基于视觉技术的机器人抓取目标识别与定位
2021-11-17王丽荣
王丽荣
(北京信息职业技术学院电子信息学院,北京 100015)
随着人工智能、图像识别等技术的快速发展,工业机器人被广泛应用于各个领域,如工业零件分拣、加工包装、产品检测、目标识别等。机器视觉技术在工业机器人领域的应用,进一步提高了工业机器人的自主能力。谭子会[1]、朱文龙[2]、马红卫[3]等分别将双目视觉技术应用到包装分拣、机器人搬运和机器人抓取物件中,取得良好的试验效果。然而光线、背景、遮挡等因素给机器视觉的稳定性和准确性带来一定的影响,如何解决该问题是当前机器视觉在工业机器人中应用的难点。现有的机器人抓取目标识别与定位通常采用传统的SIFT(尺度不变特征转换)、HOG(方向梯度直方图)特征提取结合SVM(支持向量机)等方法,识别的精度有待进一步提高。基于识别与定位精度要求,本文以零部件拆卸件为研究对象,提出了一种改进单次多边框检测(single shot multibox detector,SSD)的目标识别与定位方法,以提高机器人抓取过程中目标识别与定位的准确性,从而提高工业机器人的自主控制能力。
1 SSD卷积神经网络结构与原理
SSD卷积神经网络为单次多目标检测网络,综合了传统YOLO网络和 Faster R-CNN网络的优点,在保证算法实时性的情况下,可在不同分辨率的特征图上生成大小、长宽比各异的默认框,检测时SSD网络会为每个默认框内的物体生成一个得分,并通过调整默认框,使其更好地匹配目标物体形状,以提高对不同尺度目标检测的鲁棒性[3]。SSD网络结构如图1所示,其包括基础网络层和特征映射层两部分[4],基础网络层为深度卷积神经网络VGG-16,用于高质量图像特征的提取;特征映射层是添加在被剥离的卷积网络末端的网络层,大小随网络层数的增加逐渐减小,可实现多尺度目标的检测。SSD网络的输入图像尺寸为300像素×300像素。
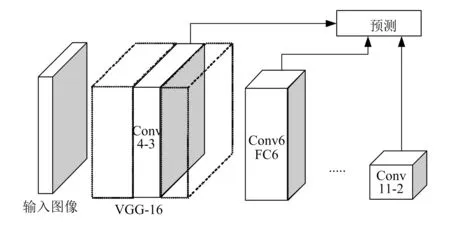
图1 SSD网络结构
2 SDD卷积网络的改进
2.1 网络结构改进
标准SSD网络受结构的影响,导致小目标物体的检测效果较差。其网络高层分辨率低,几何细节信息表达能力较弱,但是感受野区域较大,语义信息表示强烈;低层网络的图像特征分辨率高,且几何细节信息表达强,对应的特征图感受野区域较小,语义信息表示较弱。 SSD 网络利用分辨率来检测物体,即利用原始图像上大面积感受野的上层特征对大体积的目标进行预测,利用小面积感受野的底层特征对小体积对象进行预测。这样就造成在对小目标预测时,因低层网络欠缺高层语义描述而造成检测效果较差[5-6]。为解决该问题,本文对SSD网络进行改进,具体思路为:首先借助特征金字塔网络(feature pyramid network,FPN)在高层特征图中语义表达的优势,采用双线性插值法进行采样处理;然后将处理后的特征与前一层特征横向连接,横向连接过程中,为保证底层特征的定位细节信息被充分利用,应确保连接的两层特征映射在空间上的尺寸相同。通过上述采样和横向连接,实现高层特征和底层特征的强强联合。FPN和SSD网络具体的结合过程如图2所示。
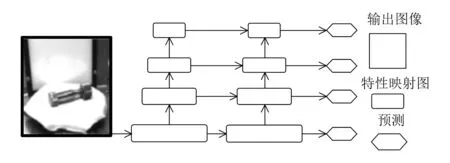
图2 FPN和SSD网络的结合过程
在具体实现时,选用7(Conv1~Conv7)层的小卷积层架构,各层通道数分别为64,96,128,128,96,96,64。用Conv3、Conv5、Conv6、Conv7层作为特征融合映射层,通过特征融合与最后的预测模块,得到预测框结果和目标的种类。改进SSD网络的整体结构如图3所示。
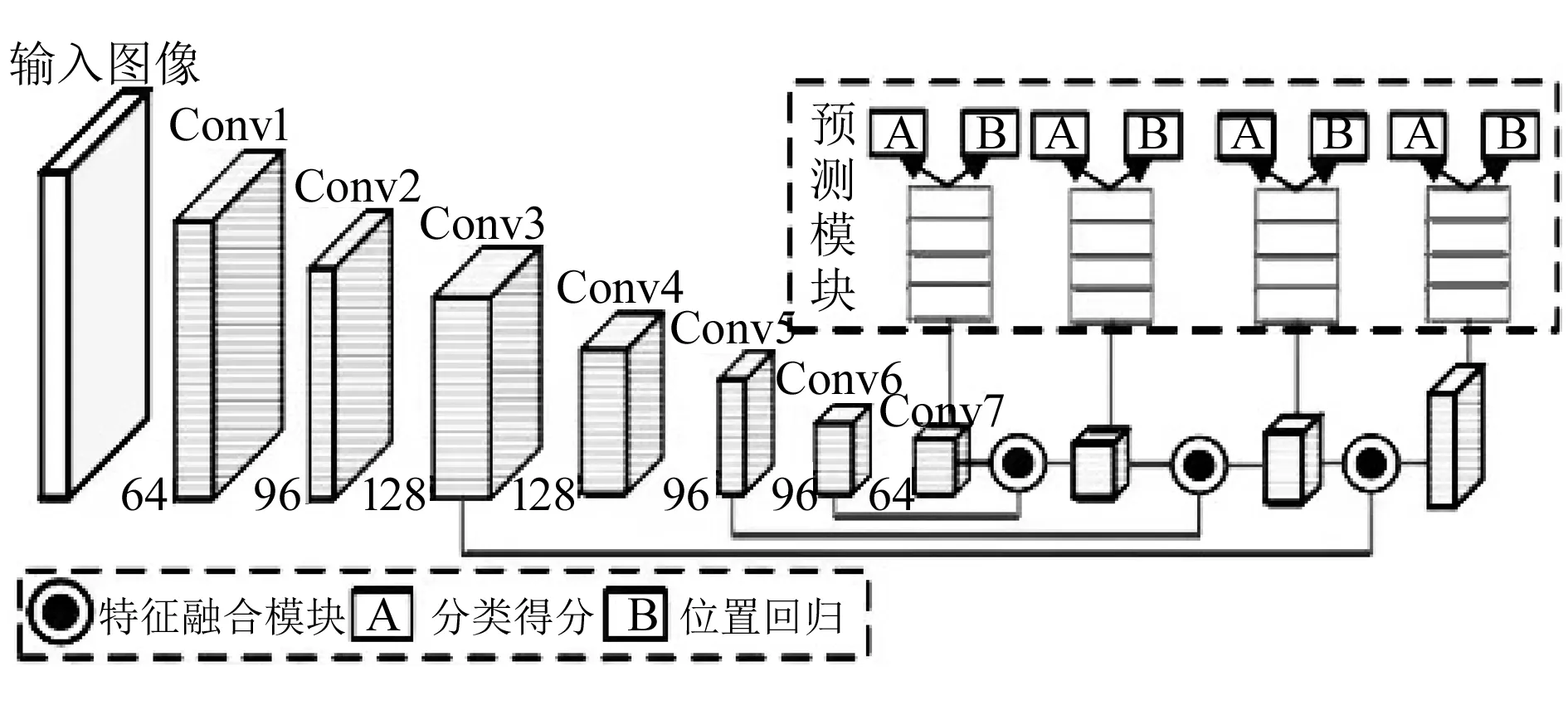
图3 改进SSD网络整体结构
2.1.1特征融合模块
高层特征与底层特征的融合如图4所示。首先高层特征通过双线性插值法上采样到2H(宽度)×2W(高度)×D(深度)的维度;然后底层特征通过归一化操作和卷积操作,将通道数转化为高层特征通道数;最后利用像素相加实现高低层特征的融合。
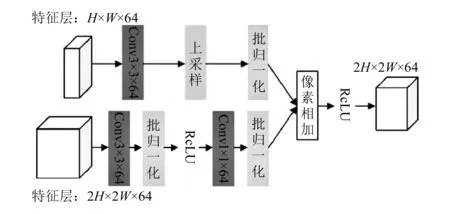
图4 高、低层特征融合
2.1.2预测模块
预测模块是位于框回归任务、分类任务与特征融合模块之间的功能模块,可提取更深层次的图像特征。预测模块结构如图5所示。
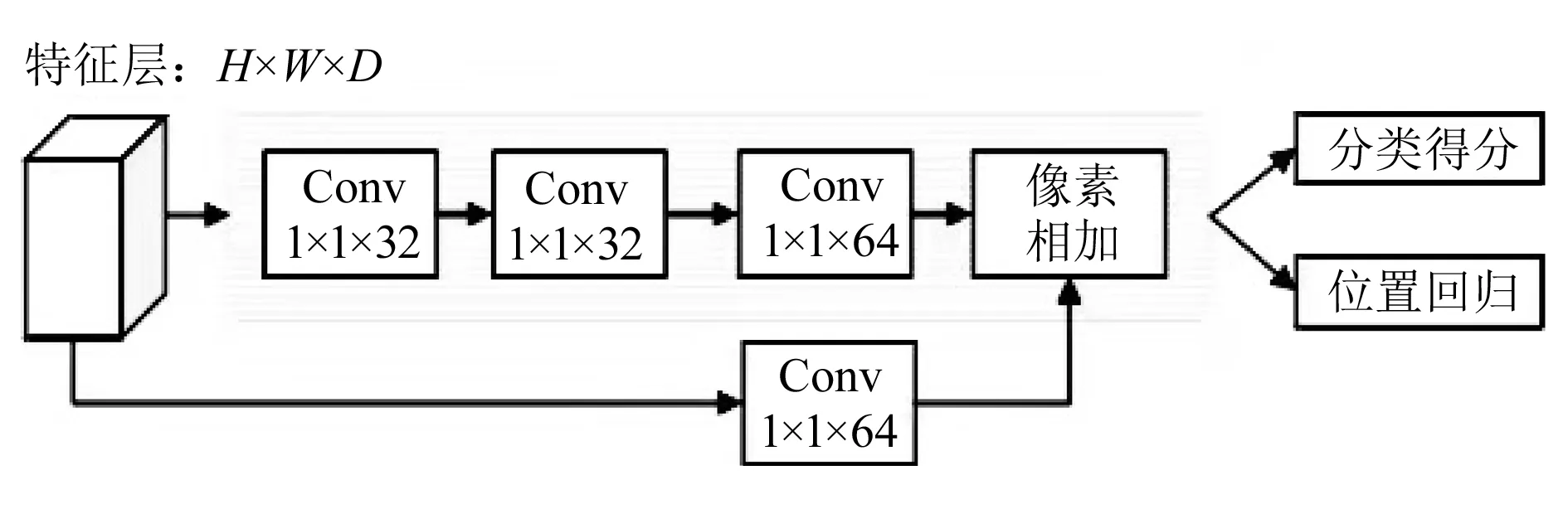
图5 预测模块结构
2.2 SSD数据增强改进
要提高SSD网络的目标识别与定位精度,需对图像特征进行提取,但工业图像往往为小数据集,从而直接影响了SSD网络的性能。为解决该问题,通过数据增强实现对有限数据样本的扩充,具体步骤如下。
首先采用传统移动、旋转、剪切和尺寸变换等方式,对抓取中产生的小数据集进行增强,如图6所示。
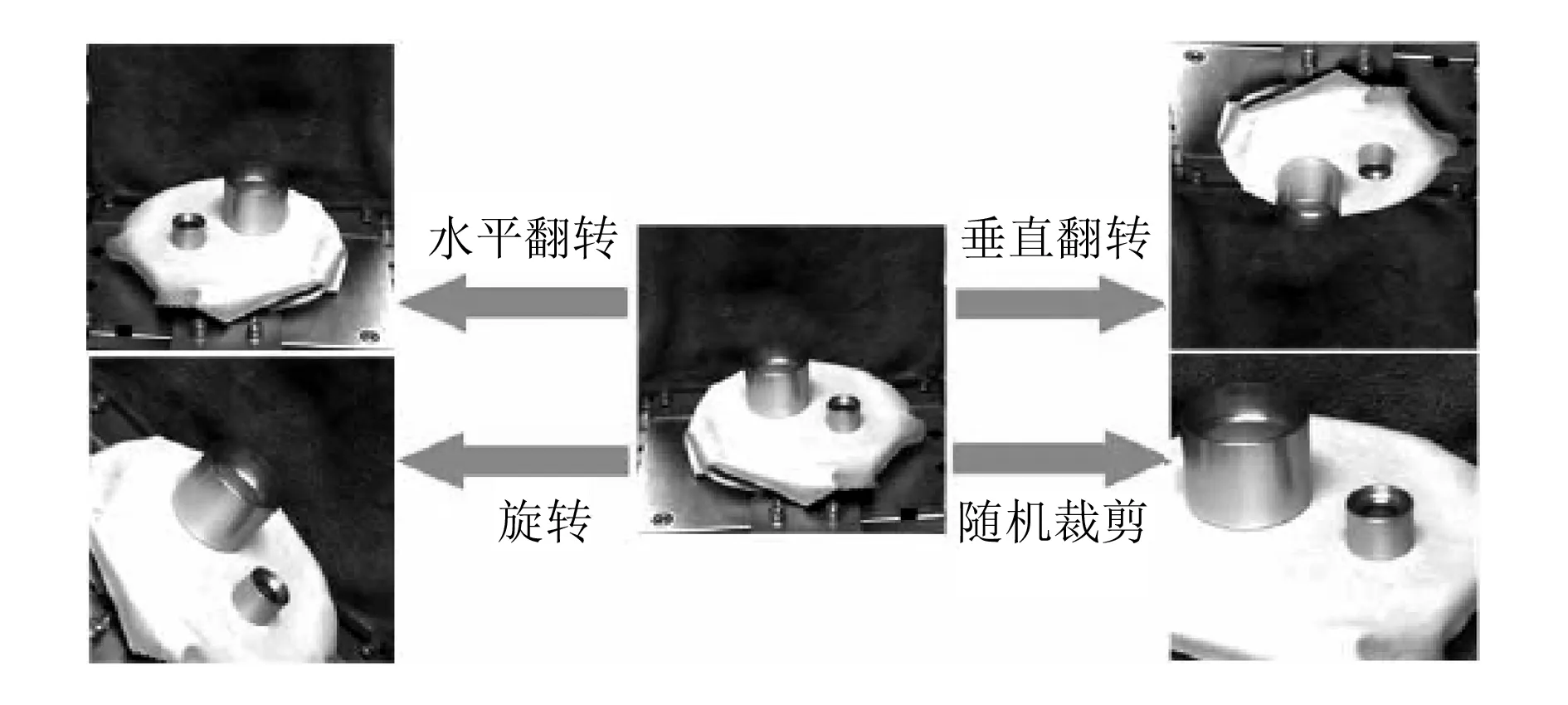
图6 数据增强效果图
其次,针对图像采集或处理过程中可能受硬件和环境等因素影响而包含大量噪声的问题,通过在训练图片中随机加入椒盐噪声和高斯噪声干扰,实现数据增强。
最后,针对机器人抓取目标容易出现相互遮挡的问题,提出随机消除数据增强法表达遮挡效果,具体步骤为:首先随机生成一个消除面积;然后随机选择长方形块的长宽比例及在图像中的相对位置;最后以黑色像素点替代原始图像相应部分像素点,完成对图像目标的遮挡。具体过程如图7所示。
3 仿真试验
3.1 工业数据集采集与标定
以拆卸机械产品中的中心轴、轴承、垫圈、螺母、轴套等图像作为机器人识别与定位的对象。通过机器人身上配置的相机,多角度、多方位对螺母、轴承等需拆卸的零部件进行图像采集,以提高图像数据的全面性和泛化能力。本次试验共采集到3 287张灰度图像,具体样本统计见表1。
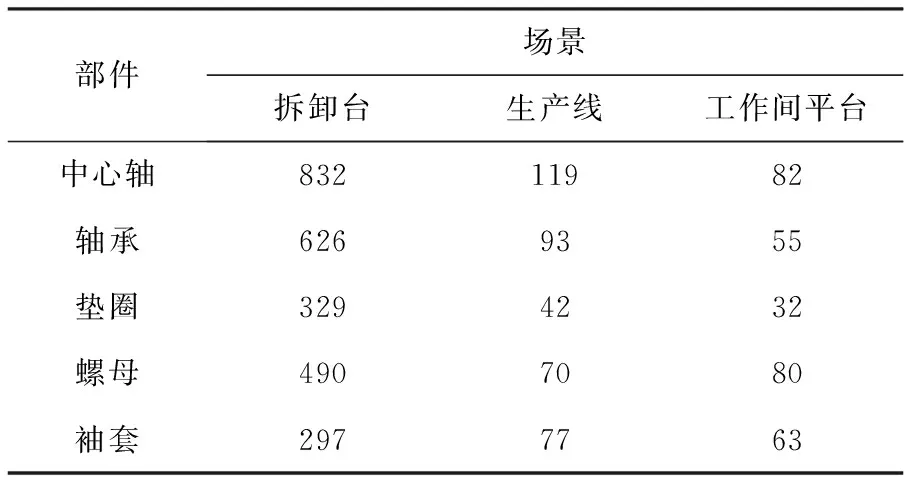
表1 样本统计
考虑到硬件性能,将以上采集到的图像统一设置为300像素×300像素,并对采集到的图像进行数据增强。抽取采集到的数据集中70%的图像作为训练数据集,20%作为测试数据集,10%作为验证数据集。此外,通过标定软件对目标部件的真实框进行标记[7]。
3.2 识别与定位结果
3.2.1不同旋转角度下的SSD识别与定位结果
机器人在图像拍摄过程中会旋转,导致其自身携带的相机也跟着旋转,而不同旋转角度下改进SSD网络的识别与定位算法效果也不同。为对比效果,以SS(选择性搜索)+SIFT+SVM、SS+HOG+SVM为对比算法,得到如图8所示的对比结果。由图可知,在不同旋转角度下,基于改进SSD网络的目标识别与定位准确率高于SS+SIFT+SVM算法和SS+HOG+SVM算法。当旋转角度为15°时,改进SSD网络的图像识别与定位准确率达到87.3%。
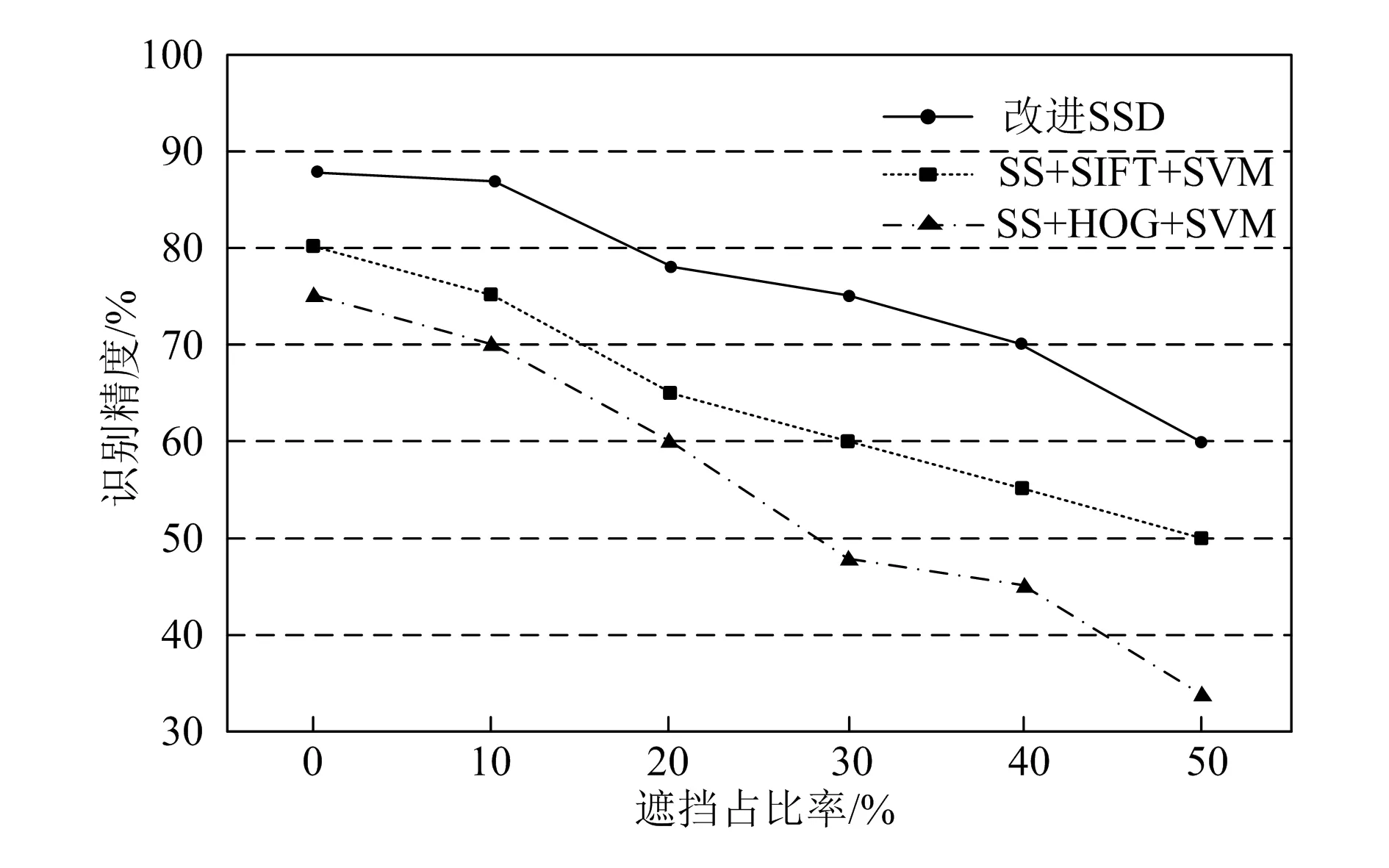
图8 不同旋转角度下图像识别与定位准确率对比
3.2.2不同遮挡程度下算法性能结果对比
以上3种算法在遮挡下的识别与定位结果如图9所示。随着黑色遮挡块占比率的增加,3种算法的目标识别准确率均呈下降趋势,但改进SSD网络的识别与定位准确率要高于其他两种算法,说明本文提出的改进SSD网络可在不同程度遮挡条件下,有效识别与定位机器人抓取的目标图像。
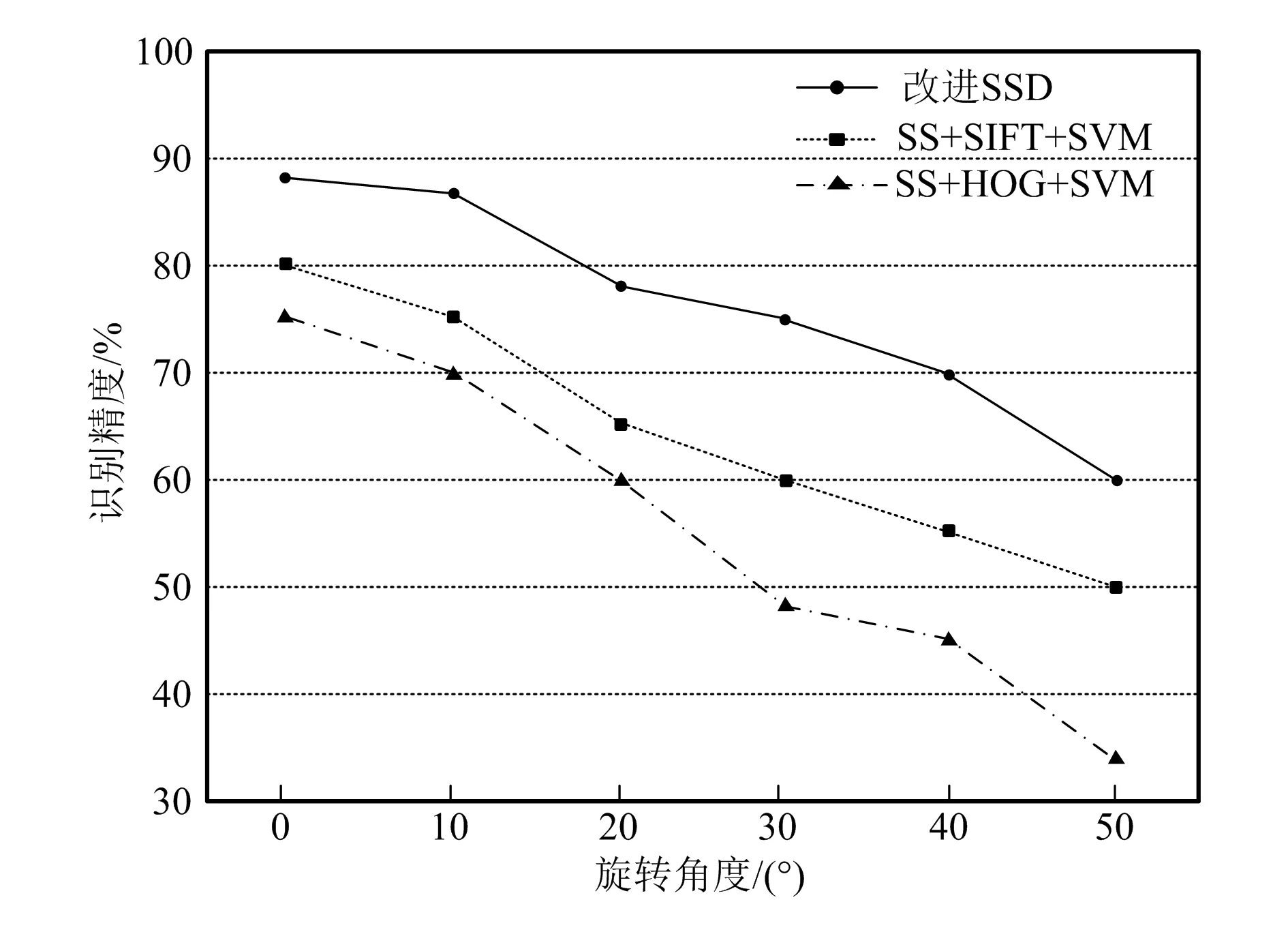
图9 不同遮挡程度算法识别定位结果
3.3 数据增强效果对比
为验证数据增强后的效果,分别训练增强数据和原始数据下的网络模型,得到两种网络模型的训练损失和验证损失结果,如图10所示。由图10(a)可知,原始数据集随训练次数增加,训练损失逐渐降低,而当训练次数达到80次后,验证损失的趋势转为逐渐上升,说明原始数据集模型出现过拟合现象。由图10(b)可知,进行数据增强后,验证损失和训练损失均在迭代一次后数值保持不变,说明该模型没有过拟合。由此说明,数据增强可改善模型训练效果,提高模型性能。
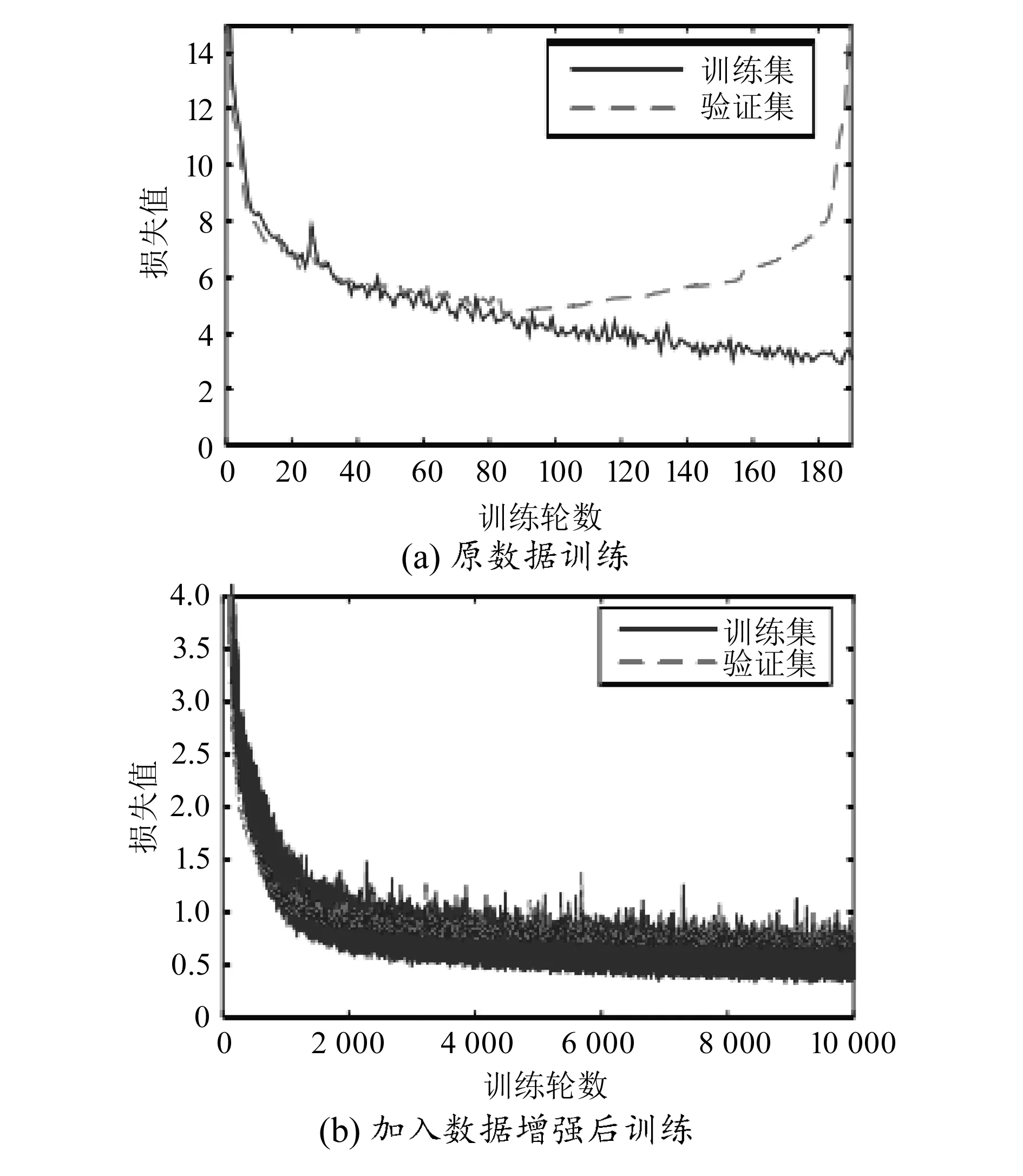
图10 数据增强前后训练结果对比
3.4 改进SSD网络的目标识别与定位展示
图11为单个或多个目标出现时,基于改进SSD网络的机器人抓取目标识别与定位结果。由图可知,单个目标条件下,改进SSD网络可有效识别定位目标;多个目标条件下,同种工件目标出现重叠或不同工件出现遮挡情况下,改进SSD网络也可有效识别定位目标。由此说明,改进SSD网络可有效识别并定位图像中所有目标。

图11 改进SSD算法识别与定位结果
4 结束语
本文提出的改进SSD网络的目标识别与定位方法,解决了工业机器人在小目标识别和定位中遇到的精度低的难题。算法实现了对多旋转角度、不同遮挡程度情况下的工件图像精确识别与定位,且识别与定位准确率高于SS+SIFT+SVM算法和SS+HOG+SVM算法。同时,试验结果表明,改进SSD网络的目标识别与定位方法可对单个或多个目标实现有效、精确的识别与定位,一定程度上提高了基于视觉技术的工业机器人的自主能力。
