基于ARCNN-GAP网络的语音情感识别
2021-12-18钱佳琪黄鹤鸣张会云
钱佳琪,黄鹤鸣,张会云
(1.青海师范大学计算机学院,青海 西宁 810008; 2.藏语智能信息处理及应用国家重点实验室,青海 西宁 810008)
0 引 言
随着人工智能(Artificial intelligence, AI)相关技术的飞速发展,人机交互不再满足于键盘、鼠标等传统机械的交互方式,赋予计算机感知各种情感特征的能力正在成为AI领域的一个全新课题[1]。语音是人与人交流最简洁的方式,也是情感传递最直接的方式。因此,识别语音中包含的情感是人类情感识别的重要组成部分[2]。语音情感识别(Speech Emotion Recognition, SER)就是利用计算机模拟人类大脑对语音信号的处理机制,对输入的语音信息进行特征提取,寻找特征与情感之间的映射关系,实现对情感的准确判断[3]。
语音情感识别属于模式识别范畴,建立更好的识别模型是它的重要研究内容[4]。
早期的研究中,多使用模式识别中常见的方法进行情感识别:Banse等人[5]提取了基频、能量等传统声学特征,选取线性判别分类器对14种情感进行分类,取得了50.00%的识别率;Dellaert等人[6]分别采用最大似然贝叶斯分类、核回归和K近邻3种方法,对4类情感进行识别实验,发现KNN具有最好的识别性能;Luengo等人[7]使用支持向量机,在EMO-DB数据库上进行情感识别,取得了78.00%的识别率。
随着人工智能的飞速发展,神经网络被广泛应用于语音情感识别。Mirsamadi等人[8]构建了基于循环神经网络(Recurrent Neural Network, RNN)与注意力机制的语音情感识别系统,在IEMOCAP数据库上取得了63.50%的加权准确率;余莉萍等人[9]将长短时记忆网络(Long Short Term Memory, LSTM)中传统的遗忘门和输入门转换为注意力门,相较于传统的LSTM,召回率最高实现了5.50%的提升,性能得到明显改进;Sun[10]在残差卷积神经网络中引入性别信息,并将全连接层替换为全局平均池化(Global Average Pooling, GAP),在多个数据库中都取得了良好的识别效果;柳长源等人[11]将循环卷积神经网络(Recurrent Convolutional Neural Network, RCNN)引入脑电情感识别,并与LSTM相结合,取得了理想的实验效果。
虽然,语音情感识别相关研究取得了一些进展,但识别模型的性能需要进一步提升。因此,本文提出一种基于RCNN的新模型ARCNN-GAP,其中,循环卷积层具有弹性路径,在确保网络深度的同时能够保证优化时的梯度回传,有利于提取更加有效的情感特征;GAP运算在减少计算复杂度的同时降低了过拟合风险;注意力机制能使模型关注更多情感相关信息。实验验证了该模型具有更好的识别性能与泛化性。
1 循环卷积神经网络
卷积神经网络(Convolutional Neural Network, CNN)是一种前馈神经网络,通过卷积运算提取输入信息中的特征[12]。RNN擅长处理序列数据,通过在同一层节点之间建立连接,使一个序列中当前时刻的输入与之前时刻的输出产生关联,有效解决了CNN不擅长对序列进行建模的问题[13]。
RCNN是一种结合了CNN和RNN各自优良特性的新型网络模型:它改进了传统CNN的连接方式,将多层CNN以递归的方式进行层内连接组成循环卷积层(Recurrent Convolutional Layer, RCL),再将多层RCL相连[14],如图1所示。
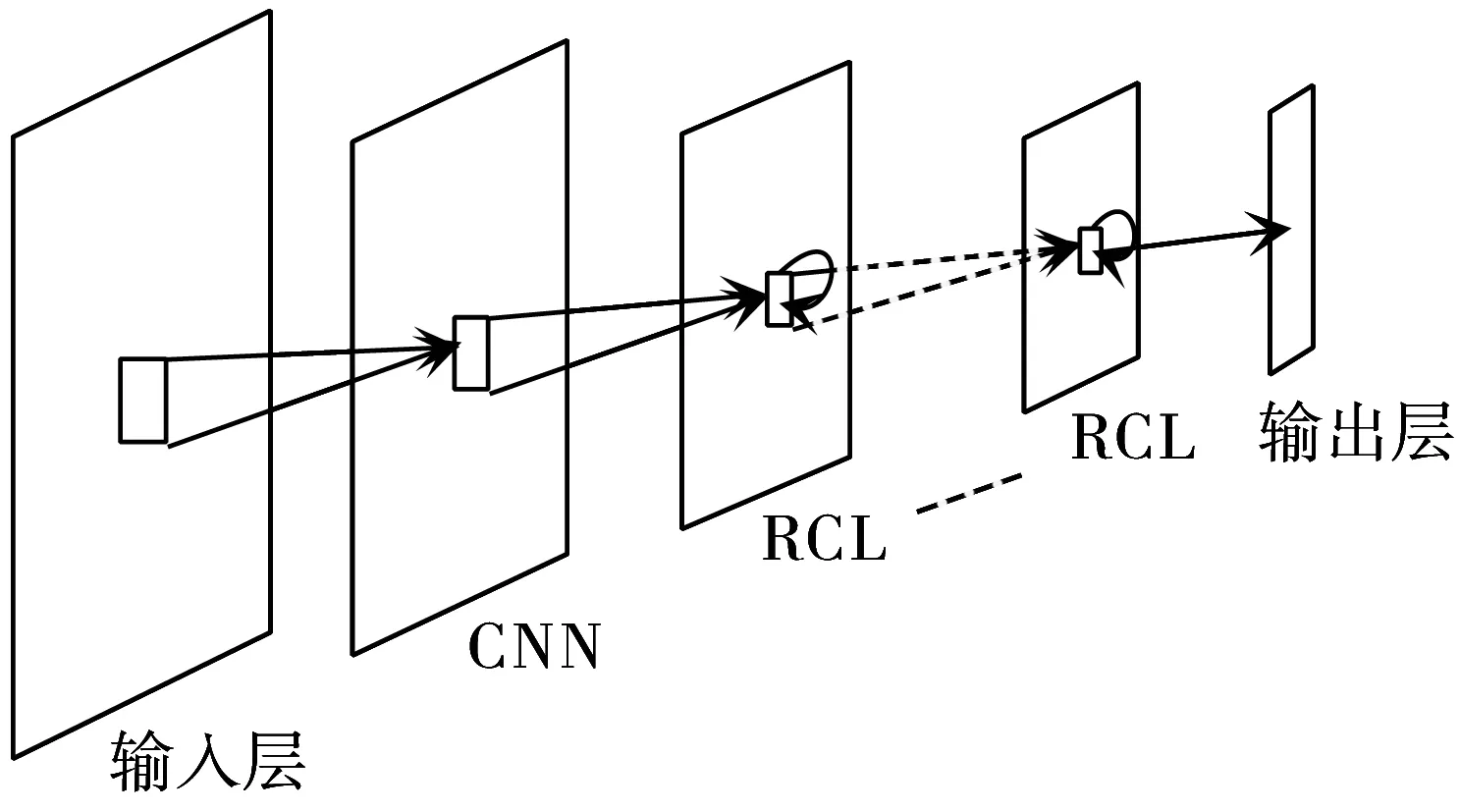
图1 RCNN结构图
RCNN主要是由一层标准的前馈卷积层和多层RCL共同组成。其中,RCL由多个卷积层构成,如果将其展开能够得到一个深度为T+1的网络。从第2层开始,RCL中每层接受的都是来自前一层和前馈卷积层的共同信息[15]。图2为RCL的展开图。
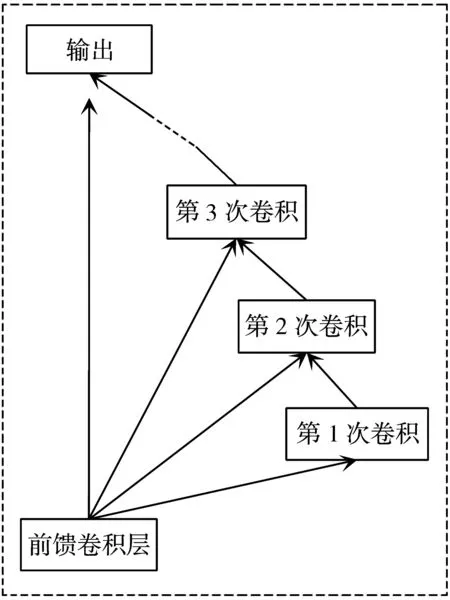
图2 RCL展开图
沿时间T展开后的RCL包含多条路径:最短的路径只经过前馈卷积层,深度为1;最长的一条路径会经过所有卷积层,深度为T+1。因此,RCL类似于一个深度为T+1的CNN,但它们之间存在一些本质上的区别:T+1层的CNN在信息进行输入时,输入的时间点是一致的;RCL的前馈输入在全过程中保持不变,但内部的卷积层输入会随时间持续更新[11]。RCL内部信息的传递可以表示为:
(1)
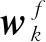
RCNN网络中,一层RCL相当于一个深度为T+1的网络,n层RCL就相当于一个深度为n(T+1)的网络。当T增大时,意味着网络深度的增加,能够提取到更加复杂的特征信息[16]。然而,单纯增加网络的深度又会增加网络复杂度,因此,RCL通过一系列弹性路径,在确保网络深度的同时保证优化时的梯度回传。
2 ARCNN-GAP模型
基于RCNN的诸多优点,结合GAP和注意力机制,本文设计了ARCNN-GAP模型。
在卷积操作之后,通常会在Softmax之前添加全连接层用来整合卷积结果和降维,将得到的结果输入到Softmax层进行分类。但过多的全连接层参数,会显著增加计算负荷,容易造成过拟合。如果用GAP代替全连接层,则可以通过降低参数数量最小化过拟合效应。
图3对比了全连接层和GAP的结构,可以看出:全连接层把每个通道在卷积层的输出重塑为一个一维向量;而GAP则将每个通道的输出特征图进行平均,得到一个单一的值。由于GAP中没有需要优化的参数,所以有效避免了过拟合现象。此外,GAP汇总了空间信息,使得输入空间的转换更具鲁棒性[10]。
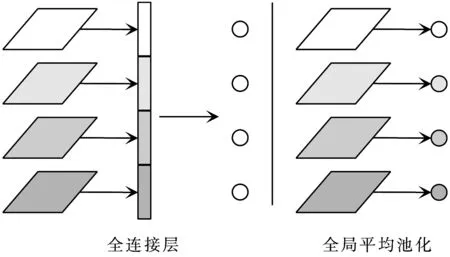
图3 全连接层和全局平均池化
对于人类而言,眼睛扫描图片信息时,通过集中注意力大脑能够迅速注意到目标区域而忽略其他区域,以获得更多的目标信息。利用这种方法,人类仅使用有限的注意力就可以迅速从大量信息中抓取关键信息,极大地提高了信息的处理效率和准确率。注意力机制就是让计算机模拟人类大脑所提出的一种信息处理机制[17]。
为了降低过拟合风险,提高信息处理效率和情感识别率,在RCNN中引入了注意力机制和GAP,得到新的模型ARCNN-GAP,如图4所示。该网络主要由5个部分组成,从下往上分别是输入层、RCNN层、注意力层、GAP层、输出层。在进行情感识别时,首先,输入信息会进入RCNN,用于提取更加复杂的特征信息,在RCNN中,第1层为CNN,后面由RCL和池化层交替排列;其次,特征信息在经过RCNN后会输入到注意力层,用以关注更多情感相关特征,RCNN的输出信息可以表示为x=[x1,x2,…,xN],x在进入注意力层后会先和WQ、WK、WV这3个不同维度的矩阵进行相乘,从而得到q、k、v,用公式表示为:q=WQx,k=WKx,v=WVx,之后需要计算输入信息的注意力权重αi,计算公式为:
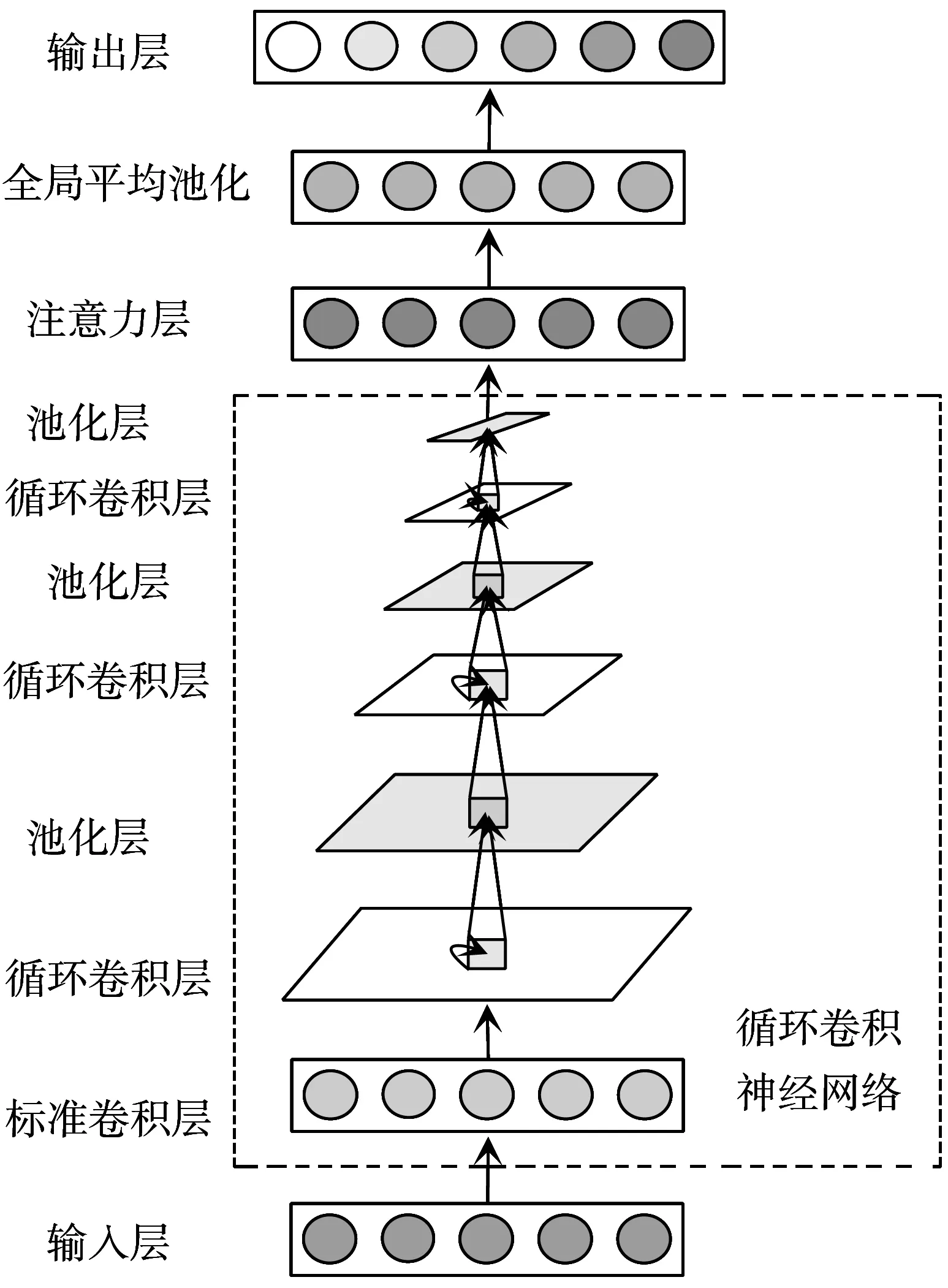
图4 ARCNN-GAP的模型结构
(2)
其中,s(qi,k)表示点积操作,计算公式为:
(3)
得到注意力权重αi后,再使用加权求和对输入信息进行汇总,计算公式为:
(4)
通过上述计算过程可以得到注意力层最终的输出结果;随后,将注意力机制的输出结果输入到GAP层进行全局平均池化,GAP能够关注整体信息,在此过程中,GAP会对每一个特征图层中的所有像素点求均值,每个特征图层都会得到一个单一的值;最后,通过Softmax函数计算出输入样本属于各类情感的概率,得到识别结果。
3 实 验
本章首先验证模型ARCNN-GAP的可行性,再通过与其他相关研究结果的对比验证该模型的优越性。
3.1 数据集
本文共使用了2个数据库:CASIA中文语音情感数据库和EM-ODB德语情感数据库。CASIA是由中科院自动化研究所录制的中文语音情感数据库,由两男两女共4位专业发音人进行录制[18];EMO-DB是由柏林工业大学专业录音室录制的德语情感数据库,由10名专业演员通过回忆自身的真实经历来对情感进行演绎[19]。表1列出了2个数据库的情感种类和规模。

表1 数据库
3.2 特征选择
韵律特征是语音情感识别的首选特征,而基于谱的相关特征又是语音情感识别性能最优的3类主流声学特征之一[20],所以,本文融合韵律特征和谱特征进行实验。表2列出了实验所使用的特征。
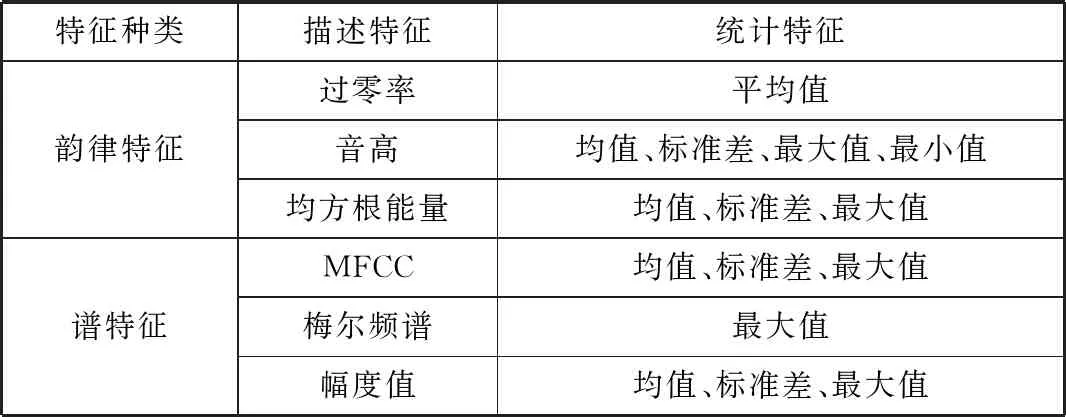
表2 特征类别
3.3 实验结果及分析
首先,在CASIA数据库上对RCNN进行实验,测试得到RCL的最优深度和最佳层数。
图5以折线图的形式呈现了CASIA数据库上RCL不同深度和不同层数对应的准确率、精确率、召回率和F1分数。其中,层数L从3到6,深度T从3到8共24种组合,分别用数字0至23代替。
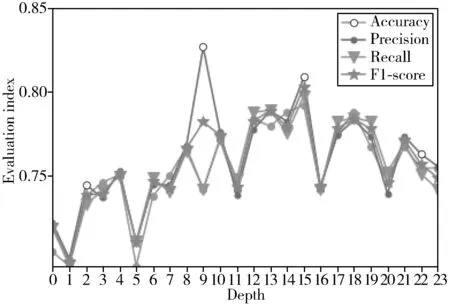
图5 不同深度评价指标变化趋势
从图5可以看出:折线图的整体变化趋势是先升高再降低,除精确率外,其他各项指标均在横坐标为15时达到最高点,而横坐标为15正对应深度L=5且T=6。由此可以得出:当深度小于L=5且T=6时,性能会随着深度增加整体呈上升趋势;当深度大于L=5且T=6时,性能会随着深度增加逐步下降,且训练时间也会逐渐增加。因此,当深度为L=5且T=6时模型的整体性能达到最优,接下来的实验都将在此深度上进行。
其次,验证模型ARCNN-GAP在CASIA数据库上的识别性能。
图6展示了模型ARCNN-GAP在CASIA数据库上的混淆矩阵。可以看出:模型的总体识别率为83.29%;中性情感的识别率达到了95.00%,其他所有情感的识别率都达到了75.00%以上;害怕和悲伤2种情感容易产生混淆。这是由于害怕和悲伤在效价-激活模型中都处于负激活维,而且2种情感的维度取值较为接近,所以容易产生混淆[21]。
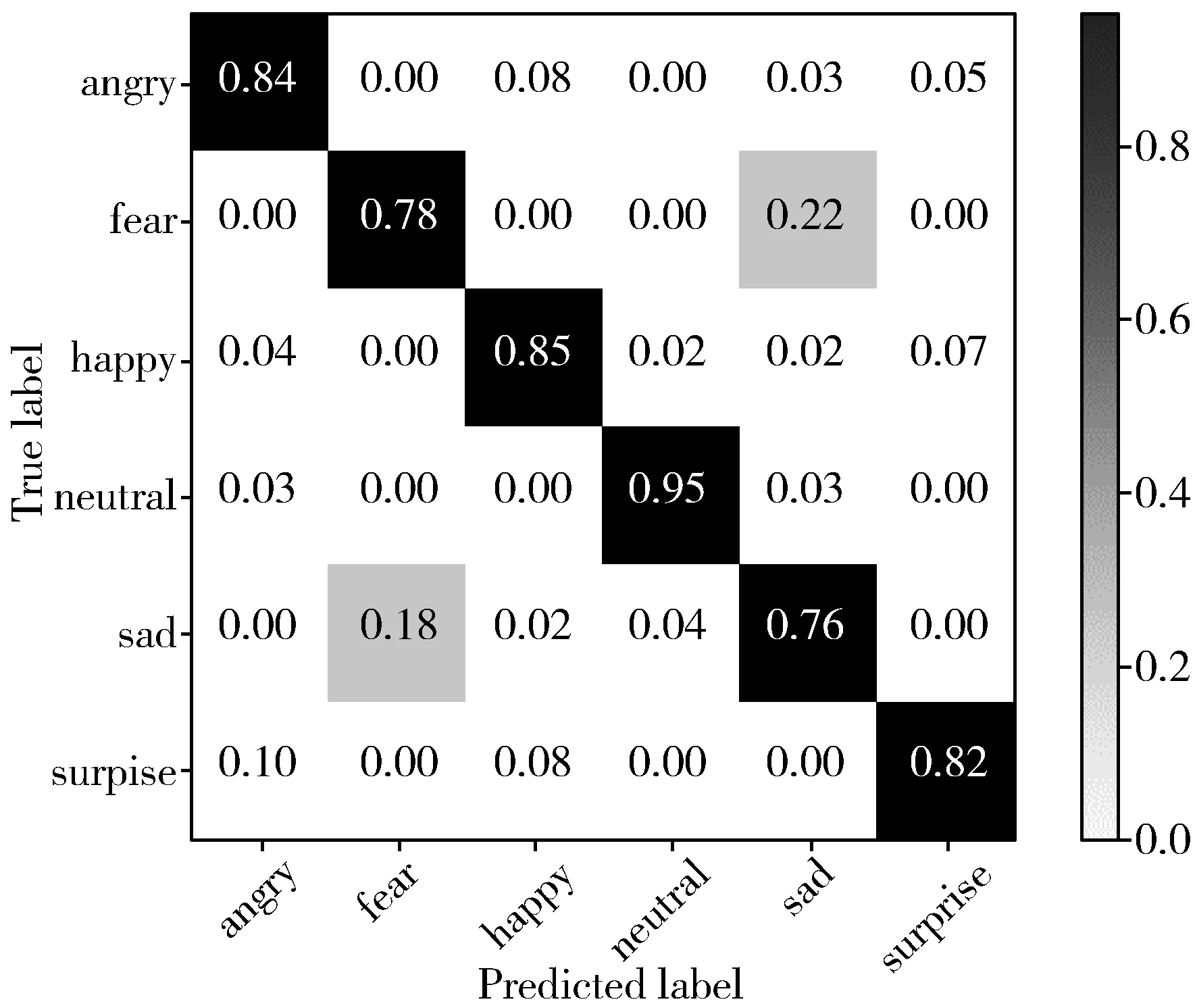
图6 ARCNN-GAP模型的混淆矩阵
模型ARCNN-GAP在CASIA数据库中训练集和测试集上准确率的变化趋势见图7。可以看出:训练到一定程度之后,训练集上的准确率能达到100.00%,测试集的准确率也能达到83.00%左右。说明引入注意力机制和GAP能使系统达到较好的性能。
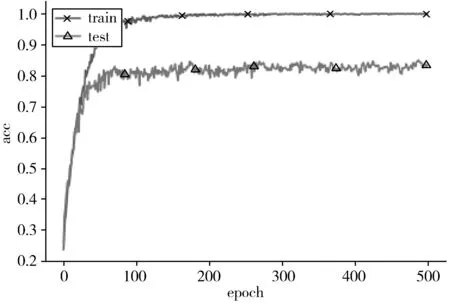
图7 ARCNN-GAP模型的准确率变化趋势
以CNN作为基线模型,采用消融实验法分别测试RCNN、ARCNN、RCNN-GAP的实验结果,并与本文提出的模型ARCNN-GAP进行对比,如表3所示。可以看出:在准确率、精确率、召回率、F1分数4项评价指标中,ARCNN-GAP模型的性能均优于基线模型和其他3种方法,特别是ARCNN-GAP模型的情感识别率为83.29%,较其他4种方法均得到了显著提升。
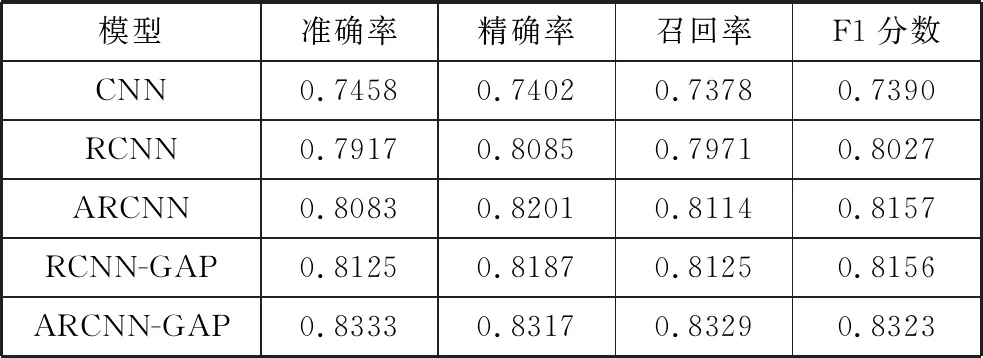
表3 不同模型结果对比
将ARCNN-GAP模型的识别性能与同样使用CASIA数据库进行实验的文献[22-24]使用的3种方法进行对比,如表4所示。其中,文献[22]提取了12类声学特征,分别计算它们的统计特征,再使用BP神经网络进行特征选择,最后使用支持向量机(Support Vector Machine, SVM)作为分类器进行情感分类。文献[23]提出了一种基于参数迁移和卷积循环神经网络(Parameter Transfer and Convolutional Recurrent Neural Network, TCRNN)的语音情感识别模型,该方法将语谱图作为网络的输入,迁移AlexNet网络模型预训练得到卷积层参数,再将CNN输出的特征图重构后输入LSTM进行训练。文献[24]提出了DNN-SVM模型,该模型采用多个不同的DNN来提取不同位置的瓶颈特征,并计算了不同瓶颈特征的统计特征,最后将所有特征融合后输入SVM进行情感识别。上述3种方法在CASIA数据库中的识别率均在75.00%以下,明显低于本文所提方法的83.29%,进一步验证了本文算法的优良性能。
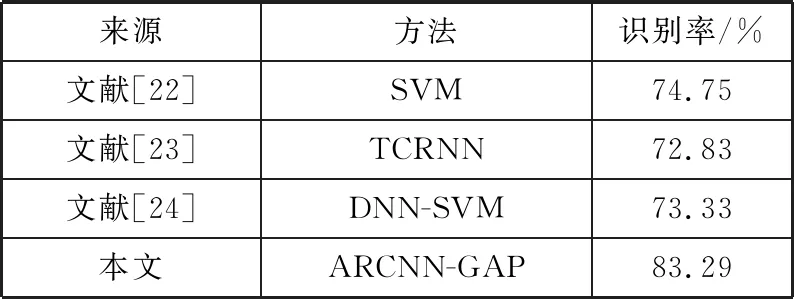
表4 不同研究结果对比
最后,测试了模型ARCNN-GAP的泛化性。
为了验证泛化性,测试了模型ARCNN-GAP在EMO-DB语料库上的准确率、精确率、召回率、F1分数,结果如表5所示。可以看出:在EMO-DB语料库上,模型的识别率为75.28%,具有较好的识别效果;精确率与CASIA数据库中的结果相差不大;其他各项指数也均在75.00%以上。综合来看,模型ARCNN-GAP在EMO-DB语料库上仍能取得较好的性能,说明模型具有良好的泛化性。

表5 ARCNN-GAP模型在CASIA和EMO-DB结果对比
4 结束语
为了得到性能优良的语音情感识别模型,本文提出了一种基于RCNN的语音情感识别模型ARCNN-GAP。其中,循环卷积层在确保网络深度的同时能够保证优化时的梯度回传,提取更多有效特征;GAP运算在减少计算复杂度的同时降低了过拟合的风险;注意力机制能使模型关注更多情感相关特性。在CASIA和EMO-DB语音情感数据库上的实验表明,这种新模型在语音情感识别中具有良好的识别率和泛化性。
未来可以继续进行研究探讨的方向如下:1)提取语谱图特征尝试以端到端的方式进行语音情感识别;2)开展藏语语音情感识别;3)开展多模态情感识别研究。
