融合词频-逆向文件频率的受限玻尔兹曼机推荐算法
2021-11-11李千目
王 成,李千目
(南京理工大学 1.信息化建设与管理处;2.计算机科学与工程学院,江苏 南京 210094)
互联网相关应用迅猛发展给用户带来了各种便捷服务,同时也积累了巨量用户交易行为数据,随之而来的“信息过载”使得用户对于有价值的信息选择变得困难,推动个性化推荐算法研究走向深入,通过推荐算法解决信息过载问题具有较强的实用价值,各类推荐算法如协同过滤算法、基于规则推荐和基于内容推荐等得到广泛使用[1]。目前推荐算法普遍存在数据稀疏、冷启动等难题。针对数据稀疏难题,主要采用建立有效的用户评分模型完善数据填充,以缓解用户数据的稀疏性[2];或者基于用户评分信息,采用机器学习,通过矩阵分解、聚类等算法对用户评分数据进行预处理[3],这些方法也取得了一定效果。
Hinton[4]首先提出的受限玻尔兹曼机(Restricted Boltzmann machine,RBM)模型因其推荐准确度较高,在诸多推荐算法中受到较多关注,是一种较为成功的神经网络模型,从现有研究结果来看,在传统推荐算法中有着较好的表现[5]。为进一步提高玻尔兹曼机推荐算法准确度,目前国内外学者提出了较多优化研究。Salakhutdinov等[5]首次提出双层受限玻尔兹曼机模型,协同过滤算法中引入深度学习算法,模型将用户的评分作为可见层,把用户信息作为隐藏层,构建应用概率模型预测评分。Tran等[6]则把几个不同玻尔兹曼机进行整合,着重分析评分序列参数,这些改进取得了不错的推荐效果。Georgiev等[7]进一步将评分值直接应用于受限玻尔兹曼机的可见层,何洁月等[8]也用同样思路将评分用于可见层,提出基于实值的玻尔兹曼机,这些改进降低了算法的复杂度,但存在可解释性相对较差的问题。霍淑华等[9]提出基于项目的推荐模型,张光荣等[10]提出用户标签至实值条件加入受限玻尔兹曼机,这些方法一定程度上缓解稀疏问题。
近年来基于受限玻尔兹曼机的混合推荐算法研究较多,沈学利等[11]提出了受限玻尔兹曼机结合加权的Slope One的混合推荐算法;He等[12]提出基于受限玻尔兹曼机和协同过滤算法的混合算法,在RBM的推荐中引入了最近邻算法的最近邻兴趣相似度;王卫兵等[13]提出受限玻尔兹曼机算法和LFM模型的混合推荐算法,利用RBM生成预测候选集并进行评分,利用LFM模型对结果进行排序;Chen等[14]提出受限玻尔兹曼机和基于邻域因子分解混合推荐算法,利用基于邻域因子分解方法进行用户评分数据建模,利用受限玻尔兹曼机推荐top-k;Kuo等[15]提出基于聚类的受限玻尔兹曼机和差分进化算法混合推荐算法。此外,为进一步优化受限玻尔兹曼机推荐,胡春华等[16]分析社交行为数据,测量用户之间信任与不信任关系,通过构造信任-不信任监督机制,应用于优化受限玻尔兹曼机推荐;Siddiqui等[17]提出受限玻尔兹曼机的无向图形模型和加权方案,利用竞争性编码推荐引擎生成的概率来进行预测,通过机器学习能在大数据环境下进行推荐。
虽然受限玻尔兹曼机算法经过改进,但仍然存在数据稀疏性、容易弱化个体用户的需求和抗过拟合能力较差的问题,而将两种协同过滤算法进行融合已成为一个重要的研究方向[18],通过将受限玻尔兹曼机融合特定算法有助于进一步提升推荐准确率,缓解已存在的问题。由于词频-逆向文件频率(Term frequency-inverse document frequency,TF-IDF)算法优势在于提取主题词、分析特征词词频与类别之间的关系、对不同的文档能给出较好区分度的推荐结果集[19],因此本文试图对这两种算法加以融合,提出融合词频-逆向文件频率的受限玻尔兹曼机推荐算法,可以较好地将用户、项目等特征融入到模型中,并在实验中验证融合推荐算法准确度。
1 融合TF-IDF的受限玻尔兹曼机推荐算法
融合词频-逆向文件频率的受限玻尔兹曼机推荐算法(Restricted Boltzmann machine & term frequency-inverse document frequency fusion algorithm,RBM-TFIDF)利用受限玻尔兹曼机建构用户评分二维矩阵,实现缓解普遍存在的稀疏问题,并得出玻尔兹曼机预测结果集。利用TF-IDF算法处理交易数据中的物品属性信息、生成评分信息,最终将两者评分融合最终生成推荐集。
1.1 受限玻尔兹曼机算法
受限玻尔兹曼机主要由可见层v、隐藏层h、权重w、对应偏置单元a和b所组成。可见层v用于接受输入参数,隐藏层h用于输出训练结果,偏置单元表示受欢迎程度,同层之间各节点相互独立,可见单元和隐藏单元之间节点全部一一相连,其结构如图1所示。其中可见单元和隐藏单元都为二元变量,状态取值一般为{0,1}。

图1 RBM结构图
RBM模型的权重矩阵为wi,j,指定了可见层单元vi和隐层单元hj之间边的权重。对每个可见层单元vi设有偏置ai,对每个隐层单元hj设有偏置bj,每个单元的能量函数(v,h)[20],如式(1)所示。
(1)
在RBM模型中,可见层、隐藏层间的能量函数联合概率分布为
(2)
式中:Z为配分函数,可以使节点集合的所有可能状态下e-E(v,h)的和为1;同理,对全部隐藏层配置求和,得到可见层的取值边缘分布为
(3)
RBM的层内节点没有相连的边,可见层节点取值情况决定了隐藏层激活状态,可见层v对隐藏层h的条件概率为
(4)
每节点的激活概率表示见式(5)和式(6),其中可见层节点数为m和隐藏层节点数为n
(5)
(6)
式中:σ代表逻辑函数。
1.2 利用对比散度算法训练RBM

利用对比散度(Contrastive divergence,CD)算法训练RBM,期望获得最优化权重矩阵。通常CD-k算法中,进行吉布斯采样一次即可,k表示需要采样次数,在可见层样本数据已知的情况下,随机初始化Wij,对样本循环下面的计算过程:
(1)通过可视层vi求出隐藏层hj,设Wij的正向梯度为:pos(wij)=vihj。
(2)由隐藏层hj再来反向计算vi,此时算出的vi和hj已经变化,Wij的负向梯度neg(wij)=vihj。
(3)更新权重wij=wij+a*(pos(wij)-neg(wij)),其中α为学习率。定义epochs训练次数,循环执行上述描述过程,循环迭代,直到收敛,即vi和hj很接近。
1.3 TF-IDF算法
本文使用TF-IDF算法来计算预测结果。TF-IDF算法主要由两个因素组成,即词频(Term frequency,TF)和逆文档频率(Inverse document frequency,IDF),词频即某词语的频率。为防止词频偏向长的文件,需要进行归一化处理,一般是词频除总词数,如式(7)所示
(7)
式中:mti表示在文档i中的词语t出现次数,M表示所有词语在文档中出现次数的总和。
逆文档频率用于衡量字词在文档中的普遍程度,字词在文档中出现越少,则字词的区分度越高,重要性也就越高。逆文档频率由文档总数除以包含特定字词的文档数,再取对数而获得,其计算公式如下
(8)
式中:D为文档总数,mt为包含词语t的文档数。TF-IDF由TF值与IDF值相乘而得到结果,通过过滤掉常见字词,留下重要的字词。字词重要性与在文档中出现的频率成正比,但与出现的文档数增加成反比。其计算公式如式(9)所示
(9)
以下计算预测评分[21]。项目综合相似度sim(a,u)计算,最近邻集合U由排名前K的邻居组成,则特定用户a的推荐初始评分如公式(10)所示
(10)

2 实验结果及分析
本文实验数据采用GroupLens Research[22]的MovieLens 1M用户电影评分数据,MovieLens网站收集了大量的用户电影评价数据,适合进行推荐算法实验和对比分析。文中采用Python编码,服务器为AMD处理器3.60 GHz,内存8.0 GB,Windows10 64位操作系统的计算机上运行。
2.1 数据集及评价指标
数据集主要由用户、评分、电影等几个方面的信息所构成,是目前推荐算法常用的数据集之一,其中ratings.dat文件包含实验所必需的用户评分信息,Movies.dat文件为电影信息,users.dat文件为用户信息,上述文件记录有6 039名用户关于3 882部电影的评分记录,共有1百多万条。
数据稀疏度即评分矩阵中空值所占比例,用户评分数据相对比较稀疏,训练集的稀疏度约为95.734%。本节验证相关算法的推荐质量,以及RBM-TFIDF算法的参数对推荐结果的影响。
2.2 推荐结果的评价指标
为评价推荐结果质量,采用平均绝对误差(Mean absolute error,MAE)和均方根误差(Root mean square error,RMSE)作为评价指标。
(1)平均绝对误差。平均绝对误差定义为真实值和预测值之间误差绝对值的平均值。设用户对于n个项目的实际评分为{r1,r2,…,rn},推荐算法给出的预测评分为{p1,p2,…,pn},那么此用户的MAE值如式(11)所示,MAE值越小则推荐的准确度越高。
(11)
(2)均方根误差。均方根误差对评价较大或较小误差敏感,能较好地反映测量的精密度,其评价指标为预测值、真实值之差取平方和,并取评估次数比值的平方根,均方根误差公式定义如下所示
(12)
上述两个评价指标数值越小则推荐结果越好,一般情况下MAE数值相对较小,但在误差离散度高、或者存在异常值的情况下,由于RMSE对偏差做一次平方,RMSE数值随之放大,有助于发现是否存在异常值情况。
2.3 比较方法
为验证算法的有效性,本文把RBM-TFIDF算法和经典推荐算法进行比较,选择了RBM模型为基础的混合推荐模型IC-CRBMF[23]、UI-RBM[24]、IR-RBM-WSO[11]和DE-based CRBM[15]。
2.4 实验过程与结果分析
实验的训练数据集为MovieLens中的ratings数据,通过随机产生的评分集合,实验中对参数进行不断更新,尽量把误差缩小到一定范围,考察了模型对比散度算法迭代次数对于模型推荐效果的影响,迭代次数起始值为3次,最高为60 次;同时考察了模型中TF-IDF候选结果集对推荐结果集的影响;最后针对参数调优情况与常见的推荐算法和混合推荐算法进行比较,发现参数设置相同的情况下,本文算法的推荐效果最优。
2.4.1 设置模型参数
本文算法的RBM部分,通过TensorFlow构建RBM,首先确定隐藏层中的神经元数量hiddenNodes为22,设置可见层偏差bias参数、隐藏层hiddenBias参数、连接可见层visibleBias参数和隐藏层的权重。因为隐藏层中的每个神经元最终都会学习一个特征,利用TensorFlow sigmoid 和relu实现RBM模型所需要的非线性激活功能。设置学习率为alpha=1.0,创建梯度更新权重和偏差函数,并计算平均绝对误差。
考察对比散度算法在不同训练epochs参数下对推荐准确度的影响,设置3、5、10、15、20、25、30、45、60 个epochs,每个epochs使用10个批次,尺寸为100,训练结束绘出epochs与MAE关系图,横坐标为epochs数,纵坐标为MAE值,从图2 RBM不同epochs训练与推荐准确度MAE关系图中可以发现,在epochs值等于20时,模型趋于稳定,超过30后,MAE值虽有下降,但下降幅度不大,对推荐效果帮助不明显。
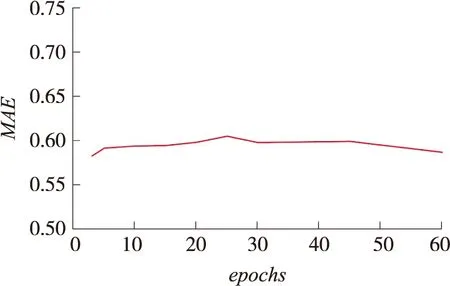
图2 RBM不同epochs训练对推荐结果MAE影响
考察模型中TF-IDF候选结果集大小对推荐结果MAE影响。设置模型的RBM训练次数epochs=15,TF-IDF候选集为20、60、100、140、180、220、260、300、340、380时,各模型的MAE情况如图3所示。由实验结果可看出:在其它参数保持不变的情况下,随着候选集变大,推荐准确度有所上升,单计算所耗时间也有增加。当候选集为220时候,推荐效果趋于较优。
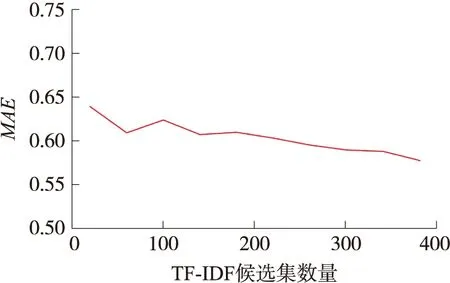
图3 TF-IDF候选结果集大小对推荐结果MAE影响
2.4.2 本文相关算法对比实验
本实验将建立在模型的epochs为15情况下,对本文推荐模型与RBM算法进行比较,两者均使用相同RBM算法构建评分矩阵,RBM算法首先给出推荐结果作为参考,RBM-TFIDF不断调整候选集参数,得到不同候选集下的最终推荐结果。实验结果如表1所示,对比结果如图4 所示。从表1和图4可得以下结论:本模型在推荐准确度上优于原始RBM算法,MAE与RMSE值分别较后者提升了3.22%与6.06%,通过融合TF-IDF算法提升评分数据质量,进一步缓解RBM算法数据稀疏,获得相对较好的推荐效果。
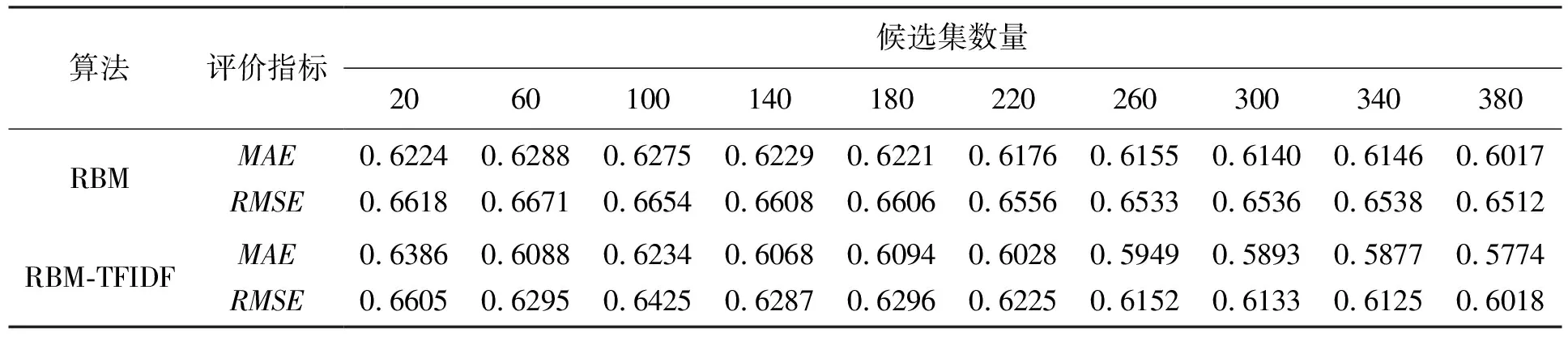
表1 RBM-TFIDF与RBM推荐试验结果

图4 RBM-TFIDF与RBM推荐对比图
2.4.3 消融实验
为了验证模型RBM和TF-IDF对融合算法RBM-TFIDF的作用,在MovieLen数据集上进行消融实验,结果如表2所示。RBM和TF-IDF两种算法效果相近;从测试集中不同用户的MAE、RMSE指标分布来看,RBM在提取用户特征向量方面表现较好,推荐结果相对平稳,具有较高可靠性;而TF-IDF整体推荐效果较好,但是存在推荐集与测试集匹配度不稳定的问题,表现为个人MAE、RMSE评分跳跃性较大;RBM-TFIDF推荐结果MAE、RMSE整体较优且推荐评分平滑度较好,相比于RBM推荐算法,MAE、RMSE分别提升了2.5%、5.2%,同时能避免TF-IDF的推荐结果跳跃性过大问题。

表2 消融实验评价结果
2.4.4 混合推荐算法对比实验
与以RBM模型为基础的混合推荐算法推荐对比。为进一步验证推荐算法性能,选取了近几年提出的基于RBM算法的混合推荐模型IC-CRBMF、UI-RBM、IR-RBM-WSO和DE-based CRBM,经过实验,其MAE值分别为0.71、0.72、0.69和0.686,而本文算法RBM-TFIDF的MAE为0.60,与IC-CBMF、UI-RBM、IR-RBM-WSO和DE-based CRBM相比,分别提高了15.4%、16.6%、13.0%和12.5%,具体MAE对比结果如图5所示。

图5 基于RBM的混合算法推荐对比
3 结束语
本文提出的融合词频-逆向文件频率的受限玻尔兹曼机推荐算法,其推荐准确率要高于RBM推荐算法,也优于参与比对实验的其它基于RBM算法的混合推荐算法。RBM-TFIDF算法首先利用受限玻尔兹曼机生成用户评分矩阵,缓解数据的稀疏问题;其次进行余弦相似度计算得出候选集评分;利用TF-IDF算法获得带评分的候选集,通过融合两者评分给出最终推荐集,并给出Top-N推荐。利用不同算法相似度,能进一步表达项目内关系,并得到较为理想的推荐效果。
