铁路客运旅客群体划分算法的研究
2022-01-04郝晓培单杏花王炜炜
郝晓培,单杏花,王炜炜
(1. 中国铁道科学研究院 研究生部,北京 100081;2. 中国铁道科学研究院集团有限公司 电子计算技术研究所,北京 100081)
在高速铁路线路建设及运营初期,巨大的建设成本导致其主要依靠政府补贴维持运营。2013年3月,随着原中华人民共和国铁道部实行政企分开,高速铁路运营模式出现了新的变化,市场化运营崭露头角;2015年底,中华人民共和国国家发展和改革委员会规定,2016年1月1日起,铁路部门可基于运输市场竞争状况、服务设施条件差异、客流分布变化规律、旅客承受能力和需求特点等,自主制定时速200 km以上的高速铁路动车组列车票价;2018年12月,原中国铁路总公司更名为中国国家铁路集团有限公司,从全民所有制改为公司制,以更加市场化的方式,灵活参与客运市场竞争。基于市场特点、服务设备条件差异、客流分布变化规律、旅客承受能力及铁路网特点等进行自主定价,使其更灵活、更市场化[1]。
铁路旅客需求的多样化趋势促使铁路部门将服务模式从政策驱动型逐渐转变为市场驱动型及客户驱动型。交通行业竞争的焦点已转移到细分旅客市场、提高服务质量、维系客户关系上。近几年铁路客运已构建了完善的用户画像及产品画像[2],为旅客群体划分提供了数据基础。客户群体划分是指,根据一个或多个属性将客户划分到不同的群组,同一群组下的客户相似度较高,不同群组的客户差异较大。通过将客户分到正确的类别,对现有及预期客户作截面分析,针对不同截面提取显著特征,即可对客户构成较准确的认识,使服务和营销定位更加精确。
1 旅客群体划分算法概述
旅客群体划分常用算法有:经验描述法、聚类算法、决策树法、RFM(Recency-Frequency-Monetary)分析法[3]等。可根据应用场景、业务数据特点及业务功能选择适合的算法。
(1)经验描述法基于专家意见进行特征选取及特征值范围划分,适用于业务简单、特征较少的服务场景。
(2)聚类算法可基于铁路客运用户画像系统发现不同的旅客群组,找到不同群组的特征,从而解决旅客分类问题。
(3)决策树法根据构建的用户特征,利用信息增益,选择最优特征及分割点,从而实现旅客自动化分群。适用于人群特征维度低、特征取值多的场景。
(4)RFM分析法计算用户的最近一次消费时间、消费频率、消费金额等,并为每个特征设定阈值,基于3个特征高于阈值和低于阈值的限定,将群体分成8类,主要用于快消品的群体分析。
铁路客运旅客数据作为一种典型的数据源,包含了大量的旅客购票及出行行为数据,通过使用统计学、机器学习等方式构建完善的用户画像系统;铁路客运旅客数据也包含了海量的社交网络数据,即同行关系及购票关系,为铁路旅客群体划分提供了重要的数据支撑。因此,需引入社交网络对用户画像特征进行修正和完善,提高聚类效果。
2 旅客群体划分算法设计
本文在铁路客运用户画像系统的基础上,构建特征处理,社交网络特征传播,群体聚类3个模块对铁路客运旅客群体进行划分,如图1所示。

图1 算法设计
2.1 特征处理
特征处理是指对结构化及非结构化的原始数据进行处理和加工,将杂乱的数据通过计算、组合、转换等方法转化为特征数据,并使用主成分分析等方法对特征数据进行选择的过程,主要方法如下。
(1)数据清洗
发现并修正原始数据中存在的可识别的错误,主要包括缺失值处理[4]和异常值检测及处理。
(2)数据规范化
在用机器学习对模型进行训练的过程中,样本数据包含数值型、枚举型等。为得到性能更优的模型,需要对不同类型的特征进行处理,主要操作包括数据无量纲化及连续变量离散化。
(3)特征衍生与提取
模型构建过程中,需要从现有的特征中构造一些特征。针对特征过多的样本,为降低模型复杂度,防止过拟合,需要进行降维处理,主要包括特征衍生及特征提取。
2.2 社交网络特征传播
2.2.1 社交网络概述
目前,铁路部分旅客出行频次较低,统计类特征不完善,存在一定量的特征缺失,需要采用策略对其进行完善。本文主要采用社交网络特征传播的方式进行特征优化,利用其邻居节点的特征及权重,对其自身特征进行完善。在旅客社交网络中,旅客不再是用户画像特征的信息载体,其个体与其他旅客之间的购票关系及同行关系对整个铁路客运社交网络中的信息产生、特征演化、知识传播过程发挥着重要作用。本文在旅客特征的基础上,将旅客关系网络与相邻节点的旅客特征信息交互融合,对旅客特征进行完善。
社交网络G(V,L) 作为网络的一种,由节点与连接节点的边组成,节点集合为节点总数;边的集合为边的总数;li连 接的节点属于节点集合V,其社交特征传播规律也与复杂网络理论研究的基本规律相同。
2.2.2 社交网络算法
为完善铁路旅客特征值,本文主要从网络视角对旅客特征进行迭代更新,根据铁路旅客间的同行关系、购票关系等构建网络结构,模拟PageRank[5]算法的随机跳转思路,对网络中的旅客节点特征进行迭代运算,直至数值稳定为止。
基于PageRank算法原理,特征传播过程主要分为3个阶段。
(1)网络初始阶段:旅客作为网络节点,旅客之间的购票关系及同行关系形成网络的连接,网络连接的权重定义为购票次数及同行关系次数,图2是以4个节点为例的关系网络。

图2 以4个节点为例的关系网络
(2)特征初始阶段:基于特征处理生成的旅客特征作为网络节点的属性,每个节点与相邻节点的重要性是不同的。本文将相邻节点和该节点购票及出行的总次数与所有相邻节点和该节点购票及出行的总次数的比值作为权重,即:其中 ,fij表示节点i为节点j购票的次数及节点i与节点j同行次数的总和;n代表节点i相邻节点的个数 。Wij越大,说明节点j的特征对节点i的影响力越大。针对每一个特征值,都需要基于网络结构对其进行更新;
(3)特征值更新阶段:针对确定的特征变量,进行迭代运算。每一次计算都将原来的特征值与该节点相邻节点的特征值加权求和并求最大值,作为新的特征值不断迭代,直至特征值趋于稳定。以节点i的特征值xit为例,其计算公式为

2.3 群体聚类
特征处理及社交网络特征传播分别对旅客特征信息进行计算及优化。聚类算法主要基于优化过的特征进行用户群体分类,常用的分类算法有Kmeans算法[6]。该算法原理相对简单,可解释性强,运行速度快,被广泛应用于客户分群、精准营销的业务场景中,取得良好的效果。然而,业务数据的不同会导致K-means算法训练的难度加大,主要体现在聚类中心初始值的选择及相似度度量算法上。为解决K-mean算法存在的问题,本文针对这两方面进行了优化。
2.3.1 初始聚类中心
传统的K-means算法采用随机的策略进行初始聚类中心的选择,选择不当易造成聚类结果波动,陷入局部最小解,也易受到噪音数据的影响,较难发现非球状的样本簇。为解决该问题,本文采用密度指标结合最大最小距离法[7]进行初始聚类中心的选择。
初始聚类中心选择步骤如下
(1)计算所有样本的平均距离dc:

其中,dij代表样本i与j之间的欧式距离。
(2)密度pi表 示落在以样本对象xi为 中心;dc为半径的区域内的样本对象的数量:

(3)计算该样本的最大密度点,将其作为第1个初始聚类中心c1,以解决选取局限性问题。
(4)采用最大最小距离法及密度法选择出其他的初始聚类中心,基于公式din)}(i=1,2,···,n)挑 选样本对象xj, 即xj到样本xi的最大最小距离为disti, 将样本平均距离dc范围内的所有样本点中样本密度值最大的对象作为第2个初始聚类中心c2。不断重复该过程以找到所有的聚类中心,通过该方式选择的初始聚类中心,分布密度高,且较为接近最终的聚类中心,可有效减少聚类过程的迭代次数。
2.3.2 相似度度量算法
传统的K-means算法主要采用欧式距离计算样本相似度,针对样本特征进行统一处理,不区分特征重要性。然而,铁路旅客的不同特征之间的相似度是有差异的。为区别对待旅客样本特征,本文将样本与样本之间的权重距离作为相似度度量依据,基于信息熵来计算特征权重,信息熵较小的赋予较小的权重,反之,则赋予较大的权重[8],权重计算方式如下。
(1)构建样本特征矩阵A:
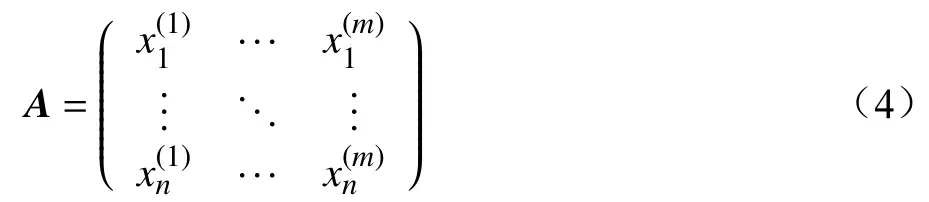
其中,n表示样本个数;m表示特征数;代表第j个样本的第i个特征。

(3)计算特征信息熵H(i):

(4)计算特征维度上的差异系数ri:

(5)计算特征权重wi:

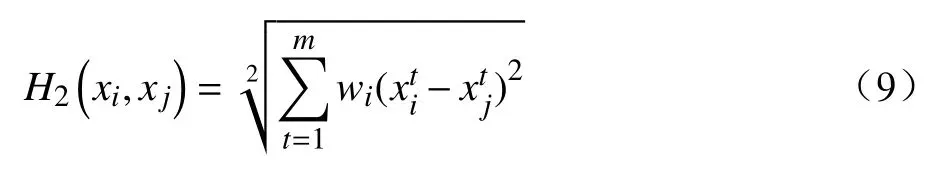
3 实例分析
3.1 特征处理
为验证模型的有效性,本文随机抽取某客运区段、一定时间内、某车次的30 000名旅客的所有出行行为数据(包括非本区段)作为数据集。通过特征处理整理出的数据特征维度包括:出行频次、动车组出行比例、一线及新一线城市出行比例、购买保险比例、打印发票比例、假日出行比例、平均同行人数、高端席别比例等,初始特征统计如表1所示。

表1 初始特征
出行频次及平均同行人数的数据值不在[0,1],需要进行归一化处理。
3.2 特征更新
特征更新策略主要基于PageRank算法思想,根据节点本身的特征及邻节点的特征进行调整,并对调整后的特征进行归一化处理,得到最终的旅客特征。
3.3 聚类
将特征处理及特征更新后的数据通过改进的Kmeans算法进行聚类,得到6个类别,对聚类结果进行处理,得到各类别平均特征值如表2所示,群体比例分布如图3所示。
由表2可知,类别1出行频率较低,且大部分是在节假日出行;类别2与类别1相近,但是其出行一线及新一线城市的比例较高;类别3所有的特征相对均衡;类别4~类别6出行频次相对较高,动车组所占比例较高,且打印发票(报销凭证)比例较高,可以定义为商务出行群体。由图3可知,该车次类别4~类别6群体所占比例接近75%,大部分为商务人群出行,可针对该车次的服务进行相应的策略配置,为票价调整提供决策依据。

图3 群体比例分布

表2 各类别平均特征值
4 结束语
本文通过铁路客运用户画像系统构建旅客特征,同时基于旅客购票关系及同行关系,利用PageRank算法思想优化完善旅客特征,作为旅客群体分类的数据特征;分析了K-means聚类算法存在的缺点,对初始聚类中心节点的选择及相似度度量算法进行了优化,从数据特征及聚类算法优化等方面提高了聚类的准确性及稳定性;对实际的生产数据进行了验证,效果较明显。然而,本文只局限于考虑旅客特征,尚未考虑区段及车次的特征,下一步可将旅客与产品进行相关分析,丰富数据种类,以提高分析效果,作出更精准的营销策略。
