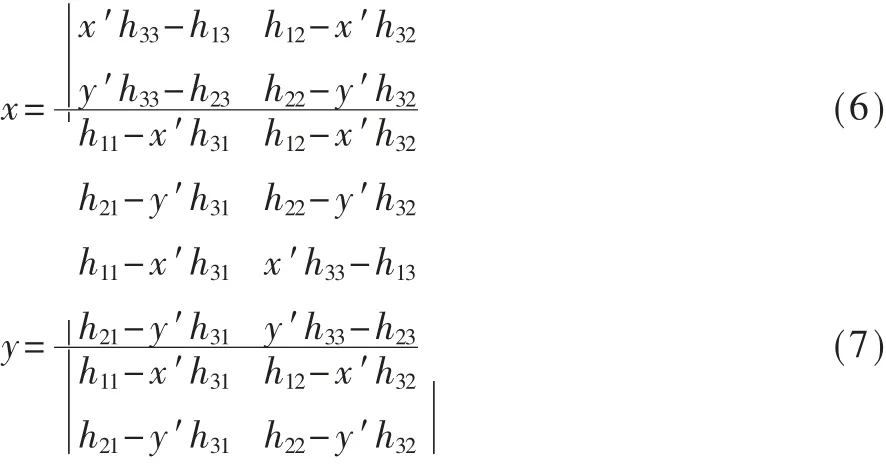
在得到8幅原图映射到全景图的单应矩阵之后,首先用合成图中所有点同原图1的单应矩阵进行逆运算。如果合成图中的某一个点是从原图1变换得到的,那么它逆变换得到的横坐标值x取值必然大于0小于原图1的宽,纵坐标y取值大于0小于原图1的高。逆变换后x,y的取值不在此范围内的点就不是原图1变换得到的。然后再把原图1中点的地址填在矩阵M的相应位置。
完成原图1单应矩阵逆变换、找出由原图1变换得到的区域之后,依此类推,按顺序分别找出原图2~8变换到合成图的区域,并将原图中相应点的地址填在矩阵M的相应位置。
对于重叠区域则采取以下方式处理:再构建7个二维矩阵(称之为m1~m7),分别对应7个重叠区域。按上文所述方法,原图2中点的地址填充到矩阵M中后,会覆盖原图1重叠区域部分点的地址。所以将原图1重叠区域点的地址信息从矩阵M中复制到矩阵m1中,再把原图2的像素地址填在矩阵M中。对其他6个重叠区域,采用同样的方法处理。LUT表示意图如图2所示。
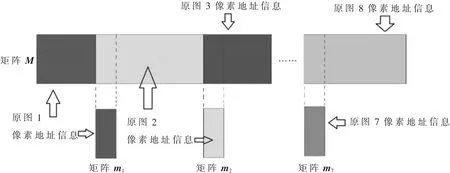
图2 LUT表示意图
2.2 实时拼接
2.2.1 基于LUT表的图像拼接
非重叠区域只需要通过LUT表(即矩阵M),按照地址映射关系,把原图(即读入的每一帧图像)中像素点的值复制到全景图对应位置即可。
重叠区域采用线性融合方法。如前所述,对于每一个重叠区域,左侧原图的像素地址信息存放在矩阵mi(i=1,2,…,7)中,右侧原图像素地址信息存放在矩阵M中。所以,使用左图像素权重线性递减、右图像素权重线性递增的方法,对重叠区域进行融合,得到重叠区域的像素值。
2.2.2 使用OpenMP多核并行方法对拼接过程进行加速
直接使用上文所述基于LUT表的图像拼接法,拼接一帧图像花费的时间就达到了40 ms以上,并不能满足8路960×540分辨率25 f/s视频信号的实时拼接。而多核CPU目前已广泛使用,所以本文采用OpenMP多核并行,对拼接每一帧图像的过程进行加速,以满足实时性要求。
2.3 全景视频的实时显示与存储
实时全景视频的显示和存储的时间代价较小,使用OpenCV库函数即可。其具体耗时将在后面的实验结果部分展示。
3 实验结果分析
本次实验的输入信号为索尼SNC网络摄像机采集的8路960×540实时视频流,主机处理器为因特尔Core i5-8500六核处理器,软件环境为Windows10+Microsoft Visual Studio2013+OpenCV2.4.11,编程语言为C++。读入500帧数据进行拼接、存储和显示,并记录每一帧的读取、拼接、显示、存储耗时和平均每一帧的各个步骤耗时。表1展示了平均每一帧的读取、拼接、显示、存储每个步骤的耗时,以及处理一帧图像总耗时的平均值。

表1 程序运行时间
平均每一帧的拼接时间为14.725 ms,总处理时间只需37.092 ms,基本满足实时性要求。
拼接得到的全景画面(分辨率3 636×932)如图3所示。画面无明显的畸变和拼缝痕迹,也未出现明显的鬼影。

图3 使用本文方法拼接得到的全景画面
4 结论
本文研究了一种基于LUT查找表技术的多目全景视频实时拼接技术。采用先离线匹配再构建LUT表的方法,解决摄像机位置固定不变情况下的视频全景实时拼接问题;但直接采用LUT法拼接8路960×540视频,仍然无法满足实时性要求,因此采用了OpenMP多核并行加速。实验结果表明,本文采用方法基本满足实时性要求,且画面无明显畸变。而如何实现更高帧率和分辨率视频信号的实时拼接,如何实现图像自动配准,以及多路视频信号色差的处理等问题,还有待进一步研究。
