基于生成式对抗网络的风场生成研究
2021-11-12叶继红杨振宇
叶继红,杨振宇
(1. 江苏省土木工程环境灾变与结构可靠性重点实验室(中国矿业大学),徐州 221116;2. 徐州市工程结构火安全重点实验室(中国矿业大学),徐州 221116;3. 东南大学土木工程学院,南京 211189)
风灾是常见自然灾害之一,每年都会对我国及全球造成巨大损失。基于数值模拟研究结构风场特性是研究者必备手段,但在现有基于数值模拟的抗风研究中,不少学者是以稳态风场或特性较为简单的非稳态风场作为风速入口,该风场与真实风场存在差异,导致其部分结果缺乏有效性。良好的风速入口是抗风研究的必要条件,需利用合理手段生成满足要求的非稳态风场作为风速入口。
对于风场模拟,其模拟结果需满足以下要求[1-2]:1)具有一定随机性;2)具有时间、空间相关性;3)易满足各种特性要求;4)易加载到各种网格划分的计算域入口。目前模拟方法主要有预前模拟法(Precursor Simulation Methods)与序列合成法(Synthesis Methods)。
预前模拟法基于CFD 数值模拟,利用预前模拟区域生成满足特定要求的风场,将该区域中提取面的数据加载到主模拟区域入口处[3-4]。Raupach[5]通过在预前模拟区域中添加粗糙元提高湍流度。朱伟亮[6]、王婷婷[7]、周桐等[8]和胡伟成等[9]通过在入口处添加随机数、劈尖等方法提高湍流度,并利用循环预前模拟法,计算多种粗糙元参数组合,最终生成与我国《建筑结构荷载规范》[10]中四类地貌要求相似的风场。
序列合成法是以特定风场特性为基础,利用数学手段生成风场。根据现有研究,序列合成法主要分为傅里叶合成法、主正交分解法、数值过滤法等方法。傅里叶合成法由Kraichnan[11]首先提出,可以生成非均匀、各向异性的湍流。Huang等[12]基于Kraichnan 方法,提出随机流场生成方法(Discretizing and Synthesizing Random Flow Generation,DSRFG),该方法将功率谱离散成多个片段再结合随机序列合成方法生成风场,可以满足湍流度、频谱特性等要求。数值过滤法(Digital Filter Method,DFM)由Klein 等[13]提出,该方法基于数值过滤器利用随机数、二阶特性及自相关函数等相关参数生成风场。徐林等[14-15]和Dong等[16]通过引入小波分析中的小波包分解与小波分解方法对DFM 中AR、ARMA 法进行改进,可以提高生成结果功率谱与目标功率谱吻合程度。
根据目前研究现状,预前模拟法与序列合成法两类方法仍存在明显缺点:1)预前模拟法生成风场速度较慢,最终生成的风场特性难以控制,需多次调整参数才能得到合适风场,且生成的风场难以加载到不同网格划分的计算域入口;2)序列合成法是以有限的风场特性为基础,利用数学手段生成风场,但真实风场特性更为复杂多变,以该方法生成的风场特性与真实风场特性总存在一定差异。
生成式对抗网络(Generative Adversarial Network,GAN)由Goodfellow[17]于2014年10 月提出,是目前人工智能领域中较为重要的方法与思想。GAN 模型主要用途为生成数据,通过引入对抗的概念训练生成器,对原始数据直接采样与推断,可以较好生成与原始数据极为相似的数据。Yang 等[18]基于卷积网络与GAN 生成音乐。Gandhi等[19]利用不对称GAN 对时间序列数据去噪,用于提高数据质量。
根据上述方法的优缺点,本文提出基于GAN生成风场,生成速度相对较快,可以满足复杂特性的要求。该方法需大量风场数据用于训练,采用真实风场数据用于训练是最理想方法,考虑到实测风场数据的困难与匮乏,本文通过改进循环预前模拟法生成训练数据。
1 生成式对抗网络训练数据的生成
由于GAN 需要训练数据,考虑到实测风场数据的困难与匮乏,本文通过改进循环预前模拟法生成训练数据。
1.1 循环预前模拟法
循环预前模拟法利用循环边界条件,将下游指定剖面处风场加载到入口处,实现循环流动。该方法基于循环流动,使风场具有无限长的发展空间。风场在经过较长发展空间之后,其湍流等特性得到充分发展并趋于稳定,最终生成的风场特性与真实风场较为接近[20]。该方法虽生成数据速度较慢,但其风场质量相对较高,适合用于训练数据的生成。
循环预前模拟法的具体表达如式(1)所示[20]:

式中: φi为初始风场; φc为循环面风场;ω为缩放因子。
1.2 循环预前模拟法的不足及改进
Morgan 等[21]在论文中指出,循环预前模拟法对循环面数据进行缩尺后,叠加上稳态风场会导致频率失真,其中低频失真较大;朱伟亮[6]在论文中指出,以稳态风场作为初始风场生成的风场湍流度不能满足结构风工程中高湍流度要求。王婷婷[7]通过添加随机数的方法提高湍流度,但该方法会使风速入口不连续,给计算域入口附近带来压力噪音,从而影响最终生成的风场特性。
为改善上述缺点,本文提出基于序列合成法生成式(1)中的非稳态初始风场。序列合成法虽生成数据的特性相对简单,但其可以生成满足湍流度、频谱特性要求的风场[22]。以该风场作为初始风场,可以提高湍流度。同时,由于该风场的频谱特性与循环面风场的频谱特性相似,两者加权组合之后带来的频率失真较少,可以改善频率失真问题。
本文采用的序列合成法具体为Huang 等[12]提出的随机流场生成方法(Discretizing and Synthesizing Random Flow Generation,DSRFG),如式(2)所示。

2 生成式对抗网络的风场生成
GAN 模型主要用途为生成数据,通过引入对抗的概念训练生成器,对原始数据直接采样与推断,可以较好生成与原始数据极为相似的数据。由于该方法对训练样本的分布特征具有较强的归纳能力,可以生成复杂分布的数据,故本文采用该方法生成风场,即以上文改进后的预前模拟法生成风场作为训练数据,利用GAN 模型学习该风场特性,并根据不同输入生成指定特性的风场。
2.1 GAN 的基本原理
图1 以GAN 生成图片为例,展示GAN 模型结构,该模型由生成器和判别器两个相互独立的部分组成。生成器以随机噪音为输入生成数据,判断器判断输入数据属于真实数据的概率。随后利用判断器的输出优化生成器与判断器。

图1 GAN 结构示意Fig. 1 GAN schematic
判断器通过训练,可以学习到真实数据特性,以此区分生成数据与真实数据;生成器通过训练可以生成与真实数据相似的数据。训练良好的判断器可以为生成器提供准确的优化目标;而训练良好的生成器可以促使判断器学习到更多真实数据特性。
在具体实践中,生成器与判断器一般都是多层神经网络,可以保证两者具有较强学习能力,从而得到较好的训练结果。
2.2 GAN 在风场生成中的实现
2.2.1 方法设计
任意一点风速时程都可以通过傅里叶级数展开表示,如式(3)所示:

方法1 是理论上效果最好的方案,可以较好捕捉相位谱与空间位置关系。但该方法一次性生成的数据量太大,难以训练。假设一个平面共有1000 个点,每个点频率数为1000,即相位谱个数为1000,那么该方法需要一次生成1 000×1000个数据,目前GAN 模型的设计与性能很难满足该要求。
方法2 的GAN 模型训练难度最低,单次仅需要生成1000 个相位值,但该方法忽略了相位谱与空间位置的关系。
方法3 模型训练难度也是最低,单次也仅需要生成1000 个值。同时该方法利用相位谱差值可以在一定程度上反映相位谱与空间位置的关系。
综合考虑,本文采用方法3 生成相位谱,并结合幅值谱生成整个风场,其中幅值谱由已知功率谱求得。
2.2.2 GAN 模型约束条件
首先,定义G ANθ为生成单点相位谱θ (m)的GAN模型,其生成器、判断器分别为Gθ、Dθ;GANΔθ为生成单位距离相位谱差值 Δθ的GAN 模型,其生成器、判断器分别为GΔθ、DΔθ。
为使 GANθ、 GANΔθ的生成结果可随高度等因素变化而变化,本文引入幅值谱作为约束条件。通过训练, GANθ、 GANΔθ可以根据输入的幅值谱生成与之对应的结果。由于幅值谱与高度等因素直接相关, GANθ、 GANΔθ结果与幅值谱直接相关,进而可得 GANθ、 GANΔθ的生成结果可随高度等因素变化而变化。
2.2.3 相位谱生成步骤
本文将采用中心递进法组合 GANθ、GANΔθ生成整个风场的相位谱。该方法基本思想是利用GANθ生成入口中心线上点的相位谱,并以此为基础,利用 G ANθ生成的相位谱差值生成同一高度其它点处相位谱。图2 为风速入口剖面示意,则利用 GANθ生成p1,3、p2,3点处相位谱,再以此为基础生成p1,2、p2,2等点的相位谱。
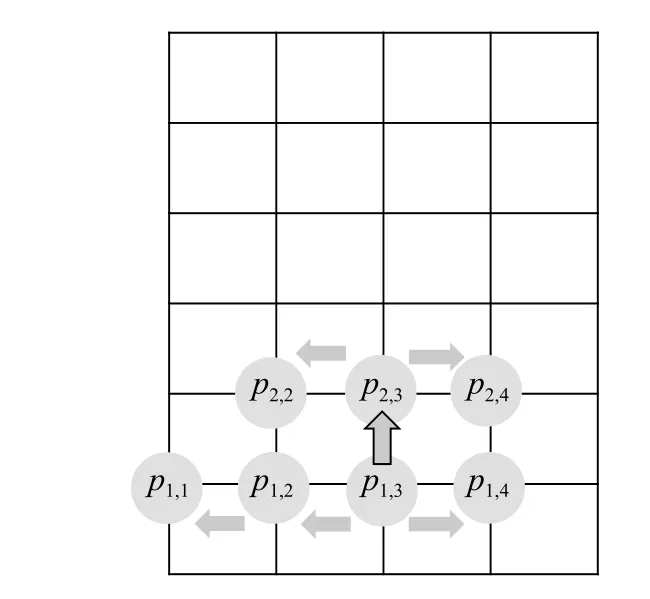
图2 风速入口剖面示意Fig. 2 Wind speed entrance profile
中心递进法具体实现步骤详见文献[19]。利用中心递进法,可以保证入口中心线上所有点相位谱都由 G ANθ生成,其相位谱特性能够符合对应高度的要求;可以保证同层相位谱都由同层中心点递进得到,相邻节点相位谱差值特性满足要求;根据中心递进法的具体步骤中选取最小si,j=f(θi′′,θ′j)的算法可以保证上下相邻节点的相位差值特性近似满足要求。
另外,需明确指出的是,风速入口需要有三个方向上的风速时程。本文把三个方向的风速时程放在同一个模型中一起训练,模型可以根据三个方向幅值谱特性差异,生成不同特性的相位谱与相位差值,不需对三个方向的风速时程分别建模。
2.3 GAN 模型建立及参数设置
根据2.2 节分析,本文需建立 GANθ与GANΔθ两个模型,前者用于生成相位谱θ,后者用于生成单位距离相位谱差值 Δθ。考虑到两个模型仅生成数据不同,其余部分基本一致,故下面仅介绍GANθ模型。
如图3 所示,选用两个神经网络作为 GANθ的生成器与判断器。生成器输入为幅值谱与随机变量,输出为相位谱,其中幅值谱、随机变量与相位谱维度相同,对应神经元个数相同。判断器输入为幅值谱与相位谱,其中幅值谱与相位谱维度相同,对应神经元个数相同,判断器输出为一个判断值。
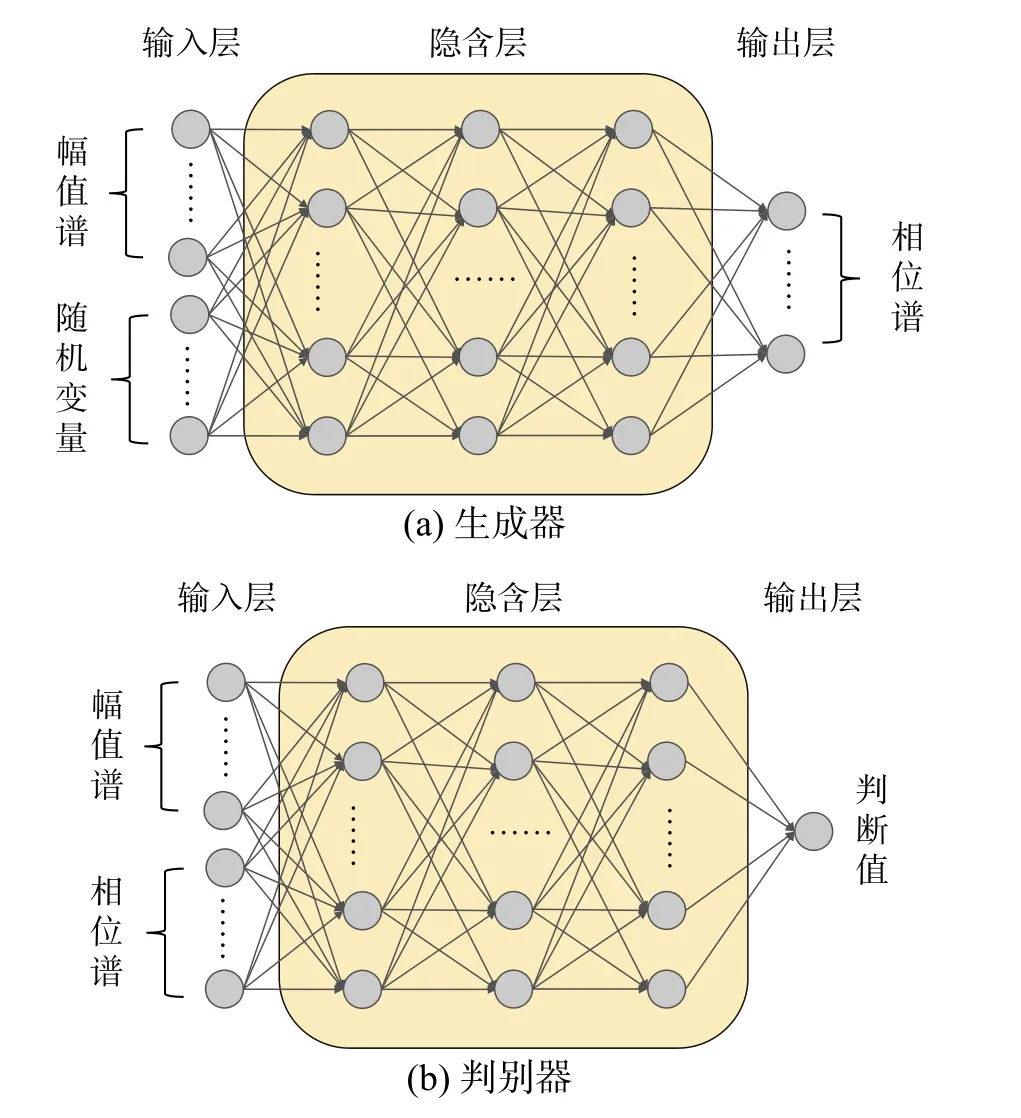
图3 G ANθ模型结构示意Fig. 3 Schematic diagram of G ANθ model
GAN 模型参数设置对GAN 的训练效果及收敛性有着巨大影响,本文通过遍历多种候选参数,最终得到适用于此处应用场景的GAN 参数,如表1 所示。

表1 GAN 参数设置Table 1 GAN parameter settings
3 训练数据的生成与处理
3.1 循环预前模拟法参数设置
本文模拟目标为B 类场地风场,为较好生成该风场,本文根据方平治等[23]和王婷婷[7]论文对循环预前模拟法中计算域及粗糙元进行设置,最终设置方案如图4 所示。计算域顺流向长度、横风向长度、高度分别为1600 m、400 m、500 m;粗糙元交错布置,其横风向与顺流向尺寸均为40 m,高度为35 m,各粗糙元占位尺寸为100 m×100 m,粗糙元沿顺流向布置9 排,横风向布置4 列;循环面提取位置为距离入口1000 m 处横截面。
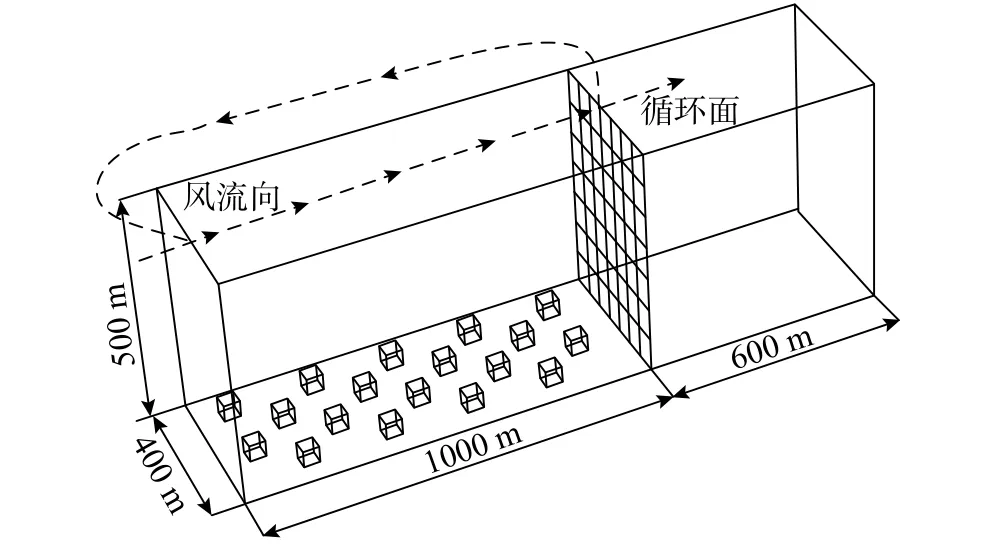
图4 计算域尺寸及粗糙元布置Fig. 4 Computational domain size and rough element layout
3.2 训练数据处理
根据循环预前模拟法中相关设置,其生成的训练数据共计7888 个网格节点;各节点具有3 个方向的风速时程;各方向风速时间总长为290 s,时间步长为0.02 s,其对应的时程长度为14500。
3.2.1 风速时程转换幅值谱与相位谱
根据第2 节相关设计及要求,需利用傅里叶变换将各点风速时程转换为幅值谱与相位谱,并利用式(5)计算相邻点的单位距离相位谱差值。

此处将风速转换为幅值谱与相位谱时,基于数据增强思想,扩充训练样本。具体方法如下:在原有的风速时程中按一定间隔抽取10 段长为2048 的风速时程,抽取方法如式(6)所示;分别利用快速傅里叶变换计算每一段上的幅值谱与相位谱,并计算对应的单位距离相位谱差值。这10 段风速时程的快速傅里叶变换结果相似但不相同,可以提高训练样本数量,增强训练的鲁棒性。其中,由于长为2N的时间序列通过快速傅里叶变换得到的幅值谱、相位谱长为N,则长为2048 的风速时程通过快速傅里叶变换得到的幅值谱、相位谱长为1024。通过上述操作,可为 GANθ提供三个方向训练样本,各方向样本数量为 7888×10=78 880;根据2.3 节GAN 模型设置可得,生成器的输入为2048 维、输出为1024 维;判断器的输入为2048维、输出为1 维。
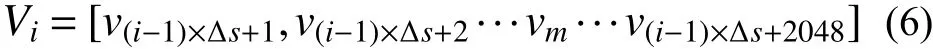
式中:Vi为抽取出的第i条时程曲线;vm为原时程曲线中m时刻对应的风速; Δs为抽取间隔,本文取1000。
3.2.2 数据归一化
为让神经网络更易处理输入数据,一般需将训练数据进行归一化处理,此处结合GAN 的特性,将数据归一化至[-1,1]之间。归一化计算方法如式(7)所示。

4 数据分布特性验证
4.1 定性分析
GAN 结果质量评定通常是一件困难的事情,定性评估是其常用的手段之一。本文将根据数据分布特性定性评估结果质量。考虑到三个方向上的相位谱θ、相位谱差值 Δθ存在一定相似之处,且限于篇幅,本文仅展示、分析 GANθ与 GANΔθ在x方向上的学习及生成能力。
4.1.1 定性分析相关方法概述
数据降维是数据分析处理中常用手段,可以去除原始高维空间中冗余信息,便于计算与可视化。本文采用的降维算法为T-SNE 算法,该算法降维效果较好,可以很好保持数据局部结构,即高维数据空间中相近的点在降维之后仍然相近[24]。
对于GAN 的定量评估,本文采用了Lopez 等[25]提出的1-最邻近(1-Nearest Neighbor,1-NN)方法。Xu 等[26]在论文中指出,1-NN 是定量评估GAN结果的最好指标之一,具有良好的判断力、鲁棒性以及效率。
4.1.2 G ANΔθ模型定性分析
图5(a)展示了x方向上真实幅值与相位差值关系,可以看出,幅值越大,相位差值越小,该分布特性主要因为相位差由相邻节点相位谱差值计算得到,而相邻节点的风速时程曲线较为接近,大幅值对应的相位差往往在0 附近;图5(b)为 GANΔθ输入数据,即相位差值为满足均匀分布的随机数、幅值为真实幅值;图5(c)为 GANΔθ输出数据,即相位差值由 GANΔθ生成、幅值为真实幅值。根据图5(b)、图5(c)可以看出 GANΔθ可以将均匀分布的随机数变成满足特定分布的数据;根据图5(a)、图5(c)可以看出 GANΔθ生成的相位差值与相位谱之间的分布关系和真实数据相似。表明 GANΔθ可以捕捉该数据分布并生成满足该分布的数据。

图5 x 方向相位差值-幅值分布Fig. 5 Phase difference-amplitude distribution in x direction
但幅值与相位差值关系仅能反映其中单一维度的分布特性,对该分布特性的评估仅能体现GANΔθ对低维、局部特性的学习能力。而在GANΔθ的设计与使用中,生成器GΔθ的生成结果为1024 维的高维数据,需进一步对该高维数据分布进行分析。
如图6 直观展示了高维数据的空间分布情况。其中,利用降维技术,将高维数据映射到2 维平面上。降维的数据样本为1000 个真实数据,1000 个输入数据,1000 个生成数据,各数据维度为2048,其中单个真实数据由幅值谱、相位谱差值组成;单个输入数据由幅值谱、随机数组成;单个生成数据由相位谱、生成器输出组成。
根据图6 可以发现生成器GΔθ的输入与真实数据分布完全不同,但经过生成器GΔθ的映射之后,其输出与真实数据在整体分布上基本重合,表明GANΔθ能够捕捉到高维数据的分布特性并生成满足该分布的数据。

图6 x 方向相位谱差值降维分布Fig. 6 Dimensionality reduction distribution of phase spectrum difference in x direction
4.1.3 G ANθ模型定性分析
图7(a)为x方向上真实数据幅值与相位值关系;图7(b)为 GANθ的输入数据,即相位值为满足均匀分布的随机数、幅值为真实幅值;图7(c)为GANθ的输出数据,即相位值为 GANθ生成、幅值为真实幅值。根据图7(a)、图7(c)可得在x方向上, GANθ很好的捕捉该分布特性并生成满足该特性的数据。

图7 x 方向相位值-幅值分布Fig. 7 Phase value-amplitude distribution in x direction
图8 展示了 GANθ对高维、全局数据分布特性的学习能力。降维的数据样本为1000 个真实数据,1000 个输入数据,1000 个生成数据,各数据维度为2048,其中单个真实数据由幅值谱、相位谱组成;单个输入数据由幅值谱、随机数组成;单个生成数据由相位谱、生成器Gθ输出组成。根据图8 可以发现,真实数据分布与生成器输入的随机数据存在区别,当输入数据经过生成器Gθ映射之后,其输出与真实数据在整体分布上基本重合,表明 G ANθ捕捉到了高维数据的分布特性并很好的生成了满足该分布的数据。

图8 x 方向相位谱降维分布Fig. 8 Dimensionality reduction distribution of phase spectrum in x direction
4.2 定量分析
表2 展示了 GANθ、 GANΔθ的1-NN 准确率,两者准确率都接近理想准确率0.5。其中,GANθ结果要略好于 G ANΔθ的结果。

表2 1-NN 准确率Table 2 1-NN accuracy
通过对 GANθ、 GANΔθ的定性、定量分析,可以看出两个模型都能捕捉到训练数据的分布特性并生成满足该特性的数据,其中 G ANθ的学习效果要略好于 G ANΔθ。
5 风场生成及特性验证
本节将从其实际应用角度出发,利用 GANθ、GANΔθ结果生成风场并对其特性进行验证。考虑到训练数据对GAN 结果质量具有较大影响,本节还将对训练数据的风场特性以及循环预前模拟法的改善效果进行验证。
5.1 风场生成
5.1.1 风场生成关键步骤
首先,以幅值谱作为 GANθ、 GANΔθ输入得到输出结果。此处需采用训练数据的功率谱计算幅值谱,若采用其它功率谱,如Karman 功率谱计算幅值谱,其幅值谱特性与训练样本中的幅值谱特性在高频部分具有明显差异,将其作为输入无法生成高质量结果。其次,根据2.2 节应用步骤,基于中心递进法利用 GANθ、 GANΔθ的结果生成相位谱,并结合谱幅值、相位谱生成风场。最后,考虑到傅里叶逆变换得到的是零均值风场,还需叠加平均风剖面。为保持附加条件的一致性,平均风剖面采用训练数据的平均风剖面。
5.1.2 风场生成时间
基于GAN 生成风场的时间为16.6 h,生成结果包含5400 个点,时间总长为20 s,时间步长为0.02 s;GAN 模型训练时间为89 h。根据笔者经验,利用循环预前模拟法生成同等风场至少需100 h,DSRFG 方法需17.9 h。上述计算过程所使用的CPU为i7-6700k。另外,需要注意的是:1)循环预前模拟法所需时间为推测时间,其原因为该方法难以直接生成指定节点数的风场,只能通过推测得到生成指定节点数的风场时间;2) GAN 方法略快于DSRFG 方法,其原因在于前者适合使用快速傅里叶变换而后者不适用。
5.2 训练数据、GAN 结果与目标风场对比
本文模拟目标为B 类场地风场,目标特性包括平均风剖面、湍流度剖面、功率谱。目标平均风剖面引用《建筑结构荷载规范》[10]相关取值;目标湍流度采用美国规范ASCE/SEI 7-10[27]相关取值;目标功率谱采用Karman 功率谱。
图9 展示了训练数据、GAN 生成数据、Kataoka方法生成数据的风场特性以及目标特性。其中,Kataoka 方法是以稳态风场作为初始风场的循环预前模拟法。

图9 风场特性对比Fig. 9 Comparison of wind field characteristics
通过对比训练数据、Kataoka 方法生成数据的风场特性及目标特性,可得:两种数据的平均风剖面基本一致且与目标值吻合较好;训练数据的湍流度与目标值吻合程度优于Kataoka 方法;两种数据的功率谱在高频部分都出现了不可避免的衰减,该现象与网格密度及LES 计算方法有着密切关系,其中Kataoka 方法的模拟结果中高频部分衰减较多,与目标功率谱Karman 谱相差较大,而训练数据与Karman 谱较为接近。通过上述对比,可以看出本文利用改进循环预前模拟法生成的训练数据风场特性较Kataoka 方法具有一定的提升,该改进方法有效且生成结果质量较高。
通过对比训练数据、生成数据的风场特性及目标特性,可得:生成数据的平均风剖面与训练数据完全一致,该剖面与目标剖面吻合较好;生成数据的湍流度剖面与训练数据曲线较为接近,与目标剖面吻合程度好于训练数据;生成数据的功率谱与训练数据基本一致,与目标功率谱在高频部分存在差异。
生成数据与训练数据的平均风剖面完全一致、功率谱基本一致,该现象是由风场生成方法导致,即以训练数据的幅值谱、平均风剖面还原风场;生成数据与训练数据的湍流度较为接近,说明GAN 模型捕捉到了风场相关特性,生成结果质量较好。生成数据与目标值存在差异,该现象是由训练数据导致;生成数据的湍流度剖面与目标剖面吻合程度好于训练数据,其原因为生成数据中隐含统计信息,导致生成数据较训练数据更为平滑,进而使生成数据与目标剖面吻合较好。
5.3 训练数据、GAN 结果特性保持能力
在CFD 模拟中,当风场进入计算域后,经过一定距离的发展,风场特性总会发生变化,而这种变化与计算模型的网格尺度及风场本身特性有关[28]。为验证训练数据、GAN 生成数据的特性保持能力,本文设计了一个空计算域,其顺流向长度、横风向长度、高度分别为600 m、400 m、500 m。分别将训练数据、GAN 生成数据作为风速入口输入到该空计算域中,并提取计算域出口竖向中心线的数据用于处理分析。
在图10~图12 中,展示了训练数据、GAN 生成数据出入口风场特性的对比,可以发现训练数据、GAN 生成数据在计算域中发生了一定变化,且两者变化幅度较相似。在图10~图11 中,出口平均风剖面、湍流度较入口特性有小幅度衰减;在图12 中,功率谱在高频部分发生了一定程度的衰减,但整体没有巨大的异变,在可接受范围之内。这些变化可以认为是风场能量在计算域中随着距离增加发生不可避免的衰减,从而导致平均风剖面、湍流度与功率谱高频部分发生小幅度衰减。通过此处对比可得,训练数据、GAN 生成数据都具有良好的特性保持能力。
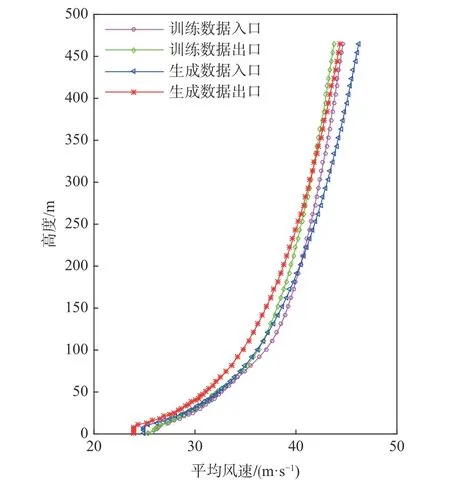
图10 出入口平均风剖面对比Fig. 10 Comparison of average wind profiles at entrances and exits

图11 出入口湍流度剖面对比Fig. 11 Comparison of inlet and outlet turbulence profile

图12 出入口功率谱对比Fig. 12 Comparison of entrance and exit power spectrum
根据GAN 生成数据与目标风场的对比,以及特性保持能力的验证,可以发现利用GAN 模型生成的风场与目标风场特性较为接近,且具有良好的特性保持能力,说明该方法可以作为风场生成的方法。
6 结论
目前风场生成方法仍存在缺陷,而生成式对抗网络(Generative Adversarial Network,GAN)作为人工智能领域较为重要的思想与方法,通过学习数据分布特性生成数据,具有良好的适应能力与生成数据能力。因此,本文提出基于GAN 生成风场。其中,由于GAN 模型需要训练数据,考虑到实测风场数据的困难与匮乏,本文通过改进循环预前模拟法生成训练数据。主要结论如下:
(1)提出基于GAN 生成风场的实现方法:① 通过改进循环预前模拟法生成数据训练两个GAN 模型,即 GANθ与 GANΔθ,前者用于生成单点相位谱,后者用于生成单位距离相位谱差值;② 基于中心递进法利用 GANθ、 GANΔθ的结果生成相位谱;③ 利用相位谱、幅值谱生成风场,其中幅值谱由功率谱计算得到。
(2)从数据分布角度定性评估了GAN 结果质量;利用1-NN 算法定量评估了GAN 结果质量。其结果表明 GANΔθ与 GANθ可以较好捕捉高维、全局数据分布特性,并生成满足该特性的数据。在定量评估中, G ANΔθ平均1-NN 准确率为0.467,GANθ平均1-NN 准确率为0.518,其中1-NN 准确率理想值为0.5,说明 GANΔθ与 GANθ生成数据效果较好。
(3)从风场特性(包括平均风剖面、湍流度剖面、功率谱)角度将GAN 生成的风场与目标风场进行了对比验证,其结果表明基于GAN 生成的风场特性与目标风场特性相近,且通过空计算域验证,该风场具有良好的特性保持能力。基于GAN生成风场与目前生成方法不同,该方法从数据特性角度出发,可以较好捕捉数据特性并生成满足该特性的数据,有效生成高质量风场。
