基于岭回归极限学习机的微博垃圾用户分类*
2021-12-01张瑶瑶朱小栋
张瑶瑶 朱小栋
(上海理工大学管理学院 上海 200093)
1 引言
在用户主导而生成内容的互联网产品模式的Web 2.0时代,Facebook、Twitter、微博、知乎、豆瓣、天涯等国内外知名社交网站的逐渐兴起火热,当代社交网络也已成为用户日常生活不可缺少的部分。据STATISTA报告,截至2018年4月美国社交媒体平台领先者Facebook月活跃账户22.34亿,与此同时中国社会媒体平台新浪微博拥有3.92亿月活跃账户;视频门户网站Youtube月活跃账户15亿;主题交流社区百度贴吧拥有月活跃账户3亿。伴随着成熟的技术和成功的推广,社交网站吸引越来越多的网民注册使用,在这样庞大的网络群体中,可能会因为垃圾用户经常发布无用信息造成社交用户个人主页信息冗杂干扰使用,也可能会发生盗取个人信息诈骗造成精神金钱损失,甚至还可能因为有组织有预谋的行为引起热门话题的讨论和舆论的错误导向[1~3]。
当下对与社交网络垃圾用户特征的研究分为三个部分——基于内容分析方法、基于用户行为分析方法、基于用户关系分析方法。第一种基于内容特征分析的模式中,通常使用一系列的机器学习算法来识别内容中的潜在垃圾关键字[4]。在第二种基于用户特征分析包括贝叶斯算法[5]、决策树分类[6]等经典机器学习算法,早期研究使用垃圾用户部分行为特征作为属性[7],如关注人数,粉丝数,关注/粉丝比,推文数等[8],但由于社交软件功能的更新以及逐渐善于伪装的垃圾用户,后来的研究逐渐考虑更多的属性,如博文之间的相似性,发文时间分布,博文中URL比例等[9],但是过多的属性也会造成数据预处理和标准化的困难,延长处理时间,降低处理效率。第三种基于用户关系特征的分析方法应用如神经网络分类法、贝叶斯网络等[10]。这类方法为了建立社交网络需要收集大量具有复杂关系的数据,但是许多垃圾用户通过学习正常用户的社交图谱规律,构建稳固的社交关系,故分类效果往往并不理想。综合分类效率和分类精度,本文提出了运用基于岭回归极限学习机的微博垃圾用户检测方法。
2 基于ELM的微博网络垃圾用户识别算法
2.1 ELM基本理论
在传统的神经网络训练中,通常要通过梯度下降算法来不断的调整隐层与输出层,输出层与隐层之间的权值矩阵,以及偏置b。在ELM(Extreme Learning Machine)算法中,隐层的权值矩阵W和偏置b则没有必要调整,在学习算法开始时任意随机给定W和b的值,利用其计算出H(隐层节点的输出),并令其保持不变,后续只需确定β[11]。设前向神经网络的输入层节点数量为P,特征向量的维数与输入节点数量相同;隐藏层的节点数量为L。则hidden layer的第i个节点的输出为
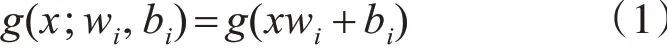
即将P维向量映射到L维向量:
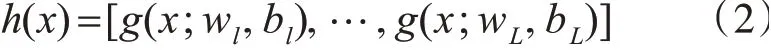
其中wi为第输入层节点与隐层节点之间的第i个链接,bi为偏置,g为激活函数,这里使用sigmoid函数:
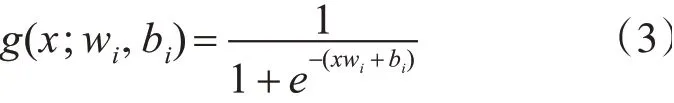
输出层的节点数记作M;第i个隐层节点和第j个输出层节点之间的权重为βi,j,则节点j的输出为
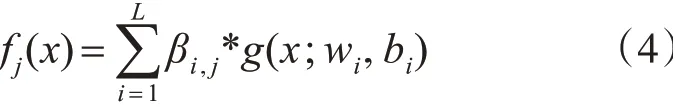
因此输入样本X,对应的输出为
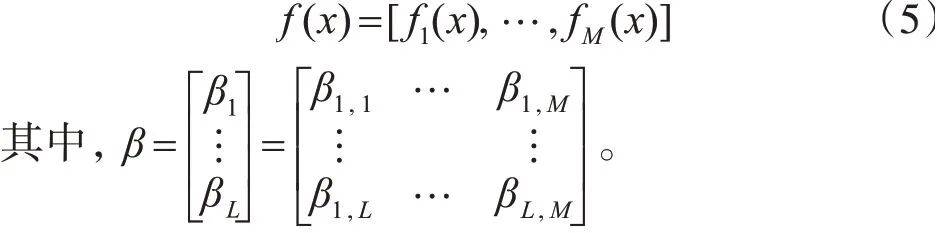
在识别阶段,给定一个样本X,则该样本所属类别为
2.2 RR-ELM理论
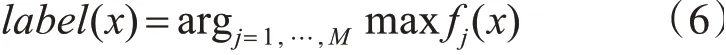
ELM算法和神经网络算法最大的区别在于:ELM不需要进行迭代,而是一次性通过标签计算出最后一层神经元的权重。而神经网络是通过梯度下降的方法,不断地根据loss值更新权重值。因此ELM算法并不适合构造出更深的网络结构,但是减少了计算量,减少了机器开销。而RR-ELM(Ridge Regression Extreme Learning Machine)相对于ELM加入了正则项的限制,防止过拟合。ELM的泛化能力和稳定性由如下代价函数得到:
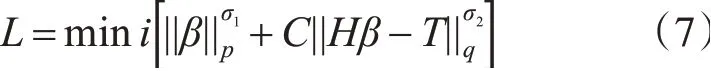
适当确定σ1,p,σ2,q,并当加入正则项后,代价函数变成:
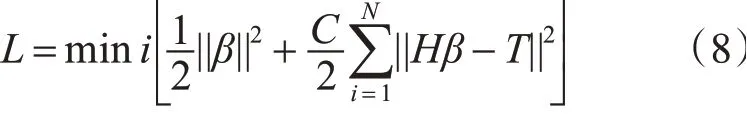
加入正则项的RR-ELM泛化能力更强,分类效果预计也更好。
2.3 基于RR-ELM的垃圾用户识别算法框架
图1 展示了所提出的微博垃圾用户检测模型的基本概念。在该方案中,训练数据被转换成一系列 的 特 征 向 量,{users:attribute1,attribute2,…,attributen}表示用户的属性特征,包括注册时间、个人简介、关注对象、粉丝、互粉数量、点赞数量等属性特征:{microblog:attribute1,attribute2,…,attributem}表示用户的一系列属性特征,包括推文的原创比例,转发比例,话题比例等属性。这些向量构成了一个ELM机器学习算法的输入值。在训练之后,得到一个分类模型,并以此来区分特定用户是否属于普通用户或垃圾用户。
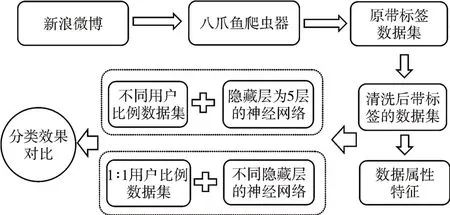
图1 基于RR-ELM的垃圾用户识别算法框架
3 数据和特征提取
目前虽然在UCI机器学习数据库有一些数据集,但是这些数据集只有数据属性,却没有标签。为验证本文微博网络垃圾用户识别方法的有效性,需从微博中爬取相关数据。本文使用八爪鱼抓取2018年8月1日到2018年9月27日多 个用 户 的粉丝和关注用户(分别为人工确认的正常用户的关注用户和非正常用户的粉丝用户)作为原数据集。通过查阅文献资料,默认手工标注的垃圾用户的粉丝同样为垃圾用户,正常用户的关注用户为正常用户[12],由此得到充足数据集,且可以省去耗费人力物力财力的人工标注的繁复步骤(且时间跨度大的人工标注往往无法保证准确率),提取的信息包括用户信息、用户行为信息、文本内容信息。
特征提取主要包括基于用户信息、基于用户行为信息、基于文本信息、基于用户关系网络等四方面[13]。但是由于基于用户关系网络需要数据量大,用户关系错综复杂,分类效果不佳,故常常提取前三个方面的特征。
4 实验
4.1 RR-ELM和ELM对比
通过微博爬虫手工标注的垃圾用户的粉丝和正常用户的关注用户得到数据集。首先通过运行SVM代码得到如下准确率。
在pycharm中 运 行ELM和RR-ELM的python程序,我们将隐藏层设置为5时,垃圾用户和真实用户的比例分别设置为5∶1,3∶1,1∶1,1∶3,1∶5五种比例,ELM的准确率为和RR-ELM的准确率如
从上表中可以直观地看出,神经元数目对于两种神经网络的分类效果影响较大。
通过查阅资料得知,SVM往往在经典机器学习分类中分类效果之最[14]。同样,当垃圾用户和真实用户比例设置为1∶1时,C值分别设置为0.1、0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9、1,且核函数为线性时,训练得到的SVM分类器的分别对于训练集和测试机的分类准确率如表2。
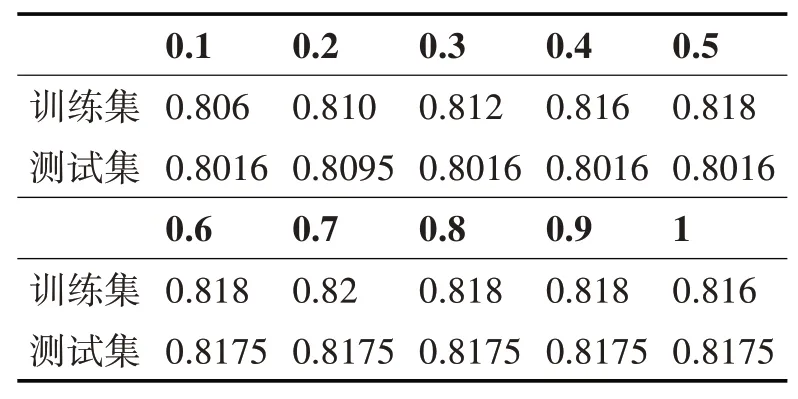
表2 惩罚系数C
将核函数的线性函数换成RFB径向基函数,惩罚函数设置为0.8时,在γ值不同的情况下的分类效果。
4.2 实验结果评价
从表1中可以看出,当垃圾用户和正常用户的比例为1∶1时,分类效果是最好的,且RR-ELM的分类效果总是好于ELM。究其原因,只有当垃圾用户和正常用户的比例达到一定的均衡接近实际比例时,训练得到的分类器才具有普适性,而比值越远1∶1效果越不好。同时可以猜测新浪微博用户是否几乎有一般的用户都是机器人操控的,分别通过不同的利益团体执行不同的任务,左右舆论和商业市场的走向,这对于社交平台的自我认识,对于未来的品牌提升思考也有一定的借鉴意义[15]。
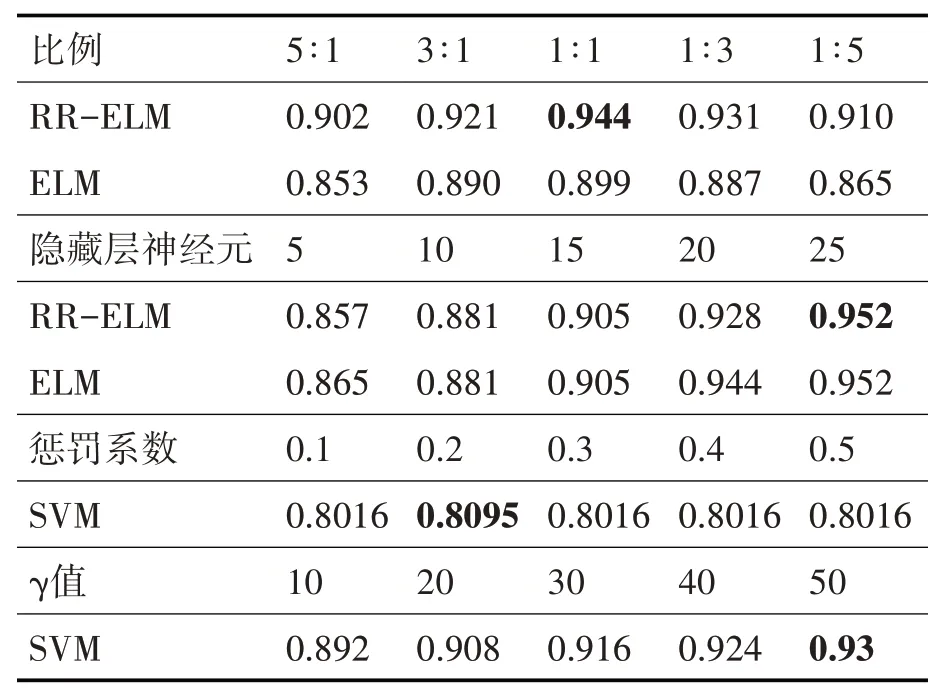
表1 不同影响因子下的准确率
另外从表1中可以看出,随着隐藏神经元数目增加,RR-ELM和ELM的分类效果也越来越好,其中RR-ELM和ELM的分类效果相差很小。故而隐藏层神经元数目对于分类器的影响相较于数据集用户比例的影响相对较小。当构建分类器时,需要注意两个因素孰轻孰重。
从表2中可以看出,刚开始时SVM对于训练集和测试集两者分类效果差别较大,但当逐渐增大C值时两者的分类效果逐渐趋于一致。且对于测试集的分类效果随着C直接增加,先下降后上升,效果不是很稳定。由于分类器是由训练集训练得到的,故对于训练集的拟合效果较好。
从表3中可以看出,径向基核函数相较于线性核函数的分类效果好很多,同样训练集的分类效果也比测试集的分类效果更佳,同样由于分类器是由训练集训练得到的,故对于训练集的拟合效果较好,分类准确率也比较稳定。
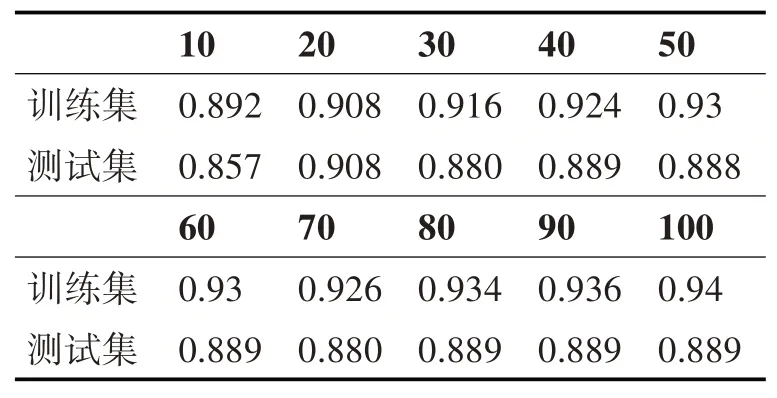
表3 γ值
5 结语
本文的主要贡献在于优化了ELM的处理能力,并给出了分类效果最好时的正常用户和垃圾用户用户比例,最佳比例为1∶1;RR-ELM分类效果也会随着神经网络的隐藏层神经元数目增加而增加。本文还得出SVM达到较好分类效果的时候惩罚系数C值和径向核函数γ值的值范围。
但是在多样化特征的社交网络用户中,任何数量的标记数据都是不足够的,只有尽可能多数量的采样,才能更好地接近实际情况[16]。为了弥补这一缺憾,未来的工作可以着手对于其他代价函数的改进对比和基于少量标记数据的半监督学习模型等,以期达到更好的分类效果。
