穿梭车仓储系统复合作业路径优化
2021-12-29王姗姗张纪会
王姗姗,张纪会
(1.青岛大学复杂性科学研究所,山东 青岛 266071;2. 山东省工业控制技术重点实验室,山东 青岛 266071)
0 引言
随着电子商务、药品流通、服装和快销品等行业的迅速发展,物品流通呈现出高时效、多品种、小批量的特点,对仓储核心设备的性能提出了更高的要求。穿梭车具有运行速度快、成本低、性能稳定等优点,而且可以与其它自动化立体仓库设备柔性连接起来,在物流仓储系统中得到广泛应用[1]。
穿梭车仓储系统(Shuttle-Based Storage and Retrieval System,SBS/RS)是一种新兴的自动化仓储系统。在该类系统中,位于巷道口的提升机完成垂直方向的移动,巷道内的穿梭车完成水平方向的移动。与传统的堆垛机式自动化立体仓库相比,在性价比、柔性化以及综合成本等方面都更具明显优势[2]。功能各异的穿梭车仓储系统不断开发并成功应用。
国内外学者对不同形式的穿梭车仓储系统进行了研究。针对单层作业的穿梭车仓储系统,Carlo等[3]研究了系统中两个货物提升机的调度问题,并提出了一种新的控制策略。Lerher等[4]考虑穿梭车和提升机的加速度,建立了系统的行程时间模型,该模型可以计算单指令循环和双指令循环的行程时间,从而评估系统的性能。Borovinšek等[5]提出考虑系统吞吐率、总投资成本和能耗的多目标优化模型,利用改进型非支配排序遗传算法求解。杨玮等[6]针对提升机同时可运输两个货物的系统,建立了复合作业路径优化模型,设计了混合植物繁殖算法对模型进行求解。针对穿梭车换层的多层穿梭车仓储系统,方彦军等[7]研究了可跨巷道的四向穿梭车与穿梭车换层提升机搭配的系统,建立了复合作业路径优化模型,设计了改进的人工狼群算法对模型进行求解。于巧玉等[8]研究了双提升机的跨层穿梭车仓储系统,建立了带有出库任务期限的出库任务调度模型,设计了改进的蚁群—粒子群双层智能优化算法对模型进行求解。Azadeh等[9]对近年来自动化立体仓库的新系统进行了综述,总结了前人对不同的穿梭车仓储系统的研究成果,指出许多实际中应用的新系统,需要新的模型和方法来解决。
在模型的求解方面,杨磊等[10]对堆垛机式自动化仓库建立了基于指派问题的复合作业路径优化模型,并用匈牙利法进行求解,但匈牙利法只适合于求解小规模问题,并且在处理一些特殊数据时,算法容易失效。智能算法如粒子群算法[11-13]、遗传算法[14],、蚁群算法[15]、模拟退火算法[16]等也常被用来解决任务指派问题。其中,粒子群优化算法的原理简单,需要调节的参数少,求解速度快,在寻优稳定性和全局收敛性等方面都具有一定优势,应用范围也由连续问题逐渐推广到离散问题中。为了解决任务指派问题,高尚等[11]设计了一种交叉粒子群优化算法,采用了遗传交叉的思想,对粒子群的位置更新,但该算法容易陷入局部最优,出现早熟收敛。谈文芳等[12]采用处理连续问题粒子群优化算法的一般公式,在粒子解更新时通过位置的排序来得到新整数排列解,这种做法忽略了离散型组合优化解的特点,存在表示冗余大、搜索效率低的缺点。孙晓雅等[13]提出了一种基于离散粒子群优化算法的求解方法,在迭代中通过定位交叉和局部搜索来对粒子的位置进行更新,增加解的多样性,避免陷入早熟收敛,但对不同的问题,需要通过复杂的参数调整,才能取得好的效果。
本文对中小型电商企业常用的穿梭车仓储系统进行研究。该系统由一辆穿梭车和一台穿梭车换层提升机协作完成巷道内货物的搬运。虽然此类系统的效率不及多辆穿梭车系统,但企业建设仓库的投入少,并且不存在由于穿梭车的碰撞和卡死带来的负面影响,深受中小型电商企业仓库的青睐。该系统的复合作业路径优化类似于传统堆垛机式的自动化立体仓库,即如何在复合作业模式下有效地将多个货位的出入库任务进行组合,从而减少出入库任务的总时间,此问题本质上是任务指派问题。针对模型的特点,重新定义了离散粒子群优化算法的位置和速度,将遗传算法中的循环交叉和交换变异思想引入到离散粒子群优化算法速度的更新公式中,为保持种群多样性和防止算法容易陷入局部最优,引入了排斥算子。最后通过仿真对比,验证了模型和算法的有效性。
1 穿梭车仓储系统模型
1.1 问题描述
本文研究的穿梭车仓储系统由穿梭车、(穿梭车换层)提升机、高层货架和传送辊道等组成(见图1)。货物放在料箱中,以料箱为拣选单元进行作业,穿梭车具有夹抱式货夹,用来夹取料箱,实现水平方向的移动,用提升机实现穿梭车垂直方向的移动。传送辊道连接拣选台,实现“货到人”的拣货模式。
该系统的作业模式有2种:单一作业和复合作业。单一作业是指系统一次只执行出库任务或入库任务。单一作业的大致流程为:提升机将穿梭车送到指定货位层,给穿梭车发送信号,穿梭车响应后水平运行到指定货位,完成存/取货任务后,返回到提升机并发送信号,提升机响应后载着穿梭车回到第一层Input/Output站台(I/O点)。在单一作业模式下,拣选时间是固定的,与任务的执行顺序无关。
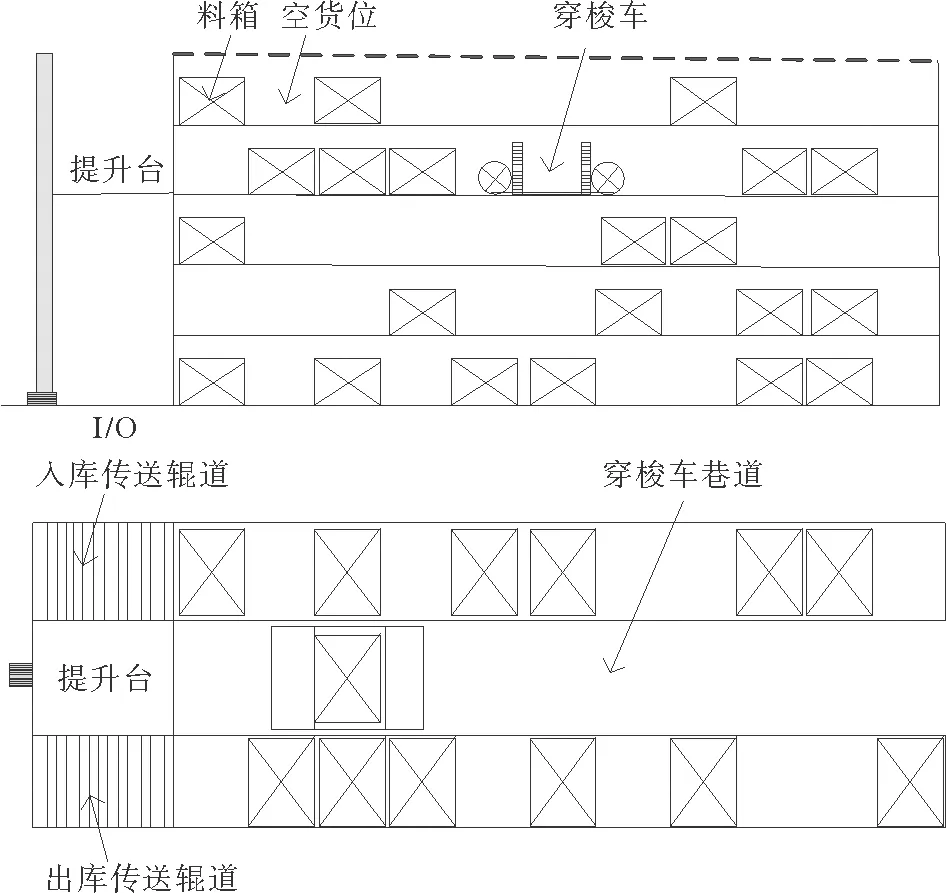
图1 穿梭车仓储系统示意图
当系统既有入库任务又有出库任务时,为提高效率,系统先到达入库任务货位点,完成入库任务后,不返回I/O点,而是直接到达出库货位点,完成取货后,再返回I/O点。对于一批出入库任务来说,按照不同的出入库任务配对进行复合作业,消耗的总作业时间是不同的,因此,研究合理的复合作业路径优化对于提升作业效率,降低作业成本具有重要意义。
1.2 模型建立
根据穿梭车仓储系统的实际运行情况,系统运行时满足以下条件:
1)穿梭车和提升机的初始位置均位于I/O点。穿梭车每次只能装载一个料箱,提升机只可运送穿梭车,提升机将穿梭车送到目标层后,停在该层等待穿梭车。
2)料箱均为轻型料箱,不考虑重力作用,穿梭车与提升机满载与空载情况下运行速度相同。
3)考虑穿梭车夹放货物所消耗的时间,以及提升机与穿梭车交互响应的时间。
4)穿梭车与提升机在运行时均考虑设备的加(减)速度。运行时间按照速度是否达到设备额定最大运行速度分为两种情况(见图2)[4]。已知设备最大运行速度为vmax,加速度为a,运行的距离为s,则运行时间为:
(1)
根据入库任务与出库任务是否位于货架的同一层,可将复合作业分为两种情况(见图3),I/O点可以看作位于货架的第1层第0排,将其坐标设为(0,1),设入库任务i的坐标为(xi,yi),出库任务j的坐标为(xj′,yj′)。当入库任务i与出库任务j位于货架同一层时,穿梭车的行程路线为:(0,1)→(0,yi)→(xi,yi)→(xj′,yj′)→(0,yj′)→(0,1)。当入库任务i与出库任务j位于货架不同层时,穿梭车的行程路线为:(0,1)→(0,yi)→(xi,yi)→(0,yi)→(0,yj′)→(xj′,yj′)→(0,yj′)→(0,1)。
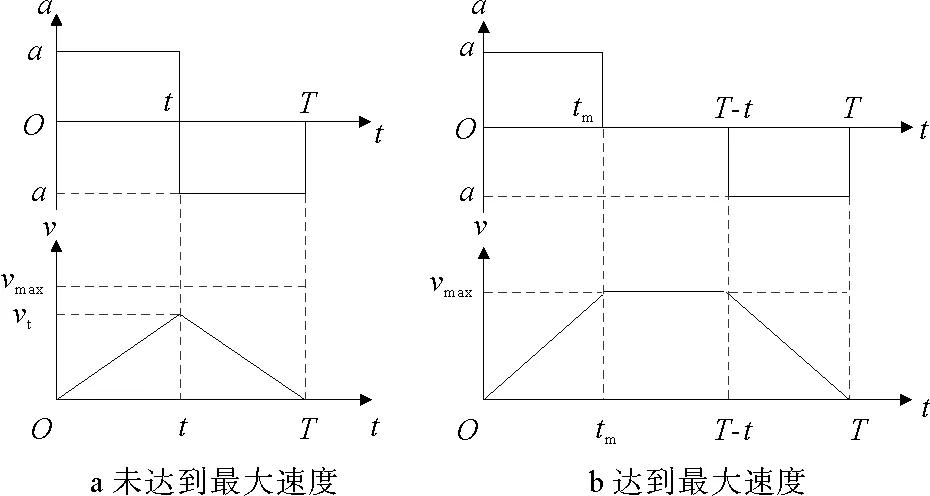
图2 速度-时间关系图
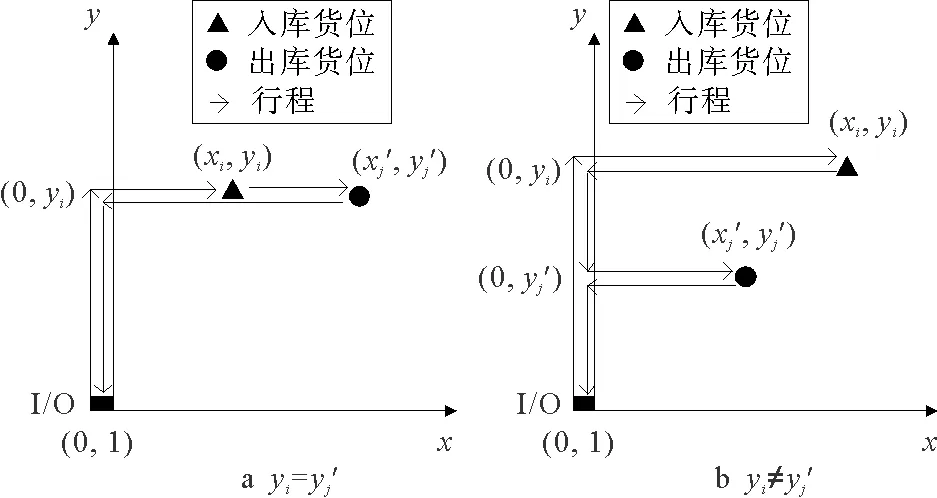
图3 复合作业路径示意图
对于给定的一批任务,设入库任务有m个,出库任务有n个。若m≠n,则用I/O点把数量较少的任务补齐,即将入库任务与出库任务均视为N=max{m,n}个。定义Q={q1,q2,…,qi,…,qN}为入库任务集合,其中,i表示入库任务编号,qi=(xi,yi)为入库任务坐标。定义P={p1,p2,…,pj,…,pN}为出库任务集合,其中,j表示出库任务编号,pj=(xj′,yj′)为出库任务坐标。
当入库任务与出库任务数量不相等时,与I/O点进行复合作业的任务,实际上执行的是单一作业。此时,穿梭车夹/放货物的次数、穿梭车与提升机交互响应的次数,与真正的复合作业不同。为了统一公式,引入参数δ,当实际执行复合作业时,δ=0;当实际执行单一作业时,δ=2。当入库任务i与出库任务j配对进行复合作业时,完成该复合作业所需时间tij的计算公式如式(2)、(3):
(2)
(3)
其中,
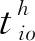
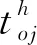
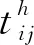
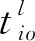
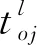
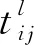
tcg表示穿梭车货夹单次取/放货时间;
tcl表示提升机与穿梭车交互响应时间。
设货架有L层H排,货格长度为l,货格高度为h,提升机加速度为ay,提升机最大速度为vy,穿梭车加速度为ax,穿梭车最大速度为vx,由式(1)可计算穿梭车和提升机在各阶段的运行时间为:
(4)
(5)
(6)
(7)
(8)
(9)
对于给定的一批出入库任务,由于入库任务需要依照一定的顺序执行,所以固定入库任务顺序,通过改变出库任务顺序,实现出入库任务的配对。将入库任务与出库任务的配对视为N个人分担N项任务的指派问题,以完成一批出入库任务的总时间最小为目标,建立复合作业路径优化模型如式(10)~(13)所示。
(10)
s.t.
(11)
(12)
(13)
其中,tij表示入库任务i与出库任务j进行复合作业所用的时间,由式(2)求出。当入库任务i与出库任务j进行复合作业时,cij=1,否则为0。约束条件(12)和(13)表示1个入库任务只能与1个出库任务配对,1个出库任务也只能与1个入库任务配对。
2 改进离散粒子群优化算法
粒子群优化算法的思想源于鸟类捕食时群体间的信息共享和协作。每个粒子包含位置和速度两个属性,粒子的位置代表问题的一个可行解,用粒子位置对应的适应度函数值评估粒子的优劣,迭代过程中记录粒子自身和群体的历史最优位置,通过速度调整粒子位置使之不断向更优的方向移动。标准粒子群优化算法的速度和位置更新方程如式(14)、(15)所示。
Vi(t+1)=ωVi(t)+c1r1(Xipbest(t)-Xi(t))+c2r2(Xgbest(t)-Xi(t))
(14)
Xi(t+1)=Xi(t)+Vi(t+1)
(15)
其中,t表示迭代次数,Xi和Vi分别表示粒子i的位置和速度,Xipbest为粒子i自身的历史最优位置,Xgbest为整个群体的历史最优位置。ω为惯性系数,c1和c2为学习因子,r1和r2是[0,1]之间的均匀分布随机数。速度的更新方程(14)由3个部分组成:ωVi称为惯性部分,主要作用是产生扰动,防止算法早熟收敛;c1r1(Xipbest-Xi)是认知部分,反应了粒子向自身历史最优位置逼近的趋势;c2r2(Xgbest-Xi)是社会部分,反应粒子向整个群体的历史最优位置逼近的趋势。通过设置适当的ω、c1、c2,可以权衡各部分所占的权重,使粒子具有均衡的局部搜索能力和全局搜索能力。
标准的粒子群优化算法是针对连续型问题给出的,并不能直接用来解决离散型问题。kennedy等[17]首先提出了二进制离散粒子群优化算法,随后许多学者提出了不同的离散粒子群优化算法。Clerc[18]指出设计离散粒子群优化算法的关键在于根据实际问题的特点对算法中的位置和速度以及运算规则重新定义。本文模型是典型的离散型问题,需要针对其特点对离散粒子群优化算法进行重新设计。
2.1 改进离散粒子群的更新方程
标准的粒子群速度更新方程(14)中涉及的运算有:速度的加法,速度的数乘、位置的减法。对于本文的模型来说,由于离散变量的特殊性,速度加法中的惯性项及速度的数乘会扰乱速度的更新,不利于算法向有利方向迭代,所以取消了标准粒子群速度更新方程中的惯性部分[19]和速度的数乘运算,只考虑个体历史最优位置、群体历史最优位置分别与粒子当前位置相减后产生的两个速度的加法运算。通过对速度的加法运算规则的设计,实现惯性部分和速度数乘运算的功能以及速度的更新。因为离散变量的运算并不是简单的数值运算,所以使用符号“⊕”“⊖”来表示离散变量的加减运算。综上所述,将速度和位置更新方程修改如式(16)、(17)所示。
Vi(t)=(Xipbest(t)⊖Xi(t))⊕(Xgbest(t)⊖Xi(t))
(16)
Xi(t+1)=Xi(t)⊕Vi(t)
(17)
算法首先随机产生粒子群的初始位置,再依照更新方程(16)和(17)依次迭代更新每个粒子的速度和位置。下面对算法中粒子位置和速度的定义及更新方程(16)和(17)中所涉及的运算规则,进行详细说明。
2.2 粒子位置和速度的定义
粒子位置X表示出入库任务的配对方案,粒子速度V的作用是改变粒子位置,使算法逐步找到更优的出入库任务配对方案。
粒子位置表示为X=(x1,x2,…,xi,…,xN),其分量都是不超过N的自然数而且各分量不重复。分量xi表示与第i个入库任务配对的出库任务编号,即其含义是编号为xi的出库任务与编号为i的入库任务组成第i个执行的复合作业任务对。
粒子速度表示为V=(v1,v2,…,vi,…,vN),其分量也都是不超过N的自然数而且各分量不重复。粒子速度的含义是将原来与编号为i的入库任务配对的出库任务,修改为与编号为vi的入库任务配对。实际上,这样定义速度的作用是对出库任务编号进行了重新排列,实现粒子位置的移动。这样定义可以保证X与任意V相加后,仍然是一个可行解。
2.3 位置的更新
更新方程(17)表示,通过粒子位置与速度的加法运算实现粒子位置的更新,使粒子到达一个新位置[19]。为便于描述,用X2=X1⊕V表示位置与速度的加法运算。如图4所示,根据粒子速度的定义,将粒子原位置X1的第i个分量x1,i依次赋值给粒子新位置X2的第vi个分量x2,vi,即X2的每一个分量由公式(18)确定。
x2,vi=x1,i
(18)
由此可以看出,当V=(1,…,i,…,N)时,将其加到原位置上,新位置将不发生改变,即X2=X1⊕V=X1。
2.4 速度的更新
速度的更新方程(16)中包含了位置的减法运算和速度的加法运算。通过位置减法得到两个速度,这两个速度反映了粒子当前位置与个体最优和群体最优的差距。通过速度的加法运算,将这两个速度结合,实现粒子速度的更新,新产生的速度综合了粒子个体最优和群体最优的位置信息,将其加到粒子位置上,可以使粒子群逐步向全局最优解靠近。
2.4.1 位置的减法
位置的减法运算用V=X2⊖X1表示,根据粒子速度的定义,该运算的实现方式是:依次找到X2中与x1,i相等的分量x2,j的位置j,并将j赋值给vi,即速度V中的每一个分量vi由式(19)产生(见图5)。
find(x2,j=x1,i),return(j),vi=j
(19)
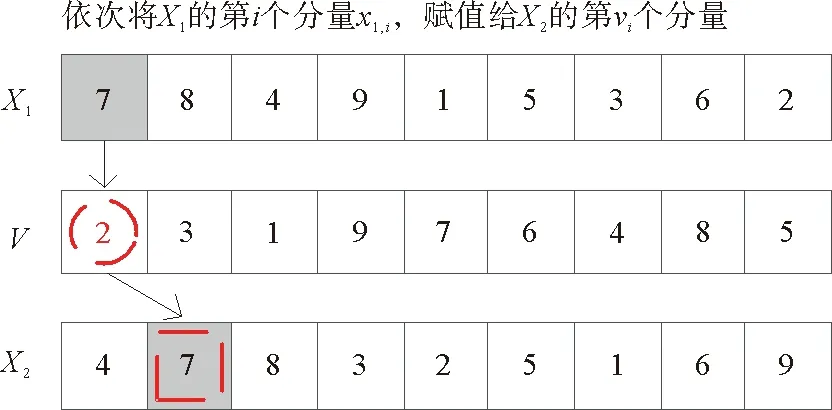
图4 位置与速度的加法
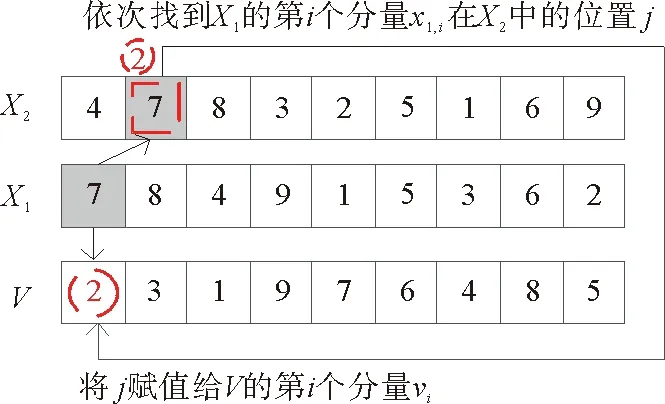
图5 位置的减法
2.4.2 速度的加法
速度的加法运算用V=V1⊕V2表示。为了实现速度加法的功能,将遗传算法的循环交叉引入到速度的加法中,把V1和V2看作两个父代染色体。循环交叉的基本思想是子代的基因必须与父母相应位置上的基因相等,这样可以较好地保留位值信息,适用于解决任务指派问题[20]。若两个速度只进行循环交叉,新产生的速度作用到粒子位置上,将使种群迅速趋同,算法失效。为防止种群迅速趋同,将交叉后的速度进行交换变异,为种群增加扰动。当粒子的多样性下降到一定程度时,定义一个排斥算子,减少算法陷入局部最优的可能,提高算法的求解精度。
综上所述,V1⊕V2的运算步骤如下:
1)循环交叉。首先随机选择V1的某一个基因,为了便于描述,以选中了V1的第一个基因为例说明(见图6),具体操作如下:
(1)将V1的第一个基因,赋给C1的第一个基因,同时将V2的第一个基因赋给C2的第一个基因。
(2)在V1中找V2的第一个基因的基因位i,将V1该基因位的基因赋给C1的相应位,将V2该基因位的基因赋给C2的相应位,……重复此过程,直到在V2上找到V1的第一个基因为止,称为一个循环。
(3)对于循环中未被选中的基因位,将V1相应位基因赋给C2,将V2相应位基因赋给C1,从而产生两个子代:C1和C2。
(4)以等同的概率随机选择C1和C2中的一个,记为V′。
2)交换变异。对循环交叉后产生的V′,以一定的变异概率Pm进行交换变异。如图7所示,若Pm大于随机数rand,则随机交换V′的两个基因,求得V;否则,直接令V=V′。变异的作用是增加扰动,在探索初期,为提高全局搜索能力,Pm取一个较大的值;在探索后期,Pm取较小的值。设Pm的取值范围为[pmin,pmax],最大迭代次数为Itermax,则第gen代的变异概率由式(20)确定。
Pm=pmax-(pmax-pmin)gen/Itermax
(20)
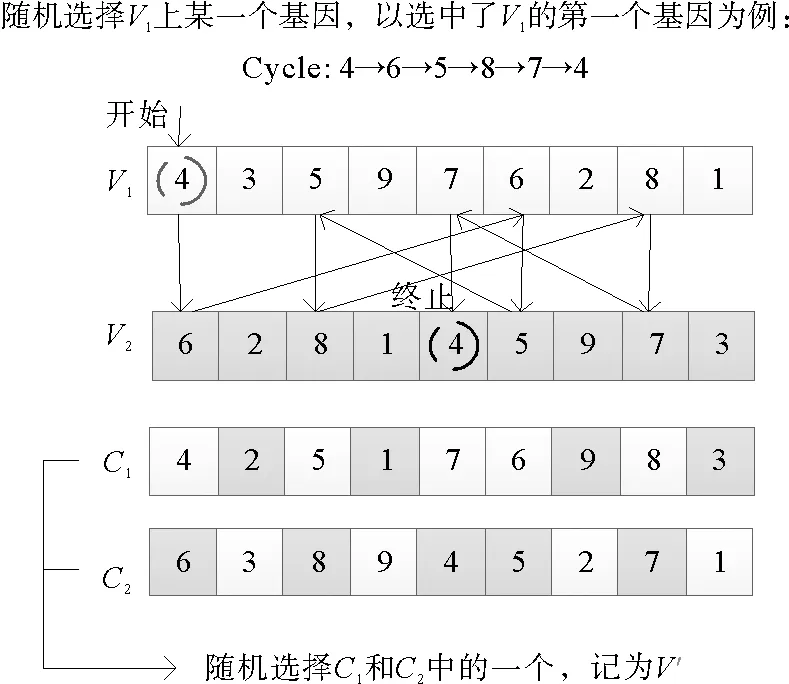
图6 循环交叉
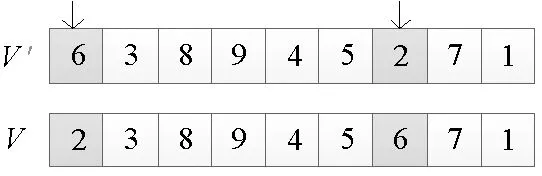
图7 交换变异
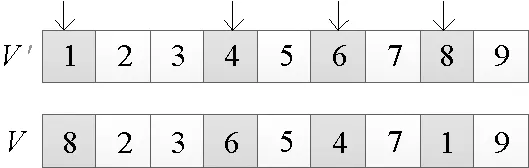
图8 排斥算子
3)排斥算子。随着算法的迭代,粒子群逐渐趋同,个体的进化能力受到很大限制,只有在其它粒子找到新的全局最优位置后,粒子才能恢复进化能力,所以,当算法迭代到一定的次数Iter时,定义一个排斥算子来增加粒子的多样性[19]。如果粒子经过循环交叉后的速度V′=(1,…,i,…,N),则表示该粒子为全局最优。为了增加扰动,此速度不再进行变异操作,而是随机选中V′上的k个基因进行反转(k∈{2,…,N}),随着迭代次数的增加,k逐渐增大,实现从局部搜索到全局搜索的过程,使得算法跳出局部最优。以k=4为例,排斥算子对速度的影响,如图8所示。
2.5 适应度函数
根据第1.2节建立的复合作业路径优化模型,将适应度函数定义为完成一批出入库任务的总时间最小:
fitness=minT
(21)
2.6 算法流程
综上所述,改进离散粒子群优化算法(IDPSO)的基本流程如图9所示。
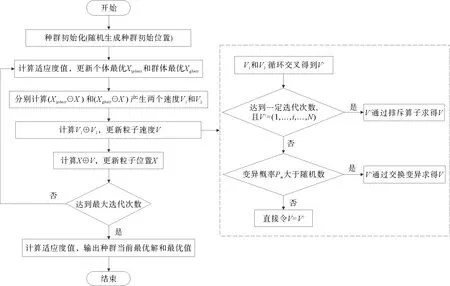
图9 改进离散粒子群优化算法流程图
3 仿真结果及分析
为了证明模型和算法的有效性,以某电商仓库为例,根据其具体数据及设备特性,使用MATLAB软件进行仿真。仓库中具体的设备运行参数如表1所示。
以系统的一组任务数据为例(见表2)。该数据有12个出库任务,10个入库任务,用I/O点将入库任务补齐为12个。根据提出的模型,经过IDPSO算法优化后,得到最优解X=(6,12,1,2,10,8,7,5,11,9,4,3),表示入库任务与出库任务以(1-6)→(2-12)→(3-1)→(4-2)→(5-10)→(6-8)→(7-7)→(8-5)→(9-11)→(10-9)→(11-3)→(12-4)的顺序进行配对执行复合作业,其中,出库任务3和4实际执行单一出库作业。优化后的总作业时间为742.666 s,较执行单一作业(1 096.734 s)和未优化前的复合作业(838.705 s),效率分别提高了32.3%和11.5%。

表1 仓库设备参数
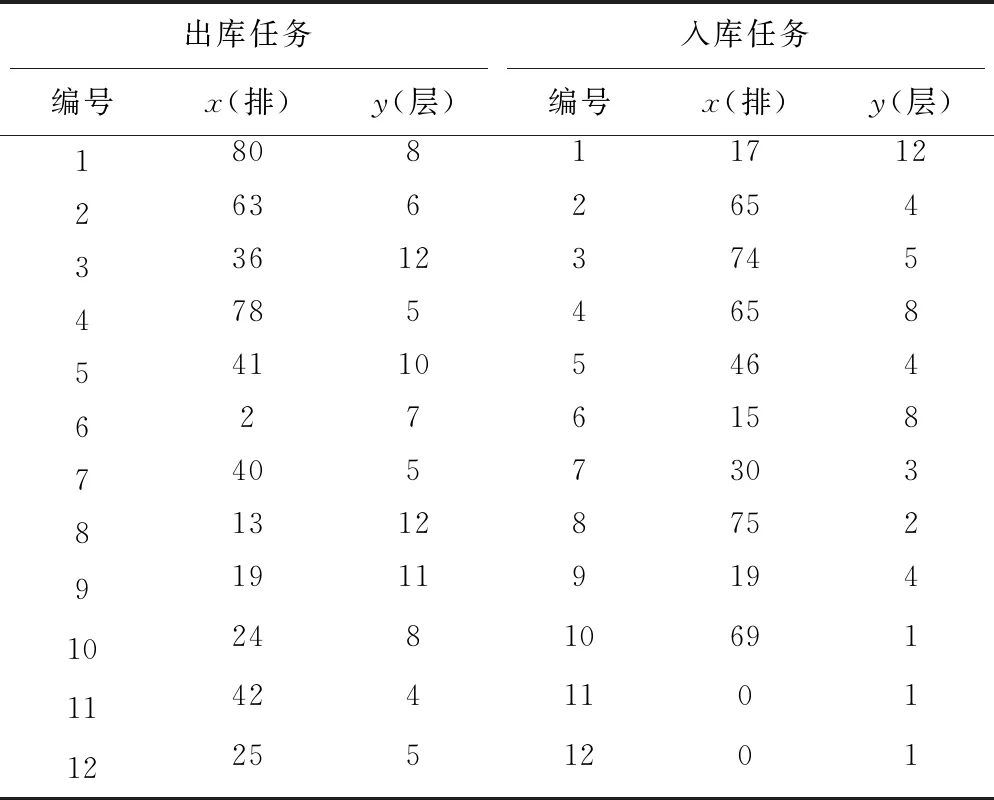
表2 出入库任务列表
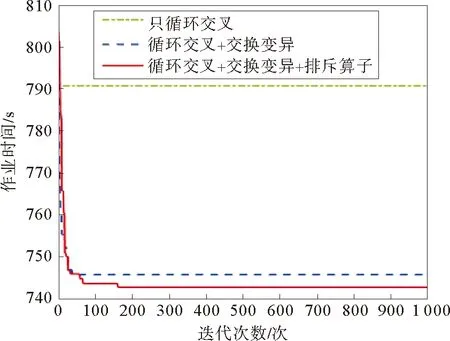
图10 不同速度加法操作下的IDPSO收敛曲线对比图
为了验证算法中速度加法的有效性,保持其它操作不变,将速度加法里面的不同操作方式产生的效果进行对比,结果如图10所示。若在速度的加法中,只进行循环交叉,不加入交换变异和排斥算子,则算法将迅速收敛早熟;在加入交换变异后,可以避免算法早熟,但仍然容易陷入局部最优解;通过排斥算子,可以进一步提高算法的求解精度。通过多次重复仿真,得到的比较结果相同,验证了算法中速度加法设计的有效性和必要性。
为了验证IDPSO算法在不同规模的数据下的性能,分别对复合作业数N(m=n=N)为30,50,100的任务订单进行优化,并与遗传算法(GA)进行比较。IDPSO种群大小设N,pmax=1.2,pmin=0.2,Iter=1/10*Itermax。GA种群大小设为3N,采用循环交叉,交换变异,精英保留策略,交叉概率为0.8,变异概率为0.2,代沟比例为0.9。两个算法最大迭代次数Itermax均设为1000,每个算法独立运行30次,计算出平均值、最小值、最大值和标准差,统计结果如表3所示。
从表3可以看出,在不同任务规模下,IDPSO得到的最优值、最差值、平均值、标准差均小于GA,证明IDPSO的求解精度和稳定性都优于GA。从算法平均运行一次的时间来看,GA的运行时间超过IDPSO的2倍,证明IDPSO的求解速度更快。
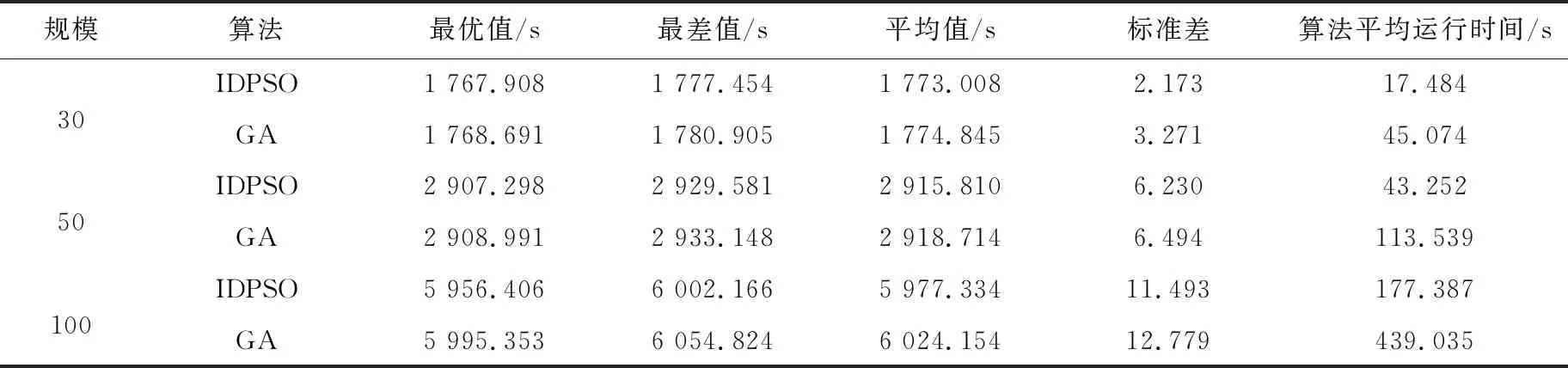
表3 IDPSO与GA算法优化结果对比
图11是两种算法在不同任务规模下的收敛曲线,可以看出IDPSO在迭代初期,可以快速收敛,而GA的收敛速度较慢。对于任务规模为30和50的曲线,IDPSO在250代左右就达到稳定,GA在400代左右才能达到稳定。对于任务规模为100的曲线,IDPSO在400代左右就达到稳定,GA在1 000代仍然未达到稳定。综上,IDPSO的收敛速度和收敛稳定性都优于GA。

图11 不同任务规模下两种算法的收敛曲线对比图
4 结论
研究了一种穿梭车仓储系统的复合作业路径优化问题。分析了该系统的作业模式和设备运行特征,以完成一批任务的总时间最小为目标,建立了基于任务指派问题的复合作业路径优化模型。根据模型的特点,设计了一种离散粒子群优化算法对模型求解,通过仿真结果,与遗传算法进行比较,验证了本文提出的算法具有更好的效果。经过优化,大大缩短了复合作业的时间,提高了作业效率,为企业节省了时间成本。
本文研究的穿梭车仓储系统一个巷道内只包含一辆穿梭车,无需考虑复杂的调度,穿梭车在巷道内运行时,提升机空闲会造成资源浪费,下一步将对更加复杂,效率更高的穿梭车仓储系统进行研究。
