基于驾驶行为模式转移的驾驶行为风险评估方法*
2021-11-25孙宫昊荣建常鑫刘思杨高亚聪
孙宫昊 荣建 常鑫 刘思杨 高亚聪
(1.北京工业大学,北京 100124;2.中国民航大学,天津 300300)
主题词:驾驶行为 驾驶风险 模式转移概率 随机森林
1 前言
研究表明,90%的交通事故与驾驶人的因素有关[1]。因此,以提升驾驶人的安全水平为切入点,准确评估驾驶行为风险,从而有针对性地开展驾驶行为培训,是提升道路交通安全水平的有效方法。同时,车辆智能化、个性化服务是未来车辆技术发展的重要趋势,驾驶人行为风险的评估研究对推动车辆智能化产品的应用具有重要意义。
目前,基于客观驾驶数据的驾驶行为风险评估方法主要分为通过识别驾驶行为事件的驾驶行为风险评估、基于驾驶行为特征参数建模的驾驶行为风险评估两种。在基于识别驾驶行为事件的驾驶行为风险评估研究中:Toledo 等通过驾驶行为数据识别加速、减速、换道等事件,结合驾驶事件的风险程度与频率,构建了综合指标评估体系,将驾驶风格分为3 类[2];吴振昕等从数据库中提取7种典型驾驶工况,利用K均值聚类和D-S证据理论方法进行聚类,将驾驶风格分为3类[3];Brombacher 等利用神经网络算法将纵向驾驶行为事件分为加速和紧急制动行为,横向驾驶行为事件分为轻度转弯、中度转弯和紧急转弯,根据驾驶行为事件的发生频率进行风险评分,将驾驶人分为5 类[4]。在基于驾驶行为特征参数建模的驾驶行为风险评估研究中:朱冰等利用跟车过程中的驾驶数据作为特征指标,建立了基于随机森林的驾驶人驾驶行为风险辨识模型[5];李经纬等采集商用车和乘用车的驾驶行为数据,通过主成分分析方法实现特征指标降维,利用K均值聚类方法进行驾驶风格的识别[6];Van Ly 等获取速度、加速度、制动踏板开度等数据,利用支持向量机(Support Vector Machine,SVM)和K均值聚类算法对驾驶人进行分类[7]。
综上,驾驶行为风险的评估研究多以驾驶操作层面的驾驶行为参数统计数据或驾驶行为事件层面的行为事件频率作为评估特征指标,缺乏考虑驾驶行为在时间序列上的连续性变化特征。因此,本文从驾驶行为的时空维度出发,以驾驶行为模式间的转移特性直观反映驾驶人在驾驶过程中的行为偏好,构建驾驶行为风险评估模型,实现对驾驶人客观行为风险的评价。
2 试验设计与数据采集
2.1 试验设备及场景
使用驾驶模拟试验平台模拟真实车辆的驾驶,并收集驾驶模拟器产生的试验车自身及周边车辆的位置、距离等数据信息[8]。驾驶模拟器(见图1)以20 Hz 的频率记录车辆的运行数据。

图1 驾驶模拟器
选取双向四车道的兴延高速公路的部分路段作为驾驶模拟仿真道路,试验路段长6.6 km,每条车道宽3.75 m,道路限速120 km/h。试验基本路径如图2所示,模拟试验道路由试验过渡路段与试验正式路段组成,为使驾驶人在正式试验前熟悉且适应操作,设置试验过渡路段为1 km。正式路段总长为5.6 km。

图2 试验基本路径
2.2 试验测试与数据提取
共招募35 名驾驶经验丰富的驾驶人,其中男性驾驶人20 人,女性驾驶人15 人,年龄分布在23~55 岁之间,平均年龄为35.8岁(标准差为11.3岁),平均驾龄为12.1 年(标准差为8.9 年),每位驾驶人均拥有C 级机动车驾驶证。同时,为了避免其他身体因素的影响,要求驾驶人在试验前身体状况良好并且避免大量进食。为确保试验的高效性和数据的有效性,试验包括预试验和正式试验,预试验在非正式试验场景下进行,以确保驾驶人适应模拟驾驶。正式试验中,为还原驾驶人真实的驾驶习惯,每一名驾驶人在整个驾驶过程中根据其自身驾驶习惯完成整个路段的行驶即可。
模拟设备以20 Hz的频率记录车辆的运行数据,可采集包括采样时间、本车X坐标、本车Y坐标、侧向位移、速度、加速度、油门踏板开度、制动踏板开度、行驶距离、与前车的距离、前车速度等驾驶特征指标数据。同时,本文根据车头间距、前车速度及自车速度计算车头时距及其变化率,表现驾驶人的跟驰变化特性:

式中,a为车头时距;h为车头间距;u为车头时距变化率;v1为自车速度;v2为前车速度。
驾驶人的部分驾驶行为数据如表1所示。

表1 部分驾驶行为数据
3 驾驶行为模式转移特征数据库构建
3.1 驾驶行为模式分解模型
驾驶行为模式是驾驶人根据所处驾驶环境,为使车辆达到预期运动状态,在一段时间内的连续操作变化[9]。在城市道路环境下,存在违规掉头、加塞等风险行为,驾驶行为模式构成复杂,因此,本文的研究范围为高速道路环境下非违法行为的驾驶模式辨识。通过参考驾驶行为分解模型[10],梳理驾驶行为辨识指标,基于车辆运行数据,对高速道路环境下的驾驶行为模式进行辨识,将纵向驾驶行为模式分解为自由直行(A1)、接近(A2)、远距离跟驰(A3)、中距离跟驰(A4)、近距离跟驰(A5)、渐远(A6)和紧急制动(A9)7种,横向驾驶行为模式分解为受限换道(A7)和自由换道(A8)2种。
在纵向驾驶模式的分解上,根据心理-生理驾驶行为模型,将纵向驾驶模式分解为自由直行、接近、跟驰、渐远、紧急制动5种[11]。在高速道路上,有约98%的情况纵向加速度小于3 m/s2,因此,将纵向减速度大于3 m/s2的驾驶行为模式辨识为紧急制动模式[12]。本文采用《美国道路通行能力手册》中对跟驰及自由状态的定义,当车头时距小于或等于3 s 时,认为车辆处于稳定跟驰状态[13]。因此,当车头时距大于3 s时,则认为车辆处于自由直行状态。根据心理-生理模型,驾驶人在跟驰过程中难以准确判断自车与前车的速度差,因此,跟驰过程中车头距离并不会保持稳定,而是随着自车加速、减速不断调整。因此,当自车速度大于前车速度,与前车距离逐渐缩小时,辨识为接近状态,当自车速度小于前车速度,与前车距离逐渐增大时,辨识为渐远状态。研究表明,车头时距变化率可用前车视角的变化衡量,进而判断车头间距的增大或减小,从而细致化区分跟驰状态,分别以跟驰时距的变化率0.03 和-0.03 为阈值将跟驰模式细分为接近、稳态跟驰和渐远模式[14]。同时,由于驾驶人的超速等原因,高速公路上追尾事故频发[15],当车头时距较小时,发生紧急情况,留给驾驶人的反应时间很短,极易发生交通事故。因此,在跟驰模式中,不同跟驰时距的危险程度也不相同。根据Li对跟驰状态的定义,以车头时距1 s 和2 s 为阈值,将稳态跟驰细分为远距离跟驰、中距离跟驰和近距离跟驰3 种模式[10]。纵向驾驶行为模式辨识模型如图3所示。

图3 纵向驾驶行为模式辨识模型
根据前方是否有车辆,将横向驾驶行为模式分为自由换道和受限换道[16]。自由换道是驾驶人根据自身意愿,在没有其他车辆干扰的情况下的换道行为。受限换道为驾驶人认为前车干扰自身行车,从而进行换道的行为。本文利用横向侧位移和车头时距实现对换道模式的辨识。横向侧位移表示车辆中心对车道边线的偏移距离,负值表示车辆向左侧车道边线偏移,正值表示车辆向右侧车道边线偏移。若驾驶人在模拟路段上的横向侧位移指标的符号发生突变,将其辨识为换道行为,在换道时,若车头时距大于3 s,辨识为自由换道,反之,则辨识为受限换道。
3.2 驾驶行为模式转移概率
在一段时间内,由于驾驶人生理、心理的特征差异,会有不同的驾驶行为模式调整方式:有些驾驶人会跟随前方车辆的状态行驶,有些驾驶人则会进行频繁换道达到目标车速。驾驶行为模式转移可以是从一种驾驶行为模式转移到另一种驾驶行为模式,或是保持自身驾驶行为模式不变,如图4所示。

图4 驾驶模式转移
为描述驾驶行为时空数据中2 种模式间的转移特性,首先需要对转移时间窗进行选择。本文驾驶模式转移时间窗选取的目的是计算2 种模式间的转移概率。数据采集周期为0.05 s,因此,选择0.1 s 的时间窗宽描述模式间的转移特性。如图5所示,以自由直行和跟驰2种模式为例,一个时间窗内包含2个模式数据,可以表示为保持自由模式、跟驰模式不变,或从直行转移至跟驰以及从跟驰转移至直行4种转移方式。
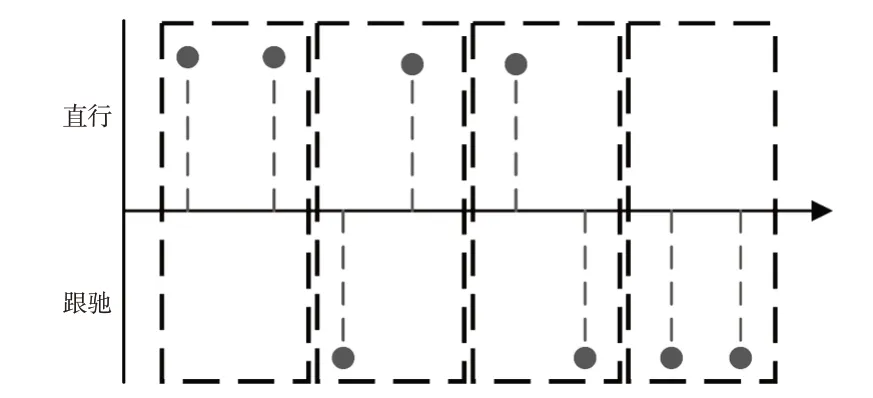
图5 驾驶模式决策过程
驾驶行为模式转移概率为在某一模式i后发生模式j的概率,当统计数据量足够大时,统计的模式转移概率通过模式的转换频率来表示:

式中,qt为驾驶人在t时刻的驾驶行为模式;p表示概率;Mi、Mj为第i种、第j种驾驶行为模式,1≤i,j≤N;N=9为驾驶行为模式种类;w为驾驶行为模式转移次数;aij∈[0,1]为驾驶行为模式转移概率。
在前向驾驶行为模式相同的情况下,9种驾驶行为模式转移概率之和为1。针对每名驾驶人可以构造出由81 种(9×9)驾驶行为模式转移概率值组成的驾驶行为模式转移矩阵O={aij}。因此,共有81 个特征组成评估驾驶人行为风险的候选特征指标集:

3.3 基于德尔菲法的驾驶行为风险评定标签
德尔菲专家咨询法是20世纪50年代美国兰德与道格拉斯公司合作研制的一种直观预测技术,具有匿名性、及时反馈性和统计性的优点[17]。本文基于德尔菲咨询法对驾驶人的驾驶行为风险等级进行评估,得到驾驶人的驾驶行为风险等级标签,以此作为驾驶风险评估数据集中的风险分类标签集,并作为比对标准验证驾驶行为风险评估模型的评估效度。
选取来自相关企业、高校、科研机构等的17 名专家,对每位驾驶人的驾驶行为风险程度进行评价,共分为安全、一般和危险3个风险程度。专家评价调查表由35 位驾驶人的驾驶模式图像和驾驶行为参数2 个部分组成,驾驶模式图像根据驾驶人在试验路段上的驾驶模式变化情况绘制,驾驶行为参数包括速度、加速度、车头时距等。一种典型驾驶人的驾驶状态变化图像如图6所示,从图6中可以看出,该驾驶人在1 800 m 和4 000 m左右的位置处进行了紧急制动,在4 500 m处迫近前车并跟驰行驶,随后减速行驶,与前车逐渐拉开距离,在短暂的跟驰行驶后,换道超车,保持自由状态行驶。由此可知,该驾驶人为达到自身驾驶目的,频繁地进行不同驾驶行为模式的变换,风险程度较高。

图6 驾驶人的驾驶转移模式图像
评估结果的专家权威程度由专家对研究任务的熟悉程度与判断依据两方面决定。通常认为专家权威系数≥0.7,即具有较好的权威性,本研究的专家权威系数为0.81,权威性较高,评价结果可靠性较强。专家意见的协调水平可以判断专家意见的一致性程度,主要用Kendall 协调系数W表现,W∈[0,1],其值越大代表专家意见的一致性越好。进行2 轮专家咨询的专家意见协调系数分别为0.453和0.488,具有90%置信度的显著性差异,说明专家意见分歧较小。根据专家评估的结果对所有参与试验驾驶人的驾驶行为风险程度进行分类,得到安全型驾驶人样本24个,一般型驾驶人样本6个,危险型驾驶人样本5个。
综上,结合驾驶模式转移特征指标集和驾驶人风险评定标签集,可以获得驾驶人行为风险评估特征数据集,并用于驾驶人行为风险评估模型的构建及分析。
4 基于模式转移的驾驶行为风险评估
4.1 特征指标相关性排序
为从众多特征指标中选取能够有效表征驾驶模式转移特征的子集,本文首先基于最大信息系数(Maximal Information Coefficient,MIC)分析各变量之间的相关性及冗余性,得到各参数与驾驶行为风险等级的相关性排序,接着通过随机森林算法,以分类准确率为判别准则,采用序列前向选择的方法进行特征子集的优选。
2011 年,Reshef 等首次提出MIC 算法理论,相较于互信息理论,MIC在度量变量间的关联程度上具有更高的准确度[18]。该算法用来衡量2个变量之间的相关性、线性或非线性关系。其计算公式为:

式中,Q为MIC值;E、F为变量;D为数据集;n为数据规模;B为关于数据规模n的函数;I为最大互信息值;M为特征矩阵。
最大信息系数的取值范围为[0,1],最大信息系数为0表示2个变量间相互独立,最大信息系数为1表示2个变量之间存在线性或非线性的关系,随着最大信息系数的增大,2个变量间的相关性增强。
计算81个驾驶行为模式转移值和驾驶行为风险等级的最大信息系数,将81 个驾驶行为模式转移方式与驾驶行为风险的相关性从大到小排序,结果如图7 所示,排在前12 位的驾驶行为模式转移方式与驾驶行为风险有着较高的相关性。当驾驶行为模式达到第13位时,最大信息系数值下降明显,且逐渐趋于平稳,与驾驶行为风险相关性较低,最终降为0,因此剔除第13 位及以后的低相关性特征指标。其中,自由换道→自由换道和自由换道→自由直行之间的最大信息系数达到0.72,2 个变量间具有较高的冗余性,同时,自由换道→自由换道的最大信息系数为0.36,自由换道→自由直行的最大信息系数为0.29。因此,自由换道→自由直行为自由换道→自由换道的冗余指标,筛除自由换道→自由直行。筛选出11个相关性最大的驾驶行为模式转移方式构成候选特征指标集,分别为:自由直行→紧急制动、自由直行→自由直行、自由直行→迫近、迫近→迫近、自由换道→自由换道、迫近→紧急制动、自由直行→自由换道、迫近→受限换道、受限换道→自由直行、受限换道→受限换道、紧急制动→紧急制动。

图7 驾驶行为模式转移方式与驾驶行为风险的相关性
4.2 特征指标优选及随机森林算法构建
机器学习有着完整的理论框架,且预测性能较好,因此在各研究领域中得到了广泛的应用。张宁等梳理了较多的预测模型,其中SVM有着良好的泛化能力,预测性能优于神经网络,但其参数的调整仍未有较好的确定方法[19]。Nadezda等使用K均值聚类、神经网络、决策树、随机森林等算法对驾驶人的驾驶风格进行识别分类,并比较各方法识别的准确度和优缺点,结果表明,随机森林算法有着优秀的分类性能,泛化能力强,且分类速度快,在实际问题中能够得到较好的应用效果[20]。本文通过对比随机森林算法和支持向量机算法的分类精度,选取分类性能较好的算法进行驾驶行为风险的评估。
(一)从政治意义看,习近平新时代中国特色社会主义思想,是新时代国家政治生活和社会生活的根本指针。从政党发展史看,拥有坚强的领导核心,拥有科学的指导思想,是一个政党形成凝聚力战斗力不可或缺的两个方面,也是政党走向成熟的重要标志。我们党确立习近平新时代中国特色社会主义思想的指导地位,确立习近平总书记的核心地位,对于维护党中央权威和集中统一领导,对于保证党和国家事业兴旺发达、长治久安具有重大而深远的意义,标志着我们这个走过97年光辉历程的世界第一大党,达到了政治上、思想上、组织上的空前团结和统一,为推进新时代中国特色社会主义事业提供了坚强政治保障。
随机森林和支持向量机算法均为有监督的机器学习算法,按驾驶行为模式与驾驶风险的相关性排序,将前11 个驾驶行为模式转移的概率作为输入特征,基于德尔菲法得到的专家评估结果作为数据标签。通过5折交叉验证和网格搜索法对算法参数调优,随机森林的基决策树数量调整为11棵,支持向量机的惩罚系数c调整为5,核参数d调整为0.1。采用5折交叉验证的平均准确率对模型的性能进行评估,其中,支持向量机算法的预测准确率为71%,随机森林算法的预测准确率为79%,随机森林算法的准确性更高,评估性能更稳定。因此,本文选择随机森林算法进行驾驶行为风险的评估。
特征优选可以降低模型的训练难度,提高模型分类速度和有效性,因此,根据驾驶模式转移特征指标的相关性进行排序,采用序列前向选择的方法,利用5 折交叉验证的平均值评估模型的分类精度。其中,基决策树数量、单决策树的最大特征数均采用网格搜索选取最优参数,交叉验证平均分类准确率达到最高时的算法参数,作为该轮迭代的随机森林算法的参数。
特征数量与辨识精度的关系如图8所示,当特征数量达到9 个时,驾驶行为风险的辨识精度达到最高的85.71%,且趋于平稳。因此,将前9 个特征指标作为基于随机森林算法的驾驶行为风险评估模型的输入特征,此时随机森林模型的基决策树数量为71 棵,最大特征数量为5,最优划分属性评判指标为Gini 值。前9 个特征指标分别是:自由直行→紧急制动、自由直行→自由直行、自由直行→迫近、迫近→迫近、自由换道→自由换道、迫近→紧急制动、自由直行→自由换道、迫近→受限换道、受限换道→自由直行。

图8 特征数量与检测精度的关系
4.3 驾驶行为模式转移风险特性分析
不同风险等级驾驶人的模式转移概率特性如图9所示。随着驾驶风险的升高,行驶时转移至受限换道的概率越高,安全型驾驶人较多保持自由直行模式,危险型驾驶人则有较大概率采用受限换道模式。驾驶风险越低,驾驶模式的转移形式越单一,驾驶风险越高,不同模式间的转移越频繁,驾驶人更倾向于通过多种驾驶模式之间的组合行驶,以达到缩短行程时间的目的。
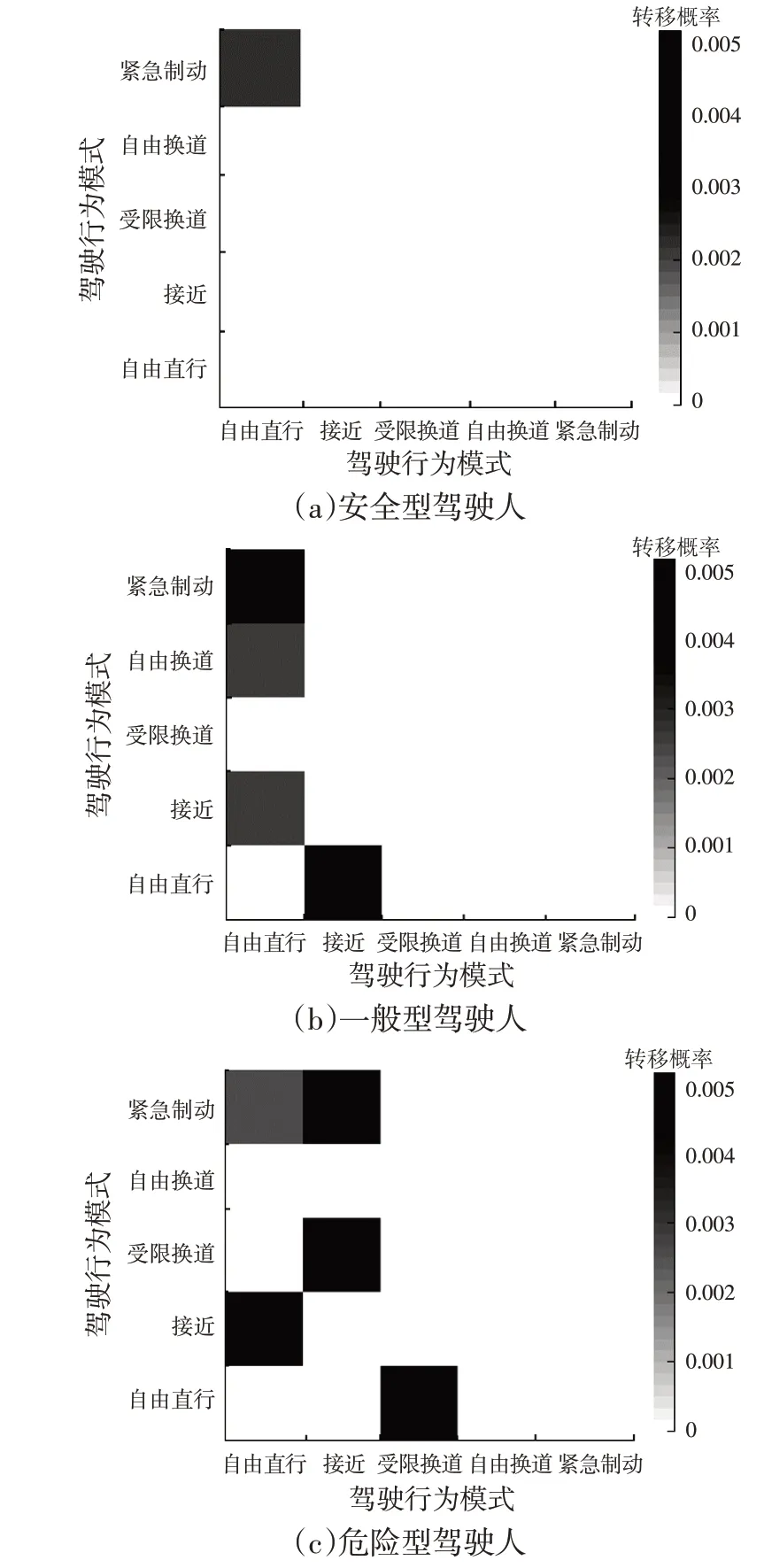
图9 不同风险等级驾驶人的驾驶模式转移概率
4.4 驾驶行为风险评估模型验证
随机森林分类器的分类结果与驾驶行为风险评估标签对比如表2所示,总体辨识精度为85.71%。由于部分驾驶人的驾驶风险存在向其他风险转移的趋势,因此,模型存在一定偏差。

表2 随机森林分类器的辨识结果 个
以往的驾驶行为风险评估研究多集中于通过驾驶行为数据的统计分析和数学建模实现驾驶行为风险的评估,因此,为进一步验证本文所提出方法的有效性,引用以往研究中一种基于驾驶行为特征参数建模的驾驶行为风险评估方法[21],依据本文所用驾驶行为数据建立分类模型,对比2 种方法的评估结果。
该方法中,选取车速超过限速80%的时间比例、车速平均值、车速标准差、总加速度标准差、加速度平均值、加速度标准差、减速度平均值、减速度标准差共8个参数作为驾驶行为风险分类的特征指标。利用因子分析的方法实现特征指标的降维,因子分数的计算公式为:
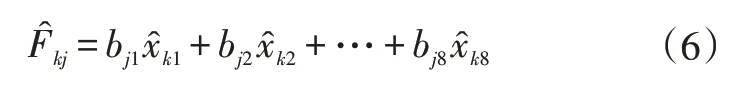
因子分数得分越高,驾驶人的驾驶行为风险越高。最后,利用系统聚类的方法将驾驶行为风险聚类为3类,系统聚类谱系如图10所示。

图10 系统聚类谱系
基于驾驶行为特征参数建模的评估方法识别准确率为60%,与本文所提出方法的评估结果相比,共有71.4%的样本识别结果相同,表明本文提出的方法与以往研究中使用的方法具有一定的一致性,同时,利用驾驶行为模式转移概率描述驾驶行为特征,并基于随机森林算法的驾驶风险识别模型辨识精度较高,可以满足驾驶风险的识别需要。
5 结束语
本文基于客观驾驶行为数据的时空特性,以驾驶人的连续驾驶行为模式变化表征驾驶操纵特征,利用驾驶行为模式之间的相互转移概率作为特征指标,借助最大信息系数、随机森林算法优选可有效表征驾驶人行为风险的驾驶行为转移模式,进而基于随机森林算法构建驾驶行为风险评估模型,实现了对驾驶人客观行为风险的评价,获得以下结论:
a.相比于传统驾驶行为特征参数统计分析,综合考虑驾驶行为的时空特性,以驾驶人的连续性驾驶行为模式变化表征驾驶操纵特征的方法能够直观反映驾驶人在驾驶过程中的行为偏好。
b.基于驾驶行为模式转移的驾驶行为风险评估模型总体识别精度为85.71%,驾驶人的行为风险识别精确度较高。
c.相比于低风险型驾驶人,高风险型驾驶人在不同驾驶行为模式间的转移更频繁,为达到行驶需求,会采取多种驾驶行为模式行驶。
随着车联网技术的发展,基于车载设备采集驾驶行为数据,分析多风险情境下的驾驶特性,更好地推动驾驶行为风险评估在智能网联车辆驾驶培训、车辆交互技术个性化设计、面向商业化智能网联汽车保险产品定制化方案设计等领域的应用将是未来的研究方向。
