基于机器学习的无线网络规划覆盖性能定量评价
2021-11-25肖振锋伍晓平徐志强刘浩田马洁明伍仁勇
肖振锋,伍晓平,徐志强,刘浩田,马洁明,伍仁勇
(1.国网湖南省电力有限公司经济技术研究院,湖南长沙,410004;2.国网湖南省电力有限公司,湖南长沙,410004;3.湖南大学信息科学与工程学院,湖南长沙,410082)
在智能电网中,电力无线网络可以基本满足输变电和配用电网智能全覆盖、信息全采集的通信需求[1],但具有投资大、建设周期长、技术实现复杂等缺点。网络覆盖面、传输容量都会制约通信网络的整体性能和投资收益,木桶效应明显。为实现网络覆盖、传输容量和投资三者之间的平衡,必须根据地区社会经济发展规划对无线网络进行准确规划[2],而网络覆盖是网络规划工作的关键。基站分布和通信参数规划直接决定了网络覆盖性能[3]。对无线网络规划方案的覆盖性能进行评估,可以提前发现网络规划方案不合理之处,进而指导网络规划方案不断改进与完善[3],提高最后工程投入-产出比。现有覆盖性能评价一般只是根据无线传播模型进行正向仿真,已有部分商业工具软件可以实现此类的性能仿真和评估,但这些技术路线往往还需要结合大量实地参数测量和覆盖模型理论分析,成本很高,且对从业人员专业技能有一定要求,难以推广使用,目前通常凭借技术人员的经验对网络规划方案优劣进行定性判断,而这常导致建成后的网络有效覆盖面出现较大偏差,技术指标与业务需求不匹配。近年来,各种机器学习新算法不断涌现[4-5],随着电力业务量和通信网络技术的不断积累,人们尝试找到与之匹配的网络规划覆盖性能评价方法,提高投入-产出比。通过构造符合当地实际的无线环境数据模型以及网络规划方案对应的无线特征,预测网络建成后的覆盖性能,最终得到网络规划区域内覆盖性能的优劣评估(0-1 标签标定)的准确数据,相对于传统技术路线,可以减少大量参数实测和理论分析工作。网络规划方案的覆盖性能评价是一个典型的分类问题,与机器学习中的分类思想相符。在解决分类问题方面,有KNN(K 最近邻算法)[6]、RF(随机森林算法)[7-8]、DT(决策树算法)[9-10]、GBDT(梯度提升决策树算法)[11]等多种机器学习算法[12-13]。本文应用随机森林算法,采用集成学习[14]的思想集成多棵独立的决策树,通过建立多个分类器的组合来解决单一预测问题。
1 机器学习和问题描述
机器学习是一个复杂迭代的过程。没有任何集成工具可用于整个机器学习处理流程,需要将工具和处理流程结合在一起才能解决实际工程问题。
1.1 机器学习
机器学习是一种数据分析技术,算法直接从大量历史数据中“学习”信息,而不依赖于预定程序模型。当可用于学习的样本数量增加时,这些算法可自适应地提高性能。机器学习总是从一个明确的问题和目标开始,图1所示为机器学习的一般过程。

图1 机器学习的一般过程Fig.1 General processes of machine learning
1)收集数据。数据可以来自电子表格、文本文件和数据库等。适合的数据数量和种类越多,机器学习模型就越精确。
2)准备数据。包括数据清理和解析、删除或纠正异常值(失控的错误值),然后,将数据分成训练数据和测试数据两部分。
3)训练模型。针对一组训练数据(用于识别数据中的模式或相关性)和测试数据(用于预测或分类),使用重复测试和误差改进方法来逐步提高模型精度。
4)评估模型。通过比较结果与测试数据集的准确度来评估模型。为了确保测试是无偏的和独立的,不能对用于训练模型的数据集进行模型评估。
5)部署和改进。可以尝试不同算法或者收集更多种类或更多数据,以提高模型预测或分类的准确度。
1.2 结合机器学习的网络覆盖性能评价
无线网络规划方案的覆盖性能评价是对网络覆盖区域内的无线信号范围和质量优劣进行判定,属于分类问题,图2所示为该分类问题的示例。从图2可知网络覆盖性能以无线信号质量(广播控制信道接收功率)是否达标作为主要评判标准,接收功率大于-80 dB·mW 表示无线信号质量优,标记为1,反之标记为0。最后,根据各地网络覆盖情况,得到网络规划方案的整体网络覆盖性能。显然,这个过程与机器学习过程高度契合。本文基于机器学习中的随机森林算法构建网络规划方案覆盖性能评估模型。

图2 无线信号质量分类示例Fig.2 A classification example of wireless signal quality
2 覆盖性能定量评价
覆盖性能评估模型的训练实际上就是通过对大量历史数据蕴含的统计知识进行学习和固化,不断优化评估模型的参数。
2.1 数据准备
影响无线网络覆盖的因素有很多,上行包括基站接收灵敏度、天线分集增益、终端发射功率、传播损耗等,下行包括有效全向辐射功率、总发射功率、路径损耗、信号频段、终端距离基站的距离、天线增益、天线挂高、下倾角、方位角、点播传播场景(市区和郊区)和地形环境(平原、山区和丘陵)等[3]。在设计和构造无线网络数据模型时,特征越多、越准确,则最终模型的预测结果越准确。
另一方面,这些影响因素之间往往存在着某些相关性,如发射功率直接影响传输距离,天线挂高则可以影响路径损耗。若对数据不进行任何处理直接应用于随机森林算法训练,则可能使森林中不同树之间具有较强的相关性,导致分类准确率下降。本文采用ZCA(zero-phase component analysis,零相位分量分析方法)[15]白化方法,首先将原始数据映射到新的特征空间,使数据各维度特征间独立不相关,再将数据映射回初始空间,使处理后的数据更加接近原始数据,并保证数据各维度的方差相同。
例如,给定含有m个样本、维度为n的数据集X,即X∈Rn×m,对其进行ZCA 白化的算法步骤如下。
1)计算数据集的协方差矩阵Σ:

2)对协方差矩阵进行奇异值分解得到特征向量u1,u2,…,un,可以得到特征向量矩阵U,利用UTX得到数据集经过旋转后的结果Xrot,即
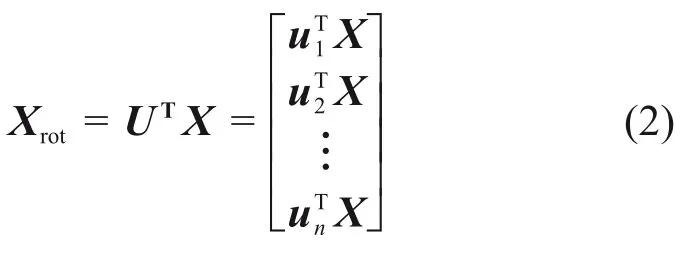
3)对数据集进行PCA(principal components analysis)[15]白化,将Xrot中的每一维都除以λi(其中,λi为协方差矩阵对角线元素),使输入特征具有单位方差。PCA白化定义为

4)将XPCAwhite,i与特征向量矩阵U相乘,得到需要的ZCA白化:

上述过程保留了数据的全部n个维度,得到的数据更加接近原始数据。
2.2 评估模型构建
网络规划方案覆盖性能评估本质上可以归为1个二分类问题。
2.2.1 构建数据集
根据目标区域历史数据中的标志(ID)字段查询获得的基站信息,然后根据对应地点经纬度、基站经纬度、方位角等计算距离和方位角差角。结合以往经验并考虑数据获取难易程度,本文选择8个特征,共同构成输入向量为

式中:d为终端距离基站的距离;p为基站发射功率;z为基站天线方位角差值;n为基站天线下倾角;h为基站高度;f为基站频率;c为覆盖类型对应的类别号;b为基站类型对应的类别号。定义无线信号质量阈值T,输出以该阈值T为分割点,广播控制信道接收大于T的数据设置标签为1,小于T的数据设置标签为0。
对大小为m的原始数据集Sn,采取自助法(bootstrap)重采样技术,随机且有放回地从原始数据集中抽取m0个样本(其中m0<m),重复w次,构建出w个不同的训练子集Sn1,Sn2,…,Snw。
2.2.2 生成决策树
应用CART[16]算法构造决策树。决策树每个内部节点表示一个属性上的测试,每个分支代表1个测试输出,每个叶节点代表一种类别。每个样本的特征维度记为n,随机地从n个特征中选取c个特征(其中c<<n),利用这些特征对选出的训练样本建立决策树。在决策树构造过程中,每次分裂时都从特征中选择最优的一个特征,每棵树都最大程度地生长,没有剪枝过程,这样降低了树之间的相似性,使得随机森林不容易陷入过拟合,具有较强的抗噪能力。
2.2.3 构建组合分类模型
重复上述过程,对w个不同的训练集进行训练生成w棵决策树,从而形成随机森林。显然,w棵决策树对应w个不同的分类模型,然后集成所有分类模型的投票结果,将投票次数最多的类别指定为最终的分类结果,构成如下多模型分类系统:

其中:H(x)为组合分类模型;h(xi)为第i棵决策树的分类模型;Vmajority_vote表示多数投票决策机制(算法)函数;w为决策树数量。该组合分类模型的构建利用了当地的历史数据,是对当地无线网络覆盖模型的重构,与当地的无线使用环境保持一致。
2.2.4 模型参数优化
构建随机森林分类模型的关键是确定特征数量c和决策树数量w的最优参数,这可以通过计算袋外错误率(out-of-bag error)[17]来判决。一般约有1/3 的训练样本没有参与第k棵树的生成,这些样本即为第k棵树的袋外(out-of-bag)样本。袋外错误估计可以分为3步。
1)假设共有w棵决策树,则对数据集中的1个样本xi而言,它作为袋外样本的树约为w/3棵,这也意味着该样本可以作为这w/3 棵树的测试样本,然后计算这w/3棵树对该样本的分类情况。
2)对w/3棵树的分类结果进行简单投票,并以多数投票结果作为该袋外样本的分类结果,其预测误差就是xi在这个随机森林上的袋外错误率,以Ei表示。
3)将每个袋外样本的预测结果与真实值进行比较,用分类错误个数占数据集中样本总数的比率作为整个随机森林的袋外错误率,以E表示。即整个随机森林的袋外错误率就是所有训练样本的平均袋外错误率,袋外错误率越低,表示模型的分类性能越好。

2.2.5 模型性能评价
由于存在袋外样本,随机森林算法无需进行交叉验证或用独立的测试集来获得误差的一个无偏估计。但与其他机器学习分类算法进行横向比较时,仍然需要采用交叉验证来评估模型的分类性能,而混淆矩阵[18]是所有评价指标的基础。表1所示为混淆矩阵,其中Tp表示将正类(真实值为1)预测为正类(预测值为1)的次数,Fn表示将负类(真实值为0)预测为负类(预测值为0)的次数,Tn表示将正类(真实值为1)预测为负类(预测值为0)的漏报次数,Fp表示将负类(真实值为0)预测为正类(预测值为1)的误报次数。

表1 混淆矩阵Table 1 Confusion matrix
模型的具体评价指标通用的有精度P、召回率R与综合评价指标F1。其中,精度P表示被分为正类的样本中实际为正类的比例,其计算公式为

召回率R是对模型预测覆盖面的度量,用于度量正类样本被正确分类的数量,其计算公式为

指标P和R有时候会存在矛盾,此时,引入F1评价不同算法分类性能。F1综合考虑P和R,对P和R进行加权调和平均,F1较高,表明模型预测效果比较好,其计算公式为

3 性能仿真与分析
3.1 仿真环境和数据处理
仿真程序使用Python 语言开发,数据处理和模型构建分别利用Python 的pandas 和scikit-learn[19]这2 个模块编码完成。原始数据集有30 万行,为某地历史路测数据。在数据准备阶段,进行一系列清洗和转换,包括删除其中信息缺失或重复的数据、采用ZCA 方法去除相关性以及对数据进行标记处理等。数据标记时,取无线信号质量阈值T为-80 dB·m,广播控制信道接收功率大于T表示信号质量优并设置标签1,小于T表示信号质量差并设置标签0。由于信号强度有一定波动性,在同经纬度、同小区识别码情况下,可能会出现各项无线网络特征相同但标签不同(0 和1 共2 种)的情况,干扰分类模型训练。此时,对广播控制信道接收功率计算并取平均值,确保同一无线网络特征对应的标签只有1个。
特征数量c和决策树数量w这2 个参数是构造决策树的关键。在通常情况下,随着决策树数量w增加,随机森林通常会收敛到更低的误差。图3所示为随机森林的袋外错误率E随决策树数量w的变化情况,其中袋外错误率取10 次实验结果的平均值。从图3可见:随着决策树数量增加,预测模型的袋外错误率快速下降,模型预测能力快速提高;但当决策树数量增加到400时,袋外错误率基本收敛,不再变化,继续增加决策树数量,模型性能不仅不会得到明显提升,而且会由于运算量增加使得程序运行变慢,因此,本文选择w为400。

图3 袋外错误率E与决策树数量w的关系Fig.3 Relationship between out-of-bag error and number of decision trees(w)
图4所示为随机森林的袋外错误率E随特征数量c的变化情况,取10 次实验结果的平均值。从图4可见:当特征数量较小时,袋外错误率较高,表明模型的预测能力较弱;随着特征数量逐渐增加,袋外错误率逐步下降,模型的预测能力逐步增强;但当特征数量大于4时,袋外错误率反而上下波动,模型的分类能力表现出不稳定现象。这是由于当特征数量增加到一定程度时,决策树之间的相关性越来越高,反而影响模型的性能,因此,特征数量并非越大越好,本文根据实验结果,取特征数量c的最优值为4。

图4 袋外错误率E与特征选取数量c的关系Fig.4 Relationship between out-of-bag error and number of features(c)
3.2 预测与评估
以某地电力无线网络规划为例。为解决网络弱覆盖问题,现对2个依据不同设想提出的无线网络规划方案进行评估,其中基站类型全向天线用1表示,扇形天线用2 表示;覆盖类型1 表示山区,2表示平原。表2所示为2个方案的相关信息,

表2 2个不同的无线网络规划方案Table 2 Two different wireless network planning schemes
首先根据上述每个无线网络规划方案提供的信息构造1个数据格式与训练数据一致的预测数据集。如根据基站信息构造训练数据的各种特征字段,使用网络规划方案提供的信息构造预测数据,构造距离、基站功率、方位角、下倾角、基站高度、基站频段、覆盖类型等无线网络特征。在预测数据集中,每一个数据都对应1个测试点的网络特征。然后,将根据无线网络规划方案构造的预测数据集导入评估模型进行预测,预测数据集中的每一组输入数据均对应1个预测结果。最后,将预测结果中广播控制信道接收功率大于无线信号质量阈值T的测试点数除以总的测试点数,得出该方案下广播控制信道接收功率大于无线信号质量阈值T的占比。该量化数据即为该网络规划方案的覆盖性能(覆盖合理度)的评估指标。
将-80 dB·m 作为无线信号质量阈值时的网络覆盖度评估结果见表3。由表3可知:当无线信号阈值取-80 dB·m时,方案1和方案2的网络覆盖度约为97%,非常接近。

表3 -80 dB·m作为无线信号质量阈值时网络覆盖度评估结果Table 3 Evaluation results of network coverage when-80 dB·m is used as wireless signal quality threshold
当上述网络覆盖合理度评估结果非常接近而无法分辨时,设置更高、更严格的无线信号质量阈值T(取值为-70 dB·m),重新训练模型,对网络规划方案进行进一步评估、对比和区分。表4所示为-70 dB·m 作为无线信号质量阈值时的网络覆盖度评价结果。从表4可见:2 种网络规划方案覆盖性能的评估结果中,方案2比方案1的网络覆盖度高,方案2位更优方案。这说明随着无线信号质量阈值T进一步提高,模型对无线信号质量优的判断标准提高,模型的分辨能力增强。

表4 -70 dB·m作为无线信号质量阈值时网络覆盖度评估结果Table 4 Evaluation result of network coverage when-70 dB·m is used as wireless signal quality threshold
为进一步比较随机森林算法相比其他分类算法的优势,将随机森林算法与KNN(K 最近邻算法)、GBDT(梯度提升决策树算法)进行对比,采用交叉验证方法评估不同模型的预测性能。将数据集进行处理后按照9∶1的比例拆分为训练集和测试集,其中训练集用于训练模型,测试集用于评估模型的泛化能力。表5所示为3种模型的参数选择及预测能力评估指标。从表5可见:随机森林算法模型的预测精度P、召回率R与综合评价指标F1等更高,表明该模型具有更强的泛化能力和更高的预测准确率,验证了随机森林算法采用集成学习思想构建的组合分类模型比单一模型的预测能力更强。
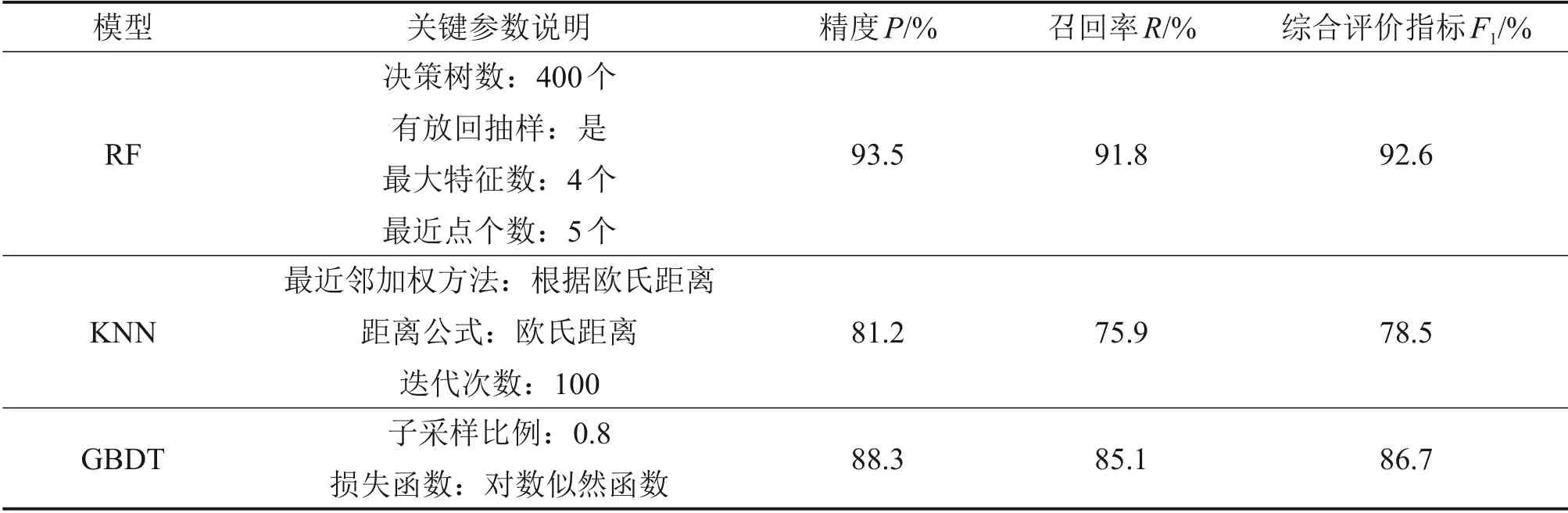
表5 3种模型性能比较Table 5 Performance comparison of three models
4 结论
1)提出一种新的基于机器学习的无线网络规划覆盖性能定量评价方法。该方法首先通过各地历史数据重构无线网络覆盖模型,较好地适应当地的无线使用环境。根据模型数据对网络规划方案进行评估,为网络规划方案的选择或判断提供了快速、准确的量化判断依据。
2)所提出的评价方法虽然基于传统算法,但能够快速、准确地进行量化评估并能区分各规划方案的覆盖性能优劣。
3)当决策树较多时,本文采用的随机森林算法的训练时-空开销较大,特别是当训练样本数据集中的噪声较大、决策树层级过多时,存在陷入过拟合的问题,影响模型预测的准确性和稳定性,这有待进一步研究。
